
Once again, I attended (virtually) this year with some of my colleagues at RecSys 2021 in Amsterdam. In this article, I will recap exciting papers and initiatives that I saw during this event (conference + workshop).
Conference
The conference days were divided by main tracks sessions, posters, virtual meetups and industrial talks. In this section, I will share the interesting papers that I saw.
Day 1
This day was focus on three topics:
- Echo Chambers and Filter Bubbles
- Theory and Practice
- Metrics and Evaluation
I selected from the first topic a paper presented by Matus Tomlein: An Audit of Misinformation Filter Bubbles on YouTube: Bubble Bursting and Recent Behavior Changes.
paper cover

This paper reiterates an experiment that happened a few years ago to audit recommender systems and evaluate how they work. The idea is to build a bot that will search on a specific topic, stored the content displayed, and after a manual process, audit the results of the recommendation systems. All the code for this process is in this GitHub repository, and there are a few results.
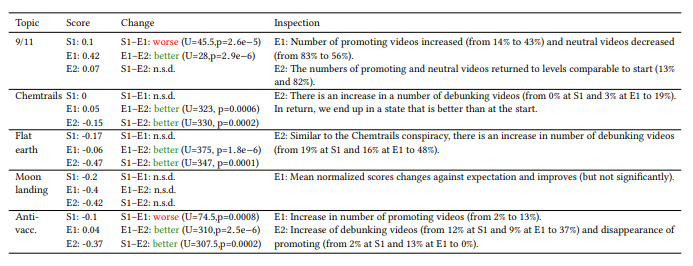
The overall results showed that on some specific topics, the recommender systems seem to be more ponderate than a few years ago by showing more neutral contents that are debunking conspiracy theories (except on subjects like the 9/11 or the anti-vaccination on the specific experiments)
In the second session around Theory and Practice, the paper that I chose is Jointly Optimize Capacity, Latency and Engagement in Large-scale Recommendation Systems presented by Hitesh Khandelwal from Facebook.
paper cover

This paper presents a technique to optimize a recommender system efficiency (for the serving) by caching recommendations to reduce latency. Usually, the caching technic is not efficient; this paper offers another approach to do it. To apply this technique of caching, you need to have a two-step recommender system with retrieval and ranker steps; if you want more details, you can watch this video of the mlops community of Eugene yan on the subject, but there is the overall flow.
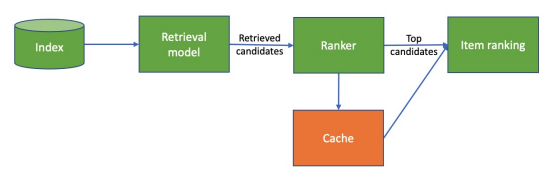
In this paper, the recommender has some new layers on the retrieval and ranking steps.
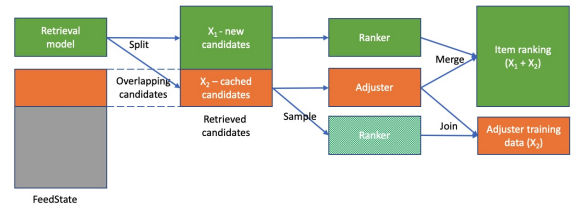
From the authors, this pipeline is relevant to different contexts (he seems to have based his work on Facebook market data), something to try at some point but needs to have the first version of the flow working.
Finally, the last session was on metrics and evaluation; the paper I am highlighting was Reenvisioning the comparison between Neural Collaborative Filtering and Matrix Factorization presented by Vito Walter Anelli from Politecnico di Bari.
paper cover

I selected this paper for two things:
- Talking about this big question that can we approximate matrix factorization with a multi-layer perceptron and if it’s giving good results (a long debate that I see a lot on the past recsys edition)
- Explanation of a pipeline to do recommender’s evaluation
I will not enter too much in the details for the first point (I will let you read the paper) because I don’t like the comparison of algorithms on standard datasets as a benchmark too much. But for the second point, it was more to highlight the work of Politecnico di Bari around the evaluation of recommender systems; they built a framework called Elliot to help evaluate recommender systems from the research perspective.
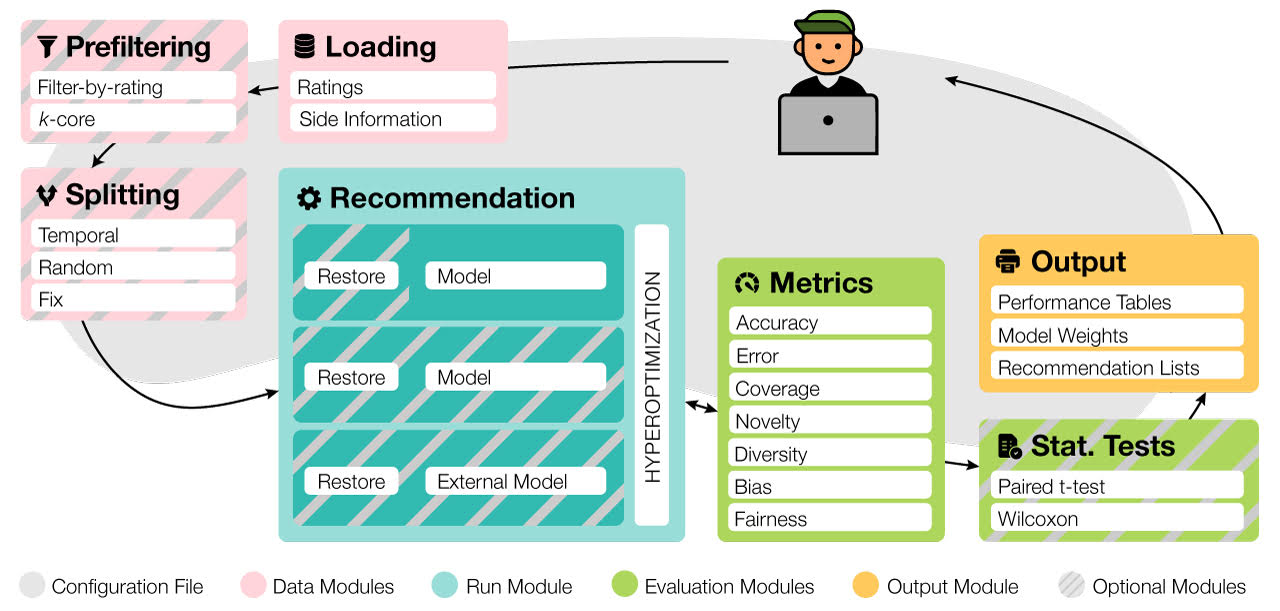
I have something on the test list in the future because sit looks super promising and helpful from an experiment perspective.
Around these sessions, there were meetups animated by people from the industry; I am not going to enter in details on this meetup because they are very informal but here are a few things that I learnt:
- Netflix meetup: talking a lot of reinforcement learning and bandit for recommender system, but didn’t want to share results of their experiments
- Zalando meetup: it’s impressive to see Zalando’s work (they have around 250 applied scientists that seem huge for me). Their workflow seems to work in kanban style, and they organized weekly science reviews on their experiment.
Finally, to conclude the day, there were industry talks organized by Zalando with three actors of the industry (once again, a quick recap on the event):
- Grubhub: the presenter was talking about their way to train models and make online learning; I like their flow around drifting of metrics based on the retraining periods
- Nike: the presenter explaining their way to build the recommender systems on their application from scratch, and they have a pretty decent pipeline (that seems complex), but that looks interesting.
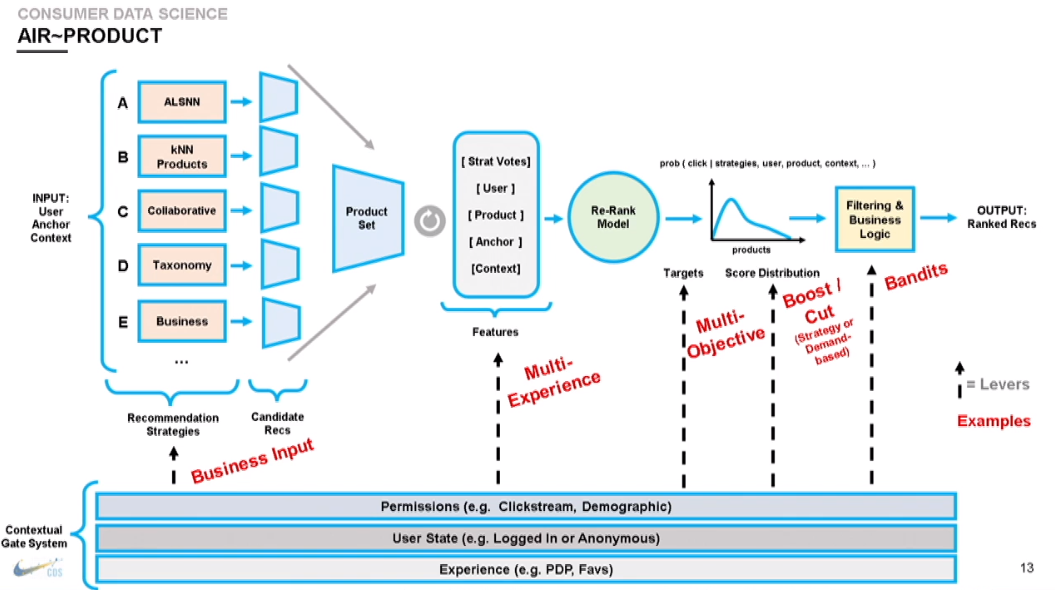
The interesting point on this flow is that their pipeline is deployed (with the same code) in each geographic area to respect privacy rules in place
- Netflix: on this talk/paper, one engineer of the company is bringing the notion of recsysops (specialized mlops for recsys), seems adapt to their need of maintenance of large and complex recommender systems, but I like in the approach is the division between four pillars (detection, prediction, diagnosis and resolution), more precisely I am a fan of :
- The prediction of problems that can occur with new contents released (try to predict one week before if content will bring model degradation and anticipate that)
- The resolution with doing a maximum of actions on a UI without code.
Oh, and I am a fan of the speaker commitment to match the theme used on the slides (it was a money heist theme)

Let’s start on day 2.
Day 2
For this day, the main track was around:
- Users in focus
- Language and knowledge
- Interactive recommendation
For the first section on users on focus, I appreciate the talk of Christina Boididou of the BBC Building public service recommenders: Logbook of a journey.
paper cover

In this talk, the speaker shared the flow of the BBC datalab team to build recommender systems for the content on the platform:
- The first one was to keep the editorial team always involved in the deployment of the new recommender system by getting their feedback on the output produced by recsys
- another aspect mentioned was their machine learning engine principle in general; I. am finding them very transparent in their approach (there is an article with more details on it available for everybody on the BBC website ); this is the overall flow
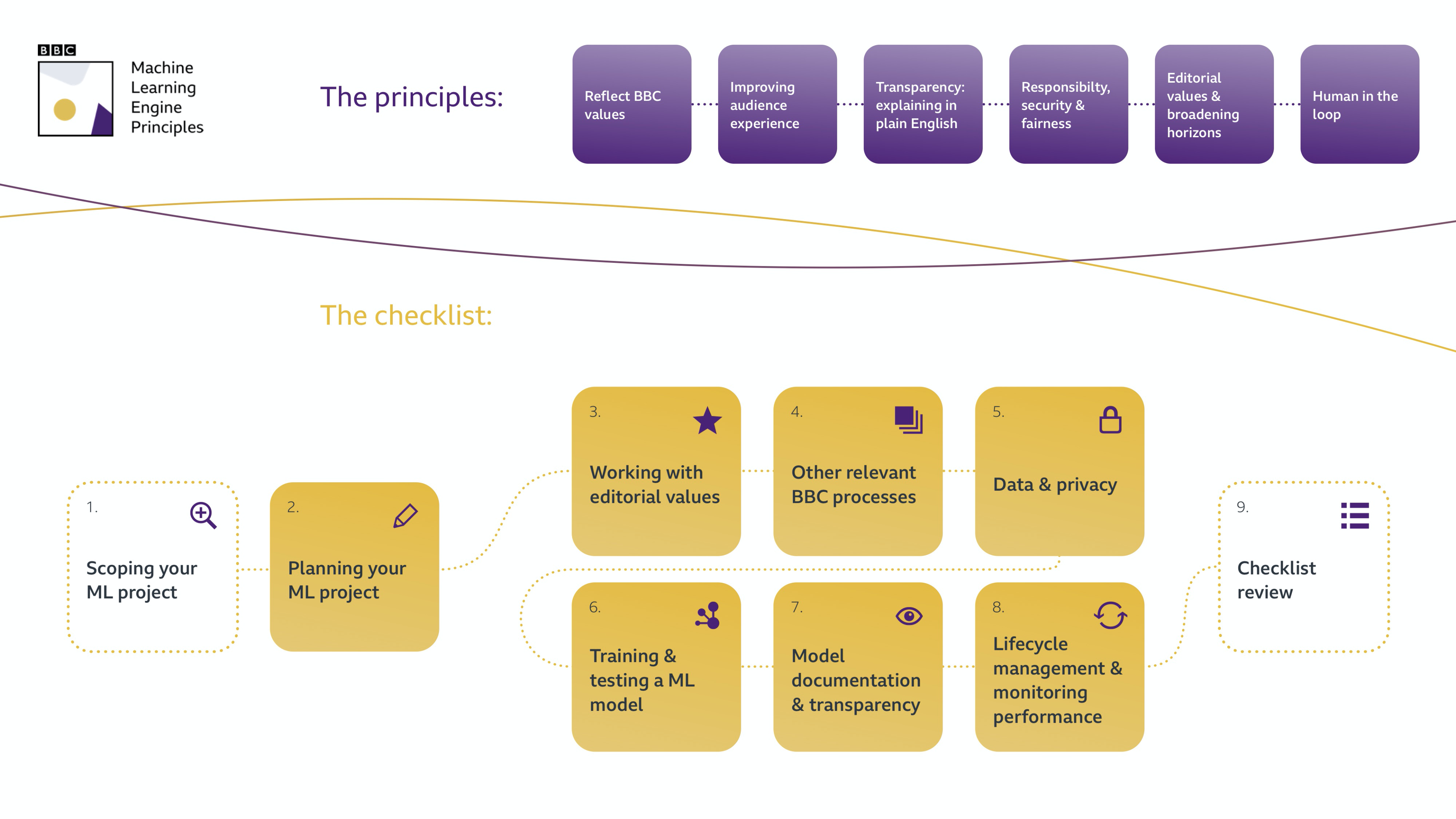
- When you start to develop an ML system, build it fast and straightforward to start.
On the second session about language and knowledge, I am cheating a bit, but I have two papers in mind:
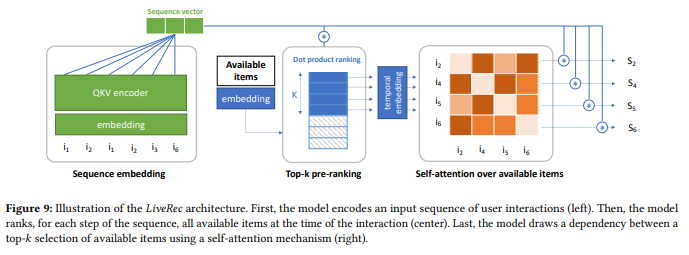
- The first one from NVIDIA presented by Even Oldridge and Gabriel de Souza Pereira Moreira Transformers4Rec: Bridging the Gap between NLP and Sequential / Session-Based Recommendation.
paper cover

This paper presents an approach to leverage transformer (than are usually in the NLP world) but for recommender systems for a session-based system.
![]()
Looks excellent and promising; I am not very knowledgeable of this kind of approach to give a clear opinion on that (except that they have a Merlin team like us, but we were here before #ubi2018)
- The second paper selected, it’s from Aravind Sankar for the University of Illinois and is called ProtoCF: Prototypical Collaborative Filtering for Few-shot Item Recommendation.
paper cover
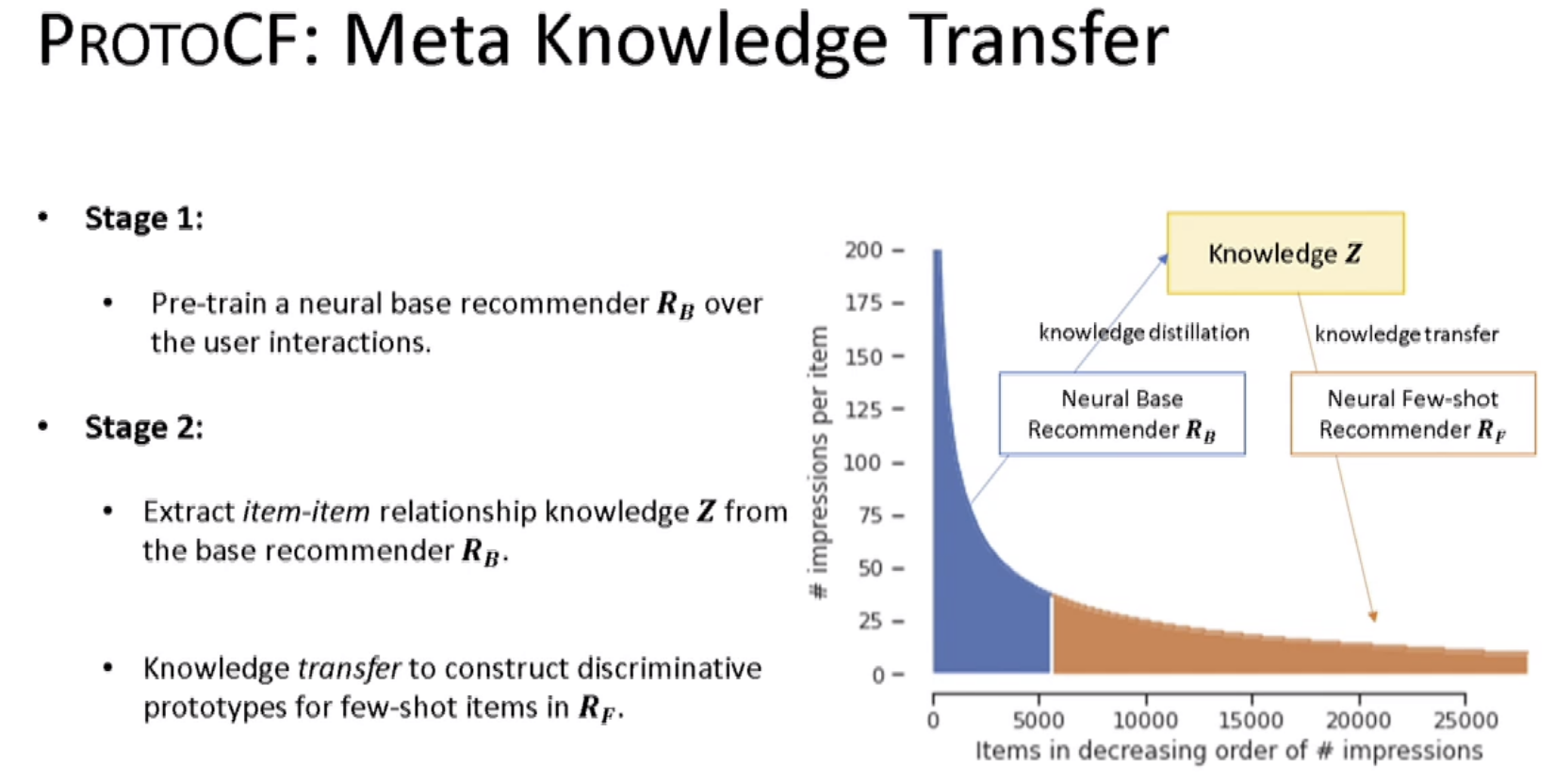
In this approach, the idea is to tackle the head and tail problem of recommender systems by doing a knowledge-based on what is happening in the head (knowledge distillation) and on the tail (knowledge transfer); this knowledge used neural network approaches.
The code is not available yet but soon.
For the last section on interactive recommenders, I selected the talk of Amazon from Francois Mairesse Learning, a voice-based conversational recommender using offline policy optimization.
paper cover

The paper presents the process to improve on the feature of Alexa to recommend songs to listen to users by starting a discussion.

All the training used a reinforcement learning approach to train a model followed by two AB tests has been done and show successful uplift of the new approach (against hardcoded path).
Let’s see the third day of the conference.
Day 3
For this day, the sessions were:
- Scalable performance
- Algorithmic advances
- Privacy fairness
I selected the paper presented by Lonqqi Yang from Microsoft, Local Factor Models for Large-Scale Inductive Recommendation for the scalable performance.
paper cover

Microsoft built a solution that leverages clusters in the user and items to make recommendations.
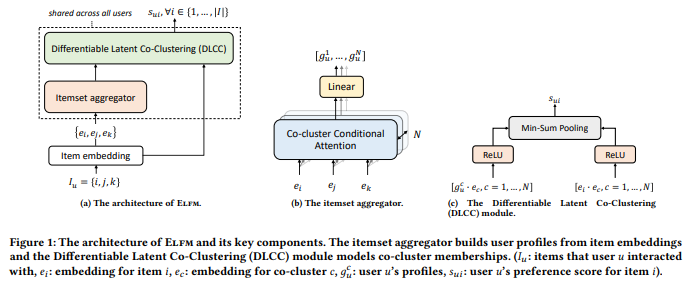
Not an expert with all the elements, but it seems a solution scalable from the presentation, and I am advising you to have a look at the Github of the speaker; there is cool stuff (like this openrec repository)
For the algorithmic advances, I chose the paper presented by Wenzhuo Song of the Jilin University, Next-item Recommendations in Short Sessions.
paper cover

The idea is to build a sequence prediction based on the knowledge extracted from previous sessions, once again not my area of knowledge (I am planning to work on this sequence problem soon, and it’s adapted for my use case at the office)
The code is not yet available, but it should arrive here soon.
Finally, on the privacy, fairness and bias, I will be honest, was not one of the highest-ranked (for me) sessions of the conference, but I found two talks very interesting:
- The first one is from Andreas Grün of ZDF (the equivalent of national TV in Germany, one of the top3), Challenges Experienced in Public Service Media Recommendation Systems.
paper cover

It’s a high-level presentation, not technical, but there are great takeaways from it like:
- Evaluate the niche content and how much these contents are seen per user
- Build a testbed for editorial people to test the various model with their data and see which one fit best (seems that are liking the recommendations from the Rulerec)
- Make the training and serving of the recommender systems greener, so evaluate this environmental impact
The second article is from Daniel James Kershaw, from Elsevier Fairness in Reviewer Recommendations at Elsevier.
paper cover

To be honest, I am not a big fan of all this paid access scientific publication with all the reviews, but I am admitting that they are building a recommender of reviewers that seems to want to fight discrimination for this project (and that’s great). The paper is pretty light, but the talk was fascinating.
Day 4
For this day, the sessions were:
- Applications-driven advances
- Practical issues
- Real-world concerns
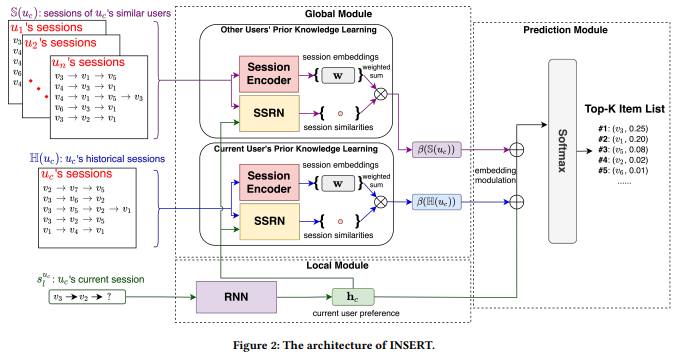
I am going, being honest. It has been a slower day for me. Still, for the first session, on application-driven advances, I selected the talk from Jérémie Rappaz of the EPFL Recommendation on Live-Streaming Platforms: Dynamic Availability and Repeat Consumption.
paper cover

The paper is around designing a recommender system in a streaming platform setup; the streams, by essence, are happening at various times of the day or the week, so this behaviour should be handled during the computation of recommendations. Thus, there is a flow of the system.
The approach looks interesting; as I said before, I need to try many things around sequence prediction before understanding the process (and the added value) clearly.
For the second session, I selected the paper presented by Jacopo Tagliabue from Coveo Labs You Do Not Need a Bigger Boat: Recommendations at Reasonable Scale in a (Mostly) Serverless and Open Stack.
paper cover

In this paper, the speaker presented a stack to make live recommendations with various trendy tools; there is an overview of the flow.
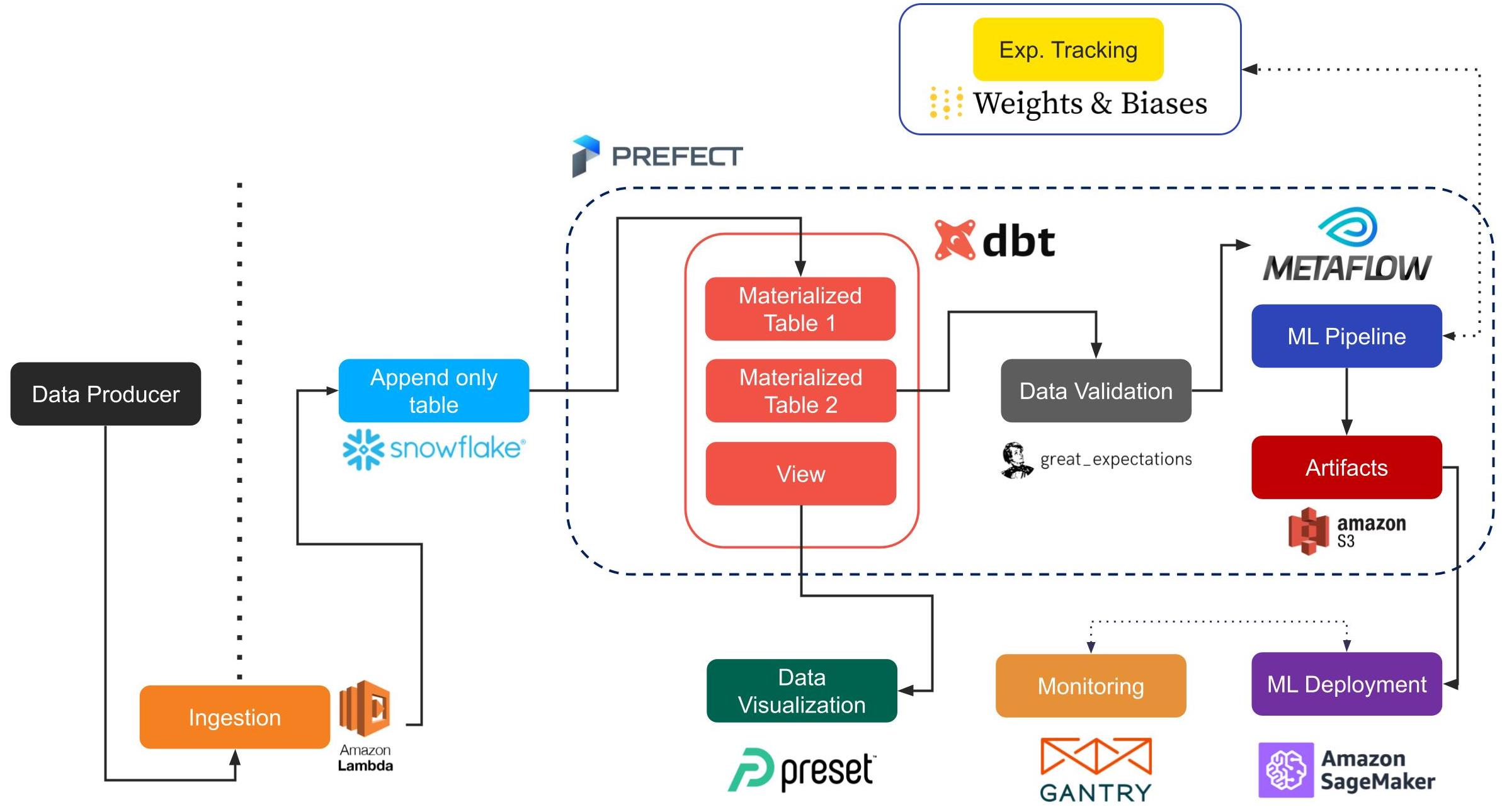
Plenty of tools that I tried on past articles, and I am advising people to look at the associated repository, a great starting point to build a recommender system in a company.
Finally, in the last session, I have selected the paper of Huiyuan Chen from Visa research Tops, Bottoms, and Shoes: Building Capsule Wardrobes via Cross-Attention Tensor Network.
paper cover

This paper is tackling the challenging task to find the right clothes that can complete an outfit by using a neural network (something called tensornet).
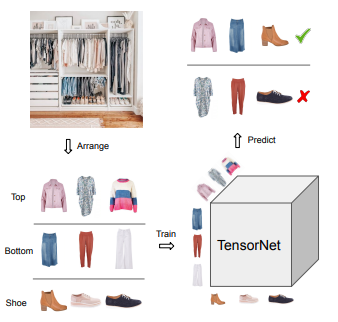
This is all for the main conference
Workshops and tutorials
I virtually attended this year to the following three workshops:
- Evaluation workshop
- Podcast workshop
- Fashion workshop
The workshops were a mix between keynote, discussion and paper presentations or panels.
From the first workshop, there are few things that I learnt from the keynote (organized by Zalando):
- Good evaluation methods diff testing and AB testing (that seems a gold standard, of course)
- The diff testing explanation was fascinating, the notion to evaluate the difference of the new model versus the baseline and analyze it. Find a good way to discuss results with a client that is maybe not too technical.
- During AB testing, To train the models using the data that the other models can have impacted seems a bad idea (because when the test is done, the model are going to lose these positive or negative inputs, so not’s the best setup for evaluation)
- There is also the notion of evaluation per subgroups of users; there is no average user, so focusing on the metric per subpopulation makes more sense.
For the exchange with the other participants, you can look at this google doc where the participants shared a recap of their discussion.
On the second workshop around the podcast, I attended by curiosity, but I collected some interesting Infos:
- There is a significant need to have a standard dataset for evaluation; there is no Movielens or Pinterest like datasets (Spotify seems to work on it)
- The research on it seems driven by a content-based approach and analysis of the audio track (Spotify open-sourced last year a dataset on the subject).
I have no google docs to share on the participant discussion but there are a few subjects that our group discussed:
- Missing datasets (of course), really a need to have more than only listen/not listen/like/not like a podcast. Having more data on the application usage (how the content is consumed) seems a graal to have
- How to handle periods like lockdown or polarised topics that are on the news in the recommendation process
Finally, for the workshop on Fashion, there are a few insights that I learnt:
- An exchange with Bjorn Hertzberg, lead data science at H&M, was giving the experience of the company to build recommendations served per email with collaborative filtering with all the drawbacks that his approach is bringing. However, a remarkable aspect is customers embeddings for the CF to clusters and seeing what is trendy on this group recently to make recommendations, super inspiring.

- A discussion with Sharon Chiarella, Chief Product Officer at stitchfix, a company that is creating a personalized shopping experience (they have a tech blog). They build a style generator tool/game to let people try to build an outfit, and it’s helpful to understand the relationship of the clothes together (kind of gamification that is used to produce training data)
- Interesting papers were presented during this workshop, and I like:
- The paper presented by Shereen Elsayed, End-to-End Image-Based Fashion Recommendation. Fantastic flow to handle images as input with the transactions of the users (code is here).
- A paper from Criteo to generate an image (like red shoes) from a text query, What Users Want? WARHOL: A Generative Model for Recommendation (no code available yet)
The workshop was super interesting, and I think I will follow it in future iterations.
Conclusion
So this is the first version of my recap built during the conference, and I will take more time to analyze the papers and replays in the future. But overall, there are a few key points that I kept:
- Applying NLP technics to make recommendations is super trendy (BERT4REC, Transformers4REC)
- Less RL and bandit projects than last year, but always cool stuff
- Two steps recommender is a thing to do (work well for a case with a vast catalogue, seems a good candidate for a future article on the sens critique data)






{kind=link}