
Web scraping et analyse des données des Opens de Crossfit
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Bonjour dans cet article, je vais donner quelques pistes sur comment créer un système de web scraping qui a été utilisé pour collecter des données du site web des jeux Crossfit de Reebok
Introduction au Crossfit
Le Crossfit est défini comme
un programme de force et de conditionnement physique consistant principalement en un mélange d’exercice aérobie, de callisthénie (exercices au poids du corps) et d’haltérophilie olympique
Ce programme semble avoir été inventé dans les années 2000 par Greg Glassman et Lauren Jenai, et le sport est sous licence au nom de CrossFit, Inc.
Je vous invite à regarder quelques vidéos sur la chaîne Crossfit Inc sur YouTube pour avoir une meilleure vue de ce que pourraient être les exercices à faire pendant une séance.
Dans mon cas, je pratique le crossfit depuis août 2017, trois fois par semaine et j’aime ça. Honnêtement, quand j’ai commencé, je regardais ce sport comme des brutes qui faisaient des exercices de gym à haute intensité.
Plus sérieusement, j’avais un peu peur de l’intensité des exercices qui de mon point de vue pouvaient blesser les gens assez gravement, mais ce sport est fait pour tout le monde. Pas besoin d’être Superman pour pratiquer le crossfit.
La force, c’est que chaque exercice peut être adapté en termes de poids et de mouvement en fonction de vos besoins (condition physique, blessures) mais le seul objectif est de terminer l’exercice. Ne jamais abandonner pourrait être la devise du crossfit.
La sélection pour le championnat de la coupe du monde est assez simple, il y a 3 phases dans le processus :
- Les Opens, tout le monde peut participer à cette qualification, les divisions sont définies par âge et par sexe et si vous n’êtes pas dans une salle de sport affiliée qui peut valider votre performance, vous pouvez la filmer et l’envoyer aux organisateurs.
- Les Regionals, où les meilleurs des Opens se battront pour être sélectionnés pour les Games
- Les Games, la coupe du monde
Pour cet article, la collecte de données ne concernera que les données Open 2018 qui peuvent être trouvées à cette adresse. Les Opens sont définis par :
- Une période de 5 semaines, où chaque semaine un nouveau WOD (workout of the day) est annoncé
- Il y a 4 jours pour essayer de faire le meilleur score sur le WOD
Alors pourquoi je veux utiliser ce cas pour mon introduction au web scraping :
- J’ai lu un article cool sur le scraping du site web des jeux Crossfit
- J’ai trouvé la présentation du classement assez limitée en termes de comparaison
- Je voulais faire un exercice de web scraping depuis longtemps
Alors plongeons dedans.
Web scraping 101
Dans ce cas, j’ai décidé de scraper les éléments suivants :
- les pages de classement pour cet article, nous travaillerons uniquement sur le résultat de 2018, mais si vous voulez l’approche pour l’année précédente, je vous invite à regarder cet article sur le sujet
- les pages des athlètes, parce que chaque athlète a une page avec des informations intéressantes
- les pages des salles de sport qui contiennent des détails sur l’emplacement de la salle de sport
Pour collecter les données de ce site web, j’ai utilisé le package appelé Beautiful Soup, qui est assez populaire pour le web scraping en Python. Dans les sections suivantes, il y aura une description des données collectées et du code associé.
Vous pouvez trouver toutes les fonctions expliquées dans cette partie dans ce dépôt GitHub.
Le classement
Il n’y a pas vraiment besoin de scraper la page web, l’API qui est utilisée par le frontend peut être appelée directement par une simple requête GET. Merci à @pedro de l’avoir remarqué. Il suffit de mentionner dans la requête :
- Le code de la division
- Si le classement concerne les athlètes scaled ou non-scaled
- La page de l’API (que vous pouvez obtenir de la requête de la première page)
Voici la requête à exécuter.

Les pages des athlètes
Dans ce cas, la page de l’athlète ressemble à la capture d’écran dans la figure suivante

Et ensuite au bas de la page, il y a quelques benchmarks pour certains exercices.

Donc j’ai décidé de scraper la page pour tous les athlètes qui ont participé aux Opens au cours des 5 dernières années et cela représente plus de 700 000 pages à scraper. Pour optimiser la collecte, j’ai décidé de paralléliser le processus et j’ai utilisé le code suivant pour obtenir les données d’une page.
Les pages des salles de sport
Dans le cas de la page de la salle de sport, la quantité d’informations à collecter est moins importante que pour les athlètes. Dans la figure suivante, il y a une capture d’écran de la page d’une salle de sport.
Le script se concentrera sur les détails dans l’en-tête de la page, qui concernent l’emplacement. Le nombre de pages à scraper dans ce cas est d’environ 10 000 pages, et le code suivant a été utilisé pour faire cela.
Éthique derrière le processus
Comme vous l’avez lu, il y a beaucoup de données qui ont été collectées par mon système, la question est Est-ce légal ou non ?
Si je me réfère à la croyance commune, c’est sur internet donc c’est gratuit, c’est bon, eh bien il semble que ce soit plus compliqué que ça. Si je me réfère à cet article, il semble que j’ai fait quelque chose d’illégal parce que je n’ai pas respecté les conditions d’utilisation du site web, donc j’ai décidé de contacter Crossfit Inc pour les avertir de ce que j’ai fait et obtenir leur retour là-dessus (j’ai contacté l’organisation via leur formulaire et quelques adresses e-mail liées à la confidentialité, etc.).
29 avril 2018 : Je n’ai pas de retour d’eux sur ce sujet.
De mon point de vue, je pense que c’est sûr tant que je n’ai pas publié d’informations personnelles sur les athlètes et vendu l’ensemble de données, mais qui sait ?
Jetons un coup d’œil à quelques aperçus globaux de l’ensemble de données.
Vous pouvez trouver toutes les fonctions expliquées dans cette partie dans ce dépôt GitHub.
Aperçus sur l’Open 2018
Aperçu
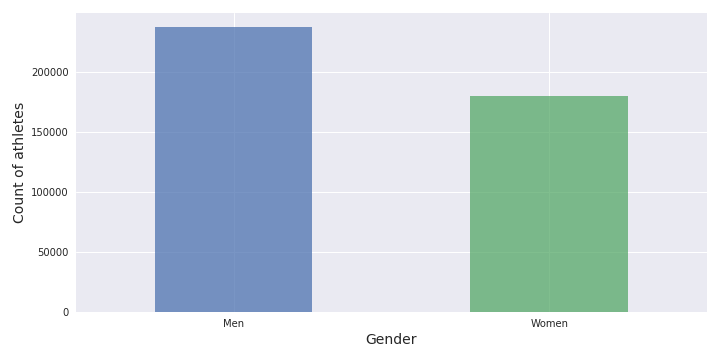
Dans cette partie, ce sera principalement un aperçu très général de l’événement Open. L’analyse commencera par la distribution par sexe.
Il est bon de voir qu’il y a un nombre assez similaire d’hommes (56,8%) et de femmes (43,2%) (similaire à ce que je peux voir pendant mon entraînement) qui étaient engagés dans l’Open. Voyons maintenant la distribution de l’âge.

La distribution de l’âge est assez similaire entre les sexes, les athlètes ayant un âge supérieur à 60 ans sont considérés comme des valeurs aberrantes. Un autre point à noter est que l’âge moyen des athlètes est supérieur à 30 ans. Cela pourrait être peut-être la marque de :
- Besoin d’expérience pour participer à l’Open (mais je ne parierais pas là-dessus)
- Le prix pour être membre d’une box est trop élevé
- La notation vidéo n’est pas très bien promue
Le graphique de distribution suivant est une bonne illustration de cette segmentation d’âge.

Ceci est l’illustration de la segmentation par âge qui peut être liée au revenu. Voyons maintenant les données des athlètes.
Analyse des athlètes
J’ai utilisé pour cela une partie des données des pages des athlètes. J’ai filtré les données aberrantes qui ne respectent pas l’IMC (Indice de Masse Corporelle) qui ne sont pas entre 13 et 83, et certaines valeurs de poids et de taille incorrectes. Il y a une visualisation de la morphologie.

Le physique général de l’athlète semble être :
- Un poids autour de 80 kg
- Une taille autour de 180 cm
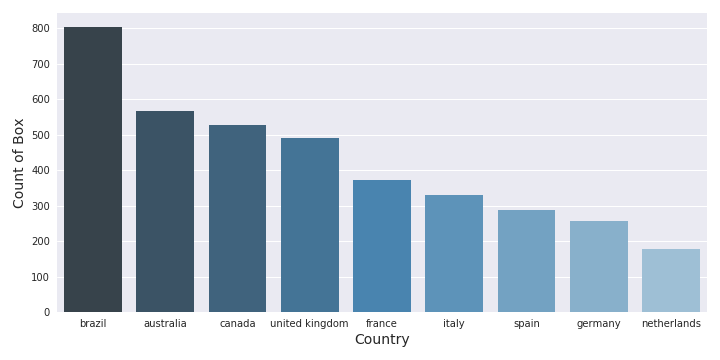
En termes de distribution par pays, les États-Unis sont en tête. Dans la figure suivante, il y a un décompte du nombre d’athlètes engagés dans l’événement aux États-Unis et dans les 10 premiers autres pays.

Je pense qu’il n’y a pas de commentaire à faire sur la popularité du crossfit aux États-Unis. Si je zoome sur les autres pays, il y a des aperçus intéressants. Dans la figure suivante, il y a plus de détails sur les 10 premiers pays (en termes de nombre d’athlètes) sans les États-Unis.

Comme nous pouvons le voir :
- Il y a un énorme écart entre les États-Unis et le deuxième pays (comme 200 000 athlètes)
- Le deuxième pays avec le nombre le plus important d’athlètes n’est pas un pays, c’est l’association de tous les athlètes qui filmaient simplement leur WOD
- Un intérêt clair des athlètes au Brésil et dans une partie du Commonwealth
- Le nombre d’athlètes engagés en Europe est moins important
Voyons maintenant quelques détails sur les salles de sport qui notaient les athlètes.
Analyse des données des salles de sport/box
Donc pour être clair, les États-Unis ont un nombre important de salles de sport/athlètes engagés dans l’événement. Dans ce qui suit, il y a une comparaison entre le nombre de salles de sport aux États-Unis et le nombre de salles de sport dans les 9 autres pays avec plus de salles de sport engagées.

Les États-Unis écrasent littéralement les autres pays. Dans la figure suivante, il y a une illustration du nombre de salles de sport dans les autres pays.

Nombre de salles de sport dans les autres pays du top 10
Il est intéressant de voir que (il y a beaucoup de similitudes entre le nombre d’athlètes et le nombre de salles de sport, ce qui est normal) :
- Le Brésil a un nombre important de salles de sport
- Le Commonwealth (Canada, Royaume-Uni, Australie) est présent
- La France est en tête de l’Europe dans le classement (mais l’Italie est proche)
Je peux continuer à faire beaucoup de graphiques avec ces données, donc j’ai décidé de créer un tableau de bord interactif que je peux faire évoluer facilement à tout moment et pour cela j’utiliserai Tableau
Tableau de bord sur Tableau Public
Tableau Public est un service qui a été développé par une entreprise en 2003 à Mountain View basé sur le travail de l’Université de Stanford (VizQL). L’entreprise a été introduite en 2013 au NYSE et comptait 2400 employés (chiffre de 2015).
Il existe différents produits développés par Tableau, mais l’objectif de cet outil est de faciliter l’échange d’informations sur les données à travers l’entreprise par la création et le partage de tableaux de bord.
Je vous invite à jeter un coup d’œil à leur site web pour avoir plus de détails sur les produits. Pour ce projet, j’ai utilisé Tableau Public pour créer le tableau de bord suivant.
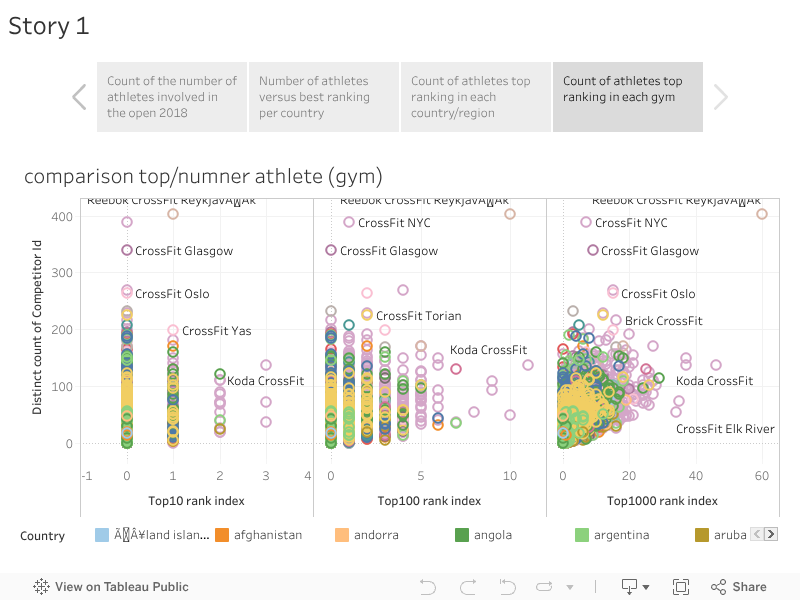
Tableau de bord Tableau
Pour finir, je voulais aller plus loin sur les données et me concentrer uniquement sur les exercices benchmark, pour essayer de trouver une connexion entre eux.
Relation entre les exercices
Pour analyser les données, j’ai dû éliminer les valeurs aberrantes, donc pour faire cela, j’avais le choix :
- Utiliser le DBSCAN pour détecter les valeurs aberrantes après normalisation des données (efficace mais un peu long à appliquer sur tous les athlètes avec les données)
- Utiliser l’approche statistique basée sur le quantile et supprimer les valeurs qui étaient en dessous de la limite du quantile de 5% et au-dessus du quantile de 95%
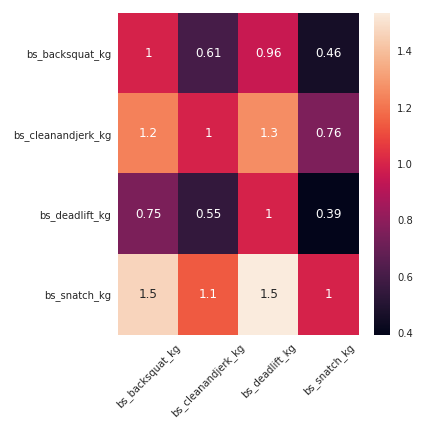
J’ai visuellement trouvé une certaine corrélation entre les exercices, comme la figure suivante illustre la relation.

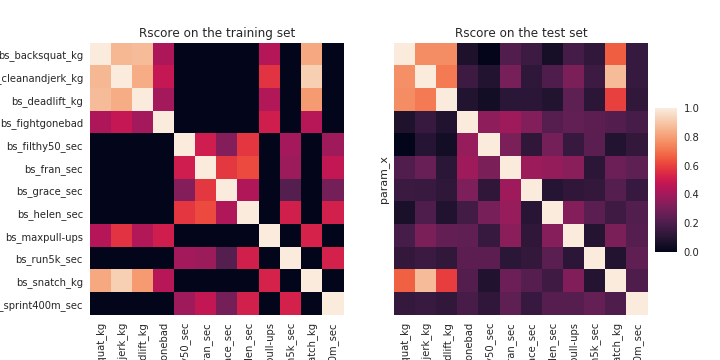
Donc je voulais appliquer la recherche de corrélation (une relation linéaire) à tous les exercices. J’ai appliqué un modèle linéaire sur 1 000 athlètes, et j’ai testé le modèle sur 250 athlètes pour voir si le modèle était assez bon. J’ai utilisé le score r comme indice pour évaluer l’efficacité des modèles.
Sur l’ensemble d’entraînement, les exercices qui impliquaient de porter du poids étaient fortement corrélés les uns aux autres, les exercices qui impliquaient une durée montraient une corrélation qui était moins importante. Lorsque les modèles ont été appliqués à l’ensemble de test, la corrélation pour les exercices de poids était encore bonne, mais les exercices avec le temps étaient définitivement en surapprentissage sur l’ensemble d’entraînement. Dans la figure suivante, il y a une illustration du modèle linéaire pour les exercices associés au poids.
Pour avoir une meilleure idée de l’impact d’une modification de poids sur un exercice, j’ai créé une table qui fait la conversion pour une modification de poids d’un exercice à un autre.
Conclusion et prochaines étapes
Ce projet était super intéressant, le scraping d’un site web est définitivement très pratique pour collecter des données, et il y avait des aperçus à obtenir de cet ensemble de données (par une analyse rapide).
Les prochaines étapes pour ce projet sont :
- Créer un ensemble de données Kaggle (si Reebok est d’accord)
- Créer une sorte d’API qui utilisera ces données pour donner des conseils d’entraînement
- En se basant sur les photos disponibles sur les profils des athlètes, comme l’âge et le sexe sont corrects, créer un modèle pour déterminer à partir du visage de quelqu’un son sexe et son âge (plage d’âge)
- Ajouter plus de données historiques à la table (j’ai scrapé les 5 dernières années mais le format des données passées est un peu différent) et peut-être ajouter des données des regionals et des games
- Améliorer et créer d’autres tableaux de bord
Références
- Site web des Crossfit Games — games.crossfit.com
- My first battle with web scraping — Medium / Towards Data Science
- Beautiful Soup — crummy.com
- Dépôt crossfit_webscraping — GitHub
- Web Scraping and Crawling Are Perfectly Legal, Right? — benbernardblog.com
- Tableau — tableau.com