
This year, I am a bit late in completing the recap of the RecSys Conference 2023, which happened in Singapore at the end of September (I attended online, thanks Ubisoft for the ticket). In this article, I am sharing a selection of good reads (for me) that I have categorized as follows:
- From the industry
- Reproducibility is a gold mine
- New datasets in the house
- Transformers and language models
- The misfits
From the industry
Recsys is always a good moment for company to share their practices and challenges , and this year I wanted to highlight these papers.
Personalised Recommendations for the BBC iPlayer: Initial approach and current challenges
Authors: Benjamin R Clark, Kristine Grivcova, Polina Proutskova, Duncan M Walker
Links: ACM Digital library
The publication primarily offers insights from the team responsible for the BBC iPlayer’s recommender system.
Here are the key takeaways:
- The player caters to a vast audience (millions of users) but has a relatively small content catalog compared to other VOD services.
- Their content release pattern, aligned with the TV schedule and a 30-day availability post-broadcast, enables more accurate traffic predictions on the platform.
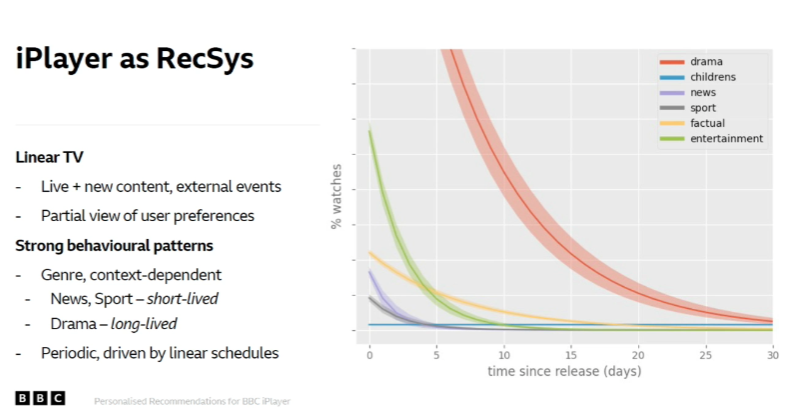
- It’s interesting to note the variation in content consumption across different genres, (look at this figure from the presentation).
- The team’s recommender system strategies are primarily based on heuristics, KNN, RP3Beta, and EASE.
- More complex models like Mult-VAE and NCF showed marginal to no improvement for an increased cost.
- They employ a mix of offline testing and user research experiments to deploy the most effective models.
- An editorial team provides feedback on the recommendations, but their decisions are also influenced by the recommender system output, which could introduce some implicit biases.
Navigating the Feedback Loop in Recommender Systems: Insights and Strategies from Industry Practice
Authors: Ding Tong, Qifeng Qiao, Ting-Po Lee, James McInerney, Justin Basilico
Links: ACM Digital Library
This paper focuses on defining the challenges inherent in operating recommender systems and the potential interference when running multiple models concurrently. Netflix’s recommender systems are constructed like reinforcement learning (RL) agents. These ML agents make recommendations (actions) based on user history (environment and observations) and receive rewards based on user actions such as streaming, clicking, and purchasing. Within this context, the training of models involves a feedback loop for the recommender system, which can be categorized as either closed (if the agent is trained on its own loop of observations) or open (the agent is trained on all possible observations).
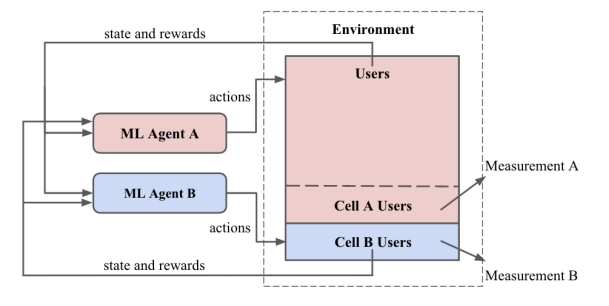
Each loop type has its advantages and disadvantages. For Netflix, maintaining a model solely in a closed loop presents a challenge, as it requires time to achieve a level of accuracy justifying evaluation. While this paper is not extensively detailed, it provides a solid set of references for future exploration in the realm of RL-based recommender systems.
Optimizing Podcast Discovery: Unveiling Amazon Music's Retrieval and Ranking Framework
Authors: Geetha S Aluri, Paul Greyson, Joaquin Delgado
Links: ACM Digital Library
This paper provides an overview of the search engine process for Amazon Music’s podcast service. Aiming to enhance content discovery, Amazon developed a framework named Unified Learning-to-Rank-and-Retrieve (LTR&R).
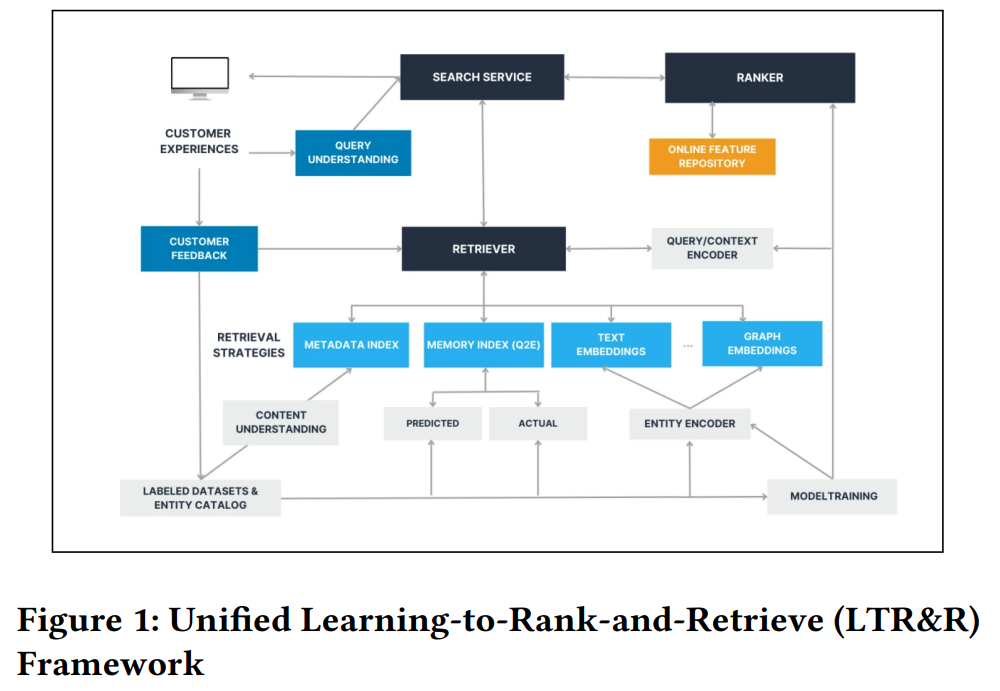
The system’s core concept involves connecting multiple systems with diverse strategies at the retrieval step, such as:
- Metadata Index: Linking search queries to the metadata of podcasts.
- Memory Index: Matching queries with user clicks within the application’s UI.
- Text Embedding: Converting podcast transcripts into embeddings and matching them with embedded queries.
- Other briefly discussed strategies include graph embedding.
The process is then followed by a reranker, utilizing a contextual multi-armed bandit to explore the retrieved items based on context (time of day, location, past actions).
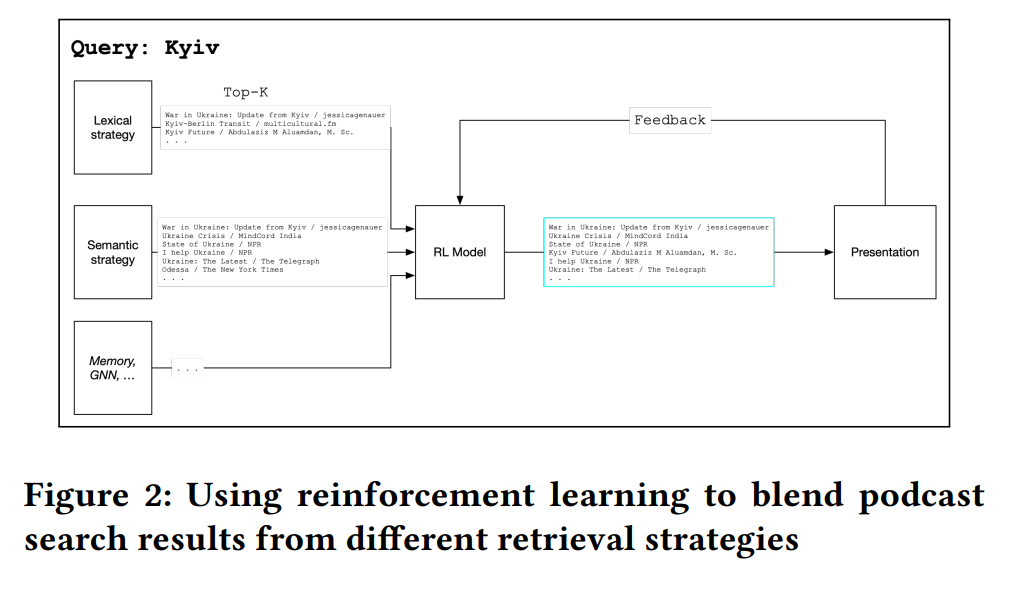
Though high-level, this paper stands out as particularly inspiring. It offers room for imagination by focusing more on concepts and less on benchmarks, code, or pseudocode.
Contextual Multi-Armed Bandit for Email Layout Recommendation
Authors: Yan Chen, Emilian Vankov, Linas Baltrunas, Preston Donovan, Akash Mehta, Benjamin Schroeder, Matthew Herman
Links: ACM Digital Library
This article from Wayfair presents their experiments with multi-armed bandits to enhance interaction with their emails, a key strategic element of their marketing. To train their system, they utilize tracking data related to email engagement (views and clicks), building a binary classifier to predict click likelihood for individual users. The classifier incorporates various features:
- Customer Features: Age, gender, and location.
- Customer-Item Features: Days since last click, last transaction.
- Email Layout Features: Layout ID, subject title.
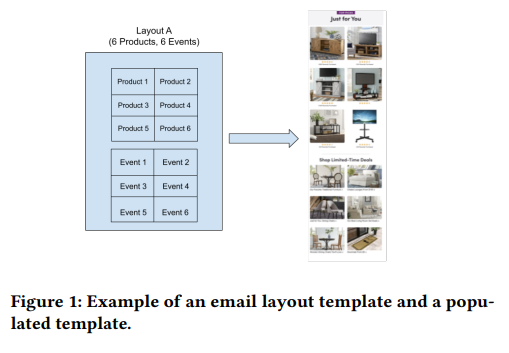
With this model, Wayfair advances the development of their multi-armed bandit system, noting that occasionally (e.g., 5% of the time) they opt for a random layout choice as part of an Epsilon-greedy strategy.
They shared A/B test results comparing the new system against the existing one. The findings indicate that the new model increased site conversion following email clicks by 2.39% and reduced email unsubscribe actions by 15%.
This article from my perspective is one of the simplest use case around multi arm bandit that I saw in the recsys conferences and I think should be the starting point when people want to explore this topic
Reproducibility is a gold mine
Reproducibility as usual is a big topic at recsys, I selected the following one that really catch my attention during the review.
The effect of third party implementations on reproducibility
Authors: Balázs Hidasi, Ádám Tibor Czapp
Links: ACM Digital Library, Arxiv
In this paper, the author is working on the evaluation of reimplementation of a recommender system GRU4REC(1,2), that the author developed a few years ago (2015), and the goal of the article is to see if the reimplementation are correct in terms of code and what are the real performance of this reimplementation versus the original one.
The paper focus on the following reimplementations:
I will make an high level summary of the results:
- The [Microsoft Recommenders]’s implementation is a total different algorithm (https://github.com/recommenders-team/recommenders) 🤯 (my reference take a shot)
- All the reimplementation have scalability issue
- Some implementations are getting the overall idea but missing some bits
- Torch-GRU4Rec seems to be the best implementation (with scalability concerns)
So I think that there is a good lesson to get from this paper : don’t trust blindly the reimplementation.
Challenging the Myth of Graph Collaborative Filtering: a Reasoned and Reproducibility-driven Analysis
Authors: Vito Walter Anelli, Daniele Malitesta, Claudio Pomo, Alejandro Bellogín, Eugenio Di Sciascio, Tommaso Di Noia
Links: Arxiv, ACM Digital Library
I selected this paper because it is a great snapshot of what could be the algorithms to start to explore if someone wanted to investigate the graph domain of recsys by selecting the most popular graph recsys:
The paper is here to test these implementations against some classic baselines (most popular random) and classic collaborative filtering (UserKNN, ItemKNN, RP3Beta and EASE) on different datasets. I screenshot the tables of results of the evaluation of the model
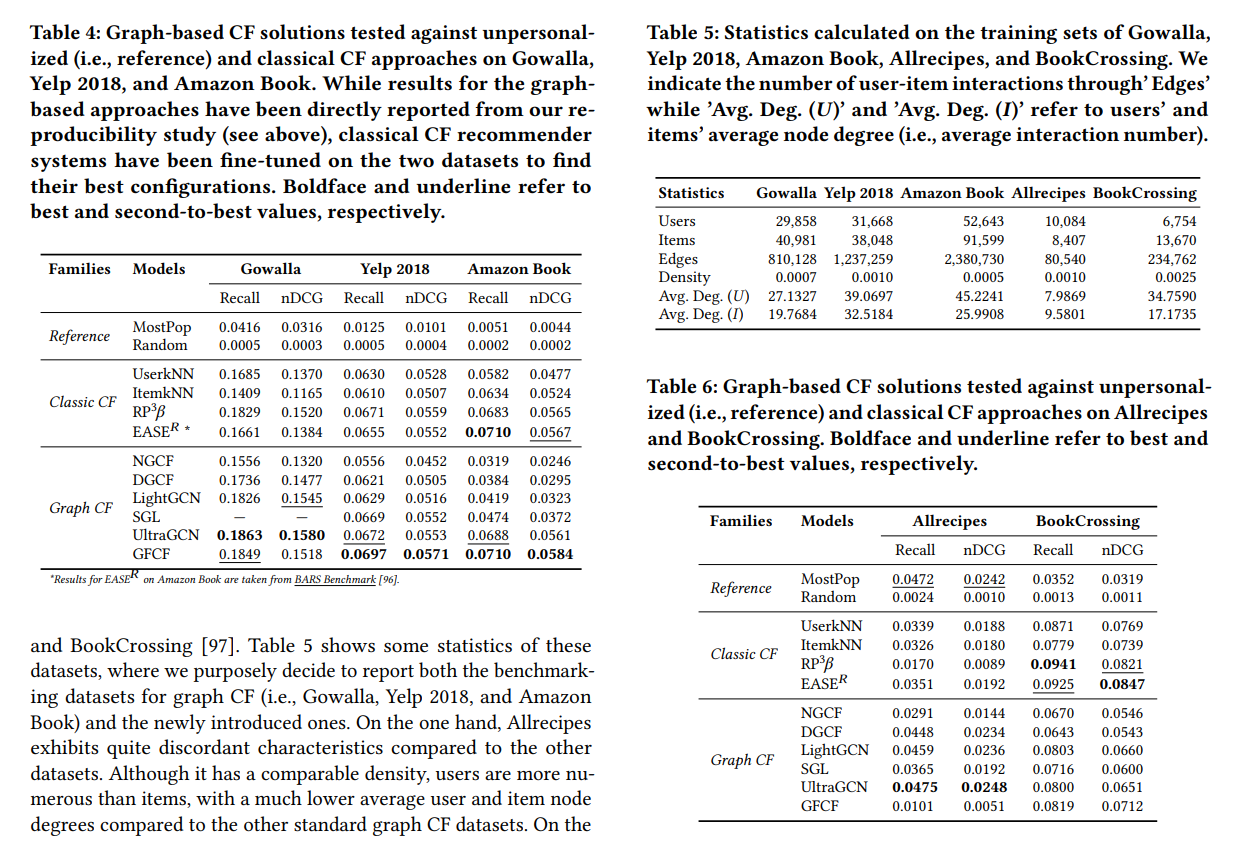
As we can see:
- most of the model with the best performance have graph based one (except on the book datasets)…
- … but the collaborative filtering based model are not so far
- the most popular have some good performance in the Allrecipes dataset
- NGCF doesn’t seem to be a good performer overall
if you are curious to see the code of the evaluation is on Github, keep in mind of their evaluation process is very dependent of their evaluation framework Elliot (I wrote a bit on a previous recsys recap).
New datasets in the house
Recsys is always a good moment to discover new datasets and this year, they had some interesting ones.
HUMMUS: A Linked, Healthiness-Aware, User-centered and Argument-Enabling Recipe Data Set for Recommendation
Author: Felix Bölz, Diana Nurbakova, Sylvie Calabretto, Lionel Brunie, Armin Gerl, Harald Kosch
Links: ACM Digital Library, GitLab
This dataset focus on recipe data and represents a comprehensive aggregation from various sources under the food.com website, with an emphasis on the healthiness of recipes—a factor often overlooked in existing datasets.
Below is an overview of the types of information available:
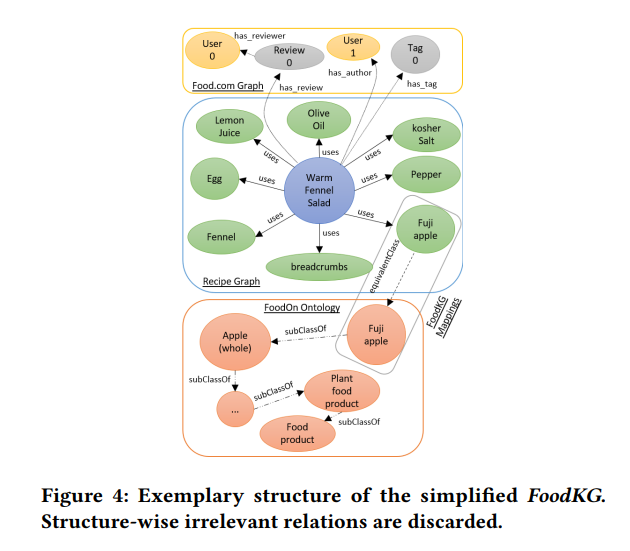
This dataset marks a significant step forward in building recipe recommender systems. For those interested in exploring further, the dataset is available on GitLab.
Delivery Hero Recommendation Dataset: A Novel Dataset for Benchmarking Recommendation Algorithms
Authors: Yernat Assylbekov, Raghav Bali. Luke Bovard, Christian Klaue
Links: ACM Digital Library, Github
This dataset, centered on food delivery, is provided by Delivery Hero and is accessible on GitHub, Below is an overview of the dataset’s structure:
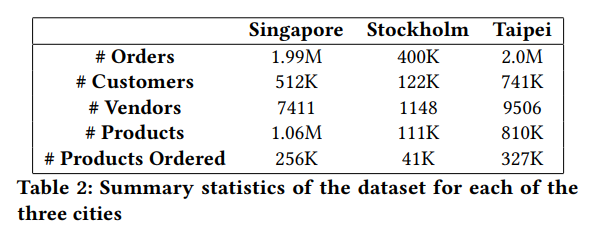
The dataset comprises various orders featuring diverse products, placed by different customers across multiple locations. With its geographical diversity spanning from Europe to Asia, where it is more predominant, this dataset presents some interesting challenges .
Transformers and Language models
The impact of transformers and language models in the recommender system domain was a major highlight at RecSys last year. ,and this year conference have interesting ones
Track Mix Generation on Music Streaming Services using Transformers
Authors: Walid Bendada, Théo Bontempelli, Mathieu Morlon, Benjamin Chapus, Thibault Cador, Thomas Bouabça, Guillaume Salha-Galvan
Links: ACM Digital Library, Arxiv
Deezer’s paper discusses their ‘track mix’ feature, which creates a playlist inspired by a specific track, similar to Spotify’s radio for me.
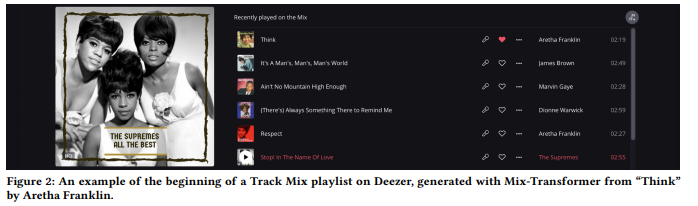
The paper details experiments with two models for this feature: mix-SVD as the baseline and mix-transformers, evaluated through A/B testing to determine the best approach.
Main Takeaways from the Models:
- mix-SVD: Generates item embeddings from user actions. Nearest neighbors searches in this space identify items closest to the specified track. The space is updated weekly, with the embeddings hosted in a Cassandra cluster.
- mix-transformer: A decoder-only Transformer trained on a playlist completion task, using the selected track as a 1-track playlist input. Deployed as an ONNX model, it handles everything from data processing to track ranking, following Deezer’s represent-then-aggregate framework.
The results of their online tests offer significant insights:

Deezer is inclined to further explore the mix-transformer for onboarding new users into their ecosystem, despite its more complex deployment.
Beyond Labels: Leveraging Deep Learning and LLMs for Content Metadata
Authors: Saurabh Agrawal, John Trenkle, Jaya Kawale
Links: Arxiv, Papers with code
In this paper by Tubi, a TV streaming platform, the focus is on the important role of content metadata in recommender systems. The article specifically addresses genre labels, proposing a novel method for analyzing genre information through a ‘genre spectrum’.
To develop this genre spectrum, they gathered textual metadata from 1.1 million movies and trained a multi-label classifier to predict associated labels. Below is an overview of the model’s architecture:
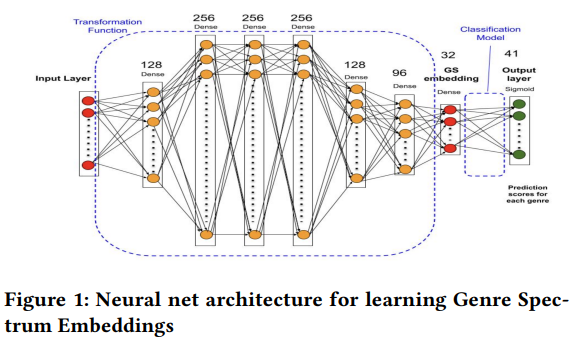
This process generate new embedding offers an enhanced representation of movies, improving recommendations. An example compares the closest movies to ‘Life of Pi’ using classic doc2Vec versus the genre spectrum embedding:

The genre spectrum embedding results in notably different and seemingly more accurate genre associations (for this example). Additionally, Tubi applied this method in the retrieval phase of their recommender system for an online A/B test, observing a relative impact of +0.6% on their engagement metric (total view).
The paper also hints at future possibilities of incorporating Large Language Models (LLMs) in their annotation process.
Station and Track Attribute-Aware Music Personalization
Authors: M. Jeffrey Mei, Oliver Bembom, Andreas Ehmann
Links: ACM Digital Library
SiriusXM, akin to Deezer, has developed a feature for generating track recommendations based on a seed artist. Their model, named STAMPer, is a transformer-based system showing more than a 10% performance improvement over their baseline matrix factorization model.
STAMPer is built upon SASRec and utilizes both implicit (song skips) and explicit (thumbs up/down) user feedback on songs/stations as a series of actions. Multiple versions of STAMPer have been developed.
This new approach appears to offer greater diversity in recommendations, as illustrated in the following comparison of models:
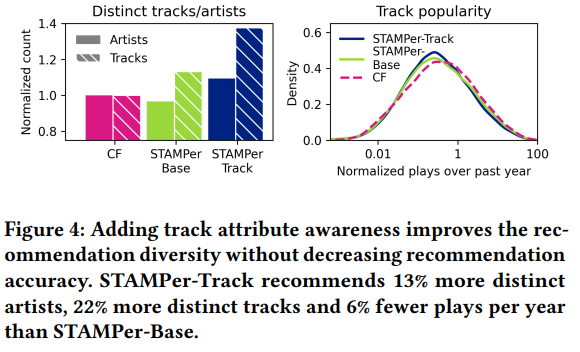
SiriusXM plans to further explore models like BERT4Rec, continuing their promising journey with transformer-based approaches.
Visual Representation for Capturing Creator Theme in Brands-Creators Marketplace
Authors: Sarel Duanis, Keren Gaiger, Ravid Cohen, Shaked Zychlinski, Asnat Greenstein-Messica Links: ACM Digital Library, ZipRecruiter
Lightricks, known for aiding brands in connecting with the right creators for product promotion, has developed a solution called Popular Pays. This solution employs various approaches to find creators:
- Lookalikes: Identifying creators similar to a specified one.
- Search Tool: A keyword- and filter-based search mechanism.
- Personal Recommendations: Using collaborative filtering to assess the likelihood of a creator working with a brand.
They utilize CLIP models to create two methods:
- SAME (Same Account Media Embedding): Generates image embeddings based on a creator’s content style and aesthetics, using siamese networks and positive/negative samples based on creator ownership.
- OAAR (Object-Agnostic Adjective Representation): Extracts adjectives from images by comparing CLIP embeddings for closely described images (e.g., a photo of a dog vs. a vivid photo of a dog).
The paper presents seemingly “simple” methods with compelling examples:
For SAME, the detection of style and aesthetics appears effective:

For OAAR, the association of adjectives seems satisfactory, though the accuracy of some outputs like ‘pleasing’ may be debatable. It demonstrates improvement over CLIP:

This approach is reminiscent of explorations during an internal hackathon at Ubisoft (👋 to Yasmine and Cloderic).
The misfits
Among the diverse papers at RecSys 2023, several intriguing ones didn’t neatly fit into specific categories that I built but needed to be highlighted
InTune: Reinforcement Learning-based Data Pipeline Optimization for Deep Recommendation Models
Authors: Kabir Nagrecha, Lingyi Liu, Pablo Delgado, Prasanna Padmanabhan
Links: Arxiv, ACM Digital Library
This Netflix paper delves into data management within deep learning-based recommender systems (DLRMs).
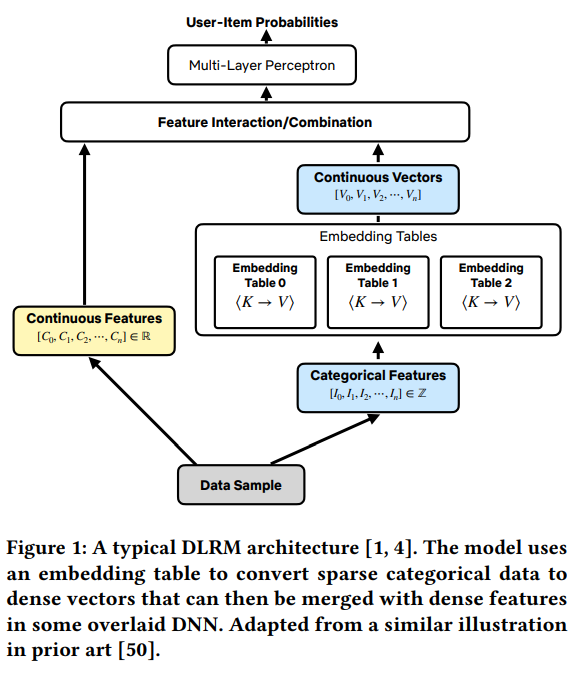
The focus is on analyzing training jobs within their training cluster, highlighting the efficiency of TensorFlow’s dataloader and the AUTOTUNE feature. Key findings from the cluster analysis include:
- Data Ingestion: 60% of the cluster’s time is spent on data ingestion.
- Data Caching: Infeasible due to the large size and high dimensionality of datasets.
- Data Pipeline Representation: Illustrates various stages and their latency contributions.
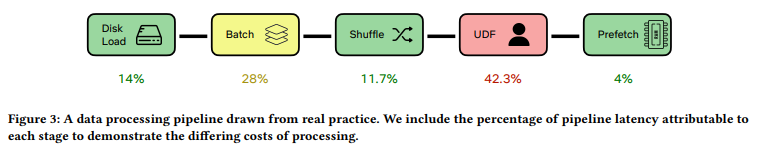
- AUTOTUNE vs. Manual Settings: Manual settings often outperform AUTOTUNE.
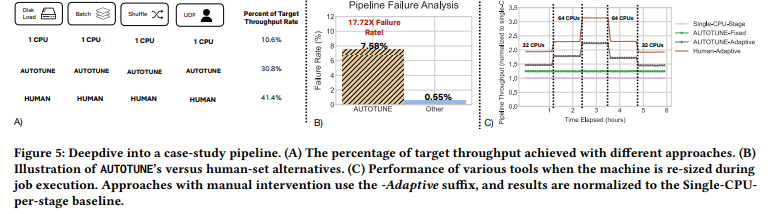
Netflix developed a system named intune, an RL agent designed to optimize data pipelines more effectively than AUTOTUNE. Its setup involves:
- Actions: Tweaking parameters of the data job.
- Reward: Based on memory usage.
Tests against various use cases and baselines like AUTOTUNE show promising results. While the approach’s applicability to other companies is uncertain, the concept of using RL to optimize ML jobs, particularly in data management, is intriguing.
Recommenders In the wild - Practical Evaluation Methods
Authors: Kim Falk, Morten Arngren
Links: ACM Digital Library, GitHub
This tutorial, not part of the main tracks or posters at the conference, focused on evaluating recommender systems. It was divided into two parts, led by Kim Falk (author of Practical Recommender Systems) and Morten Arngren.
First Section by Kim Falk:
- Focuses on learning and processes to keep in mind during real-life recommender system operations and deployments.
- Key takeaways include:
- The number one rule of any ML project:

- Insights from client discussions:

- The flow of a recommender system:
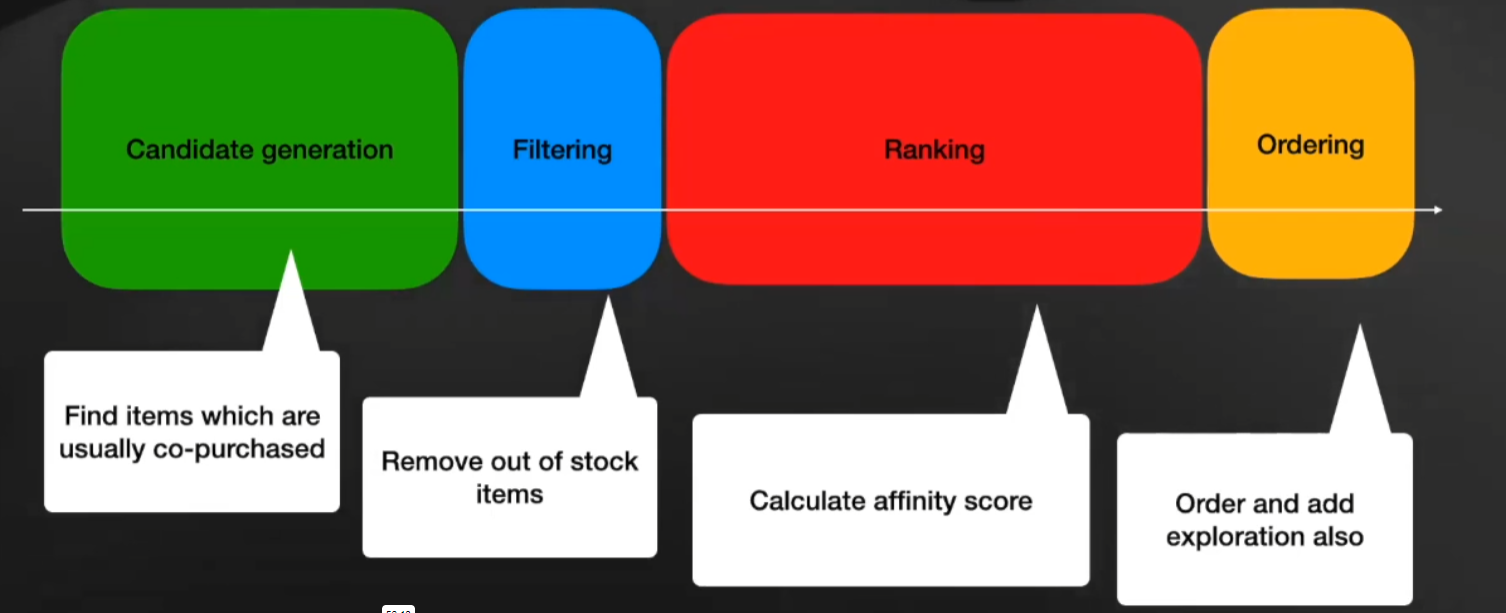
- Guidelines for introducing a new model:

Second Section by Morten Arngren:
- An excellent introduction to A/B testing, with easy-to-understand slides and a collection of notebooks explaining various A/B testing approaches.
- A snapshot from the presentation:
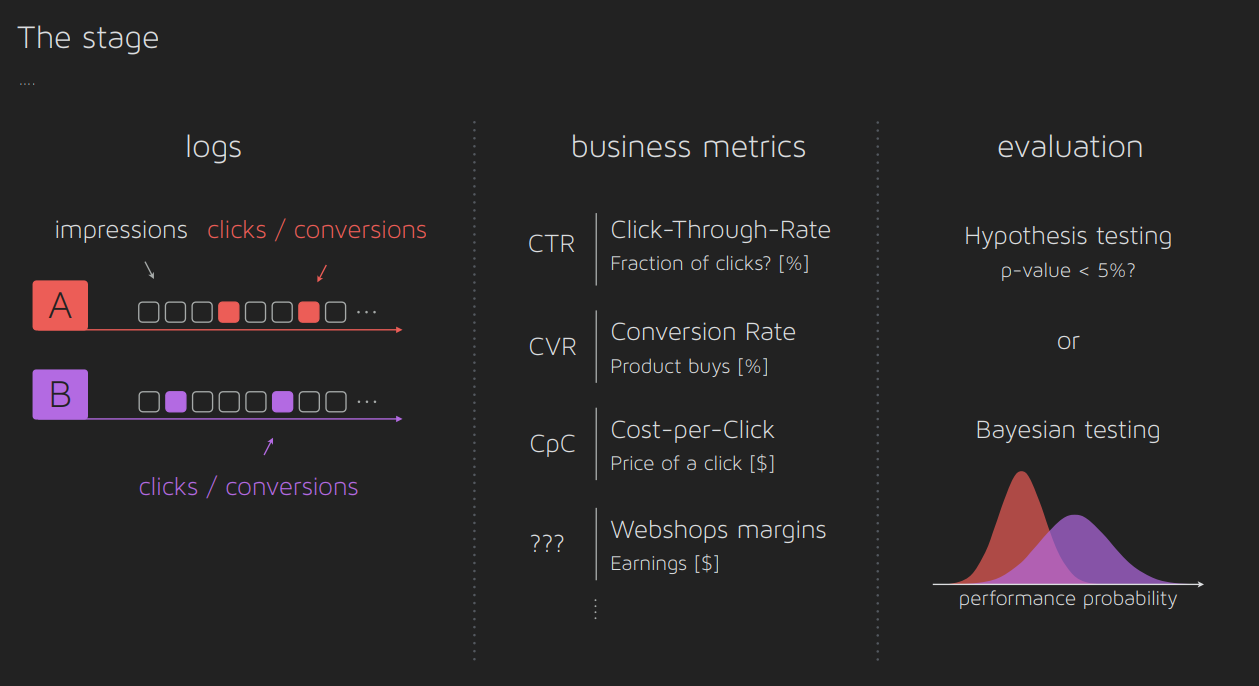
This tutorial provided valuable insights into the evaluation process of recommender systems, with practical guidelines and comprehensive resources for understanding A/B testing.
Trending Now: Modeling Trend Recommendations
Authors: Hao Ding , Branislav Kveton , Yifei Ma , Youngsuk Park , Venkataramana Kini , Yupeng Gu , Ravi Divvela , Fei Wang , Anoop Deoras , Hao Wang
Links: Amazon blog, ACM Digital Library
This presentation by AWS AI Labs explored trend recommendations, a concept crucial for Amazon Video’s operation of their top carousel in the app.
Key concepts in trend analysis include popularity, velocity, and acceleration:
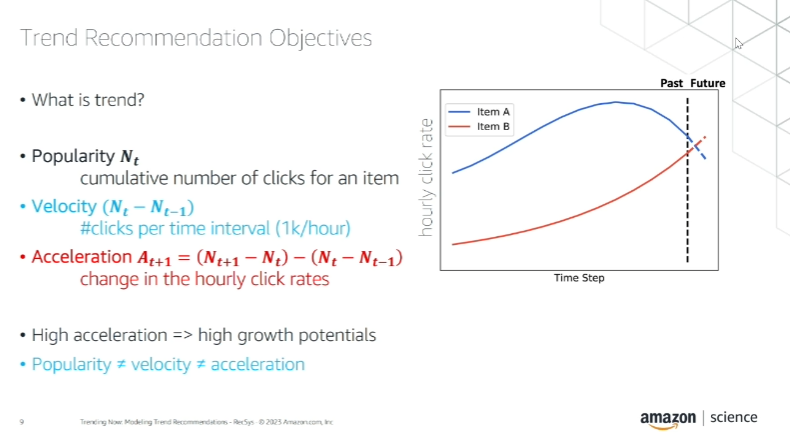
An important takeaway is the differentiation of these concepts: “Popularity is about the past, velocity is about the present, and acceleration is about the future.”
The talk emphasized working with time frames close to the hour, a rapid pace that could also be relevant in contexts like user-generated content (UGC) monitoring. These metrics are useful for forecasting item consumption, and the presentation highlighted their DeepAR model in this context. The combination of forecasting and item embeddings (in this case, from GRU4REC) forms the basis of their ‘trendRec’ recommendation method.
Although the method appears technical, the concept of integrating trends into recommender systems is intriguing and holds potential for a variety of applications.
How Should We Measure Filter Bubbles? A Regression Model and Evidence for Online News
Authors: Lien Michiels, Jorre # Vannieuwenhuyze, Robin Verachtert, Annelien Smets, Jens Leysen, Bart Goethals
Links: ACM Digital Library
This paper, focusing on news recommendation, introduces an in-depth exploration of the concept of diversity (but it’s far to be the core of the article that is around filter bubbles). While outside my usual area of work, I found their definition of diversity to be quite insightful.
The paper elaborates on three aspects of diversity:
- Variety: The most straightforward aspect, referring to the range of different items.
- Balance: How evenly distributed the items are across different categories.
- Disparity: The degree of difference between items within the same category.

By applying these concepts more broadly, such as replacing ‘shape’ with ‘genre’ or ‘type,’ they become relevant and potentially useful in various recommendation contexts.
Conclusion
For me the highlights of this recsys 2023 conference are these papers:
- Track Mix Generation on Music Streaming Services using Transformers by Deezer: This paper is great for its approach to evaluating recommender systems and its novel use of transformers, presented with clarity and detail.
- Recommenders In the Wild - Practical Evaluation Methods: A comprehensive collection of best practices, particularly beneficial for those implementing recommender systems in production, authored by experienced professionals in the field.
- Personalised Recommendations for the BBC iPlayer: Initial Approach and Current Challenges: Offers valuable insights into the operational challenges and strategies of recommender systems in the streaming industry.
But my general takeaways are:
- EASE and RP3Beta seem to be good collaborative filtering technics used in reproducible papers and in production
- Access to metadata and increase knowledge of item with embedding is essential
- Collecting a decent level of data around user actions is essential if you want to evaluate the recommender system and operate new technics (like RL based recsys)
- Transformers that was the big trend last year is still present (but it’s not the finish line)







{kind=link}