
Retour de Recsys 2024
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
C’est cette période de l’année (avec un léger retard, je sais) où je fais un récapitulatif de la conférence RecSys, qui cette année a eu lieu à Bari, en Italie. J’ai assisté à l’événement virtuellement (merci à Ubisoft pour le billet). Dans cet article, vous trouverez une sélection des meilleurs articles, posters et ateliers que j’ai découverts pendant cet événement.
Factorisation matricielle partout tout à la fois
Comme d’habitude, lors de la conférence, il y avait plusieurs articles discutant du sujet de la factorisation matricielle, qui est toujours un composant fort du domaine des systèmes de recommandation (J’ai écrit à ce sujet cet été). Pour cette année, j’ai choisi deux articles sur le sujet.
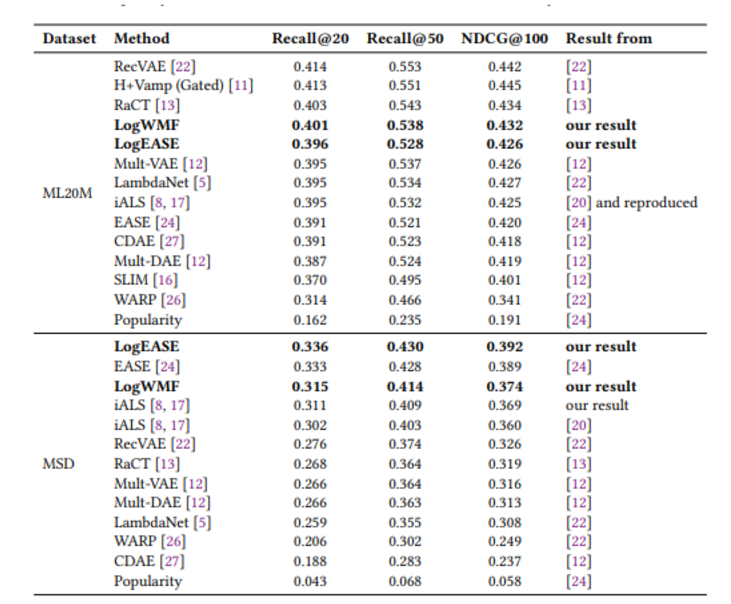
Le premier article est The Role of Unknown Interactions in Implicit Matrix Factorization: A Probabilistic View. C’est une question que j’ai toujours eu en tête—comment le poids des items non observés peut impacter les prédictions de recommandations (fondamentalement, quel est l’impact de la sparsité matricielle ?). Habituellement, les algorithmes comme ALS gèrent ces interactions inconnues à travers l’échantillonnage négatif, mais je dirais que c’est une simplification excessive de la réalité. Par exemple, la non-interaction ne signifie pas toujours un manque d’intérêt ; cela pourrait simplement signifier que l’utilisateur n’a pas vu l’item (basé sur l’entonnoir d’interaction, comme le contenu caché dans un endroit inhabituel, tel qu’au bas d’un menu déroulant, etc.). L’article propose une approche probabiliste appelée LogWMF (Logistic Weighted Matrix Factorization) pour attribuer différents poids aux échantillons inconnus en donnant une probabilité pour chaque interaction inconnue d’être soit positive soit négative. Cela est réalisé en utilisant une fonction logistique pour modéliser la probabilité des interactions positives et en représentant les inconnus comme le produit de probabilités positives et négatives.
Cette approche encourage le modèle à trouver un équilibre entre les deux possibilités. Les probabilités inconnues sont approximées avec une fonction gaussienne, permettant une optimisation efficace. Leurs benchmarks semblent légèrement améliorer certaines métriques par rapport à la version implicite d’ALS. Ils étendent également cette approche probabiliste aux versions modifiées d’EASE (logEASE et WEASE), inspirées par leur méthode pour LogWMF (j’attache les résultats).
L’autre article que j’ai choisi lié à la factorisation matricielle est un qui combine la factorisation avec les réseaux de neurones graphiques. Integrating Matrix Factorization with Graph-Based Models est un article très bref qui fournit un aperçu et des réflexions générales sur comment ces deux méthodes pourraient être intégrées pour travailler ensemble pour produire des recommandations. Par exemple, il inclut une représentation de comment un ensemble de données similaire pourrait être représenté dans un contexte de factorisation et de graphe.
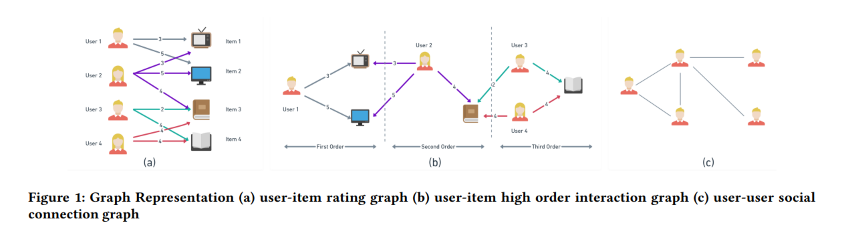
Il y a une forte emphase sur le fait que les techniques NMF semblent être les meilleures méthodes pour la factorisation matricielle (basé sur quelques enquêtes/revues).
Si, comme moi, les graphes vous ont toujours intrigué, j’ai déjà eu un stagiaire (👋 Cyril M) qui a travaillé sur le sujet en 2019. Cependant, je n’ai jamais vraiment eu le temps de creuser plus profondément depuis. Il y a aussi un tutoriel qui a eu lieu pendant RecSys, présenté par Panagiotis Symeonidis, comme introduction à l’utilisation des graphes pour les recommandations. Ce tutoriel fait partie d’un corpus de travaux plus large du professeur, qui semble super intéressant pour quiconque est curieux des systèmes de recommandation en général.
Grouplens : Comment réinventer le flux de recommandations
La plupart du temps, les recommandations sont très statiques, où vous ne pouvez pas influencer directement la sortie ou fournir seulement des feedbacks très explicites qui affecteront le flux plus tard (comme les notations sur Netflix ou Prime Video). Cependant, GroupLens (l’équipe de l’Université du Minnesota derrière le célèbre ensemble de données MovieLens) a publié deux articles intéressants cette année sur des expériences qu’ils ont menées pour retravailler le processus de recommandation en recueillant plus d’input des utilisateurs pendant une session.
Un de ces articles, The MovieLens Beliefs Dataset: Collecting Pre-Choice Data for Online Recommender Systems (récompensé lors de la conférence), illustre une expérience de quelques membres de GroupLens. Dans ce travail, ils explorent comment collecter des feedbacks spécifiques en demandant aux utilisateurs : “Que pensez-vous de ce film ?”
Par exemple, dans le contexte des films, un utilisateur pourrait croire qu’il apprécierait une comédie plus qu’un film d’horreur, même s’il n’a pas vu des films spécifiques de ces genres. Ces croyances influencent les choix de l’utilisateur. Quand une plateforme suggère un film que l’utilisateur n’avait pas considéré, cela peut changer la croyance initiale de l’utilisateur sur ce film. Si la recommandation est efficace, elle pourrait persuader l’utilisateur de regarder un film qu’il n’aurait pas choisi autrement.
Dans cette approche, ils visent à capturer la perception globale de l’utilisateur du contenu affiché. Ils ont utilisé des mécanismes économiques de prise de décision des utilisateurs pour modéliser ce phénomène (avec des concepts comme “bien” et “utilité”). Ils ont également développé une interface spécifique dans l’application MovieLens pour collecter ce feedback. L’interface inclut une fonctionnalité “vu ou non” (pour déterminer si l’utilisateur a manqué la notation du film) et un système de notation 5 étoiles pour capturer la perception générale de l’utilisateur.
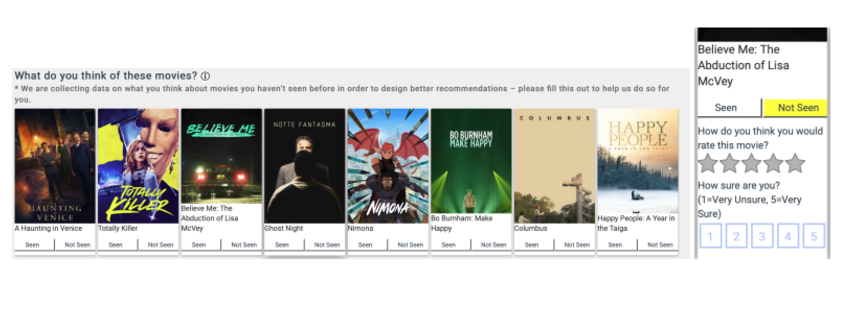
Je ne suis pas sûr de comment nous pourrions voir cela implémenté sur les plateformes de streaming courantes, mais je suis un grand fan des feedbacks explicites. Personnellement, j’aimerais avoir l’option d’évaluer ce qui m’est offert dans les recommandations.
Ils ont également partagé quelques chiffres sur comment s’est déroulée leur campagne de collecte de feedbacks. Il semble que 7,8% du temps, un utilisateur MovieLens qui a reçu une suggestion de croyance a rempli le formulaire. Pas mal, si vous me demandez ! L’ensemble de données devrait être public et disponible ici, mais malheureusement, le lien ne semble pas fonctionner.
Dans le second article, Interactive Content Diversity and User Exploration in Online Movie Recommenders: A Field Experiment, l’équipe a travaillé sur la capacité de surprendre l’utilisateur (la question continue d’exploration vs. exploitation). Dans ce cas, ils ont fait quelques ajustements à l’UI de MovieLens pour tester deux choses :
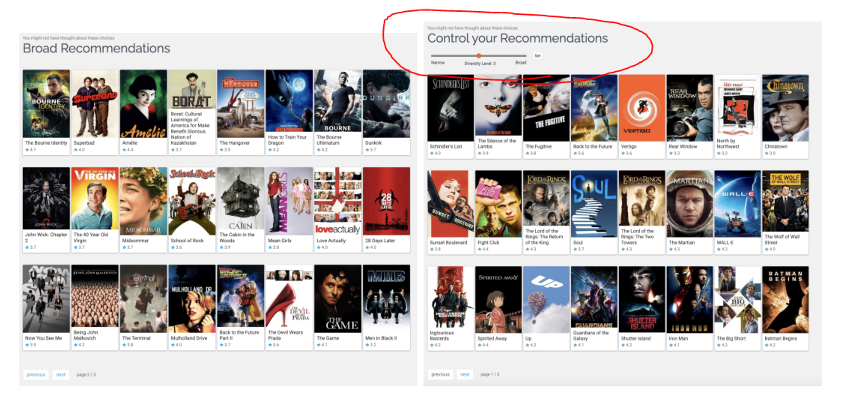
- Ajouter un carrousel qui étend la longueur des recommandations affichées.
- Introduire un curseur qui donne aux utilisateurs plus de contrôle sur ce qui est affiché.
Ces changements impactent la diversité des recommandations. Par exemple, le curseur de diversité permet aux utilisateurs d’influencer la variété du contenu qu’ils voient.
Ils ont mené une expérience de six semaines en 2022 avec 1 859 utilisateurs actifs de la plateforme en 2021. Ces utilisateurs ont été assignés aléatoirement à un groupe de traitement (carrousel ou curseur).
Gardez à l’esprit que sur MovieLens, vous pouvez changer le type de recommandations que vous voulez recevoir en choisissant l’un des quatre chemins : Paysan, Guerrier, Magicien ou Barde.
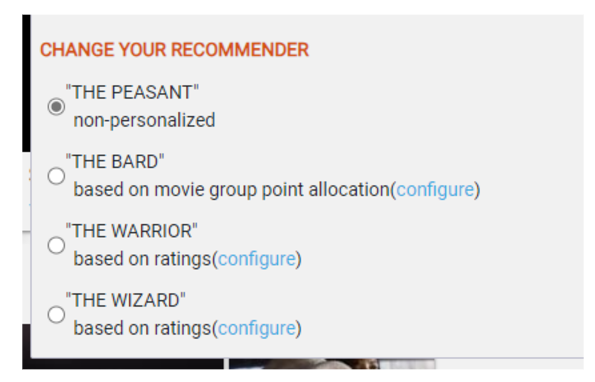
Pendant l’étude, ils ont fait quelques découvertes intéressantes :
- Les utilisateurs avec des goûts plus diversifiés qui ont interagi avec le carrousel pendant l’expérience semblaient continuer à s’engager davantage avec MovieLens après.
- Le carrousel semblait être plus efficace que le curseur (donc triste à ce sujet !).
Cependant, l’article souligne également un point important : la conception du système de recommandation lui-même peut influencer comment ces mises à jour UX impactent le parcours de l’utilisateur.
Globalement, ces expériences de GroupLens sont vraiment cool et reflètent une tendance que j’ai remarquée à la conférence RecSys, où les “entreprises” explorent de nouvelles façons d’interagir avec les recommandations (comme l’article de Deezer sur Flow Moods). Ils mentionnent également qu’une de leurs prochaines étapes est d’explorer les recommandeurs conversationnels et les outils alimentés par l’IA pour mieux répondre aux divers besoins des utilisateurs.
Articles de reproductibilité
Comme d’habitude, il y a un article sur le benchmarking des implémentations, et cette année j’ai choisi un article sur le Bayesian Personalized Ranking. L’article, Revisiting BPR: A Replicability Study of a Common Recommender System Baseline, fournit un aperçu de l’implémentation de l’algorithme ainsi que les diverses fonctionnalités activées dans le processus (comme dans ce tableau).

Ils ont benchmarké à la fois les implémentations open-source et les leurs, découvrant que l’implémentation de Cornac se démarque avec des performances impressionnantes. De plus, les BPRs sur Elliot reflètent fidèlement l’article original de 2009, les rendant hautement fiables.
Un récapitulatif de la conférence RecSys ne serait pas complet sans mentionner un article de Deezer (et du CNRS). Cette année, l’article Do Recommender Systems Promote Local Music? A Reproducibility Study Using Music Streaming Data a pris la scène centrale. Ils ont revisité une étude précédente, Traces of Globalization in Online Music Consumption Patterns and Results of Recommendation Algorithms, qui suggérait que certains systèmes de recommandation pourraient présenter des biais contre la musique locale.
Deezer et le CNRS ont visé à reproduire ces découvertes en utilisant des données propriétaires, se concentrant sur les marchés français, allemand et brésilien, où Deezer est un leader local. Fait intéressant, ils n’ont pas pu répliquer les résultats de l’étude originale, qui étaient basés sur l’ensemble de données lfm-2b. L’article inclut une représentation rapide des streams locaux dans les deux ensembles de données.
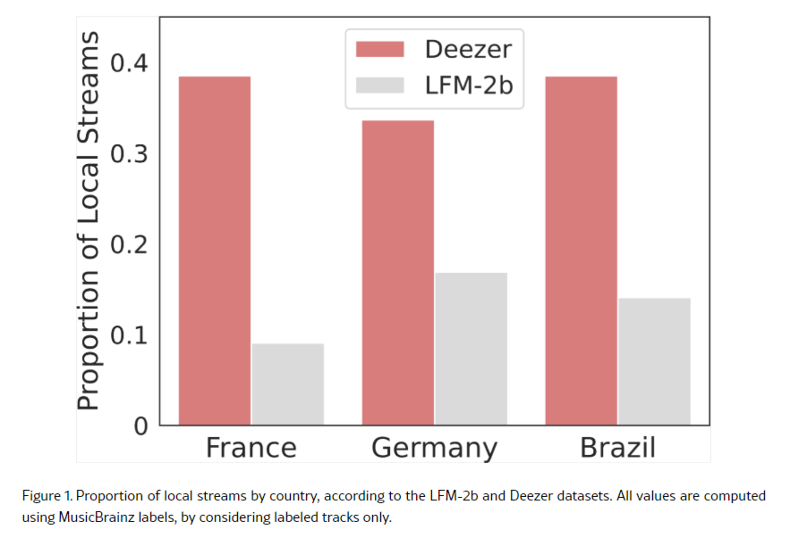
Les auteurs ont également analysé les biais algorithmiques de deux systèmes de recommandation, NeuMF et ItemKNN, utilisés dans l’étude originale. Cependant, ils ont trouvé que les biais observés sur LFM-2b ne se traduisaient pas systématiquement sur l’ensemble de données Deezer. Dans certains cas, la direction du biais s’est même inversée selon l’ensemble de données, les paramètres d’entraînement et la source d’étiquette utilisés.
LLM ceci LLM cela
Comme prévu, les modèles de langage ont été un sujet brûlant lors de la conférence, reflétant la popularité croissante des systèmes basés sur les transformers au cours des dernières années. Je suis tombé sur quelques articles qui valent vraiment la peine d’être explorés.
Le premier, de Microsoft, s’intitule Analyzing User Preferences and Quality Improvement on Bing’s WebPage Recommendation Experience with Large Language Models. Dans cet article, l’équipe présente comment ils exploitent les grands modèles de langage pour créer des extraits de sites web qui peuvent être recommandés dans la fonctionnalité “Explore Further”.
Ils ont utilisé GPT-4.0 pour générer des titres de haute qualité et des résumés d’extraits pour un grand ensemble de données de pages web et affiné Mistral 7B pour mettre à l’échelle cette tâche. Avec ces nouvelles insights, ils ont réussi à créer plusieurs scénarios de recommandation tels que :
- Same Tier Alternative : Substituer des pages web ou des services.
- More Authoritative Alternative : Pages web avec une plus grande autorité sur le sujet.
- Complementary Recommendation : Contenu qui complète la page web originale.
Ils classifient les sites web basés sur l’évaluation du LLM. De plus, ils ont développé une nouvelle métrique appelée Recommendation Quality Discounted Cumulative Gain (RecoDCG), qui note les paires de sites web basés sur leur pertinence et qualité, incorporant les évaluations générées par LLM.
Les autres articles que j’ai choisis sont de Spotify, discutant de la recherche en deux composants et spécifiquement comment les LLM sont utilisés pour générer des données synthétiques pour entraîner des modèles. Le premier est Encouraging Exploration in Spotify Search through Query Recommendations, où Spotify décrit leur approche pour améliorer le mécanisme de recherche.
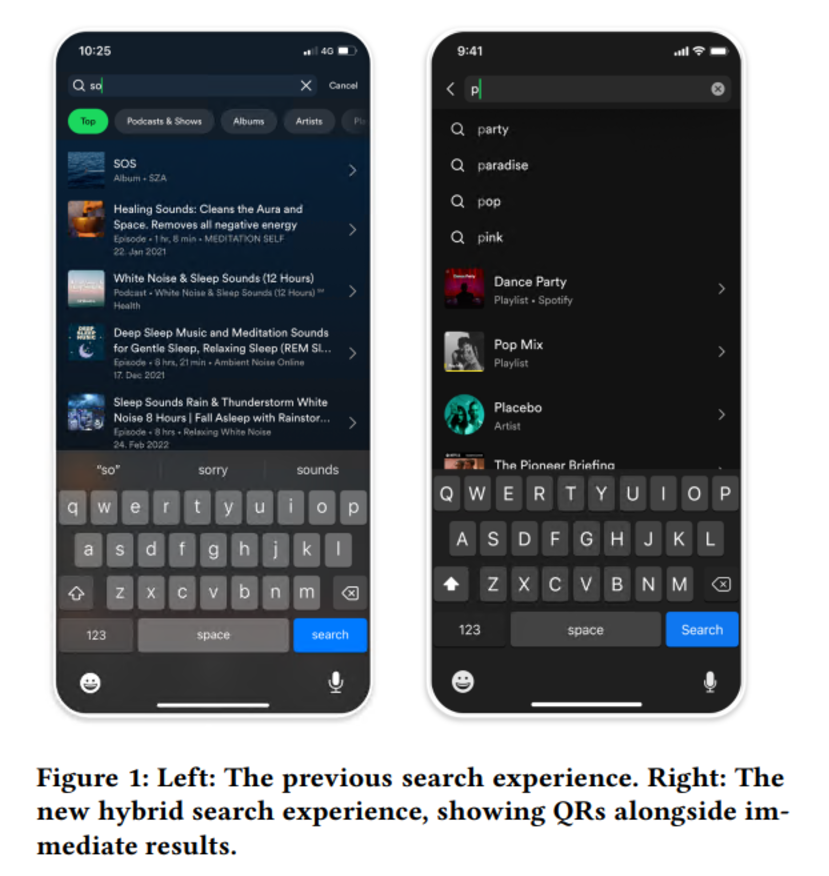
Dans ce cas, l’objectif est de faire des recommandations de requêtes (QR) et d’explorer différentes méthodologies pour construire de nouvelles requêtes, telles que :
- Extraire des requêtes des titres d’items du catalogue (par exemple, noms d’artistes, noms de playlists)
- Miner des requêtes complètes à partir des journaux de recherche
- Exploiter les recherches récentes des utilisateurs et les items personnels
- Utiliser des métadonnées et des règles d’expansion (par exemple, “[nom d’artiste] + covers”)
- Employer des LLM pour générer des requêtes en langage naturel
Leur système QR est un hybride qui fonctionne avec leur recherche instantanée, fournissant des recommandations aux côtés de résultats immédiats. Cette approche hybride vise à soutenir à la fois les recherches d’items connus et exploratoires. Ils ont observé quelques résultats intéressants :
L’introduction de QR a conduit à une augmentation de 30% de la longueur de requête maximale par utilisateur et une augmentation de 10% de la longueur moyenne de requête. Cela suggère que les utilisateurs formulent des recherches plus complexes. Le système a résulté en une augmentation de 9% de la part des requêtes exploratoires, indiquant que les utilisateurs s’engagent dans des recherches plus orientées vers la découverte.
L’autre article de Spotify que j’ai choisi, Bridging Search and Recommendation in Generative Retrieval: Does One Task Help the Other?, enquête sur si l’entraînement d’un seul modèle de récupération générative sur les données de recherche et de recommandation peut améliorer les performances pour les deux tâches. Cette recherche est plus théorique et offline, sans impact mesuré de manière live, mais elle fournit toujours un excellent exemple de comment les LLM peuvent être utilisés pour créer des variantes de requêtes.
L’étude suggère que l’entraînement d’un seul modèle sur les deux données de recherche et de recommandation améliore la capacité du modèle à comprendre les items et à faire de meilleures prédictions en combinant les informations de contenu et de comportement de l’utilisateur.
Enfin, il y a un article très court mais intéressant du Los Angeles Times intitulé More to Read at the Los Angeles Times: Solving a Cold Start Problem with LLMs to Improve Story Discovery. Cet article présente leur fonctionnalité “More to Read”, qui suggère des articles similaires que les lecteurs pourraient trouver intéressants, voici une capture d’écran de la fonctionnalité.
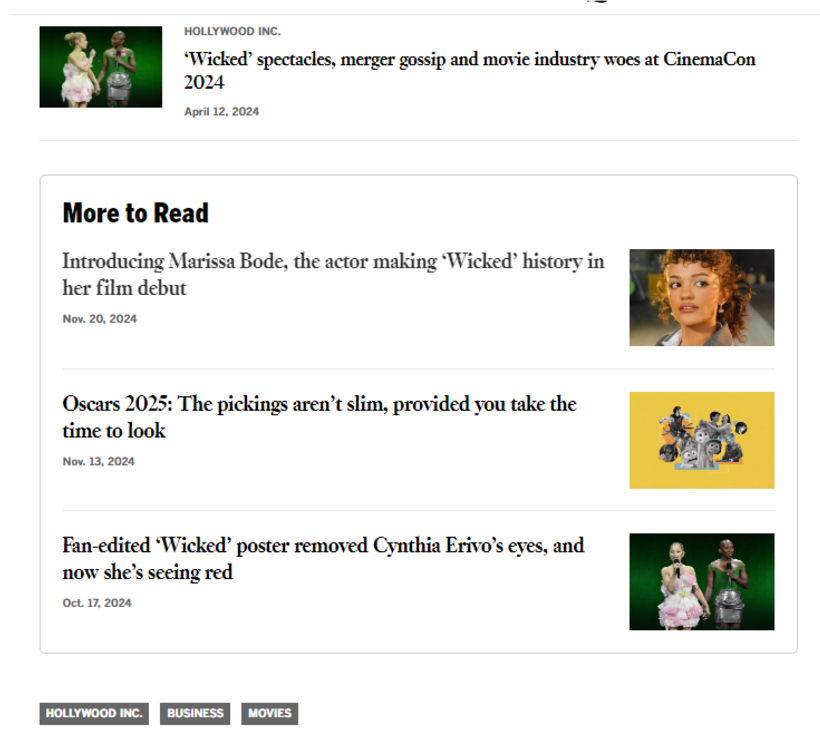
Ils ont benchmarké deux systèmes : un basé sur TF/IDF (term frequency–inverse document frequency) et l’autre sur GTE (General Text Embedding). Les deux systèmes ont montré des résultats impressionnants, atteignant une augmentation de 39,4% du CTR par rapport à un modèle basé sur la popularité, indiquant que les utilisateurs ont trouvé les recommandations plus pertinentes et engageantes. Cependant, ces deux systèmes différaient dans le type de recommandations qu’ils généraient :
- TF/IDF : Ce système tendait à recommander des articles très similaires à l’article de départ, créant une expérience plus immersive pour l’utilisateur.
- GTE : Ce système identifiait des articles qui exploraient des thèmes et contextes connexes, offrant une expérience plus nouvelle qui encourageait l’exploration de sujets tangentiels.
Pour illustrer la différence, ils ont regardé un article sur Jennifer Aniston et la cancel culture. Les recommandations des deux modèles différaient clairement en contenu, mettant en valeur les forces uniques de chaque approche.

La classification de la similarité est basée sur une comparaison du 5W1H (Who, What, When, Where, Why, and How) de chaque article. Les recommandations immersives ont des éléments 5W1H étroitement correspondants, tandis que les recommandations nouvelles ont des éléments 5W1H plus diversifiés.
En fin de compte, le LA Times a sélectionné GTE pour sa capacité à offrir des recommandations plus nouvelles, ce qui aide à limiter la bulle de filtre et le phénomène de chambre d’écho.
Les inadaptés !?
Pour cette section, je voulais agréger quelques articles qui ne rentrent pas dans les sections plus grandes mais qui valent définitivement la peine d’être lus.
Le premier est A Dataset for Adapting Recommender Systems to the Fashion Rental Economy. Cet article d’introduction, disponible sur Kaggle, met en évidence une configuration unique pour faire des recommandations avec des contraintes très spécifiques, telles que l’usure et la dégradation des vêtements : à mesure que les articles sont loués plusieurs fois, leur condition se détériore. L’article mentionne également un repository GitHub utile pour le traitement des données.
Une découverte intéressante de l’article est l’utilisation du modèle EfficientNet_V2_L pour taguer les images de vêtements. Ce modèle semble être l’un des meilleurs basé sur leur benchmark, voici une représentation globale des tags associés aux tenues (Merci à Karl Audun pour la distribution wordcloud des tags).

Un autre article que j’ai choisi est A Pre-trained Zero-shot Sequential Recommendation Framework via Popularity Dynamics de l’Université de l’Illinois. L’équipe a développé une méthode appelée PREPRec, qui utilise une nouvelle architecture de transformer consciente de la dynamique de popularité pour exploiter les préférences changeantes des utilisateurs mises en évidence par la dynamique de popularité des items avec lesquels ils ont interagi.
L’objectif est d’encoder la séquence d’actions non pas basée sur l’item lui-même mais sur la tendance de l’item sur des périodes courtes (comme 2 jours) ou longues (comme 10 jours). L’article fournit également un aperçu de l’architecture du transformer.
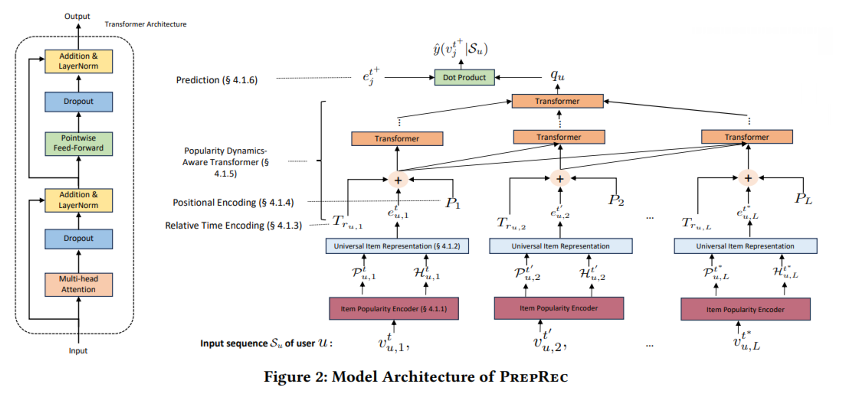
Le code et la théorie semblent un peu complexes, mais les résultats sont très impressionnants, tels que :
- Jusqu’à 6,5% d’amélioration de performance en Recall@10 pour le transfert cross-domain zero-shot par rapport aux modèles entraînés sur cible.
- 11,8% d’augmentation moyenne en Recall@10 et 22% en NDCG@10 lors de l’interpolation des résultats PREPRec avec BERT4Rec.
- 12 à 90 fois plus petite taille de modèle par rapport à BERT4Rec, SasRec, et TiSasRec.
J’ai trouvé l’approche vraiment innovante et potentiellement très transférable dans des contextes où les applications sont publiées régulièrement, même si elles varient en structure (comme les jeux vidéo 😁).
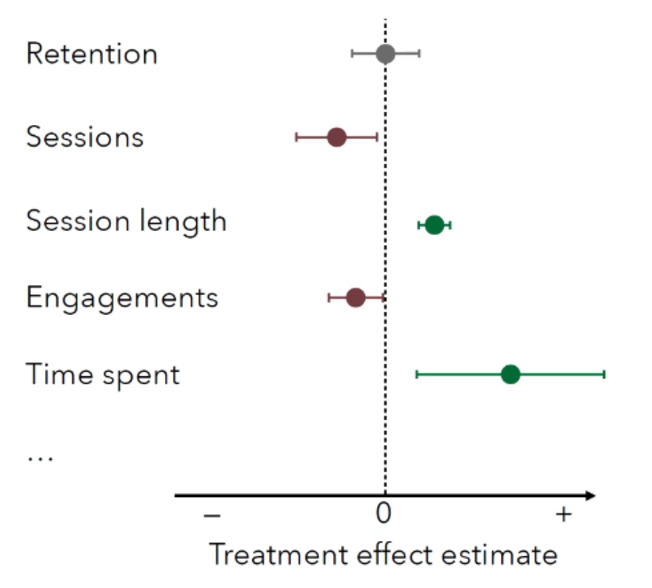
Le test A/B est un composant fort, et il y a un excellent article, Powerful A/B-Testing Metrics and Where to Find Them de ShareChat, qui fournit un excellent aperçu du paradigme pour une configuration de recommandeur. J’ai vraiment apprécié leurs visualisations sur les métriques dans leurs diapositives, que je pense pourraient être un excellent récapitulatif pour toute analyse de test A/B.
Une autre initiative cool est le travail de l’Université de Siegen, intitulé Recommender Systems Algorithm Selection for Ranking Prediction on Implicit Feedback Datasets. Cette étude explore le problème de la sélection d’algorithmes pour les systèmes de recommandation se concentrant sur la prédiction de classement utilisant des ensembles de données de feedback implicite. Pour résoudre cela, ils ont créé un méta-ensemble de données englobant les scores de performance de 24 algorithmes de systèmes de recommandation différents (avec deux configurations d’hyperparamètres chacun) sur 72 ensembles de données divers. Ces ensembles de données représentent une variété de tailles, domaines et caractéristiques, incluant divers nombres d’utilisateurs, items, interactions et sparsité des données, qui composent les méta-caractéristiques des données.
Ils ont entraîné plusieurs méta-apprenants, incluant des modèles de machine learning traditionnels comme la régression linéaire, K-Nearest Neighbors, Random Forest et XGBoost, ainsi qu’un algorithme de machine learning automatisé (AutoGluon). Les résultats sont impressionnants :
- Le meilleur méta-modèle en termes de Recall@1 (prédire correctement l’algorithme le plus performant) est XGBoost, atteignant un rappel de 48,6%.
- Random Forest excelle en Recall@3, identifiant deux des trois meilleurs algorithmes pour 66,9% des ensembles de données.
- Le machine learning automatisé avec AutoGluon démontre une corrélation légèrement plus élevée avec le classement de vérité terrain par rapport aux modèles traditionnels. Cependant, les modèles traditionnels surpassent légèrement AutoGluon dans la prédiction des meilleurs et trois meilleurs algorithmes.
Je pense que cet article pourrait être un excellent point de départ pour quiconque cherchant à explorer quel algorithme utiliser pour un nouveau cas d’usage. Il offre également des conseils pratiques pour les praticiens cherchant à optimiser les systèmes de recommandation.
Une grande tendance ces dernières années a été d’utiliser des approches multi-modales pour aborder les recommandations. Il y a un excellent article de Kuaishou Technology intitulé A Multi-modal Modeling Framework for Cold-start Short-video Recommendation. Dans cet article, ils expliquent leur système appelé M3CSR, un nouveau cadre de modélisation multi-modale conçu pour aborder le problème de cold-start dans les recommandations de vidéos courtes. Les auteurs mettent en évidence les défis de recommander de nouvelles vidéos avec des données d’interaction utilisateur limitées, se concentrant sur l’écart entre l’extraction d’embedding multi-modale pré-entraînée et la modélisation d’intérêt utilisateur personnalisée.
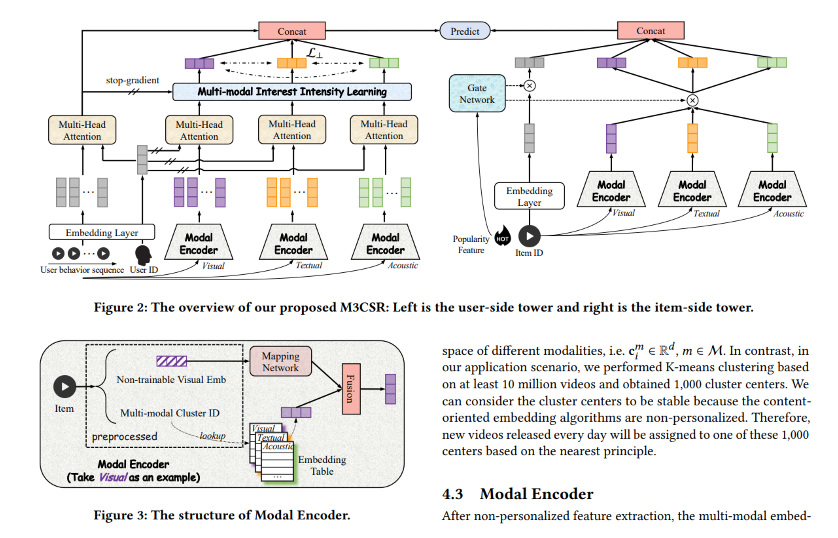
Ils mélangent la séquence d’actions utilisateur avec les relations entre items basées sur leur modalité (image, acoustique, textuelle). Pour construire ces modalités, ils utilisent des “petits modèles” comme :
- Modalité image : Resnet
- Modalité texte : Sentence-BERT
- Modalité acoustique : VGGish
Toutes ces modalités peuvent être utilisées pour associer de nouvelles vidéos avec des IDs de cluster, qui peuvent ensuite être utilisés dans le processus de tour double pour faire des recommandations à la volée. Cela semble complexe, mais ils ont obtenu des résultats très impressionnants lors des tests A/B sur diverses métriques (bien que les détails du groupe de contrôle ne soient pas fournis) :
- Engagement : Taux de clics (+3,385%), likes (+2,973%), et follows (+3,070%) montrent un engagement utilisateur accru avec les vidéos recommandées.
- Temps de visionnage : Une augmentation de +2,867% suggère que les utilisateurs trouvent les recommandations plus engageantes et regardent pendant des durées plus longues.
- Découverte de vidéos Cold-Start : L’augmentation significative de “Climbing4k” (+1,207%) indique que M3CSR aide à promouvoir de nouvelles vidéos de haute qualité en les associant efficacement aux utilisateurs intéressés.
- Couverture : L’augmentation de la couverture (+3,634%) implique qu’une plus grande gamme de vidéos cold-start sont surfacées avec succès aux utilisateurs, contribuant à la diversité du contenu et à la croissance de la plateforme.
Enfin, je n’ai pas réussi à assister à l’atelier VideoRecSys + LargeRecSys 2024, mais il y avait une présentation intéressante de Justin Basilico, qui dirige les efforts de ML et de systèmes de recommandation chez Netflix. Vous pouvez trouver la présentation ici. Dans sa présentation, il a partagé certains de ses apprentissages sur la construction et le fonctionnement de systèmes de recommandation, faisant une analogie avec l’éducation d’un adolescent. Cette présentation est une bonne collection de la vision de Netflix sur comment opérer un système de recommandation, avec quelques apprentissages clés valant la peine d’être soulignés :
- Concevoir un système auto-améliorant en utilisant une approche de bandit contextuel. Cela implique un apprentissage continu à partir des interactions utilisateur.
- La personnalisation nécessite d’équilibrer la précision, la diversité, la découverte, la continuation, le nouveau et l’existant contenu, et la scalabilité. Se concentrer sur la satisfaction à long terme des membres est la clé pour atteindre cet équilibre.
- Reconnaître que les erreurs sont inévitables et concevoir des systèmes pour la résilience, la détection rapide et la récupération rapide (appliquer Recsysops).
- Reconnaître les dynamiques temporelles des intérêts des utilisateurs et de la consommation de contenu. Rendre les modèles conscients du temps pour capturer les préférences à court et long terme.
- Prioriser le plaisir de l’utilisateur plutôt que les simples métriques d’engagement.
Mais à la fin la leçon finale est 😁

Notes de conclusion
Dans RecSys, il y a toujours quelque chose de nouveau à apprendre, et nous pouvons voir l’émergence de nouvelles tendances (comme les LLM—qui aurait pu s’y attendre ?). J’ai vraiment apprécié l’article A Pre-trained Zero-shot Sequential Recommendation Framework via Popularity Dynamics, que j’ai trouvé être une tournure innovante dans la recommandation de séquence et les systèmes de recommandation cross-domain. Je suis vraiment excité pour l’année prochaine et la conférence à Prague.
Au-delà de cet article, j’aime discuter de données, d’IA et de conception de systèmes—comment les projets sont construits, où ils réussissent et où ils échouent. Si vous voulez échanger des idées, remettre en question des hypothèses ou parler de vos propres projets, n’hésitez pas à me contacter. Je suis toujours ouvert pour une bonne conversation.
Références
- Bari, en Italie — Wikipedia
- The Role of Unknown Interactions in Implicit Matrix Factorization: A Probabilistic View — dl.acm.org
- EASE — arXiv
- Integrating Matrix Factorization with Graph-Based Models — dl.acm.org
- corpus de travaux plus large — panagiotissymeonidis.com
- GroupLens — grouplens.org
- The MovieLens Beliefs Dataset: Collecting Pre-Choice Data for Online Recommender Systems — arXiv
- ici — grouplens.org
- Interactive Content Diversity and User Exploration in Online Movie Recommenders: A Field Experiment — arXiv
- l’article de Deezer sur Flow Moods — arXiv
- Revisiting BPR: A Replicability Study of a Common Recommender System Baseline — arXiv
- l’implémentation de Cornac — GitHub
- BPRs sur Elliot — GitHub
- l’article original de 2009 — arXiv
- Do Recommender Systems Promote Local Music? A Reproducibility Study Using Music Streaming Data — arXiv
- Traces of Globalization in Online Music Consumption Patterns and Results of Recommendation Algorithms — humrec.github.io
- l’ensemble de données lfm-2b — cp.jku.at
- Analyzing User Preferences and Quality Improvement on Bing’s WebPage Recommendation Experience with Large Language Models — dl.acm.org
- Encouraging Exploration in Spotify Search through Query Recommendations — dl.acm.org
- Bridging Search and Recommendation in Generative Retrieval: Does One Task Help the Other? — arXiv
- More to Read at the Los Angeles Times: Solving a Cold Start Problem with LLMs to Improve Story Discovery. — dl.acm.org
- TF/IDF — Wikipedia
- GTE — arXiv
- 5W1H — Wikipedia
- A Dataset for Adapting Recommender Systems to the Fashion Rental Economy — dl.acm.org
- disponible sur Kaggle — Kaggle
- repository GitHub — GitHub
- leur benchmark — link.springer.com
- la distribution wordcloud des tags — Kaggle
- A Pre-trained Zero-shot Sequential Recommendation Framework via Popularity Dynamics — arXiv
- Powerful A/B-Testing Metrics and Where to Find Them — arXiv
- Recommender Systems Algorithm Selection for Ranking Prediction on Implicit Feedback Datasets. — arXiv
- 72 ensembles de données divers — GitHub
- A Multi-modal Modeling Framework for Cold-start Short-video Recommendation — dl.acm.org
- Resnet — paperswithcode.com
- Sentence-BERT — sbert.net
- VGGish — v-iashin.github.io
- VideoRecSys + LargeRecSys 2024 — largeandvideorecsys.github.io
- Recsysops — Medium / Towards Data Science
- conférence à Prague — recsys.acm.org