
Être plus efficace pour produire des pipelines machine learning avec Metaflow
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Pour cet article, je vais décrire mon expérience pratique sur une nouvelle bibliothèque qui a été récemment open-sourcée par Netflix pour opérer et versionner des pipelines de machine learning / data science appelée Metaflow.
L’idée de cet article est de :
- Avoir un aperçu du package
- Détailler avec deux exemples les fonctionnalités du package (et aller plus loin que les tutoriels)
Aperçu de Metaflow
Metaflow est un package développé par Netflix, ils ont commencé à travailler dessus il y a quelques années (vers 2016), et l’ont open-sourcé en 2019. L’idée de Metaflow est d’offrir un framework pour les data scientists afin de construire rapidement un pipeline de data science/machine learning, et qui peut passer facilement du développement à la production.
Je vous invite à regarder la présentation de Ville Tuulos de Netflix à AWS reinvent 2019.
La grande question chez Netflix derrière ce package était
Quelle est la chose la plus difficile pour un data scientist dans son travail quotidien ?”
Les ingénieurs de Netflix s’attendaient à entendre parler d’accès à de grands jeux de données, de grande puissance de calcul et d’utilisation de GPU, mais la réponse (il y a deux ans) était différente. L’un des plus grands goulots d’étranglement était l’accès aux données et le passage du PoC à la production.
Dans la figure suivante, il y a une visualisation de l’intérêt des data scientists et des besoins d’infrastructure dans un processus ML/DS.

Dans cet article qui annonce Metaflow, il y a une citation que je pense définir l’esprit derrière Metaflow :
L’infrastructure devrait leur permettre d’exercer leur liberté en tant que data scientists, mais elle devrait fournir suffisamment de garde-fous et d’échafaudages, pour qu’ils n’aient pas à trop se préoccuper de l’architecture logicielle.
L’idée est d’offrir un chemin sûr pour le data scientist dans son travail sans compromettre sa créativité. Ce framework doit être facile à utiliser et offrir un accès à une grande puissance de calcul sans avoir à mettre les mains dans l’infrastructure.
Voyons plus en détail la conception du framework.
Conception de Metaflow
Metaflow est une bibliothèque Python qui fonctionne uniquement sur Linux, principalement inspirée de Spotify Luigi, et conçue autour de DAG. Dans la figure suivante, il y a une représentation d’un flux typique sur Metaflow.
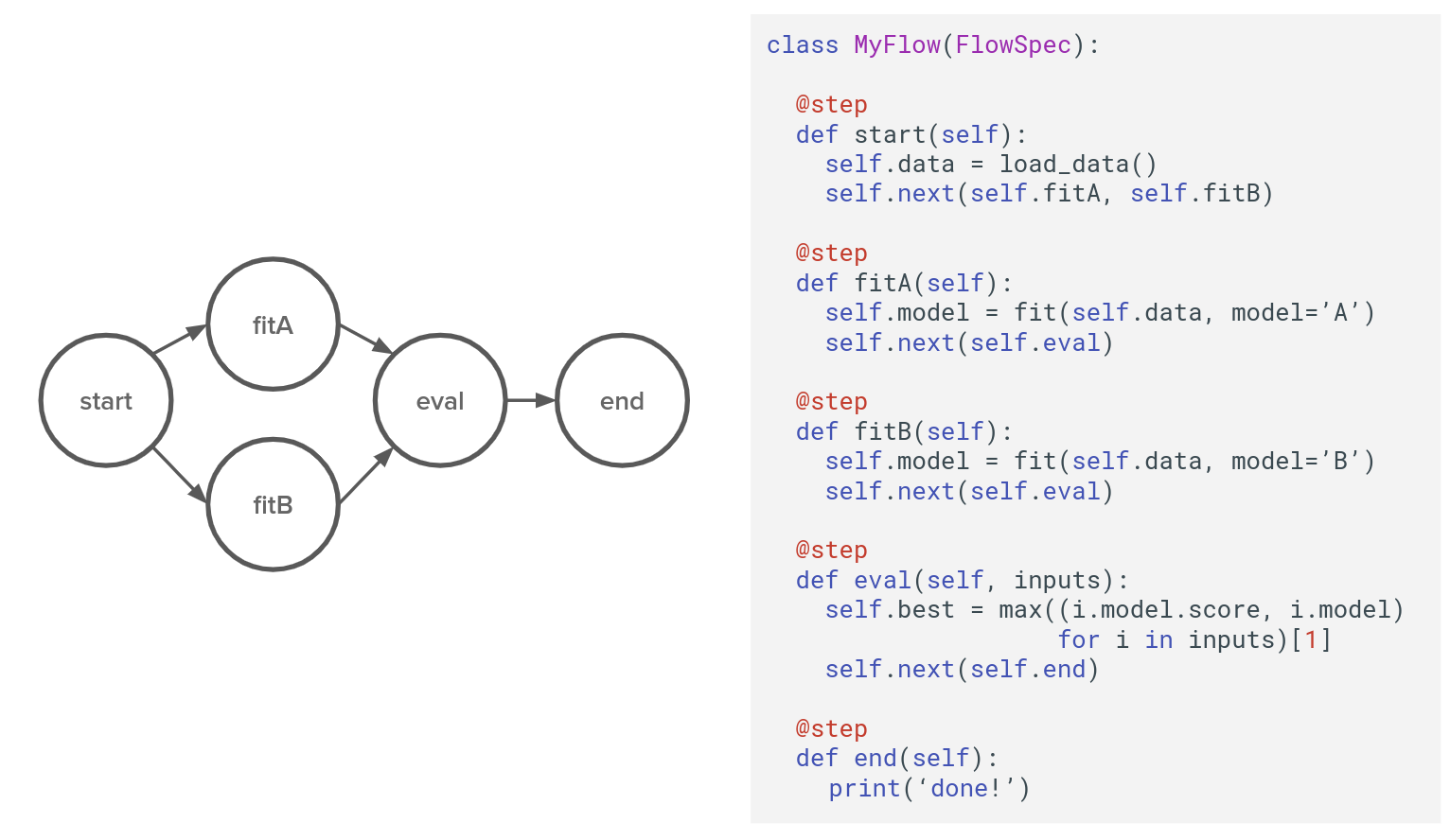
Le DAG est structuré autour de :
- Flow : l’instance qui gère tous les codes pour le pipeline. C’est un objet Python dans ce cas class MyFlow(Flowspec)
- Steps : parties du flux, délimitées par le décorateur @step, ce sont des fonctions python dans l’objet MyFlow, dans ce cas, def start, fitA, fitB, eval, end.
- Transitions : liens entre les étapes, ils peuvent être de différents types (linéaire, branche et for each) ; il y a plus de détails sur la documentation.
Parlons maintenant de l’architecture. Dans la figure suivante de Netflix, il y a une vue des composants.
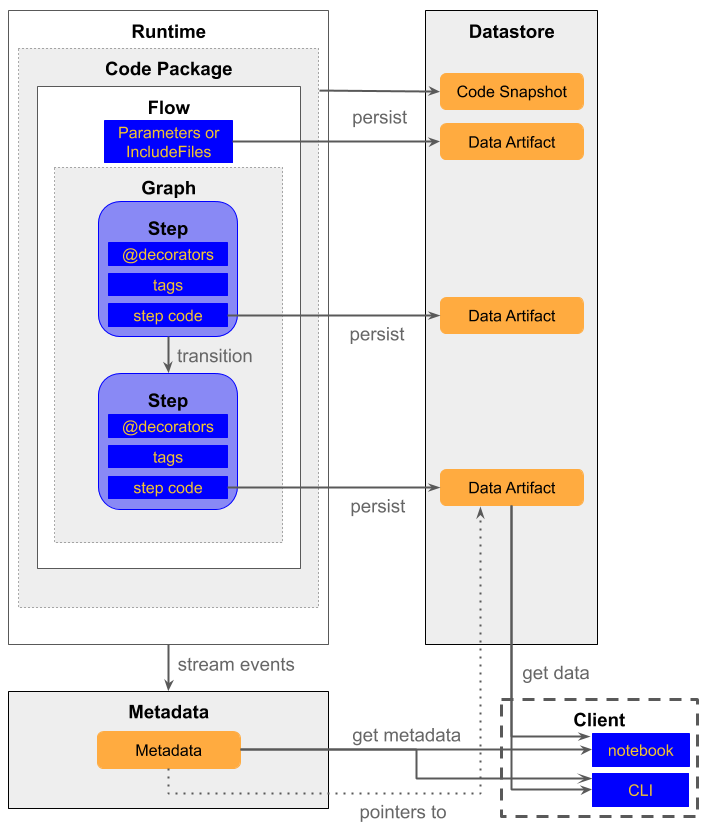
Il y a 3 composants autour du flux :
- Le datastore qui est l’endroit où toutes les données (artefacts de données) générées tout au long du flux sont stockées
- Les métadonnées sont l’endroit où les informations sur l’exécution du flux sont stockées
- Le client est le composant qui est la connexion pour accéder aux données dans le datastore et obtenir des informations sur le flux à partir des métadonnées
Pour moi, l’une des parties centrales qui gère le cœur de Metaflow est le décorateur. C’est une fonctionnalité Python qui permet de mettre à jour la propriété d’un objet python sans modifier sa structure, et je vous invite à lire cet article de Data camp sur le sujet.
Dans Metaflow, il y a plusieurs décorateurs, bien expliqués dans cette section de la documentation. Néanmoins, pour moi, les plus importants sont ceux que je vais expliquer dans la partie suivante.
Expérience pratique sur MetaFlow
J’ai construit un flux simple pour illustrer les décorateurs et les transitions de branches. Le code du flux est dans ce dépôt (dossier decorator_experimentation) ; le flux ressemble à ça.
Et voici une illustration visuelle du flux.
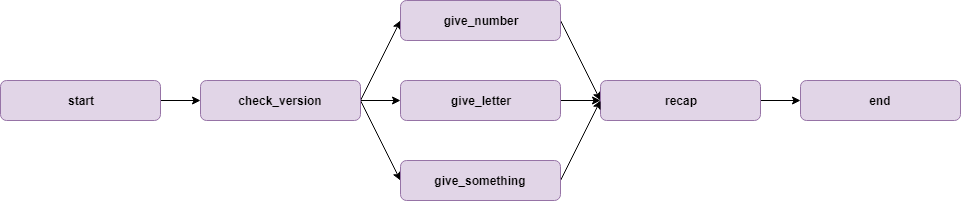
L’objectif de ce flux est de :
- Tester la version de Python et Pandas dans l’étape start,
- Tester (encore !?) la version de Python et Pandas dans l’étape check_version
- Exécuter une transition à 3 branches qui va donner un nombre aléatoire (give_number), une lettre (give_letter), ou un nombre/lettre (give_something)
- Une étape de jonction appelée recap pour afficher les produits des étapes précédentes,
- Une étape de fin qui va afficher (encore !?) la version de Python/Pandas
La vérification régulière de la version de Python/Pandas est pour illustrer deux décorateurs spécifiques. Commençons par l’exécution standard du script ; pour exécuter ce flux, vous devez exécuter la commande suivante dans le dossier du script.

Voici le log produit par le script.
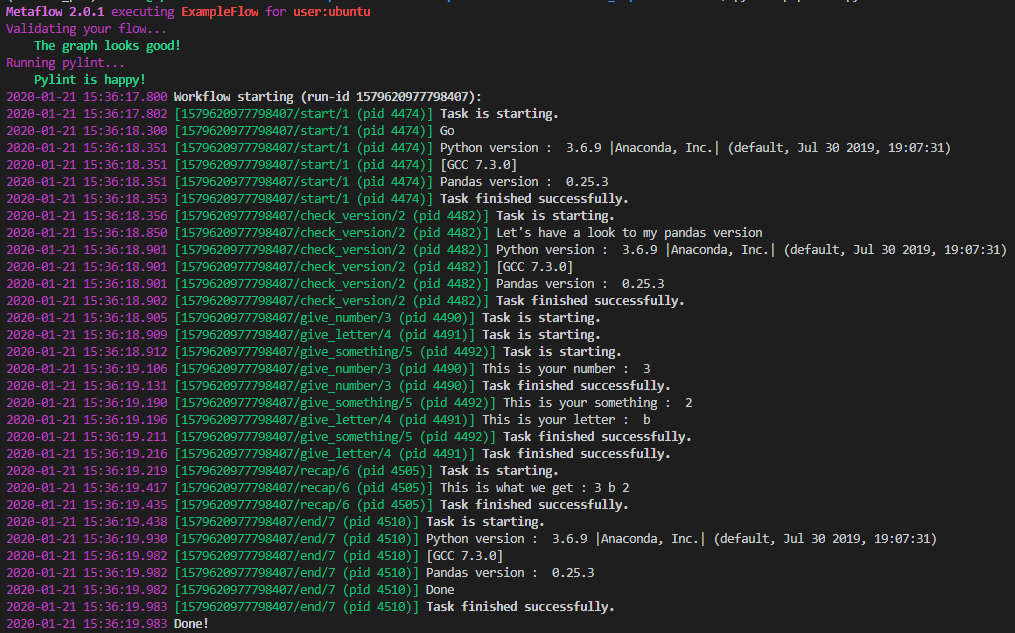
Comme nous pouvons le voir sur le log, la version de Python est 3.6.9 et Pandas est 0.25.3. Testons le décorateur @conda_base. Il suffit de décommenter une ligne et d’exécuter la ligne de commande suivante.
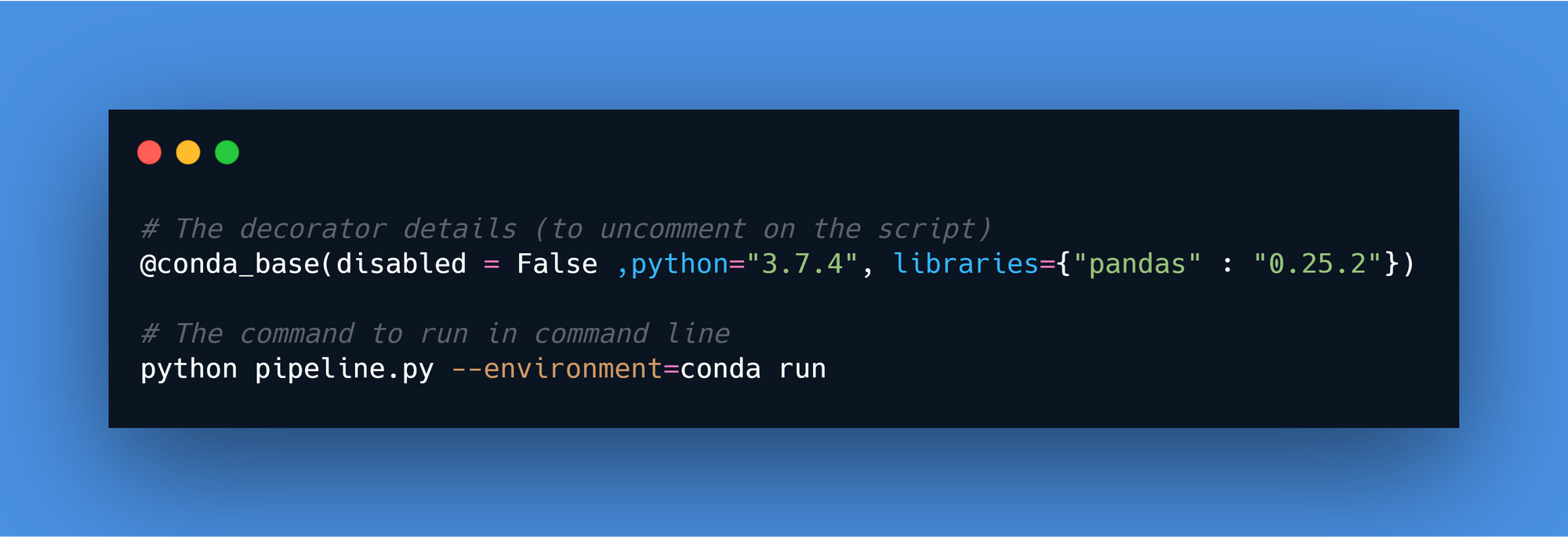
Ce décorateur a appliqué une nouvelle version de Python sur le flux, dans ce cas, 3.7.4, avec une nouvelle version de Pandas (0.25.2). Voici le log produit par le pipeline.
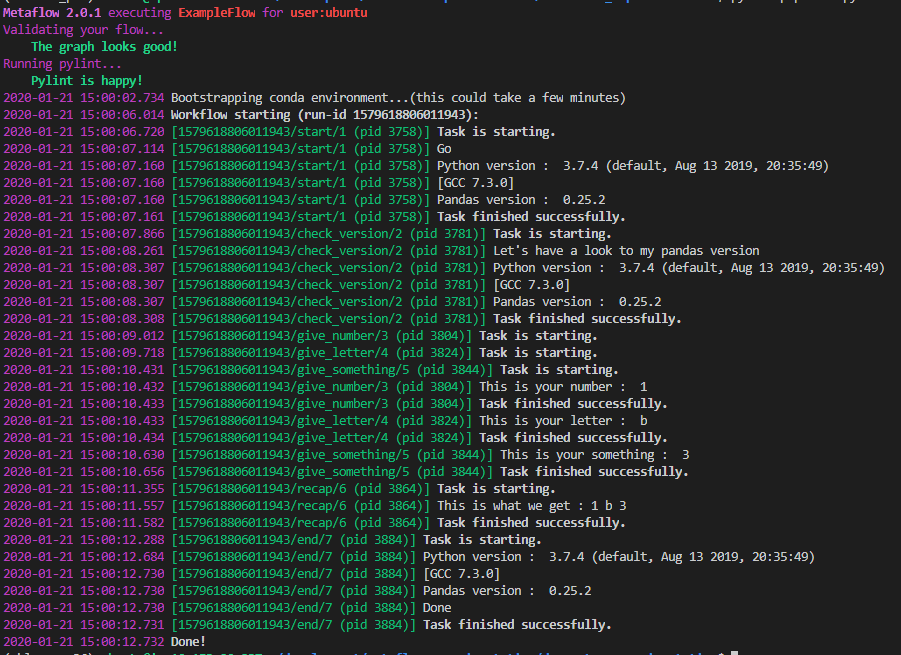
Comme je l’ai dit, il y a maintenant une nouvelle version de Python/Pandas utilisée pour exécuter tout le flux. Pour finir, voyons le décorateur @conda.
Celui-ci est comme le @conda_base, mais seulement pour une étape, dans ce cas, je modifie la version python à 3.6.8 juste pour cette étape spécifique (avec une version aléatoire de Pandas, je sais que ça a l’air stupide, mais c’est juste pour tester).
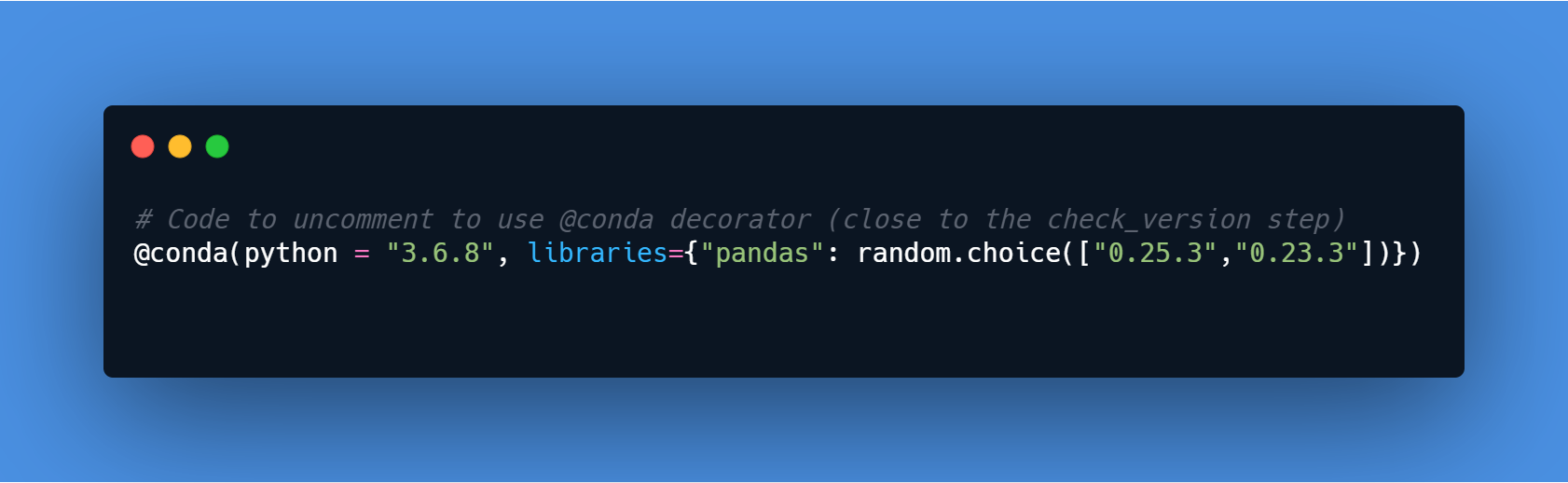
Et dans le log, nous pouvons voir qu’il y a une nouvelle version de Python/pandas appliquée juste pour l’étape check_version.
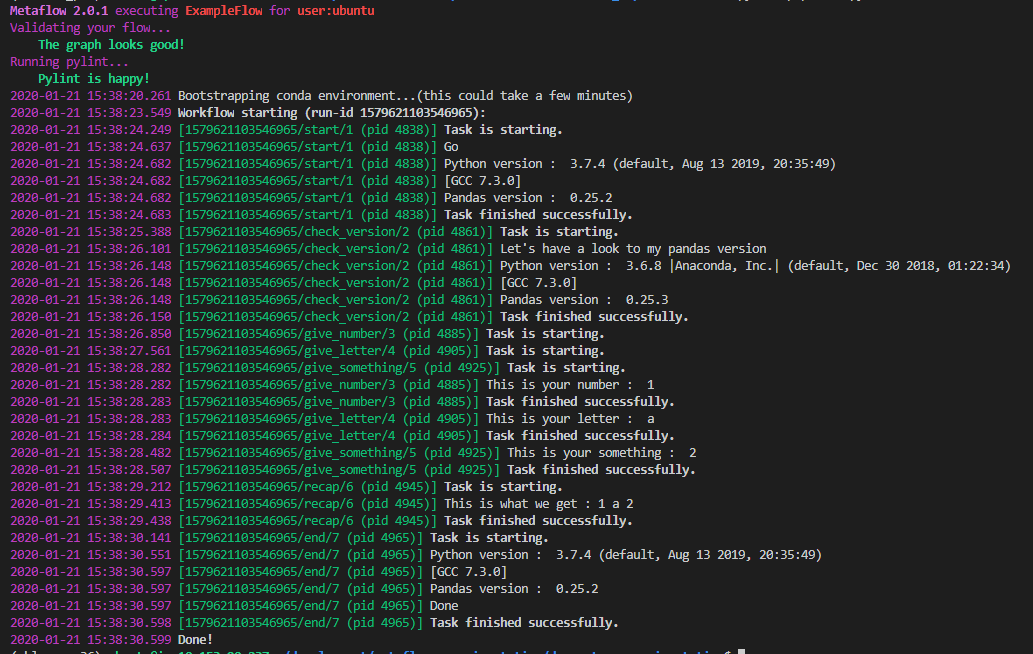
Je pense que ce test illustre l’utilisation de Metaflow pour versionner l’environnement utilisé pour l’exécution d’un flux ou d’une étape. La force de Metaflow est d’offrir la flexibilité à un data scientist de configurer précisément l’environnement nécessaire pour exécuter du code sans avoir à configurer un environnement conda ou un conteneur.
Il y a plus que ces décorateurs dans le package comme :
- Ceux pour l’exécution comme @retry, @timeout, @catch, @resources
- Ceux AWS (@batch) auxquels je reviendrai plus tard.
Voyons un flux de data science/machine learning conçu avec Metaflow.
Construire un prédicteur d’archétype pour Hearthstone avec Metaflow
Il y a quelques semaines, j’ai construit un jeu de données lié à Hearthstone, le jeu de cartes de Blizzard. Je vous invite à y jeter un œil si vous n’avez pas une vision claire du jeu.
Un aspect que j’ai évité dans l’article précédent était la notion d’archétype. Ces archétypes sont basés sur le héros sélectionné et les cartes dans le deck, il y a plusieurs types d’archétypes, et certains sont les plus populaires.
Dans le jeu de données présenté dans l’article précédent, 40% des decks n’ont pas d’archétype associé, donc je voulais commencer à construire un prédicteur d’archétype basé sur les cartes utilisées (C’est un système factice juste pour tester le flux de Metaflow).
Dans la figure suivante, il y a une représentation du flux que j’ai conçu pour tester Metaflow (le code est dans le dossier lié à Hearthstone dans ce dépôt).

L’idée de ce flux est de construire un prédicteur de forêt aléatoire de l’archétype basé sur les meilleures cartes de l’archétype que nous voulons attribuer à ceux qui n’ont pas d’archétype. Je pense que le code est assez clair, donc je ne vais pas entrer trop dans les détails de l’exécution car ce n’est pas passionnant. Je vais prendre le temps d’analyser le résultat de plusieurs exécutions avec le client de Metaflow.
Surveillance du flux et des exécutions
Les données produites pendant les différentes exécutions du flux sont stockées dans un data store dans un stockage local (dans un dossier caché /metaflow sur votre répertoire de travail). Néanmoins, tous les résultats peuvent être accessibles directement dans un notebook. Je vais mettre la “partie de traitement” des artefacts des différentes exécutions dans un gist.
L’objectif est de calculer le temps d’exécution, collecter le premier échantillon de l’ensemble d’entraînement, et les informations sur le meilleur modèle produit par le HPO (précision et paramètres). Voici une capture d’écran du traitement.

Comme nous pouvons le voir, il y a beaucoup d’informations qui sont versionnées pendant l’exécution du flux. J’aime vraiment ce versionnement de toutes les données produites pendant un pipeline pour la reproductibilité et le débogage, c’est excellent.
Regardons maintenant la partie AWS de Metaflow.
Et le cloud ?
Metaflow vous donne tous les processus pour configurer votre environnement AWS dans leur documentation. Néanmoins, je suis paresseux, et ils peuvent vous donner accès à un sandbox AWS (avec des ressources restreintes pour tester les fonctionnalités sur le cloud) juste en vous inscrivant sur le site web.
Après quelques jours, vous avez accès au sandbox (je voudrais encore remercier le support Metaflow d’avoir accordé mon accès un peu plus longtemps à leur sandbox pour faire quelques présentations autour de moi).

Pour configurer la connexion au sandbox, c’est simple, il suffit d’ajouter un jeton dans une ligne de commande de Metaflow. Après cela, tout votre backend est :
- Datastore sur S3
- Metadata store dans une base de données de type RDS
- Calcul sur votre machine locale ou le service AWS batch
- Notebook dans Amazon Sagemaker
Deux options sont utilisées pour accéder au calcul AWS depuis votre machine locale :
- Utilisez l’attribut --with batch avec la commande run, comme ça tout votre flux utilise AWS batch comme ressource de calcul
- Si vous voulez exécuter seulement des étapes spécifiques sur AWS, et utiliser la puissance de votre machine locale pour les autres tâches, vous pouvez utiliser le décorateur AWS @batch à la déclaration de votre étape
J’ai trouvé cette approche de gestion cloud convaincante et facile à utiliser et le passage du calcul local au calcul cloud est simple. Pour illustrer le calcul cloud, j’ai juste pris une capture d’écran de l’utilisation du CPU sur mon instance qui exécute mon code Metaflow par rapport au type d’exécution que j’ai effectué.
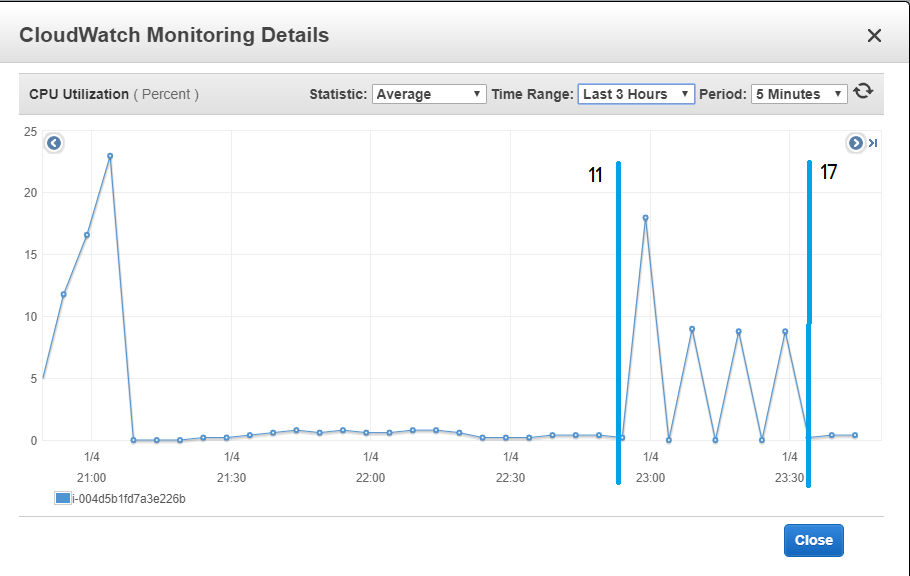
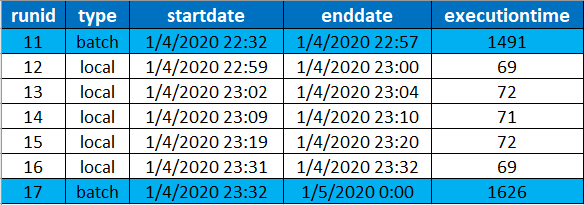
Je pense que c’est une bonne illustration du fait que ma machine locale n’est pas utilisée pour faire le calcul par rapport à l’exécution locale (entre les limites de l’exécution 11 et 17).
Et maintenant la question finale sur Metaflow, peut-il fonctionner avec mlflow.

Ne croisez pas les flux !?
Non s’il vous plaît faites-le, j’ai ajouté dans l’autre script la couche mlflow à mon HPO. J’ajoute juste dans mes logs mlflow des informations liées à mon exécution Metaflow. Voici une capture d’écran des logs de mlflow.
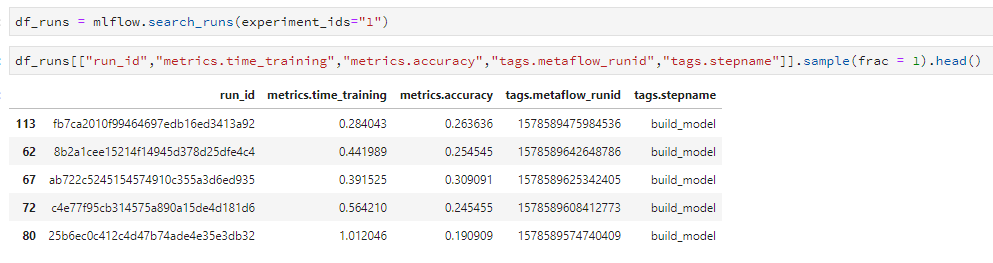
Les deux frameworks de versionnement semblent bien fonctionner ensemble. Donc aujourd’hui, nous pouvons faire le monitoring de votre pipeline avec Metaflow, logger votre modèle et faire le déploiement avec mlflow sur n’importe quelle plateforme cloud supportée.
Retour d’expérience
Metaflow est un framework qui a été développé pour les data scientists, il offre :
- Le versionnement de tous les artefacts produits dans un pipeline de machine learning DS
- Une utilisation facile du cloud et la possibilité de paralléliser facilement les tâches
C’est un excellent travail qui a été fait par Netflix et open-sourcé. Plus d’éléments arrivent sur Metaflow comme :
- Le package R
- La capacité d’utiliser AWS steps comme un ordonnanceur (mais ce n’est pas encore là, donc je pense que cela montre que ce n’est pas une technologie si facile à utiliser).
- Le déploiement de modèles avec Sagemaker, ils vont couvrir un autre aspect de mlflow (sur AWS).
Les seuls inconvénients que j’ai sur Metaflow sont :
- Le décorateur conda construit beaucoup d’environnements conda dans votre environnement python donc ça peut paraître désordonné
- Le framework semble très lié à AWS donc pas ouvert à d’autres plateformes cloud (mais sur GitHub il semble que certaines personnes essaient de le faire fonctionner pour GCP par exemple)
- Spark semble totalement hors du plan
Je vais suivre l’évolution de Metaflow, mais honnêtement, le premier essai était bon, et je vous invite à l’essayer et à vous faire votre propre opinion.
Références
- Metaflow — metaflow.org
- Tutoriels Metaflow — documentation
- Open-Sourcing Metaflow, a Human-Centric Framework for Data Science — Medium / Towards Data Science
- Spotify Luigi — GitHub
- Documentation Metaflow — documentation
- Les décorateurs en Python — datacamp.com
- Dépôt metaflow-experimentation — GitHub
- Documentation Metaflow sur AWS — documentation
- Sandbox AWS Metaflow — metaflow.org
- AWS S3 — AWS
- AWS RDS — AWS
- AWS Batch — AWS
- Amazon Sagemaker — AWS