
Lancer un projet big data avec AWS EMR et Pyspark
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Bonjour lecteurs, je voulais depuis longtemps écrire un article sur un service AWS que j’utilise dans mon travail quotidien appelé EMR. Ce service permet de “facilement exécuter et mettre à l’échelle Apache Spark, Hive, Presto et d’autres frameworks big data”. Dans cet article, je vais exploiter ce service sur un jeu de données open-source pour effectuer des tâches ETL et des analyses/prédictions simples avec Pyspark.
Configuration des données
Quoi de mieux qu’un jeu de données open-source d’Ubisoft pour cette expérience ? Il y en a un appelé data peek qui peut faire l’affaire. Je vais faire une brève description de la configuration, mais je vous invite à lire l’article expliquant les données plus en détail.
Les données utilisées pour ce projet proviennent du suivi du jeu Rainbow Six siege, un jeu de tir tactique en ligne à la première personne développé par le studio Ubisoft Montréal et sorti en décembre 2015 et toujours actif avec une communauté importante (le jeu a atteint 70 millions de joueurs il y a un mois). Cet article ne détaillera pas la structure du jeu Rainbow Six Siege (mais il ressemble à un jeu de counter strike avec des personnages appelés opérateurs ayant des capacités et équipements uniques). Mais je vous invite à regarder cette vidéo pour comprendre la logique.
De nouveaux contenus sont ajoutés régulièrement dans ce qu’on appelle une saison qui arrive tous les trois mois et apporte de nouveaux personnages, cosmétiques, cartes, modes (voici le plan pour l’année en cours 😄). Dans cet article, les données collectées se concentreront sur la saison 1 de la deuxième année, appelée operation velvet shell.

Dans cette saison, deux nouveaux opérateurs sont ajoutés ainsi qu’une nouvelle carte.
Au cours de la saison, plusieurs patchs (mises à jour dans le jeu pour ajuster/corriger certaines choses) ont été déployés (source) :
- Mise à jour 2.1.0 : Velvet Shell le 7 février 2017
- Mise à jour 2.1.1 le 21 février 2017
- Mise à jour 2.1.2 : Mid-Season Reinforcements le 15 mars 2017
- Mise à jour BattlEye le 18 avril 2017, pour PC
- Mise à jour 2.1.3 le 19 avril 2017
- Hotfix le 21 avril 2017, pour PS4
- Hotfix le 26 avril 2017, pour PC
- Hotfix le 28 avril 2017, pour consoles
- Maintenance le 2 mai 2017
- Hotfix le 10 mai 2017
Pour cet article, je me concentrerai sur le gros morceau de données (le fichier de 19 Go) contenant la configuration des matchs en mode classé.
Configuration EMR
Avec EMR, vous pouvez lancer très rapidement une flotte de machines appelée cluster pour utiliser des frameworks big data de manière efficace (la fameuse computation distribuée). Je suis plutôt utilisateur de Spark (pyspark for life) pour présenter ma configuration dans ce cas.
Il existe diverses versions d’EMR qui ont été publiées au fil du temps, mais actuellement, les deux branches principales sont :
- EMR 5.x
- EMR 6.x
Les deux principales différences entre les versions sont que la version de Pyspark sur la 6.x est la version 3 de spark, alors que sur la 5.x c’est encore la version 2.X de Spark. Attention, chaque version a ses avantages et inconvénients, donc gardez cela à l’esprit (par exemple, le type de fichiers gérés dans S3).
Pour ce cas, la version EMR 5.31.0 utilisée pour le test (j’ai essayé d’utiliser la 5.32, mais elle ne fonctionne pas très bien avec les notebooks EMR). Il y a une liste de logiciels installés sur les machines de travail.
Il y a beaucoup de logiciels possibles à avoir (même Tensorflow), mais dans mon cas, les plus utiles sont Spark, Hadoop.
Comme c’est principalement pour le test, j’utilise uniquement des machines m5.xlarge (un master et trois cores). La configuration est relativement petite, mais je n’ai pas besoin de plus (honnêtement, j’utilise cette approche, mais je suis sûr qu’une seule machine aurait suffi pour traiter ces données #showoff).
Pendant l’étape de configuration des machines, il y a l’option d’ajouter des paramètres de configuration pour les applications qui s’exécuteront sur ce cluster ; c’est appelé classification (vous pouvez trouver la mienne ici). Dans ce fichier de configuration, il y a :
- Une clé liée à l’accès au catalogue de données Glue pour construire et sauvegarder facilement des tables Hive (je l’expliquerai plus tard)
- La configuration Livy évite (ou au moins retarde) le fameux timeout de session d’application spark qui peut se produire si l’application Spark ne fait rien.
Vous pouvez modifier votre application lorsque le cluster est actif, mais avec cela, chaque fois que vous le lancez, tout sera prêt (petit conseil, si vous utilisez cette fonctionnalité, stockez le fichier dans S3, l’éditeur local n’est pas très pratique pour mettre à jour ce dictionnaire de configuration)
Un excellent ajout que je trouve très utile en tant que data scientist dans EMR est les EMR notebooks que vous pouvez attacher à un cluster pour exploiter le kernel spark dans un environnement jupyter/lab. Si le cluster se termine, tous les notebooks sont sauvegardés (avant j’utilisais le logiciel jupyterhub installé sur le cluster, c’est bien, mais si le cluster s’arrête, vous perdez tout).
L’un des atouts du notebook sur EMR est la capacité de configurer rapidement les bonnes bibliothèques nécessaires pour faire de l’exploration ; il y a une excellente ressource qui présente la manière d’utiliser cette fonctionnalité.
Maintenant que la configuration est simple, regardons la phase de traitement avant d’analyser les données.
ETL
Une phase de prétraitement doit être effectuée pour transformer les fichiers CSV en tables Hive. Pour démarrer cette étape de traitement, deux choses doivent être faites :
- Copier les fichiers CSV dans un bucket s3 (dans un sous-dossier spécifique)
- Construire une base de données qui pointera vers un autre emplacement s3 pour stocker les fichiers prétraités qui seront les données pour les tables hive.
Pour cette expérience, le format des fichiers composant la table hive sera parquet, mais il était possible de stocker dans d’autres types. J’ai utilisé le notebook pour construire les tables, et ces nouvelles données sont accessibles depuis d’autres services comme AWS Athena.
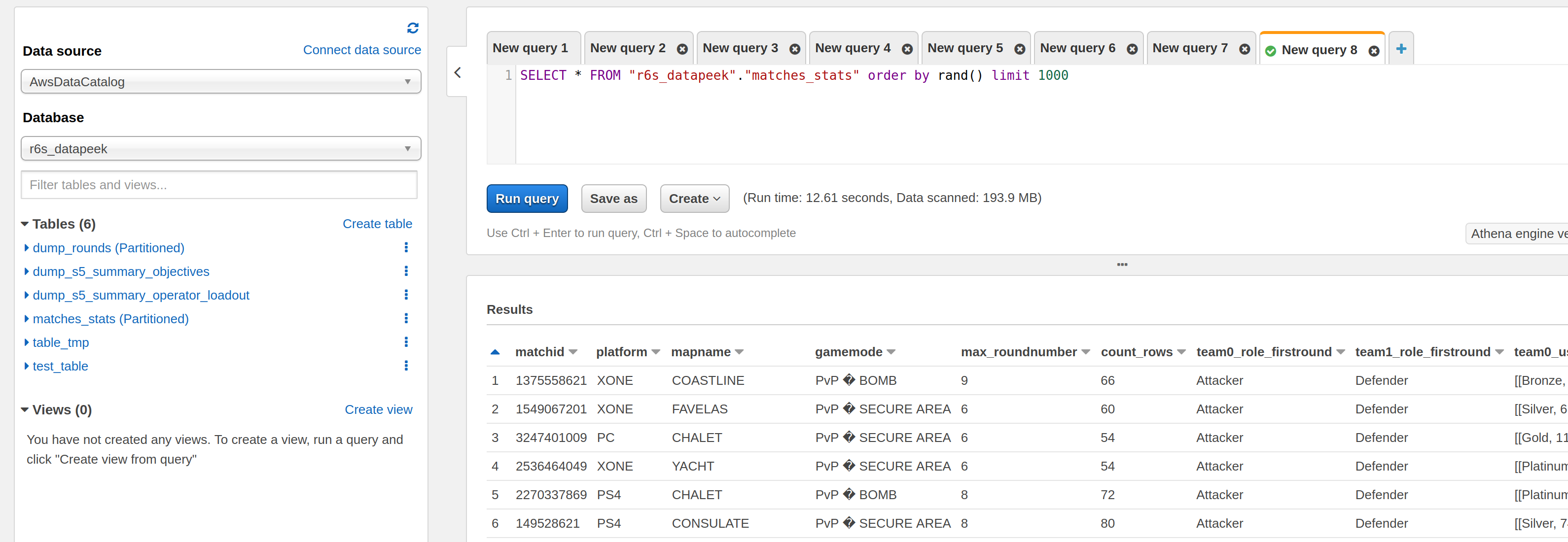
La table contenant les informations des joueurs est partitionnée par le dateid (date de la création des données dans le serveur de jeu) facilite la navigation dans les données de la saison. Quelques graphiques montrent le nombre de matchs disponibles, la répartition par plateforme et mode de jeu pour illustrer les nouvelles tables construites.
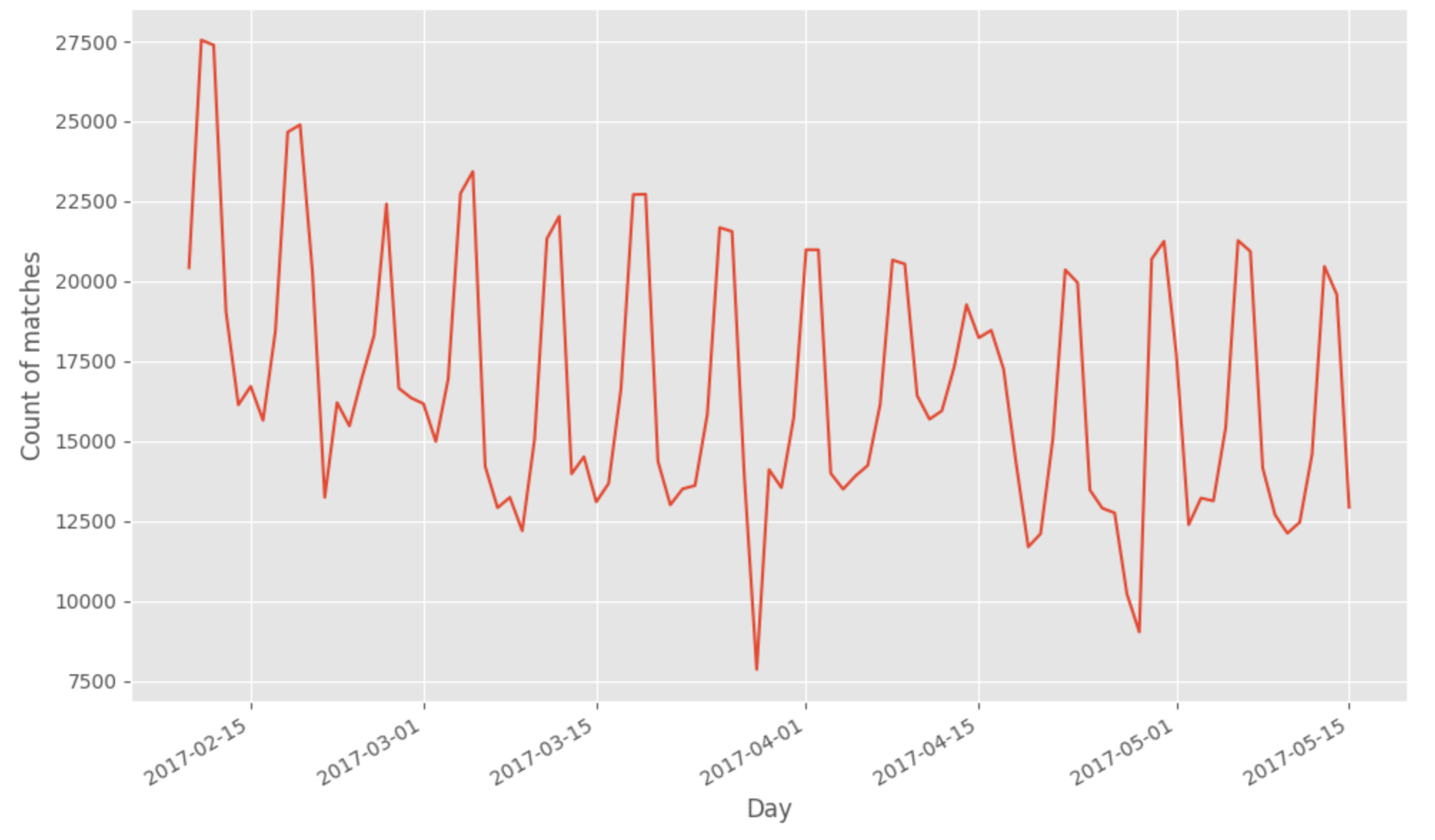
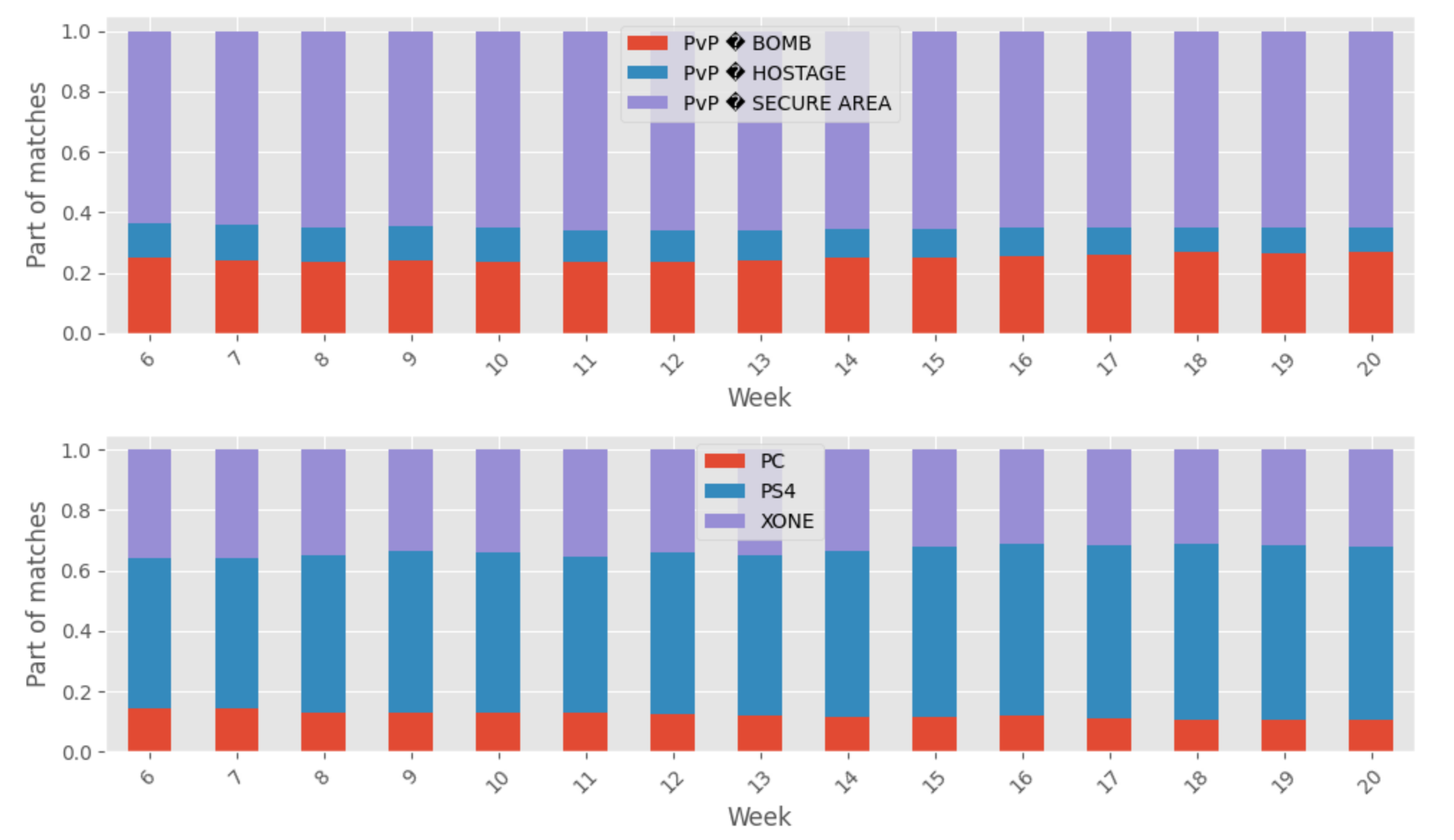
À remarquer de cette première analyse des nouvelles données construites :
- Il y a 1588833 matchs pour 9187971 rounds
- Il y a plus de matchs joués dans cet extrait sur PS4 (#sonyrepresents)
- Le mode de jeu le plus populaire est PvP secure area
Comme nous pouvons le voir, il y a beaucoup de matchs et de données à utiliser dans ce jeu de données, mais je veux appliquer une phase de vérification de santé pour déterminer
- les bons matchs : les équipes semblent les mêmes du premier au dernier round) et ont cinq membres de chaque côté
- les matchs ragequit : l’une des équipes perd au moins un membre, mais chaque équipe commence avec au moins cinq membres
- Les mauvais matchs : les matchs ne rentrent dans aucune des catégories précédentes
Vous pouvez trouver ici le notebook avec tout le traitement, mais ce qu’il est essentiel de garder à l’esprit dans les processus des données est :
- Déterminer le dernier round de chaque match
- Agréger par équipe les informations liées au niveau du joueur et à la classe de rang dans chaque round (il y a un identifiant unique du joueur, donc nous évaluerons que si les niveaux de l’équipe et le rang de compétence ne changent pas, l’équipe est la même)
- Comparer l’équipe dans le premier et le dernier round.
Dans tous les cas, à partir de ce traitement, il y a 10% des matchs considérés comme bons, 27% sont des ragequit, et le reste est mauvais.
Vous pouvez trouver dans ce fichier un extrait sur les informations calculées sur chaque match ; avec toutes ces informations sur les matchs, des analyses plus approfondies peuvent être effectuées.
Analyse de l’équité
Après avoir effectué le calcul de certaines métriques sur les matchs, je voulais voir s’il y avait une certaine équité dans la configuration des bons matchs et des matchs ragequit. Dans un jeu en ligne, derrière la sélection des équipes et des coéquipiers, il y a un système appelé matchmaking qui combine la connaissance du joueur, la configuration en ligne actuelle (localisation, qualité de connexion, etc.) et d’autres paramètres.
Ma connaissance du matchmaking n’est pas super étendue, mais si vous êtes intéressé, je vous invite à jeter un œil au travail de Microsoft sur les sujets avec les articles suivants Trueskill, Trueskill II (plus axé sur le développement d’une métrique de classement du joueur) et True match (axé sur l’exploitation de la connaissance du joueur, etc. pour construire un meilleur matchmaking, il y a une brillante conférence sur le sujet à la GDC 2020).
Mais du point de vue d’un joueur, je ne trouve pas le matchmaking très équitable (parfois #badplayer), donc je voulais voir si, par exemple, sur les données disponibles pour Rainbow Six, nous pouvons voir des problèmes dans la sélection des matchs. Pour faire cette estimation, j’ai commencé à construire un prédicteur de victoire de l’équipe de référence (c’est l’équipe 0 dans ce cas) basé sur :
- La moyenne et l’écart type des niveaux de chaque équipe
- La distance euclidienne entre la répartition du rang de compétence (pour chaque équipe, je compte le nombre d’équipes de chaque type de rang de compétence qui s’est produit dans l’équipe)
- La configuration du match (plateforme, version du patch, mode de jeu, carte)
Le modèle utilisé pour faire cette prédiction est un random forest regressor de mllib dans Spark entraîné sur 80% des bons/ragequit matchs et évalué sur les 20% restants (code ici). L’attente est que comme il y a un système de matchmaking en place, la prédiction de victoire devrait être autour de 50% pour tous les matchs.
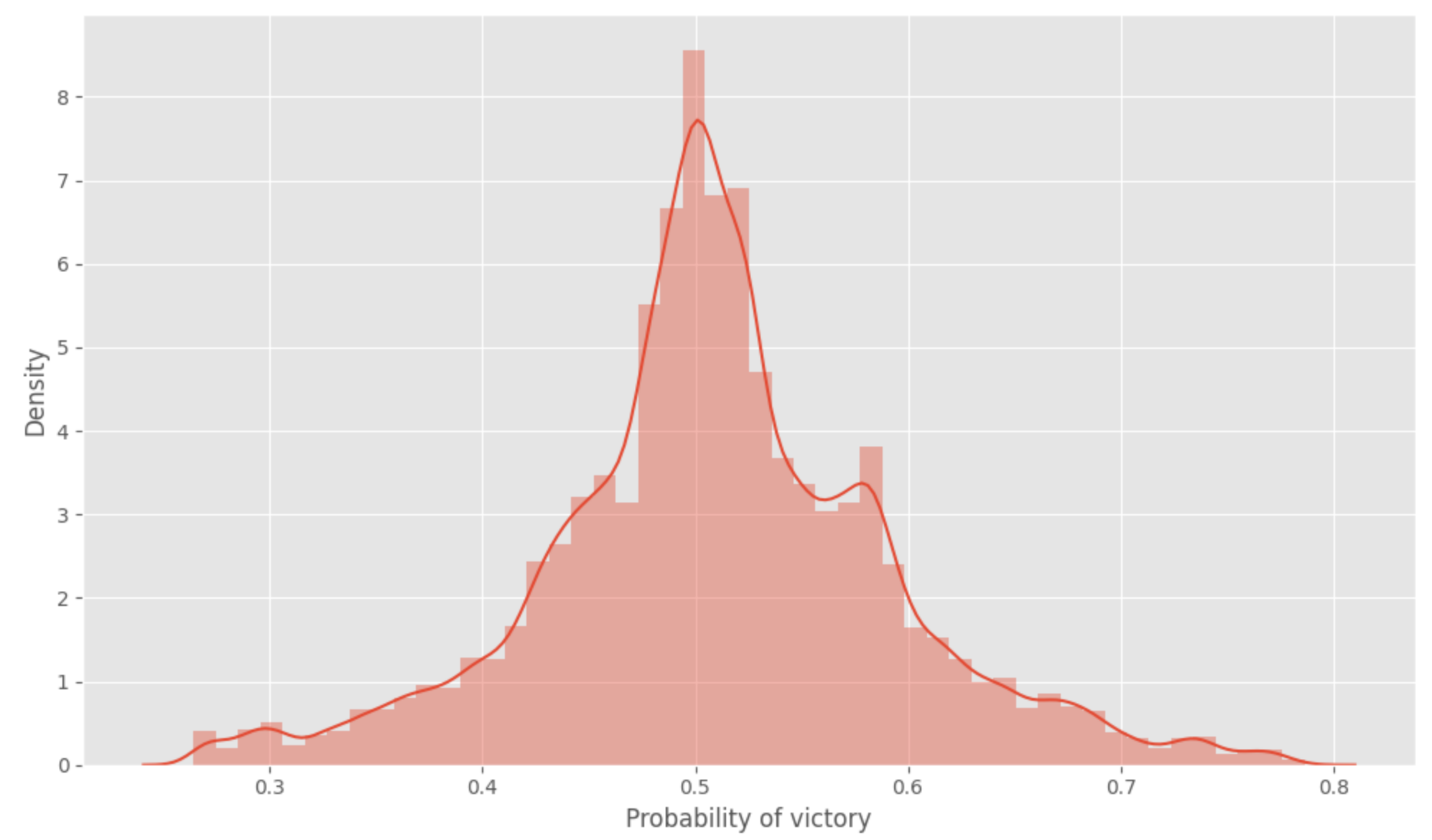
Bien de voir que le système en place semble être équitable (ou au moins il n’y a pas trop de valeurs extrêmes, j’ai supposé que le matchmaking pourrait parfois étendre la plage de recherche par manque de joueurs disponibles qui peuvent correspondre à un bon matchmaking).
Pour aller un peu plus loin dans le modèle, un graphique trace l’importance des caractéristiques utilisées dans ce modèle.
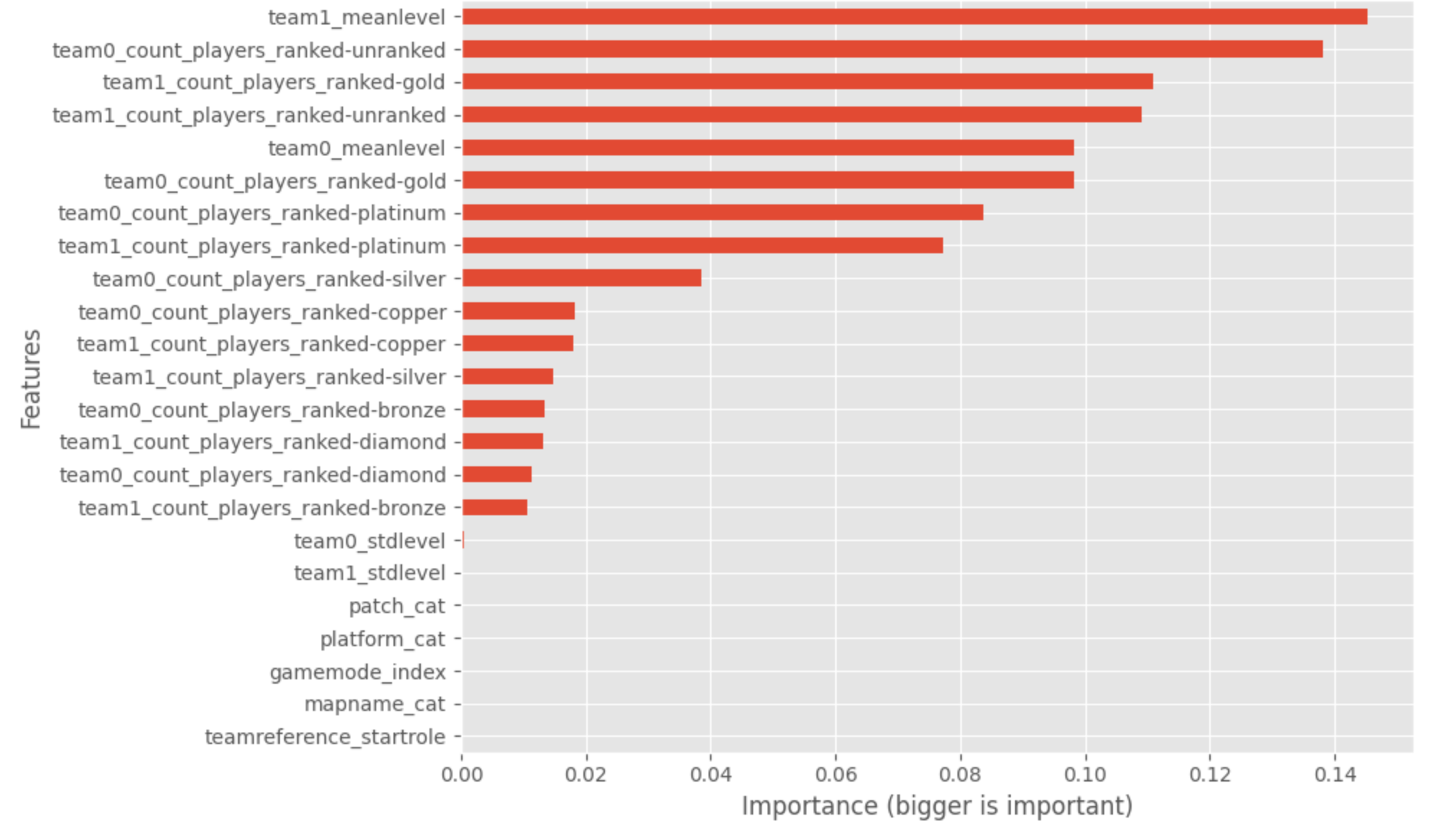
Nous pouvons remarquer que le niveau moyen et le nombre de rangs gold sont les caractéristiques essentielles ; nous voulons jeter un coup d’œil rapide à la prédiction par rapport à la différence entre le niveau moyen de chaque équipe. Nous pouvons voir la relation entre la différence d’expérience (qu’attendiez-vous).
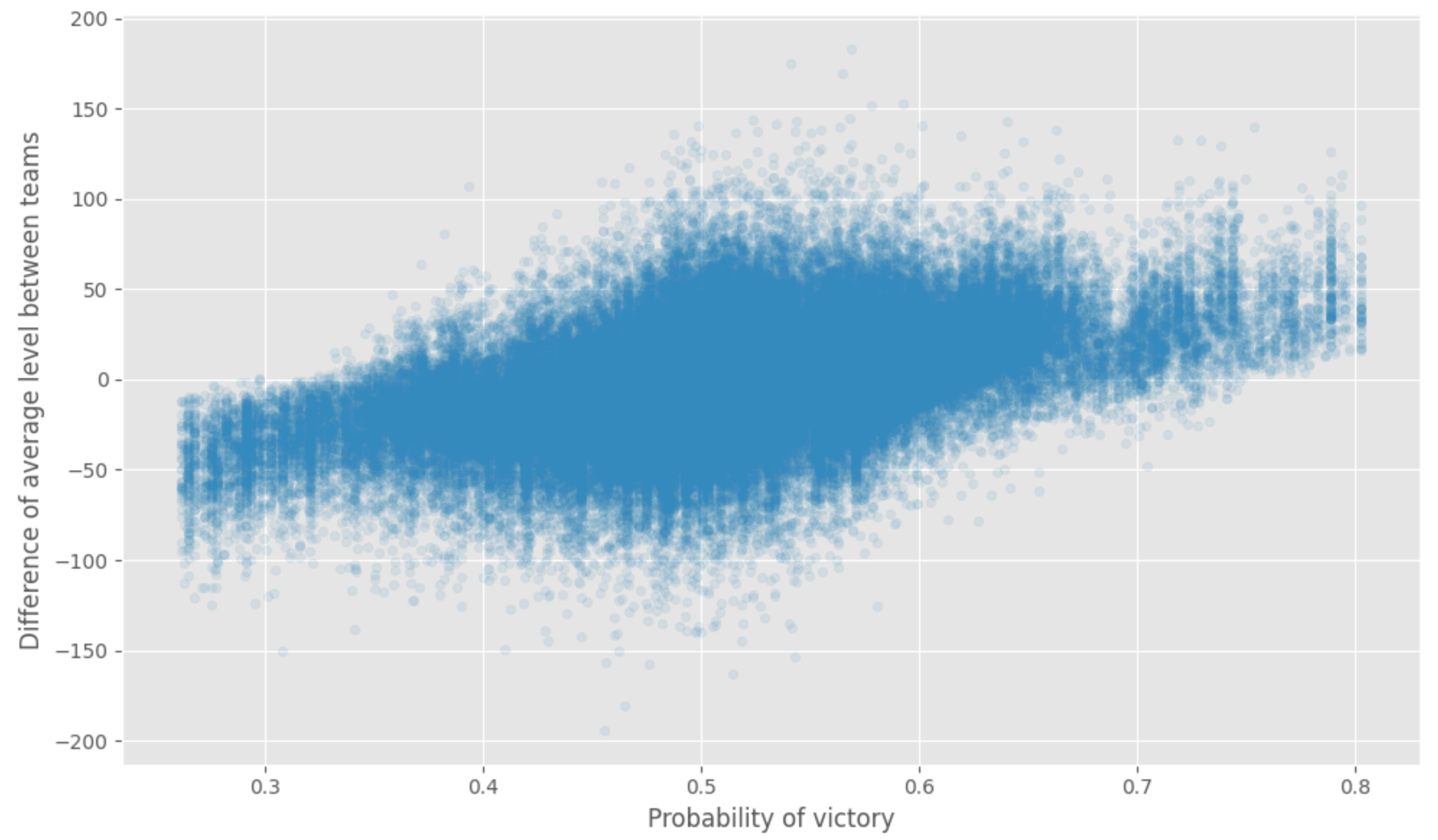
Pourtant, toutes ces analyses sont faites sans trop sur :
- L’exécution exacte du match, honnêtement en jouant au jeu, vous pouvez réaliser que prédire le résultat d’un match uniquement basé sur les caractéristiques sélectionnées n’est pas la meilleure façon de le faire (peut-être travaillerai-je sur une autre version plus basée sur les rounds)
- Ne pas connaître le joueur sur son expérience (carte, opérateur, matchs historiques) et la saison actuelle n’est pas optimal (ne pas avoir son humeur actuelle comme gagner des jeux, ne pas savoir s’il joue avec son équipe régulière, etc.)
Quoi qu’il en soit, c’était un estimateur très simple construit avec pyspark, et il y a beaucoup de questions qui peuvent être construites et répondues.
Conclusion
Cet article a été l’occasion de présenter un service d’AWS qui peut être utile pour démarrer des tests de framework Big data. Il y a quelques éléments que je n’ai pas utilisés pour ce projet, mais qui pourraient être utiles pour votre expérience :
- Avec EMR, vous pouvez lancer et arrêter des clusters, mais ce que vous pouvez faire c’est générer un cluster de machines, exécuter des scripts spécifiques (appelés step) et fermer la machine ; l’approche est assez utile si nous voyons l’utilisation du cluster plus dans une approche serverless (pour économiser les coûts)
- Si la configuration actuelle du cluster EMR est assez limitée, vous pouvez installer des bibliothèques spécifiques en utilisant un élément appelé bootstrap actions, essentiellement des scripts bag qui installeront des bibliothèques, des logiciels comme git ou des dossiers pour stocker des données (totalement valable mais pas nécessaire dans mon cas)
- Si vous voulez exécuter des scripts en ligne de commande (comme, par exemple, un spark-submit pour un job spark), vous pouvez configurer lors du lancement du cluster une clé ssh pour établir une connexion en ssh et exécuter les commandes en tant qu’utilisateur Hadoop
Comme les choses sont bien faites, il y a une excellente connexion entre EMR et Sagemaker, il y a une excellente doc ici, mais je vous conseillerai de suivre ces étapes (dans leur cas, ils veulent que les gens l’ajoutent au lifecycle) :
- Ajouter la politique suivante du rôle associé au notebook sagemaker (et noter le groupe de sécurité du notebook sagemaker)
- Pour démarrer et connecter un cluster à votre notebook, il y a ce notebook et un script bash (déclenché par le notebook)
Et dans le cas où vous n’êtes pas intéressé à utiliser EMR pour Spark, vous pouvez l’utiliser avec un autre framework comme dask, par exemple (il y a une configuration pour utiliser yarn avec dask ici). Dans le cas où vous ne connaissez pas dask, il y a une excellente explication de ce que c’est (et la différence par rapport à Spark).
Dans un autre aspect, il n’y a pas trop de jeu de données autour des jeux vidéo et des matchs en ligne dans les jeux de tir à la première personne, donc je conseillerai aux gens de jeter un œil à ce jeu de données d’Ubisoft. Même si le jeu de données sous sa forme originale n’est pas facile à utiliser, vous pouvez trouver une version plus digeste sur Kaggle comme ici.
Références
- EMR — AWS
- diverses versions d’EMR — AWS
- EMR 5.31.0 — AWS
- paramètres de configuration — AWS
- ici — GitHub
- EMR notebooks — AWS
- excellente ressource — AWS
- phase de prétraitement — GitHub
- ici — GitHub
- dans ce fichier — GitHub
- Trueskill — microsoft.com
- Trueskill II — microsoft.com
- True match — microsoft.com
- random forest regressor de mllib dans Spark — spark.apache.org
- ici — GitHub
- bootstrap actions — AWS
- ici — AWS
- politique suivante — GitHub
- notebook — GitHub
- script bash — GitHub
- ici — yarn.dask.org
- ici — Kaggle