
Hello, this is autumn and who says autumn says Recsys time, and this year Seattle was the place to be. I attended digitally to the conference (Thanks Ubisoft), and in this article, I will recap papers/posters that I found interesting.
Build smarter search engine
Recommender systems and search engines are tight applications and classified as discovery applications (Eugene yan), and I found that this year there were exciting resources on the subject.
Learning Users’ Preferred Visual Styles in an Image Marketplace (Shutterstock)
In this paper, Shutterstock presents their search engine-based join with a recommender system. The idea is to use the classic search engine as a candidate generator (like a two-step recommender system) and, after using a “visual style recsys” to order these candidates.
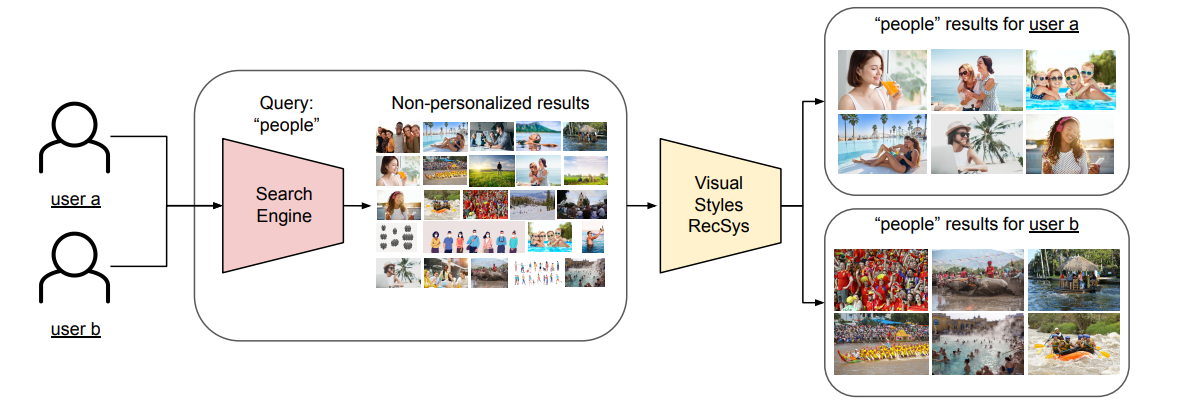
The features in the “visual style recsys” are interesting; it’s using the type of subscription (primordial in this kind of business model because the catalogue will be different) and the userid because they wanted to encode the identity of the users also. In addition, there are features around colour, angle and style for the image (not too many details on how they build these features).
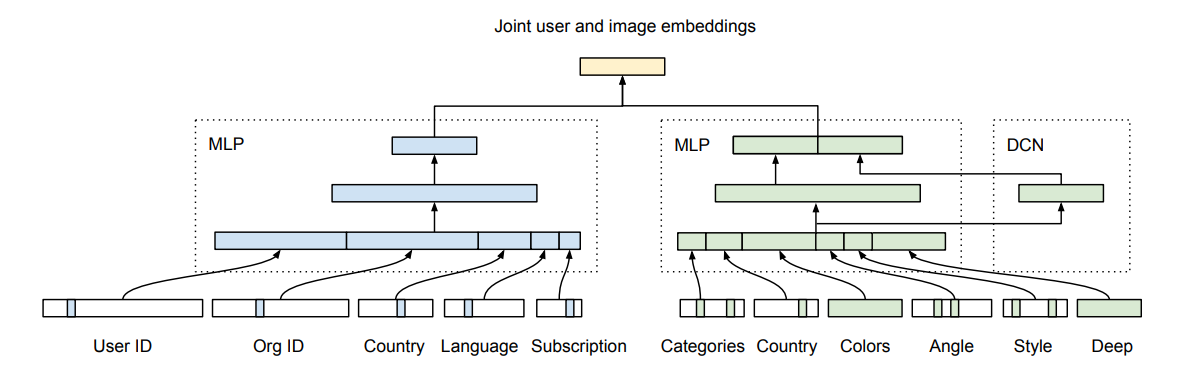
The process is ingenious and, I think, pretty efficient for the computation; sadly, there was nothing on the industrialization because it seems that they’re just starting to test it live (but they are planning to communicate the results).
PS: Recently, Shutterstock published an excellent article about their approach to building recommendations (and they presented this project). Very high level but some noticeable findings:
- They are using metaflow and TensorFlow recommenders
- Shutterstock is providing ai consulting services
- They have exciting blog posts around colours and other topics; it’s an excellent way to promote works
Augmenting Netflix Search with In-Session Adapted Recommendations (Netflix)
In this case, the search is based on multiple factors; there is a representation of the input data.
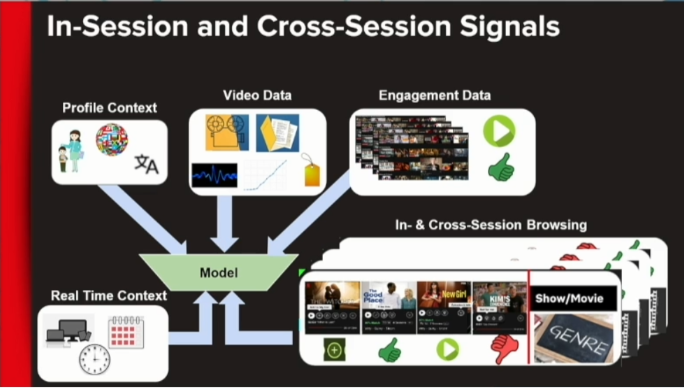
The exciting part is that they are using the information on the user but also in session information; their stack is represented in the paper looks standard, and I discovered a concept of a JIT server (just in time). Unfortunately, the model under the hood is pretty foggy; they seem to have tested “simple RNN, LSTM, bi-directional LSTM and transformer architectures.” On the other hand, the system seems to have increased the offline metrics by 6% (it seems small, but I will be curious to see it online).
In this presentation, there were mentions of two insightful Netflix papers :
- The first one around the Challenges in Search on Streaming Services: Netflix Case Study, seems to list some critical elements to design a search system (gave me some ideas to experiment on side projects)
- Another article about the search system design at Netflix looks like the details that were missing in the previous article, so a good addition.
Transformers united
They started to make their hole a few years ago, but they shine on this edition.
A Systematic Review and Replicability Study of BERT4Rec for Sequential Recommendation (Glasgow university)
A paper of Glasgow university on how to leverage other architectures of Transformers to build better recommender systems, the transformers for recsys was a significant trend last year, and this article is highlighting two things:
- Reproduce results of the papers is sometimes not possible #humanafterall
- Other architecture seems to do a great job in terms of performance.
![]()
It seems to be (harder !?) better, faster (stronger !?).
I am unfamiliar with the transformers #dlnoob, but this article is astounding to catch some exciting architectures.
There is a GitHub repository associated with these two last articles HERE.
Rethinking Personalized Ranking at Pinterest: An End-to-End Approach (Pinterest)
This article is an excellent addition to a series of articles that Pinterest started on their tech blog a few weeks ago. In this article, there is a representation of one of their approach to building a recommender system of images/pins.
![]()
The idea of the recommender system is to mix models that will build long-term and short-term features. Then, these features will be injected into a transformer to produce recommendations (it seems to have been applied in the home feed and related pin ads).
The exciting part is the conception of the features:
- Long-term: they build two components called pinnerformer and pinsage to process events
For pinnerformer, they have a process to extract features from the last year’s interactions.
![]()
For pinsage, It is not detailed in the paper, but there are more details on their blog HERE that leverage graph CNN to process the data.
- Short term: the process os short details, but they seem to leverage some awesome embeddings from pinsage on recent actions (and not the most recent one, but they are doing some time windowing because the system was too responsive)
The process positively impacts the user’s experience, with a lift of around 7 to 15% based on the configuration of the recsys.
This work is also a good illustration of their way of optimizing computation with GPU; they built a great article on their tech blog (HERE), and there is a table of comparison of gains based on the kind of models (his size)and the infra upgrade.
![]()
It is starting to be interesting to deploy big models without a significant increase in cost.
PS: in the video, they also have an excellent way to split a recommender into four levels/stages/steps in a pyramid.
![]()
BRUCE - Bundle Recommendation Using Contextualized item Embeddings (University of the Negev)
In this article, the authors tackled the problem of recommending bundles of items; the situation can be complex. The core of the model’s approach is based on Transformers, but they have designed different approaches to feed it.
![]()
Their results look promising, with uplifting accuracy metrics between 20% and 36%.
A Lightweight Transformer for Next-Item Product Recommendation (Wayfair)
Once again, another transformer (I think we have more papers in this article with Transformer model than Transformers movies), but this one was an interesting little twist related to deployment and evaluation.
The model is based on the implementation SAS2Rec (from Wang-Cheng Kang and Julian McAuley). The recsys ingests the sequence of the items viewed, managed to categorize from a projection of the items embedding the items of the same category (based on their price, popularity, style and functionality).
![]()
I like this way of visualizing the embedding. But the most important parts of this article are:
- The deployment of this model in different areas of the globe seems to show different results and performance, which can make sense because the catalogue can be different, and the needs.
- They highlight that recall and ndcg are not so great for offline evaluation, and MRR (mean reciprocal rank) is adequate in their context.
PS: Wayfair seems to have a very solid techblog with plenty of subjects from AI to UI/UX.
Beyond and around the recommender systems
There is a compilation of exciting initiatives to improve your recommender system experiment.
Personalizing Benefits Allocation Without Spending Money (Booking.com)
The concept of discount recommendation is an exciting area for companies selling offers. For a booking company to be capable of keeping the user in the loop of their website for their entire travel is an excellent move to keep their client in the long term. The main issue with the discount is that potentially the company can lose money by doing too much or too significant discounts; the paper (mainly the presentation of the paper because the paper is pretty light) of booking discusses this aspect.
Behind the optimization of the discounting is using technics under the uplift modelling, which aims to predict the CATE (Conditional Average Treatment Effect). Then, on a more human working basis, try to predict the impact of a change without deploying, which is very similar to causal analysis and an excellent alternative to AB testing.

Even if the paper is not very detailed, Booking did a great job of democratizing their work:
- There is an excellent tutorial available on their tech blog on the subject of personalization HERE (uplift modelling HERE)
- They have a GitHub repository on a package called upliftML that can help to do some tests HERE.
That’s an exciting way to optimize tests and limit potential risks before deploying a test in production. However, I am still unsure how precise it can be before submitting the recommended discount (I need to read more on that).
Tools around recsys: Some interesting initiatives around better-explaining recommendations; it’s always been interesting to be more transparent with people using a recommender system for one of their projects.
RepSys: Framework for Interactive Evaluation of Recommender Systems (Czech Technical University in Prague)
Monitoring a recommender system, depending on the context (live or batch for the serving), can be overwhelming because you can compute many metrics, having a different level of aggregations and plenty of information to display. In this project, they propose a tool that can help to dive into the performance of the predictions in a very interactive way and also can simulate predictions by entering input data; there are some screenshots of the tool.
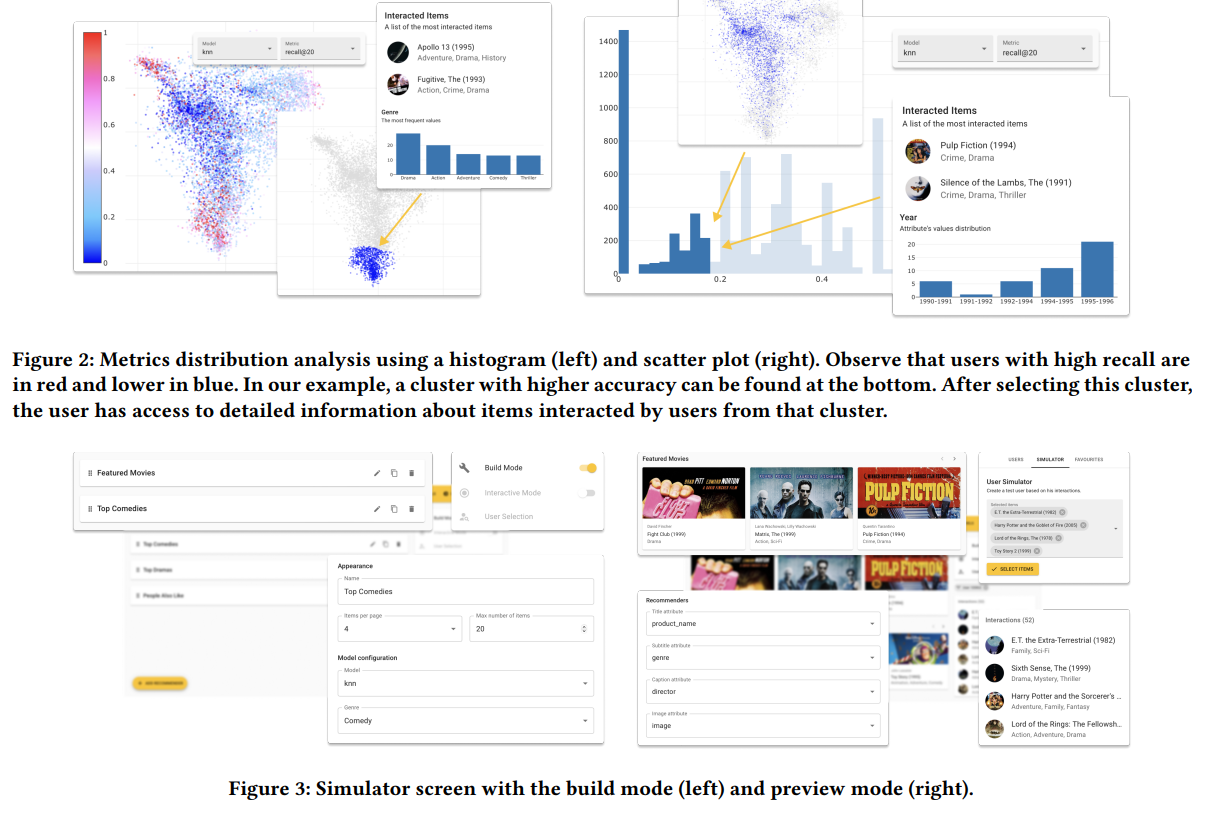
Honestly, for people working on monitoring tools/pipelines around recsys can be a good starting point to find metrics etc.
Who do you think I am? Interactive User Modelling with Item Metadata (University of Antwerp)
For this one, the tool is more to study the impact of a specific item in predicting recommendations. This paper is an excellent example of an interactive tool to help feature owners of a recommender system better understand the predictions produced by a recsys. There is a live demo here and a screenshot of the UI.
Under the hood, there is a model called TEASER, a hybrid recommender based on implicit feedback (it seems based on a model called EDLAE with a few twists in it).
Tech and framework highlight: A quick selection of articles related to tech and frameworks to build a recommender system.
TorchRec: a PyTorch domain library for recommendation systems (Meta)
This paper is very brief in the content, and I think it is a response to the TensorFlow recommenders package announced a few years ago at Recsys. Still, I think it is a perfect illustration of the weight of Pytorch in the community in 2022. Therefore, I am curious to see how this wrapper around PyTorch will be used in the future.
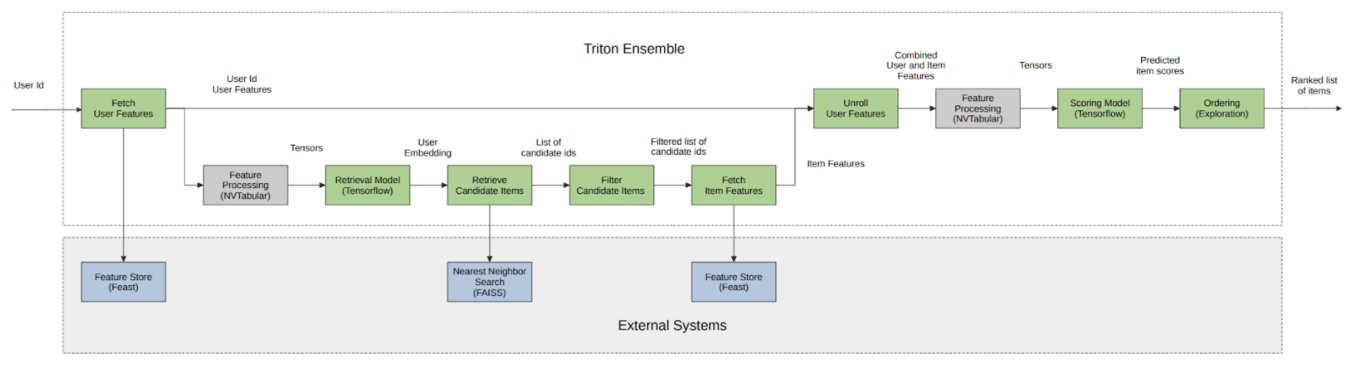
Building and Deploying a Multi-Stage Recommender System with Merlin (NVIDIA)
This one is an excellent compilation of the works of NVIDIA around their framework Merlin to operate deep learning recsys on production. This is a compilation of articles on their tech blog; they have an exemplary diagram for a four stages recommender system.
Tweak other things than your algorithm
There are more than algorithms to make great recommender systems; this section is a perfect example of things to try.
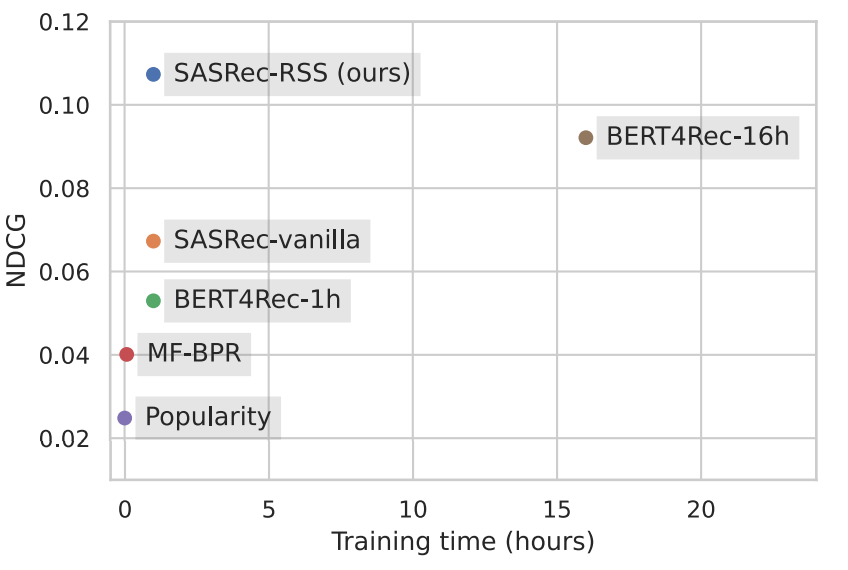
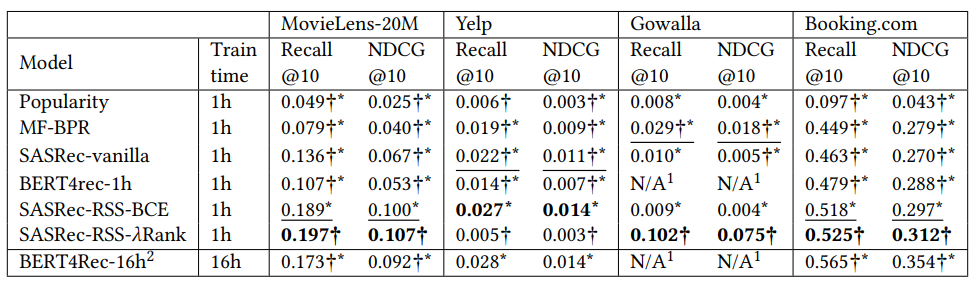
Effective and Efficient Training for Sequential Recommendation using Recency Sampling (Glasgow university)
An article that s making a great introduction to the landscape of recommender systems using deep learning technics and with a good comparison of models, precision VS training time (avoid the blue dot because it’s a spoiler).
The idea is to process the sequence of items by weighting them based on their position in the sequence and then apply classic deep learning techniques.
The model’s training was also limited to 1 hour, and they managed to build a model that seems more performant in most of their cases.
The experimentation on booking was not successful, but the constraint related to the location of the reservation (not in the model) could explain it.
Overall for me, that is currently levelling up on deep learning. However, I found this article a great source to start the idea of weighing the item with a simple function called Recency feature importance is pretty intelligent.

From my perspective, I also think that maybe weighting by popularity or age of the item is interesting also (because the most popular items recommender system is always a good start).
Don’t recommend the obvious: estimate probability ratios (Amazon)
This article illustrates the long tail problem and the impact of popularity bias in a recommender system. Furthermore, this approach offers a vision of reducing the popularity impact on the conception of a recommender system. the team tested different sampling strategies and wanted to illustrate the impact on metrics. Finally, there is an example of the production for the same model, but with different sampling strategies applied.
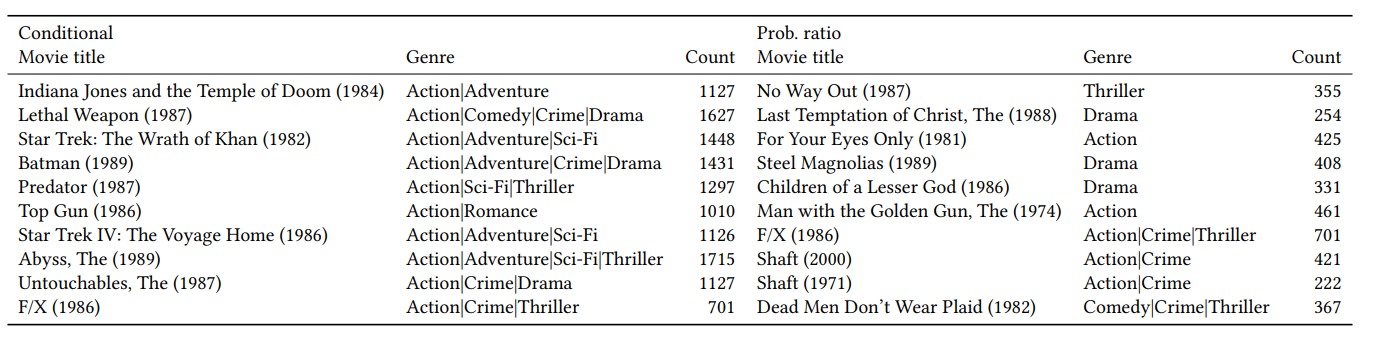
It can be constructive to serve niche users with specific tastes. Still, the article’s authors warn that it can also increase the risk of building harmful recommendations for the mass audience (always the trade-off of exploration VS exploitation).
Discovery Dynamics: Leveraging Repeated Exposure for User and Music Characterization (Deezer)
This article does not focus on recommender systems but illustrates a phenomenon widespread in music streaming platforms: the mere exposure effect. The formal definition of this effect is Users’ interest tends to rise with the first repetitions and attains a peak, after which interest will decrease with subsequent exposures, resulting in an inverted-U shape ).
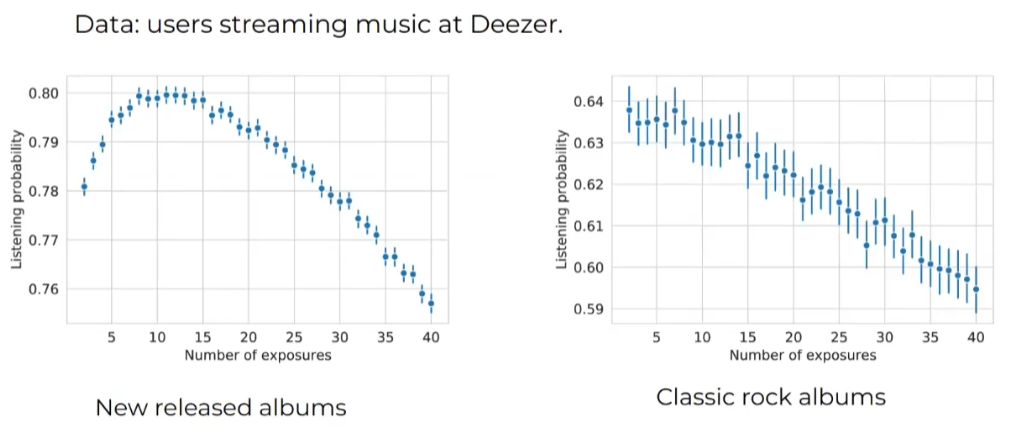
It’s particular to music streaming services, but I found it interesting to highlight because measuring this exposure is essential in the conception of recommender systems.
Towards the Evaluation of Recommender Systems with Impressions (Politecnico di Milano)
It can be related to the previous one in a way. Still, I like to see articles related to leveraging the impression/interaction of items as an input of recommender systems, with a list of models that could be a good starting point.
The cool misfits
Sometimes you cannot put things in boxes, and these articles are part of this mantra.
Optimizing product recommendations for millions of merchants (Shopify)
This presentation/paper shows their approach to building recommender systems as a service that can help millions of merchants on their platform.
The approaches used behind are simple on paper (frequently bought together, similar items, items from similar collections). Their test at the shop seems to be 50/50 splits with AA tests (a perfect illustration of their approach in the following table).
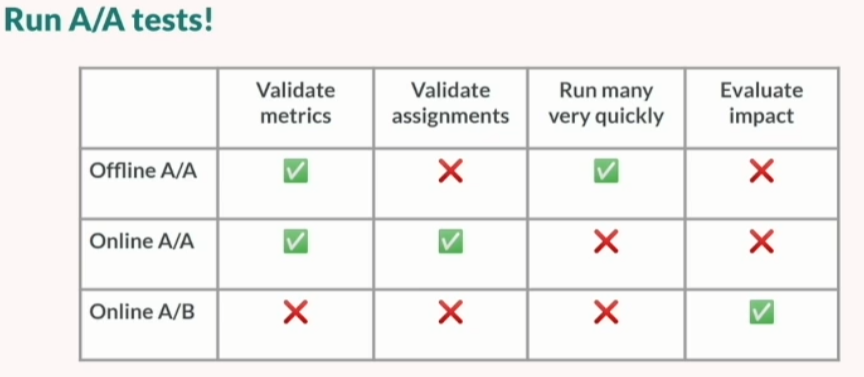
Their use case is particular, but they have some nifty strategies to test on different segments and play on different models on the tiles of a shop (Multi-arm bandit is your friend)
And I just realized that this is Kim Falk from the book practical recommender systems at manning.
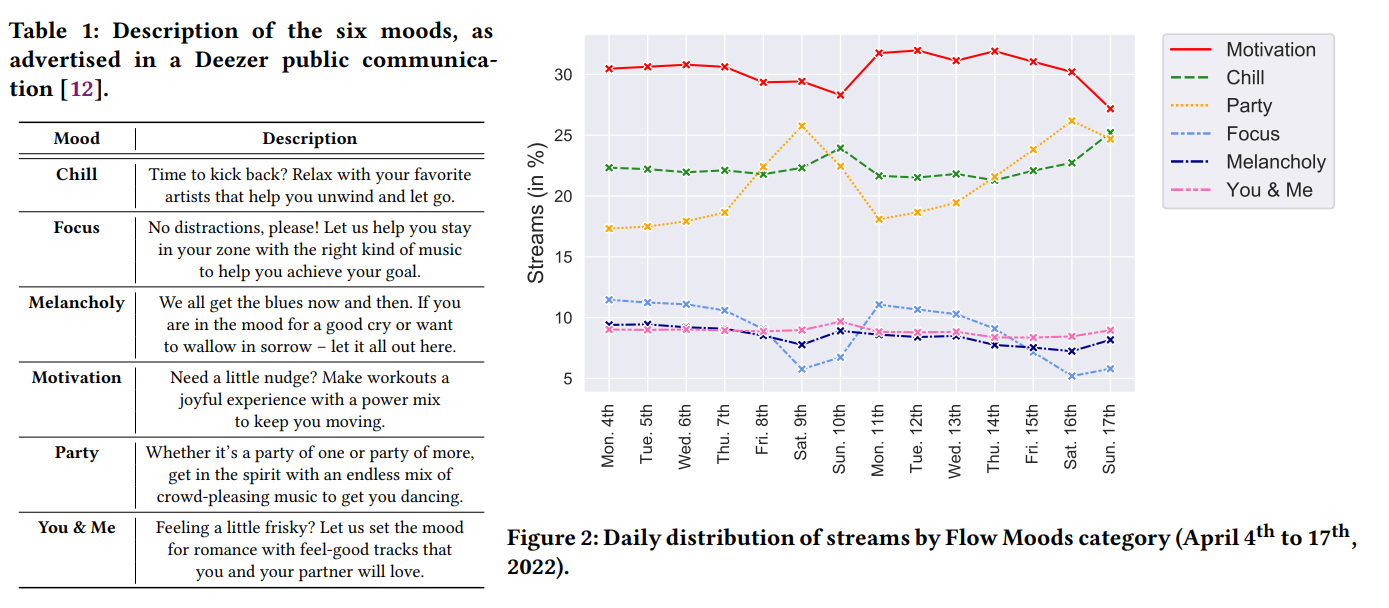
Flow Moods: Recommending Music by Moods on Deezer (Deezer)
Usually, Deezer is coming at Recsys with super papers; as usual, this one is cool (I think my favourite). First, they explain the process behind their Flow feature: building recommendations based on your data and a mood input by the user (6 values are possible ).
They seem to have labelled songs with music experts with these moods and built classifiers with this data. The processing of the song is done with musicnn, and they have built one classifier per mood that will create data for the playlist generation.
Some analysis of the song consumption based on the day of the week is fascinating to watch, with some peak of party songs during the weekend and focus play less and less during the weekdays.
Recsys Challenge, what happened?
This year the recsys challenge was around “fashion recommendations; given a sequence of item views, the label data for those items, and the label data for all candidate items, the task is to predict the item purchased in the session.”
The challenge was organized with dressipi and if you want to learn more about the competition and the data setup, look at their website; it’s well documented (and there is also the paper).
There is the top3 submission of this competition:
#3: A Diverse Models Ensemble for Fashion Session-Based Recommendation (Nvidia)
The king has fallen … to the third place :), a fantastic approach around mixing different kinds of models and architecture in a 3 stage recommender system (cf picture)
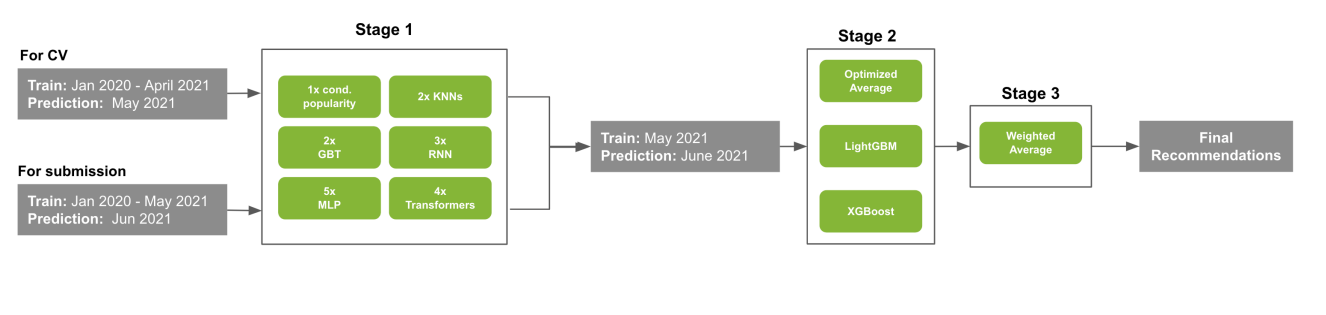
A terrific way to build recommendations if you want my opinion, and it could fit in batch recommendations (because in a live context, it could be tricky to use in terms of latency and scale).
#2: Session-based Recommendation with Transformers (layer6)
The transformer sees the way to go; this team tried multiple kinds of architecture and models.
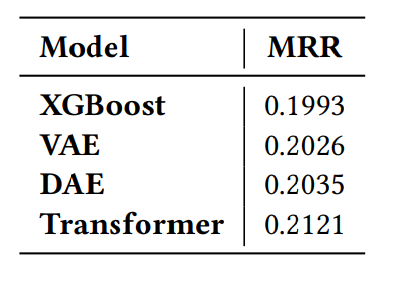
Unfortunately, at the moment of the writing of this recap, the paper is not available freely like the other one, so it’s going to be a guess that there is no transformer on this one, more graph neural network and tree.
Wrap-up
Unfortunately, I didn’t participate in the workshops live like last year, but globally there are the main takeaway from this edition of the recsys conference.
![]()
They seem to have made their place everywhere (except at the first place on the leaderboard of the challenge 😜), it’s an excellent approach; I recently found a great highlight from Andrew Trask on one of the elements behind Transformer called attention, so I think it could be a great start to learn more on the theory.
But overall, if I wanted to pick my top 3 articles of this conference, I would highlight:
- Flow mood from Deezer
- Search engine based on the visual preferences of Shutterstock
- Recency sampling from sequence recommendations from Glasgow’s university
The conference, as usual, was incredible and gave great ideas for future projects.







{kind=link}