
Points clés de RecSys 2021
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Encore une fois, j’ai assisté (virtuellement) cette année avec certains de mes collègues à RecSys 2021 à Amsterdam. Dans cet article, je vais récapituler les articles et initiatives excitants que j’ai vus pendant cet événement (conférence + workshop).
Conférence
Les jours de conférence étaient divisés par des sessions de pistes principales, des affiches, des rencontres virtuelles et des conférences industrielles. Dans cette section, je partagerai les articles intéressants que j’ai vus.
Jour 1
Ce jour était axé sur trois sujets :
- Echo Chambers et Filter Bubbles
- Théorie et Pratique
- Métriques et Évaluation
J’ai sélectionné du premier sujet un article présenté par Matus Tomlein : An Audit of Misinformation Filter Bubbles on YouTube: Bubble Bursting and Recent Behavior Changes.
couverture de l'article

Cet article réitère une expérience qui s’est produite il y a quelques années pour auditer les systèmes de recommandation et évaluer comment ils fonctionnent. L’idée est de construire un bot qui recherchera sur un sujet spécifique, stockera le contenu affiché, et après un processus manuel, auditera les résultats des systèmes de recommandation. Tout le code pour ce processus est dans ce repository GitHub, et il y a quelques résultats.
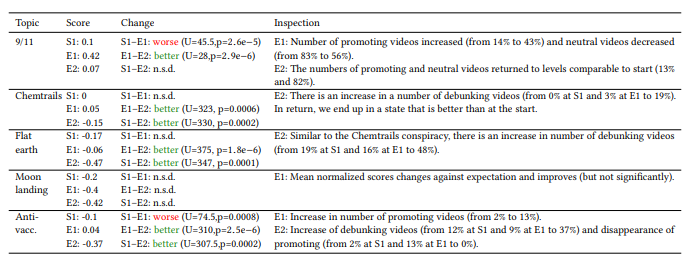
Les résultats globaux ont montré que sur certains sujets spécifiques, les systèmes de recommandation semblent être plus pondérés qu’il y a quelques années en montrant plus de contenus neutres qui démystifient les théories du complot (sauf sur des sujets comme le 9/11 ou l’anti-vaccination sur les expériences spécifiques)
Dans la deuxième session autour de la Théorie et de la Pratique, l’article que j’ai choisi est Jointly Optimize Capacity, Latency and Engagement in Large-scale Recommendation Systems présenté par Hitesh Khandelwal de Facebook.
couverture de l'article

Cet article présente une technique pour optimiser l’efficacité d’un système de recommandation (pour le service) en mettant en cache les recommandations pour réduire la latence. Habituellement, la technique de mise en cache n’est pas efficace ; cet article offre une autre approche pour le faire. Pour appliquer cette technique de mise en cache, vous devez avoir un système de recommandation en deux étapes avec des étapes de récupération et de classement ; si vous voulez plus de détails, vous pouvez regarder cette vidéo de la communauté mlops d’Eugene yan sur le sujet, mais il y a le flux global.
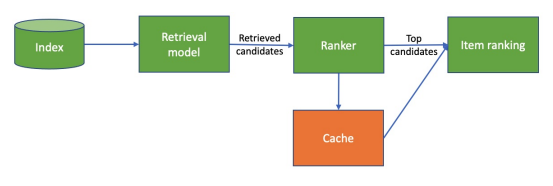
Dans cet article, le recommandeur a de nouvelles couches sur les étapes de récupération et de classement.
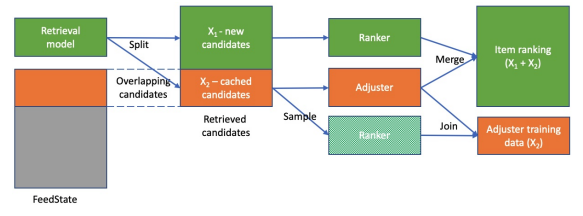
D’après les auteurs, ce pipeline est pertinent pour différents contextes (il semble avoir basé son travail sur les données du marché Facebook), quelque chose à essayer à un moment mais doit avoir la première version du flux fonctionnant.
Enfin, la dernière session était sur les métriques et l’évaluation ; l’article que je mets en évidence était Reenvisioning the comparison between Neural Collaborative Filtering and Matrix Factorization présenté par Vito Walter Anelli du Politecnico di Bari.
couverture de l'article

J’ai sélectionné cet article pour deux choses :
- Parler de cette grande question que pouvons-nous approximer la factorisation matricielle avec un perceptron multicouche et si cela donne de bons résultats (un long débat que je vois beaucoup sur les éditions passées de recsys)
- Explication d’un pipeline pour faire l’évaluation du recommandeur
Je n’entrerai pas trop dans les détails pour le premier point (je vous laisserai lire l’article) parce que je n’aime pas trop la comparaison d’algorithmes sur des jeux de données standard comme benchmark. Mais pour le deuxième point, c’était plus pour mettre en évidence le travail du Politecnico di Bari autour de l’évaluation des systèmes de recommandation ; ils ont construit un framework appelé Elliot pour aider à évaluer les systèmes de recommandation du point de vue de la recherche.
J’ai quelque chose sur la liste de test dans le futur car cela semble super prometteur et utile du point de vue de l’expérience.
Autour de ces sessions, il y avait des rencontres animées par des gens de l’industrie ; je ne vais pas entrer dans les détails sur cette rencontre car elles sont très informelles mais voici quelques choses que j’ai apprises :
- Rencontre Netflix : parler beaucoup d’apprentissage par renforcement et de bandit pour le système de recommandation, mais ne voulaient pas partager les résultats de leurs expériences
- Rencontre Zalando : c’est impressionnant de voir le travail de Zalando (ils ont environ 250 scientifiques appliqués qui semblent énormes pour moi). Leur flux de travail semble fonctionner en style kanban, et ils organisaient des revues scientifiques hebdomadaires sur leurs expériences.
Enfin, pour conclure la journée, il y avait des conférences industrielles organisées par Zalando avec trois acteurs de l’industrie (encore une fois, un rapide récapitulatif sur l’événement) :
- Grubhub: le présentateur parlait de leur façon d’entraîner des modèles et de faire de l’apprentissage en ligne ; j’aime leur flux autour de la dérive des métriques basé sur les périodes de ré-entraînement
- Nike: le présentateur expliquant leur façon de construire les systèmes de recommandation sur leur application à partir de zéro, et ils ont un pipeline assez décent (qui semble complexe), mais cela semble intéressant.
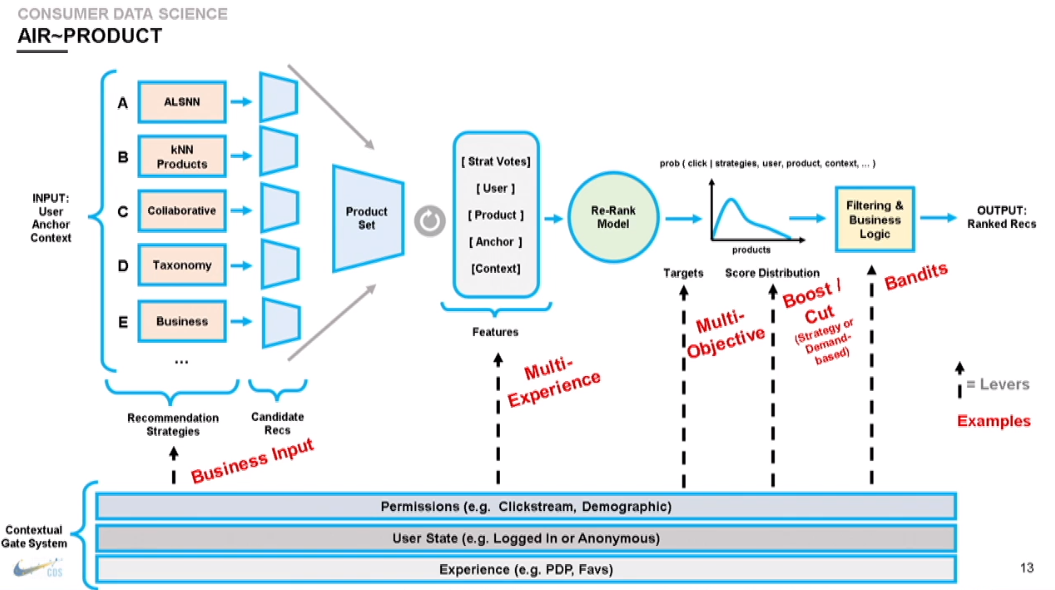
Le point intéressant sur ce flux est que leur pipeline est déployé (avec le même code) dans chaque zone géographique pour respecter les règles de confidentialité en place
- Netflix: sur cette conférence/article, un ingénieur de l’entreprise apporte la notion de recsysops (mlops spécialisé pour recsys), semble adapté à leur besoin de maintenance de systèmes de recommandation larges et complexes, mais j’aime dans l’approche la division entre quatre piliers (détection, prédiction, diagnostic et résolution), plus précisément je suis fan de :
- La prédiction des problèmes qui peuvent se produire avec de nouveaux contenus publiés (essayer de prédire une semaine avant si le contenu apportera une dégradation du modèle et anticiper cela)
- La résolution en faisant un maximum d’actions sur une UI sans code.
Oh, et je suis fan de l’engagement du conférencier à correspondre au thème utilisé sur les diapositives (c’était un thème de money heist)

Commençons le jour 2.
Jour 2
Pour ce jour, la piste principale était autour de :
- Utilisateurs en focus
- Langage et connaissance
- Recommandation interactive
Pour la première section sur les utilisateurs en focus, j’apprécie la conférence de Christina Boididou de la BBC Building public service recommenders: Logbook of a journey.
couverture de l'article

Dans cette conférence, la conférencière a partagé le flux de l’équipe datalab de la BBC pour construire des systèmes de recommandation pour le contenu sur la plateforme :
- Le premier était de garder l’équipe éditoriale toujours impliquée dans le déploiement du nouveau système de recommandation en obtenant leurs retours sur la sortie produite par recsys
- un autre aspect mentionné était leur principe de moteur de machine learning en général ; je trouve qu’ils sont très transparents dans leur approche (il y a un article avec plus de détails dessus disponible pour tout le monde sur le site web de la BBC) ; voici le flux global
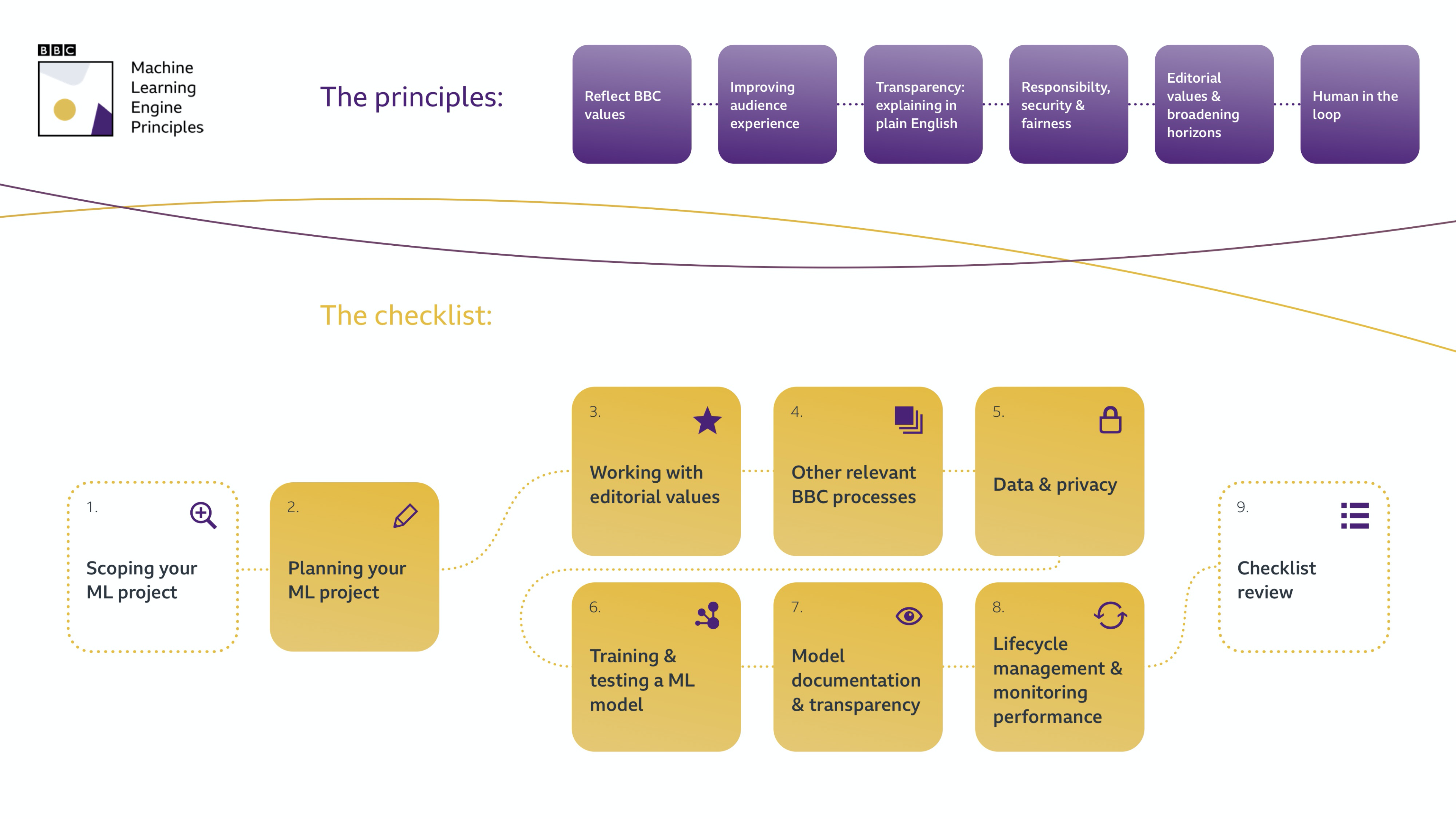
- Quand vous commencez à développer un système ML, construisez-le rapidement et simplement pour commencer.
Sur la deuxième session sur le langage et la connaissance, je triche un peu, mais j’ai deux articles en tête :
- Le premier de NVIDIA présenté par Even Oldridge et Gabriel de Souza Pereira Moreira Transformers4Rec: Bridging the Gap between NLP and Sequential / Session-Based Recommendation.
couverture de l'article

Cet article présente une approche pour exploiter les transformers (qui sont habituellement dans le monde NLP) mais pour les systèmes de recommandation pour un système basé sur les sessions.
![]()
Semble excellent et prometteur ; je ne suis pas très connaisseur de ce genre d’approche pour donner une opinion claire dessus (sauf qu’ils ont une équipe Merlin comme nous, mais nous étions là avant #ubi2018)
- Le deuxième article sélectionné, c’est d’Aravind Sankar pour l’Université de l’Illinois et est appelé ProtoCF: Prototypical Collaborative Filtering for Few-shot Item Recommendation.
couverture de l'article
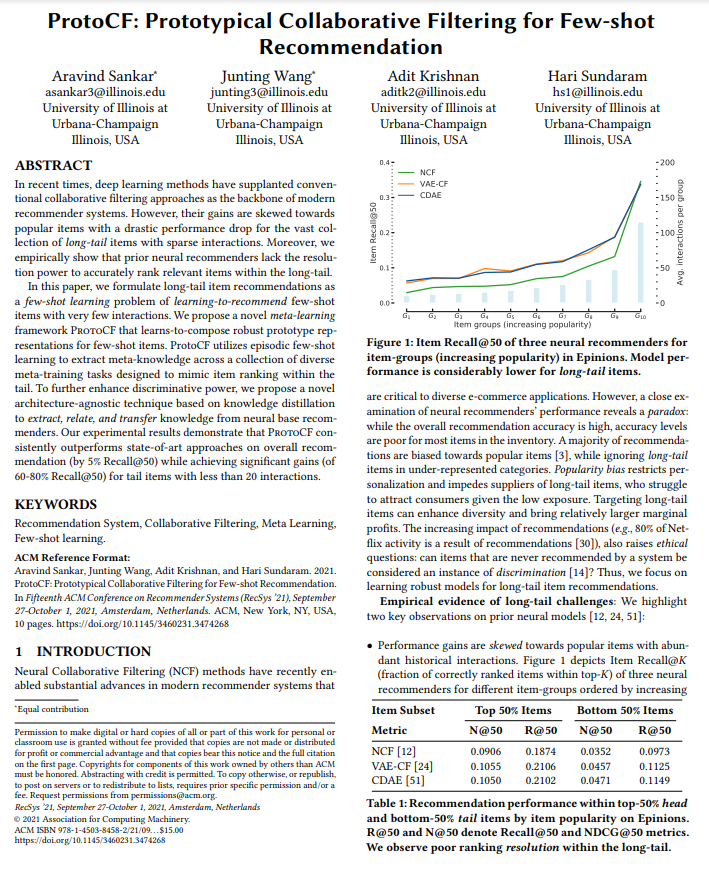
Dans cette approche, l’idée est de s’attaquer au problème de la tête et de la queue des systèmes de recommandation en faisant une connaissance basée sur ce qui se passe dans la tête (distillation de connaissance) et sur la queue (transfert de connaissance) ; cette connaissance utilisait des approches de réseaux de neurones.
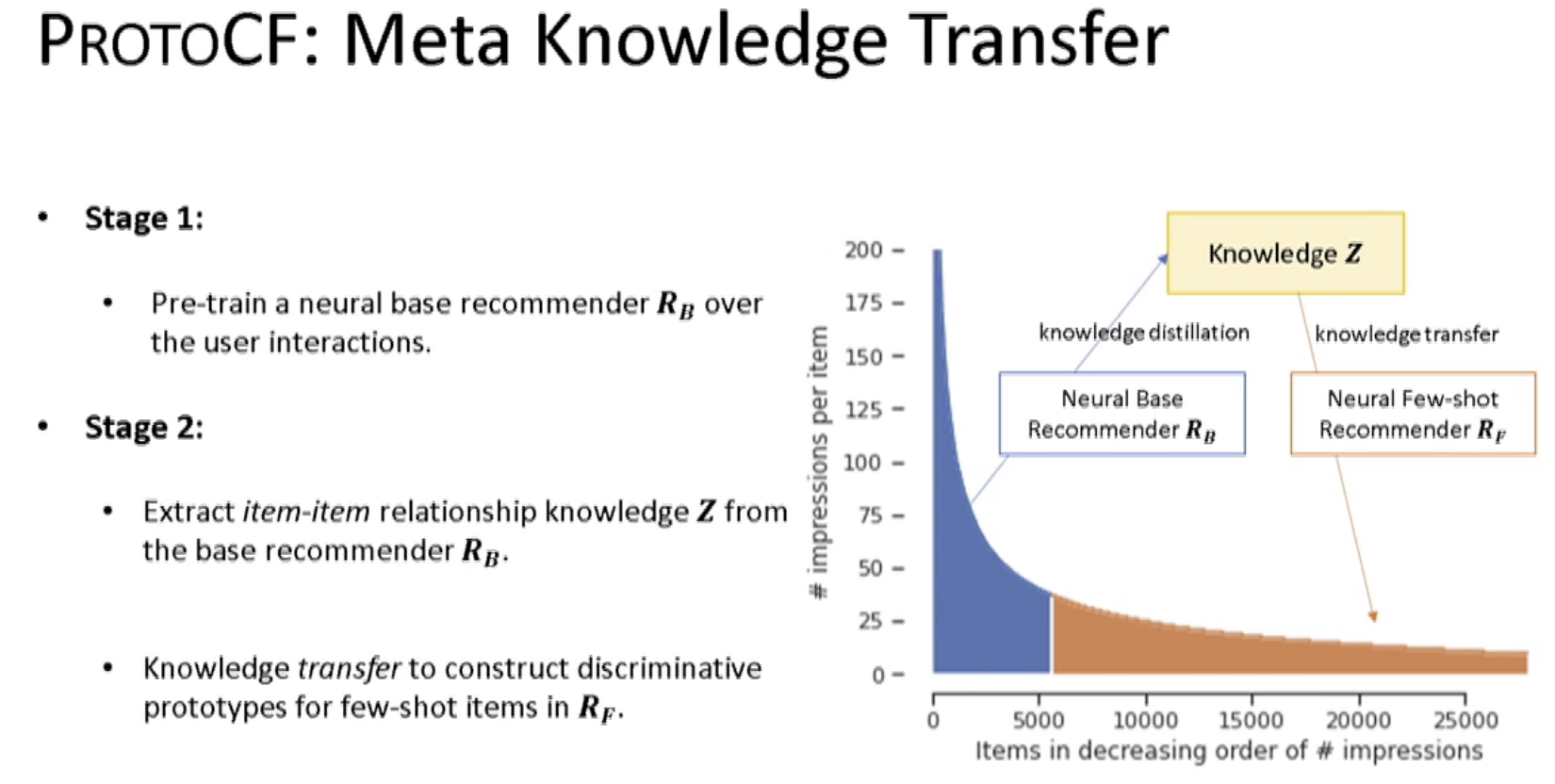
Le code n’est pas encore disponible mais bientôt.
Pour la dernière section sur les recommandeurs interactifs, j’ai sélectionné la conférence d’Amazon de Francois Mairesse Learning, a voice-based conversational recommender using offline policy optimization.
couverture de l'article

L’article présente le processus pour améliorer la fonctionnalité d’Alexa pour recommander des chansons à écouter aux utilisateurs en démarrant une discussion.

Tout l’entraînement a utilisé une approche d’apprentissage par renforcement pour entraîner un modèle suivi de deux tests AB a été fait et montre un uplift réussi de la nouvelle approche (contre un chemin hardcodé).
Voyons le troisième jour de la conférence.
Jour 3
Pour ce jour, les sessions étaient :
- Performance évolutive
- Avancées algorithmiques
- Équité de la confidentialité
J’ai sélectionné l’article présenté par Lonqqi Yang de Microsoft, Local Factor Models for Large-Scale Inductive Recommendation pour la performance évolutive.
couverture de l'article

Microsoft a construit une solution qui exploite des clusters dans l’utilisateur et les articles pour faire des recommandations.
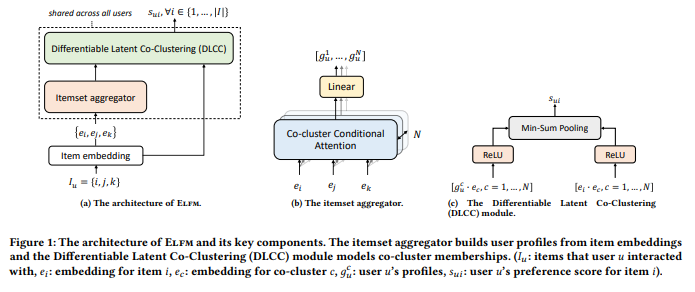
Pas un expert avec tous les éléments, mais cela semble une solution évolutive de la présentation, et je vous conseille de jeter un œil au Github du conférencier ; il y a des choses cool (comme ce repository openrec)
Pour les avancées algorithmiques, j’ai choisi l’article présenté par Wenzhuo Song de l’Université de Jilin, Next-item Recommendations in Short Sessions.
couverture de l'article

L’idée est de construire une prédiction de séquence basée sur la connaissance extraite des sessions précédentes, encore une fois pas mon domaine de connaissance (je prévois de travailler sur ce problème de séquence bientôt, et c’est adapté pour mon cas d’usage au bureau)
Le code n’est pas encore disponible, mais il devrait arriver ici bientôt.
Enfin, sur la confidentialité, l’équité et le biais, je serai honnête, ce n’était pas l’une des sessions les mieux classées (pour moi) de la conférence, mais j’ai trouvé deux conférences très intéressantes :
- La première est d’Andreas Grün de ZDF (l’équivalent de la télévision nationale en Allemagne, l’une des top3), Challenges Experienced in Public Service Media Recommendation Systems.
couverture de l'article

C’est une présentation de haut niveau, pas technique, mais il y a de grandes leçons à en tirer comme :
- Évaluer le contenu de niche et combien ces contenus sont vus par utilisateur
- Construire un banc d’essai pour les gens éditoriaux pour tester les divers modèles avec leurs données et voir lequel correspond le mieux (semble qu’ils aiment les recommandations du Rulerec)
- Rendre l’entraînement et le service des systèmes de recommandation plus verts, donc évaluer cet impact environnemental
Le deuxième article est de Daniel James Kershaw, d’Elsevier Fairness in Reviewer Recommendations at Elsevier.
couverture de l'article

Pour être honnête, je ne suis pas un grand fan de toute cette publication scientifique avec accès payant avec toutes les revues, mais j’admets qu’ils construisent un recommandeur de réviseurs qui semble vouloir lutter contre la discrimination pour ce projet (et c’est génial). L’article est assez léger, mais la conférence était fascinante.
Jour 4
Pour ce jour, les sessions étaient :
- Avancées axées sur les applications
- Problèmes pratiques
- Préoccupations du monde réel
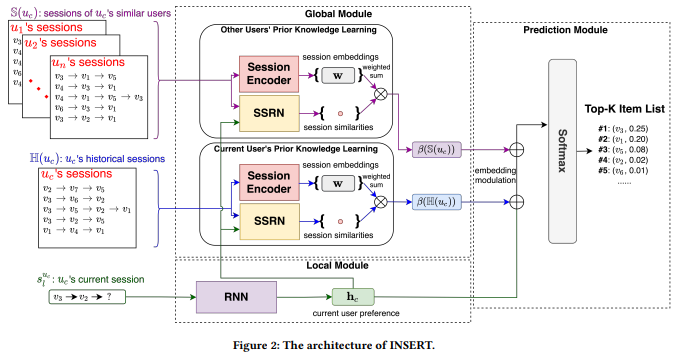
Je vais être honnête. Cela a été une journée plus lente pour moi. Mais pour la première session, sur les avancées axées sur les applications, j’ai sélectionné la conférence de Jérémie Rappaz de l’EPFL Recommendation on Live-Streaming Platforms: Dynamic Availability and Repeat Consumption.
couverture de l'article

L’article est autour de la conception d’un système de recommandation dans une configuration de plateforme de streaming ; les streams, par essence, se produisent à divers moments de la journée ou de la semaine, donc ce comportement devrait être géré pendant le calcul des recommandations. Ainsi, il y a un flux du système.
L’approche semble intéressante ; comme je l’ai dit avant, je dois essayer beaucoup de choses autour de la prédiction de séquence avant de comprendre clairement le processus (et la valeur ajoutée).
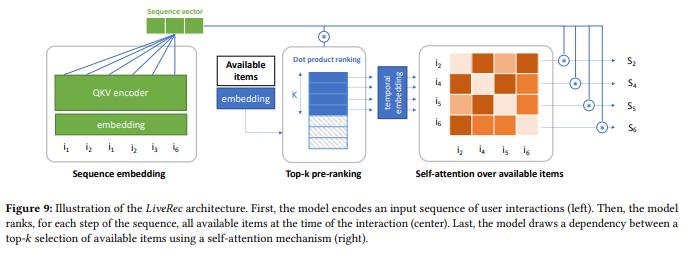
Pour la deuxième session, j’ai sélectionné l’article présenté par Jacopo Tagliabue de Coveo Labs You Do Not Need a Bigger Boat: Recommendations at Reasonable Scale in a (Mostly) Serverless and Open Stack.
couverture de l'article

Dans cet article, le conférencier a présenté une pile pour faire des recommandations en direct avec divers outils tendance ; il y a un aperçu du flux.
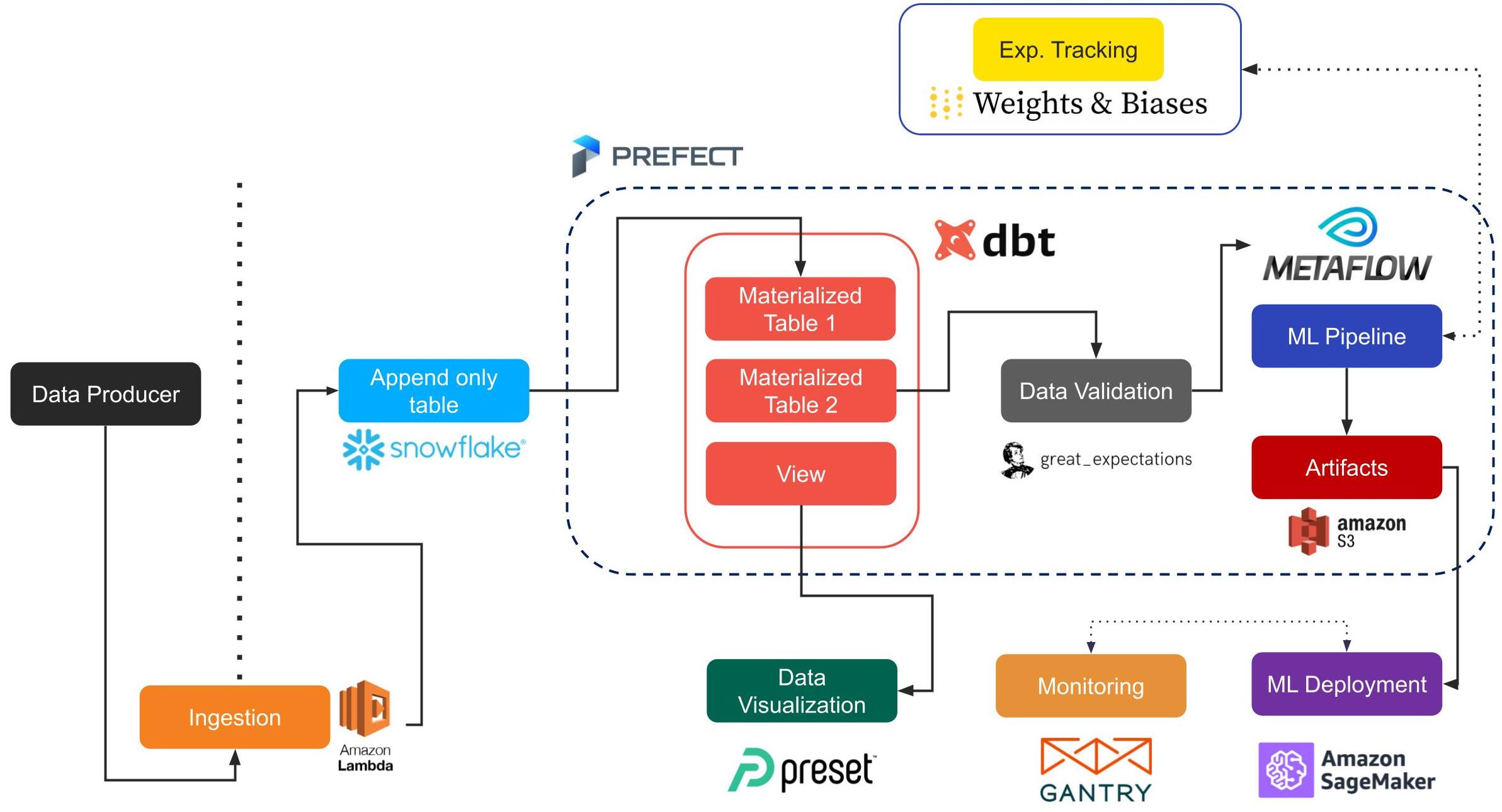
Beaucoup d’outils que j’ai essayés sur des articles passés, et je conseille aux gens de regarder le repository associé, un excellent point de départ pour construire un système de recommandation dans une entreprise.
Enfin, dans la dernière session, j’ai sélectionné l’article d’Huiyuan Chen de Visa research Tops, Bottoms, and Shoes: Building Capsule Wardrobes via Cross-Attention Tensor Network.
couverture de l'article

Cet article s’attaque à la tâche difficile de trouver les bons vêtements qui peuvent compléter une tenue en utilisant un réseau de neurones (quelque chose appelé tensornet).
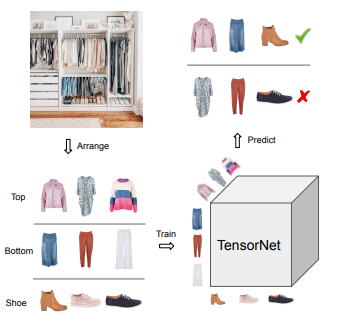
C’est tout pour la conférence principale
Workshops et tutoriels
J’ai assisté virtuellement cette année aux trois workshops suivants :
- Workshop d’évaluation
- Workshop de podcast
- Workshop de mode
Les workshops étaient un mélange entre keynote, discussion et présentations d’articles ou panels.
Du premier workshop, il y a quelques choses que j’ai apprises de la keynote (organisée par Zalando) :
- De bonnes méthodes d’évaluation diff testing et AB testing (qui semble être un gold standard, bien sûr)
- L’explication du diff testing était fascinante, la notion d’évaluer la différence du nouveau modèle versus la base de référence et l’analyser. Trouver un bon moyen de discuter les résultats avec un client qui n’est peut-être pas trop technique.
- Pendant le AB testing, entraîner les modèles en utilisant les données que les autres modèles peuvent avoir impactées semble être une mauvaise idée (parce que quand le test est fait, les modèles vont perdre ces entrées positives ou négatives, donc ce n’est pas la meilleure configuration pour l’évaluation)
- Il y a aussi la notion d’évaluation par sous-groupes d’utilisateurs ; il n’y a pas d’utilisateur moyen, donc se concentrer sur la métrique par sous-population a plus de sens.
Pour l’échange avec les autres participants, vous pouvez regarder ce google doc où les participants ont partagé un récapitulatif de leur discussion.
Sur le deuxième workshop autour du podcast, j’ai assisté par curiosité, mais j’ai collecté quelques informations intéressantes :
- Il y a un besoin significatif d’avoir un jeu de données standard pour l’évaluation ; il n’y a pas de Movielens ou de jeux de données comme Pinterest (Spotify semble travailler dessus)
- La recherche dessus semble être menée par une approche basée sur le contenu et l’analyse de la piste audio (Spotify a open-sourcé l’année dernière un jeu de données sur le sujet).
Je n’ai pas de google docs à partager sur la discussion des participants mais il y a quelques sujets que notre groupe a discutés :
- Jeux de données manquants (bien sûr), vraiment un besoin d’avoir plus que seulement écouter/ne pas écouter/aimer/ne pas aimer un podcast. Avoir plus de données sur l’utilisation de l’application (comment le contenu est consommé) semble être un graal à avoir
- Comment gérer des périodes comme le confinement ou des sujets polarisés qui sont dans les actualités dans le processus de recommandation
Enfin, pour le workshop sur la Mode, il y a quelques informations que j’ai apprises :
- Un échange avec Bjorn Hertzberg, lead data science chez H&M, donnait l’expérience de l’entreprise pour construire des recommandations servies par email avec un filtrage collaboratif avec tous les inconvénients que son approche apporte. Cependant, un aspect remarquable est les embeddings des clients pour le CF pour les clusters et voir ce qui est tendance sur ce groupe récemment pour faire des recommandations, super inspirant.
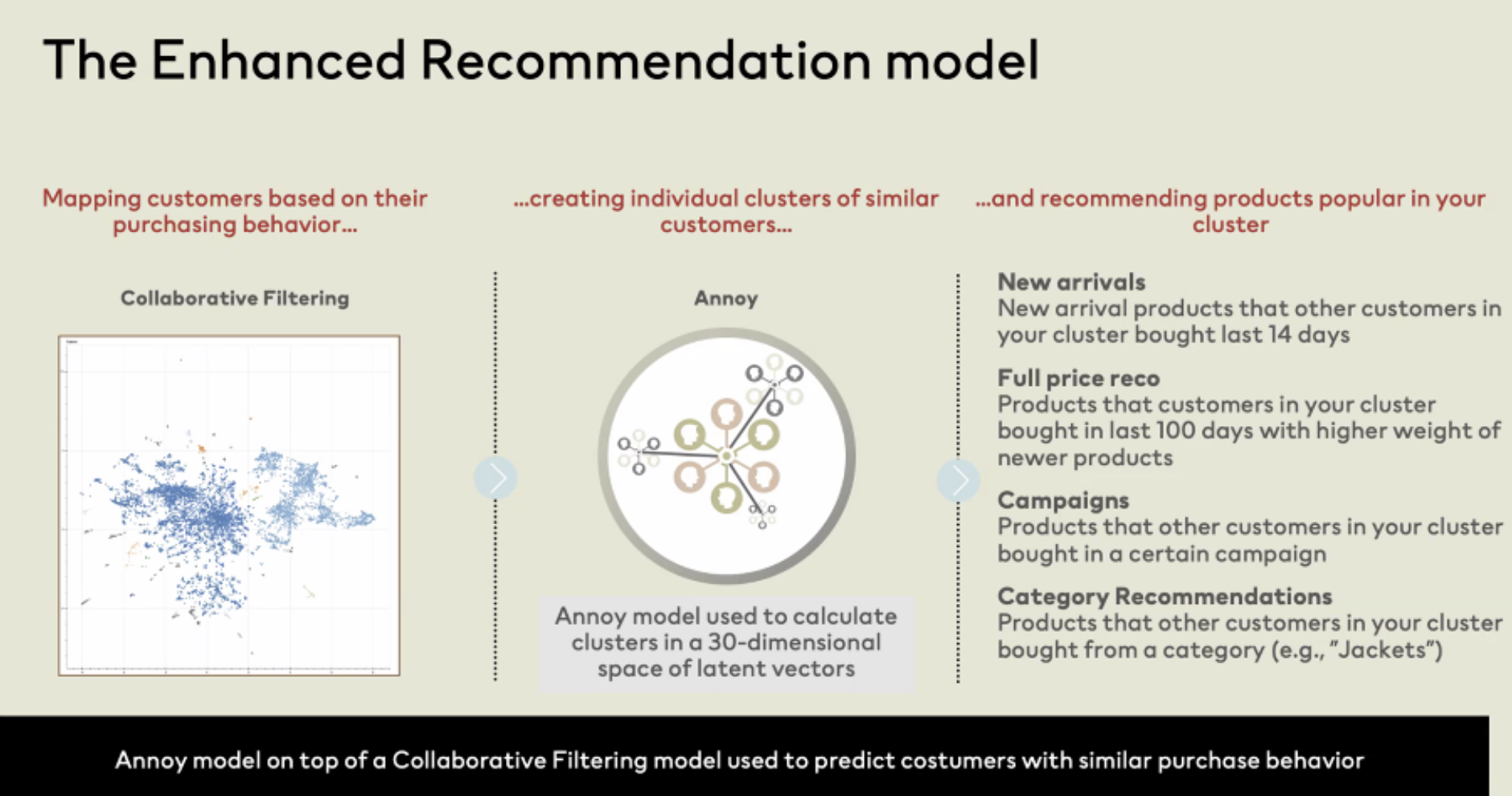
- Une discussion avec Sharon Chiarella, Chief Product Officer chez stitchfix, une entreprise qui crée une expérience de shopping personnalisée (ils ont un blog tech). Ils construisent un outil/jeu générateur de style pour laisser les gens essayer de construire une tenue, et c’est utile pour comprendre la relation des vêtements ensemble (genre de gamification qui est utilisée pour produire des données d’entraînement)
- Des articles intéressants ont été présentés pendant ce workshop, et j’aime :
- L’article présenté par Shereen Elsayed, End-to-End Image-Based Fashion Recommendation. Flux fantastique pour gérer les images comme entrée avec les transactions des utilisateurs (le code est ici).
- Un article de Criteo pour générer une image (comme des chaussures rouges) à partir d’une requête de texte, What Users Want? WARHOL: A Generative Model for Recommendation (pas de code disponible encore)
Le workshop était super intéressant, et je pense que je le suivrai dans les itérations futures.
Conclusion
Donc voici la première version de mon récapitulatif construit pendant la conférence, et je prendrai plus de temps pour analyser les articles et les replays dans le futur. Mais dans l’ensemble, il y a quelques points clés que j’ai gardés :
- Appliquer des techniques NLP pour faire des recommandations est super tendance (BERT4REC, Transformers4REC)
- Moins de projets RL et bandit que l’année dernière, mais toujours des choses cool
- Le recommandeur en deux étapes est une chose à faire (fonctionne bien pour un cas avec un vaste catalogue, semble être un bon candidat pour un futur article sur les données sens critique)
Références
- RecSys 2021 — recsys.acm.org
- An Audit of Misinformation Filter Bubbles on YouTube — dl.acm.org
- Dépôt GitHub yaudit-recsys-2021 — GitHub
- Jointly Optimize Capacity, Latency and Engagement in Large-scale Recommendation Systems — dl.acm.org
- Reenvisioning the comparison between Neural Collaborative Filtering and Matrix Factorization — dl.acm.org
- Politecnico di Bari — SisInfLab — sisinflab.poliba.it
- Elliot — GitHub — GitHub
- Article Grubhub — dl.acm.org
- Article Nike — dl.acm.org
- Article Netflix recsysops — dl.acm.org
- Building public service recommenders: Logbook of a journey (BBC) — dl.acm.org
- Principes du moteur ML de la BBC — bbc.co.uk
- Transformers4Rec: Bridging the Gap between NLP and Sequential / Session-Based Recommendation — dl.acm.org
- ProtoCF: Prototypical Collaborative Filtering for Few-shot Item Recommendation — dl.acm.org
- GitHub ProtoCF — GitHub
- Learning, a voice-based conversational recommender using offline policy optimization — dl.acm.org
- Local Factor Models for Large-Scale Inductive Recommendation — dl.acm.org
- GitHub ylongqi — GitHub
- Dépôt openrec — GitHub
- Next-item Recommendations in Short Sessions — dl.acm.org
- GitHub wzsong17 — GitHub
- Challenges Experienced in Public Service Media Recommendation Systems (ZDF) — dl.acm.org
- GitHub RuleRec — GitHub
- Fairness in Reviewer Recommendations at Elsevier — dl.acm.org
- Recommendation on Live-Streaming Platforms — dl.acm.org
- You Do Not Need a Bigger Boat — dl.acm.org
- Dépôt GitHub you-dont-need-a-bigger-boat — GitHub
- Tops, Bottoms, and Shoes: Building Capsule Wardrobes via Cross-Attention Tensor Network — dl.acm.org
- Récapitulatif du workshop d’évaluation (Google doc) — docs.google.com
- Jeu de données podcast Spotify — byspotify.com
- End-to-End Image-Based Fashion Recommendation — drive.google.com
- GitHub ImgRec — GitHub
- WARHOL: A Generative Model for Recommendation — drive.google.com
- Blog tech Stitchfix — multithreaded.stitchfix.com