
Analyse des données de compteurs intelligents à Londres (Royaume-Uni)
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Bonjour, l’objectif de cet article est d’offrir une description claire de l’ensemble de données que j’ai téléchargé en novembre 2017 sur Kaggle suivi de quelques analyses de cet ensemble de données.
Description de l’ensemble de données
Pour mieux suivre la consommation d’énergie, le gouvernement souhaite que les fournisseurs d’énergie installent des compteurs intelligents dans chaque foyer en Angleterre, au Pays de Galles et en Écosse. Il y a plus de 26 millions de foyers que les fournisseurs d’énergie doivent atteindre, avec l’objectif que chaque foyer ait un compteur intelligent d’ici 2020.
Ce déploiement de compteurs est mené par l’Union européenne qui a demandé à tous les gouvernements membres d’examiner les compteurs intelligents dans le cadre des mesures visant à moderniser notre approvisionnement en énergie et à lutter contre le changement climatique. Après une étude initiale, le gouvernement britannique a décidé d’adopter les compteurs intelligents dans le cadre de leur plan de mise à jour de notre système énergétique vieillissant.
Dans cet ensemble de données, vous trouverez une version refactorisée des données du magasin de données de Londres, qui contient les relevés de consommation d’énergie d’un échantillon de 5 567 ménages londoniens ayant participé au projet Low Carbon London mené par UK Power Networks entre novembre 2011 et février 2014. Les données des compteurs intelligents semblent associées uniquement à la consommation électrique.
Pour avoir un ensemble de données plus facile à manipuler, différentes transformations ont été appliquées sur l’ensemble de données :
- Collecte de toutes les données d’un ménage spécifique dans le même fichier (ce qui n’était pas le cas dans l’ensemble de données original)
- Les personnes du même groupe ACORN sont dans le même fichier
L’ensemble de données original et nettoyé peut être trouvé dans le fichier zip halfhourly_dataset et un fichier ressemble à cette capture d’écran.
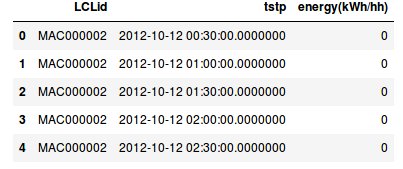
Aperçu des données demi-horaires
Comme vous pouvez le voir, l’ensemble de données est assez facile à manipuler avec :
- LCLid qui correspond à l’ID du ménage
- tstp l’horodatage de la mesure
- energy(kWh/hh) l’énergie consommée au cours des 30 dernières minutes en kWh
Mais pour faciliter la vie de l’utilisateur de mon ensemble de données, j’ai créé deux autres fichiers zip qui contiennent des données pré-traitées :
- le daily_dataset qui contient des informations quotidiennes sur la consommation des ménages
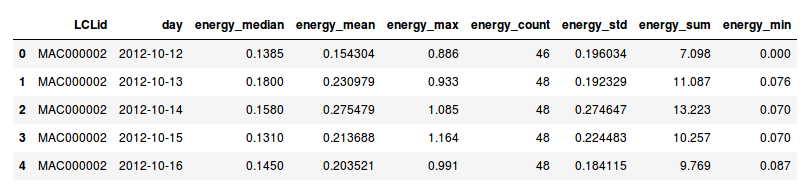
- le hhblock_dataset qui contient les données transposées d’une journée pour un ménage (sous forme de tableau) avec par exemple la colonne hh_0 qui est la consommation entre 00:00 et 00:30
 ######
######
Ceci est un aperçu de toutes les données du compteur intelligent, mais pour faciliter l’exploration, il y a une table qui stocke tous les ménages et leurs fichiers associés (informations_households.csv).
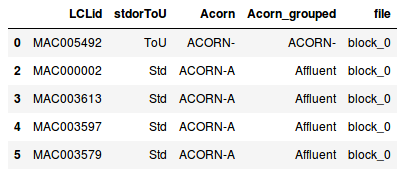
Dans cette table, il y a :
- LCLid qui correspond à l’ID du ménage
- stdorToU le type de tarif appliqué (ToU le tarif dynamique en fonction des jours ou Std le tarif fixe classique)
- Acorn le groupe ACORN associé, qui catégorise le ménage
- Acorn_grouped il s’agit d’une autre classification plus globale de l’ACORN (fusion de différents groupes ACORN)
- file nom du fichier dans les différents fichiers zip où vous pouvez trouver les données du ménage
Toutes ces informations proviennent de l’ensemble de données original, mais pour compléter les informations disponibles pour faire d’autres études, il y a un ajout de quelques nouveaux ensembles de données :
- acorn_details.csv : qui contient l’indice de plusieurs paramètres en comparaison de la moyenne nationale (qui a un indice de 100)
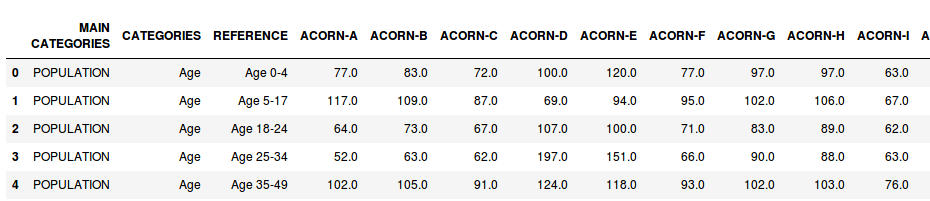
Aperçu des détails sur les groupes ACORN
- uk_bank_holidays.csv : les jours fériés bancaires pour la période de l’étude

Aperçu des détails sur les jours fériés bancaires
- weather_daily_darksky.csv : les informations quotidiennes sur la météo de darksky à Londres pendant l’étude
Aperçu des informations météorologiques quotidiennes
- weather_hourly_darksky.csv : les informations horaires sur la météo de darksky à Londres pendant l’étude
Aperçu des informations météorologiques horaires
Cette première partie offre un aperçu général du contenu de l’ensemble de données, il est maintenant temps d’obtenir une vision plus claire sur les données du compteur intelligent.
Exploration de l’ensemble de données
Sélection des ménages
La première étape de cette étude est de trouver la meilleure période pour faire la comparaison. Dans mon article précédent sur la consommation électrique en France, il y avait un effet saisonnier, donc une bonne période pour étudier sera d’au moins un an de données. Dans la figure suivante, il y a une illustration du nombre de ménages avec des données (les 48 horodatages dans la journée) par jour de l’étude.
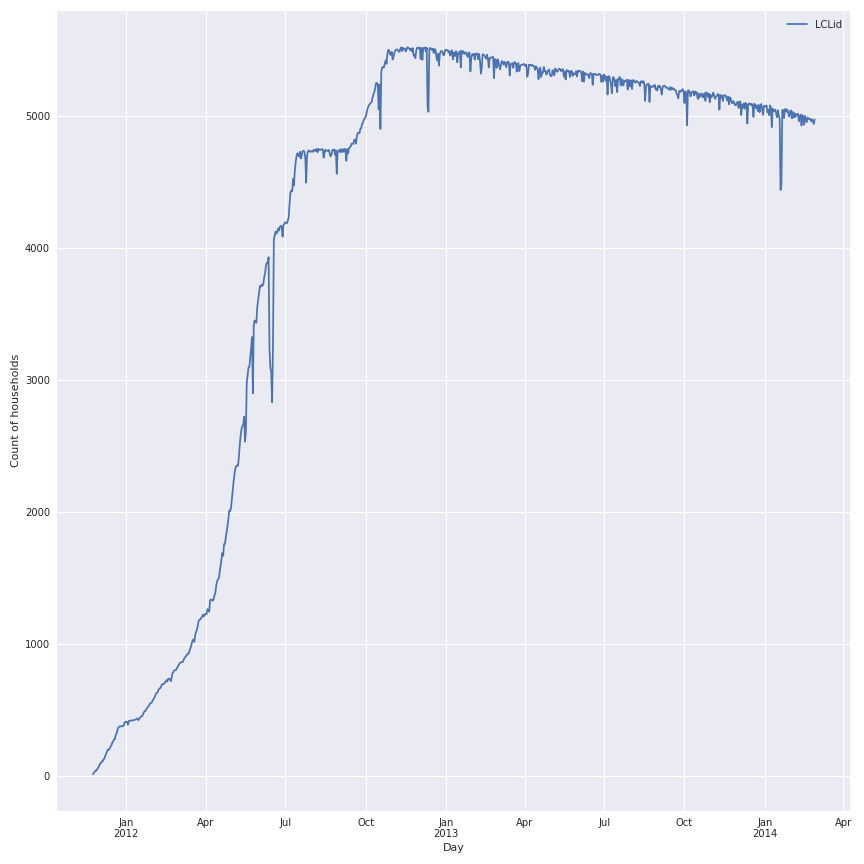
Notes: Il y a clairement une augmentation du nombre de ménages disponibles depuis le début de l’étude fin 2011, le pic est atteint en 2013. Une bonne période pour notre étude pourrait être 2013 (et j’ai choisi celle-ci). Mais il est maintenant important de connaître la distribution des jours disponibles pour cette période dans les ménages de l’expérience. Dans la figure suivante, il y a une représentation de cette distribution dans un boxplot.
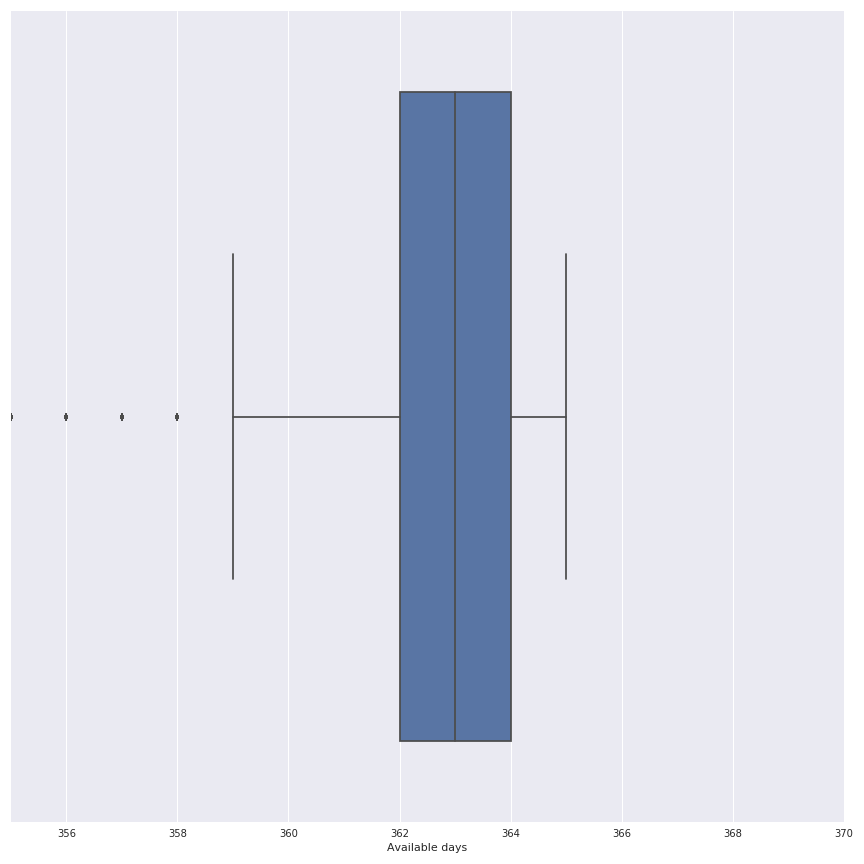
La décision a été prise d’utiliser les ménages qui possèdent au moins 357 jours, donc sur l’ensemble de données original cela représente une perte de 632 ménages sur les 5566 disponibles dans l’ensemble de données, ce qui est totalement acceptable.
Aperçu du panel
L’une des premières choses à faire est d’afficher la consommation moyenne par jour de ces ménages pendant l’année 2013. Dans la figure suivante, il y a la consommation moyenne globale de ces ménages pendant la période.
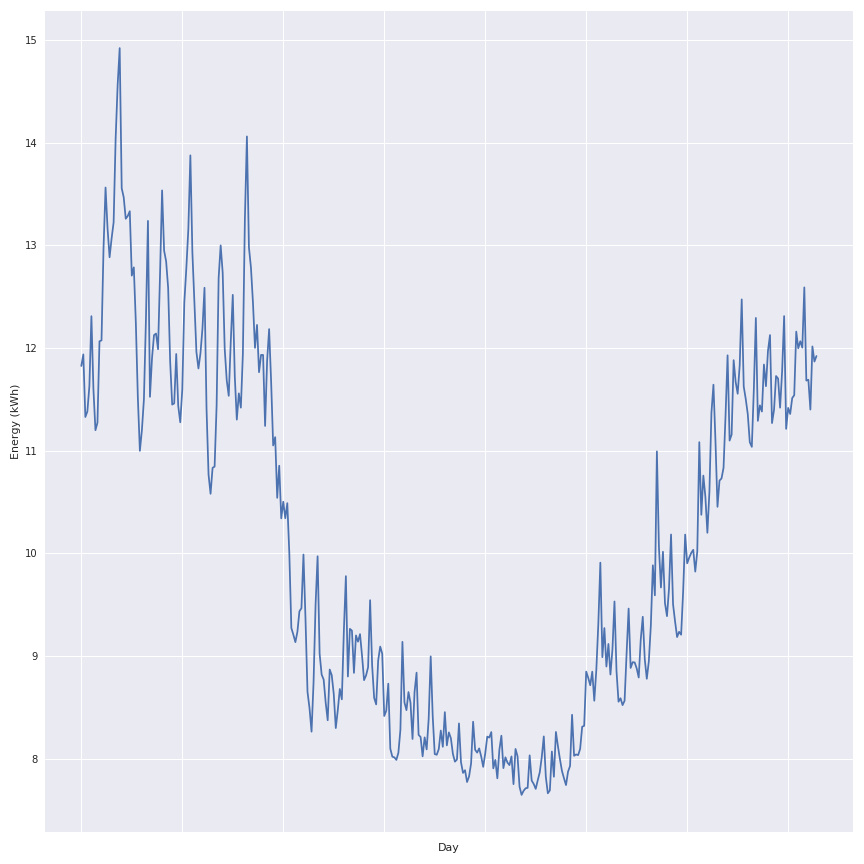
Notes: Il est évident qu’il y a un lien entre la consommation électrique et le jour de l’année (même résultat que dans mon article précédent). L’effet saisonnier est très clair, donc dans ce panel, il y a beaucoup de personnes qui utilisent l’électricité comme source de chauffage. Si la température extérieure moyenne quotidienne et la consommation quotidienne totale du panel sont croisées, la figure suivante affiche la relation :
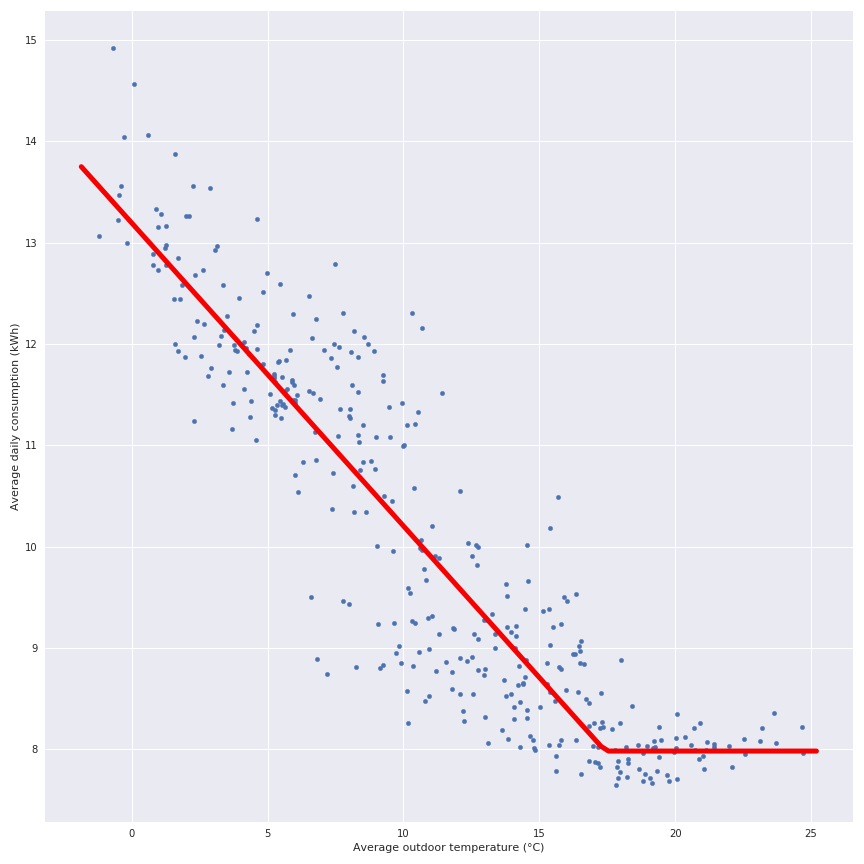
Cette observation générale offre une vision claire que le PTG (le tracé rouge) de l’article précédent peut être calculé pour chaque ménage. Dans la figure suivante, il y a une représentation de la consommation quotidienne et du PTG associé à ce ménage (et leur score r²).
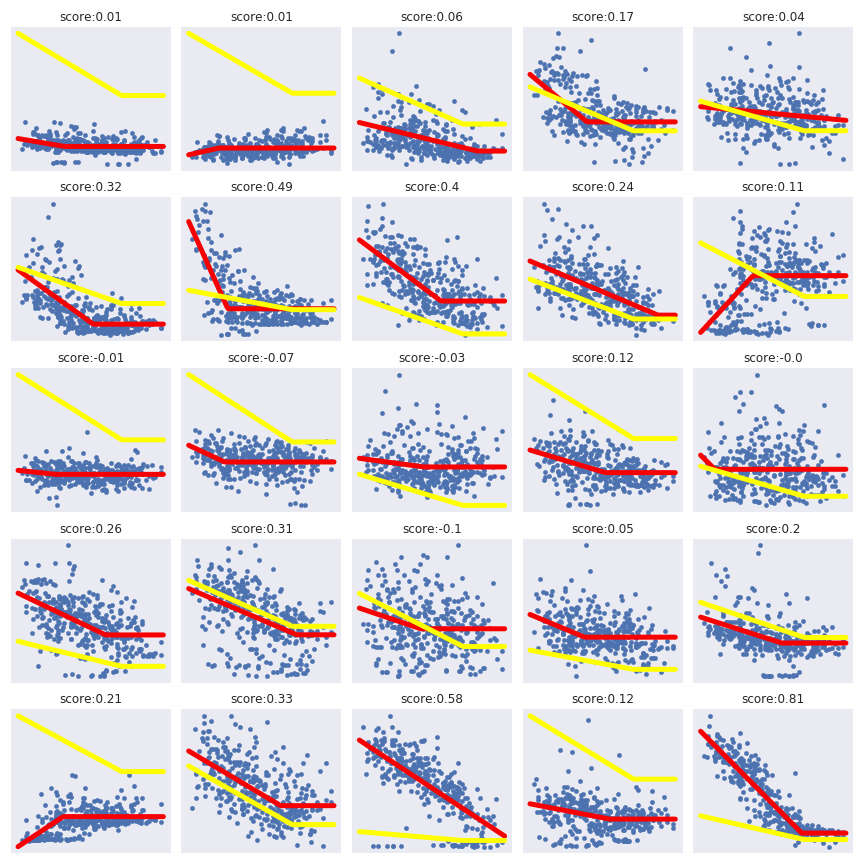
Notes: Ceci est une bonne illustration que pour certains ménages le score r² fonctionne très bien (ces ménages devraient avoir un système de chauffage électrique) mais pour certains ménages cela ne fonctionne pas du tout. Le modèle général dérivé de la consommation quotidienne moyenne (la courbe jaune) illustre que la consommation quotidienne moyenne ne représente pas le comportement général des ménages. Dans la figure suivante, il y a le diagramme de dispersion de la température pivot en fonction du score r².
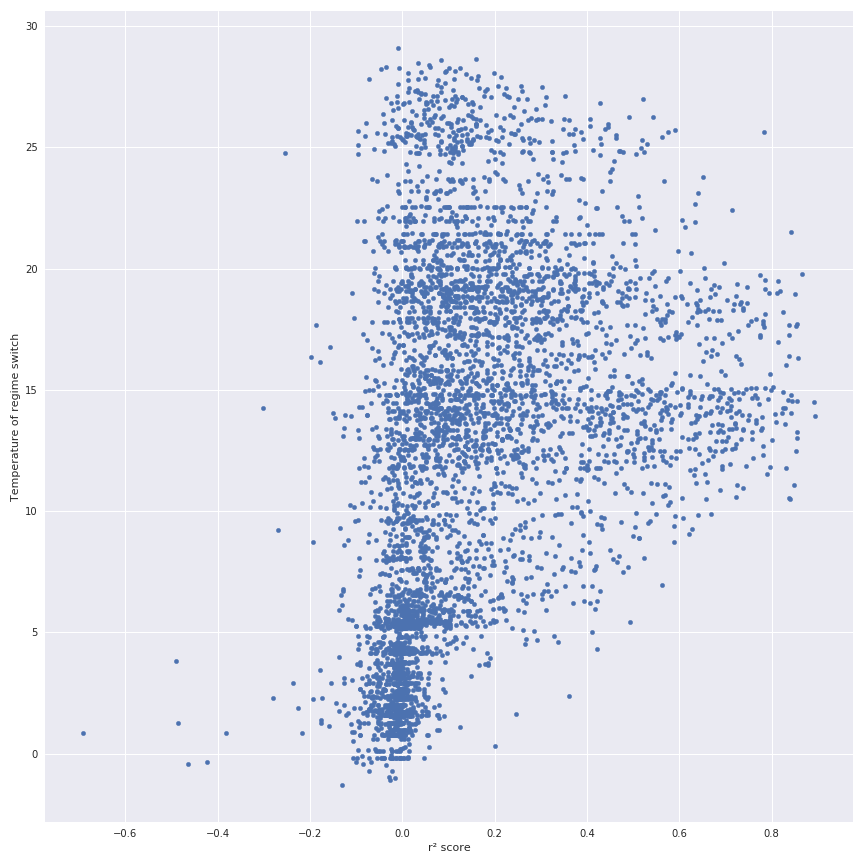
Une autre façon d’identifier les ménages qui ont un système de chauffage électrique pourrait être de comparer la consommation moyenne pendant l’hiver et l’été et de faire un simple rapport entre ces deux consommations. Les données ont été croisées avec les informations des ménages, et il y a un extrait du nouvel ensemble de données.

Dans ce dataframe, il y a :
- model_a la pente du modèle ptg (dans la partie hiver)
- model_b l’intersection des modèles ptg
- model_x0 la température de changement de régime
- r2score le score r² du modèle ptg sur le ménage
- season_0 la consommation moyenne en hiver
- season_1 la consommation moyenne au printemps
- season_2 la consommation moyenne en été
- season_3 la consommation moyenne en automne
- ratio_winter_summer le rapport de la consommation hiver/été
- stdorToU le type de tarif
- Acorn le groupe ACORN
- Acorn_grouped les groupes ACORN agrégés
Il y a une quantité sérieuse de données à croiser, donc dans la figure suivante, il y a un pairplot qui croise toutes ces données et les filtre en fonction de l’Acorn_grouped.
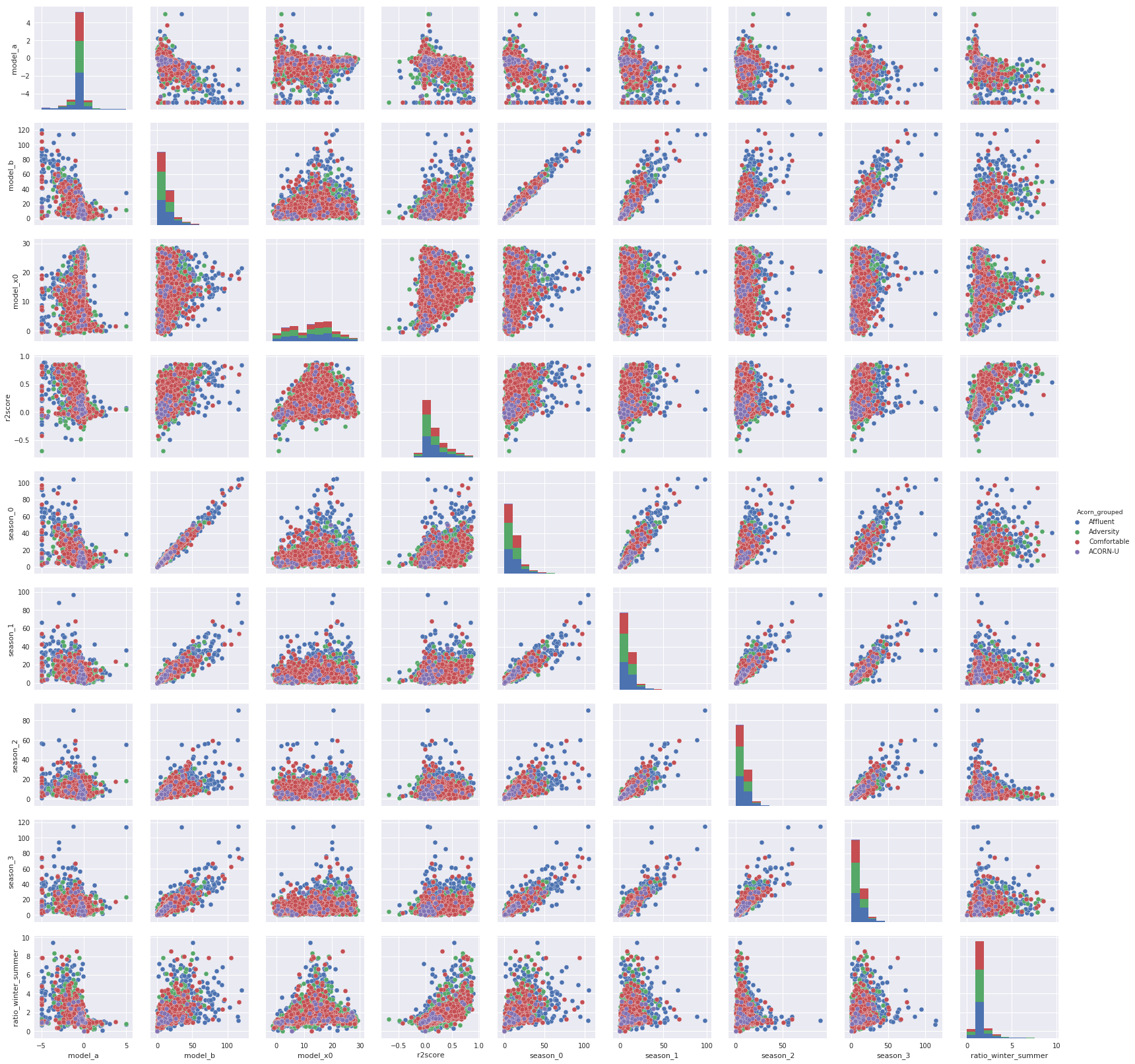
Notes: Il n’y a pas de relation évidente entre tous ces indices qui définissent les ménages sauf entre season_0 et model_b, mais ces deux sont liés à l’hiver donc c’est normal. Mais il n’y a pas de lien entre ces indices et l’Acorn_grouped, le résultat est similaire avec l’Acorn, ce qui est un peu décevant.

Prochaines étapes
Comme vous pouvez le voir, cette première exploration de l’ensemble de données a mis en évidence certaines caractéristiques de la consommation électrique à Londres comme l’influence de la météo dans cette consommation, mais il y a beaucoup plus de choses à faire sur cet ensemble de données. Quelques idées pour les analyses futures :
- Croiser les données ACORN et les données des compteurs intelligents
- Essayer de prévoir la consommation des différents ménages
- Ajouter de nouveaux ensembles de données comme :
- Les données EPC de Londres
- Des données supplémentaires sur Londres comme des grèves du métro ou des trains pendant la période
- Faire des regroupements dans les données des ménages et les profils énergétiques, comme vous pouvez le voir dans la carte thermique suivante, il y a un “motif” dans la consommation totale de ces ménages.
Vous pouvez trouver tout le code pour faire cet article dans ce dépôt GitHub
Références
- Compteurs intelligents de Londres (Kaggle) — Kaggle
- London Data Store jeu de données compteurs intelligents — data.london.gov.uk
- Groupe ACORN — acorn.caci.co.uk
- API Dark Sky — darksky.net
- Dépôt london_smartmeter — GitHub
- API open data EPC — epc.opendatacommunities.org