
Créer un système de prévision de la consommation énergétique nationale française
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Bonjour lecteurs, pour cet article je vais expliquer mon approche pour créer un système de prévision de la consommation énergétique française (métropolitaine). Ce type de problème est plus ou moins lié à une partie de mon travail chez EDF Energy mais ce travail a été fait sur mon temps libre pour compléter mon nanodegree d’ingénieur en machine learning de Udacity.
Dans cet article, il y aura une description des données utilisées pour ce projet, une explication de l’approche utilisée pour faire une prévision quotidienne de la consommation et la version demi-horaire.
Exploration du jeu de données
Dans ce cas, les données pour créer le modèle proviennent de :
- RTE, le gestionnaire du réseau énergétique en France qui a créé une plateforme de données ouvertes pour accéder à différents jeux de données sur le réseau
- Le jeu de données GEOFLA qui donne des informations sur le nombre d’habitants dans la ville et la surface
- Weather underground. J’ai dû scraper cette source de données depuis le site web (j’ai concentré mon scraping sur les stations météo des aéroports) et j’ai choisi les stations météo qui ont assez de données pendant la période mesurée par RTE. J’ai concentré mon analyse de données sur la température extérieure et la vitesse du vent.
Pour les conditions météorologiques, j’ai choisi de créer un jeu de données météo national où en gros chaque région a sa station météo associée. Ces stations sont pondérées par le nombre de personnes qui sont dans cette région (cette information provient du jeu de données GEOFLA). Pour faire l’analyse de données, j’ai choisi de convertir la puissance moyenne consommée de RTE en énergie (en MWh).
Dans la figure suivante il y a une illustration de l’énergie moyenne consommée en France au cours des dernières années.
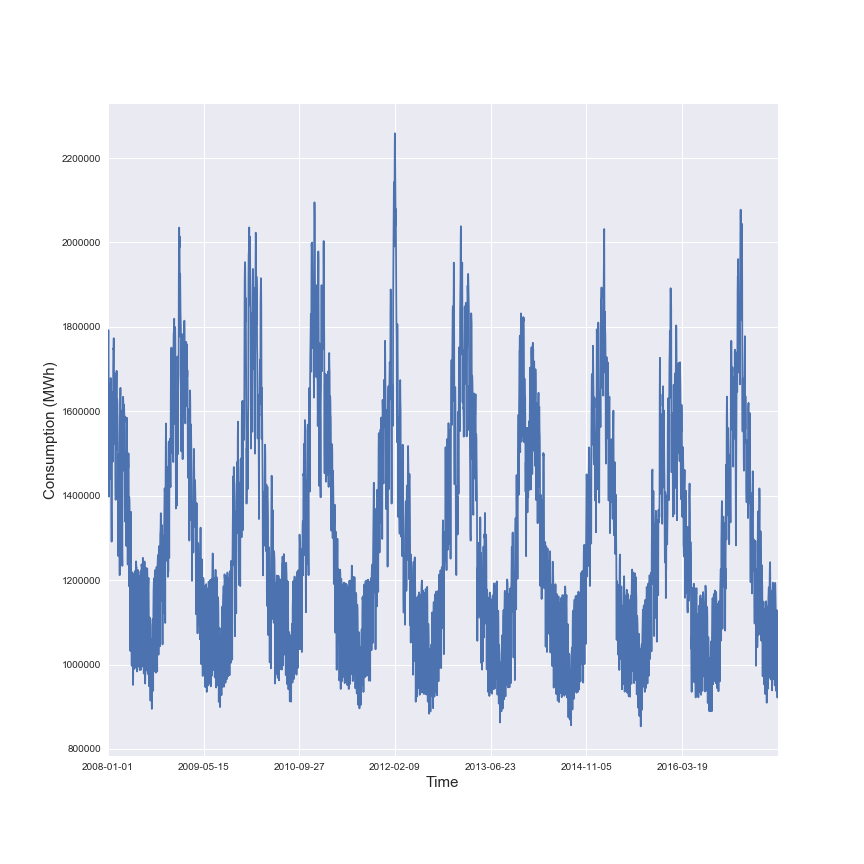
Cette figure illustre la saisonnalité dans la consommation énergétique en France.
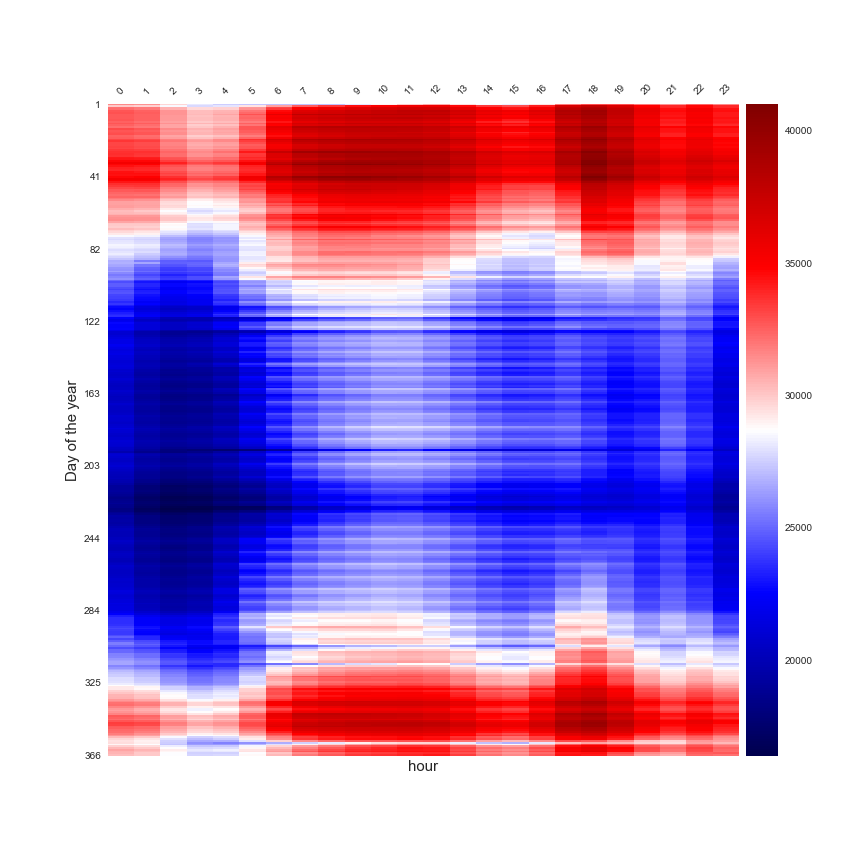
Après cela pour faire la prévision à l’échelle quotidienne, je dois agréger les données. Dans les figures suivantes, il y a une représentation des données quotidiennes agrégées à différentes échelles dans une heatmap.
Une étude de l’effet horaire en fonction du jour de l’année
Une étude de la consommation du mois de l’année et du jour de la semaine.
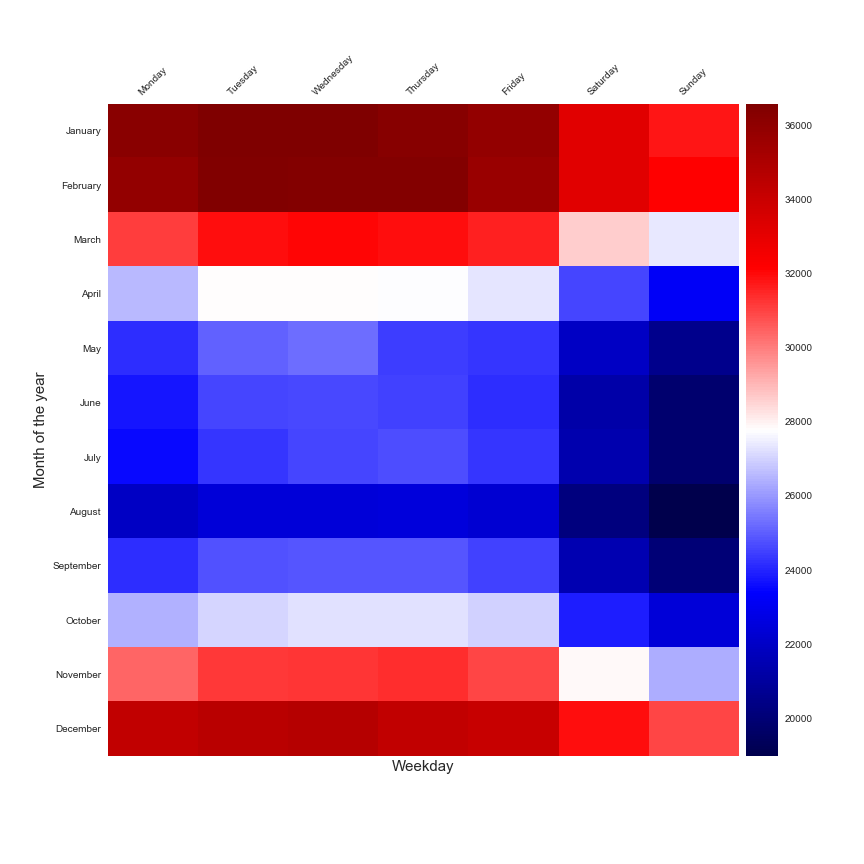
Ces deux figures sont parfaites pour illustrer que la consommation quotidienne est liée au moment de l’année et au jour de la semaine. Mais ces aperçus ne sont pas suffisants pour créer un modèle de prévision. Une approche très populaire qui est utilisée pour faire une prévision de la consommation énergétique est l’étude de la consommation quotidienne en fonction de la température extérieure moyenne quotidienne. Cette technique est appelée PTG pour Power Temperature Gradient et vous pouvez trouver beaucoup de publications qui sont basées sur cette approche.
Dans la figure suivante il y a une représentation de ce modèle utilisé pour la prévision.
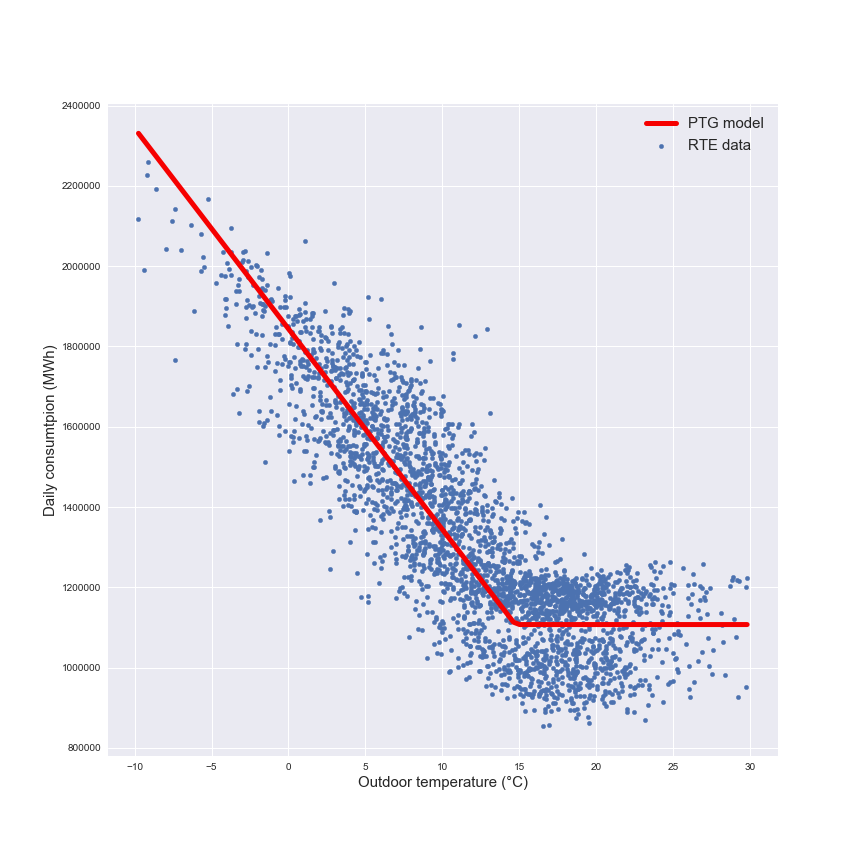
Le modèle est une régression par morceaux avec une partie hivernale représentée par la régression linéaire (qui inclut les besoins de chauffage et les appareils) et une partie estivale avec la partie constante (seulement les appareils). Ce modèle sera le modèle de référence pour la prochaine partie.
Prévision quotidienne
Pour créer le modèle, le jeu de données sera divisé entre ensemble d’entraînement et ensemble de test, la sélection des échantillons pour les ensembles sera randomisée. Cela représente :
- 2337 échantillons pour l’ensemble d’entraînement
- 585 échantillons pour l’ensemble de test
C’est un problème de régression, donc les modèles suivants de scikit learn vont être testés :
- Régresseur polynomial
- Régresseur de forêt aléatoire
- Régresseur d’arbre de décision
- K plus proches voisins
- Régresseur de réseau de neurones MLP
C’est une sélection personnelle de différents modèles et il y a plein d’autres modèles à essayer mais pour un début je pense que c’était suffisant. Je dois régler les différents modèles et trouver les meilleurs paramètres à utiliser. J’ai utilisé une approche k-fold sur l’ensemble d’entraînement (j’ai créé dix plis) pour tester les différents paramètres. Je vous invite à consulter mon rapport pour voir les choix faits sur les paramètres pour les différents modèles.
Pour tester l’impact de l’entrée dans les modèles, j’ai testé différentes entrées :
- seulement la température extérieure
- température extérieure et vitesse du vent
- température extérieure et mois de l’année et jour de la semaine
Pour faciliter l’utilisation des entrées je dois normaliser les ensembles. Pour évaluer la précision du modèle j’ai utilisé la métrique r²score qui est utilisée pour les problèmes de régression. Mais cette métrique n’est pas suffisante pour évaluer la qualité de l’algorithme. La deuxième métrique que j’utiliserai est le temps pour créer le modèle. Dans le tableau suivant il y a l’évolution du r²score en fonction du modèle utilisé.
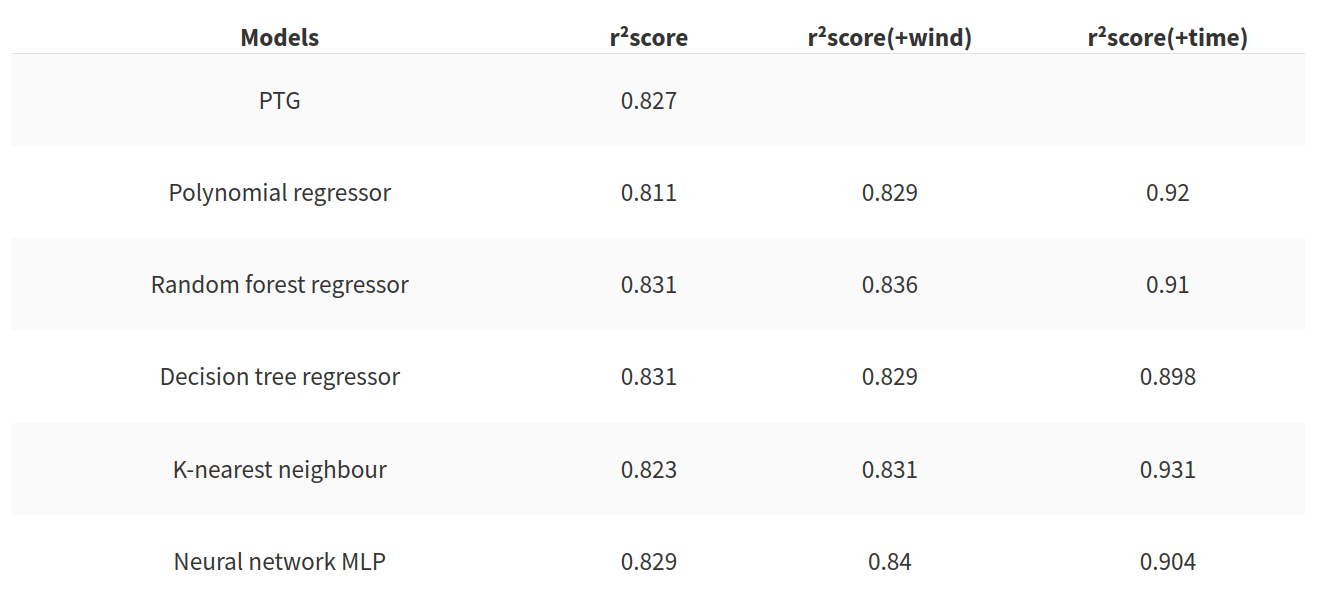
Ce tableau nous permet de tirer les conclusions suivantes :
- Le PTG est un assez bon modèle. Pour un modèle basé uniquement sur la température extérieure, le score est bon mais les modèles basés sur les arbres et le réseau de neurones offrent aussi de bons résultats
- l’ajout de la vitesse du vent améliore le score mais le gain est très petit
- l’ajout offre un gain intéressant au score pour chaque modèle testé
Mais comme je l’ai dit précédemment le r²score n’est pas suffisant, dans le tableau suivant il y a le temps pour créer le modèle dans le cas de l’ajout des caractéristiques temporelles aux entrées initiales.
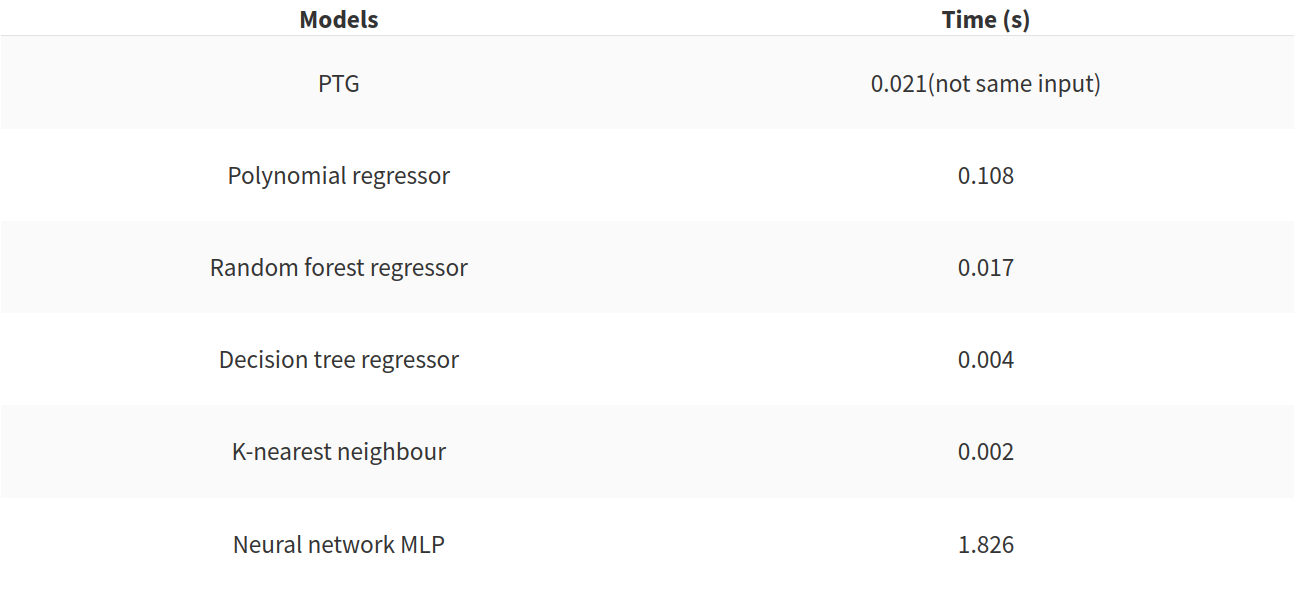
Ce tableau illustre que le PTG a de bonnes performances, et que le réseau de neurones est très mauvais en termes de vitesse. Le régresseur polynomial devrait être évité aussi. Mais ces deux métriques ne sont pas suffisantes pour évaluer l’efficacité des modèles. L’impact de la taille de l’ensemble d’entraînement devrait être étudié. Dans la figure suivante, il y a une illustration de l’impact de l’ensemble d’entraînement.
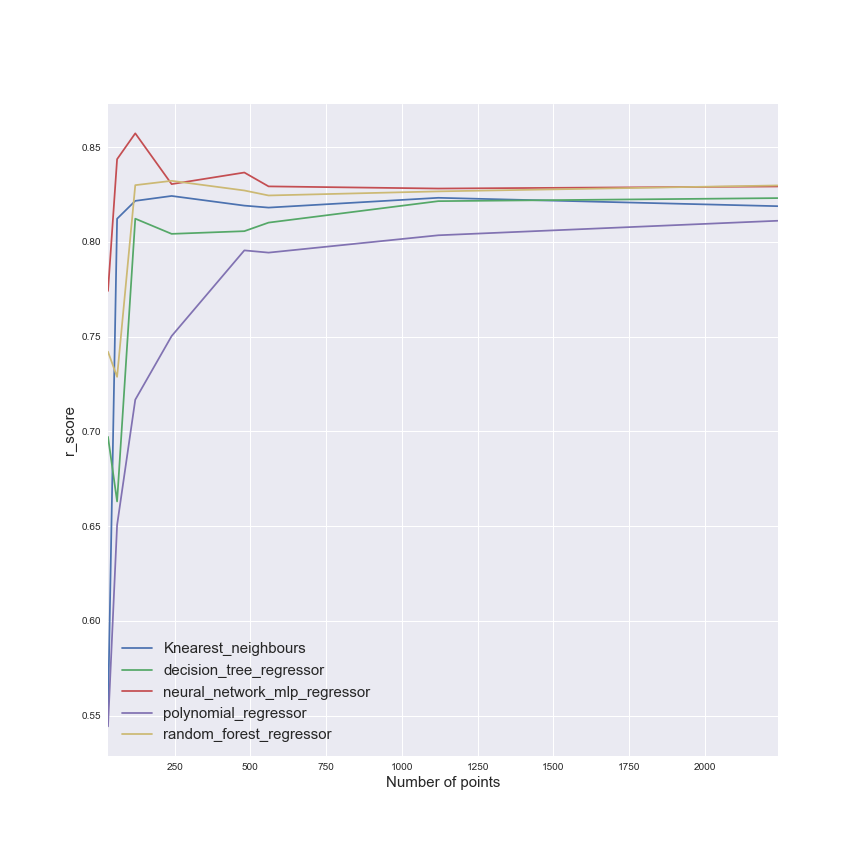
Cette figure nous montre que la taille de l’ensemble d’entraînement a un impact clair sur le régresseur polynomial, tandis que d’autres modèles semblent moins impactés (le réseau de neurones montre une bonne efficacité assez rapidement).
Prévision demi-horaire
Pour cette partie, nous utiliserons tous les résultats trouvés précédemment (l’utilisation des caractéristiques temporelles essentiellement). Je testerai les mêmes modèles que pour la prévision quotidienne et utiliserai les mêmes métriques.
Mon modèle de référence sera le modèle ARIMA. Ce modèle est assez populaire pour prévoir les séries temporelles (mais nécessite de ne pas randomiser les ensembles). Ces ensembles sont composés de :
- 112176 échantillons pour l’ensemble d’entraînement
- 28080 échantillons pour l’ensemble de test
Dans mon problème les résultats du modèle sont mauvais. Dans le tableau suivant il y a un résumé des résultats du modèle de référence et des autres modèles testés.
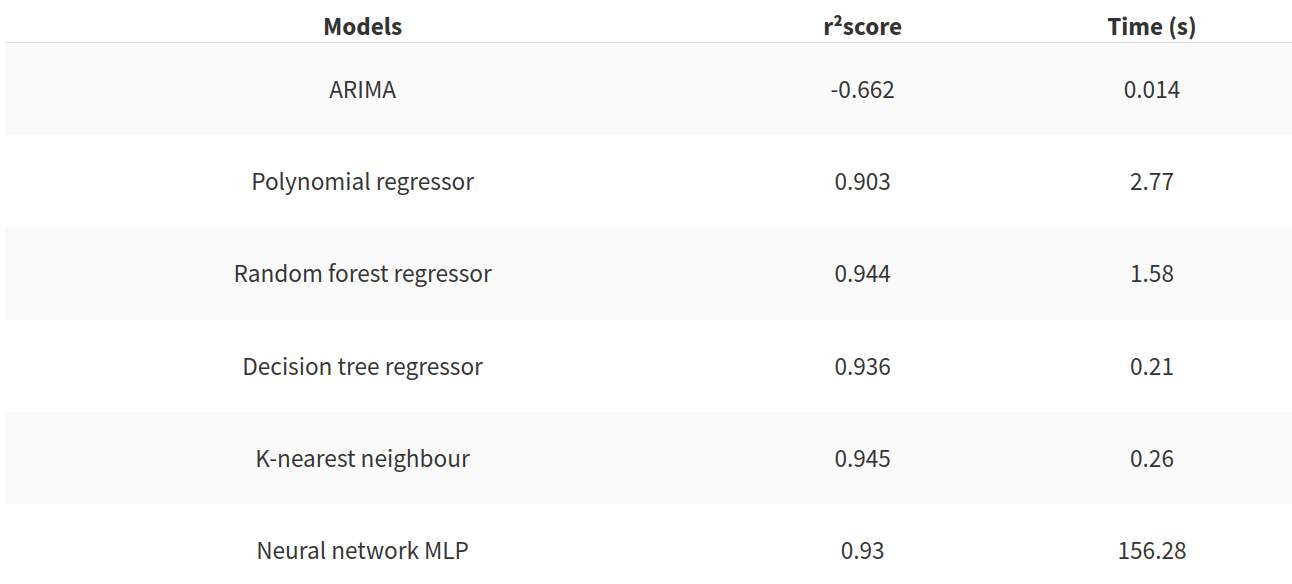
Ce tableau final nous montre que le modèle de référence est assez facile à battre. Le réseau de neurones est très lent à construire mais deux modèles semblent très bons à utiliser pour notre problème :
- le régresseur d’arbre de décision
- le K plus proches voisins
Conclusion
Ce travail a été utilisé pour compléter mon nanodegree. C’est mon approche, pas la seule, et je pense qu’il y a beaucoup de choses à essayer comme une approche de deep learning ou une approche d’apprentissage par renforcement par exemple.
Je vous invite à utiliser les jeux de données de ce projet pour essayer de créer votre propre (meilleur ?!) modèle et si vous avez des commentaires, écrivez-les ci-dessous.
Références
- Udacity — udacity.com
- Plateforme open data RTE — rte-opendata.opendatasoft.com
- Jeu de données GEOFLA — professionnels.ign.fr
- Weather Underground — wunderground.com
- Article PTG (IBPSA) — ibpsa.org
- Régresseur polynomial (scikit-learn) — scikit-learn.org
- Régresseur de forêt aléatoire (scikit-learn) — scikit-learn.org
- Régresseur d’arbre de décision (scikit-learn) — scikit-learn.org
- K plus proches voisins (scikit-learn) — scikit-learn.org
- Régresseur de réseau de neurones MLP (scikit-learn) — scikit-learn.org
- Rapport nanodegree ML Udacity — GitHub
- ARIMA for Time Series Forecasting with Python — machinelearningmastery.com
- Jeux de données udacity_mlen — GitHub