
PUBG - Faire des analyses avec AWS et plotly
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Pour cet article, je vais commencer l’analyse des données extraites avec le pipeline expliqué dans cet article. L’objectif de cet article est de :
- Obtenir une introduction à AWS athena
- Obtenir des informations sur les données en utilisant plotly
- Mieux comprendre la consommation du jeu vidéo PUBG
Rappel sur PUBG
PUBG est l’un de ces jeux qui est défini comme battle royale, où le principe est qu’il y a X personnes (ou squads) qui sont larguées sur une île, l’objectif est d’être le dernier survivant sur l’île en utilisant les objets, les armes qui sont déployés aléatoirement sur l’île. Et pour augmenter la tension dans le jeu (et lui donner une fin), la partie de la carte disponible diminue régulièrement pour pousser les joueurs à se battre pour leur vie.
En termes de gameplay, il y a plusieurs îles disponibles (chacune avec son propre environnement comme désert, neige) , et vous pouvez jouer dans différents modes (solo, duo, squad) et parfois la caméra peut être prédéfinie (fpp pour first person player uniquement ou caméra première/troisième personne)
Côté technique
Aperçu d’Athena
Athena est le service développé par Amazon pour donner la possibilité à quelqu’un d’interroger facilement des données d’un bucket S3 sans utiliser de serveurs ou de data warehouses. Il y a un exemple de l’interface pour utiliser Athena sur un navigateur web.
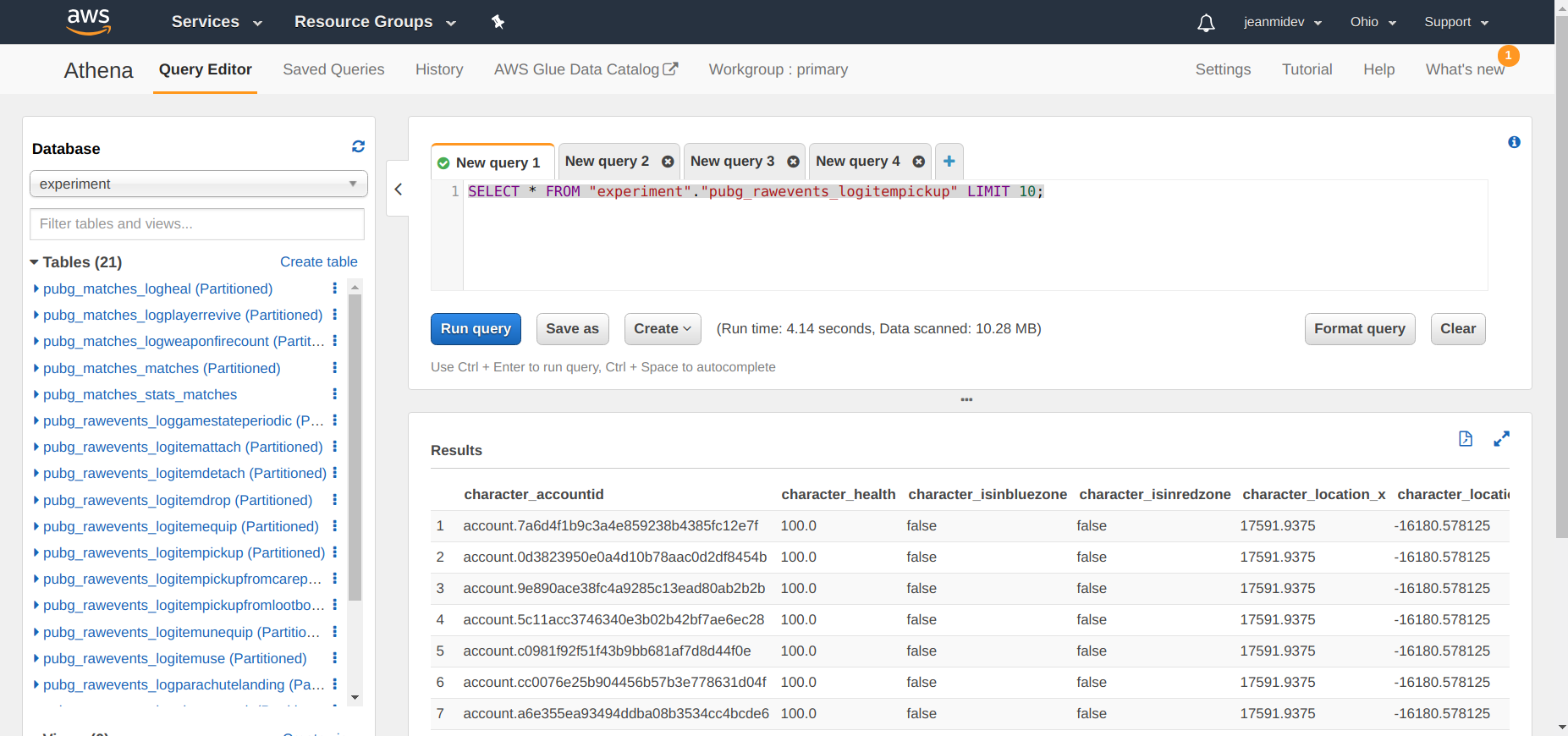
Le système développé est assez ouvert en termes de format de données qui peut être utilisé : CSV, JSON, ORC, Avro et Parquet.
Le cœur du système est construit sur Presto qui est défini comme un moteur de requête SQL distribué open source. L’un des principaux utilisateurs de ce projet est Facebook sur divers sujets autour des analyses interactives, ETL par lots, tests A/B et analyses de développeurs publicitaires.
Il y a un bon article sur Presto qui entre plus en détail sur toute la machinerie du moteur.
Certains autres gros utilisateurs de cet outil sont Netflix et Airbnb qui construisent des services autour de ce type de système.
Si nous revenons au service Athena, le système serverless est intéressant car la facturation est basée uniquement sur les données scannées. Donc vraiment ce combo S3 + Athena est un bon mélange pour les personnes qui veulent gérer un volume de données qui peut être considéré comme “big” sans gérer toute l’infrastructure (qui est un travail à temps plein).
Pour connecter AWS Athena à un script python, il y a un package pyathenajdbc qui peut être installé et qui installera un connecteur qui peut être utilisé dans un dataframe pandas. Il y a un exemple de script pour connecter les données.
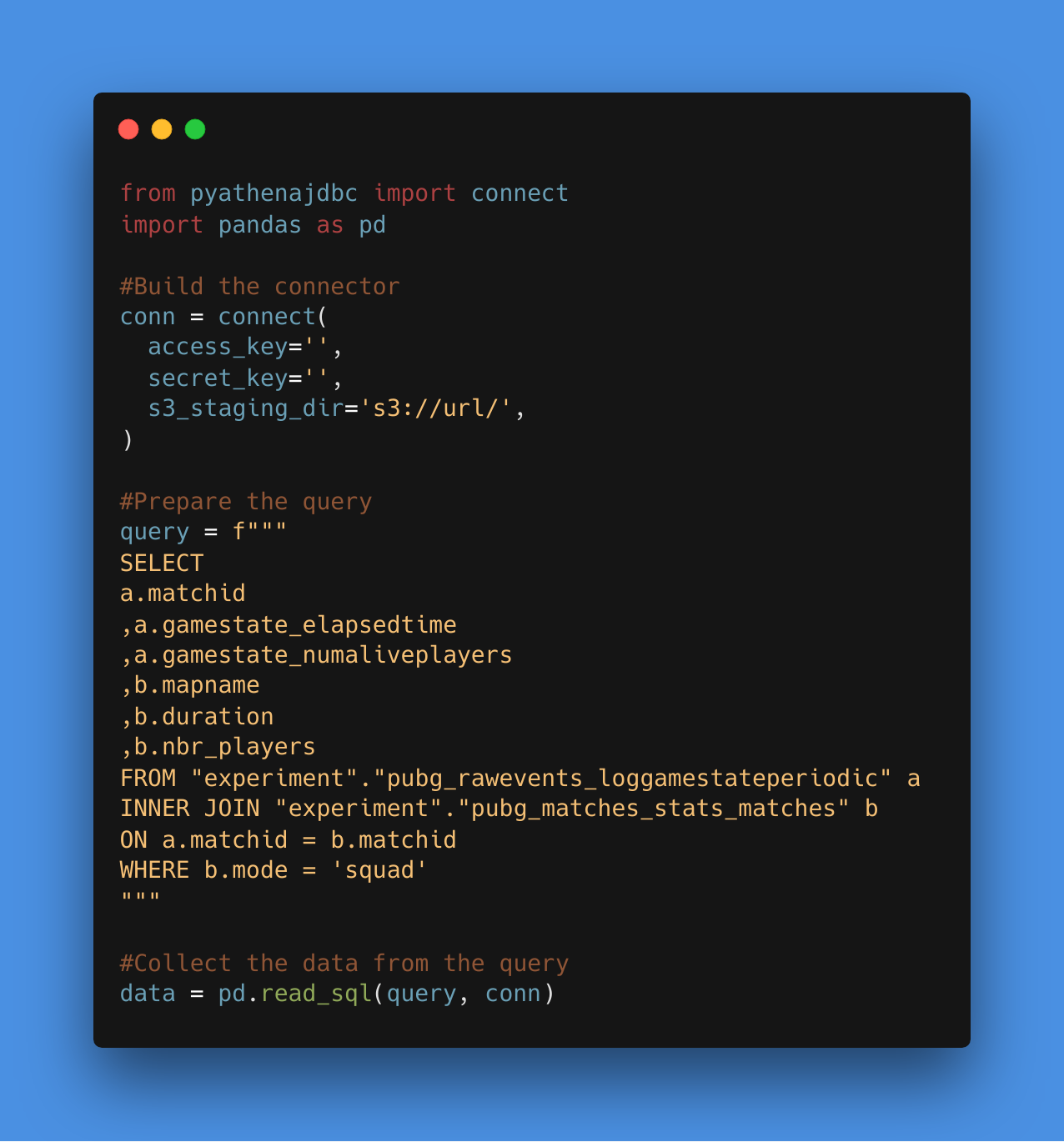
Le code est assez simple et ressemble à un appel à une base de données postgreSQL classique. Pour être vraiment transparent en termes de coût, il y a un graphique avec le coût pour l’expérience.
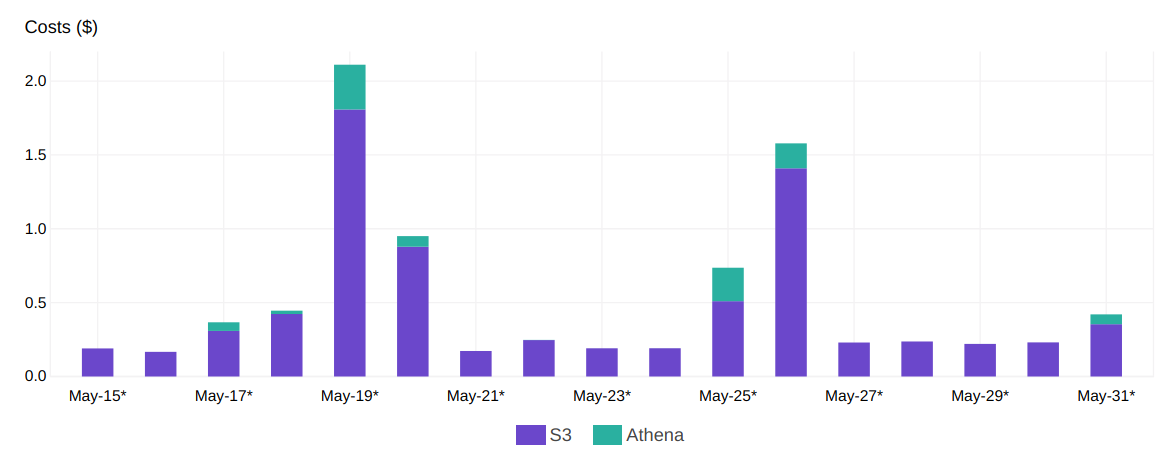
Le montant réel est celui qui provient de la lecture S3 et de l’activation d’Athena et c’est moins de 2$ par jour d’analyse (qui sont juste 4 pour cette expérience).
Commençons l’analyse des données associées à PUBG.
État des données collectées
Le pipeline a tourné pendant plus d’un mois entre le 26 janvier 2019 et le 5 avril 2019, cette période de temps représente environ 69000 matchs donc c’est un volume de données assez intéressant à gérer (avec la quantité d’événements collectés pendant le match).
En termes de zone et de plateforme, le pipeline était concentré pour extraire les données de la plateforme PC en Amérique du Nord.
Je vais me concentrer sur 3 événements pour cette analyse :
- Le gamestat periodic, qui représente environ 11 000 000 de lignes
- Le player kill, qui représente environ 7 000 000 de lignes
- Les items used, qui représentent environ 19 000 000 de lignes
Plotly et co
Je suis un assez grand fan de la bibliothèque plotly. J’ai fait un article l’année dernière sur un package python de type Shiny appelé Dash alimenté par plotly, c’est vraiment un package cool qui rend la construction de tableaux de bord plus facile en Python.
Le package a été développé par la société Plotly qui est basée à Montréal dans le Mile End donc nous sommes littéralement voisins (vraiment comme 4 minutes de marche).
Le package original est une bibliothèque vraiment cool qui est gratuite pour faire des graphiques interactifs basés sur D3.js, ils offrent la possibilité de déployer sur leur chart studio les graphiques qui sont produits (la version gratuite vous offre la possibilité d’héberger 25 graphiques sur leur plateforme mais avec un compte premium vous pouvez héberger plus de graphiques/données)
En termes d’utilisation, la syntaxe originale est un peu “lourde” donc il y a des personnes qui ont développé des wrappers pour faciliter la construction d’un graphique dans un style plus one liner :
- Cufflinks développé par Jorge Santos (et de nombreux contributeurs)
- Plotly express développé par Plotly eux-mêmes
Pour cet article, je n’ai utilisé que cufflinks mais je prévois de faire d’autres articles qui utiliseront plotly express.
PUBG sous différentes perspectives
Données extraites
Pour être honnête, il y a plusieurs sites web qui ont fait des analyses similaires comme PUBGmap.io mais il est toujours intéressant de faire différentes analyses et de faire des comparaisons.
Il y a une représentation des matchs collectés basée sur la carte et le mode.
Le mode le plus populaire est le mode squad, et la carte est Savage. Pour les analyses suivantes, je vais me concentrer sur le mode squad.
Durée des matchs
En termes de durée, j’ai pris un échantillon des matchs (1000 matchs) pour chaque carte et il y a quelques boxplots.
La carte Savage semble avoir un comportement différent sur la durée, qui pourrait être expliqué par la taille qui est beaucoup plus petite que les autres (il y a comme un différentiel de 5 minutes pour la médiane).
Évolution des matchs
Pour la durée de vie des joueurs, dans la figure suivante il y a la représentation du pourcentage de joueurs vivants VS l’achèvement du match en fonction de la carte.
Au début du match, la plupart des joueurs restent en vie, ce qui est lié au moment de l’atterrissage de tous les joueurs sur la carte. En termes d’évolution des joueurs vivants, la carte ne semble pas avoir la même évolution jusqu’à la fin, la carte semble être “plus douce” que l’autre, Erangel et dihorotok sont très similaires et Savage est celle qui semble la plus violente (et cela peut s’expliquer par le format de la carte).
Usage des armes
En termes d’armes utilisées pour tuer, il y a la distribution du nombre de kills par arme pendant la période.
Il y a plusieurs types d’armes dans le jeu, des pistolets, fusils, fusils de chasse ou arbalètes, mais la plus populaire est l’AK47, et il y a beaucoup de fusils dans le top des armes.
Une autre donnée vraiment intéressante de l’événement kill est la localisation sur le corps du tir final, dans la figure suivante il y a la répartition pour chaque arme de la localisation du tir final.
La portion de headshots est différente en fonction de l’arme, les pistolets semblent beaucoup moins précis pour faire des headshots que les fusils (et cela a du sens)
Une autre information intéressante est que certaines armes semblent être spécifiques à une carte, dans la figure suivante il y a une distribution des armes par carte.
Usage des objets de support
Pour conclure, j’ai décidé d’avoir un aperçu de l’utilisation des objets de soin et de booster dans le jeu, il y a dans la figure suivante l’évolution des événements pour utiliser un objet de soin et un objet de booster en fonction de l’achèvement du match.
Pour le booster, il y a définitivement un pic autour de 40% du match, mais pour l’objet de soin il y a un premier bump dans les 15% qui se réfère à la première vague de joueurs éliminés, le pic est au milieu du match avec une deuxième phase d’élimination.
Conclusion
Cet article était une introduction à plus de travaux que je vais faire avec les données collectées de PUBG, je vais donner un focus dans un futur article sur PUBG sur les données de position, ce dataset représente environ 500 000 000 de lignes donc cela va être plus intéressant.
Références
- Presto — GitHub
- Presto: Interacting with petabytes of data at Facebook — facebook.com
- Presto: SQL on Everything — research.fb.com
- Metacat: Making Big Data Discoverable and Meaningful at Netflix — Medium / Towards Data Science
- Airpal (Airbnb) — airbnb.io
- PyAthenaJDBC — pypi.org
- D3.js — d3js.org
- Cufflinks — GitHub
- Introducing Plotly Express — Medium / Towards Data Science