
Être plus efficace pour produire des modèles de machine learning avec mlflow
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
La version utilisée pour cet article est mlflow 1.4.0
Bonjour, dans cet article je vais faire une expérimentation sur un outil appelé mlflow qui est sorti l’année dernière pour aider les data scientists à mieux gérer leurs modèles de machine learning.
L’idée de cet article n’est pas de construire le modèle parfait pour le cas d’usage où je vais construire un modèle de machine learning, mais plus de plonger dans les fonctionnalités de mlflow et de voir comment il peut être intégré dans un pipeline ML pour apporter de l’efficacité au quotidien pour un data scientist/ machine learning engineer.
mlflow kezako ?!
mlflow est un package python développé par databricks qui est défini comme une plateforme open source pour le cycle de vie du machine learning. Il y a trois piliers autour de mlflow (Tracking/Projects/Models).
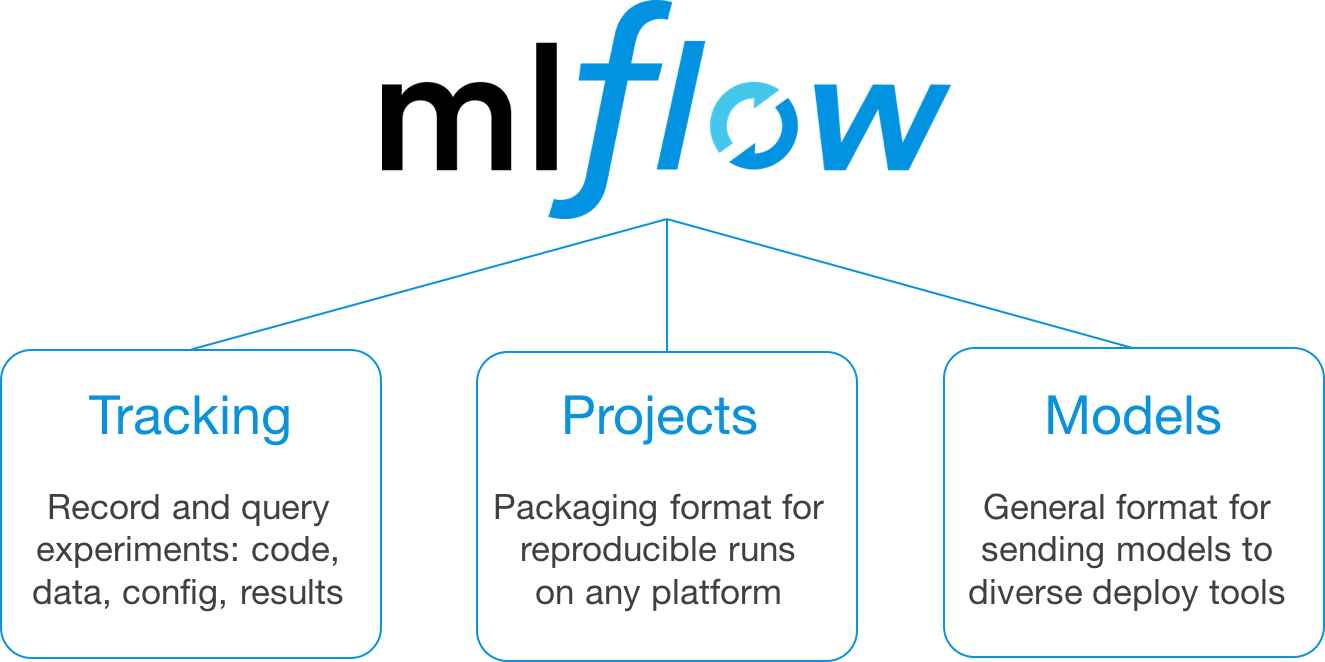
Leur documentation est vraiment excellente et ils ont un bon tutoriel pour expliquer les composants de mlflow. Pour cet article, je vais concentrer mes tests sur les parties Tracking et Models de mlflow car je serai honnête avec vous, je n’ai pas vu l’intérêt de la partie Project (cela ressemble à un export conda et un fichier de config pour exécuter des scripts python dans un ordre spécifique) mais je suis sûr que cela peut aider certaines personnes sur l’aspect reproductif d’un pipeline ml.
Jetons maintenant un œil sur le cas que je veux utiliser pour tester mlflow.
Description du cas d’usage
Pour tester mlflow, je vais utiliser le même cas d’usage que j’ai utilisé pour compléter mon nanodegree d’ingénieur ML Udacity en 2017 :
Construire un système de prévision de la consommation d’électricité en France
Vous pouvez trouver toutes les ressources que j’ai produites à ce moment-là dans ce dossier de mon dépôt Github sur le nanodegree.
Je ne vais pas entrer trop dans les détails de l’analyse des données que vous pouvez trouver dans le rapport du dépôt mais essentiellement la consommation d’électricité en France est saisonnière.
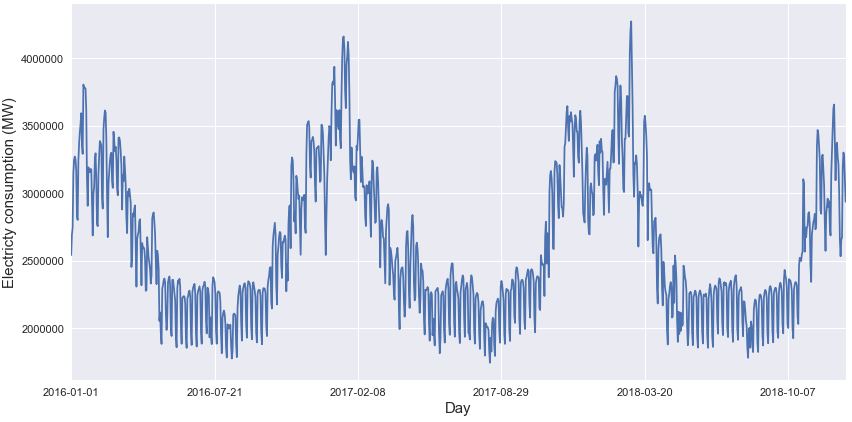
Et comme les ménages utilisent la plupart du temps le chauffage électrique, la consommation est très dépendante de la température extérieure.
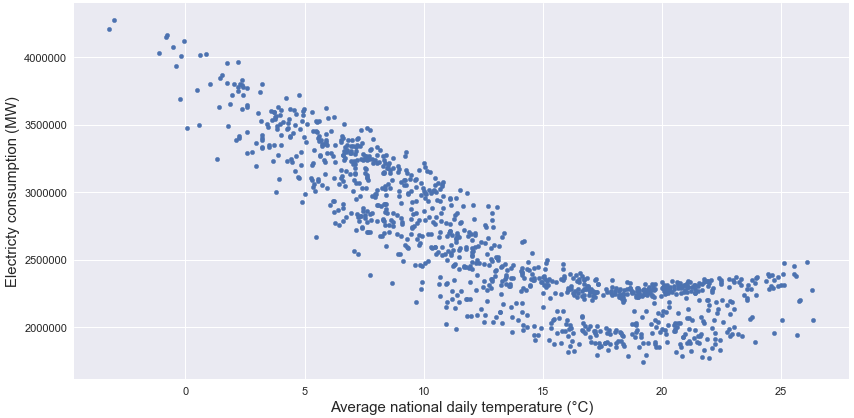
Plus important encore dans cette analyse, pour la relancer en 2019, je suis retourné sur le site web opendata de RTE et j’ai eu la bonne surprise de voir que le site web a évolué en ajoutant plus de données sur la plateforme (ils se sont associés avec d’autres sociétés de gestion de l’énergie) donc maintenant il y a les données de consommation d’énergie et des informations supplémentaires comme la météo régionale par exemple.
Pour ce projet, je vais juste utiliser les caractéristiques suivantes pour entraîner un modèle :
- Informations sur le jour comme le jour de la semaine, le mois, le numéro de semaine et si c’est un jour férié en France avec le package holidays)
- Informations sur la température extérieure quotidienne (Min, Moyenne et Max) en France, l’une est juste une moyenne globale de la température extérieure dans chaque région (avg) et l’autre est une moyenne pondérée basée sur le nombre de personnes dans chaque région
Vous pouvez trouver le notebook qui traite les données brutes d’ouverture dans ce dépôt
Pour la partie modélisation, comme je l’ai dit, l’idée n’est pas de construire le super modèle qui va prévoir la consommation d’énergie avec une précision de 99.999% mais plus de voir comment intégrer mlflow dans le pipeline que j’ai construit il y a un an pour mon nanodegree.
Je vais tester les modèles suivants :
- un KNN regressor de scikit learn (avec divers paramètres et caractéristiques)
- un MLP regressor de scikit learn (avec divers paramètres et caractéristiques)
- une régression linéaire par morceaux artisanale appelée PTG
L’idée sera d’utiliser les données de 2016 à 2019 (exclu) pour l’entraînement et de tester l’algorithme sur les données de 2019.
Description du pipeline de machine learning
Dans la figure suivante, il y a ma vision d’un pipeline de flux ml simple pour répondre à ce genre de cas d’usage.
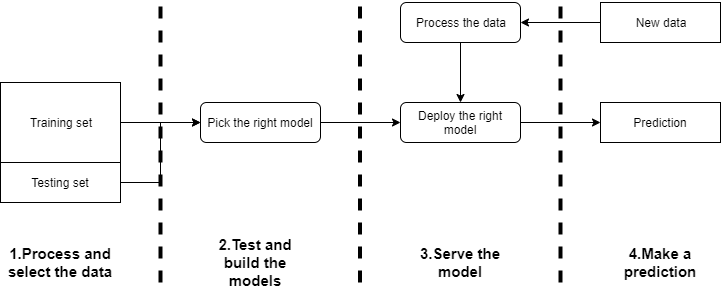
Il y a 4 étapes principales dans ce pipeline ML :
- la première est de collecter toutes les données, construire les caractéristiques qui seront utilisées pour faire le prédicteur
- la phase de test et de construction où le bon modèle avec les bons paramètres va être construit avec les données d’entraînement et testé sur l’ensemble de test
- La partie de déploiement où quand vous avez le bon modèle, vous devez le déployer pour l’utiliser pour faire des prédictions
- La partie prédiction quand vous avez de nouvelles données qui seront traitées pour être transformées en caractéristiques qui peuvent être utilisées pour faire une prédiction avec le modèle déployé
Donc où mlflow s’intègre-t-il dans ce pipeline ?
Pour moi, la bibliothèque s’intègre clairement aux étapes 2, 3 et un peu à la 4 et c’est vraiment génial de couvrir toute cette portée.
Jetons maintenant un œil plus en détail sur l’utilisation de mlflow.
Tester et construire les modèles (mlflow Tracking)
Comme nous l’avons dit précédemment, nous devrons trouver les bons modèles pour résoudre ce problème de prévision. Pour initialiser le pipeline, nous devrons définir une expérience, qui sera electricityconsumption-forecast , qui aura un experimentid aussi (1 dans ce cas).
Chaque test d’un modèle (modèles ou paramètres) sera défini comme un run dans mlflow (et tagué par runid) et stocké dans le dossier mlruns qui apparaîtra dans le dossier actuel.
Pour organiser mon code, je garde la même structure que dans le tutoriel mlflow. Il y a un exemple d’un morceau de mon code pour entraîner un KNN regressor.
Avec cette approche, chaque modèle est tagué par le type de modèle et les caractéristiques utilisées pour le construire. Pour les métriques d’évaluation, je concentre mon évaluation sur :
- les métriques de précision comme le RMSE, R-squared, ou l’erreur absolue moyenne
- le temps d’exécution du model.fit et du model.predict car il y a plus que la précision pour choisir un bon modèle.
J’applique cette approche à tous les modèles et toutes les données sont stockées dans le dossier mlruns.
Pour utiliser l’interface mlflow, il suffit d’exécuter la commande suivante dans votre répertoire de travail.
mlflow uiVous devriez accéder à l’interface par la page localhost:5000, et choisir la bonne expérience. Il y a une capture d’écran de la page principale d’une expérience.
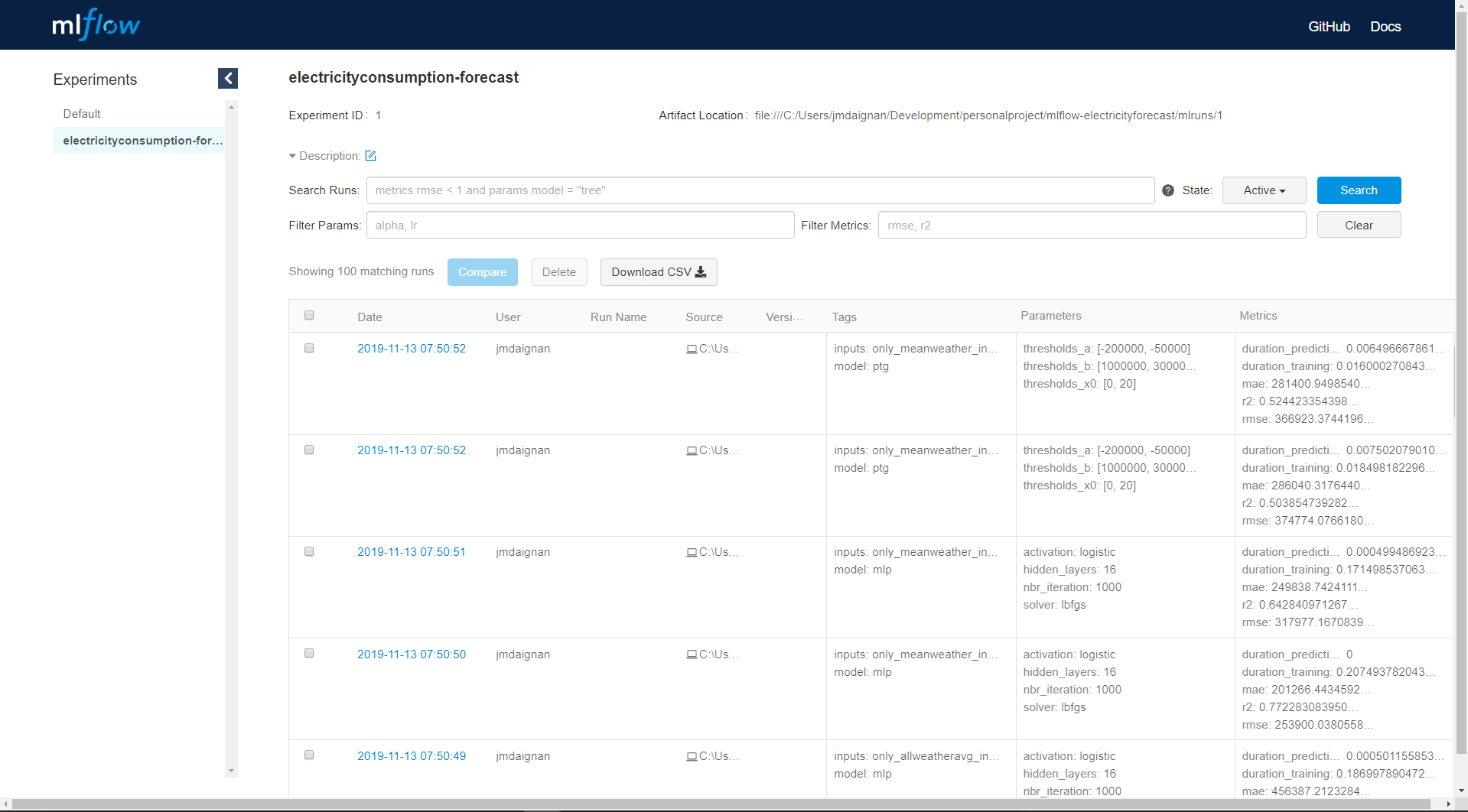
Il y a sur cette page toutes les métriques calculées pour chaque modèle avec tous les tags qui peuvent avoir été associés et des informations supplémentaires sur l’utilisateur et l’emplacement du modèle enregistré. De cette page, nous pouvons accéder à chaque run en cliquant sur la date du run.
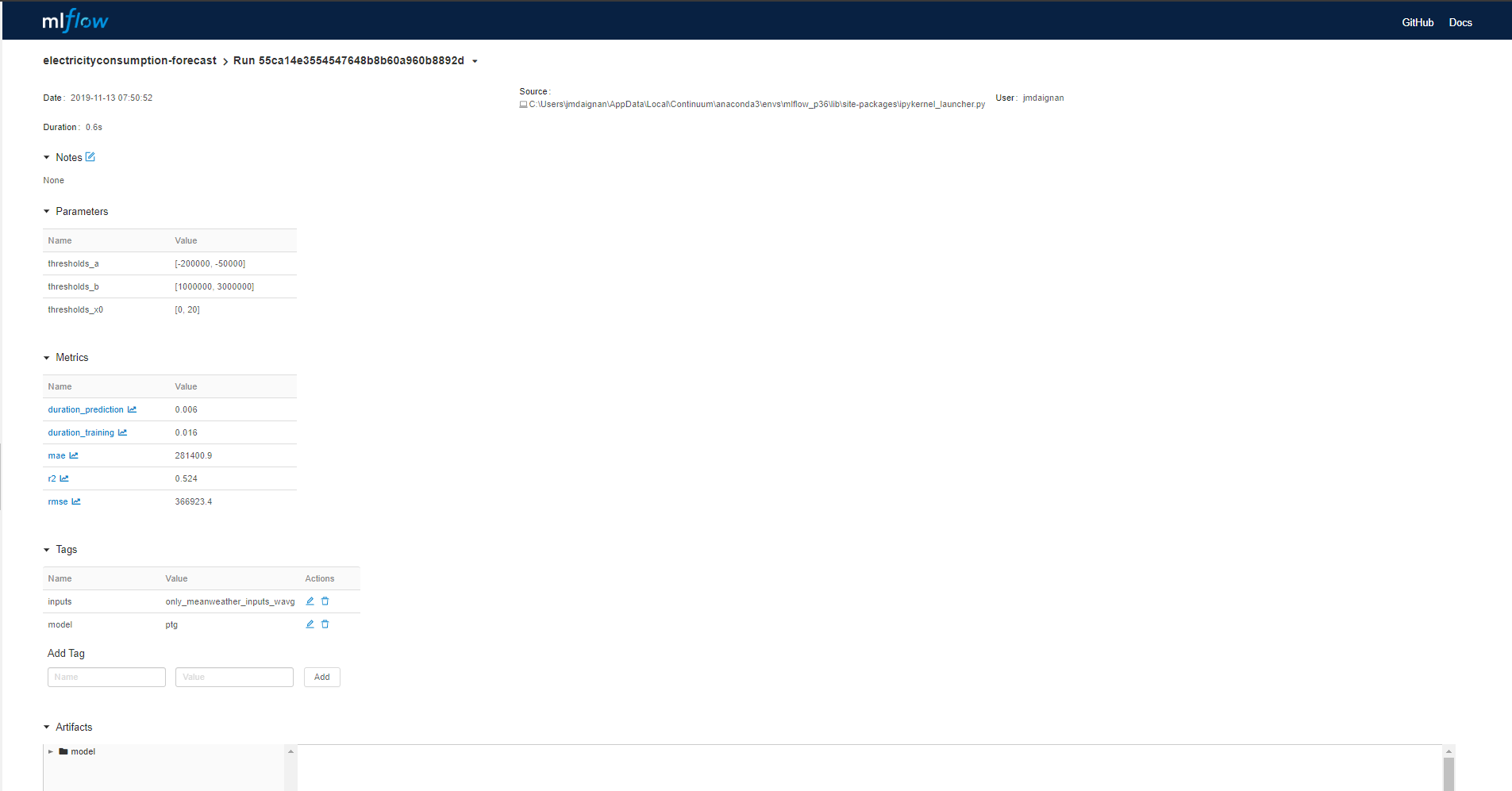
Dans la page du run, il y a :
- la section des paramètres où vous pouvez trouver les paramètres appliqués dans le modèle
- les métriques calculées pendant le run
- les tags associés au modèle
Une autre partie importante de l’interface est l’Artifact où il y a l’organisation du dossier qui contient les informations sur le modèle.
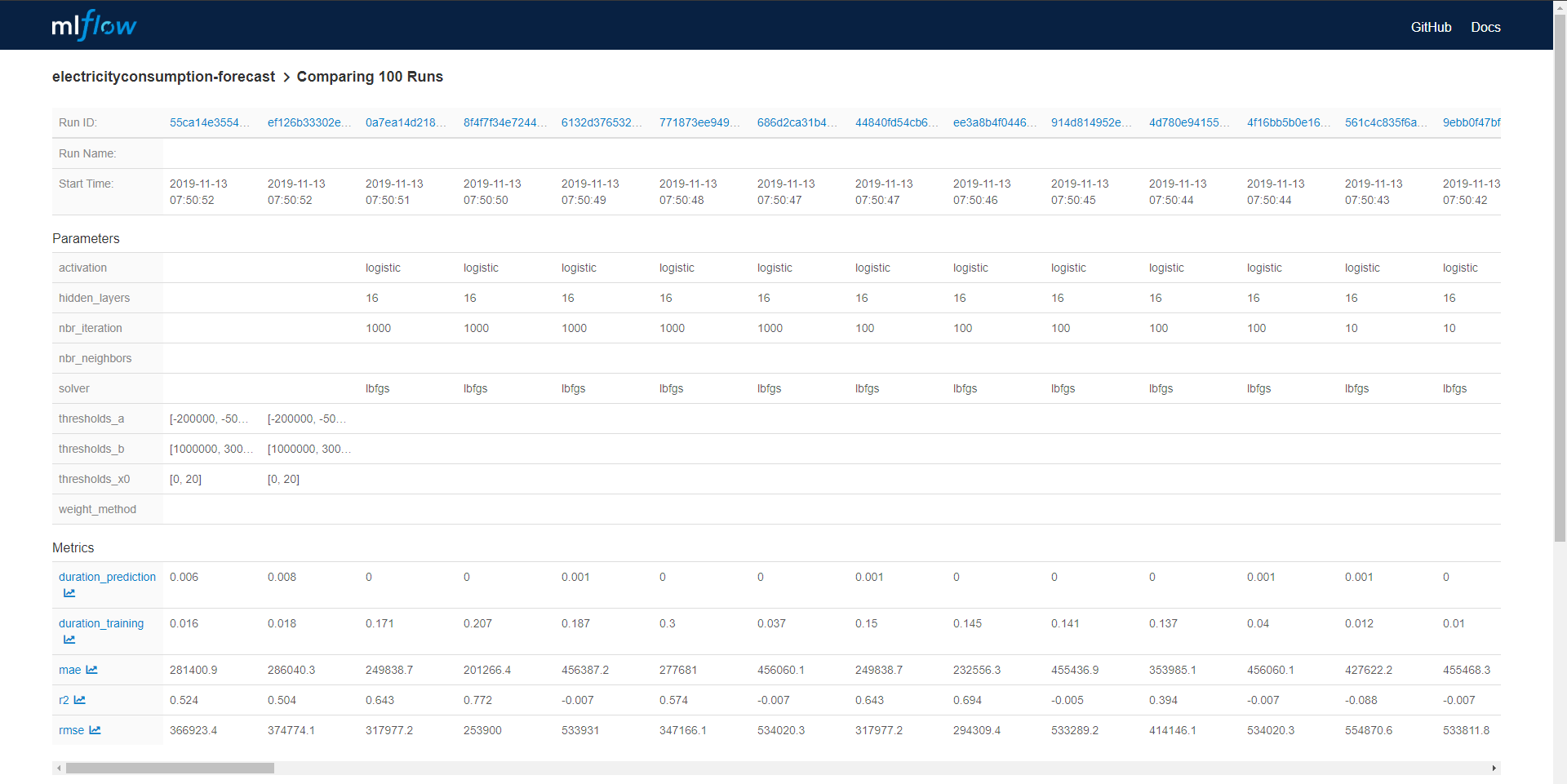
De la page principale, vous pouvez sélectionner tous les modèles qui peuvent être comparés entre eux. Le panneau de comparaison contenait deux panneaux, un avec un tableau pour mettre les modèles côte à côte avec toutes les métriques explosées.
Et il y a un autre panneau pour faire de la visualisation avec Plotly et comparer les modèles entre eux. J’ai fait une animation rapide de ce panneau de visualisation.
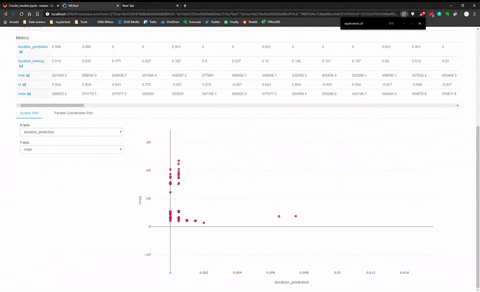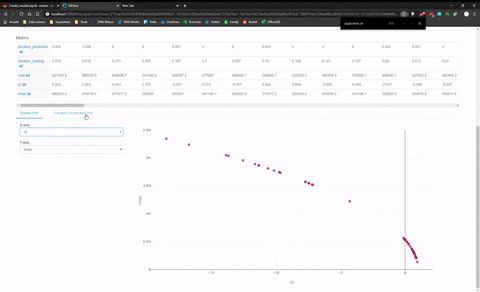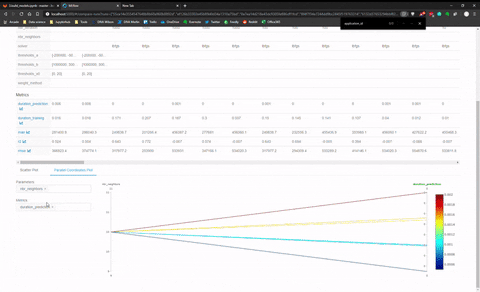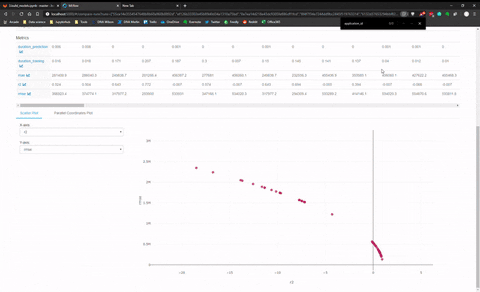
J’ai trouvé cette dernière fonctionnalité assez limitée pour la comparaison entre modèles de différentes catégories (comme KNN versus MLP), elle semble plus adaptée pour comparer des modèles de la même famille.
Mais cette interface n’est pas la seule façon de faire l’analyse des logs, tous les logs peuvent être collectés dans un dataframe avec la commande en python.
mlflow.search_runs(experiment_ids="1")Et avec cela, des analyses plus approfondies peuvent être faites sur votre environnement python, par exemple obtenir le meilleur modèle basé sur le score RMSE. Il y a une analyse simple faite à partir des logs en Python.
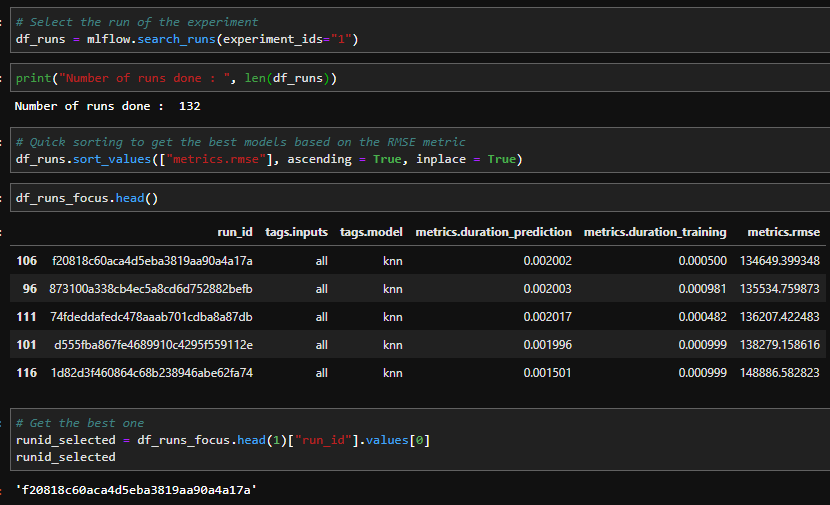
Le meilleur modèle a un runid spécifique qui peut être utilisé après pour exécuter le déploiement.
Déploiement du modèle (mlflow Models)
Avec mlflow, vous pouvez rapidement déployer un modèle local avec la commande suivante :
mlflow serve -m path_to_the_model_stored_with_the_logfuction_of_mlflow -p 1234Il suffit de guider la commande mlflow serve vers le dossier du modèle avec le -m et d’assigner un nouveau port (celui par défaut est le même que celui pour l’interface mlflow et cela pourrait être ennuyeux)
Pour exécuter un appel de prédiction, vous devez envoyer une requête POST au endpoint /invocation de cette API avec sur ce paramètre un dataframe qui a été transformé en json avec un orient split (sera plus compréhensible avec le code pour la transformation 👇)
toscore = df_testing.to_json(orient = "split")Et après vous pouvez facilement appeler l’API avec une requête POST depuis Postman ou Python
import requests
import json
endpoint = "http://localhost:1234/invocations"
headers = {"Content-type": "application/json; format=pandas-split"}
response = requests.post(endpoint, json = json.loads(toscore) , headers=headers)Mais maintenant la grande question est Comment le déployer en ligne ?
mlflow est plutôt bien fait, vous avez des fonctions intégrées pour déployer rapidement le modèle sur Microsoft AzureML ou sur AWS Sagemaker. Comme je suis plus un gars AWS, je vais me concentrer sur le déploiement sur AWS Sagemaker.
Le déploiement se fait en deux phases :
- Déployer un container sur AWS ECR qui contiendra votre environnement pour exécuter le modèle, le déploiement est très simple avec la commande suivante :
mlflow sagemaker build-and-push-containerBien sûr, la commande doit être exécutée sur une machine qui a Docker installé et un utilisateur AWS avec les bons droits pour déployer des choses sur AWS, par exemple le mien a des accès admin, peut-être pas la bonne chose mais YOLO.
- Après la fin du déploiement du container, il y a une commande deploy pour mlflow sagemaker qui est très similaire à celle utilisée pour faire le déploiement local avec mlflow
mlflow sagemaker deployMais même sur Windows ou Linux, cela n’a pas fonctionné pour moi. Donc j’ai essayé une autre approche depuis ce billet de blog. Il y a un résumé du code dans ce gist.
Le déploiement est assez rapide (environ 10 minutes) et après vous pouvez appeler l’API déployée sur AWS avec ce morceau de code (du blog databricks)
Donc maintenant le modèle peut être appelé pour faire des prévisions de la consommation d’énergie depuis cet endpoint (cette approche avec un utilisateur AWS gère toute l’authentification donc c’est assez sécurisé je suppose).
Retour d’expérience
J’ai vraiment aimé expérimenter sur mlflow, le versioning du Machine learning est un grand sujet en général mais dans mon entreprise actuelle Ubisoft (si vous voulez rejoindre la famille Ubi, il y a peut-être un emploi pour vous ici) cela commence à être un vrai gros problème.
De mon point de vue mlflow est vraiment génial pour faire des expériences hors ligne et trouver le bon modèle, et faire des prototypes rapides.
J’ai encore quelques préoccupations sur des sujets très spécifiques :
- Dans un modèle ml, il y a l’algorithme mais les données sont très importantes aussi donc la fonctionnalité tags peut être utilisée pour donner des informations sur les données utilisées mais de mon avis c’est peut-être pas assez
- La classe du modèle doit faire la prédiction à partir d’un Pandas dataframe, c’est génial mais peut-être un peu une contrainte aussi
- Manque de moyen de documenter automatiquement le modèle sur les caractéristiques/données qui ont été utilisées pour aider à faire l’appel au modèle déployé derrière une API
- La gestion des modèles de Tensorflow semble super compliquée (pytorch semble plus facile) mais ce dernier point vient peut-être du fait que je ne suis pas très familier avec ces frameworks (pas de position dans la guerre Tensorflow VS Pytorch 😀 ).
Mais honnêtement excellent travail @databricks, vous avez fait un outil vraiment génial pour aider les data scientists dans leurs expérimentations

Références
- mlflow — mlflow.org
- Databricks — Databricks
- mlflow Tracking — mlflow.org
- mlflow Projects — mlflow.org
- mlflow Models — mlflow.org
- Documentation mlflow — mlflow.org
- Tutoriel mlflow — mlflow.org
- Dossier capstone udacity_mlen — GitHub
- Plateforme open data RTE — opendata.reseaux-energies.fr
- Package holidays — pypi.org
- Dépôt mlflow-energyforecast — GitHub
- KNN Regressor (scikit-learn) — scikit-learn.org
- MLP Regressor (scikit-learn) — scikit-learn.org
- Article PTG (IBPSA) — ibpsa.org
- RMSE — Wikipedia
- R-squared — Wikipedia
- Erreur absolue moyenne — Wikipedia
- Déploiement mlflow sur AzureML — mlflow.org
- Déploiement mlflow sur Sagemaker — mlflow.org
- AWS ECR — AWS
- Docker — docker.com
- Deploying models to production with mlflow and Amazon Sagemaker — Medium / Towards Data Science
- Databricks mlflow quick start deployment AWS — Databricks