
Back from the 2026 Databricks Data + AI Summit
In mid-June I spent four days at the Databricks Data+AI Summit 2026 in San Francisco, among more than 31,000 on-site attendees, moving between trainings, keynotes, and breakout sessions.
This article recaps the keynote announcements and my session highlights. I am keeping the training deep-dives for separate, more technical articles.
Keynotes
The first two days of morning keynotes were packed with release announcements, some new, some highlights of recent releases, all structured around the 4 Cs of success for modern data and AI initiatives: Context, Control, Cost, and Choice.

Context
For the Context pillar, the most representative announcements were the various new Genie features in Databricks. The first one is Genie ONE, which positions itself as a ChatGPT for Databricks (they market it as a “data-smart AI coworker”).

It is the main entry point to Databricks resources, from data to agents, where you can ask anything and take actions, such as transforming insights into new agents or apps; it is also not confined to its own surface and can interface with Slack or Teams directly. Since Genie ONE is built on top of components like the Unity Catalog, a well-documented system brings more trust to its answers and full traceability on every insight by surfacing the chain of thought behind it.

One key component behind Genie ONE is the Genie Ontology, which can be seen as an automatic context layer, essentially a knowledge graph that connects every element of your Unity Catalog. It adds a layer of authority to each element using an approach similar to PageRank called OntoRank, scoring authority based on all the metadata linked to a table, dashboard, ML model, or AI assets in your catalog (usage, author credibility, completeness of description, and so on) and retrieving the right content through this authority-based ranking.
Less flashy but also closely connected to the ontology is the evolution of the Delta Sharing open protocol into OpenSharing, which extends the work of Delta Sharing to AI elements like skills, models, or Genie spaces (this is part of the Linux Foundation so it’s open to everyone).

Finally, one interesting statistic on this topic: state-of-the-art LLMs typically have a lifespan of about 2 months before a new challenger arrives. They illustrated this with OpenAI GPT-5.5 vs. Anthropic’s Mythos (during its brief availability). This is the perfect illustration of why it is essential to make context (lineage, logs, documentation) the durable layer that outlasts any individual model, enabling teams to iterate quickly as new models emerge.
Context gives you the foundation. But knowing what data exists is only useful if you can also govern who uses it and how. That brings us to the second C: Control.

Control
For this section, what stood out most were the announcements around the AI Gateway, which adds the governance layer necessary for enterprise AI usage. Through it, you can easily access a centralized agent and model catalog, set up policies for your agents (restricting them to specific content in your Unity Catalog), configure monitoring guardrails for the system, and enable smart routing to the right model (for the budget).
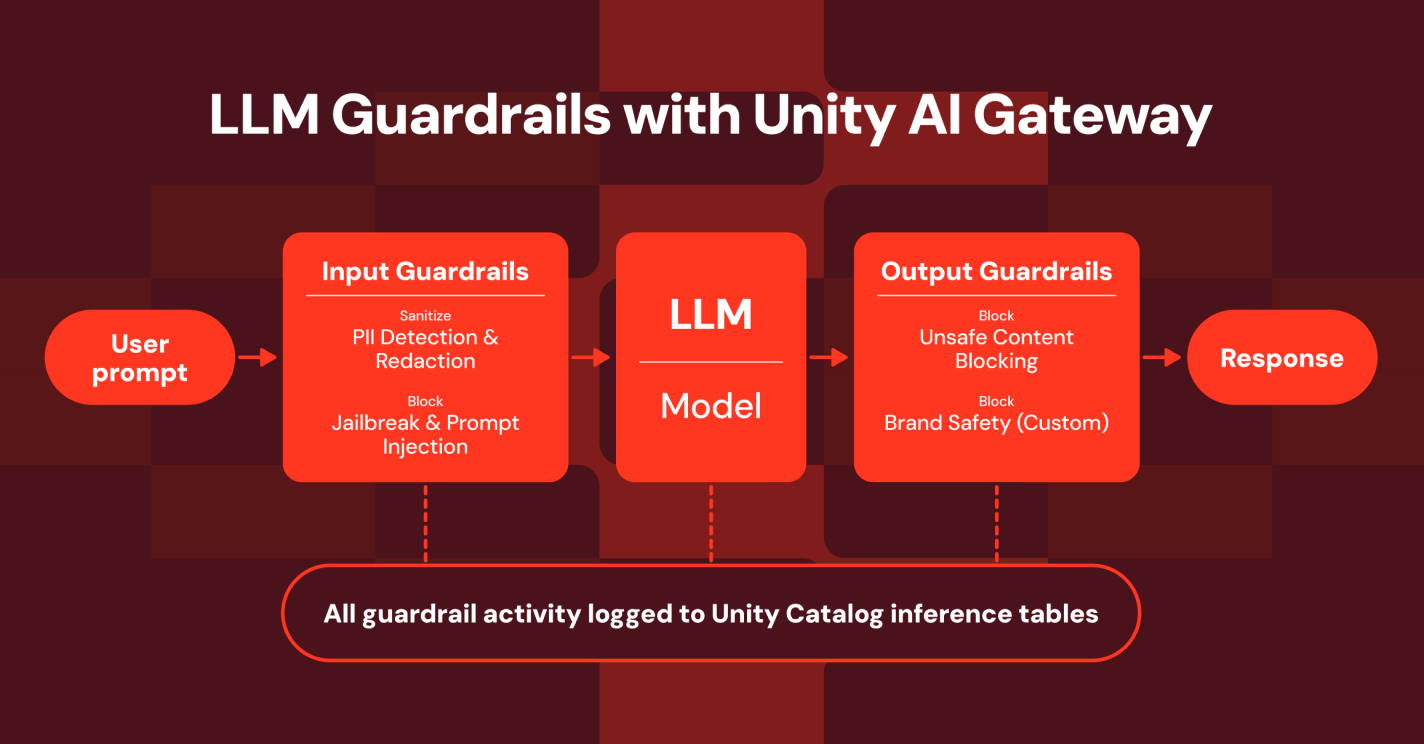
All of this is tightly integrated with MLflow, offering a complete logging system and full traceability in one place, because the real difficulty is not in the model itself, but in governing it: tracking costs, ensuring traceability, and maintaining oversight.
Another announcement closely related to agents is the Postgres branching capability. An entire database can now be branched for any process, such as an agent exploring data without interfering with the main branch. This is a genuinely useful feature: it lets agents experiment freely without having to recreate database permissions or risk polluting production data.
This ability to create data sandboxes and track agents easily will give anyone on Databricks the ability to shift from an approach that was tokenmaxing to valuemaxing (not my words, someone on stage coined that one).
With governance locked in, the next natural question is: how much does all this actually cost? Let’s look at the third C.

Cost
Cost ran through earlier announcements too; here’s where it surfaced most directly.
The rise of the serverless for GPU/AI runtime and Databricks Apps with serverless microapps illustrate that running workloads on Databricks is becoming more efficient and cost-effective (more on the code performance improvements later).
Beyond serverless, there was also the announcement of a new data engine called Reyden, tied to Lakehouse RT, described as a real-time warehouse that delivers millisecond performance at massive scale, without data movement.
The performance of Reyden looks impressive from the benchmarks, and the magic under the hood appears to be machine learning-driven, used to automatically find the right storage and data access patterns.

From what I heard about this new technology:
- It is not more expensive than the classic Databricks SQL engines.
- To take full advantage of it, all code feeding and fetching data needs to be Photon-optimized. One of the major ongoing efforts at Databricks is making most SQL and Spark functions Photon-ready, as it will ease Reyden adoption.
Efficiency gains matter, but only if you are not locked into a single vendor’s stack. That is the spirit behind the fourth and final C: Choice.

Choice
During the conference, Databricks made it very clear that they are against vendor lock-in and want to let people choose their own data storage, compute, and more.
Tied to the AI Gateway, Databricks announced collaborations with LLM providers, for example, xAI’s Grok models will be available directly through the gateway (the audience reaction was… let’s say politely lukewarm).
The most interesting Choice announcement was around Omnigent, a meta-harness for AI agents. It is currently only available on Mac, but the concept is to have a runner and a server that orchestrate different agents together.

It offers a clean, collaborative interface and the project is fully open source.
The 4 Cs covered the main thrust of the keynotes, but a handful of announcements did not fit neatly into any of them. Let’s look at those next.
Beyond the 4 Cs
The first noteworthy one is Genie ZeroOps, which can be defined as an agent tied to your data pipelines. It is not purely a coding agent; it also digs into the data itself to detect bugs that might otherwise be masked by silent failures. Overall, it monitors your pipelines for issues and proposes fixes to apply.

The second Genie-related announcement was the upcoming release of Genie Code for ML engineering. As a heavy user of the AutoML features of Databricks to kick-start model development, I am excited to get my hands on it as it is the kind of assistant that can also execute code, which should make exploring new models much faster.
These two new Genies feel like vigilantes joining my toolbox.

As a Databricks app builder, I appreciated the arrival of the Genie App Builder, a vibe-coding interface similar to Replit for creating web apps on top of AppKit (sorry, Python lovers like me, AppKit is TypeScript-based).
Finally, as someone working on recommender systems, I found the announcement of CustomerLake intriguing. It is very agentic and marketing-oriented, but I am curious to see how it could fit into a personalization workflow.

That wraps up the keynotes. Let’s move on to the sessions.
Session Recap
Over the conference, I attended sessions across five themes:
- Security Topics in Video Games
- Short-Video Personalization at Fox One
- Automation with a Sprinkle of LLM
- Practical Databricks Takeaways
- The Misfits
Side note: there was a scavenger-hunt-style summit quest with prizes. I narrowly missed the Genie plush cutoff.

Security Topics in Video Games
Over the past 10 months I have been more involved in security topics for Rainbow Six Siege, so presentations on this subject naturally caught my interest. There were two sessions worth highlighting: the first was by Krafton, who presented their ESP (Extra-Sensory Perception, i.e. wall hacks) detection system, and the second was by Supercell, who presented their child safety system applied to text chat.
In their talk Operating Scalable AI for Games: From LLM Intelligence to Real-Time ML Systems, Krafton actually covered two distinct topics: an LLM-based pipeline for reporting the online impact of ban waves (which I will cover in the next section), and their ESP detection system. The ESP part was built by a team of three in just two months, and they walked through how it produces a series of bans every hour for all kinds of matches, whereas the previous system ran every 2–3 hours and only covered a few matches at a time.
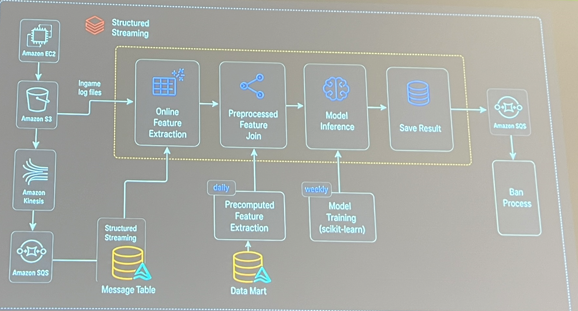
Here are the interesting bits:
- The model features come from three places: real-time log files and structured streaming to process deeper real-time data into the online feature store, plus daily precomputed features that are too heavy to compute in real time.
- Weekly retraining of a scikit-learn model (I think it was a LightGBM).
- Ban events are sent to a queue mechanism to be processed.
During the presentation they also explained that to process data in real time they used functions like applyInPandas/toPandas to reduce bottlenecks for live inference.
What stood out is that even though they had a working pipeline within a few months, they seemed to have accumulated some technical debt that they are now working to fix. Even if Databricks enables you to move quickly, you still need to be rigorous and take the time to implement things properly.
Still in the game security topic, I attended the session How Supercell Uses Databricks to Serve Nearly 300M Monthly Players and Prevent Player Harm. In this talk, Supercell first gave a quick overview of their Databricks experience: they have more than 5 PB of data on the platform, started onboarding in 2021, and have since improved their costs by between 30 and 60% by leveraging solutions like serverless.
In their second segment, they presented a child safety pipeline built as a layered, funnel-like system. I genaied a small schema around it:
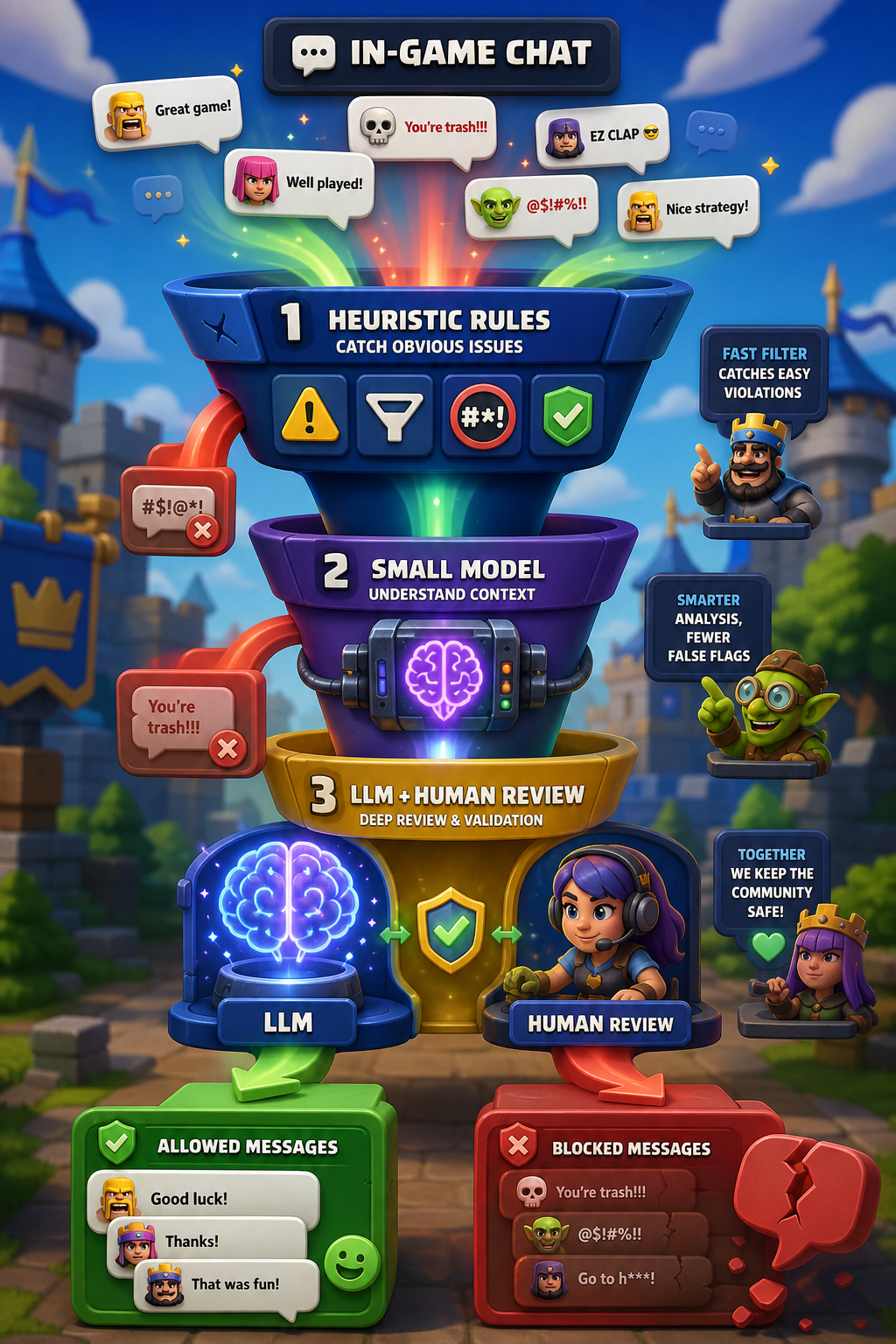
What was interesting about this pipeline beyond the funnel approach is that:
- most of their models ran on serverless GPUs.
- they took a very incremental approach, starting with a single language (English) and gradually extending to others.
- they embed the system into the moderator workflow by providing training to help moderators work with the model’s predictions.
Enough about security. Let’s move to something I always find more exciting: personalization.
Short-Video Personalization at Fox One
There were not many sessions on personalization at this conference (so 2024, as Databricks people would say 😄), but there was one from the team at Fox One: Video Personalisation at Fox One.
In this talk they presented their approach to building short video generation and recommendation in the Fox One application.

The goal was to promote shows and content using short videos on the platform. One of their main challenges was producing these shorts and making recommendations with very limited user data, and the answer to most of those problems lies in language models.
With more than 210 hours of content available per day, they were not short on content to be shortened, but this operation is difficult to execute manually, so they developed a process using Gemini models to analyze the available content and build shorts from it.

The main challenge was around how to cut the shorts, as the original pipeline was cutting content randomly and the quality was poor (after LLM and human review). They reduced the cut search space by applying some minor video processing to detect “blank” periods, which drastically improved the cutting mechanism.
For the recommendation side, they ran into another difficulty: the lack of user information and the cold start problem for new content, since short videos have a pretty limited lifespan (a short clip of a football match from three weeks ago is much less interesting to people). They developed a ranking system to address this and considered using large LLMs directly, but had some constraints.

So they still leveraged LLMs, but more to generate sample data to train a ranker that could estimate the appeal of a video for a certain type of user.
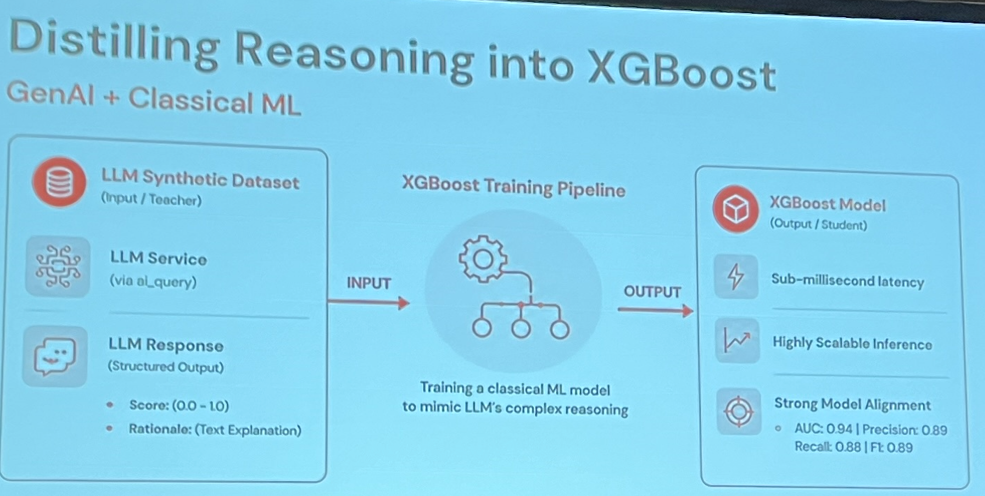
I found it surprising that they had so little information on their users and could not infer a ranking mechanism from past data. One interesting idea was the “evergreen” short, a clip that stays popular regardless of when it’s watched.
They developed an A/B testing pipeline to evaluate the quality of the ranking systems they were building, using LLM as judge.
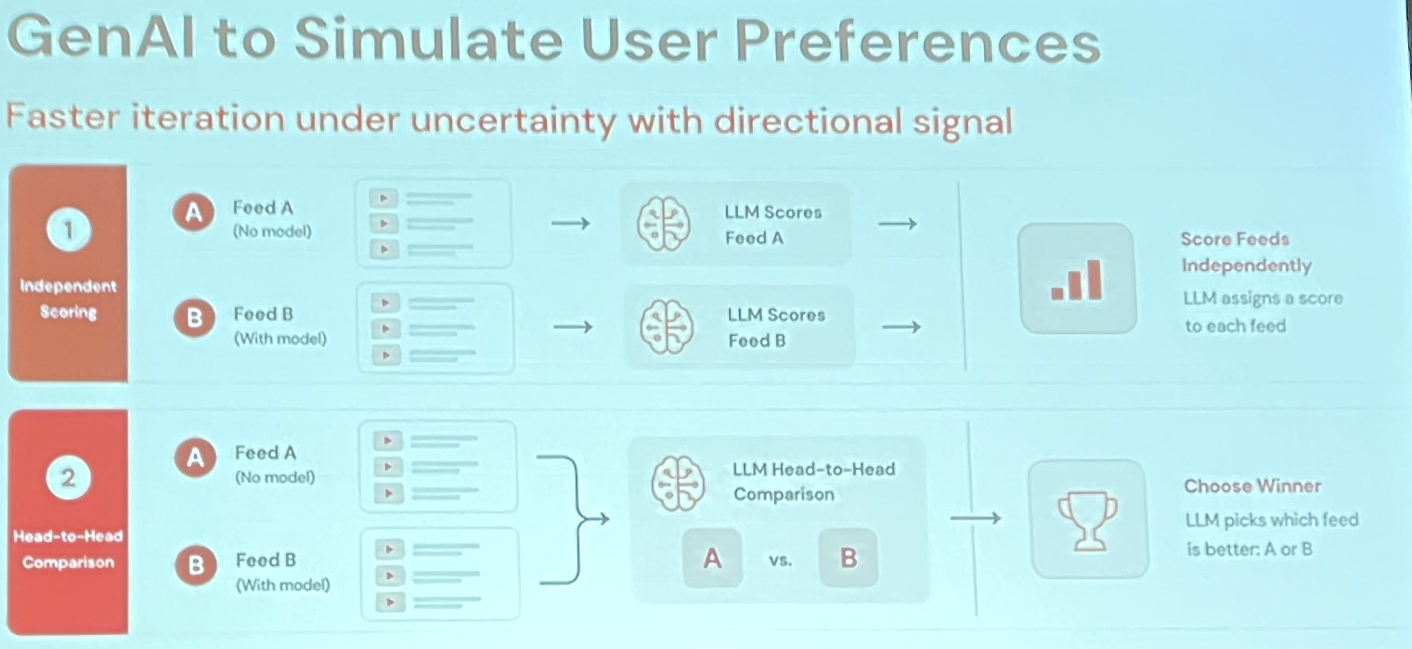
The idea of leveraging LLMs at different stages of the project is worth noting and can inspire approaches to many cold-start situations.
That cold-start approach connects to a broader theme running through the conference: LLM-powered automation of reporting.
Automation with a Sprinkle of LLM
An important theme of the conference was the automation of reporting and the integration of LLMs into it. It fits right in the spirit of Genie and everything around it, and the work on this topic stood out.
The first example came from the first part of the Krafton presentation, where they presented their flow to collect sentiment around ban waves in PUBG. Their flow looks like this:
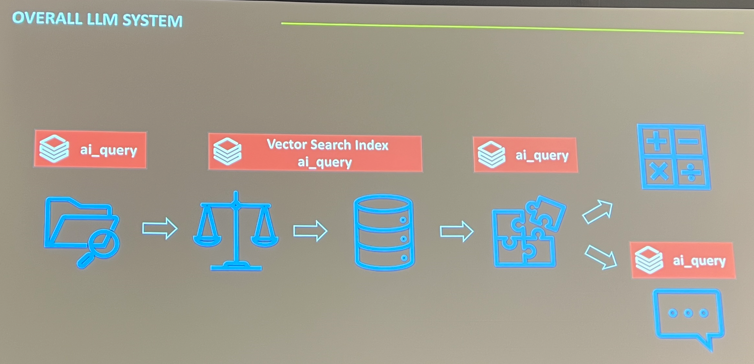
Everything is built on Databricks and leverages the ai_query function, which batch-processes raw information collected from websites to embed the content and compare it against vectors via vector search, determining whether a message can be classified under a specific candidate topic. Another LLM then validates that the content is assigned to the right topic. From these topics, aggregations and summaries are built, and they automate a report from the analysis that looks like this (sorry for the quality):
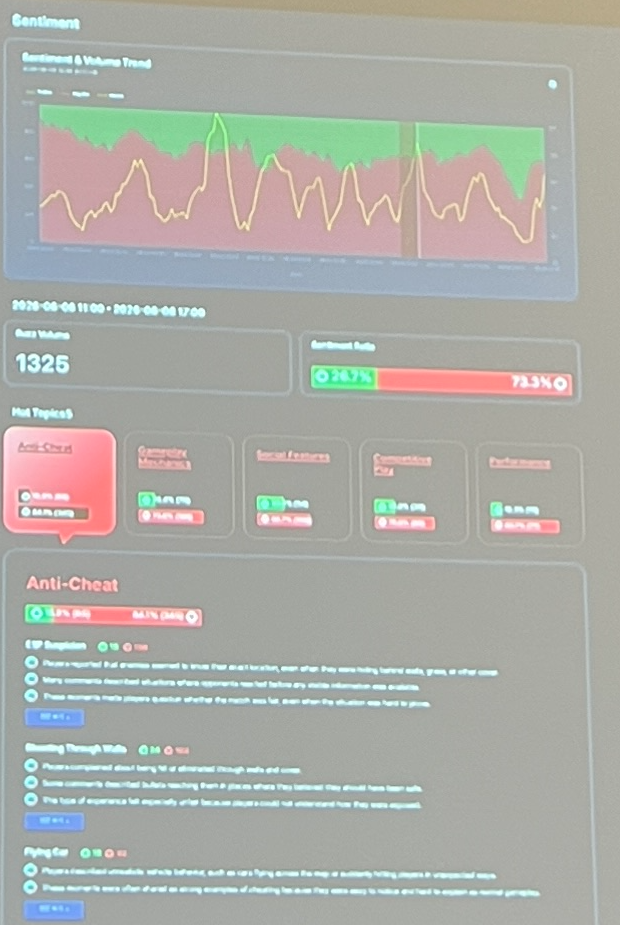
The report contains tables and graphs to display trends and overall satisfaction with a color code.
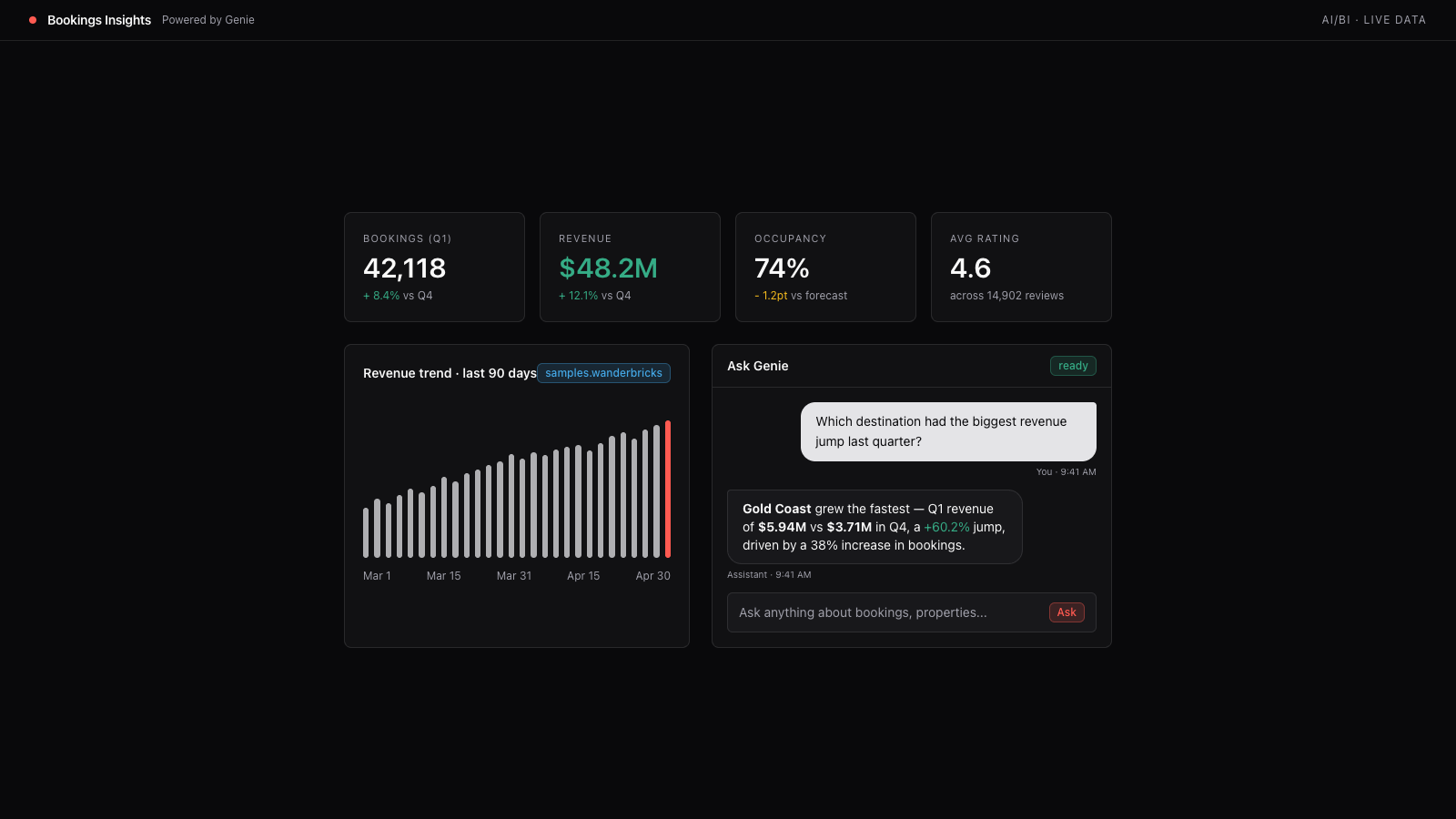
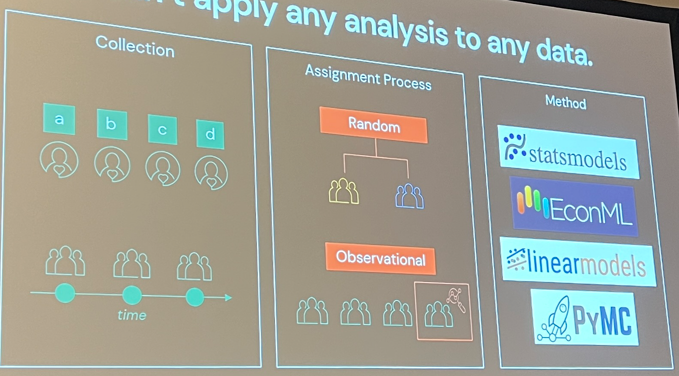
Another automation talk came from Sega, who presented From 8 Hours to 8 Minutes: Automating A/B Test Analysis on Databricks. They started from a manual process run by analysts in 2020 that could not scale as the number of A/B tests grew. With Databricks they developed a system to automate the A/B test process, from the methodology (using a Bayesian and frequentist dual approach):
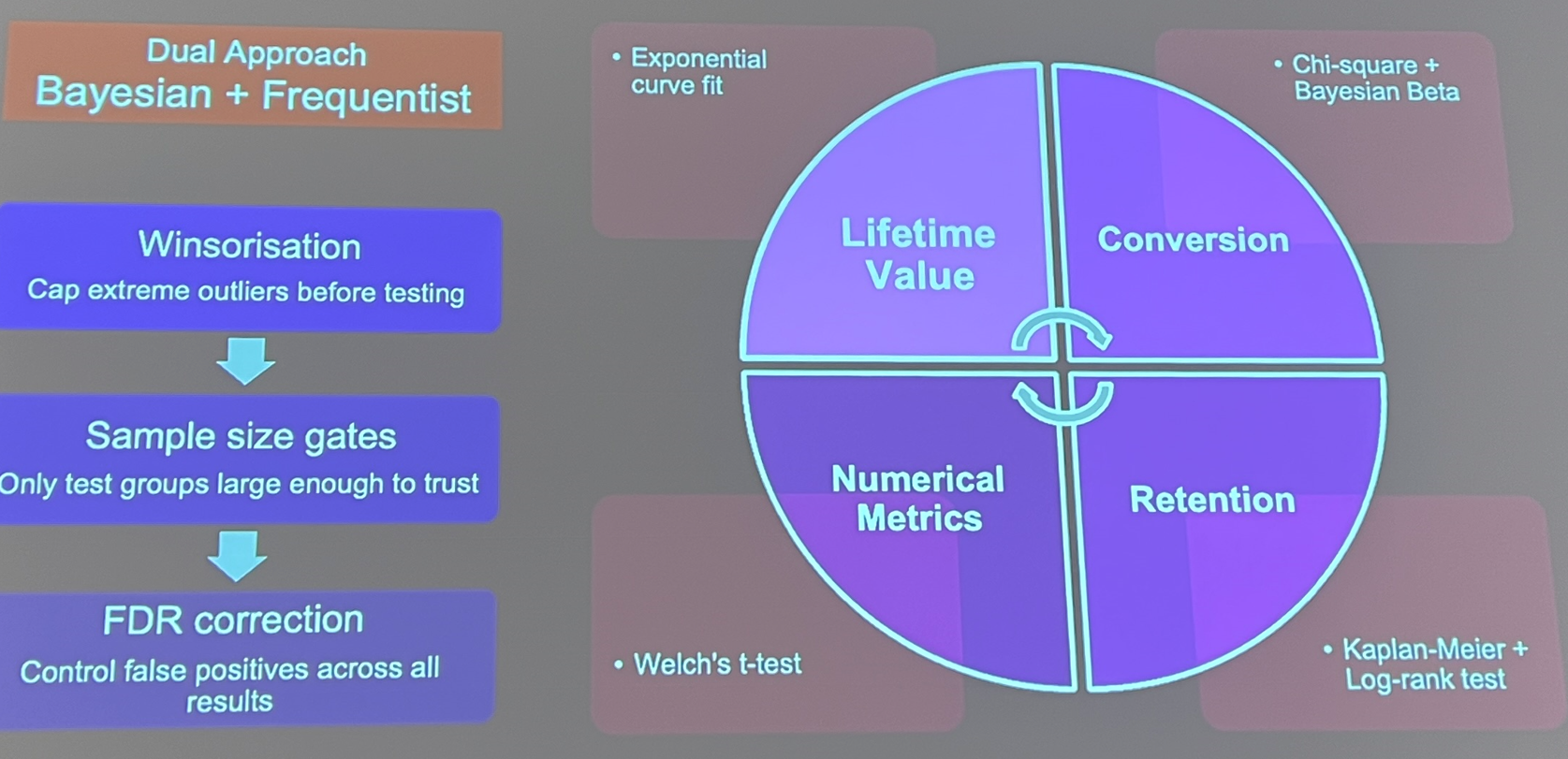
They managed to automate their ETL and associated queries to feed a live dashboard where all the metrics were stored in MLflow experiments, with MosaicAI used to support report generation.
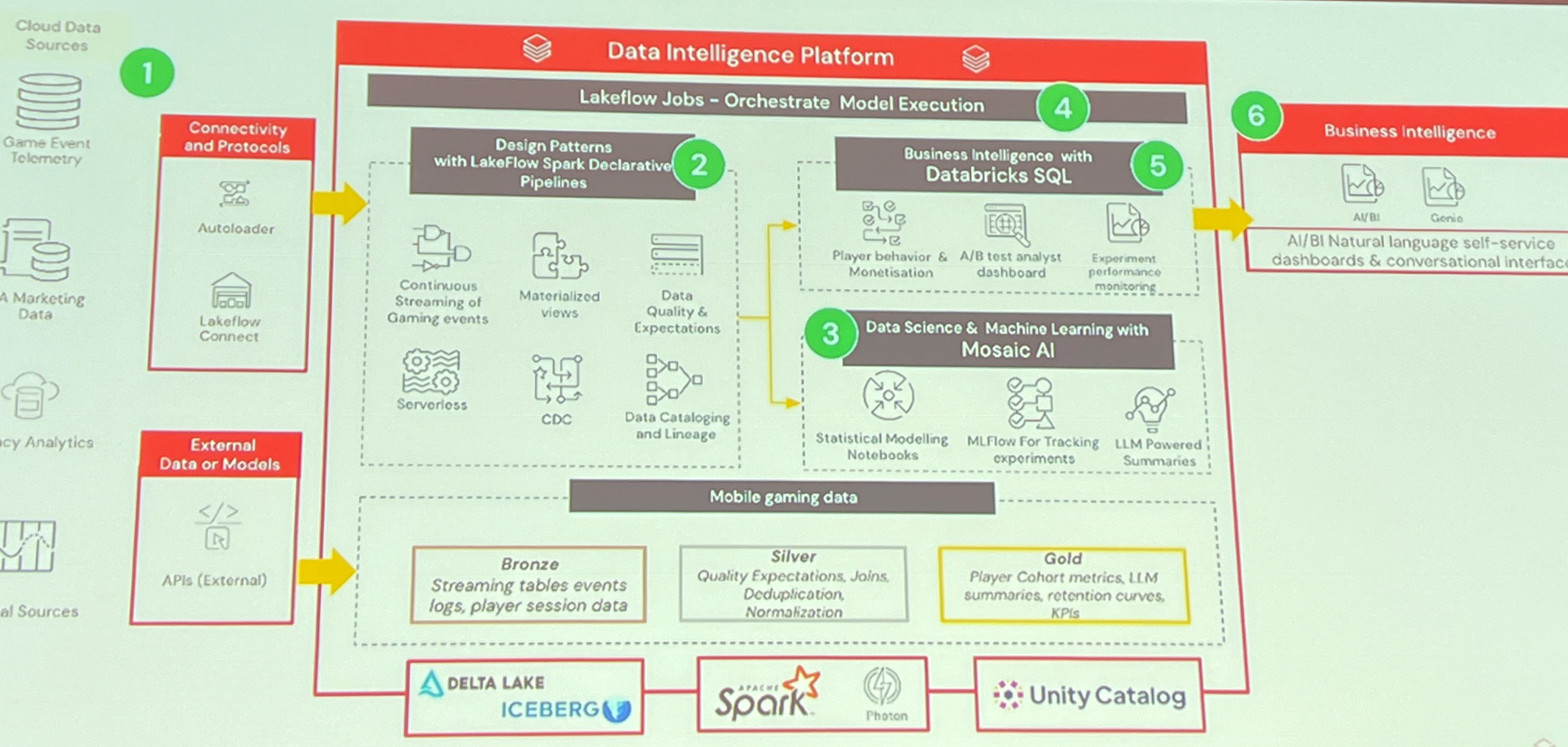
Their dashboard is divided into three tabs (experiment health, in-game health, and final analysis), where analysts select an experiment by name and receive a pre-populated results view including survival/retention metrics and an LLM-generated executive summary.
From automation, on to the practical platform guidance that surfaced across several talks.
Practical Databricks Takeaways
One of my favorite features on Databricks is Databricks Apps, and at this conference there was a dedicated talk: Architecture Best Practices and Common Patterns on Databricks Apps. Here are a few takeaways:
- Lakebase is most useful for single-row reads/writes by key, whereas for larger row counts you should lean toward DBSQL (Reyden will bridge the two in the future).
- For authentication, use the OAuth On-Behalf-Of (OBO) pattern.
- Sync vs. async request handling matters for worker efficiency: synchronous calls hold a worker thread for the full duration, so async patterns are preferred under load; LLM and tool calls should go through serving endpoints or Unity Catalog connections.
- MLflow Agent Server is presented as a strong alternative to FastAPI for building agent-backed applications, as it provides streaming response support so the UI does not have to wait for the full message to complete.
On a related note, during a braindate session with people interested in vibe-coding apps, the new developer portal came up as a useful resource, it hosts a good number of templates for building your own app on AppKit.
I attended a less technical talk organized by Databricks, Your AI Strategy is Only as Good as Your People Strategy, which highlighted what appears to be an internal study by Databricks and their customers. Here are a few takeaways:
- 94% of leaders report AI skills shortages, and agentic AI is expected to widen rather than close this gap.
- Companies are segmented into three AI maturity tiers: scalers (60%, stagnating), reinventors (35%, actively scaling), and AI-native operators (5%, where agentic employees are already a reality), with Adidas cited as a reinventor and Workday as an example of an AI-native workforce.
- The main blocker to agent deployment is human readiness, cited by 76% of companies; only 11% currently have agents in production, while 72% plan to deploy by end of 2026.
- They proposed an AI capability framework built on four pillars: (1) appetite for change and a builder mindset with ethical practice ownership at every level; (2) fluency across roles covering data/AI literacy and practitioner depth; (3) automation by default; and (4) a unified data and AI platform (of course that one :).
- The closing quote was: every company will use the same model; the only differentiator will be the people.
Finally, two more Databricks talks stood out: From Training to Production — MLOps Best Practices for Deep Learning and The Right Model for the Job: A Practical Framework for AI. Both covered practical guidance on developing deep learning models on Databricks, working with LLMs through model choice matrices, MLflow usage in a GenAI context, fine-tuning an LLM, and an AI dev kit for Databricks.

To close out the session section, here are a few talks that did not fit neatly into any of the above themes but were worth attending.
The Misfits
The first talk was from Princeton’s Research Accelerator, which built what they described as a telescope for social networks, a large-scale data collection and research platform. During the talk they discussed the growing difficulty of accessing data following data scandals like Cambridge Analytica and the changes in API access policies that affected companies like Meta and Twitter/X. This team built a scraper for sources like Telegram and set up a data platform for any researcher interested in accessing these datasets and working with them. Built on top of Databricks, here is an overview of the system:
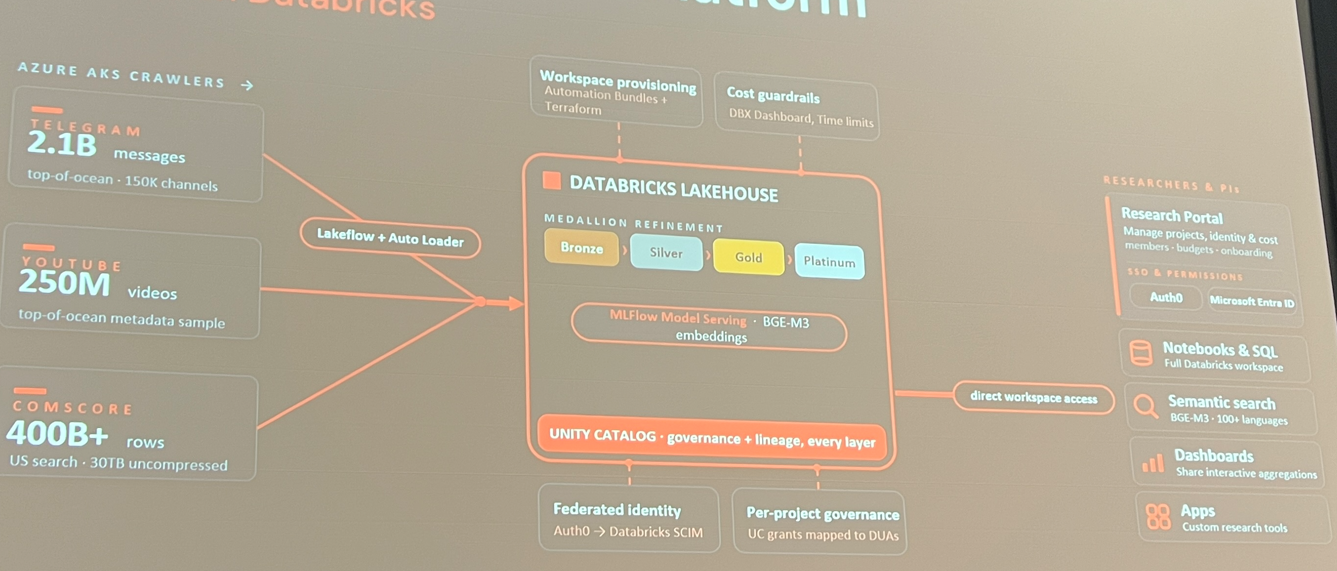
The platform includes rules around script execution time to control costs. It is a genuinely interesting project with clear public interest.
On a completely different note, Aimpoint Digital shared a Databricks app they built that is simply a Legend of Zelda-like video game. The talk did not go into much detail on the stack, but they shared the technology under the hood in this nice infographic, which could be a good starting point for anyone building video game tracking on the Databricks stack.

Finally, and this was the last presentation I attended at the summit, Databricks shared the experimentation platform they built to test Databricks itself. Here are a few learnings:
- They highlighted the inconsistency in metric definitions (for example, the definition of “active users” varied across teams), so they built a metric store where each metric is defined as code and documented properly.
- They built an assignment event system that relies on tracking and exposes results via an API.
- It was also important to them to let non-technical people run their own tests, so they built a UI for non-technical users to interact with the experimentation platform.
They listed the packages they use for all their tests, nothing new but still nice to have them in one place:
With that, the sessions are covered. Time to wrap up.
Closing Notes
It was my first attendance at the conference and I left genuinely impressed. I was a bit skeptical about the keynotes going in (you can watch them on YouTube if you missed them), but they turned out to be a great way to get a dense, curated picture of where the platform is heading. The sessions and trainings were strong, with a lot of practical takeaways I am still processing.
If I had to distill the whole week into a few lines, here is what I would keep:
- Agents are coming on strong, and Databricks is well-equipped for that.
- Documentation and context are the durable layer. Invest in them now, before the next model wave hits.
- MLflow can log everything. I remember using the tracking API to log my online pipeline, which felt hacky at the time, but now everything can fit inside it cleanly.
As a Databricks user for over 18 months, attending was worth it. Beyond the connections with people across the industry, it gave me a clearer sense of where to focus over the coming months with the platform.