
Introduction de TensorFlow 2.0
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Dans cet article, je vais présenter certaines de mes découvertes sur mon exploration de TensorFlow, l’idée sera avec TensorFlow de construire et surveiller des modèles ML autour de la classification d’images et quel meilleur jeu de données que le jeu de données de voitures que j’ai construit il y a quelques semaines.
TensorFlow, qu’est-ce que c’est ?
TensorFlow est un projet lancé en 2011 par Google Brain comme projet de recherche et qui est devenu très populaire dans le groupe Alphabet au fil des années. Le framework est populaire dans la communauté du machine learning par son architecture hautement flexible qui peut exploiter différents types d’unités de traitement comme CPU, GPU ou TPU pour exécuter des calculs sans grandes modifications du code en cours d’exécution.
Le framework est open-sourcé depuis 2015 et semble très populaire partout dans le monde avec plus de 76 000 000 de téléchargements. Il existe plusieurs API offertes par Google pour interagir avec le framework comme Python, Javascript, C++, Java et Go.
TensorFlow possède plusieurs outils pour produire des systèmes de machine learning :
- TensorFlow (dah)
- TensorFlow.js
- TensorFlow lite pour déployer des modèles de machine learning dans un système embarqué
- TensorFlow Extended pour productioniser des pipelines de machine learning
- TensorFlow Quantum une “bibliothèque pour le prototypage rapide de modèles ML hybrides quantiques-classiques”
L’ensemble d’outils est très large et je vous conseille vraiment de jeter un œil aux différentes documentations ci-dessus qui vous donneront un excellent aperçu des outils.
Je vais juste parler de TensorFlow, mais je prévois de jeter un œil dans quelques semaines sur les outils Lite et .js (j’ai commandé un appareil pour faire des tests dessus 😉).
TensorFlow, comment construire un modèle ML ?
Pour interagir avec TensorFlow, l’une des API les plus populaires est celle Python (et pour être honnête, c’est celle avec laquelle je suis le plus à l’aise), mais il y a deux chemins disponibles pour interagir avec cette API :
- Celui pour débutant qui utilise une API séquentielle conviviale appelée Keras
- Celui pour expert qui utilise une API de sous-classement plus pythonique
Je vous joins une capture d’écran d’un exemple des deux formats d’API
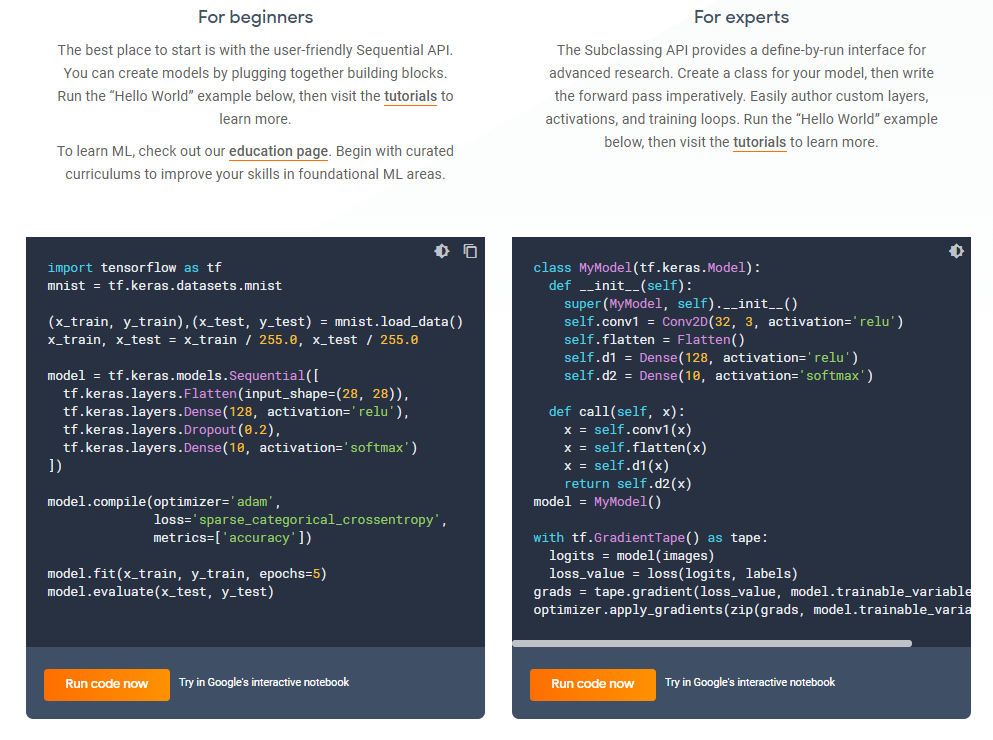
Pour moi, je conseillerais vraiment d’utiliser celle Keras qui est peut-être plus facile à lire pour un non-expert Python. Cette API, à l’origine dans la version TensorFlow 1.x, n’était pas une API native (depuis la 2.0 c’est natif) et devait être installée séparément pour y accéder.
Keras est une API qui peut fonctionner au-dessus de divers frameworks ML comme TensorFlow, CNTK et Theano pour aider les gens à réutiliser facilement des fonctions pour construire des couches, des solveurs, etc. sans aller trop en profondeur sur le framework ML (une couche d’abstraction en quelque sorte).
Construisons quelques modèles pour tester le framework.
Construction de modèles
Dans cette partie, je ne vais pas entrer dans une explication des architectures des modèles que je vais utiliser (peut-être dans un article spécifique). Pour commencer la construction du modèle, je dois d’abord connecter le framework aux données.
Les données sont divisées entre des dossiers liés à l’ensemble d’entraînement, de validation et de test, dans chaque dossier, il y a un sous-dossier pour chaque classe à prédire contenant toutes les images qui seront utilisées pour le processus. Voici un graphique pour représenter la distribution des images par classe dans l’ensemble d’entraînement.
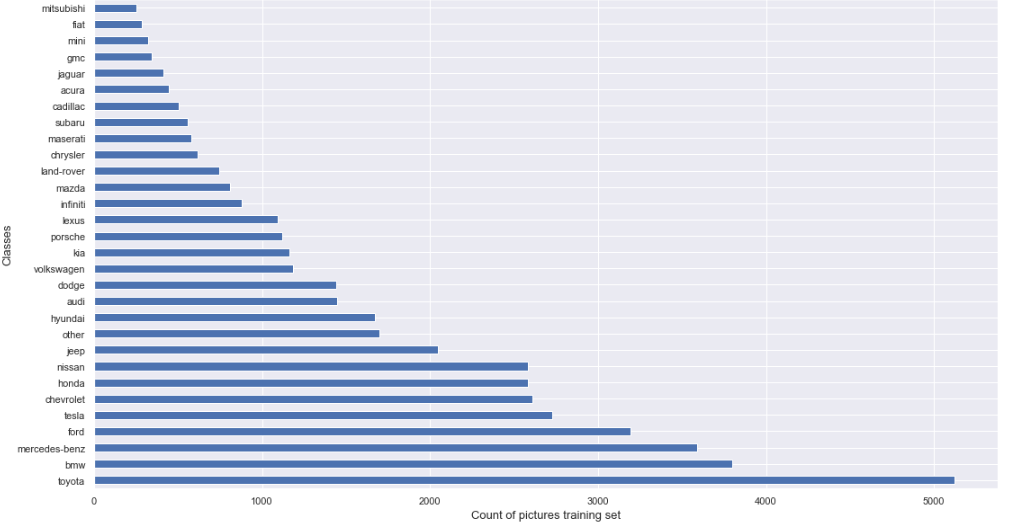
La répartition des classes dans l’ensemble de validation et de test est la même que dans l’ensemble d’entraînement avec juste moins de données (entraînement 80%, validation 10% et test 10% du jeu de données complet).
Pour utiliser les données dans le modèle, un générateur de données peut être utilisé comme dans ce tutoriel de TensorFlow, voici une capture rapide du code.
L’idée de ce code est de :
- Normaliser l’image (RGB converti d’une valeur entre 0-255 à 0-1)
- Redimensionner les images
- Construire les différents lots pour l’entraînement
Il doit être appliqué à tous les dossiers, mais après cela, tout est prêt pour commencer l’entraînement du modèle.
En termes de modèles, j’ai réutilisé la conception de modèle du tutoriel de TensorFlow et appliqué à d’autres ressources. Les modèles peuvent être trouvés dans ces gists :
- Le tutoriel CNN de TensorFlow
- Le MLP d’Aurelien Geron dans le chapitre 10 de son livre Hands-on machine learning with Scikit-Learn, Keras and TensorFlow
- Le CNN de Sebastian Raschka et Vahid Mirjalil dans le chapitre 15 de leur livre Python machine learning
Les entrées et la sortie du modèle ont été adaptées pour répondre à mes besoins, mais la plupart du code provient des différentes ressources listées. Encore une fois, ces modèles sont seulement là pour tester le framework, ils ne sont pas optimaux pour mon problème (et auront besoin de beaucoup de raffinement).
En exécutant la génération de données et la construction du modèle, le modèle est prêt après quelques minutes.

Jetons maintenant un œil au composant de surveillance de TensorFlow.
Surveillance du modèle
Pour surveiller votre modèle, il y a deux chemins (pour moi) avec TensorFlow :
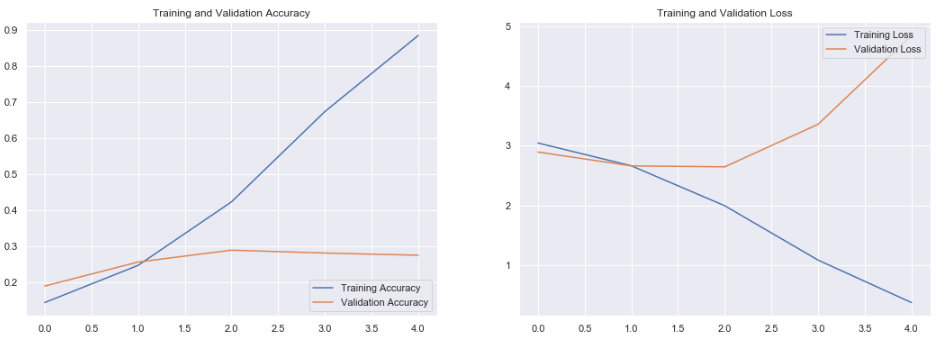
- Utiliser l’historique de l’opération d’ajustement du modèle pour accéder aux différentes métriques qui ont été calculées (dans ce cas la perte et la précision)
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']La sortie de l’historique peut être utilisée pour tracer des graphiques très facilement avec matplotlib par exemple.
- L’autre chemin est d’utiliser un composant appelé Tensorboard, c’est un package associé à TensorFlow qui offre la capacité de collecter en direct diverses métriques pendant votre exécution pour construire un modèle (cf gif), visualiser l’architecture, les données, etc.
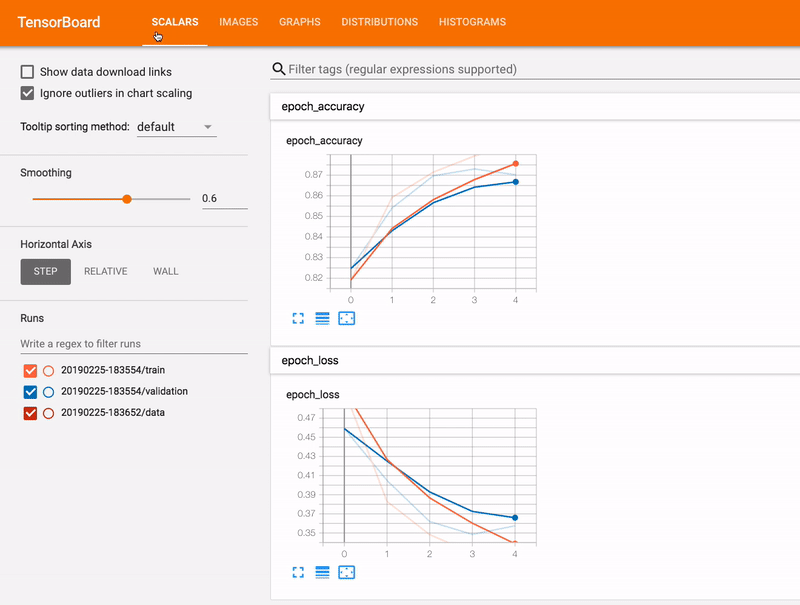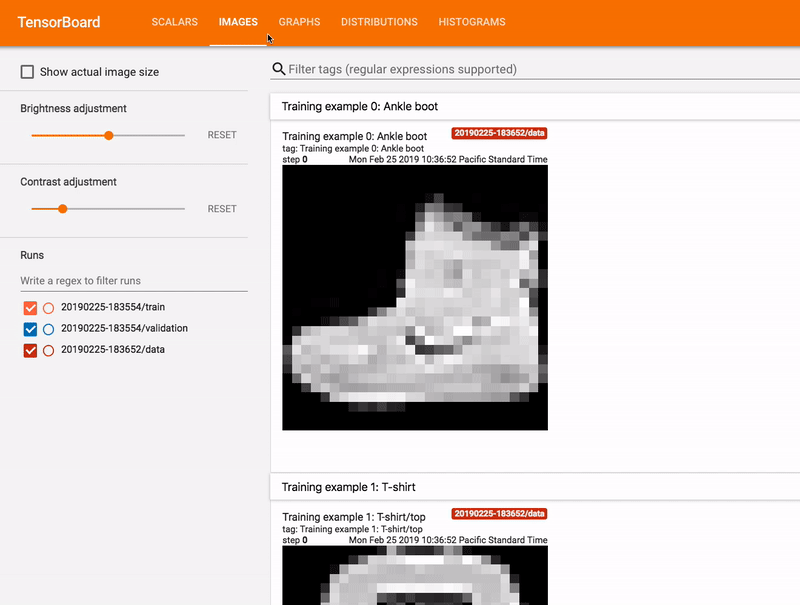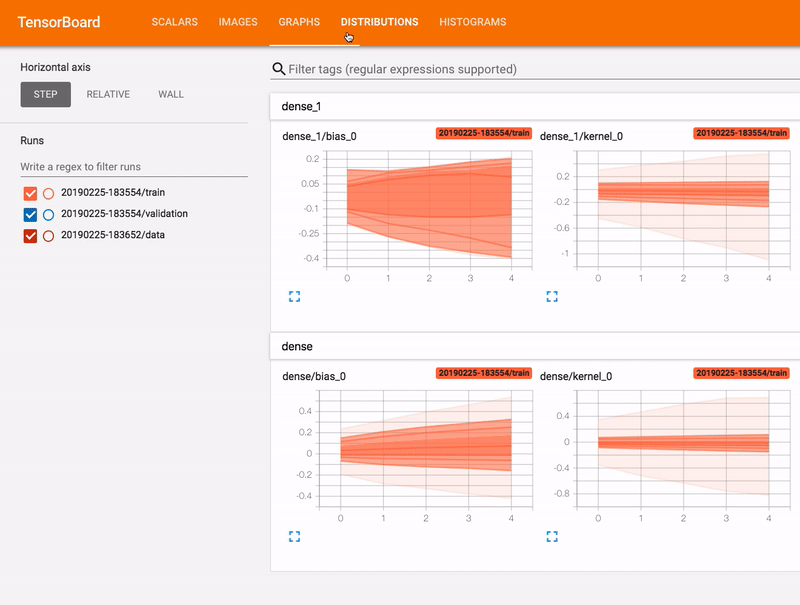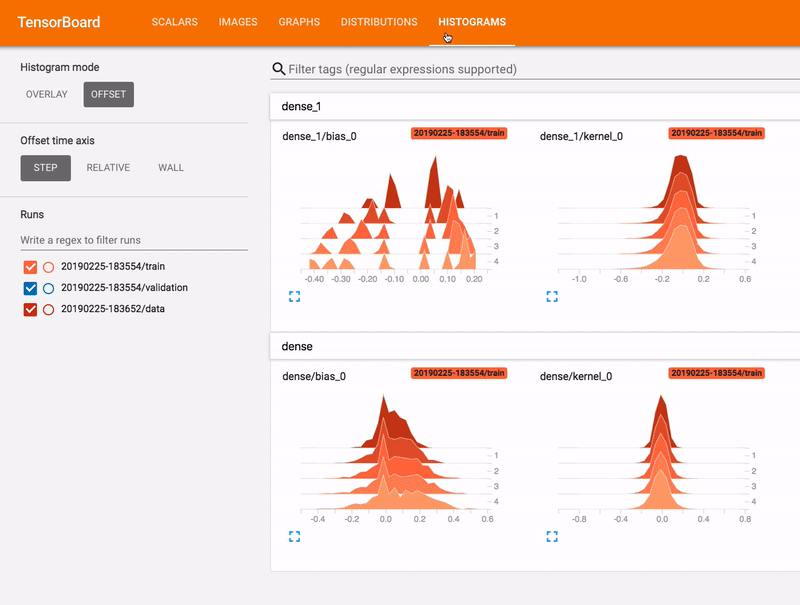
Récemment, Google a annoncé la capacité de partager le tableau de bord avec tout le monde avec l’initiative tensorboard.dev, vous pouvez trouver par exemple à ce lien un tensorboard associé à certaines de mes exécutions pour ce projet.
Tensorboard est une initiative intéressante et ils ont annoncé beaucoup de nouvelles fonctionnalités lors du dernier sommet TensorFlow dev, mais je ne suis honnêtement pas un praticien du deep learning très expérimenté donc je ne suis pas un très bon défenseur de ce composant qui me semble complexe, mais je pense que cela pourrait être un très bel outil pour une boîte à outils de data science en association avec mlflow.
Pour finir cette analyse, je voulais présenter un autre composant appelé TensorFlow hub.
Partage de modèles avec TensorFlow hub
TensorFlow hub est né chez Google d’une situation simple : si je lis un très bon article sur une architecture de réseau de neurones qui semble très prometteuse, mais beaucoup de questions peuvent surgir pendant l’investigation comme :
- comment puis-je reproduire cet article ?
- (dans le cas d’un dépôt dans l’article) Est-ce la dernière version du modèle ?
- où sont les données ?
- (dans le cas d’un dépôt dans l’article) Est-il sûr d’utiliser ce morceau de code ?
TensorFlow hub veut être là pour les gens pour limiter toutes ces questions et donner plus de transparence sur le développement ML.
Une fonctionnalité très intéressante de TensorFlow hub est d’aider les gens à construire un modèle de machine learning avec des composants de modèles célèbres et robustes, cette approche est de réutiliser les poids de modèles d’un autre modèle et on appelle ça transfer learning.
Avec TensorFlow hub, vous pouvez réutiliser en quelques lignes de code des composants d’un autre modèle très facilement, dans le gist suivant il y a une illustration d’un code que j’ai construit pour réutiliser un extracteur de caractéristiques d’un modèle appelé Mobilenetv2 très populaire pour la classification d’objets (principalement inspiré par le tutoriel TensorFlow).
Faisons maintenant un récapitulatif de cette analyse
Retour d’expérience
Cette première expérience pratique sur TensorFlow était très bonne, j’ai trouvé les tutoriels plutôt bien faits et compréhensibles et vous pouvez vraiment facilement construire des réseaux de neurones avec l’API Keras du framework. Il y a beaucoup de composants que je n’ai pas encore testés comme on peut le voir sur cette capture d’écran

J’ai eu l’occasion de jeter un œil à TensorFlow Extended (TFX) qui est l’approche de Google pour construire un pipeline de machine learning, j’ai fait un essai sur une instance AWS EC2 mais le tutoriel a planté à un moment donné, mais je vous invite à regarder cette excellente présentation de Robert Crowe qui présente l’outil plus en détail.
L’approche semble très prometteuse et je suis vraiment curieux de voir les interactions qui existeront entre TFX et Kubeflow (un autre pipeline ML de Google basé sur Kubernetes).
Ma seule préoccupation/interrogation sur TensorFlow est l’utilisation de l’unité de traitement, pendant mes tests j’ai alterné entre CPU et GPU mais ma surveillance du traitement n’a pas montré que l’unité de traitement était utilisée à plein potentiel (mais je suis peut-être juste un débutant).
Une autre piste pour augmenter l’efficacité de TensorFlow est d’utiliser les tfRecords, mais il semble que la gestion des données soit toujours un sujet brûlant (d’après ce que j’entends autour de moi), j’ai trouvé une présentation Pydata vraiment intéressante autour de la gestion des fichiers parquet avec TensorFlow.
Mes prochaines tâches autour du deep learning sont de :
- Faire une introduction douce à Pytorch, fait par Facebook, il semble être la némésis de TensorFlow et ce framework gagne beaucoup de traction dans le monde de la recherche
- Monter en compétence sur les algorithmes de deep learning pour construire un classificateur de voitures décent
- Comprendre le déploiement de ces modèles de deep learning en production (gestion des données, service, etc.)
Références
- TensorFlow — tensorflow.org
- CPU — Wikipedia
- GPU — Wikipedia
- TPU — Wikipedia
- TensorFlow — tensorflow.org
- TensorFlow.js — tensorflow.org
- TensorFlow lite — tensorflow.org
- TensorFlow Extended — tensorflow.org
- TensorFlow Quantum — tensorflow.org
- deux chemins disponibles — tensorflow.org
- tutoriel — tensorflow.org
- conception de modèle — tensorflow.org
- Le tutoriel CNN de TensorFlow — GitHub Gist
- Le MLP d’Aurelien Geron — GitHub Gist
- Hands-on machine learning with Scikit-Learn, Keras and TensorFlow — oreilly.com
- Le CNN de Sebastian Raschka et Vahid Mirjalil — GitHub Gist
- Python machine learning — packtpub.com
- Tensorboard — tensorflow.org
- tensorboard.dev — tensorflow.org
- TensorFlow hub — tfhub.dev
- transfer learning — Wikipedia
- Mobilenetv2 — arXiv
- tutoriel TensorFlow — tensorflow.org
- TFX — tensorflow.org
- Kubeflow — kubeflow.org
- tfRecords — tensorflow.org
- traction — thegradient.pub