
![]()
In the past weeks, I have been involved in discussions about making the process of deploying recommender systems more efficient, and I have also contributed to designing a part of an internal bootcamp to introduce the use of recommender systems and personalization at Ubisoft.
These discussions made me think and research about the design of a recommender system and what such a service could look like in 2024. So, I decided to compile my experience and the findings of my research into an article that could be useful for anyone curious about it.
Disclaimers:
- If you are very early in your recommender system journey, my go to book is Kim Falk Practical Recommender Systems
- There will be no discussion about algorithms, datasets, etc. This article focuses more on the overall vision of how a recommendation service should look, so it’s pretty high-level
Core Features of a Recommender System
For this section, I decided to dig into various documentations and papers from some companies to get a sense of the current trends and specifications of a recommender system and the expectations of this kind of service.
Disclaimers:
- I will give some input on features that I think are fundamental for a recommender system, but keep in mind that this can only exist in a setup where your user and item tracking definition is minimal (basically, you can accurately know what a user is doing in your application, and it’s not sampled).
- All this content comes mostly of public documentations of companies like AWS, Spotify, Shopify, Recombee
Exposing Trends
I always noticed that popularity is a strong element in any recommender service, and this component is essential in any good service that can provide recommendations. For example, there are multiple endpoints connected to the popularity in the following documentation of these services:
- Get Artist top tracks on Spotify developers API.
- Get Popular items on AWS personalize Popular Item Recipe.
- Get popular logic on Recombee.
These are not just endpoints with no setup, but they offer a capacity for interesting configuration. For example, on Spotify, you can get the popularity of tracks of an artist based on the market.
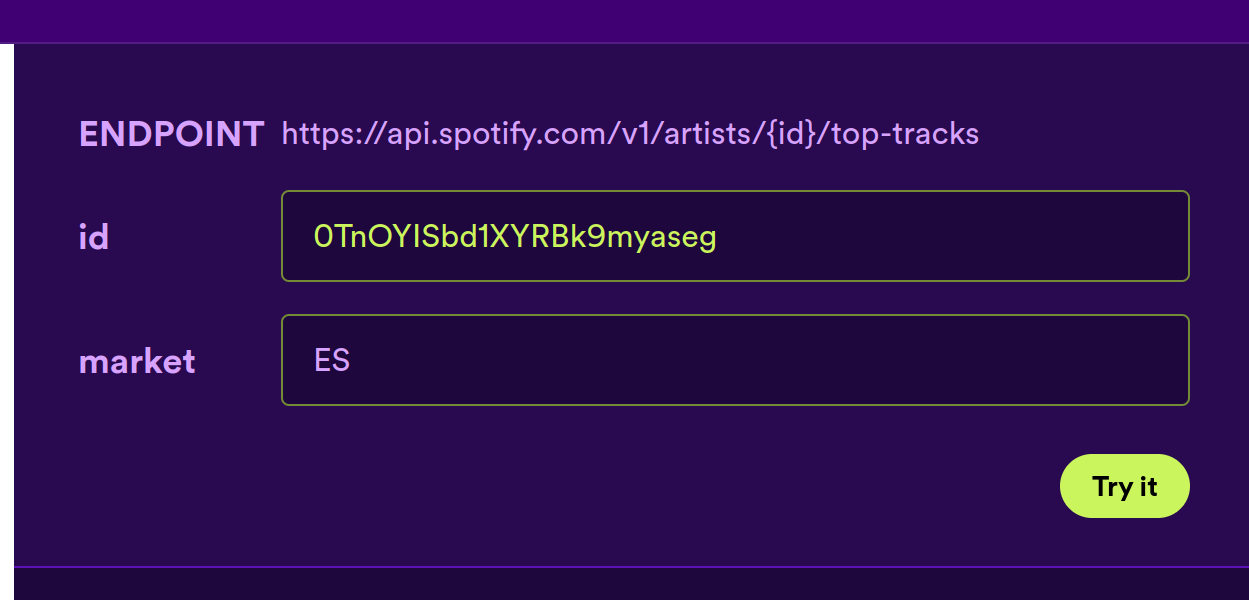
For AWS or Recombee, you can tweak the time period over which the popularity should be measured:
- on AWS, it looks like between 1 hour to 1 day
- on Recombee, it looks more flexible from hours to days, with the default being 14 days
Being able to collect trendy items is essential. In the section Fallback Strategies: A Pillar of Reliability of this article, I experimented with different strategies, and the most popular items were the most efficient. So, I believe that having the ability to efficiently collect the most popular/trendy items is a must-have when you start to design a recommender system strategy (like Google says, the best first step of an ML project is to not do ML).
Enhancing User Experience with Related Items
Following the theme of the popularity feature, another crucial aspect of a recommender service is the “related entity feature”. This functionality offers recommendations when you are browsing a specific content page. For instance, while watching a TV show on Netflix, the service can suggest similar shows or related content that other viewers enjoyed.
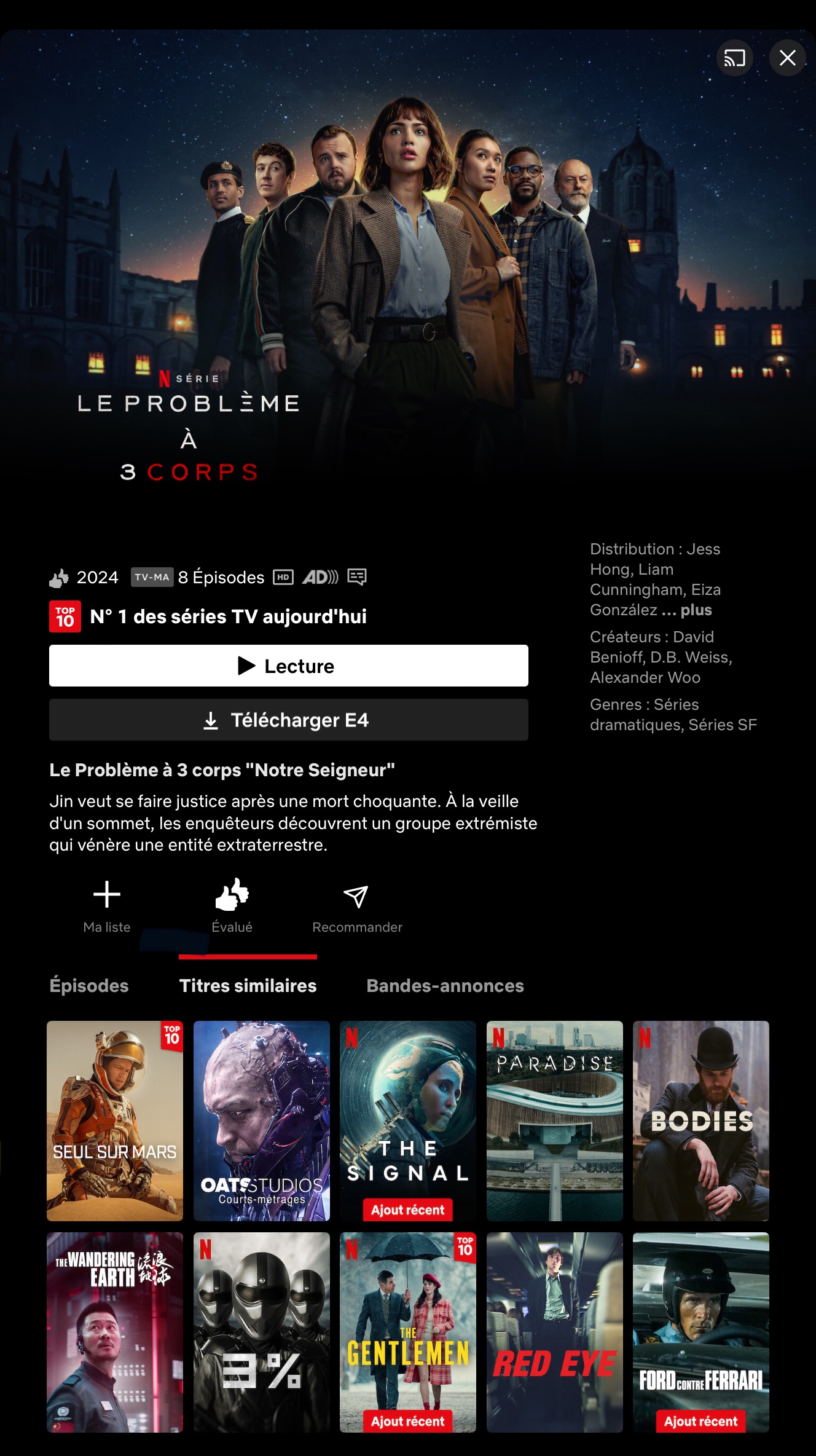
This feature enhances the user experience by seamlessly integrating recommendations that are likely to align with the viewer’s current interests, encouraging deeper engagement with the platform’s content. This kind of feature seems to be really standard in the endpoints provided in recommendation system services, for example:
- AWS Personalize offers the Related Items Recipe.
- Recombee with the Items to Item or Users to User recommendations.
- Shopify with its Related Products or Complementary Products.
- Spotify and the Get Related Artists.
To develop this kind of feature, multiple strategies can be put in place, such as co-association matrices, similarity searches, and many other options that can be envisioned.
These approaches can bring great value to any application with a vast and diverse catalog with a very limited cost.
Balancing Exploration and Exploitation
In the field of recommender systems, there is always a balance to be found between exploring new content and exploiting what is already known to be popular. This balance, known as the explore-exploit tradeoff, is a key part of decision-making in general.

By exploiting, the system recommends content that is popular and likely to meet the user’s needs based on general preferences. On the other hand, exploration allows the system to find less popular content that might be a perfect match for the user - content they will love but haven’t discovered yet.
There are several helpful resources on this topic. For example, an article by Minmin Chen from Google, presented at the RecSys 21 conference, and an article by Yu Zhang from the DoorDash tech blog. Nowadays, most methods for balancing exploration and exploitation rely on reinforcement learning techniques. The goal is to find the best balance to boost both the short and long-term experiences of users, which can lead to better user retention. However, it’s crucial to keep a good track of user responses to both the recommendations and items in the catalog.
This concept is practically applied in recommender system designs, such as AWS’s Personalize service, which includes the user personalization recipe. This recipe features an exploration_weight parameter that can be adjusted to control the level of exploration (0 for no exploration, 1 for maximum exploration, with a default value of 0.3).
Advanced Filtering and Promotion Techniques
Controlling the output is crucial in recommendation systems. For most APIs, like those from AWS, Recombee, or Spotify, the maximum number of items to return is a parameter in the API call. Usually, there’s a hard limit of about 100 items, with a default value around 20-25 items based on the service. Limiting the number of items is practical because receiving a catalog of hundreds of items at once can be overwhelming (and slow).
Systems offer ways to filter and adjust the output of the recommendation system in two main ways:
- By allowing users to set selection criteria. A great example is on Spotify’s get-recommendations endpoint, where users can filter recommendations based on song characteristics (like danceability, acousticness, etc.).
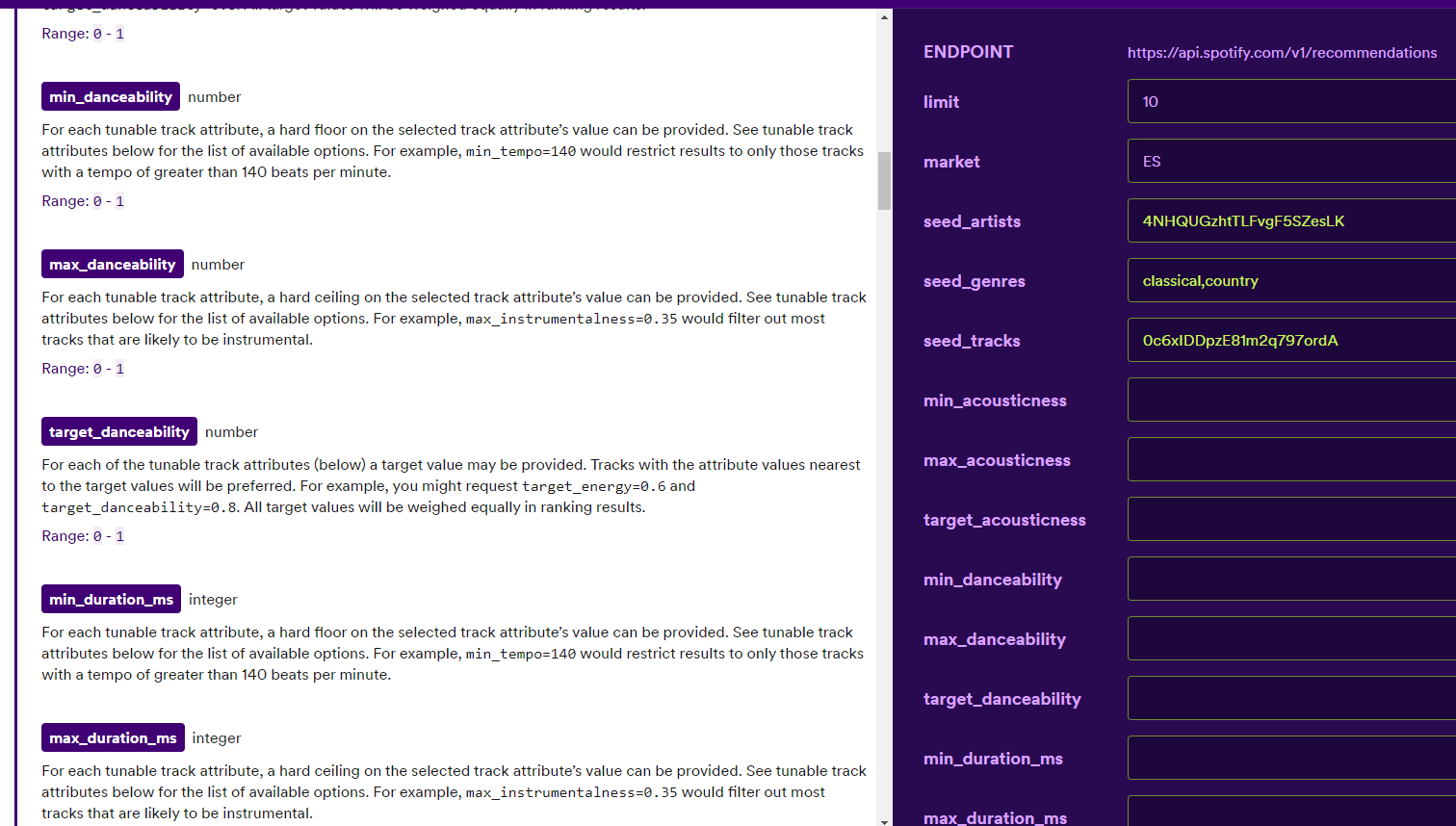
- By incorporating a concept of item promotion, where specific content can be highlighted in the recommendation process. AWS Personalize introduces the concept of promotion (limited to 25 items), where each item is associated with a weight. Recombee uses a similar concept called boosted items.
The ability to promote certain items is key for platforms/applications with a real content strategy. It allows for specific rules to be set and can enable manual influence over the recommendations. This approach is likely used by platforms like Netflix, where such mechanisms are integral to their recommendation logic, even if not visibly so.
Anticipating User Actions
When setting up a pipeline to collect and process data related to users, good practices suggest having a dataset structured as follows:
date: the date of the actionuser: identifier of the useritem: identifier of the itemaction: type of action that the user performed on the item
This structure is basic but serves as a starting point for other datasets (for instance, from this action, you could compute an implicit rating). This approach appears to be a standard, as Recombee, for example, supports several typical action formats (view, purchase, rate, added to cart, bookmark) by default in its database. These actions then become inputs for their recommendation logic.

Predicting a user’s next action can be crucial for a business. AWS Personalize, for instance, offers a recipe to predict the next best action of a user within an ecosystem. While their examples are high-level (like app downloads, etc.), you can extend this to recommendations by aiming part of the user flow to be optimize for specific actions (like filtering the recommendations based on predicted filters that fit the next best action. For instance, in the case of Spotify, filter more on danceability than acousticness because the user is in a dance mood).
That concludes my points on what I believe are fundamental functionalities of a recommender system. Now, let’s have a look more into how these can be integrated in detail.
Design Principles for a Recommender System
For this section, I’ll focus more on analyzing the best ways to design a recommender system and its integration into workflows, rather than on the features of the recommender system itself.
The Two Steps Approach: Retrieval and Ranking
This concept, which I often discuss and mention once or twice a year on my blog or at work, is well-summarized in an article by Eugene Yan that presents the approaches of companies like Alibaba, Facebook, JD, DoorDash. For me, the most crucial aspect is the diagram showing the overall flow of such a system.
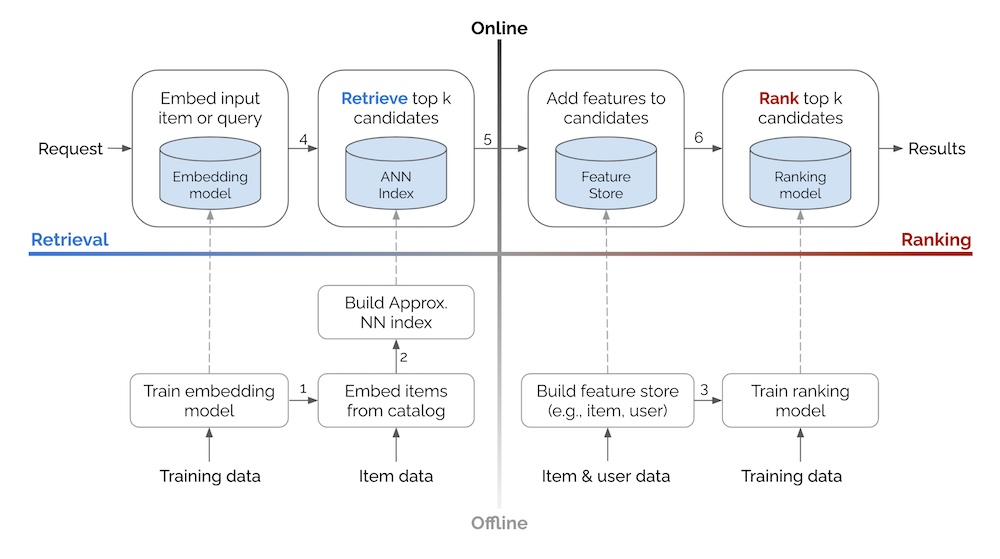
(Even Oldridge from Nvidia proposed a 4 steps variation, maintaining the flow but emphasizing the filtering/business logic.)
The concept is straightforward:
- #1 Design a candidate retriever to identify the most relevant items for a user (based on user and item characteristics) minus the items that the user can no longer interact with.
- #2 Rank the candidates (based on user and item information).
From my perspective, this approach is very appealing because:
- It simplifies the process, making it easier to understand and adopt due to its modularity.
- It avoids the need for a single complex model (which is harder to debug, test, and requires more resources).
- It opens up possibilities for standardization (through basic retrieval and ranking strategies) and reliable block definition
- It allows for customization with additional pipelines on the side.
Honestly, in my recent personalization projects, I’ve been adopting this approach, generally starting with a V0 of my pipeline focused only on retrieval and iterating from there.
Routes for Personalized Recommendations
In this section, I’ll focus more on the routes/endpoints that are essential for personalizing the user experience.
Disclaimer: These routes are inspired by the different endpoints available on AWS Personalize and Recombee, it’s a big mashup of all these services with a few tweaks coming from my experience.
I see three main paths:
get recommendations: Endpoint to fetch personalized recommendations.get trends: Endpoint to fetch trending items.get random items: Endpoint to fetch a random list of items.

All of these routes will return a JSON object with the following structure:
- recid: ID of the recommendations produced.
- recommendations: A list of dictionaries, each defined by an
idkey with the ID of the entity recommended. - source: Details on the source of the recommendations, which could include a general explanation of the recommendations, the update date, etc.
Looking more closely at the routes themselves, the get recommendations route will return the output of the two-step pipeline (or just the retriever), get trends will focus on fetching trendy items (referring to the most popular items mentioned in this article), and get random items will return some random selections (which, from my experience, can be surprisingly useful).
For each route, quickly knowing the status of the inventory and user history (what cannot be recommended basically) is crucial. This knowledge is essential for filtering out items that can no longer be recommended.
Below is a brief description of the inputs that can be provided for these routes:
get recommendations- pipelineid: Identifier for the project/pipeline associated with the recommendations.
- userid: Identifier defining a user.
- itemid (optional): Identifier of an item used as context for related items features.
- k (optional): Number of items to include in the recommendations.
- default=20
- min=1
- max=100
- retriever strategy (optional): Name of the retriever phase, linked to the pipelineid.
- default=default
- ranker strategy (optional): Name for the ranker phase, linked to the pipelineid.
- default=default
- exploration factor (optional): Factor of exploration in the pipeline.
- default=0.1
- min=0
- max=1
- promoted items (optional): List of items to be promoted in the recommendations.
- excluded items (optional): List of items to be excluded in the recommendations.
- detailed output (optional): Boolean to determine if additional details (metadata, explanation, score, etc.) should be included in the list of recommended items.
- default=False
get trends- Inputs such as pipelineid, userid, itemid, k, promoted items, excluded items, and detailed output are included in this route as well.
- time period: Time period in seconds to determine the trends.
- default = 604800 seconds (7 days)
- min = 3600 seconds (1 hour)
- max = 1209600 seconds (14 days)
These inputs allow for a tailored recommendation experience, where the integrator can tweak the output easily and enabling users to receive personalized, trending, or random item suggestions based on their preferences and context.
Implementation of Recommender Routes
In this section, I’ll discuss a practical use case of homepage personalization, where the homepage needs to display 13 items.

In a real scenario, the goal is to follow a plan with different strategies to manage the list of items to be displayed:
- #1 Define the filling strategy: What approach do I want to use?
- #2 Define the fallback strategy: What should I do if the filling strategy doesn’t work?
- #3 Define the worst-case scenario: What should I do if I need to display something but all else fails?
The filling strategy is the first approach you want to apply. You can configure any of the routes presented earlier. A piece of advice for the number of items you request: aim for twice what can be displayed (in this case, 26 items) to have options to select from.
The Fallbacks strategy address what to do if the number of items from the filling strategy is less than what can be displayed. In such cases, accessing get trends or get random items could be relevant alternatives.
The worst-case scenario is what happens if both the filling and fallback strategies fail, or if the get routes are not reachable. This should be the last resort to apply (usually a default behavior from the application client), ensuring that there is always something to display, maintaining user engagement even when personalized content is not available.
Creating this plan early is very important because it can reduce the risk of potential problems in advance. It also emphasizes the need to quickly gather a user’s inventory/history to adjust the content shown accordingly.
Choosing Between Batch and Live Serving
For any ML project, the question often arises: should I serve the model in a batch manner (updated every X hours) or in a live manner (computation on demand)? Chip Huyen wrote an interesting piece about this duality, and for a recommender system, this choice is less obvious.
From my perspective, in terms of integration (for those connecting the API to an application), it should be transparent and always optimized in terms of cost and latency.
As a data scientist/MLE deciding whether to serve a recommender pipeline in a live or batch manner is more related to:
- The real value of having fresher information/data in my prediction. A good approach can be to look at offline metrics and compare models. Even if we know that an uplift in an offline metric may not translate the same way in an online metric, it can help make decisions.
- The impact in terms of user coverage when choosing live vs. batch serving. How many times this specific setup for the user is happening that can justify the need of live serving.
Another aspect is that batch serving is great for large models, as they can take a lot of time to produce predictions, whereas live serving requires models to be more responsive. My two cents on that, especially if you’re going down the get recommendations path, is that you could have a retriever that runs in batch every day, with a ranker that can be in live serving. It’s not necessarily one or the other only, but a hybrid approach can be interesting to set up.
In any case, it’s essential to monitor how the recommendations served are behaving in terms of:
- Cost per user: How much is the pipeline costing to run?
- Gains: In terms of metrics related to application usage, what’s the added value to the user?
- The performance of the predictions with classic recsys metrics like hit ratio, NDCG, etc.
In this setup, it’s important to keep a good experimental mindset to try out different ideas to figure out which pipeline works best for both the users and the company. For example, in some cases, a pipeline might not be relevant anymore (not enough users/activity), and you can decide to switch to the fallback strategy/worst case scenario to reduce the cost. Continuous experimentation can help make these decisions in advance by anticipating changes.
Companies like Spotify have extensive experience in this area and are starting to share their knowledge by building services like Confidence, their experimentation platform that can be a good starting point for anyone that want to set in place good practices.
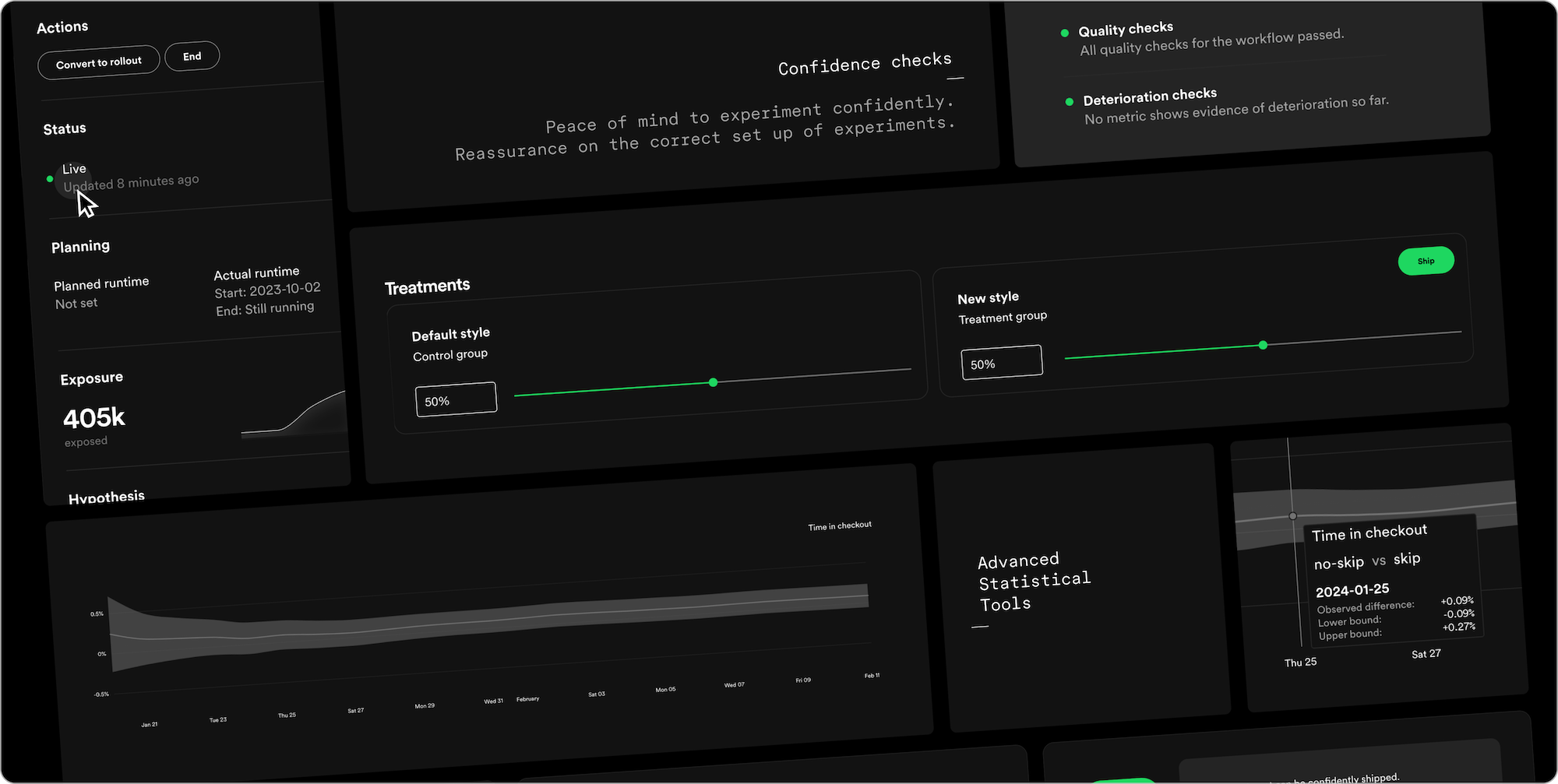
Setting aside the aspects related to the experimentation protocol (sample size, significance, etc.), when you’re conducting continuous experimentation, it’s also essential to keep the training of the model in a closed loop to avoid the positive or negative impact from other groups. Netflix published a paper at the last RecSys conference on this topic and shared their experience.
Get recommendations for a batch of users/items
Something that I’ve noted in my current experience of building recommendations in applications is the ability to access these same recommendations in different contexts for a group of users at the same time.
This ability is really important in a connected ecosystem where, for example, you can provide recommendations on the home page of an app, but you also want to attract users through other channels like email or notifications, etc. So, you need to be able to collect recommendations for multiple users in one shot to activate the right channel at the right moment.
A good inspiration of how this could look is the AWS Personalize batch features, where you can fetch a list of recommendations for a set of users or items. The call should look like the routes presented earlier, with the same configuration parameters except for the users and items fields to get a batch at the same time (with thousands of entities in one shot).

But as we can expect, the referential of IDs in the main application where the content lives is not the same as the one related to the notification or the email system, so it’s essential to have strong mapping capabilities of items to transfer the recommendation from one context (specific ID) to another (with another ID) without interference.
Finally, and I think it’s important to highlight, you should not stop recommending something in the application just because you cannot use some asset in the email. It doesn’t make sense and will make the experience poorer for the user in the end. So, decoupling the problem of user activation and content personalization is essential.
Leveraging Recommendations for Content Strategy Insights
Finally, and I think it’s one of the most important points of this article, is that a recommender system is not only here to provide recommendations. It is also here to provide insights to the application/content creators on content consumption and status.
Knowing that some items perform better in some contexts and understanding the association of items in a user’s basket are two simple and obvious use cases that are just the tip of the iceberg of the knowledge that can be extracted from a recommender system, and this should not be underestimated. It can help monitor application performance and make informed decisions.
An example of this application is Netflix, in their RecSysOps paper, presents an interesting point where they can predict if content will perform as expected or not, and a recommender system could aid in this detection. My interpretation in their case is that when new content is provided, there are a number of metadata/assets associated with it, and they can estimate how this content with the current metadata/asset will perform for specific users, like how new content will be perceived by action movie fans, and can adjust it before the release to avoid any problems when the content goes live.
Decoupling the recommender system into two parts (retriever and ranker) can assist in this, but it’s also important to implement other elements like user archetypes to determine the overall behavior of the application in specific contexts and with content. More generally, a recommender system should only be one component of an editorialization strategy, and streaming platforms see it like that and really leverage its knowledge to make decisions on the overall experience (the BBC wrote an article on their experience for the RecSys 2023 conference).
Closing notes
This article is quite dense, I know, but I think it can be a good starting point for anyone who wanted to understand all the elements that can be in place under this kind of application. I would have been happy to have something like this 6 years ago when I arrived at Ubisoft, but the field was not the same then. For me, this article will be the starting point of various experiments and thoughts on the field of recommender systems, so stay tuned ✌.
Exploring documentation of recommender systems as a service was quite interesting, and AWS Personalize and Recombee are for sure a great start for anyone who wants to kickstart a recommender system in a company without experience in this field. But be careful about a few things:
- The price: It seems from people around me that this kind of system is very easy to integrate, but it can become very expensive quickly.
- The data: Like with any service like that , be very aware of how your data will be used. I am not focusing on the security of the data but more on the fact that the data provided (and knowledge extracted) can be used by this service to become more efficient.(Update 20240415, based on Recombee repost of my article)
- Standardization is not everything: I noted that on the premium service of Recombee, it is offering a tailored solution by their DS team, so it illustrates that some customization is needed.
As I said in the introduction, the algorithms and the data were not the focus of this article, but in my research, I managed to find an interesting thing. It seems that AWS Personalize was built on top of an HRNN (Hierarchical Recurrent Neural Networks), potentially something to dig into. But more seriously, for any DS/MLE involved in this topic, I don’t think the focus of the recommender system pipeline should be on the algorithm itself, but focusing more on:
- Feature engineering: Process user/item data and extract relevant features.
- Embedding engineering: Extract information from an item from different sources (image, text, sound, etc.).
About LLM and Gen AI, I see a few points to have in mind:
- The transformers architecture began to impact the recommender system world a few years ago. My first encounter was with Transformers4Rec of NVIDIA in 2021. It seems to be useful in real-life applications. For example, Deezer recently made a comparison between a transformers architecture and SVD architecture on a specific feature of their app. However, like with deep learning-based models, their effectiveness still needs to be proven (from my experience, they are not a one-size-fits-all solution).
- LLM and multimodal models are very helpful in generating metadata for items by analyzing descriptions and assets to produce tags. I did a few tests to classify some content, and it was quite effective.
- GenAI in the world of recommendations can be very useful to customize and adjust content. AWS has embraced this approach by adding some generative AI capabilities to their Personalize product.
Finally, there are a few points I hinted at that can also be important in designing a recommender system:
- Having a clear item catalog definition is crucial. As suggested in various sections earlier, knowing what the items are and how they are defined in your application/ecosystem is very important.
- Building segments of items can improve efficiency. Recombee builds this definition, and I think it can help in the inference stage (optimize the retrieval phase by retrieving a pool of items) and provide valuable insights into the application’s usage in general.
- The concept of rotating items: Rotating recommendations to include items seen in the past can boost engagement (I’ve tried it; trust me). If it’s based on tracking, you can adjust the importance of items based on a user’s past exposure (a good example of the importance of user tracking). Recombee is offering the ability to set some rotation factor in the api call of their endpoint (rotation rate and rotation time)
- Pagination in recommendations: Recombee’s endpoint offers the ability to browse through recommendations. This feature can be useful when you need to quickly access more content, and having an identifier for the produced recommendation is crucial. It can be especially useful in applications with intensive use, like a social network with the infamous and controversial infinite scroll mechanism.
I hope you found this read as enjoyable as I found writing it, and if you have any feedback or points to add/comment, please feel free to share.







{kind=link}