
Retours et découvertes sur RecSys 2020
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Dans cet article, il y aura une description de la conférence Recsys qui s’est déroulée en septembre 2020 virtuellement (Merci Ubisoft de m’avoir offert la possibilité d’y assister 😀). Le contenu de cet article est divisé entre :
- Aperçu
- Sélection d’articles
- Défi Recsys
Aperçu
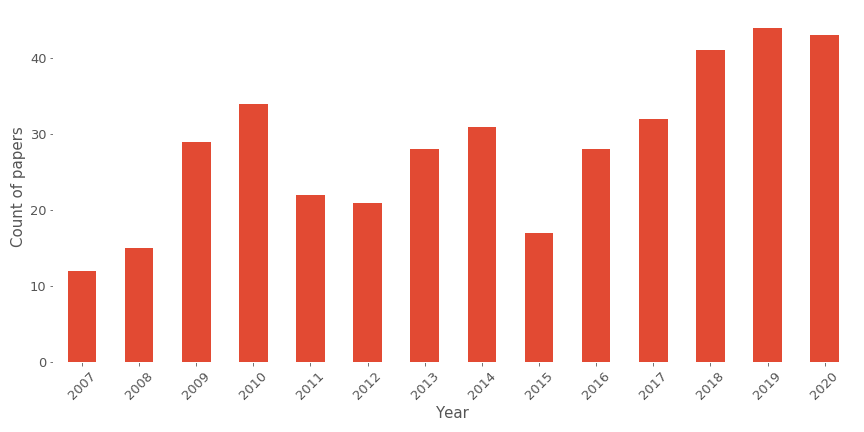
Recsys fait partie de la conférence ACM (Association of computing machinery) et est définie comme LA conférence sur les systèmes de recommandation dans le monde. De nombreuses grandes entreprises technologiques sponsorisent ce genre d’événement, de Netflix à Google, et généralement, l’emplacement de l’événement alterne entre l’Europe et l’Amérique. Pour l’édition 2020, la conférence aurait dû avoir lieu au Brésil, mais grâce au Covid, elle est passée à une édition virtuelle. La conférence a commencé en 2007, donc c’était la 14e édition. La conférence est assez classique avec un mélange entre articles longs, articles courts, posters, tutoriels et ateliers, et en termes d’acceptation d’articles longs, il y a 21% des articles soumis qui sont sélectionnés.
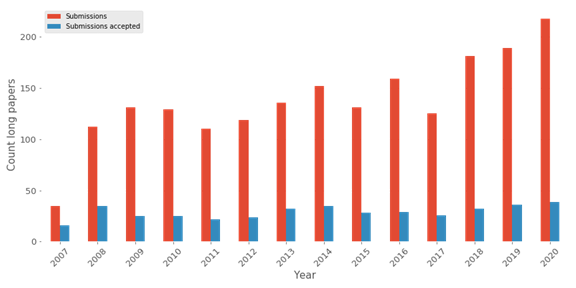
Cette figure donne une bonne vision du gain de popularité de la conférence avec une augmentation des soumissions. Néanmoins, dans l’ensemble, si nous considérons tous les articles présentés lors de cette conférence, il y a une augmentation (cf figure suivante).
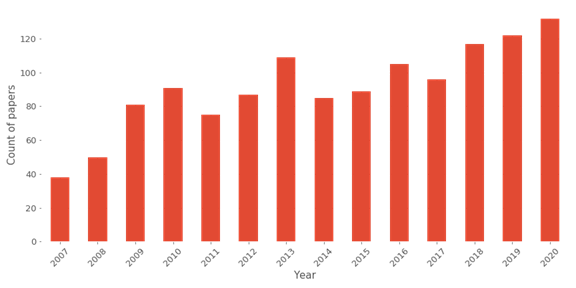
Chaque année, les pistes de la conférence évoluent, et cette année, voici les principales pistes présentées :
- Applications du monde réel (III)
- Évaluation et explication des recommandations
- Nouvelles approches de machine learning (III)
- Équité, bulles de filtres, préoccupations éthiques.
- Évaluation et recommandation sans biais
- Compréhension et approches de modélisation
Les sujets sont très différents, mais j’aime qu’ils aient des pistes d’application du monde réel (avec trois sessions).
Donc, comme nous pouvons le voir dans le graphique, il y a environ 130 articles sur l’édition, je ne vais pas résumer tous les articles, mais il y a des sélections d’articles que je trouve assez attractifs.
Sélection d’articles
Je vais juste tirer sur cette section 9 articles que je trouve intéressants et connectés aux autres.
Behaviour-based Popularity Ranking on Amazon Video
Cet article, écrit par Lakshmi Ramachandran d’Amazon Video, est une bonne illustration que l’article le plus populaire est une excellente approche de personnalisation, mais mettons ça sous stéroïdes. La configuration pour Amazon Video pour que les gens naviguent dans le contenu est d’utiliser la barre de recherche ou la section de découverte.

L’idée de l’article est : Basé sur toutes les données d’interaction de nos utilisateurs et les informations liées aux émissions, comment pouvons-nous prédire si les vidéos seront diffusées par les gens ?

Le prédicteur est construit avec un modèle basé sur des arbres. L’interaction sur les vidéos est pondérée avec l’utilisation de la date de téléchargement du contenu (les caractéristiques de l’article sont essentielles dans ce contexte car Amazon propose du contenu sportif en direct). Amazon a fait quelques expériences et a trouvé que son approche a boosté la diffusion du contenu et a eu un impact négatif sur le contenu non diffusable de la plateforme.
Balancing Relevance and Discovery to Inspire Customers in the IKEA App
Une autre grande tendance dans cette conférence recsys et les discussions passées était l’utilisation de bandit contextuel (et certaines approches RL en général) pour faire des recommandations de contenu (non directement liées aux fonctionnalités de monétisation d’une application) affichées. Ikea fait l’article qui nomme cette section, et c’est une bonne illustration de l’approche d’un bandit pour la recommandation d’images affichées.

L’un des défis rencontrés par cette approche est de trouver l’équilibre entre la pertinence des recommandations versus la découverte du contenu dans les articles qui peuvent être affichés. Dans le contexte d’Ikea, il semble que l’approche apporte un bon impact sur le clic avec une augmentation de 20% contre une approche de filtrage collaboratif classique (pourquoi pas, je suis toujours intrigué par les stats car pour faire une approche CF, vous avez besoin d’au moins une interaction contre un bandit où nous pouvons afficher des trucs au hasard et l’article est assez flou donc…).

From the lab to production: A case study of session-based recommendations in the home-improvement domain
Cet article est l’un des meilleurs articles de la conférence car il offre le point de vue des applications du monde réel que je peux rencontrer chez Ubisoft ; il a écrit par une entreprise (relational AI) que je présume fait de la consultance ML pour Home Depot, et ils essaient de construire un système de recommandation basé sur la session avec un modèle séquentiel, c’était l’occasion de découvrir beaucoup de nouveaux modèles.
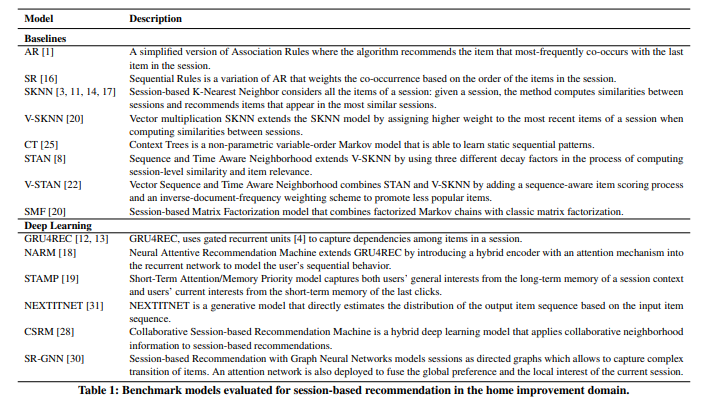
Et j’aime leur façon d’évaluer le modèle hors ligne avec l’ajout d’experts humains dessus pour voir si les recommandations produites ont du sens et sont assez bonnes. À lire absolument si vous voulez mon avis dessus.
On Target Item Sampling in Offline Recommender System Evaluation
Cet article offre une bonne question sur l’évaluation du modèle hors ligne en appliquant un filtrage pour prédire la sortie. Cette situation peut se produire car, pour certains problèmes d’évolutivité/contraintes de temps, vous devez prendre des décisions, et cela peut arriver. Rocío Cañamares qui est l’un des auteurs de l’article et présentatrice pendant la conférence a fait un test sur les movie lens et a illustré l’impact de l’échantillonnage de la sortie à prédire.
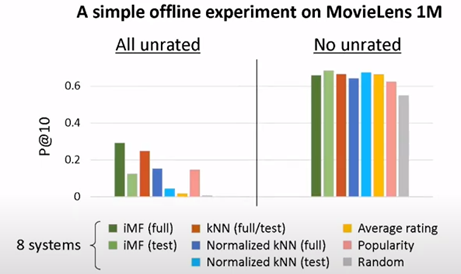
Pour moi, le fait de réduire le pool d’articles aura un impact direct sur le modèle (algorithmes et paramètres), mais ce que j’aime dans cet article, c’est la façon de comparer l’effet du jeu de données utilisé pour l’entraînement sur tous les modèles. Ils utilisent le score de Kendall pour atteindre le classement du modèle versus le jeu de données (illustration du jeu de données).
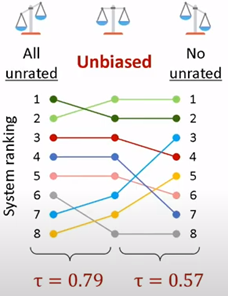
Un autre aspect de l’évaluation du modèle et de leur exécution est pour une interaction spécifique sur l’ensemble de test ; certaines métriques traditionnelles sont calculées comme le MAP@k ou le NDCG@k sur chaque enregistrement de l’ensemble de test, donc l’idée est de comparer chaque modèle du classement combien de fois il y a des égalités sur les enregistrements et l’évaluation.
Are We Evaluating Rigorously? Benchmarking Recommendation for Reproducible Evaluation and Fair Comparison
Comme d’habitude, à cette conférence, il y a beaucoup d’articles autour de l’évaluation, il y a une étude rapide sur les mots-clés dans les documents et le radical ‘evaluat’.
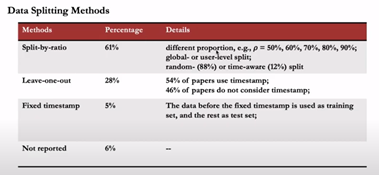
Mais cette année, il y a un bon aperçu de la pratique dans divers articles dans différentes conférences de :
- Le jeu de données
- les métriques
- Le modèle de référence
- la division du jeu de données



L’article est une sorte de méta-analyse sur la façon d’évaluer et de construire un pipeline pour comparer les modèles. L’une des sorties est que parfois ces articles peuvent être difficiles à reproduire, c’est pourquoi Zhu sun et ses équipes qui construisent cet article ont fait un framework qui peut aider à faire cette évaluation daisyREC. Honnêtement, le deuxième meilleur article de la conférence et même si à chaque itération de la conférence, certaines équipes font la même chose pour construire un framework d’évaluation, mais c’est toujours intéressant.
Investigating Multimodal Features for Video Recommendations at Globoplay
Cet article est fascinant car nous entrons dans l’article avec plus de R&D. L’objectif de cet article est fait par une équipe de Globoplay (un peu comme un grand réseau au Brésil, je l’appelle le Canal+ brésilien). Ils ont développé un système de recommandation pour le contenu (vidéos) basé sur des attributs de contenu.
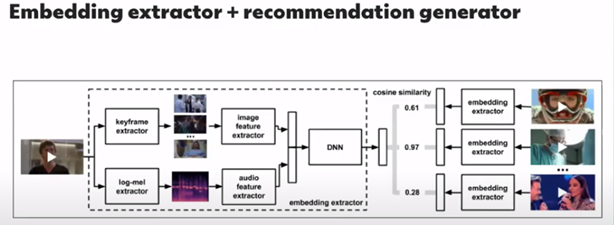
L’idée est d’analyser la vidéo et l’audio du contenu pour extraire certaines caractéristiques du contenu. Ils ont utilisé deux modèles pré-entraînés pour l’extraction de caractéristiques (c3d, sport1M pour la vidéo + VGG google audioset pour l’audio) pour construire ce générateur de caractéristiques. Un aspect passionnant du test du recommandeur était de faire la fausse interface utilisateur pour tester les recommandations produites par le créateur de contenu et l’utilisateur de la plateforme globoplay. Le modèle semble avoir été utilisé, et il semble avoir apporté une amélioration contre l’approche TF-IDF.

Quickshots
- The Embeddings that Came in From the Cold: Improving Vectors for New and Rare Products with Content-Based Inference
Toujours, le problème de démarrage à froid comme cela a été abordé dans l’article précédent, mais comment pouvons-nous recommander des articles qui sont rares dans un pool d’objets ? Cette équipe a développé un projet inspiré par word2vec cold prod2vec.

Le modèle utilisé derrière utilise des métadonnées et la popularité pour construire les recommandations, mais ce que j’aime, c’est la façon d’évaluer les recommandations (pas besoin de trouver les articles exacts, mais quelque chose de proche en termes de métadonnées suffit)
- Contextual and Sequential User Embeddings for Large-Scale Music Recommendation
Dans cet article sur Spotify, il y a une autre application de la prédiction de séquence de la prochaine chanson à jouer basée sur le moment de la journée et le type d’appareil utilisé.
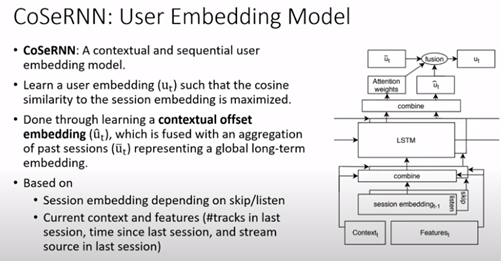
Le modèle peut générer des embeddings d’utilisateurs et est utilisé dans des recherches de voisins les plus proches.
- Neural Collaborative Filtering vs. Matrix Factorization Revisited
Dans ce dernier article de la sélection, il y a une comparaison de la factorisation matricielle classique versus le filtrage collaboratif neuronal pour produire des recommandations. Il était intéressant de comparer comment calculer la fonction de similarité (produit scalaire pour MF versus MLP pour NCF) ; MLP est vu comme une solution pour approcher toutes les fonctions. Néanmoins, le MLP ne semble pas faire un bon travail ou doit être très compliqué dans notre cas.

L’article n’est pas contre l’utilisation de NN en général, mais il souligne juste que cette technique qui semble très populaire n’est pas si optimale, donc à utiliser avec précaution.
Défis Recsys
Un autre composant important de la conférence RecSys est une compétition qui commence quelques semaines avant le sommet, mais le gagnant est plus ou moins couronné pendant cette conférence ; il y a un diagramme de l’un des hôtes de l’atelier autour du défi.
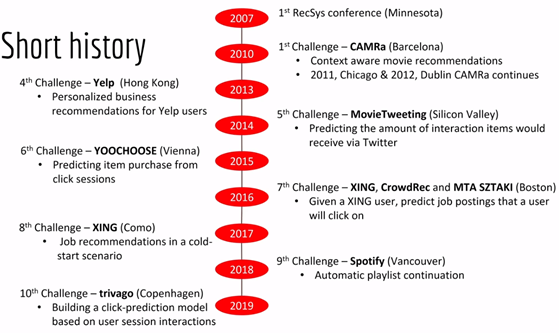
Le format de ce genre de compétition est une sorte de configuration classique d’une compétition Kaggle. Comme vous pouvez le voir en termes de fournisseurs de données pour chaque compétition, de grands noms de Yelp, Spotify, et récemment, Twitter était le fournisseur de données.
Une brève description de la configuration de la compétition passée montre un excellent article de l’un des organisateurs sur le problème à résoudre et les solutions gagnantes. Mais je vais quand même faire un résumé rapide du défi et quelques découvertes clés :
- Compétitions : prédire pour un utilisateur spécifique s’il va s’engager (retweeter, répondre ou aimer) avec un tweet basé sur son profil Twitter (lecteur), le profil Twitter de l’auteur
- La solution gagnante est du “GPU porn” avec la suite cool de Nvidia rapids, basée sur xgboost et de l’ingénierie de fonctionnalités de haut niveau (je dois écrire un article sur ces bibliothèques)
- Le deep learning ne semble pas bien performer en comparaison de la solution Nvidia.
- Une excellente approche pour évaluer son jeu de données et ses fonctionnalités est d’utiliser la validation adversariale pour éviter le surapprentissage.
Je suis super impressionné par les solutions développées. Je vous invite à jeter un œil aux 3 meilleures solutions dans l’article Twitter, mais il y a encore quelque chose à garder à l’esprit que cette approche n’est peut-être pas parfaite pour une inférence en direct (besoin de répondre en millisecondes), mais toujours une bonne connaissance qui peut être utile dans un contexte de prédiction par lots.
Pour conclure, les techniques de deep learning (DL) ne semblent pas bien performer, et il y avait une discussion. Donc la sous-performance de ces techniques sur le défi semble provenir de :
- Le format des données utilisées pour ce défi n’est pas aligné avec ce qui est nécessaire pour que les techniques DL performent bien. Habituellement, une fenêtre de temps spécifique de données est utilisée donc cela pourrait impacter l’entraînement.
- Un deuxième aspect est l’optimisation des hyperparamètres / la recherche de grille ; pour faire cela avec les techniques DL, c’est plus délicat qu’avec les techniques classiques. Cela prend plus de temps, donc ce n’est peut-être pas aligné avec une compétition (Kaggle ?)
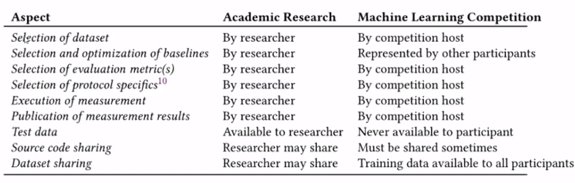
- Et la différence de configuration pour une compétition de défi et un article académique pourrait être une autre raison de sous-performance (il y a une représentation de la différence des configurations)
Conclusion
De cette conférence, il y a beaucoup de choses passionnantes que je garde à l’esprit :
- Les approches de bandit et de séquence prennent de la place.
- Les applications de jeux vidéo étaient un peu timides cette session (juste un article qui était un écho de quelques articles sur les conférences passées)
- Il y a beaucoup de nouvelles idées pour évaluer le modèle pendant la recherche de grille (score de Kendall) et le jeu de données (validation adversariale)
- Un manque de papiers sur les résultats d’expérimentation en direct (je peux comprendre que cela peut être difficile)
- L’expert (quelqu’un de non technique ML) dans certains projets semble avoir un impact sur la sélection du modèle par maquette de fausse interface utilisateur
- Construire un environnement de simulation pour tester les approches RL et non RL est une chose à faire
Références
- ACM — acm.org
- daisyREC — GitHub
- rapids — rapids.ai
- validation adversariale — Medium / Towards Data Science