
Retour du Databricks Data + AI Summit 2026
Note : Cette version française a été générée par Claude Sonnet 4.6 (claude-sonnet-4-6) le 29 juin 2026. La version originale en anglais est disponible ici.
En mi-juin, j’ai passé quatre jours au Databricks Data+AI Summit 2026 à San Francisco, parmi plus de 31 000 participants sur site, entre formations, keynotes et sessions en parallèle.
Cet article récapitule les annonces des keynotes et mes points forts des sessions. Je réserve les approfondissements des formations pour des articles séparés, plus techniques.
Keynotes
Les deux premières matinées de keynotes ont été chargées d’annonces, certaines nouvelles, d’autres mettant en valeur des sorties récentes, toutes structurées autour des 4 C du succès pour les initiatives modernes de données et d’IA : Contexte, Contrôle, Coût et Choix.

Contexte
Pour le pilier Contexte, les annonces les plus représentatives concernaient les nouvelles fonctionnalités Genie de Databricks. La première est Genie ONE, qui se positionne comme un ChatGPT pour Databricks (ils le commercialisent comme un « collaborateur IA intelligent pour les données »).

C’est le point d’entrée principal aux ressources Databricks, des données aux agents, où vous pouvez poser n’importe quelle question et agir, par exemple transformer des insights en nouveaux agents ou applications ; il n’est pas non plus limité à sa propre interface et peut interagir avec Slack ou Teams directement. Puisque Genie ONE s’appuie sur des composants comme le Unity Catalog, un système bien documenté renforce la confiance dans ses réponses et offre une traçabilité complète de chaque insight en exposant le raisonnement derrière lui.

Un composant clé de Genie ONE est la Genie Ontology, qui peut être vue comme une couche de contexte automatique, essentiellement un graphe de connaissances qui connecte chaque élément de votre Unity Catalog. Elle ajoute une couche d’autorité à chaque élément via une approche similaire à PageRank appelée OntoRank, en évaluant l’autorité à partir de toutes les métadonnées liées à une table, un tableau de bord, un modèle ML ou des assets IA dans votre catalogue (usage, crédibilité de l’auteur, complétude de la description, etc.) et en récupérant le bon contenu via ce classement par autorité.
Moins spectaculaire mais également lié à l’ontologie est l’évolution du protocole ouvert Delta Sharing vers OpenSharing, qui étend le travail de Delta Sharing aux éléments IA comme les skills, modèles ou espaces Genie (cela fait partie de la Linux Foundation, donc ouvert à tous).

Enfin, une statistique intéressante sur ce sujet : les LLM de pointe ont typiquement une durée de vie d’environ 2 mois avant qu’un nouveau challenger n’arrive. Ils ont illustré cela avec OpenAI GPT-5.5 vs. le Mythos d’Anthropic (pendant sa brève disponibilité). C’est l’illustration parfaite de pourquoi il est essentiel de faire du contexte (lignage, logs, documentation) la couche durable qui survit à tout modèle individuel, permettant aux équipes d’itérer rapidement à mesure que de nouveaux modèles émergent.
Le contexte vous donne les fondations. Mais savoir quelles données existent n’est utile que si vous pouvez aussi gouverner qui les utilise et comment. Cela nous amène au deuxième C : Contrôle.

Contrôle
Pour cette section, ce qui s’est le plus démarqué sont les annonces autour de l’AI Gateway, qui ajoute la couche de gouvernance nécessaire à l’usage de l’IA en entreprise. Grâce à lui, vous pouvez facilement accéder à un catalogue centralisé d’agents et de modèles, définir des politiques pour vos agents (en les restreignant à du contenu spécifique de votre Unity Catalog), configurer des garde-fous de monitoring pour le système, et activer le routage intelligent vers le bon modèle (selon le budget).
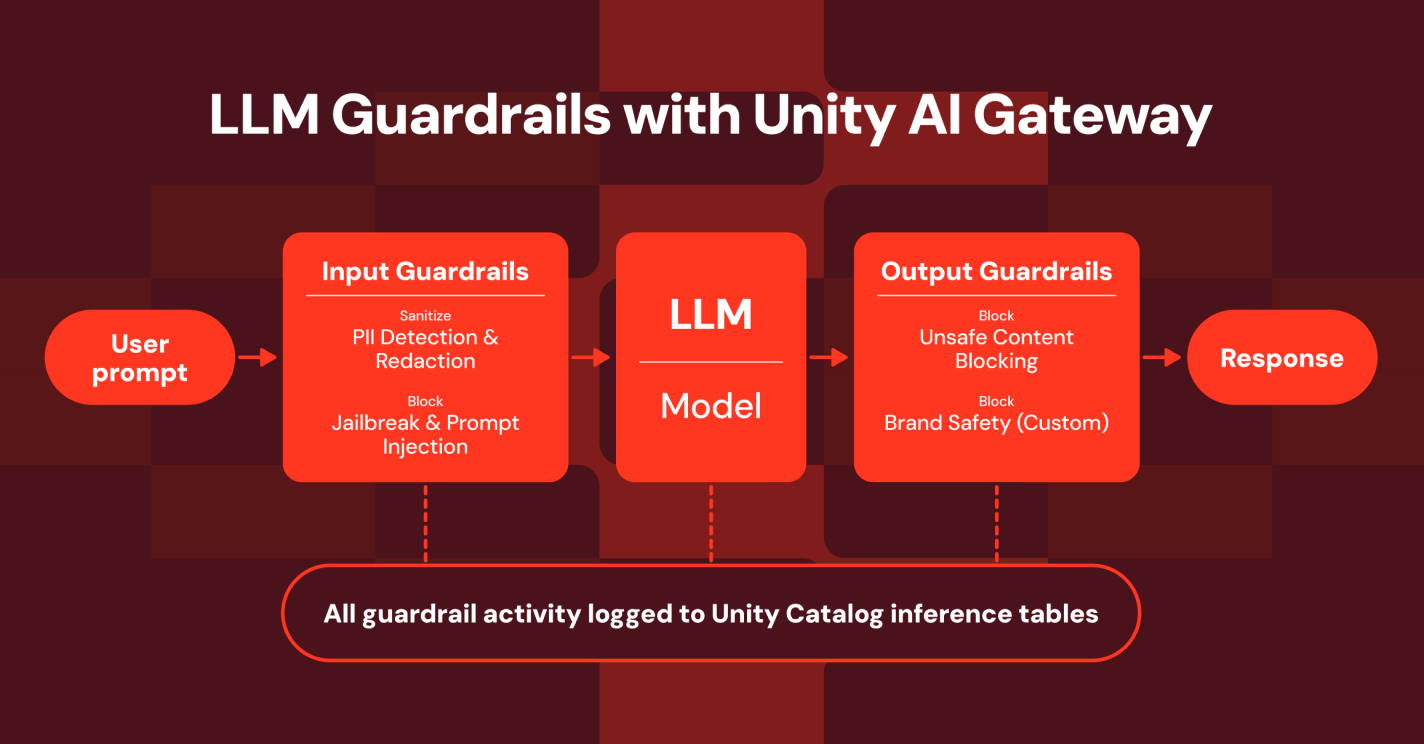
Tout cela est étroitement intégré à MLflow, offrant un système de logging complet et une traçabilité totale en un seul endroit, car la vraie difficulté ne réside pas dans le modèle lui-même, mais dans sa gouvernance : suivre les coûts, assurer la traçabilité et maintenir la supervision.
Une autre annonce étroitement liée aux agents est la capacité de branchement Postgres. Une base de données entière peut maintenant être branchée pour n’importe quel processus, comme un agent explorant des données sans interférer avec la branche principale. C’est une fonctionnalité utile : elle permet aux agents d’expérimenter librement sans avoir à recréer les permissions de la base de données ni risquer de polluer les données de production.
Cette capacité à créer des bacs à sable de données et à suivre facilement les agents donnera à quiconque sur Databricks la possibilité de passer d’une approche tokenmaxing to valuemaxing (pas mes mots, quelqu’un sur scène a inventé ça).
Avec la gouvernance en place, la question naturelle suivante est : combien tout cela coûte-t-il réellement ? Regardons le troisième C.

Coût
Le Coût a traversé les annonces précédentes aussi ; c’est ici qu’il est apparu le plus directement.
La montée en puissance du serverless pour le runtime GPU/IA et des Databricks Apps avec les microapps serverless illustre que l’exécution de workloads sur Databricks devient de plus en plus efficace et rentable (plus sur les améliorations de performance du code plus tard).
Au-delà du serverless, il y avait aussi l’annonce d’un nouveau moteur de données appelé Reyden, lié à Lakehouse RT, décrit comme un real-time warehouse that delivers millisecond performance at massive scale, without data movement.
Les performances de Reyden semblent impressionnantes d’après les benchmarks, et la magie sous le capot semble être pilotée par le machine learning, utilisé pour trouver automatiquement les bons patterns de stockage et d’accès aux données.

De ce que j’ai entendu sur cette nouvelle technologie :
- Il n’est pas plus coûteux que les moteurs SQL Databricks classiques.
- Pour en tirer pleinement parti, tout le code alimentant et récupérant les données doit être optimisé Photon. L’un des grands efforts en cours chez Databricks est de rendre la plupart des fonctions SQL et Spark Photon-ready, ce qui facilitera l’adoption de Reyden.
Les gains d’efficacité comptent, mais seulement si vous n’êtes pas enfermé dans l’écosystème d’un seul fournisseur. C’est l’esprit du quatrième et dernier C : Choix.

Choix
Lors de la conférence, Databricks a clairement indiqué qu’ils sont contre le vendor lock-in et souhaitent laisser les utilisateurs choisir leur propre stockage de données, compute, et plus encore.
Lié à l’AI Gateway, Databricks a annoncé des collaborations avec des fournisseurs de LLM, par exemple, les modèles Grok de xAI seront disponibles directement via la gateway (la réaction du public était… disons poliment mitigée).
L’annonce Choix la plus intéressante concernait Omnigent, un méta-harness pour agents IA. Il n’est actuellement disponible que sur Mac, mais le concept est d’avoir un runner et un serveur qui orchestrent différents agents ensemble.

Il offre une interface collaborative et propre et le projet est entièrement open source.
Les 4 C ont couvert l’essentiel des keynotes, mais une poignée d’annonces ne rentraient pas clairement dans l’une d’elles. Regardons celles-là ensuite.
Au-delà des 4 C
La première à noter est Genie ZeroOps, que l’on peut définir comme un agent lié à vos pipelines de données. Ce n’est pas purement un agent de code ; il creuse aussi dans les données elles-mêmes pour détecter des bugs qui pourraient autrement être masqués par des défaillances silencieuses. Globalement, il surveille vos pipelines pour détecter des problèmes et propose des correctifs à appliquer.

La deuxième annonce liée à Genie était la sortie prochaine de Genie Code pour l’ingénierie ML. En tant qu’utilisateur intensif des fonctionnalités AutoML de Databricks pour démarrer le développement de modèles, je suis enthousiaste à l’idée de le tester car c’est le genre d’assistant qui peut aussi exécuter du code, ce qui devrait accélérer l’exploration de nouveaux modèles.
Ces deux nouveaux Genie ressemblent à des justiciers qui rejoignent ma boîte à outils.

En tant que développeur d’applications Databricks, j’ai apprécié l’arrivée du Genie App Builder, une interface de vibe-coding similaire à Replit pour créer des applications web sur AppKit (désolé, les amateurs de Python comme moi, AppKit est basé sur TypeScript).
Enfin, en tant que personne travaillant sur des systèmes de recommandation, j’ai trouvé l’annonce de CustomerLake intrigante. C’est très agentique et orienté marketing, mais je suis curieux de voir comment cela pourrait s’intégrer dans un workflow de personnalisation.

Ça conclut les keynotes. Passons aux sessions.
Récapitulatif des sessions
Pendant la conférence, j’ai assisté à des sessions regroupées en cinq thèmes :
- Sécurité dans les jeux vidéo
- Personnalisation de vidéos courtes chez Fox One
- Automatisation avec une pincée de LLM
- Retours pratiques sur Databricks
- Les Inclassables
Note de bas de page : il y avait aussi une quête de type chasse au trésor avec des prix. J’ai manqué de peu la peluche Genie.

Sécurité dans les jeux vidéo
Au cours des 10 derniers mois, je me suis davantage impliqué dans des sujets de sécurité pour Rainbow Six Siege, donc les présentations sur ce sujet ont naturellement capté mon attention. Deux sessions méritent d’être soulignées : la première était de Krafton, qui a présenté leur système de détection ESP (Extra-Sensory Perception, i.e. wall hacks), et la seconde de Supercell, qui a présenté leur système de sécurité pour enfants appliqué au chat textuel.
Dans leur talk Operating Scalable AI for Games: From LLM Intelligence to Real-Time ML Systems, Krafton a en fait couvert deux sujets distincts : un pipeline basé sur LLM pour rapporter l’impact en ligne des vagues de bans (que je couvrirai dans la section suivante), et leur système de détection ESP. La partie ESP a été construite par une équipe de trois personnes en seulement deux mois, et ils ont expliqué comment il produit une série de bans chaque heure pour toutes sortes de matchs, alors que le système précédent tournait toutes les 2-3 heures et ne couvrait que quelques matchs à la fois.
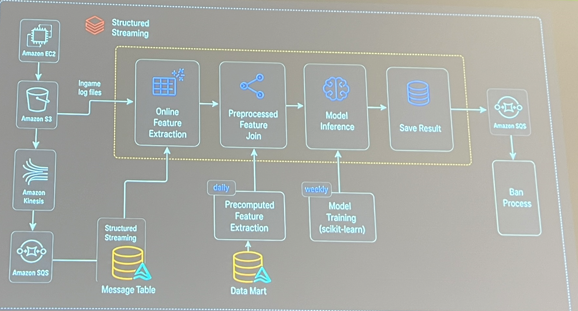
Voici les points intéressants :
- Les features du modèle proviennent de trois endroits : des fichiers de logs en temps réel et du streaming structuré pour traiter des données en temps réel plus profondes dans le feature store en ligne, plus des features précomputées quotidiennement trop lourdes à calculer en temps réel.
- Réentraînement hebdomadaire d’un modèle scikit-learn (je crois que c’était un LightGBM).
- Les événements de ban sont envoyés à un mécanisme de file d’attente pour être traités.
Pendant la présentation, ils ont aussi expliqué que pour traiter les données en temps réel, ils ont utilisé des fonctions comme applyInPandas/toPandas pour réduire les goulots d’étranglement lors de l’inférence en direct.
Ce qui s’est démarqué, c’est que même s’ils avaient un pipeline fonctionnel en quelques mois, ils semblaient avoir accumulé de la dette technique qu’ils cherchent maintenant à corriger. Même si Databricks permet d’avancer vite, il faut quand même être rigoureux et prendre le temps d’implémenter les choses correctement.
Toujours dans le domaine de la sécurité dans les jeux, j’ai assisté à la session How Supercell Uses Databricks to Serve Nearly 300M Monthly Players and Prevent Player Harm. Dans ce talk, Supercell a d’abord donné un aperçu rapide de leur expérience Databricks : ils ont plus de 5 Po de données sur la plateforme, ont commencé l’onboarding en 2021, et ont depuis amélioré leurs coûts de 30 à 60 % en tirant parti de solutions comme le serverless.
Dans leur deuxième segment, ils ont présenté un pipeline de sécurité pour enfants construit comme un système en couches, en forme d’entonnoir. J’ai genaied un petit schéma autour de ça :
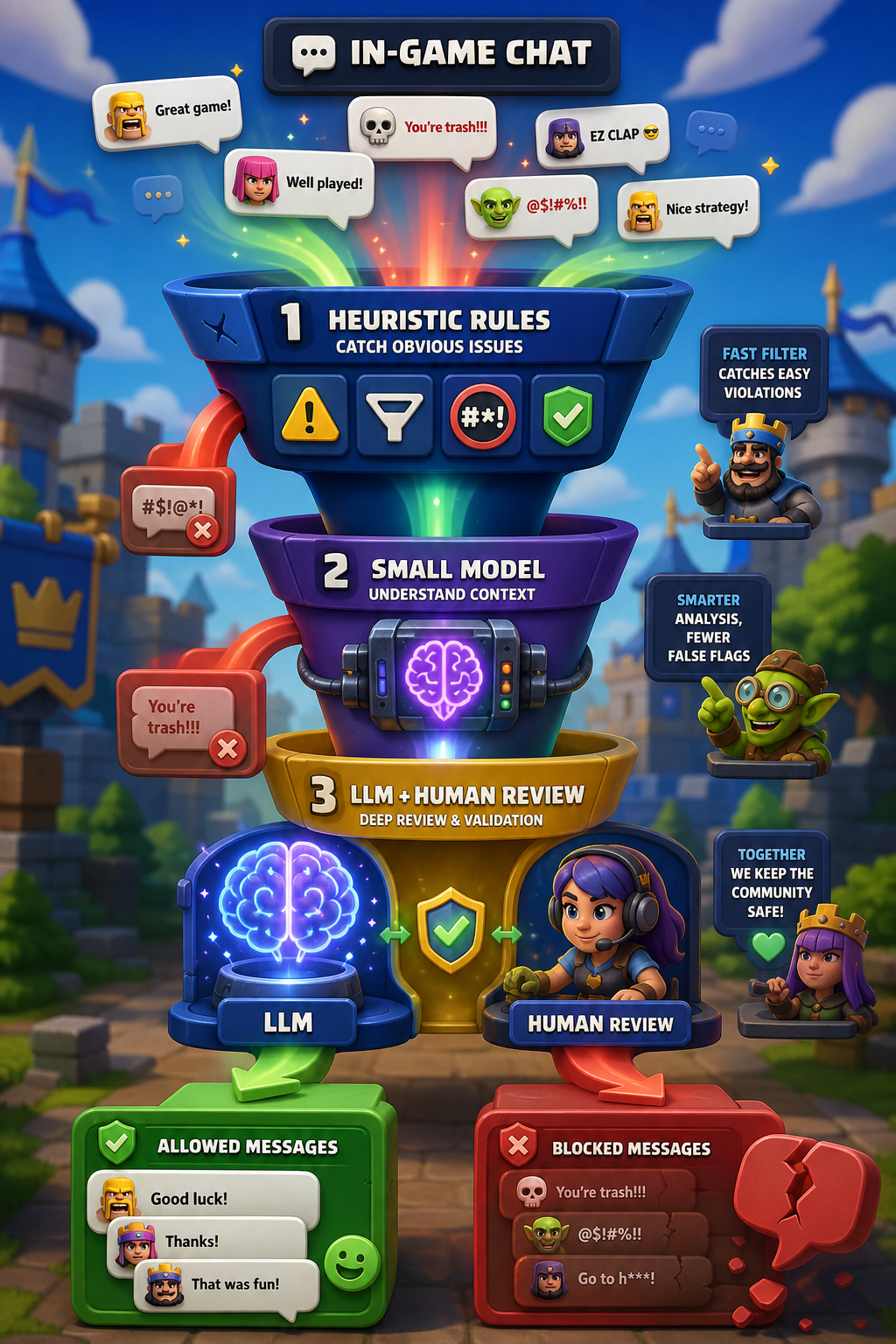
Ce qui était intéressant dans ce pipeline au-delà de l’approche en entonnoir :
- la plupart de leurs modèles tournaient sur des GPUs serverless.
- ils ont adopté une approche très incrémentale, en commençant par une seule langue (l’anglais) et en l’étendant progressivement à d’autres.
- ils intègrent le système dans le workflow des modérateurs en fournissant une formation pour les aider à travailler avec les prédictions du modèle.
Assez de sécurité. Passons à quelque chose que je trouve toujours plus excitant : la personnalisation.
Personnalisation de vidéos courtes chez Fox One
Il n’y avait pas beaucoup de sessions sur la personnalisation à cette conférence (tellement 2024, comme diraient les gens de Databricks 😄), mais il y en avait une de l’équipe de Fox One : Video Personalisation at Fox One.
Dans ce talk, ils ont présenté leur approche pour construire la génération et la recommandation de vidéos courtes dans l’application Fox One.

L’objectif était de promouvoir des émissions et du contenu via des vidéos courtes sur la plateforme. L’un de leurs principaux défis était de produire ces shorts et de faire des recommandations avec très peu de données utilisateur, et la réponse à la plupart de ces problèmes réside dans les modèles de langage.
Avec plus de 210 heures de contenu disponible par jour, ils n’avaient pas pénurie de contenu à raccourcir, mais cette opération est difficile à exécuter manuellement, ils ont donc développé un processus utilisant des modèles Gemini pour analyser le contenu disponible et créer des shorts à partir de celui-ci.

Le principal défi concernait la façon de couper les shorts, car le pipeline original découpait le contenu aléatoirement et la qualité était mauvaise (après revue LLM et humaine). Ils ont réduit l’espace de recherche des coupes en appliquant un traitement vidéo mineur pour détecter les périodes « vides », ce qui a considérablement amélioré le mécanisme de coupe.
Pour le côté recommandation, ils ont rencontré une autre difficulté : le manque d’informations utilisateur et le problème du cold start pour le nouveau contenu, car les vidéos courtes ont une durée de vie assez limitée (un clip d’un match de football d’il y a trois semaines intéresse beaucoup moins les gens). Ils ont développé un système de classement pour y remédier et ont envisagé d’utiliser directement de grands LLM, mais avaient quelques contraintes.

Ils ont donc quand même utilisé des LLM, mais davantage pour générer des données d’exemple pour entraîner un ranker capable d’estimer l’attrait d’une vidéo pour un certain type d’utilisateur.
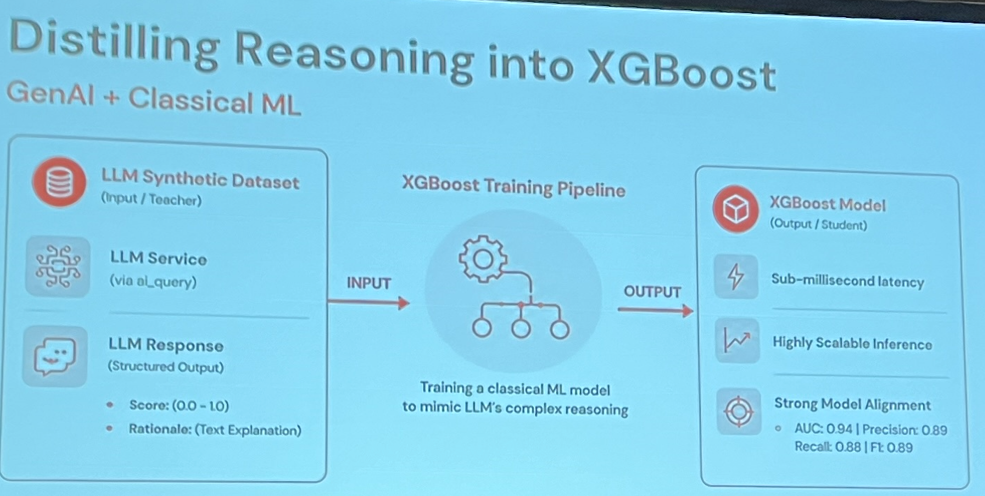
J’ai trouvé surprenant qu’ils aient si peu d’informations sur leurs utilisateurs et ne puissent pas déduire un mécanisme de classement à partir des données passées. Une idée intéressante était le short « evergreen », un clip qui reste populaire peu importe quand il est regardé.
Ils ont développé un pipeline de tests A/B pour évaluer la qualité des systèmes de classement qu’ils construisaient, en utilisant un LLM comme juge.
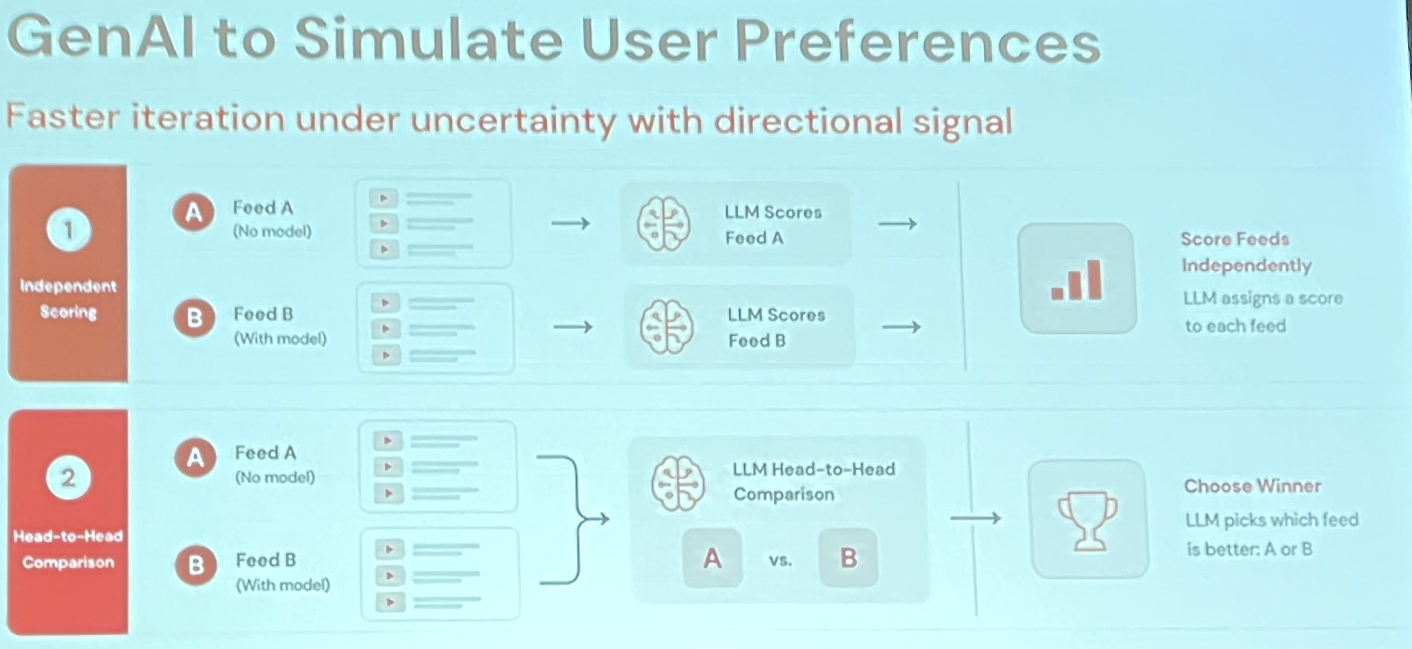
L’idée de tirer parti des LLM à différentes étapes du projet mérite d’être notée et peut inspirer des approches pour de nombreuses situations de cold-start.
Cette approche du cold-start rejoint un thème plus large traversant la conférence : l’automatisation du reporting alimentée par les LLM.
Automatisation avec une pincée de LLM
Un thème important de la conférence était l’automatisation du reporting et l’intégration des LLM dans celle-ci. Cela s’inscrit dans l’esprit de Genie et de tout ce qui l’entoure, et le travail sur ce sujet s’est démarqué.
Le premier exemple venait de la première partie de la présentation de Krafton, où ils ont présenté leur flow pour collecter le sentiment autour des vagues de bans dans PUBG. Voici à quoi ressemble leur flow :
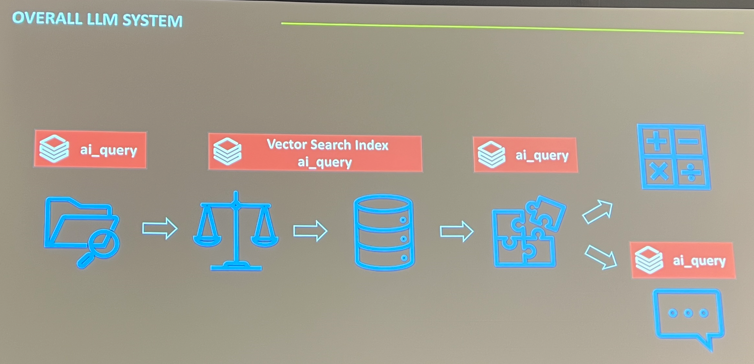
Tout est construit sur Databricks et tire parti de la fonction ai_query, qui traite en batch les informations brutes collectées sur des sites web pour les intégrer et les comparer à des vecteurs via la recherche vectorielle, déterminant si un message peut être classé sous un topic candidat spécifique. Un autre LLM valide ensuite que le contenu est attribué au bon topic. À partir de ces topics, des agrégations et résumés sont construits, et ils automatisent un rapport à partir de l’analyse qui ressemble à ça (désolé pour la qualité) :
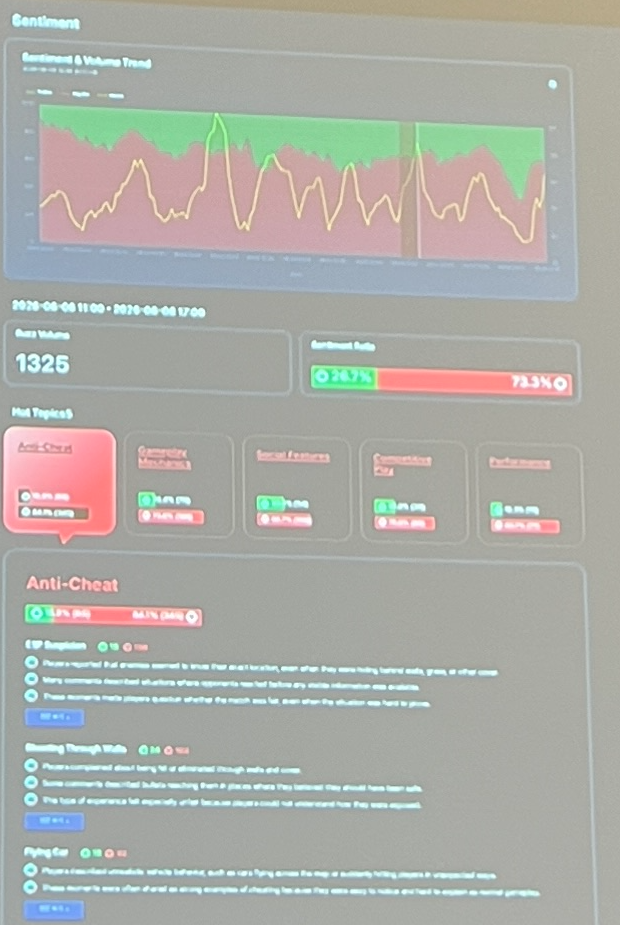
Le rapport contient des tableaux et des graphiques pour afficher les tendances et la satisfaction globale avec un code couleur.
Une autre présentation sur l’automatisation venait de Sega, qui a présenté From 8 Hours to 8 Minutes: Automating A/B Test Analysis on Databricks. Ils sont partis d’un processus manuel exécuté par des analystes en 2020 qui ne pouvait pas monter en charge avec le nombre croissant de tests A/B. Avec Databricks, ils ont développé un système pour automatiser le processus de test A/B, de la méthodologie (en utilisant une approche duale bayésienne et fréquentiste) :
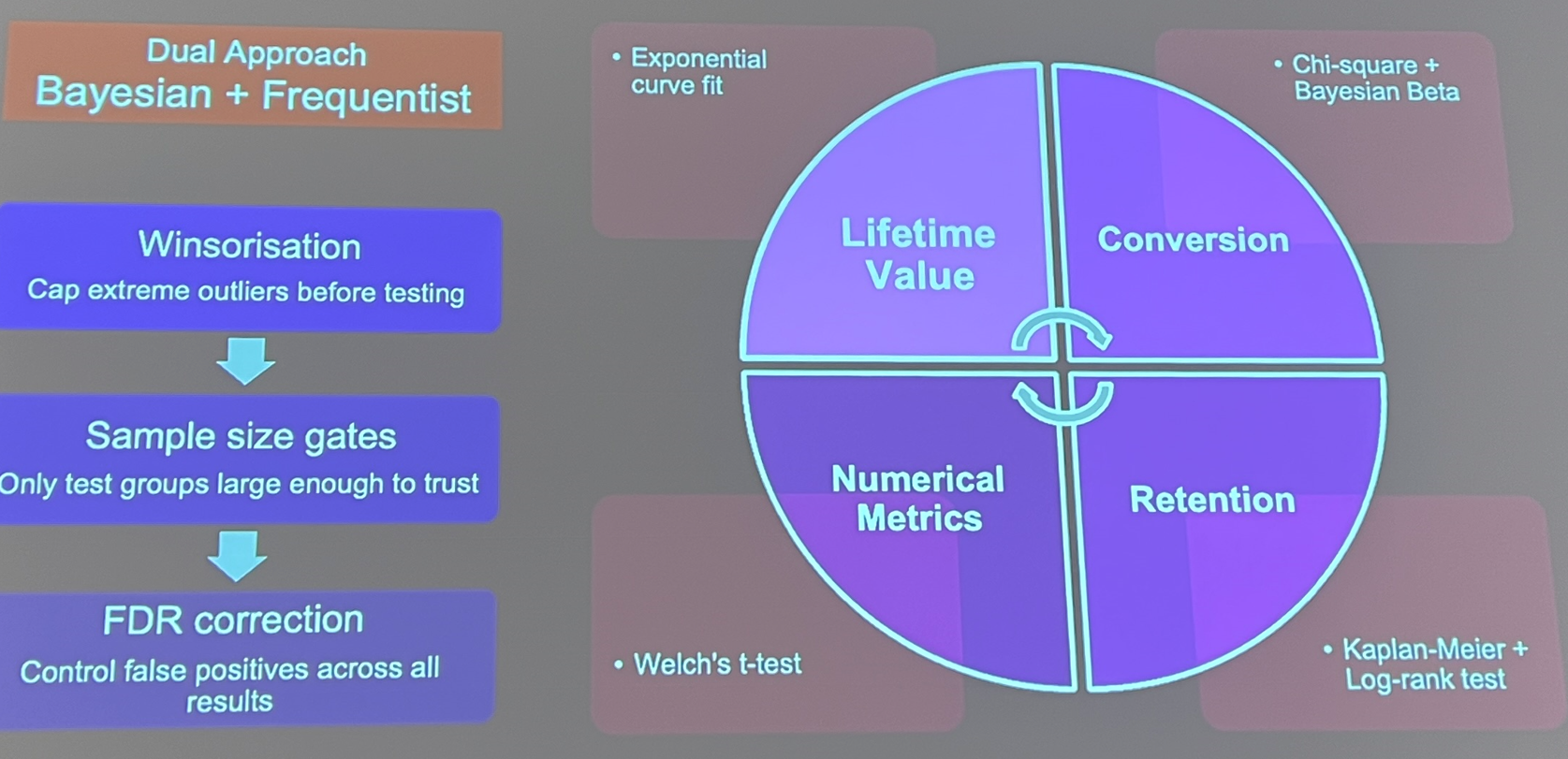
Ils ont réussi à automatiser leur ETL et les requêtes associées pour alimenter un tableau de bord en direct où toutes les métriques étaient stockées dans des expériences MLflow, avec MosaicAI utilisé pour soutenir la génération de rapports.
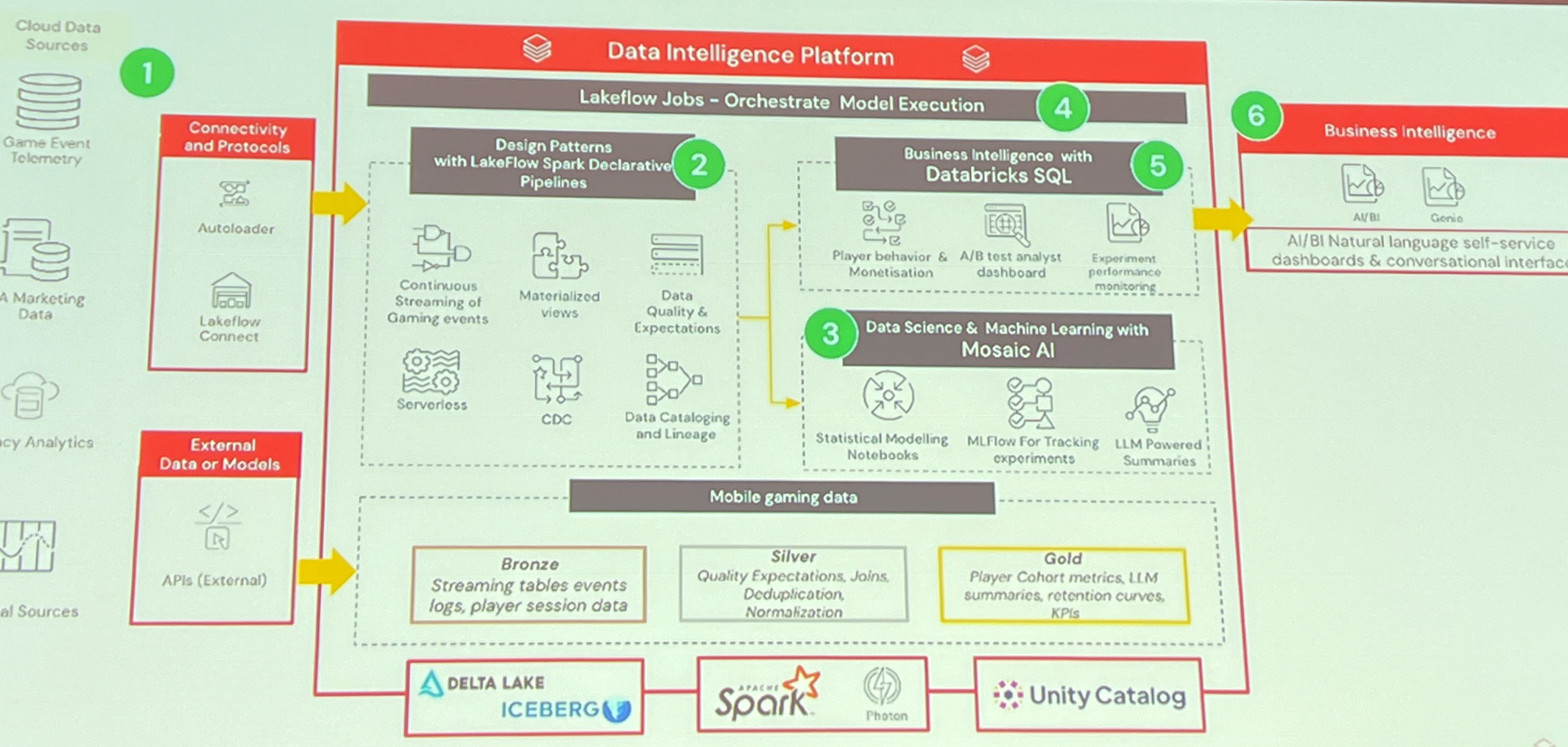
Leur tableau de bord est divisé en trois onglets (santé de l’expérience, santé in-game et analyse finale), où les analystes sélectionnent une expérience par nom et reçoivent une vue des résultats préremplie incluant les métriques de survie/rétention et un résumé exécutif généré par LLM.
De l’automatisation, passons aux conseils pratiques sur la plateforme qui ont émergé dans plusieurs talks.
Retours pratiques sur Databricks
L’une de mes fonctionnalités préférées sur Databricks est Databricks Apps, et à cette conférence il y avait un talk dédié : Architecture Best Practices and Common Patterns on Databricks Apps. Voici quelques points à retenir :
- Lakebase est le plus utile pour les lectures/écritures mono-ligne par clé, alors que pour des volumes de lignes plus importants, vous devriez vous tourner vers DBSQL (Reyden comblera les deux à l’avenir).
- Pour l’authentification, utilisez le pattern OAuth On-Behalf-Of (OBO).
- La gestion des requêtes synchrones vs. asynchrones importe pour l’efficacité des workers : les appels synchrones bloquent un thread worker pendant toute la durée, donc les patterns asynchrones sont préférés sous charge ; les appels LLM et tool doivent passer par des serving endpoints ou des connexions Unity Catalog.
- MLflow Agent Server est présenté comme une alternative solide à FastAPI pour construire des applications supportées par des agents, car il fournit un support de réponse en streaming pour que l’interface n’ait pas à attendre le message complet.
En lien avec cela, lors d’une session braindate avec des personnes intéressées par le vibe-coding d’apps, le nouveau portail développeur a émergé comme une ressource utile, il héberge un bon nombre de templates pour construire votre propre app sur AppKit.
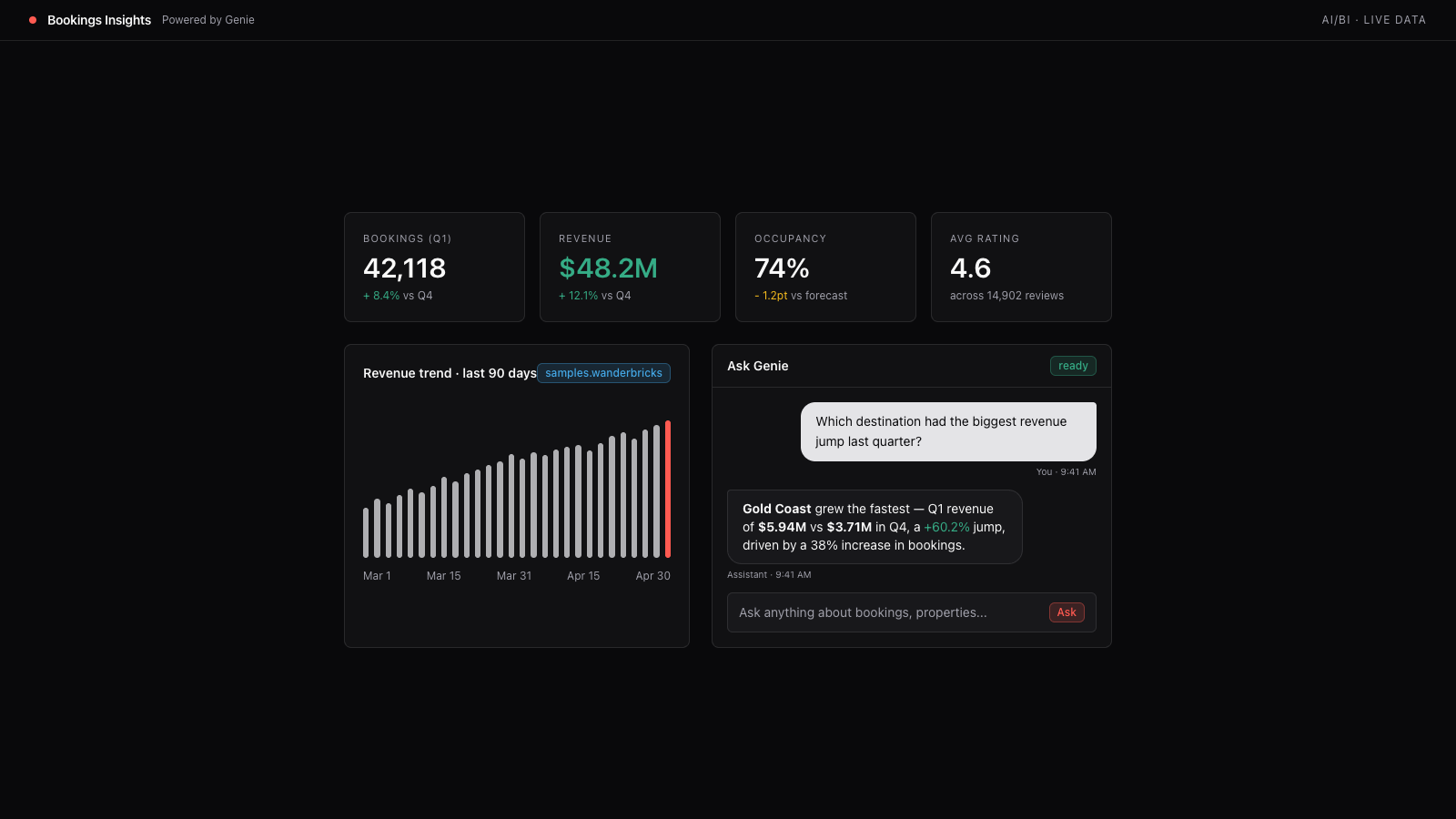
J’ai assisté à un talk moins technique organisé par Databricks, Your AI Strategy is Only as Good as Your People Strategy, qui a mis en lumière ce qui semble être une étude interne de Databricks et leurs clients. Voici quelques points à retenir :
- 94 % des dirigeants signalent des pénuries de compétences en IA, et l’IA agentique devrait creuser plutôt que combler cet écart.
- Les entreprises sont segmentées en trois niveaux de maturité IA : les scalers (60 %, en stagnation), les reinventors (35 %, en montée en puissance active), et les opérateurs AI-native (5 %, où les employés agentiques sont déjà une réalité), avec Adidas cité comme reinventor et Workday comme exemple de workforce AI-native.
- Le principal frein au déploiement d’agents est la préparation humaine, citée par 76 % des entreprises ; seulement 11 % ont actuellement des agents en production, tandis que 72 % prévoient de déployer d’ici fin 2026.
- Ils ont proposé un cadre de capacités IA construit sur quatre piliers : (1) appétit pour le changement et mentalité de constructeur avec une pratique éthique à chaque niveau ; (2) fluidité entre les rôles couvrant la littératie données/IA et la profondeur praticienne ; (3) automatisation par défaut ; et (4) une plateforme de données et d’IA unifiée (bien sûr celle-là :).
- La citation de clôture était : toutes les entreprises utiliseront le même modèle ; le seul différenciateur sera les personnes.
Enfin, deux autres talks Databricks se sont démarqués : From Training to Production — MLOps Best Practices for Deep Learning et The Right Model for the Job: A Practical Framework for AI. Les deux ont couvert des conseils pratiques sur le développement de modèles de deep learning sur Databricks, le travail avec les LLM via des matrices de choix de modèles, l’utilisation de MLflow dans un contexte GenAI, le fine-tuning d’un LLM, et un AI dev kit pour Databricks.

Pour clore la section sessions, voici quelques talks qui ne rentraient pas dans les thèmes ci-dessus mais valaient la peine d’être suivis.
Les Inclassables
Le premier talk venait du Princeton’s Research Accelerator, qui a construit ce qu’ils ont décrit comme un télescope pour les réseaux sociaux, une plateforme de collecte de données et de recherche à grande échelle. Pendant le talk, ils ont discuté de la difficulté croissante d’accéder aux données suite à des scandales de données comme Cambridge Analytica et des changements de politiques d’accès aux API qui ont affecté des entreprises comme Meta et Twitter/X. Cette équipe a construit un scraper pour des sources comme Telegram et mis en place une plateforme de données pour tout chercheur intéressé à accéder à ces jeux de données et à travailler avec eux. Construite sur Databricks, voici un aperçu du système :
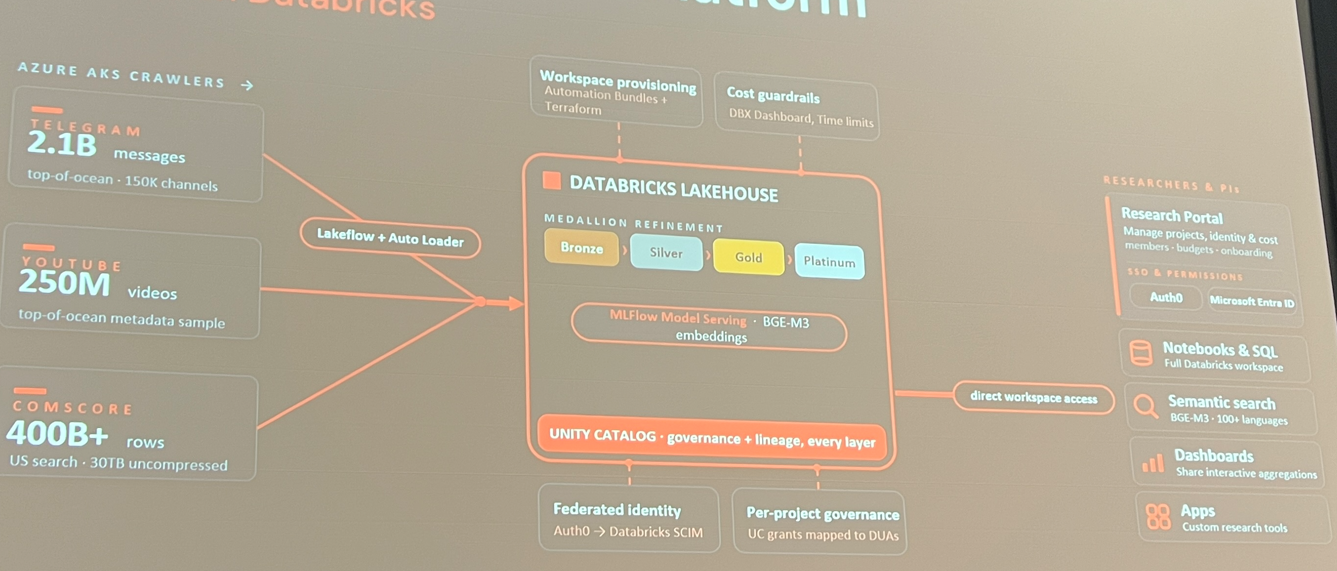
La plateforme inclut des règles sur le temps d’exécution des scripts pour contrôler les coûts. C’est un projet genuinement intéressant avec un intérêt public clair.
Sur une note complètement différente, Aimpoint Digital a partagé une app Databricks qu’ils ont construite qui est simplement un jeu vidéo façon Legend of Zelda. Le talk n’est pas entré dans beaucoup de détails sur la stack, mais ils ont partagé la technologie sous le capot dans cette belle infographie, qui pourrait être un bon point de départ pour quiconque construisant du tracking de jeux vidéo sur la stack Databricks.

Enfin, et c’était la dernière présentation à laquelle j’ai assisté au sommet, Databricks a partagé la plateforme d’expérimentation qu’ils ont construite pour tester Databricks lui-même. Voici quelques apprentissages :
- Ils ont mis en évidence l’incohérence dans les définitions des métriques (par exemple, la définition des « utilisateurs actifs » variait selon les équipes), ils ont donc construit un metric store où chaque métrique est définie comme du code et documentée correctement.
- Ils ont construit un système d’événements d’affectation qui s’appuie sur le tracking et expose les résultats via une API.
- Il était aussi important pour eux de laisser les personnes non-techniques exécuter leurs propres tests, ils ont donc construit une interface utilisateur pour les non-techniciens pour interagir avec la plateforme d’expérimentation.
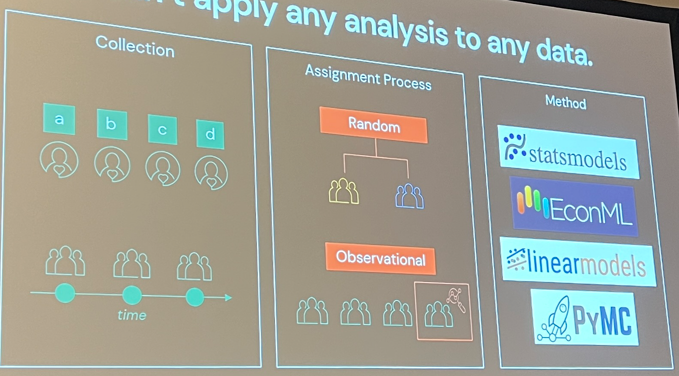
Ils ont listé les packages qu’ils utilisent pour tous leurs tests, rien de nouveau mais agréable de les avoir en un seul endroit :
Avec ça, les sessions sont couvertes. Il est temps de conclure.
Notes de clôture
C’était ma première participation à la conférence et j’en suis ressorti vraiment impressionné. J’étais un peu sceptique vis-à-vis des keynotes en arrivant (vous pouvez les regarder sur YouTube si vous les avez manqués), mais ils se sont révélés être une excellente façon d’avoir une image dense et curatée de là où la plateforme se dirige. Les sessions et formations étaient solides, avec beaucoup de points pratiques que je suis encore en train de traiter.
Si je devais distiller toute la semaine en quelques lignes, voici ce que je retiendrais :
- Les agents arrivent en force, et Databricks est bien équipé pour ça.
- Documentation et contexte constituent la couche durable. Investissez dedans maintenant, avant que la prochaine vague de modèles n’arrive.
- MLflow peut tout logger. Je me souviens avoir utilisé l’API de tracking pour logger mon pipeline en ligne, ce qui semblait bricolé à l’époque, mais maintenant tout peut s’intégrer dedans proprement.
En tant qu’utilisateur de Databricks depuis plus de 18 mois, la participation en valait la peine. Au-delà des connexions avec des personnes de toute l’industrie, cela m’a donné une idée plus claire de là où concentrer mes efforts sur la plateforme dans les mois à venir.