
Retour de Recsys 2023
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Cette année, je suis un peu en retard dans la rédaction du récapitulatif de la conférence RecSys 2023, qui a eu lieu à Singapour fin septembre (j’y ai assisté en ligne, merci Ubisoft pour le billet). Dans cet article, je partage une sélection de bonnes lectures (pour moi) que j’ai catégorisées comme suit :
- De l’industrie
- La reproductibilité est une mine d’or
- De nouveaux ensembles de données arrivent
- Transformers et modèles de langage
- Les inadaptés
De l’industrie
RecSys est toujours un bon moment pour les entreprises de partager leurs pratiques et défis, et cette année, je voulais mettre en évidence ces articles.
Recommandations personnalisées pour BBC iPlayer : approche initiale et défis actuels
Auteurs : Benjamin R Clark, Kristine Grivcova, Polina Proutskova, Duncan M Walker
Liens : ACM Digital library
La publication offre principalement des insights de l’équipe responsable du système de recommandation de BBC iPlayer.
Voici les points clés à retenir :
- Le lecteur s’adresse à un vaste public (des millions d’utilisateurs) mais dispose d’un catalogue de contenu relativement petit par rapport aux autres services VOD.
- Leur modèle de sortie de contenu, aligné sur le calendrier télévisé et une disponibilité de 30 jours après la diffusion, permet des prédictions de trafic plus précises sur la plateforme.
- Il est intéressant de noter la variation de la consommation de contenu selon les différents genres (regardez cette figure de la présentation).
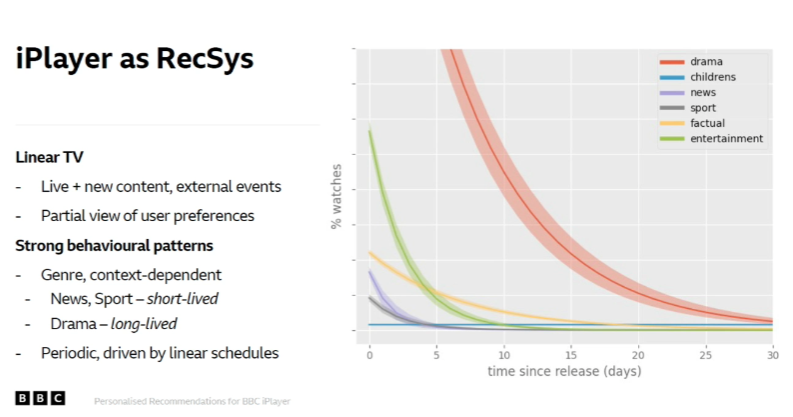
- Les stratégies de système de recommandation de l’équipe sont principalement basées sur des heuristiques, KNN, RP3Beta, et EASE.
- Des modèles plus complexes comme Mult-VAE et NCF ont montré une amélioration marginale à nulle pour un coût accru.
- Ils utilisent un mélange de tests hors ligne et d’expériences de recherche utilisateur pour déployer les modèles les plus efficaces.
- Une équipe éditoriale fournit des commentaires sur les recommandations, mais leurs décisions sont également influencées par la sortie du système de recommandation, ce qui pourrait introduire des biais implicites.
Naviguer dans la boucle de feedback des systèmes de recommandation : insights et stratégies de la pratique industrielle
Auteurs : Ding Tong, Qifeng Qiao, Ting-Po Lee, James McInerney, Justin Basilico
Liens : ACM Digital Library
Cet article se concentre sur la définition des défis inhérents à l’exploitation de systèmes de recommandation et l’interférence potentielle lors de l’exécution de plusieurs modèles simultanément. Les systèmes de recommandation de Netflix sont construits comme des agents d’apprentissage par renforcement (RL). Ces agents ML font des recommandations (actions) basées sur l’historique de l’utilisateur (environnement et observations) et reçoivent des récompenses basées sur les actions des utilisateurs telles que le streaming, le clic et l’achat. Dans ce contexte, l’entraînement des modèles implique une boucle de feedback pour le système de recommandation, qui peut être catégorisée comme fermée (si l’agent est entraîné sur sa propre boucle d’observations) ou ouverte (l’agent est entraîné sur toutes les observations possibles).
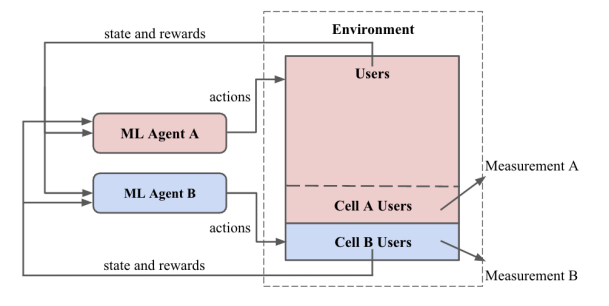
Chaque type de boucle a ses avantages et inconvénients. Pour Netflix, maintenir un modèle uniquement dans une boucle fermée présente un défi, car il nécessite du temps pour atteindre un niveau de précision justifiant l’évaluation. Bien que cet article ne soit pas très détaillé, il fournit un ensemble solide de références pour une exploration future dans le domaine des systèmes de recommandation basés sur RL.
Optimiser la découverte de podcasts : dévoiler le framework de récupération et de classement d'Amazon Music
Auteurs : Geetha S Aluri, Paul Greyson, Joaquin Delgado
Liens : ACM Digital Library
Cet article donne un aperçu du processus du moteur de recherche pour le service de podcasts d’Amazon Music. Dans le but d’améliorer la découverte de contenu, Amazon a développé un framework nommé Unified Learning-to-Rank-and-Retrieve (LTR&R).
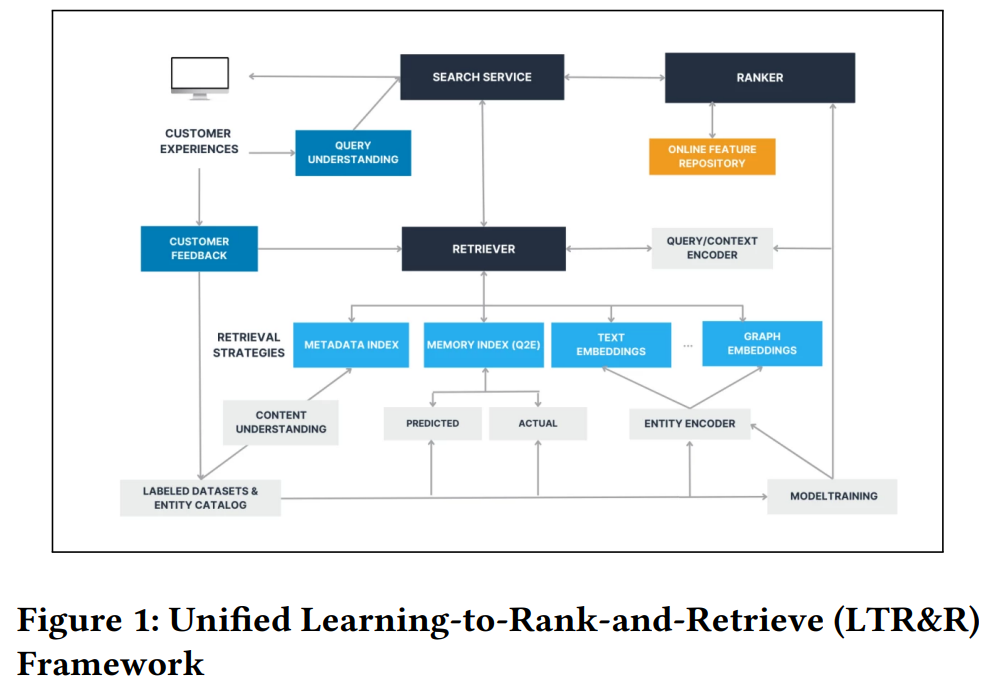
Le concept central du système implique la connexion de plusieurs systèmes avec diverses stratégies à l’étape de récupération, telles que :
- Index de métadonnées : Lier les requêtes de recherche aux métadonnées des podcasts.
- Index de mémoire : Faire correspondre les requêtes avec les clics des utilisateurs dans l’interface de l’application.
- Embedding de texte : Convertir les transcriptions de podcasts en embeddings et les faire correspondre avec des requêtes incorporées.
- D’autres stratégies brièvement discutées incluent l’embedding de graphe.
Le processus est ensuite suivi d’un reclasseur, utilisant un bandit multi-bras contextuel pour explorer les éléments récupérés en fonction du contexte (heure de la journée, emplacement, actions passées).
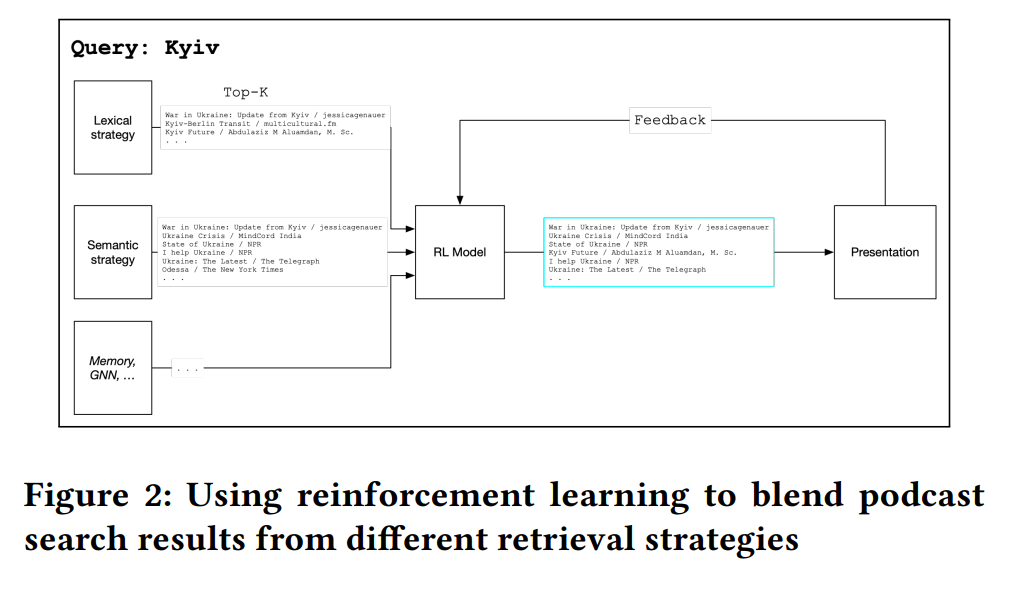
Bien que de haut niveau, cet article se distingue comme particulièrement inspirant. Il laisse place à l’imagination en se concentrant davantage sur les concepts et moins sur les benchmarks, le code ou le pseudocode.
Bandit multi-bras contextuel pour la recommandation de mise en page d'email
Auteurs : Yan Chen, Emilian Vankov, Linas Baltrunas, Preston Donovan, Akash Mehta, Benjamin Schroeder, Matthew Herman
Liens : ACM Digital Library
Cet article de Wayfair présente leurs expériences avec des bandits multi-bras pour améliorer l’interaction avec leurs emails, un élément stratégique clé de leur marketing. Pour entraîner leur système, ils utilisent des données de suivi liées à l’engagement des emails (vues et clics), construisant un classificateur binaire pour prédire la probabilité de clic pour les utilisateurs individuels. Le classificateur intègre diverses fonctionnalités :
- Caractéristiques du client : Âge, sexe et emplacement.
- Caractéristiques client-article : Jours depuis le dernier clic, dernière transaction.
- Caractéristiques de mise en page d’email : ID de mise en page, titre du sujet.
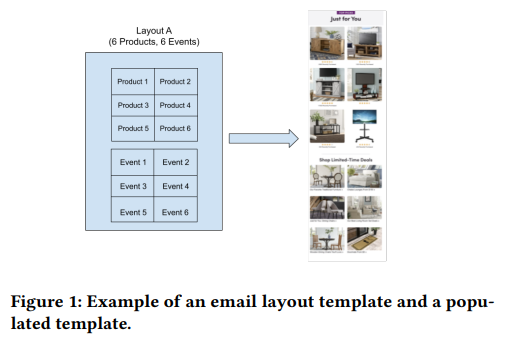
Avec ce modèle, Wayfair fait progresser le développement de leur système de bandit multi-bras, notant qu’occasionnellement (par exemple, 5% du temps) ils optent pour un choix de mise en page aléatoire dans le cadre d’une stratégie Epsilon-greedy.
Ils ont partagé les résultats des tests A/B comparant le nouveau système au système existant. Les résultats indiquent que le nouveau modèle a augmenté la conversion du site suite aux clics sur les emails de 2,39% et réduit les actions de désabonnement des emails de 15%.
Cet article de mon point de vue est l’un des cas d’usage les plus simples autour du bandit multi-bras que j’ai vu dans les conférences recsys et je pense devrait être le point de départ quand les gens veulent explorer ce sujet
La reproductibilité est une mine d’or
La reproductibilité comme d’habitude est un grand sujet à recsys, j’ai sélectionné celui qui a vraiment attiré mon attention pendant la revue.
L'effet des implémentations tierces sur la reproductibilité
Auteurs : Balázs Hidasi, Ádám Tibor Czapp
Liens : ACM Digital Library, Arxiv
Dans cet article, l’auteur travaille sur l’évaluation de la réimplémentation d’un système de recommandation GRU4REC(1,2), que l’auteur a développé il y a quelques années (2015), et l’objectif de l’article est de voir si les réimplémentations sont correctes en termes de code et quelles sont les performances réelles de ces réimplémentations par rapport à l’original.
L’article se concentre sur les réimplémentations suivantes :
Je vais faire un résumé de haut niveau des résultats :
- L’implémentation de Microsoft Recommenders est un algorithme totalement différent (ma référence prend un coup)
- Toutes les réimplémentations ont des problèmes d’évolutivité
- Certaines implémentations obtiennent l’idée générale mais manquent certains éléments
- Torch-GRU4Rec semble être la meilleure implémentation (avec des préoccupations d’évolutivité)
Donc je pense qu’il y a une bonne leçon à tirer de cet article : ne faites pas aveuglément confiance aux réimplémentations.
Remettre en question le mythe du filtrage collaboratif de graphe : une analyse raisonnée et axée sur la reproductibilité
Auteurs : Vito Walter Anelli, Daniele Malitesta, Claudio Pomo, Alejandro Bellogín, Eugenio Di Sciascio, Tommaso Di Noia
Liens : Arxiv, ACM Digital Library
J’ai sélectionné cet article car c’est un excellent aperçu de ce que pourraient être les algorithmes pour commencer à explorer si quelqu’un voulait enquêter sur le domaine des graphes des recsys en sélectionnant les recsys de graphe les plus populaires :
L’article est là pour tester ces implémentations contre certaines lignes de base classiques (plus populaire aléatoire) et le filtrage collaboratif classique (UserKNN, ItemKNN, RP3Beta et EASE) sur différents ensembles de données. Je capture les tableaux de résultats de l’évaluation du modèle
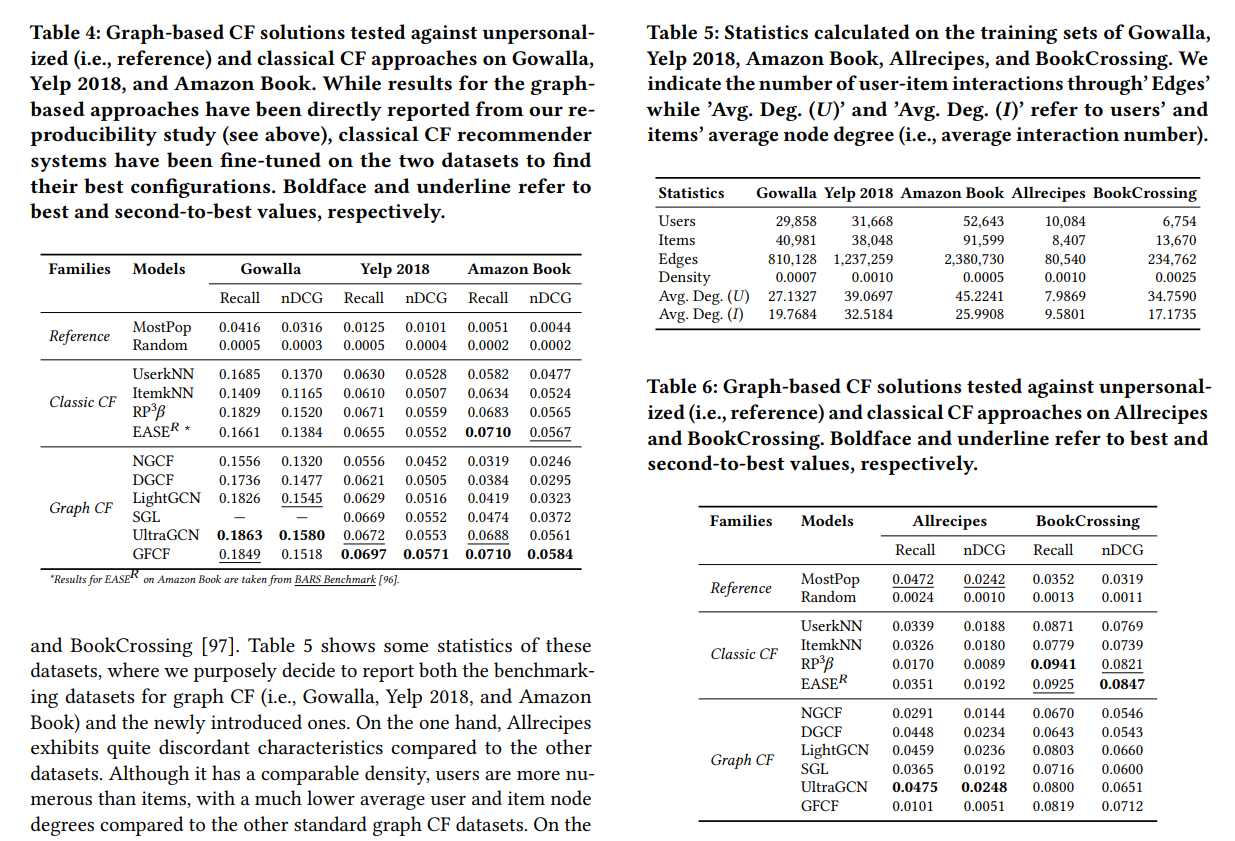
Comme nous pouvons le voir :
- la plupart des modèles avec les meilleures performances ont des modèles basés sur les graphes (sauf sur les ensembles de données de livres)…
- … mais les modèles basés sur le filtrage collaboratif ne sont pas si loin
- les plus populaires ont de bonnes performances dans l’ensemble de données Allrecipes
- NGCF ne semble pas être un bon performeur dans l’ensemble
si vous êtes curieux de voir le code de l’évaluation est sur Github, gardez à l’esprit que leur processus d’évaluation est très dépendant de leur framework d’évaluation Elliot (J’ai écrit un peu sur un précédent récapitulatif de recsys).
De nouveaux ensembles de données arrivent
Recsys est toujours un bon moment pour découvrir de nouveaux ensembles de données et cette année, ils en avaient d’intéressants.
HUMMUS : un ensemble de données de recettes lié, axé sur la santé, centré sur l'utilisateur et permettant l'argumentation pour la recommandation
Auteur : Felix Bölz, Diana Nurbakova, Sylvie Calabretto, Lionel Brunie, Armin Gerl, Harald Kosch
Liens : ACM Digital Library, GitLab
Cet ensemble de données se concentre sur les données de recettes et représente une agrégation complète de diverses sources sous le site web food.com, avec un accent sur la santé des recettes - un facteur souvent négligé dans les ensembles de données existants.
Voici un aperçu des types d’informations disponibles :
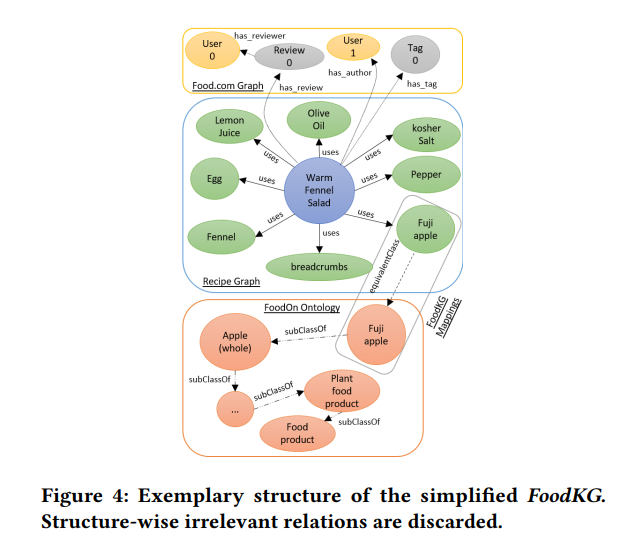
Cet ensemble de données marque une étape importante dans la construction de systèmes de recommandation de recettes. Pour ceux intéressés à explorer davantage, l’ensemble de données est disponible sur GitLab.
Ensemble de données de recommandation Delivery Hero : un nouvel ensemble de données pour évaluer les algorithmes de recommandation
Auteurs : Yernat Assylbekov, Raghav Bali. Luke Bovard, Christian Klaue
Liens : ACM Digital Library, Github
Cet ensemble de données, centré sur la livraison de nourriture, est fourni par Delivery Hero et est accessible sur GitHub, Voici un aperçu de la structure de l’ensemble de données :
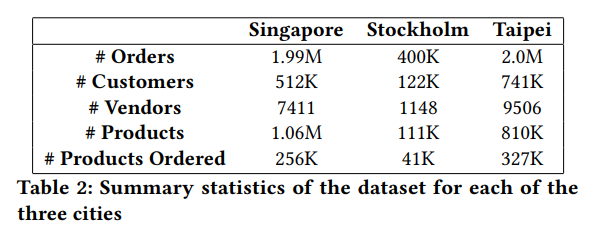
L’ensemble de données comprend diverses commandes avec divers produits, passées par différents clients dans plusieurs emplacements. Avec sa diversité géographique s’étendant de l’Europe à l’Asie, où il est plus prédominant, cet ensemble de données présente des défis intéressants.
Transformers et modèles de langage
L’impact des transformers et des modèles de langage dans le domaine du système de recommandation a été un point fort majeur à RecSys l’année dernière, et la conférence de cette année a des articles intéressants
Génération de mix de pistes sur les services de streaming musical utilisant les Transformers
Auteurs : Walid Bendada, Théo Bontempelli, Mathieu Morlon, Benjamin Chapus, Thibault Cador, Thomas Bouabça, Guillaume Salha-Galvan
Liens : ACM Digital Library, Arxiv
L’article de Deezer discute de leur fonctionnalité ‘track mix’, qui crée une playlist inspirée par une piste spécifique, similaire à la radio de Spotify pour moi.
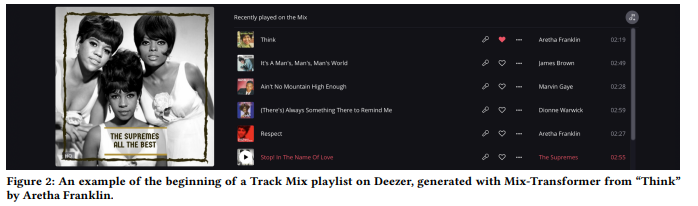
L’article détaille les expériences avec deux modèles pour cette fonctionnalité : mix-SVD comme ligne de base et mix-transformers, évalués par des tests A/B pour déterminer la meilleure approche.
Principaux points à retenir des modèles :
- mix-SVD : Génère des embeddings d’articles à partir des actions des utilisateurs. Les recherches de voisins les plus proches dans cet espace identifient les éléments les plus proches de la piste spécifiée. L’espace est mis à jour hebdomadairement, avec les embeddings hébergés dans un cluster Cassandra.
- mix-transformer : Un Transformer décodeur uniquement entraîné sur une tâche de complétion de playlist, utilisant la piste sélectionnée comme entrée de playlist à 1 piste. Déployé comme un modèle ONNX, il gère tout, du traitement des données au classement des pistes, suivant le framework represent-then-aggregate de Deezer.
Les résultats de leurs tests en ligne offrent des insights significatifs :

Deezer est enclin à explorer davantage le mix-transformer pour intégrer de nouveaux utilisateurs dans leur écosystème, malgré son déploiement plus complexe.
Au-delà des étiquettes : exploiter le deep learning et les LLMs pour les métadonnées de contenu
Auteurs : Saurabh Agrawal, John Trenkle, Jaya Kawale
Liens : Arxiv, Papers with code
Dans cet article de Tubi, une plateforme de streaming TV, l’accent est mis sur le rôle important des métadonnées de contenu dans les systèmes de recommandation. L’article aborde spécifiquement les étiquettes de genre, proposant une nouvelle méthode pour analyser les informations de genre à travers un ‘spectre de genre’.
Pour développer ce spectre de genre, ils ont rassemblé des métadonnées textuelles de 1,1 million de films et entraîné un classificateur multi-étiquettes pour prédire les étiquettes associées. Voici un aperçu de l’architecture du modèle :
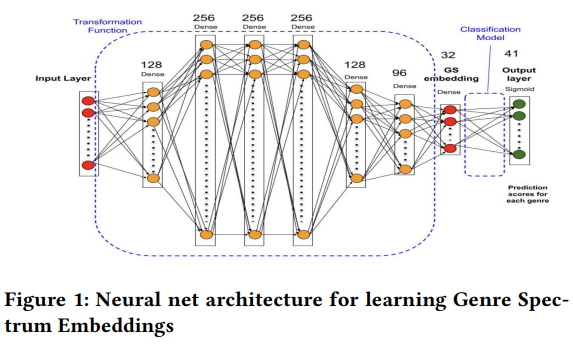
Ce processus génère un nouvel embedding offre une représentation améliorée des films, améliorant les recommandations. Un exemple compare les films les plus proches de ‘Life of Pi’ en utilisant le doc2Vec classique par rapport à l’embedding du spectre de genre :

L’embedding du spectre de genre se traduit par des associations de genre notamment différentes et apparemment plus précises (pour cet exemple). De plus, Tubi a appliqué cette méthode dans la phase de récupération de leur système de recommandation pour un test A/B en ligne, observant un impact relatif de +0,6% sur leur métrique d’engagement (vue totale).
L’article fait également allusion aux possibilités futures d’incorporer des modèles de langage large (LLMs) dans leur processus d’annotation.
Personnalisation de station et d'attribut de piste pour la musique
Auteurs : M. Jeffrey Mei, Oliver Bembom, Andreas Ehmann
Liens : ACM Digital Library
SiriusXM, similaire à Deezer, a développé une fonctionnalité pour générer des recommandations de pistes basées sur un artiste de départ. Leur modèle, nommé STAMPer, est un système basé sur les transformers montrant plus de 10% d’amélioration des performances par rapport à leur modèle de factorisation de matrice de base.
STAMPer est construit sur SASRec et utilise à la fois les commentaires implicites (sauts de chansons) et explicites (pouces levés/baissés) des utilisateurs sur les chansons/stations comme une série d’actions. Plusieurs versions de STAMPer ont été développées.
Cette nouvelle approche semble offrir une plus grande diversité dans les recommandations, comme illustré dans la comparaison suivante de modèles :
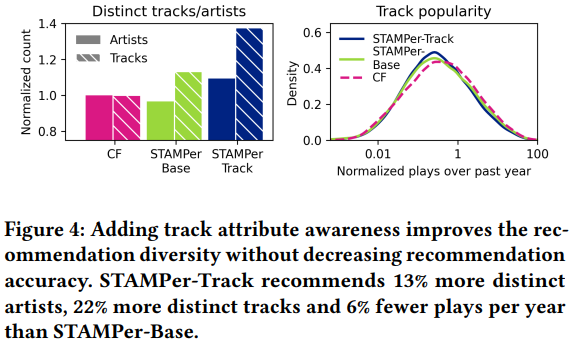
SiriusXM prévoit d’explorer davantage des modèles comme BERT4Rec, continuant leur voyage prometteur avec des approches basées sur les transformers.
Représentation visuelle pour capturer le thème du créateur sur le marché marques-créateurs
Auteurs : Sarel Duanis, Keren Gaiger, Ravid Cohen, Shaked Zychlinski, Asnat Greenstein-Messica Liens : ACM Digital Library, ZipRecruiter
Lightricks, connu pour aider les marques à se connecter avec les bons créateurs pour la promotion de produits, a développé une solution appelée Popular Pays. Cette solution emploie diverses approches pour trouver des créateurs :
- Lookalikes : Identifier des créateurs similaires à un créateur spécifié.
- Outil de recherche : Un mécanisme de recherche basé sur des mots-clés et des filtres.
- Recommandations personnelles : Utilisant le filtrage collaboratif pour évaluer la probabilité qu’un créateur travaille avec une marque.
Ils utilisent des modèles CLIP pour créer deux méthodes :
- SAME (Same Account Media Embedding) : Génère des embeddings d’images basés sur le style de contenu et l’esthétique d’un créateur, utilisant des réseaux siamois et des échantillons positifs/négatifs basés sur la propriété du créateur.
- OAAR (Object-Agnostic Adjective Representation) : Extrait des adjectifs d’images en comparant les embeddings CLIP pour des images étroitement décrites (par exemple, une photo d’un chien vs une photo vivante d’un chien).
L’article présente des méthodes apparemment “simples” avec des exemples convaincants :
Pour SAME, la détection de style et d’esthétique semble efficace :

Pour OAAR, l’association d’adjectifs semble satisfaisante, bien que la précision de certaines sorties comme ‘pleasing’ puisse être discutable. Il démontre une amélioration par rapport à CLIP :

Cette approche rappelle des explorations lors d’un hackathon interne chez Ubisoft (à Yasmine et Cloderic).
Les inadaptés
Parmi les divers articles à RecSys 2023, plusieurs intrigants ne s’intégraient pas facilement dans les catégories spécifiques que j’ai construites mais devaient être mis en évidence
InTune : optimisation de pipeline de données basée sur l'apprentissage par renforcement pour les modèles de recommandation profonds
Auteurs : Kabir Nagrecha, Lingyi Liu, Pablo Delgado, Prasanna Padmanabhan
Liens : Arxiv, ACM Digital Library
Cet article de Netflix plonge dans la gestion des données au sein des systèmes de recommandation basés sur l’apprentissage profond (DLRMs).
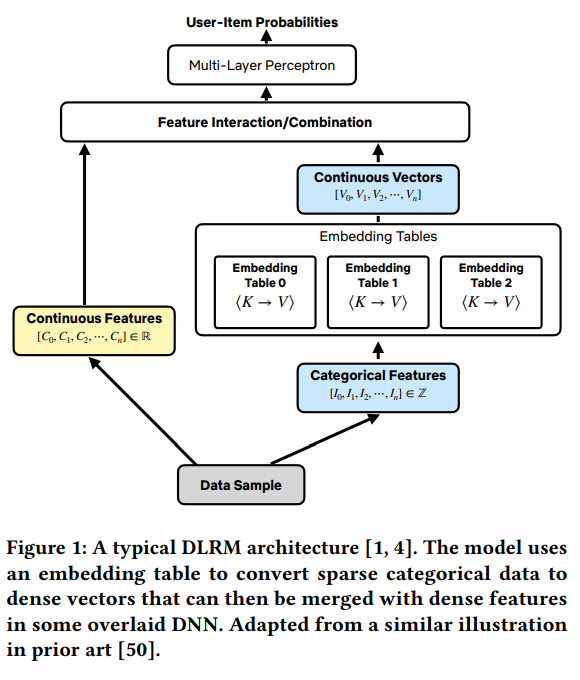
L’accent est mis sur l’analyse des tâches d’entraînement au sein de leur cluster d’entraînement, mettant en évidence l’efficacité du dataloader de TensorFlow et la fonctionnalité AUTOTUNE. Les principales conclusions de l’analyse du cluster incluent :
- Ingestion de données : 60% du temps du cluster est consacré à l’ingestion de données.
- Mise en cache des données : Irréalisable en raison de la grande taille et de la haute dimensionnalité des ensembles de données.
-
Représentation du pipeline de données : Illustre diverses étapes et leurs contributions à la latence.
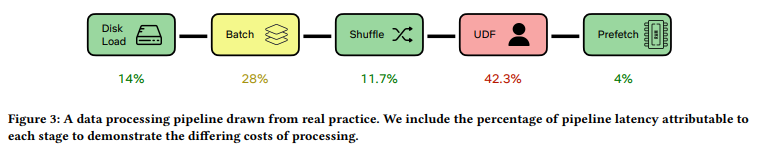
- AUTOTUNE vs paramètres manuels : Les paramètres manuels surpassent souvent AUTOTUNE.
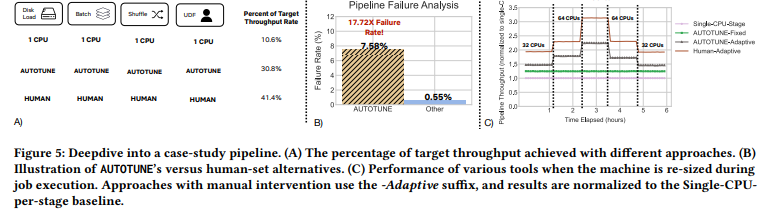
Netflix a développé un système nommé intune, un agent RL conçu pour optimiser les pipelines de données plus efficacement qu’AUTOTUNE. Sa configuration implique :
- Actions : Ajuster les paramètres du travail de données.
- Récompense : Basée sur l’utilisation de la mémoire.
Les tests contre divers cas d’usage et lignes de base comme AUTOTUNE montrent des résultats prometteurs. Bien que l’applicabilité de l’approche à d’autres entreprises soit incertaine, le concept d’utilisation de RL pour optimiser les tâches ML, en particulier dans la gestion des données, est intrigant.
Recommandeurs dans la nature - Méthodes d'évaluation pratiques
Auteurs : Kim Falk, Morten Arngren
Liens : ACM Digital Library, GitHub
Ce tutoriel, ne faisant pas partie des pistes principales ou des posters de la conférence, s’est concentré sur l’évaluation des systèmes de recommandation. Il était divisé en deux parties, dirigées par Kim Falk (auteur de Practical Recommender Systems) et Morten Arngren.
Première section par Kim Falk :
- Se concentre sur l’apprentissage et les processus à garder à l’esprit pendant les opérations et déploiements réels de systèmes de recommandation.
- Les points clés à retenir incluent :
- La règle numéro un de tout projet ML :

- Insights des discussions avec les clients :

- Le flux d’un système de recommandation :
- Directives pour introduire un nouveau modèle :

- La règle numéro un de tout projet ML :
Deuxième section par Morten Arngren :
- Une excellente introduction aux tests A/B, avec des diapositives faciles à comprendre et une collection de notebooks expliquant diverses approches de tests A/B.
- Un aperçu de la présentation :
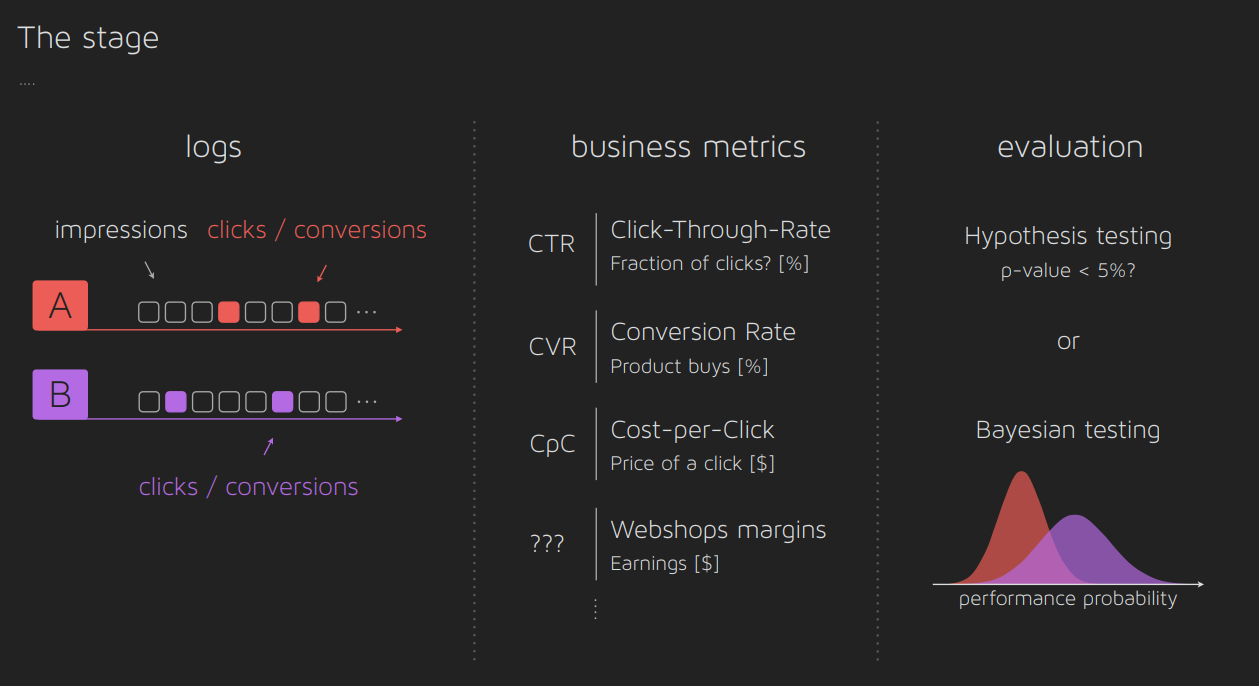
Ce tutoriel a fourni des insights précieux sur le processus d’évaluation des systèmes de recommandation, avec des directives pratiques et des ressources complètes pour comprendre les tests A/B.
Tendances actuelles : modéliser les recommandations de tendances
Auteurs : Hao Ding, Branislav Kveton, Yifei Ma, Youngsuk Park, Venkataramana Kini, Yupeng Gu, Ravi Divvela, Fei Wang, Anoop Deoras, Hao Wang
Liens : Amazon blog, ACM Digital Library
Cette présentation par AWS AI Labs a exploré les recommandations de tendances, un concept crucial pour le fonctionnement d’Amazon Video de leur carrousel supérieur dans l’application.
Les concepts clés dans l’analyse des tendances incluent la popularité, la vélocité et l’accélération :
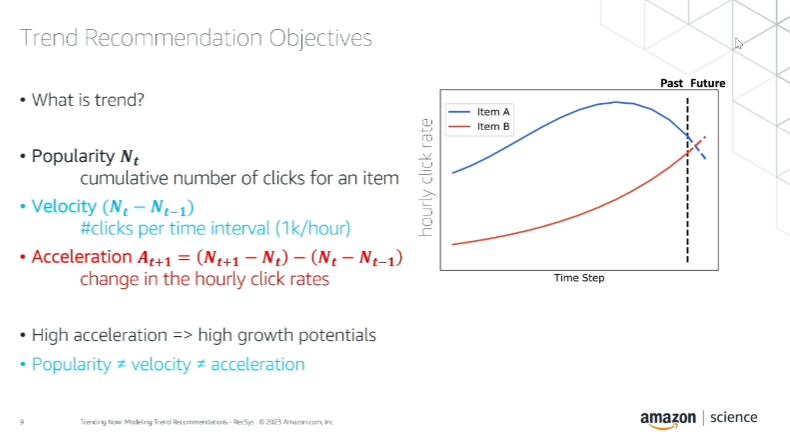
Un point important à retenir est la différenciation de ces concepts : “La popularité concerne le passé, la vélocité concerne le présent et l’accélération concerne l’avenir.”
La présentation a mis l’accent sur le travail avec des plages horaires proches de l’heure, un rythme rapide qui pourrait également être pertinent dans des contextes comme la surveillance du contenu généré par les utilisateurs (UGC). Ces métriques sont utiles pour prévoir la consommation d’articles, et la présentation a mis en évidence leur modèle DeepAR dans ce contexte. La combinaison de la prévision et des embeddings d’articles (dans ce cas, de GRU4REC) forme la base de leur méthode de recommandation ‘trendRec’.
Bien que la méthode semble technique, le concept d’intégration des tendances dans les systèmes de recommandation est intrigant et a du potentiel pour une variété d’applications.
Comment devrions-nous mesurer les bulles de filtres ? Un modèle de régression et des preuves pour les actualités en ligne
Auteurs : Lien Michiels, Jorre # Vannieuwenhuyze, Robin Verachtert, Annelien Smets, Jens Leysen, Bart Goethals
Liens : ACM Digital Library
Cet article, se concentrant sur la recommandation d’actualités, introduit une exploration approfondie du concept de diversité (mais c’est loin d’être le cœur de l’article qui concerne les bulles de filtres). Bien qu’en dehors de mon domaine de travail habituel, j’ai trouvé leur définition de la diversité assez perspicace.
L’article développe trois aspects de la diversité :
- Variété : L’aspect le plus simple, se référant à la gamme d’articles différents.
- Équilibre : Comment les articles sont répartis uniformément à travers différentes catégories.
- Disparité : Le degré de différence entre les articles au sein de la même catégorie.

En appliquant ces concepts plus largement, comme remplacer ‘forme’ par ‘genre’ ou ‘type’, ils deviennent pertinents et potentiellement utiles dans divers contextes de recommandation.
Conclusion
Pour moi, les points forts de cette conférence recsys 2023 sont ces articles :
- Track Mix Generation on Music Streaming Services using Transformers par Deezer : Cet article est excellent pour son approche de l’évaluation des systèmes de recommandation et son utilisation novatrice des transformers, présentée avec clarté et détail.
- Recommenders In the Wild - Practical Evaluation Methods : Une collection complète de meilleures pratiques, particulièrement bénéfique pour ceux qui implémentent des systèmes de recommandation en production, rédigée par des professionnels expérimentés dans le domaine.
- Personalised Recommendations for the BBC iPlayer: Initial Approach and Current Challenges : Offre des insights précieux sur les défis opérationnels et les stratégies des systèmes de recommandation dans l’industrie du streaming.
Mais mes principaux points à retenir sont :
- EASE et RP3Beta semblent être de bonnes techniques de filtrage collaboratif utilisées dans des articles reproductibles et en production
- L’accès aux métadonnées et l’augmentation de la connaissance des articles avec l’embedding est essentiel
- Collecter un niveau décent de données autour des actions des utilisateurs est essentiel si vous voulez évaluer le système de recommandation et opérer de nouvelles techniques (comme les recsys basés sur RL)
- Les transformers qui étaient la grande tendance l’année dernière sont toujours présents (mais ce n’est pas la ligne d’arrivée)
Au-delà de cet article, j’aime discuter de données, d’IA et de conception de systèmes - comment les projets sont construits, où ils réussissent et où ils échouent. Si vous voulez échanger des idées, remettre en question des hypothèses ou parler de vos propres projets, n’hésitez pas à me contacter. Je suis toujours ouvert à une bonne conversation.
Références
- ACM Digital library — dl.acm.org
- RP3Beta — researchgate.net
- EASE — arXiv
- Mult-VAE — arXiv
- NCF — arXiv
- ACM Digital Library — dl.acm.org
- ACM Digital Library — dl.acm.org
- ACM Digital Library — dl.acm.org
- ACM Digital Library — dl.acm.org
- Arxiv — arXiv
- 1 — arXiv
- 2 — arXiv
- GRU4REC-pytorch — GitHub
- Torch-GRU4Rec — GitHub
- GRU4Rec_Tensorflow — GitHub
- KerasGRU4Rec — GitHub
- Microsoft Recommenders — GitHub
- Recpack — recpack.froomle.ai
- Arxiv — arXiv
- ACM Digital Library — dl.acm.org
- NGCF — arXiv
- DGCF — arXiv
- LightGCN — arXiv
- SGL — arXiv
- UltraGCN — arXiv
- GFCF — arXiv
- Github — GitHub
- Elliot — GitHub
- ACM Digital Library — dl.acm.org
- GitLab — gitlab.com
- site web food.com — food.com
- ACM Digital Library — dl.acm.org
- Github — GitHub
- Delivery Hero — deliveryhero.com
- ACM Digital Library — dl.acm.org
- Arxiv — arXiv
- represent-then-aggregate — arXiv
- Arxiv — arXiv
- Papers with code — paperswithcode.com
- Tubi — tubitv.com
- ACM Digital Library — dl.acm.org
- SiriusXM — siriusxm.com
- SASRec — arXiv
- ACM Digital Library — dl.acm.org
- CLIP — openai.com
- Lightricks — lightricks.com
- Arxiv — arXiv
- ACM Digital Library — dl.acm.org
- ACM Digital Library — dl.acm.org
- GitHub — GitHub
- Practical Recommender Systems — manning.com
- diapositives — GitHub
- Amazon blog — amazon.science
- ACM Digital Library — dl.acm.org
- DeepAR — arXiv
- ACM Digital Library — dl.acm.org