
Analyse des certificats de performance énergétique avec Dataiku DSS
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Depuis que j’ai publié l’article sur les compteurs intelligents de Londres et les analyses possibles des données, je reçois régulièrement des messages de personnes intéressées par la connexion des données des compteurs intelligents et l’efficacité énergétique des moniteurs de ménages. J’ai écrit dans cet article qu’il n’y a pas de moyen direct de connecter les données des compteurs intelligents, l’ACORN et l’efficacité énergétique du ménage mais il y a encore des choses intéressantes à faire avec d’autres datasets autour de l’énergie et de l’efficacité énergétique d’un ménage.
J’ai voulu pendant longtemps faire un article sur un outil intéressant que j’ai testé dans mon précédent emploi, qui s’appelle DSS de Dataiku, qui est très intéressant pour les personnes qui travaillent avec des données. Dans cet article, je vais présenter cet outil et ces autres datasets.
Qu’est-ce que Dataiku DSS
Dataiku DSS est un produit développé par la société française Dataiku qui est défini sur leur site web comme une “plateforme logicielle collaborative de data science pour les équipes de data scientists, d’analystes de données et d’ingénieurs pour explorer, prototyper, construire et livrer leurs propres produits de données plus efficacement”.
Pour faire simple, c’est un outil pour simplifier le traitement et le partage de données/modèles dans une entreprise. Je vous invite vraiment à jeter un œil sur leur site web qui décrit beaucoup de cas d’usage et les fonctionnalités de la plateforme. Mais ce qui est important à savoir, c’est qu’il y a deux types d’éditions de la plateforme :
- L’édition gratuite : que j’utilise pour ce projet qui est hébergée sur ma machine (mais il y a une version qui peut être hébergée gratuitement sur le serveur Dataiku aussi)
- L’édition entreprise : qui offre plus de connecteurs de données (Hive, etc.) et moins de limitations. Il n’y a pas de prix annoncé sur le site car je pense que c’est basé sur les besoins du client, mais d’après les rumeurs que j’ai entendues, ce n’est pas bon marché. Mais il y a un essai gratuit de 2 semaines pour tester le service.
L’installation de l’édition gratuite est très simple et vous pouvez l’installer sur tous les OS possibles. Je vais plonger dans les fonctionnalités du logiciel après la présentation des données.
Décrire les données
Pour ce projet, je vais utiliser les sources de données suivantes :
- EPC : C’est une collection de plusieurs certificats de performance au Royaume-Uni (environ 15 millions)
- Données Nomis : Site web qui est une collection de plusieurs informations au Royaume-Uni collectées lors des différents recensements (le plus récent est celui de 2011)
Voyons une description plus détaillée des datasets.
EPC
Donc d’abord, qu’est-ce qu’un EPC ? C’est assez simple, c’est une évaluation de la performance énergétique d’un ménage. Il y a un exemple dans la figure suivante.
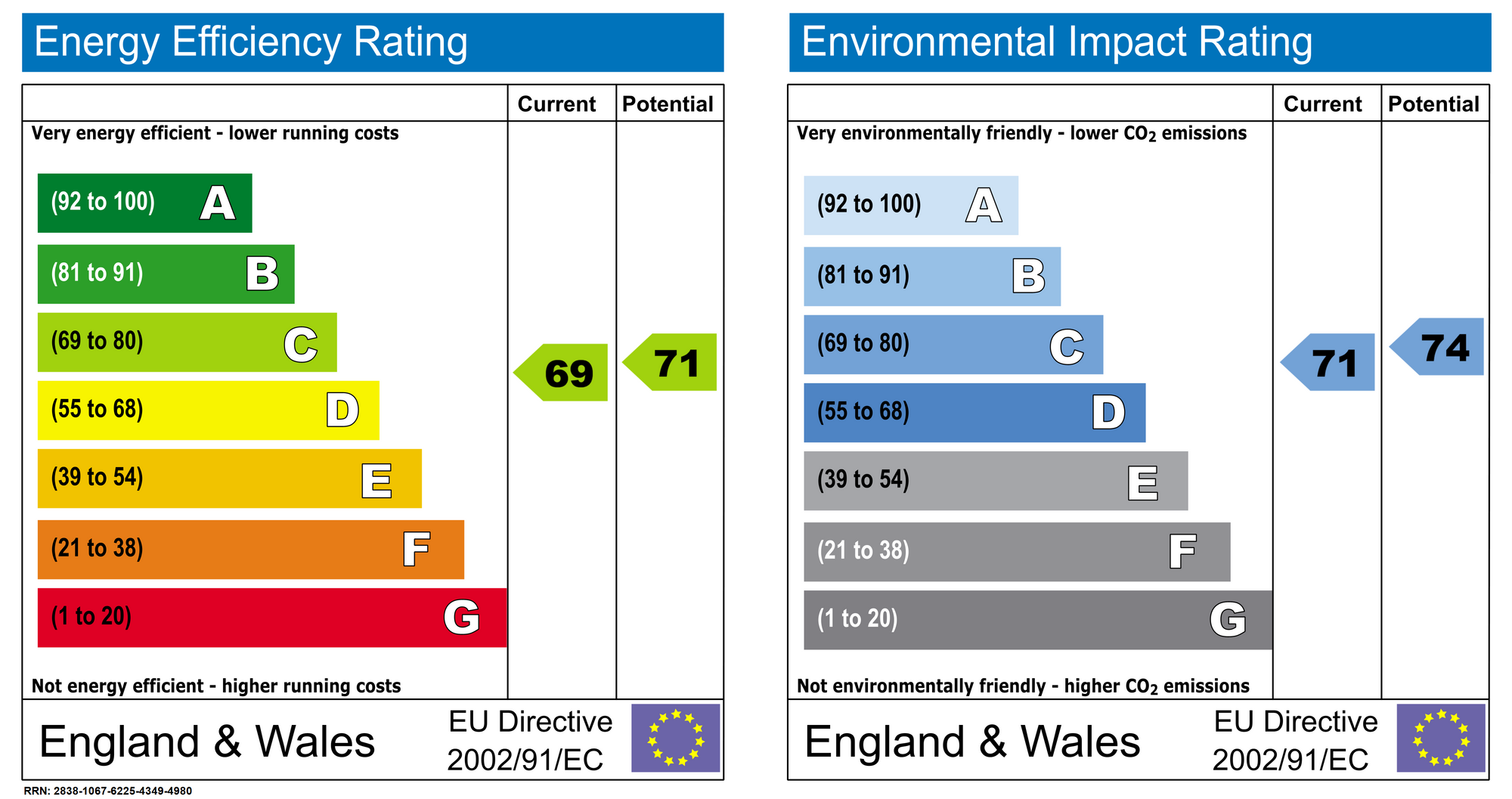
C’est comme celui qu’on peut trouver sur les appareils électroménagers par exemple, et il doit être actualisé pour chaque nouveau locataire ou propriétaire. La source de données qui est ouverte par le Ministry of Housing, Communities & Local Government est très complète (plus de 15 millions de certificats), et il y a plus qu’une simple note dans ces données (dictionnaire de données). Il y a des informations sur le vitrage, la consommation d’énergie, la surface au sol, etc.
Données Nomis
Le site web Nomis “est un service fourni par l’Office for National Statistics, ONS, pour donner un accès gratuit aux statistiques les plus détaillées et les plus récentes du marché du travail britannique à partir de sources officielles”, et sur ce site web il y a plusieurs informations sur les citoyens britanniques collectées lors de différents recensements. Il y a plusieurs informations avec un bon niveau de détail et les données des recensements sont principalement utilisées pour créer le groupe ACORN qui a été défini dans mon article sur le compteur intelligent.
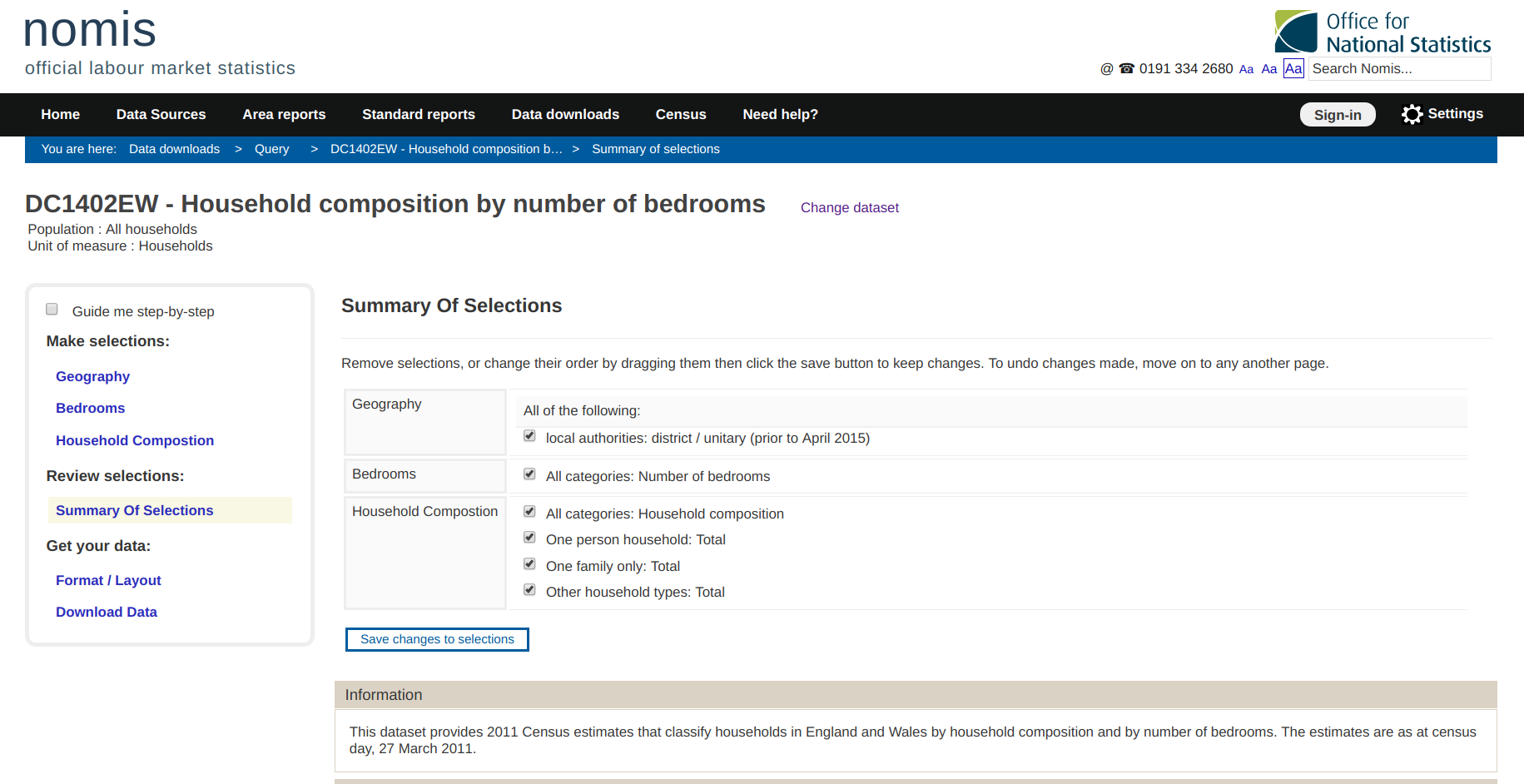
De ce portail, j’ai extrait des informations sur les citoyens britanniques au niveau du district sur leur :
- Occupation
- Qualification
- NS-SEC (National Statistic-Socio Economic Classification)
- Population
Commençons maintenant Dataiku DSS.
Traitement des données dans DSS
Toutes les données extraites pour ce projet sont des fichiers CSV. Dans l’animation suivante, il y a une illustration du processus pour créer un dataset dans DSS.
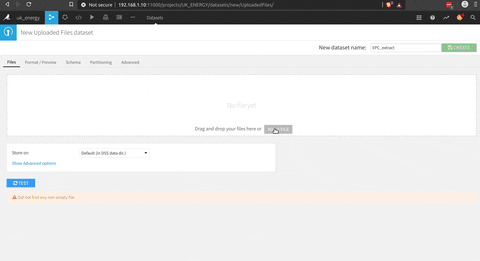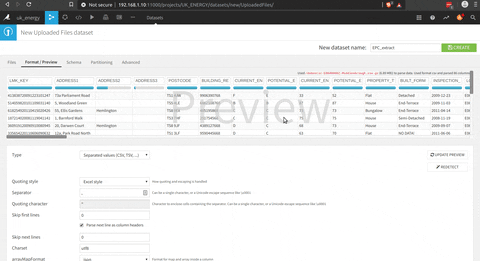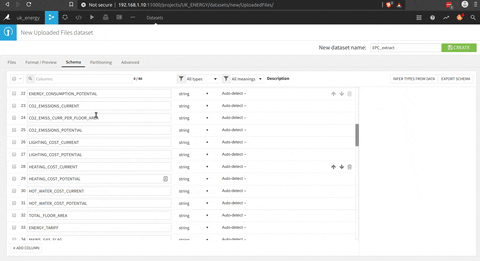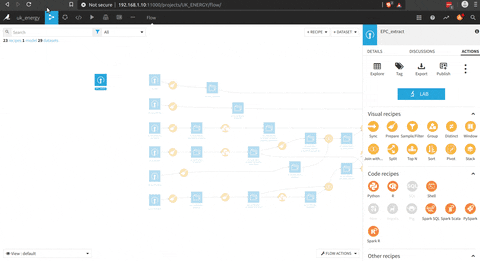
Les fichiers peuvent être facilement glissés-déposés dans DSS, et vous pouvez avoir un aperçu des données, de la qualité, etc. Dans la version gratuite, une base de données SQL peut être connectée aussi et c’est très facile.
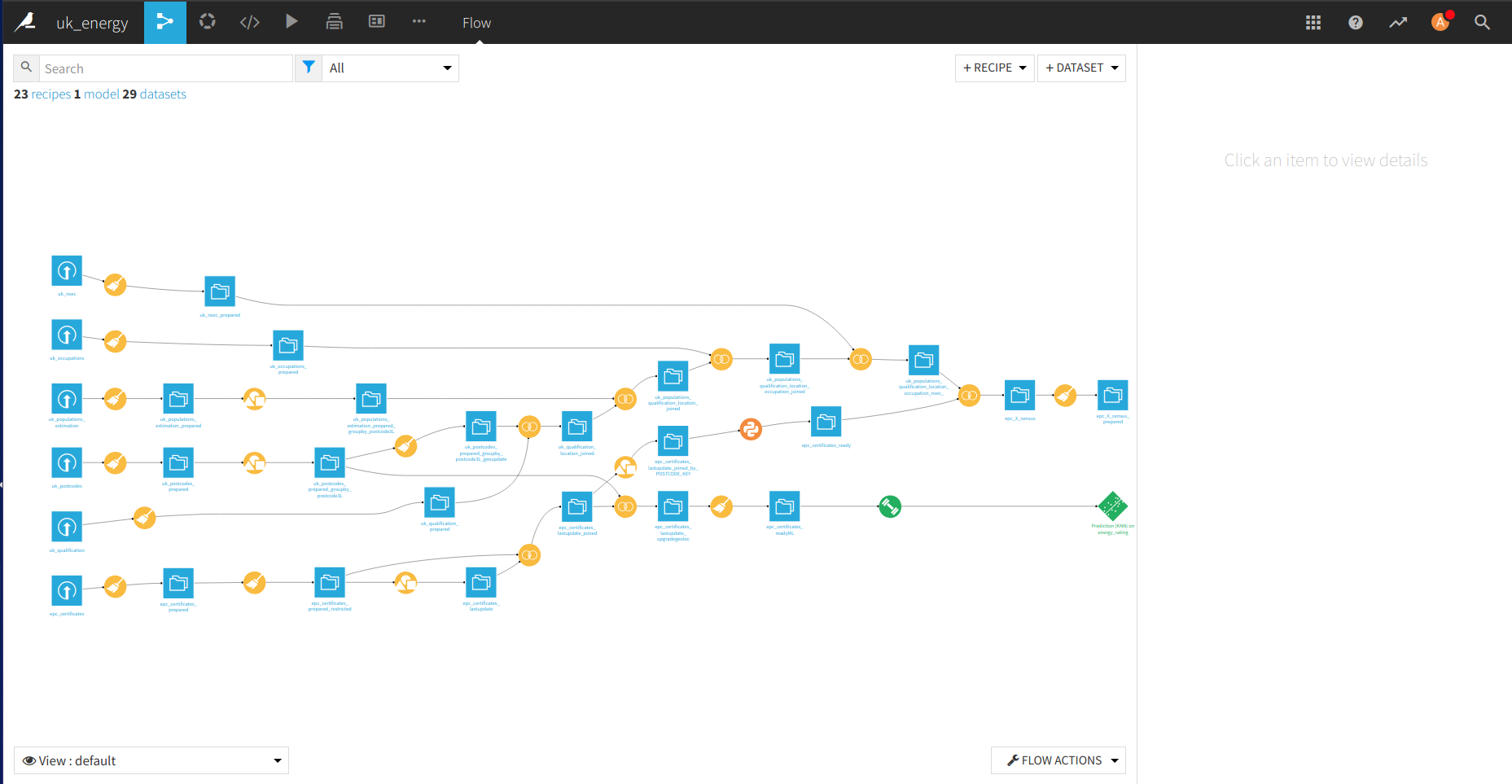
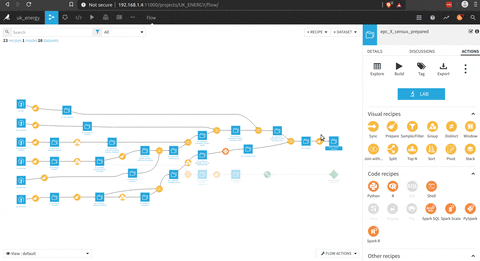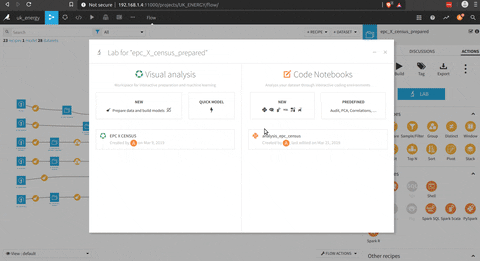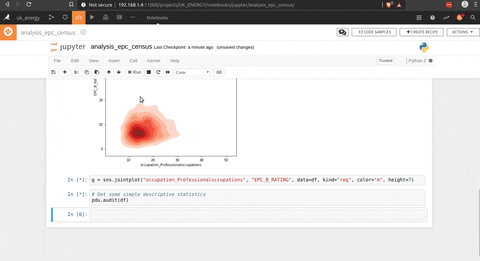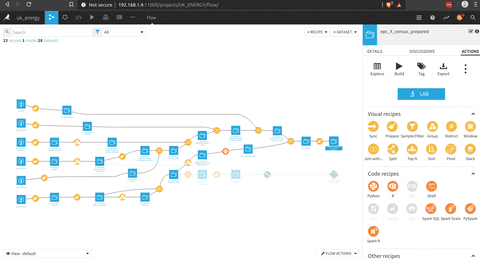
Pour ce projet, l’idée est de connecter les données de l’EPC et les données Nomis, donc il y a une grande partie de traitement des certificats pour être agrégés au niveau du district et être connectés aux données Nomis.
Il y a un aperçu du processus complet.
Dans la figure suivante, il y a le processus pour préparer le dataset EPC qui pourrait être connecté avec les données Nomis.
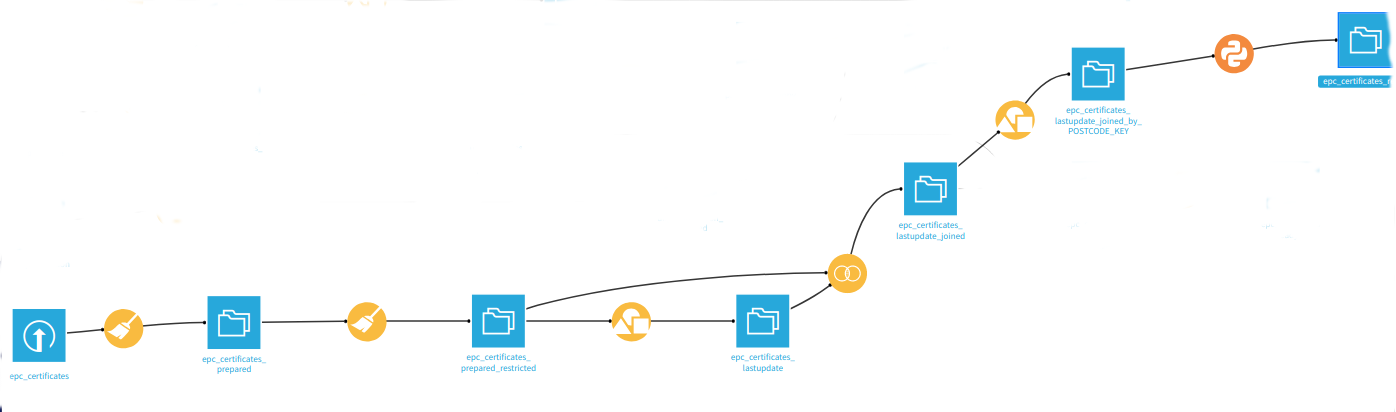
Il y a une phase de préparation (avec la brosse) où il y a une sélection des bonnes colonnes, un traitement du code postal pour obtenir le code du district.
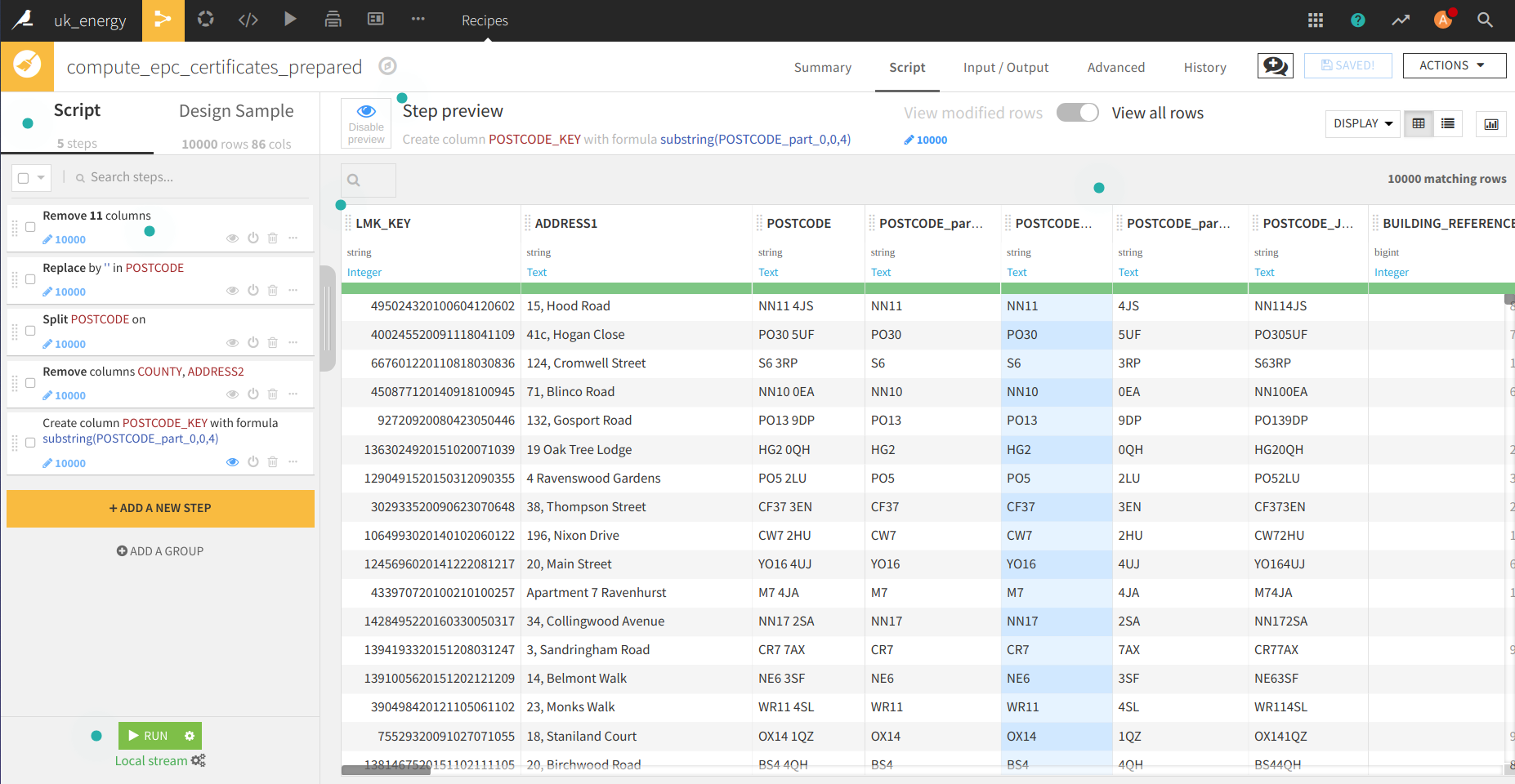
Une deuxième étape qui aurait pu être mise avec la précédente est de préparer le dataset pour trouver l’EPC le plus récent du ménage (format correct de la date d’inspection).
Pour obtenir la dernière date d’inspection de chaque ménage dans le dataset, il y a une fonction group by (l’icône carré triangle cercle sur l’image du processus). Il y a une illustration du processus dans l’animation suivante.
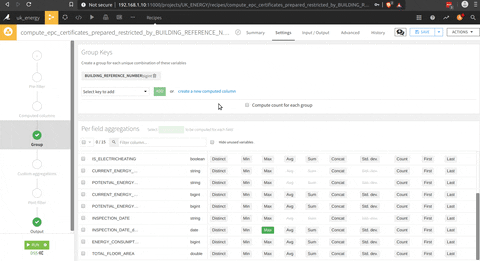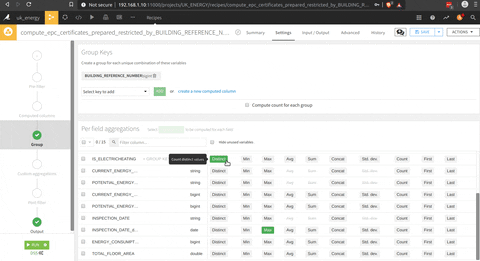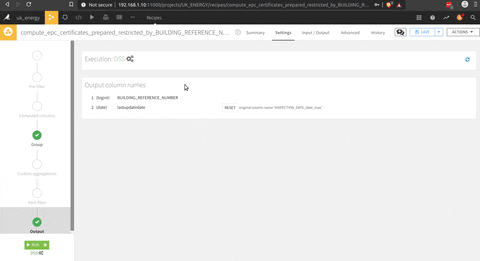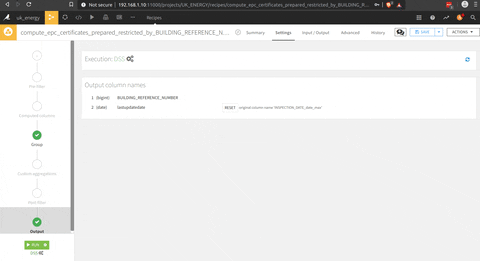
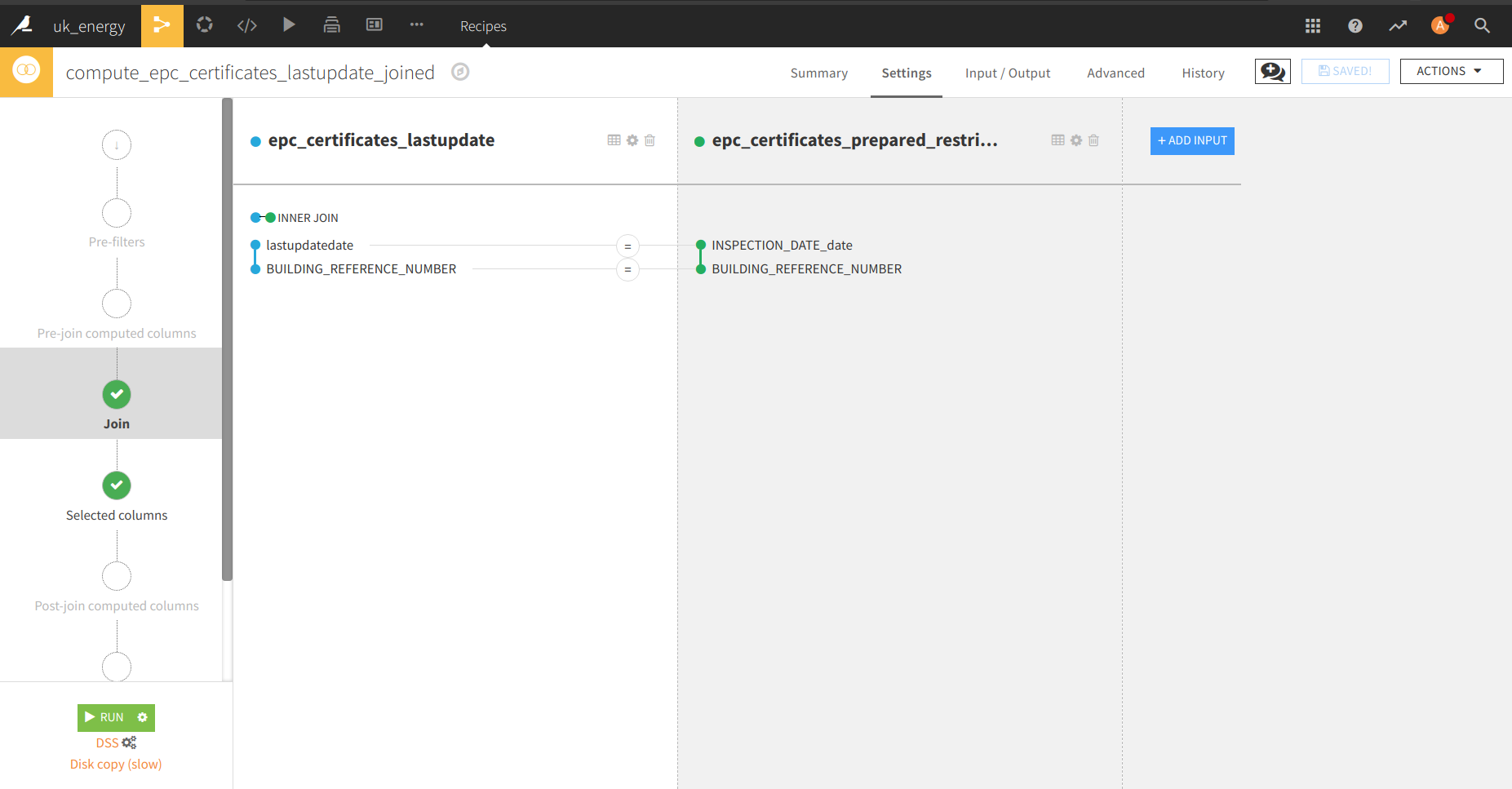
Maintenant que nous avons l’EPC nettoyé, et une liste des dernières dates d’inspection pour chaque ménage dans une autre table, une jointure entre ces deux datasets avec la fonction join (le logo join dans le processus). Il y a une présentation du menu de la jointure où vous pouvez sélectionner la clé de jointure et les colonnes sélectionnées.
Et enfin, il y a une fonction group by par district, type de ménage, type de système de chauffage et note EPC.
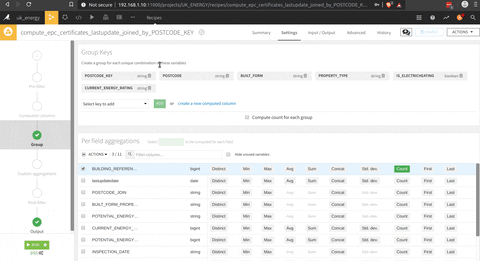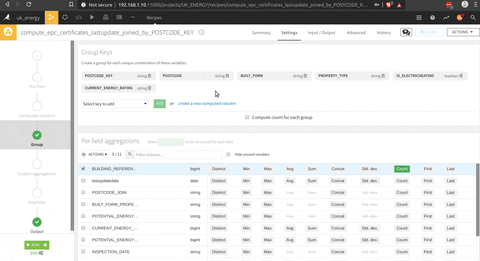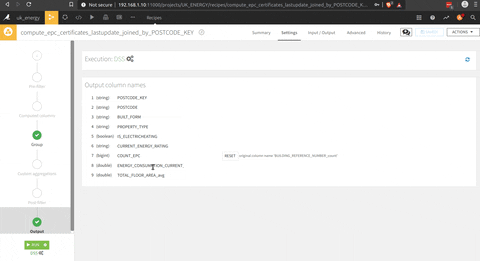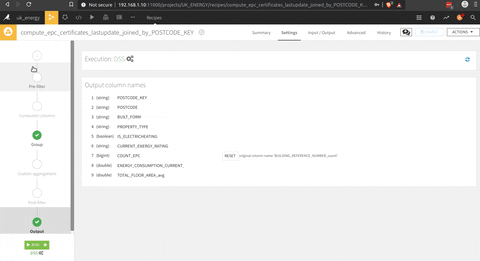
Et la dernière étape est le script Python pour obtenir des informations agrégées au niveau du district avec la fonction pivot de pandas (compte d’EPC par note et type de ménage), mais j’aurais pu utiliser la fonction pivot de DSS.
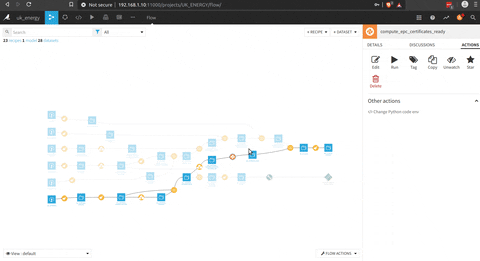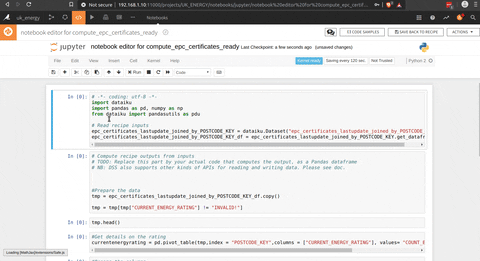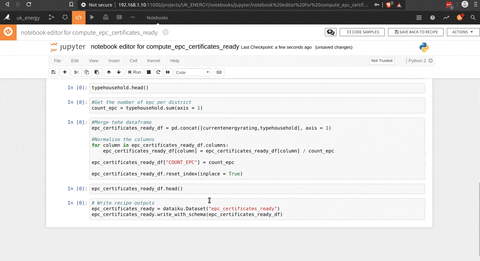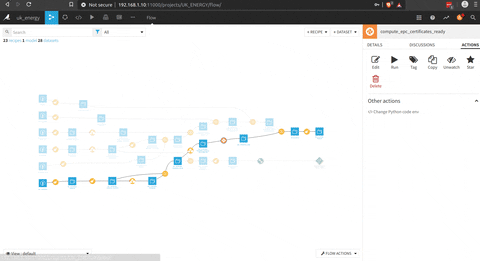
Et voilà, nous avons les données de l’EPC agrégées au niveau du district, ce qui nous donne des connaissances sur la note du ménage et le type de ménage à ce niveau.
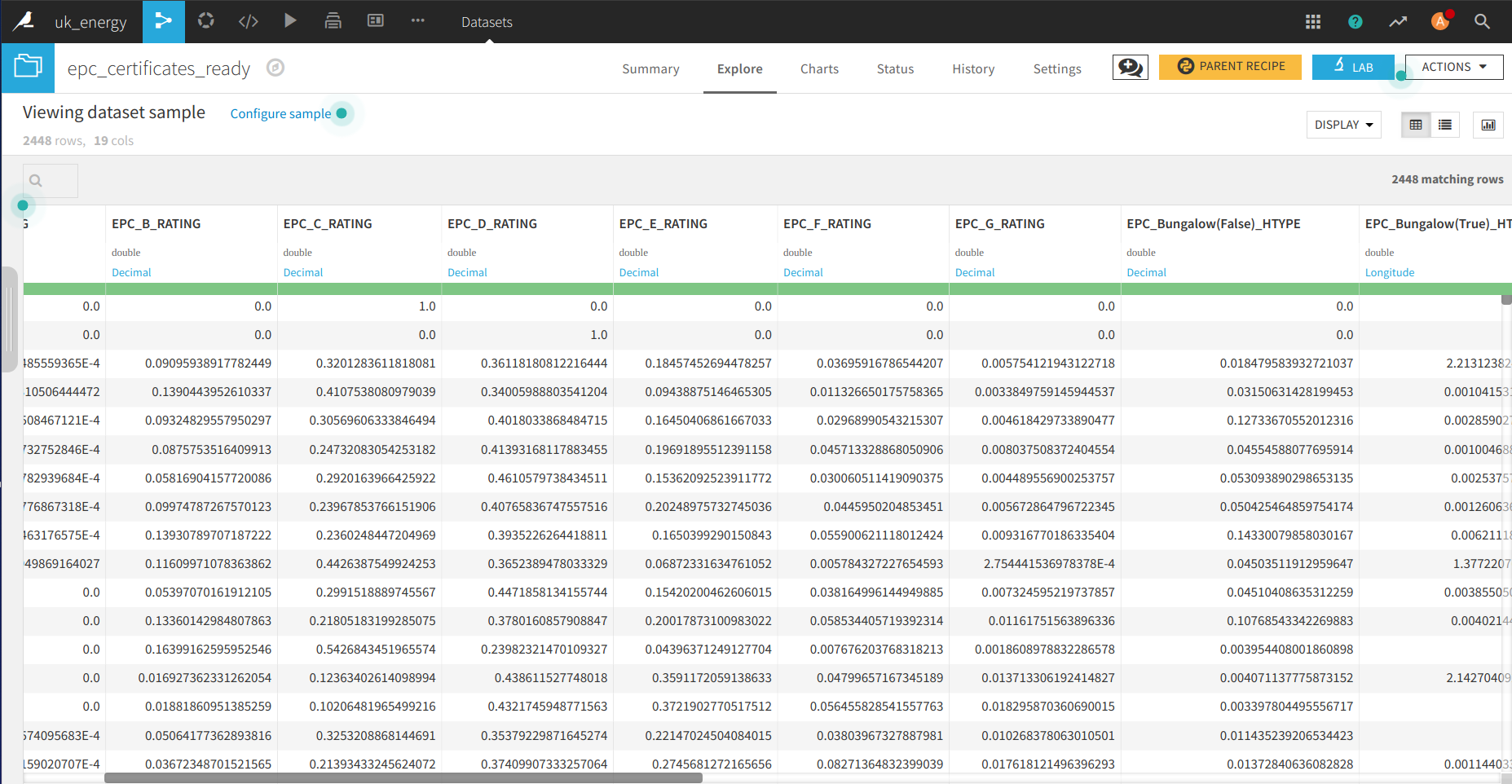
Ces données peuvent être facilement jointes avec les données de Nomis avec la fonction join.
J’ai utilisé certaines fonctions internes de DSS pour faire la jointure et le groupby mais j’aurais pu utiliser :
- Un script Python ou R pour construire le dataset
- Un script SQL s’il s’agissait de tables SQL
- Hive ou Impala dans le cas d’une configuration “big data”
Maintenant que les données sont disponibles, faisons une analyse et un tableau de bord pour résumer quelques résultats.
Analyse de données dans DSS
Les analyses vont être de très haut niveau, c’est seulement pour montrer les fonctionnalités de DSS.
Voici une animation d’un tableau de bord que j’ai construit avec DSS.
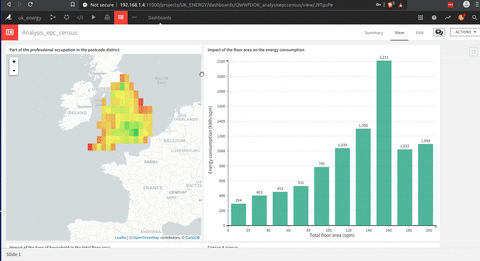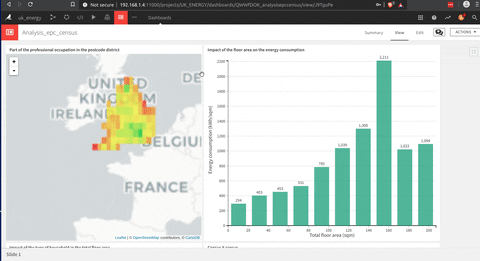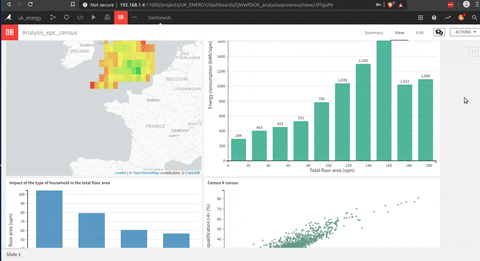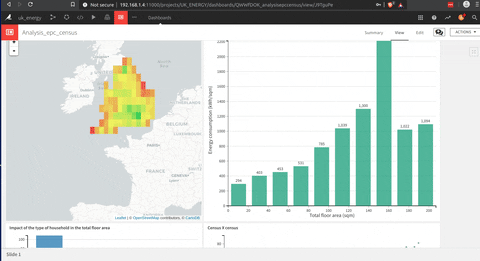
La construction de ce tableau de bord est beaucoup plus facile qu’un Tableau (mon opinion), mais ils partagent cette approche glisser-déposer pour construire chaque graphique qui est très utile.
Il y a un moyen de faire des analyses directement depuis le dataset avec l’outil lab où des fonctions internes peuvent être utilisées (pour déterminer la corrélation par exemple) ou utiliser des scripts pour analyser les données. Dans ce cas, j’ai choisi Python pour faire quelques graphiques avec seaborn.
La partie analyse est vraiment cool et je pense qu’elle pourrait répondre à beaucoup de besoins, mais l’autre partie qui est vraiment impressionnante est la partie ML pour construire des modèles basés sur les données traitées.
Déploiement de modèles dans DSS
Donc il y a plusieurs façons de construire un modèle, mais d’abord définissons un objectif pour cette partie :
“Construire un estimateur de note énergétique basé sur l’emplacement, la surface au sol totale et le type de chauffage du ménage”
Il y a trois “niveaux” que DSS vous donne pour construire un modèle mais soyons honnêtes, c’est la même interface, juste que votre parcours sur la partie configuration du modèle commence plus haut dans la hiérarchie du menu.
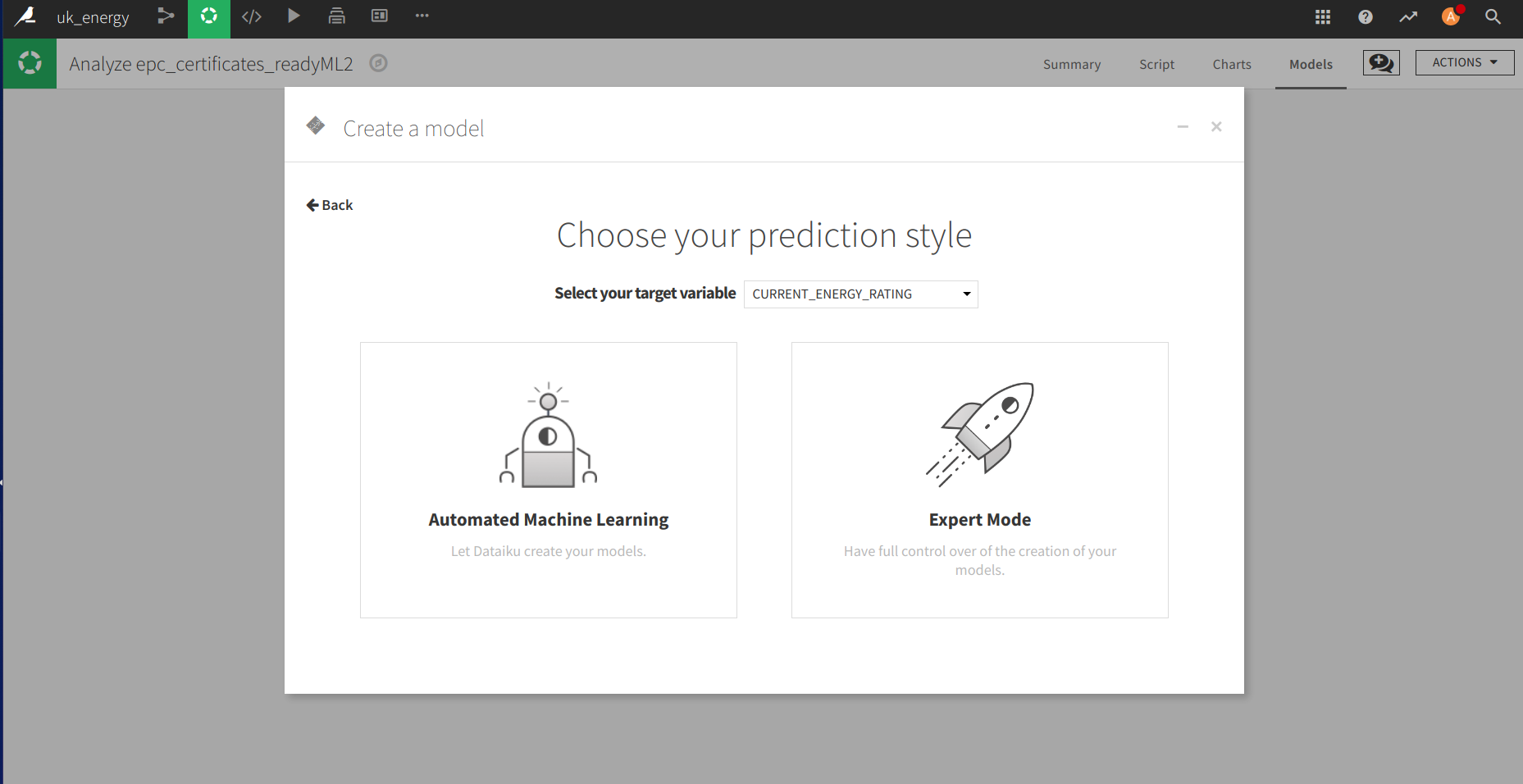
Dans le menu pour construire le modèle, il y a la possibilité de :
- Préparer les ensembles d’entraînement et de test
- Choisir la métrique d’évaluation
- Choisir les caractéristiques
- Choisir les modèles et les paramètres pour la recherche en grille
- Comparer les modèles après la partie test
Il y a une simple animation qui fait un aperçu des fonctionnalités du constructeur de modèles.
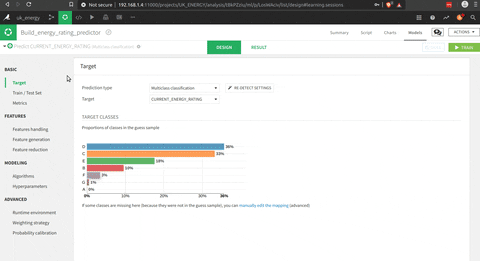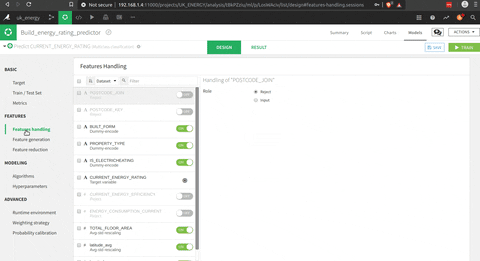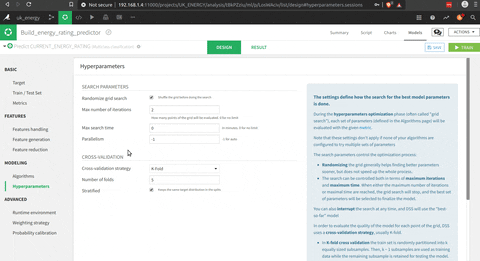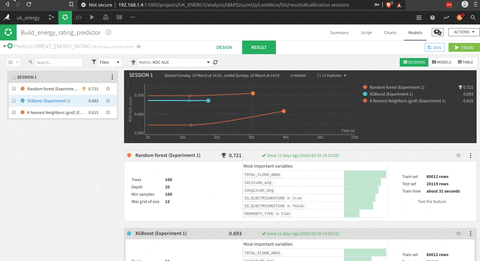
La partie intéressante est que vous pourriez utiliser des fonctions pré-construites (je présume des fonctions scikit-learn), ou écrire votre propre code Python. L’outil pour tester le modèle est vraiment impressionnant en termes de visualisation du processus et des résultats.
Un bon point est la visualisation des résultats avec par exemple un arbre de décision qui est vraiment facile à comprendre (décomposé avec cet outil).
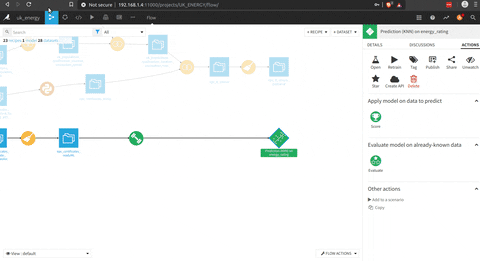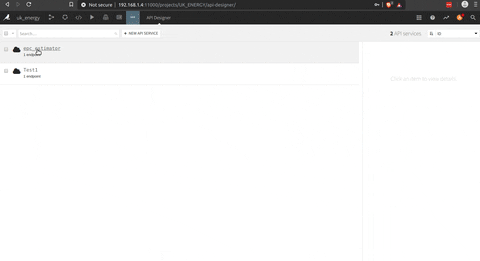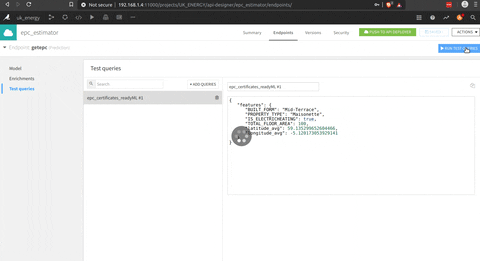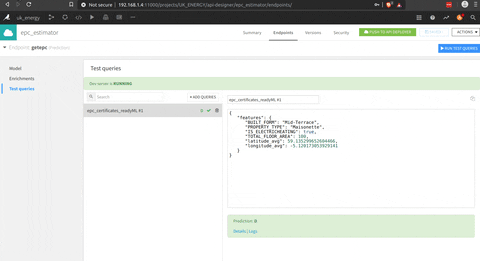
Après avoir trouvé le bon modèle, il y a un constructeur d’API pour intégrer le modèle. Dans cet espace, vous pouvez définir des requêtes de test pour voir le modèle en action.
Pour exposer le modèle, la fonctionnalité n’est pas activée pour la version gratuite (ou j’ai raté comment l’utiliser) mais cela semble assez intuitif.
Maintenant il est temps de conclure.
Retour d’expérience sur le projet
Je recommande fortement aux personnes qui travaillent sur ou sont intéressées par le secteur de l’énergie de plonger dans les données EPC car elles sont une très bonne source de connaissances sur le marché du logement au Royaume-Uni. En général, et c’est très douloureux pour moi en tant que gars le plus français à l’étranger de dire cela, mais le gouvernement britannique fait un excellent travail en collectant et en partageant des données et il y a des datasets très intéressants sur la plateforme gouvernementale qui pourraient être utilisés par les data scientists (en France nous sommes très en retard sur ce sujet mais les choses changent lentement).
Pour Dataiku DSS, c’est un excellent outil pour les data scientists, expérimentés ou non. Je peux sentir que cet outil a été conçu par des data scientists pour des data scientists et il y a tellement de fonctionnalités que je n’ai pas utilisées comme toute la partie collaboration, le deep learning, etc. Il y a plusieurs fonctions internes pour faciliter le traitement des données, ce qui est vraiment cool mais cela pourrait devenir un fardeau si par exemple Dataiku décide de supprimer ces fonctionnalités (ou de les rendre premium). Si les personnes qui travaillent avec les données ne savent pas comment faire une jointure, un groupby, etc., le transfert du pipeline de données pourrait être difficile, mais j’aime vraiment le fait que Dataiku ne verrouille pas l’utilisateur dans leurs fonctions internes et permet la possibilité d’autres façons de manipuler les données (avec SQL par exemple).
Dans mon travail quotidien, DSS peut-il remplir MES besoins ? NON, parce que j’ai actuellement plusieurs outils à ma disposition pour faire mon travail et j’ai besoin de flexibilité du côté des données et du côté du développement pour expérimenter et déployer des choses mais cet outil vaut vraiment la peine d’être essayé car il peut répondre aux besoins des équipes de données qui n’ont pas mes besoins (et ils sont nombreux dans le monde).
Références
- Dataiku — dataiku.com
- Éditions Dataiku DSS — dataiku.com
- API open data EPC — epc.opendatacommunities.org
- Données Nomis — nomisweb.co.uk
- Dictionnaire de données EPC — epc.opendatacommunities.org