
Déployer un pipeline pour collecter des données sur Twitter et Google trends
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Bonjour, dans cet article, je vais vous faire un rapide tour d’un projet que j’ai récemment ressuscité pour collecter les données en ligne de l’élection présidentielle française sur Twitter et Google trends. L’article passera par le nouveau pipeline que j’ai conçu (avec le design original), le monitoring, les jeux de données produits/partagés, et les améliorations potentielles.
Pipeline original
Le projet original a été développé en 2017 ; j’ai découvert le plan AWS free tier et l’API de Twitter (avec Tweepy).
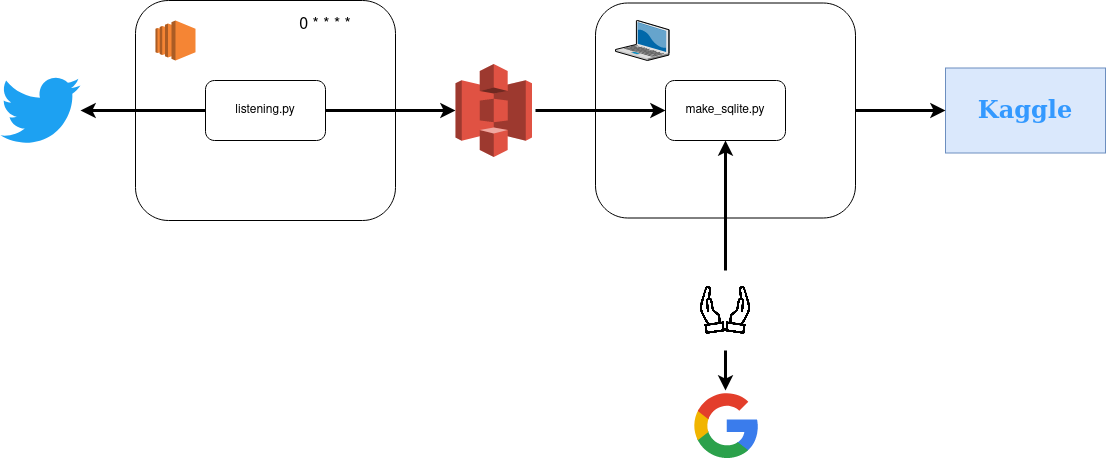
Tout le code mentionné dans ce flux est ici, mais voici les étapes principales :
- Une première étape (listening.py) collecte pendant 10 minutes toutes les heures les tweets liés aux candidats à l’élection présidentielle en 2017 (le filtre était sur leur nom et leurs comptes Twitter affiliés sans filtrer sur la langue)
- Les tweets collectés de ce pipeline dans un fichier JSON et poussés vers S3 avec la ligne de commande AWS
- J’utilisais ma machine locale un script (make_sqlite.py) pour agréger les fichiers qui étaient sur S3 dans une base de données SQLite
- Aussi, je faisais manuellement depuis le site web Google trends un extrait des données liées aux candidats
- Enfin, j’ai compilé toutes ces données et les ai rendues disponibles sur Kaggle ici
Donc c’était le pipeline original, pas parfait, mais il faisait un excellent travail et m’a permis de répondre à une interview pour Kaggle pour ça #brag.
Pipeline actuel
Donc maintenant, l’élection arrive bientôt (le premier tour en avril 2022) ; je voulais relancer le projet mais le rendre meilleur. Tout commence avec une instance EC2 pour le calcul (notre focus pour cette partie) ; voici le flux global.
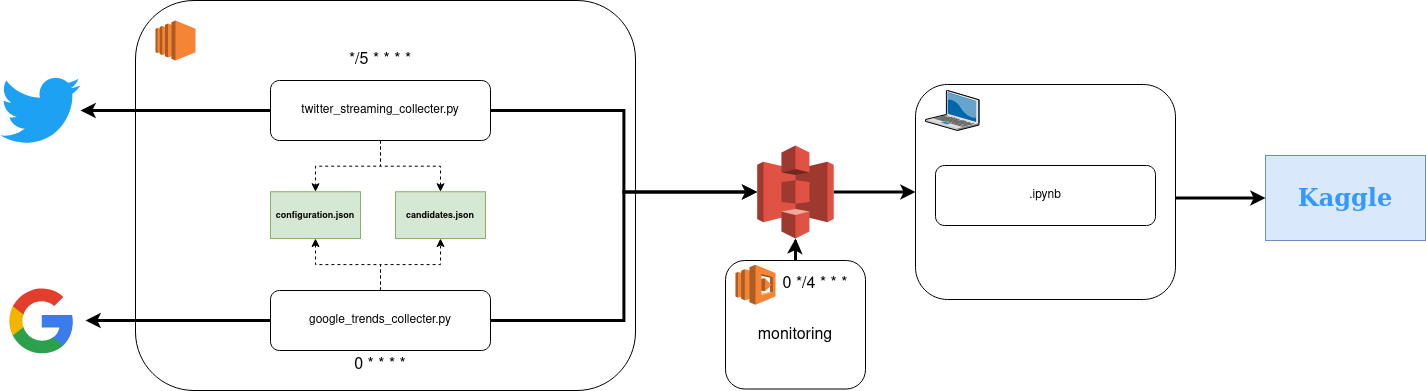
L’environnement pour exécuter le code est en python, et les détails sont dans ce fichier YAML, notez que la version Tweepy pour exécuter est 3.x où la plus récente est 4.x.
Plusieurs parties sont en jeu pour le calcul, mais le cœur (si nous mettons les scripts de côté) est composé de :
- Configuration.json, un fichier avec des informations liées à AWS ; voici le design global du fichier
{
"aws" : {
"key" : "",
"secret" : "",
"bucket" : ""
},
"twitter" : {
"consumer_key" : "",
"consumer_secret" : "",
"access_token" : "",
"access_token_secret" : ""
}
}Sur ce fichier, il y a un champ lié à AWS avec la clé/secret qui est un rôle IAM avec seulement des droits d’écriture sur le bucket s3 mentionné aussi. La deuxième section est pour twitter avec le secret et le token liés à une application que j’ai construite sur le portail développeur Twitter pour accéder à l’API streaming.
- Candidates.json un fichier avec des informations liées aux candidats potentiels pour l’élection présidentielle française. Toutes ces informations sont une compilation des données du Monde de cet article avec un point d’entrée par candidat potentiel.
{
"emacron" : {
"name" : "Emmanuel Macron",
"group" : "Centre",
"party" : "La République en marche (LRM)",
"status" : 0,
"twitter_account" : ["@EmmanuelMacron", "@enmarchefr"],
"image" : "https://assets-decodeurs.lemonde.fr/decodeurs/assets/candidats_presidentielle_2022/macron@1x.png"
}
}Comme vous pouvez le voir, pour chaque entrée, il y a différentes informations :
- Nom/groupe/parti : informations très génériques qui offrent des détails généraux sur la personne
- Statut avec trois valeurs possibles, -1 plus candidat, 0 candidat potentiel, 1 candidat déclaré (mais peut toujours devenir -1)
- Comptes Twitter : les principaux comptes Twitter (personne + parti)
- Image : Url vers une image sur le site web du Monde pour le candidat
Les deux scripts consomment ces ressources pour collecter les données en ligne, et c’est plus flexible si je dois faire des ajustements sur le pipeline comme l’emplacement pour écrire sur AWS ou la portée des candidats.
Regardons maintenant les pipelines directement.
Streaming Twitter
Ce code est très proche de l’original. Les informations liées aux candidats sont maintenant dans un fichier de configuration, et j’utilise pandas pour agréger tous les tweets avant de les envoyer vers S3 avec boto3.
Le principal point de changement est la fréquence de collecte ; maintenant, ce script collecte pendant 5 minutes toutes les 5 minutes les tweets liés aux candidats sorte de pipeline de données en temps quasi réel avec un délai de 5 minutes.
Google trends
Pour celui-ci, c’est une nouvelle chose pour remplacer mon processus manuel, et j’exploite le package pytrends pour lier ma machine et Google trends.
L’idée de ce flux, si vous regardez le code ici, est de donner :
- La fenêtre de temps que vous voulez collecter les données liées à un candidat, par défaut ce sera la dernière heure (horaire) à partir de maintenant, mais il est possible de collecter le dernier jour (quotidien) ou la dernière semaine (hebdomadaire)
- La zone aussi il y a deux zones possibles, fr (avec la France comme zone et le français comme langue) et monde (avec le monde comme zone et l’anglais comme langue)
L’idée est de collecter pour tous les candidats (basé sur leurs noms) des informations stockées sur Google trends à leur sujet autour de :
- Intérêt au fil du temps : Proportion de recherches pour le nom du candidat sur la zone et la fenêtre de temps par rapport à la zone avec l’utilisation la plus élevée de ce mot-clé (valeur de 100). Par exemple, une valeur de 50 signifie que le nom a été utilisé moitié moins souvent dans cette région, et une valeur de 0 signifie données insuffisantes pour ce mot-clé.
- Intérêt par région : Métrique pour trouver où le nom du candidat a été le plus populaire dans la sous-région de la zone (100 est la sous-région avec le pourcentage le plus élevé d’utilisation de ce mot-clé sur le nombre total de recherches locales, 50 le nom du candidat a été utilisé moitié moins souvent dans cette région et 0 la sous-région n’a pas enregistré assez de données pour le candidat.
- Sujets liés : Les utilisateurs qui ont recherché le nom du candidat ont également recherché ces sujets ; il y a deux niveaux avec le hot one et le plus fréquent
- Requêtes liées : Les utilisateurs qui ont recherché le nom du candidat ont également effectué les requêtes suivantes, il y a deux niveaux avec le hot one et le plus fréquent
Maintenant toutes les sources sont connectées à mon bucket S3 dédié à ce projet ; quelque chose à considérer est comment les données sont structurées sur S3 pour chacune de ces sources. J’ai décidé de stocker les données dans des “sous-dossiers” pour le niveau du jour de chaque source (très standard). Je voulais aussi avoir plus de visibilité sur la vie de mon pipeline, donc j’ai commencé à construire une application rapide pour surveiller les données envoyées à AWS.
Monitoring
Pour surveiller mon pipeline, j’ai décidé d’exploiter un package amazon que j’ai utilisé il y a un an dans mon expérience sagemaker appelé chalice. D’abord, voici la description Github : Chalice est un framework pour écrire des applications serverless en python. Il vous permet de créer et déployer des applications qui utilisent AWS Lambda rapidement. Il fournit :
- Un outil en ligne de commande pour créer, déployer et gérer votre application
- Une API basée sur les décorateurs pour s’intégrer avec Amazon API Gateway, Amazon S3, Amazon SNS, Amazon SQS, et d’autres services AWS.
- Génération automatique de politique IAM
Dans mon cas, je voulais avoir quelque chose d’utile pour moi pour surveiller les données entrant dans mes autres buckets s3 pour d’autres projets, le code est ici, et voici le flux global.
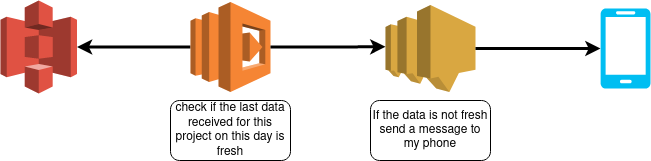
Le cœur de cet outil est un fichier de configuration qui donnera à la Lambda différentes informations sur le projet
configuration = {
"alerts" : {
"frenchpresidential2022_twitter" : {
"bucket" : "",
"prefix" : "data/raw/twitter/",
"time_threshold" : 600
},
"frenchpresidential2022_google" : {
"bucket" : "",
"prefix" : "data/raw/google_trends/fr/interest_by_region/",
"time_threshold" : 7200
}
},
"phone_number" : "",
"aws_key" : {
"aws_access_key_id" : "",
"aws_secret_access_key" : ""
}
}Il y a :
- Informations générales pour accéder aux ressources AWS (secret/token)
- Informations pour l’alerte sur chaque projet à surveiller
- Le bucket s3 à surveiller
- L’emplacement sur la hiérarchie S3, où trouver le sous-dossier du jour
- Le seuil de temps
L’idée est de vérifier toutes les 4 heures si, pour tous les projets, les données reçues pour un projet spécifique à la date actuelle sont plus fraîches que le seuil de temps, et sinon, j’envoie un message sur mon téléphone par le service SNS.
Le processus est simple, généralisé à travers tous mes projets utilisant la même façon de partitionner les données (au niveau du jour). Il m’aide à déboguer et ne me force pas à regarder mon pipeline tous les jours pour vérifier que tout va bien car la règle est simple (#alertingisthebestmonitoring).
Avec ce pipeline, je voulais aussi rendre ces données disponibles pour tout le monde, et j’ai encore décidé d’exploiter Kaggle.
Partager c’est prendre soin #Kaggle.
Le jeu de données est ici, et voici la structure du jeu de données.
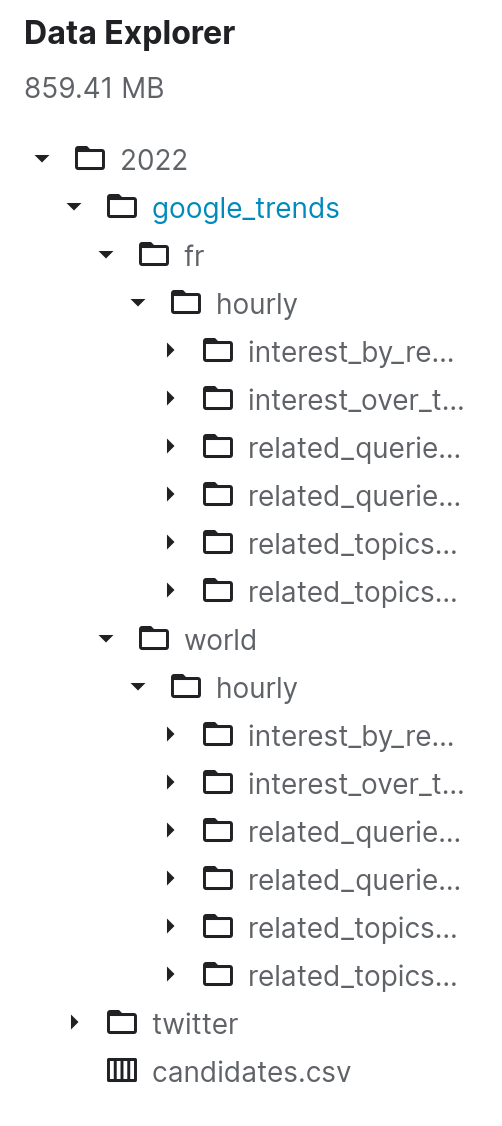
L’objectif est d’avoir :
- Un dossier par élection (prévoyant de déplacer les données originales ici)
- Un sous-dossier par source
- Dans chaque sous-dossier, il y aura un fichier par semaine de l’année nommé avec year_week.csv.gz
Je prévois d’ajouter de nouvelles données dans Kaggle jusqu’à l’inauguration du nouveau président en mai 2021. Pour le rafraîchissement. Je commencerai avec des mises à jour mensuelles, mais la fenêtre de temps peut changer en fonction du statut de l’élection.
En termes d’analyse, je ferai une analyse élémentaire pour promouvoir les nouvelles données, mais mon analyse se produira après l’inauguration pour comprendre la connexion entre les utilisateurs et les tweets.
Les données liées à Google trends sont encore en cours, j’avais besoin de faire quelques ajustements pour gérer différents niveaux d’agrégation sur les tendances et garder un script similaire (devrait être terminé pour décembre 2021)
Avec plus de temps, de motivation et de plaisir
Ce projet fonctionne depuis mi-novembre, et j’ai eu quelques réflexions sur les améliorations possibles (qui arriveront peut-être) :
- Gérer l’environnement de développement avec des conteneurs et un service comme ECR ; je pense que ce pourrait être plus facile si je rencontre des problèmes avec ma machine EC2 pour relancer la pile de zéro
- Exploiter AWS Lambda comme collecteur de données pourrait être génial pour les données Google trends, mais je ne suis pas sûr que cela conviendra aux données de streaming Twitter.
- Déployer de nouvelles versions du jeu de données vers Kaggle par ligne de commande et non avec le drag and drop. Je fais actuellement un dump manuel, et je pense que le package est assez attractif pour aider à ajouter une couche d’automatisation au processus.
- Optimiser la façon de stocker les données ; actuellement, c’est un fichier CSV hebdomadaire pour chaque source ; peut-être cela fonctionnera ou peut-être pas, donc une exploration devra être faite à un moment donné.
Enfin, la question du streaming, je vois des gens dire, “Jean-Michel, vous devriez construire un pipeline de streaming avec Kafka…” et je dis NON. Ma pile est adaptée pour cette application et offre un ratio raisonnable courbe d’apprentissage/coût pour fonctionner. Avoir un pipeline de streaming pourrait être excitant, mais pour des moments particuliers comme pendant un débat mais pas dans mon cas donc je vais peut-être explorer quelque chose dans le futur (comme kafka) mais rien à court terme.
Conclusion
Globalement il y a quelques points clés de cette initiative :
- Le code d’il y a cinq ans pour Twitter a redémarré rapidement
- Pytrends est un package puissant mais faites attention au taux API
- Construire du monitoring avec AWS chalice est super facile et exploiter SNS pour obtenir des notifications sur son téléphone est facile
Je suis aussi vraiment curieux de voir comment les gens vont interagir avec le jeu de données et je ferai quelques mises à jour pour le rendre plus facile à utiliser (ajout de plus de données et d’informations).
Ce projet était vraiment amusant à redémarrer et j’ai de grands espoirs qu’il va être la fondation pour un futur projet autour de ma veille technique personnelle sur les sujets tech donc restez à l’écoute 📻
Références
- Tweepy — tweepy.org
- French presidential election Twitter POV — GitHub — GitHub
- listening.py — GitHub
- make_sqlite.py — GitHub
- Ligne de commande AWS — AWS
- Site web Google Trends — trends.google.com
- Kaggle — Jeu de données élection présidentielle française — Kaggle
- French presidential election 2022 data collector — GitHub — GitHub
- Fichier YAML d’environnement — GitHub
- Portail développeur Twitter — developer.twitter.com
- API streaming Twitter — developer.twitter.com
- Le Monde — Article sur les candidats — lemonde.fr
- Candidates.json — GitHub
- pandas — pandas.pydata.org
- boto3 — AWS
- pytrends — pypi.org
- Code du collecteur Google trends — GitHub
- Chalice — Framework serverless AWS — GitHub
- AWS Lambda — AWS
- Chalice S3 watcher — GitHub — GitHub
- AWS SNS — AWS
- Kaggle — Jeu de données French presidential online listener — Kaggle
- API Kaggle en ligne de commande — GitHub
- pytrends — GitHub GeneralMills — GitHub