
Fonctionnalités et principes de conception d'un système de recommandation
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
![]()
Au cours des dernières semaines, j’ai été impliqué dans des discussions sur la façon de rendre le processus de déploiement des systèmes de recommandation plus efficace, et j’ai également contribué à la conception d’une partie d’un bootcamp interne pour introduire l’utilisation des systèmes de recommandation et de la personnalisation chez Ubisoft.
Ces discussions m’ont fait réfléchir et rechercher sur la conception d’un système de recommandation et à quoi un tel service pourrait ressembler en 2024. J’ai donc décidé de compiler mon expérience et les résultats de ma recherche dans un article qui pourrait être utile pour quiconque est curieux à ce sujet.
Avertissements :
- Si vous êtes très tôt dans votre parcours de système de recommandation, mon livre de référence est Practical Recommender Systems de Kim Falk
- Il n’y aura pas de discussion sur les algorithmes, les ensembles de données, etc. Cet article se concentre plus sur la vision globale de comment un service de recommandation devrait être, donc c’est assez haut niveau
Fonctionnalités principales d’un système de recommandation
Pour cette section, j’ai décidé de fouiller dans diverses documentations et articles de certaines entreprises pour avoir une idée des tendances actuelles et des spécifications d’un système de recommandation et des attentes de ce type de service.
Avertissements :
- Je donnerai quelques inputs sur les fonctionnalités que je pense être fondamentales pour un système de recommandation, mais gardez à l’esprit que cela ne peut exister que dans une configuration où votre définition de suivi d’utilisateur et d’item est minimale (fondamentalement, vous pouvez savoir avec précision ce qu’un utilisateur fait dans votre application, et ce n’est pas échantillonné).
- Tout ce contenu provient principalement de documentations publiques d’entreprises comme AWS, Spotify, Shopify, Recombee
Exposer les tendances
J’ai toujours remarqué que la popularité est un élément fort dans tout service de recommandation, et ce composant est essentiel dans tout bon service pouvant fournir des recommandations. Par exemple, il existe plusieurs endpoints connectés à la popularité dans la documentation suivante de ces services :
- Obtenir les meilleures pistes d’artiste sur l’API développeurs Spotify.
- Obtenir les items populaires sur AWS personalize Popular Item Recipe.
- Obtenir la logique populaire sur Recombee.
Ce ne sont pas juste des endpoints sans configuration, mais ils offrent une capacité de configuration intéressante. Par exemple, sur Spotify, vous pouvez obtenir la popularité des pistes d’un artiste basée sur le marché.
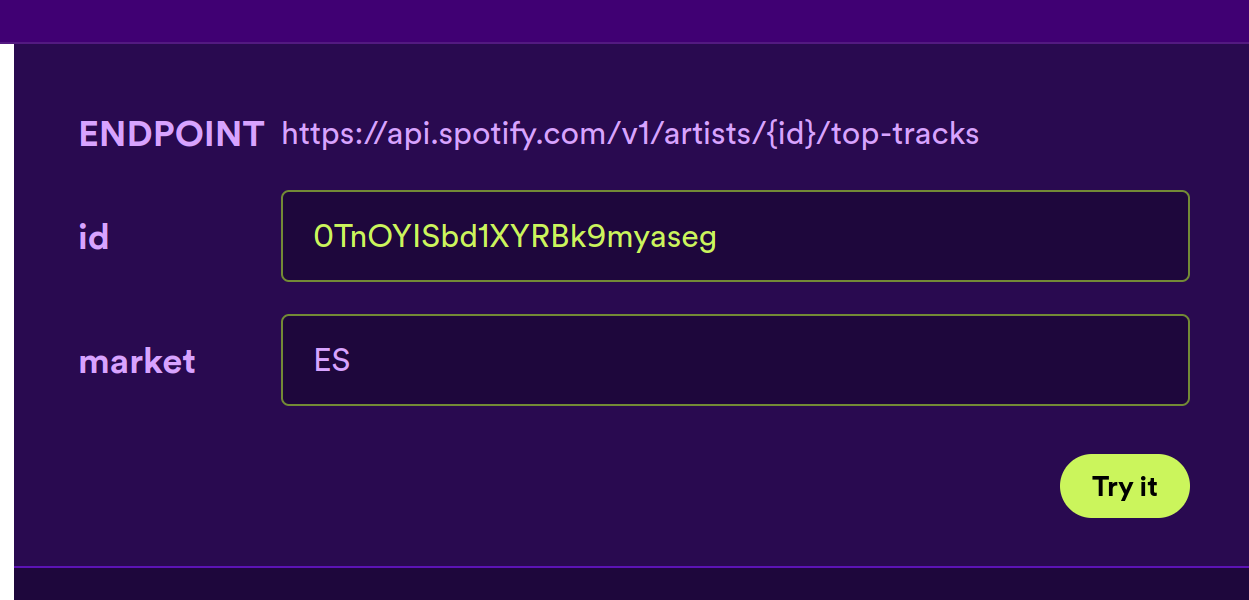
Pour AWS ou Recombee, vous pouvez ajuster la période de temps sur laquelle la popularité devrait être mesurée :
- sur AWS, il semble entre 1 heure et 1 jour
- sur Recombee, cela semble plus flexible de heures à jours, avec la valeur par défaut étant 14 jours
Être capable de collecter des items tendance est essentiel. Dans la section Fallback Strategies: A Pillar of Reliability de cet article, j’ai expérimenté avec différentes stratégies, et les items les plus populaires étaient les plus efficaces. Donc, je pense qu’avoir la capacité de collecter efficacement les items les plus populaires/tendance est un must-have quand vous commencez à concevoir une stratégie de système de recommandation (comme Google le dit, la meilleure première étape d’un projet ML est de ne pas faire de ML).
Améliorer l’expérience utilisateur avec des items liés
Suivant le thème de la fonctionnalité de popularité, un autre aspect crucial d’un service de recommandation est la “fonctionnalité d’entité liée”. Cette fonctionnalité offre des recommandations lorsque vous naviguez sur une page de contenu spécifique. Par exemple, en regardant une série TV sur Netflix, le service peut suggérer des séries similaires ou du contenu connexe que d’autres téléspectateurs ont apprécié.
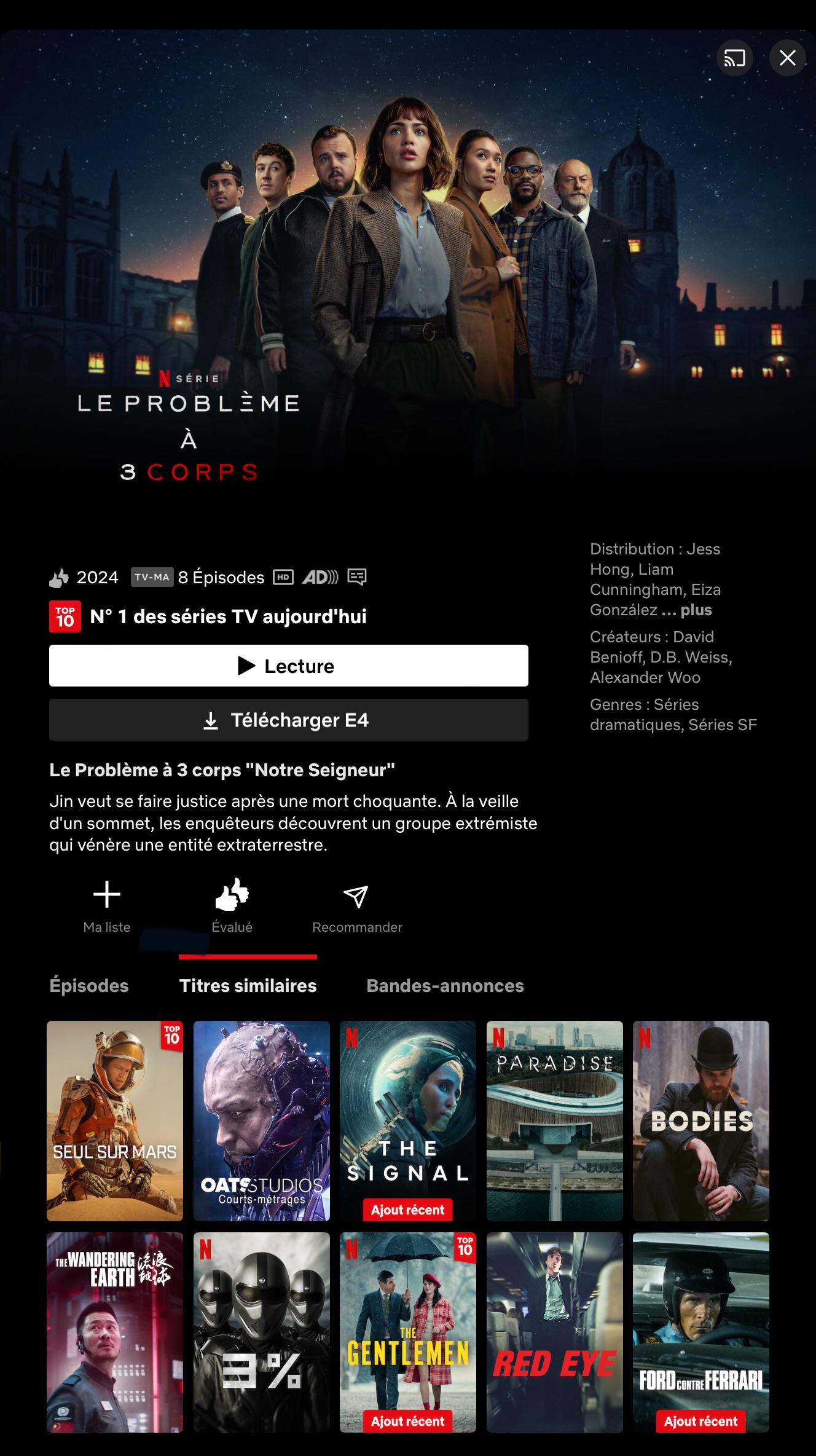
Cette fonctionnalité améliore l’expérience utilisateur en intégrant de manière transparente des recommandations qui sont susceptibles de s’aligner avec les intérêts actuels du spectateur, encourageant un engagement plus profond avec le contenu de la plateforme. Ce type de fonctionnalité semble être vraiment standard dans les endpoints fournis dans les services de système de recommandation, par exemple :
- AWS Personalize offre la Related Items Recipe.
- Recombee avec les recommandations Items to Item ou Users to User.
- Shopify avec ses Related Products ou Complementary Products.
- Spotify et le Get Related Artists.
Pour développer ce type de fonctionnalité, plusieurs stratégies peuvent être mises en place, telles que les matrices de co-association, les recherches de similarité, et bien d’autres options qui peuvent être envisagées.
Ces approches peuvent apporter une grande valeur à toute application avec un catalogue vaste et diversifié avec un coût très limité.
Équilibrer exploration et exploitation
Dans le domaine des systèmes de recommandation, il y a toujours un équilibre à trouver entre explorer du nouveau contenu et exploiter ce qui est déjà connu pour être populaire. Cet équilibre, connu sous le nom de compromis exploration-exploitation, est une partie clé de la prise de décision en général.

En exploitant, le système recommande du contenu qui est populaire et susceptible de répondre aux besoins de l’utilisateur basé sur les préférences générales. D’autre part, l’exploration permet au système de trouver du contenu moins populaire qui pourrait être un match parfait pour l’utilisateur - du contenu qu’il aimera mais qu’il n’a pas encore découvert.
Il existe plusieurs ressources utiles sur ce sujet. Par exemple, un article de Minmin Chen de Google, présenté à la conférence RecSys 21, et un article de Yu Zhang du blog tech DoorDash. De nos jours, la plupart des méthodes pour équilibrer l’exploration et l’exploitation reposent sur des techniques d’apprentissage par renforcement. L’objectif est de trouver le meilleur équilibre pour améliorer à la fois les expériences à court et long terme des utilisateurs, ce qui peut conduire à une meilleure rétention des utilisateurs. Cependant, il est crucial de bien suivre les réponses des utilisateurs aux recommandations et aux items dans le catalogue.
Ce concept est pratiquement appliqué dans les conceptions de systèmes de recommandation, comme le service Personalize d’AWS, qui inclut la user personalization recipe. Cette recette comporte un paramètre exploration_weight qui peut être ajusté pour contrôler le niveau d’exploration (0 pour pas d’exploration, 1 pour une exploration maximale, avec une valeur par défaut de 0,3).
Techniques avancées de filtrage et de promotion
Contrôler la sortie est crucial dans les systèmes de recommandation. Pour la plupart des API, comme celles d’AWS, Recombee, ou Spotify, le nombre maximum d’items à retourner est un paramètre dans l’appel API. Habituellement, il y a une limite stricte d’environ 100 items, avec une valeur par défaut autour de 20-25 items basé sur le service. Limiter le nombre d’items est pratique car recevoir un catalogue de centaines d’items à la fois peut être écrasant (et lent).
Les systèmes offrent des moyens de filtrer et d’ajuster la sortie du système de recommandation de deux manières principales :
- En permettant aux utilisateurs de définir des critères de sélection. Un excellent exemple est sur l’endpoint get-recommendations de Spotify, où les utilisateurs peuvent filtrer les recommandations basées sur les caractéristiques des chansons (comme la dansabilité, l’acousticité, etc.).
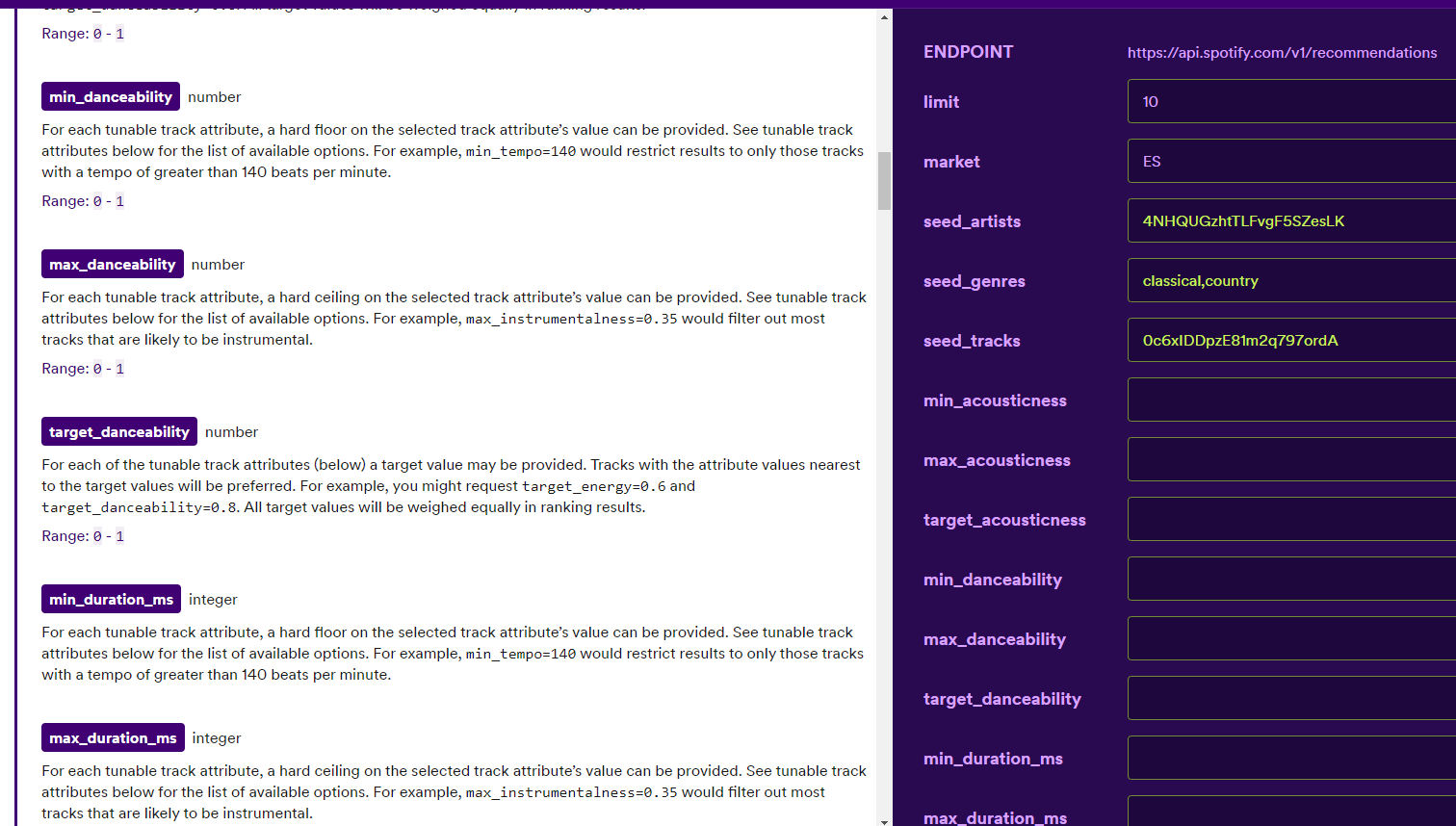
- En incorporant un concept de promotion d’item, où du contenu spécifique peut être mis en évidence dans le processus de recommandation. AWS Personalize introduit le concept de promotion (limité à 25 items), où chaque item est associé à un poids. Recombee utilise un concept similaire appelé boosted items.
La capacité de promouvoir certains items est clé pour les plateformes/applications avec une vraie stratégie de contenu. Cela permet de définir des règles spécifiques et peut permettre une influence manuelle sur les recommandations. Cette approche est probablement utilisée par des plateformes comme Netflix, où de tels mécanismes sont intégraux à leur logique de recommandation, même si ce n’est pas visiblement apparent.
Anticiper les actions des utilisateurs
Lors de la mise en place d’un pipeline pour collecter et traiter les données liées aux utilisateurs, les bonnes pratiques suggèrent d’avoir un ensemble de données structuré comme suit :
date: la date de l’actionuser: identifiant de l’utilisateuritem: identifiant de l’itemaction: type d’action que l’utilisateur a effectuée sur l’item
Cette structure est basique mais sert de point de départ pour d’autres ensembles de données (par exemple, à partir de cette action, vous pourriez calculer une notation implicite). Cette approche semble être un standard, car Recombee, par exemple, prend en charge plusieurs formats d’action typiques (voir, acheter, noter, ajouté au panier, marque-page) par défaut dans sa base de données. Ces actions deviennent ensuite des inputs pour leur logique de recommandation.

Prédire la prochaine action d’un utilisateur peut être crucial pour un business. AWS Personalize, par exemple, offre une recette pour prédire la prochaine meilleure action d’un utilisateur dans un écosystème. Bien que leurs exemples soient de haut niveau (comme les téléchargements d’applications, etc.), vous pouvez étendre cela aux recommandations en visant une partie du flux utilisateur à optimiser pour des actions spécifiques (comme filtrer les recommandations basées sur les filtres prédits qui correspondent à la prochaine meilleure action. Par exemple, dans le cas de Spotify, filtrer plus sur la dansabilité que l’acousticité parce que l’utilisateur est dans une ambiance danse).
Cela conclut mes points sur ce que je crois être des fonctionnalités fondamentales d’un système de recommandation. Maintenant, regardons plus en détail comment celles-ci peuvent être intégrées.
Principes de conception pour un système de recommandation
Pour cette section, je me concentrerai plus sur l’analyse des meilleures façons de concevoir un système de recommandation et son intégration dans les workflows, plutôt que sur les fonctionnalités du système de recommandation lui-même.
L’approche en deux étapes : récupération et classement
Ce concept, dont je parle souvent et que je mentionne une ou deux fois par an sur mon blog ou au travail, est bien résumé dans un article d’Eugene Yan qui présente les approches d’entreprises comme Alibaba, Facebook, JD, DoorDash. Pour moi, l’aspect le plus crucial est le diagramme montrant le flux global d’un tel système.
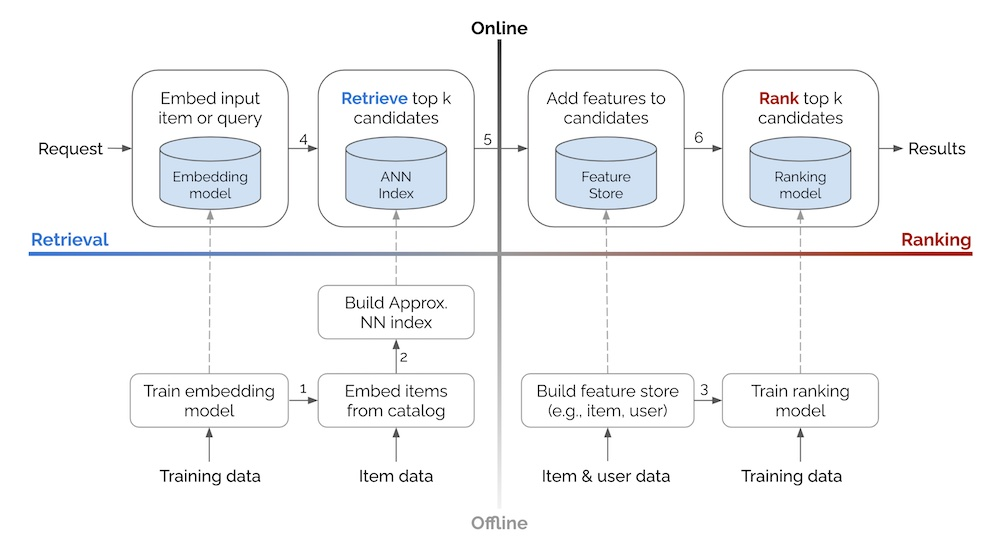
(Même Oldridge de Nvidia a proposé une variation à 4 étapes, maintenant le flux mais mettant l’accent sur le filtrage/logique business.)
Le concept est simple :
- #1 Concevoir un récupérateur de candidats pour identifier les items les plus pertinents pour un utilisateur (basé sur les caractéristiques de l’utilisateur et de l’item) moins les items avec lesquels l’utilisateur ne peut plus interagir.
- #2 Classer les candidats (basé sur les informations de l’utilisateur et de l’item).
De mon point de vue, cette approche est très attrayante car :
- Elle simplifie le processus, le rendant plus facile à comprendre et à adopter grâce à sa modularité.
- Elle évite le besoin d’un seul modèle complexe (qui est plus difficile à déboguer, tester et nécessite plus de ressources).
- Elle ouvre des possibilités de standardisation (à travers des stratégies de récupération et de classement de base) et de définition de blocs fiables
- Elle permet la personnalisation avec des pipelines supplémentaires sur le côté.
Honnêtement, dans mes projets de personnalisation récents, j’ai adopté cette approche, commençant généralement par une V0 de mon pipeline concentrée uniquement sur la récupération et itérant à partir de là.
Routes pour des recommandations personnalisées
Dans cette section, je me concentrerai plus sur les routes/endpoints qui sont essentiels pour personnaliser l’expérience utilisateur.
Avertissement : Ces routes sont inspirées des différents endpoints disponibles sur AWS Personalize et Recombee, c’est un grand mashup de tous ces services avec quelques ajustements venant de mon expérience.
Je vois trois chemins principaux :
get recommendations: Endpoint pour récupérer des recommandations personnalisées.get trends: Endpoint pour récupérer des items tendance.get random items: Endpoint pour récupérer une liste aléatoire d’items.

Toutes ces routes retourneront un objet JSON avec la structure suivante :
- recid : ID des recommandations produites.
- recommendations : Une liste de dictionnaires, chacun défini par une clé
idavec l’ID de l’entité recommandée. - source : Détails sur la source des recommandations, qui pourraient inclure une explication générale des recommandations, la date de mise à jour, etc.
En regardant de plus près les routes elles-mêmes, la route get recommendations retournera la sortie du pipeline en deux étapes (ou juste le récupérateur), get trends se concentrera sur la récupération d’items tendance (se référant aux items les plus populaires mentionnés dans cet article), et get random items retournera quelques sélections aléatoires (qui, d’après mon expérience, peuvent être étonnamment utiles).
Pour chaque route, savoir rapidement le statut de l’inventaire et l’historique utilisateur (ce qui ne peut pas être recommandé fondamentalement) est crucial. Cette connaissance est essentielle pour filtrer les items qui ne peuvent plus être recommandés.
Ci-dessous une brève description des inputs qui peuvent être fournis pour ces routes :
get recommendations- pipelineid : Identifiant pour le projet/pipeline associé aux recommandations.
- userid : Identifiant définissant un utilisateur.
- itemid (optionnel) : Identifiant d’un item utilisé comme contexte pour les fonctionnalités d’items liés.
- k (optionnel) : Nombre d’items à inclure dans les recommandations.
- default=20
- min=1
- max=100
- retriever strategy (optionnel) : Nom de la phase de récupérateur, lié au pipelineid.
- default=default
- ranker strategy (optionnel) : Nom pour la phase de classeur, lié au pipelineid.
- default=default
- exploration factor (optionnel) : Facteur d’exploration dans le pipeline.
- default=0.1
- min=0
- max=1
- promoted items (optionnel) : Liste d’items à promouvoir dans les recommandations.
- excluded items (optionnel) : Liste d’items à exclure dans les recommandations.
- detailed output (optionnel) : Booléen pour déterminer si des détails supplémentaires (métadonnées, explication, score, etc.) devraient être inclus dans la liste d’items recommandés.
- default=False
get trends- Des inputs tels que pipelineid, userid, itemid, k, promoted items, excluded items, et detailed output sont inclus dans cette route également.
- time period : Période de temps en secondes pour déterminer les tendances.
- default = 604800 secondes (7 jours)
- min = 3600 secondes (1 heure)
- max = 1209600 secondes (14 jours)
Ces inputs permettent une expérience de recommandation sur mesure, où l’intégrateur peut ajuster la sortie facilement et permettre aux utilisateurs de recevoir des suggestions d’items personnalisées, tendance ou aléatoires basées sur leurs préférences et contexte.
Implémentation des routes de recommandation
Dans cette section, je discuterai d’un cas d’usage pratique de personnalisation de page d’accueil, où la page d’accueil doit afficher 13 items.

Dans un scénario réel, l’objectif est de suivre un plan avec différentes stratégies pour gérer la liste d’items à afficher :
- #1 Définir la stratégie de remplissage : Quelle approche je veux utiliser ?
- #2 Définir la stratégie de secours : Que dois-je faire si la stratégie de remplissage ne fonctionne pas ?
- #3 Définir le scénario du pire cas : Que dois-je faire si j’ai besoin d’afficher quelque chose mais que tout le reste échoue ?
La stratégie de remplissage est la première approche que vous voulez appliquer. Vous pouvez configurer n’importe laquelle des routes présentées précédemment. Un conseil pour le nombre d’items que vous demandez : visez le double de ce qui peut être affiché (dans ce cas, 26 items) pour avoir des options à sélectionner.
La stratégie de secours aborde quoi faire si le nombre d’items de la stratégie de remplissage est inférieur à ce qui peut être affiché. Dans de tels cas, accéder à get trends ou get random items pourrait être des alternatives pertinentes.
Le scénario du pire cas est ce qui se passe si les stratégies de remplissage et de secours échouent toutes les deux, ou si les routes get ne sont pas accessibles. Cela devrait être le dernier recours à appliquer (habituellement un comportement par défaut du client de l’application), s’assurant qu’il y a toujours quelque chose à afficher, maintenant l’engagement utilisateur même quand le contenu personnalisé n’est pas disponible.
Créer ce plan tôt est très important car il peut réduire le risque de problèmes potentiels à l’avance. Il souligne également le besoin de recueillir rapidement l’inventaire/historique d’un utilisateur pour ajuster le contenu montré en conséquence.
Choisir entre service batch et live
Pour tout projet ML, la question se pose souvent : dois-je servir le modèle de manière batch (mis à jour toutes les X heures) ou de manière live (calcul à la demande) ? Chip Huyen a écrit un article intéressant sur cette dualité, et pour un système de recommandation, ce choix est moins évident.
De mon point de vue, en termes d’intégration (pour ceux connectant l’API à une application), cela devrait être transparent et toujours optimisé en termes de coût et de latence.
En tant que data scientist/MLE décidant de servir un pipeline de recommandation de manière live ou batch est plus lié à :
- La vraie valeur d’avoir des informations/données plus fraîches dans ma prédiction. Une bonne approche peut être de regarder les métriques offline et comparer les modèles. Même si nous savons qu’une amélioration d’une métrique offline pourrait ne pas se traduire de la même manière dans une métrique online, cela peut aider à prendre des décisions.
- L’impact en termes de couverture utilisateur lors du choix entre service live vs. batch. Combien de fois cette configuration spécifique pour l’utilisateur se produit qui peut justifier le besoin de service live.
Un autre aspect est que le service batch est excellent pour les grands modèles, car ils peuvent prendre beaucoup de temps pour produire des prédictions, tandis que le service live nécessite des modèles plus réactifs. Mon avis là-dessus, surtout si vous descendez le chemin get recommendations, est que vous pourriez avoir un récupérateur qui s’exécute en batch tous les jours, avec un classeur qui peut être en service live. Ce n’est pas nécessairement l’un ou l’autre seulement, mais une approche hybride peut être intéressante à mettre en place.
Dans tous les cas, il est essentiel de surveiller comment les recommandations servies se comportent en termes de :
- Coût par utilisateur : Combien coûte l’exécution du pipeline ?
- Gains : En termes de métriques liées à l’utilisation de l’application, quelle est la valeur ajoutée pour l’utilisateur ?
- La performance des prédictions avec des métriques recsys classiques comme le taux de succès, NDCG, etc.
Dans cette configuration, il est important de garder un bon état d’esprit expérimental pour essayer différentes idées pour déterminer quel pipeline fonctionne le mieux à la fois pour les utilisateurs et l’entreprise. Par exemple, dans certains cas, un pipeline pourrait ne plus être pertinent (pas assez d’utilisateurs/activité), et vous pouvez décider de basculer vers la stratégie de secours/scénario du pire cas pour réduire le coût. L’expérimentation continue peut aider à prendre ces décisions à l’avance en anticipant les changements.
Des entreprises comme Spotify ont une vaste expérience dans ce domaine et commencent à partager leurs connaissances en construisant des services comme Confidence, leur plateforme d’expérimentation qui peut être un bon point de départ pour quiconque veut mettre en place de bonnes pratiques.
Mettant de côté les aspects liés au protocole d’expérimentation (taille d’échantillon, signification, etc.), lorsque vous menez une expérimentation continue, il est également essentiel de garder l’entraînement du modèle en boucle fermée pour éviter l’impact positif ou négatif d’autres groupes. Netflix a publié un article lors de la dernière conférence RecSys sur ce sujet et a partagé leur expérience.
Obtenir des recommandations pour un lot d’utilisateurs/items
Quelque chose que j’ai noté dans mon expérience actuelle de construction de recommandations dans les applications est la capacité d’accéder à ces mêmes recommandations dans différents contextes pour un groupe d’utilisateurs en même temps.
Cette capacité est vraiment importante dans un écosystème connecté où, par exemple, vous pouvez fournir des recommandations sur la page d’accueil d’une application, mais vous voulez aussi attirer les utilisateurs via d’autres canaux comme l’email ou les notifications, etc. Donc, vous devez être capable de collecter des recommandations pour plusieurs utilisateurs d’un coup pour activer le bon canal au bon moment.
Une bonne inspiration de comment cela pourrait ressembler est les fonctionnalités batch d’AWS Personalize, où vous pouvez récupérer une liste de recommandations pour un ensemble d’utilisateurs ou d’items. L’appel devrait ressembler aux routes présentées précédemment, avec les mêmes paramètres de configuration sauf pour les champs utilisateurs et items pour obtenir un batch en même temps (avec des milliers d’entités d’un coup).

Mais comme nous pouvons nous y attendre, le référentiel d’IDs dans l’application principale où le contenu vit n’est pas le même que celui lié au système de notification ou d’email, donc il est essentiel d’avoir de solides capacités de mapping d’items pour transférer la recommandation d’un contexte (ID spécifique) à un autre (avec un autre ID) sans interférence.
Enfin, et je pense que c’est important à souligner, vous ne devriez pas arrêter de recommander quelque chose dans l’application juste parce que vous ne pouvez pas utiliser certains actifs dans l’email. Cela n’a pas de sens et rendra l’expérience plus pauvre pour l’utilisateur au final. Donc, découpler le problème de l’activation utilisateur et de la personnalisation du contenu est essentiel.
Exploiter les recommandations pour des insights de stratégie de contenu
Enfin, et je pense que c’est l’un des points les plus importants de cet article, est qu’un système de recommandation n’est pas seulement là pour fournir des recommandations. Il est également là pour fournir des insights aux créateurs d’application/contenu sur la consommation et le statut du contenu.
Savoir que certains items performent mieux dans certains contextes et comprendre l’association d’items dans le panier d’un utilisateur sont deux cas d’usage simples et évidents qui ne sont que la pointe de l’iceberg des connaissances qui peuvent être extraites d’un système de recommandation, et cela ne devrait pas être sous-estimé. Cela peut aider à surveiller la performance de l’application et à prendre des décisions éclairées.
Un exemple de cette application est Netflix, dans leur article RecSysOps, présente un point intéressant où ils peuvent prédire si le contenu va performer comme attendu ou non, et un système de recommandation pourrait aider dans cette détection. Mon interprétation dans leur cas est que lorsque du nouveau contenu est fourni, il y a un certain nombre de métadonnées/actifs associés avec lui, et ils peuvent estimer comment ce contenu avec les métadonnées/actifs actuels va performer pour des utilisateurs spécifiques, comme comment le nouveau contenu sera perçu par les fans de films d’action, et peuvent l’ajuster avant la sortie pour éviter tout problème quand le contenu devient live.
Découpler le système de recommandation en deux parties (récupérateur et classeur) peut aider dans cela, mais il est également important d’implémenter d’autres éléments comme les archétypes d’utilisateurs pour déterminer le comportement global de l’application dans des contextes et avec du contenu spécifiques. Plus généralement, un système de recommandation devrait être seulement un composant d’une stratégie d’éditorialisation, et les plateformes de streaming le voient comme ça et exploitent vraiment sa connaissance pour prendre des décisions sur l’expérience globale (la BBC a écrit un article sur leur expérience pour la conférence RecSys 2023).
Notes de conclusion
Cet article est assez dense, je sais, mais je pense qu’il peut être un bon point de départ pour quiconque voulait comprendre tous les éléments qui peuvent être en place sous ce type d’application. J’aurais été heureux d’avoir quelque chose comme ça il y a 6 ans quand je suis arrivé chez Ubisoft, mais le domaine n’était pas le même alors. Pour moi, cet article sera le point de départ de diverses expériences et réflexions sur le domaine des systèmes de recommandation, donc restez à l’écoute ✌.
Explorer la documentation des systèmes de recommandation en tant que service était assez intéressant, et AWS Personalize et Recombee sont sûrement un excellent départ pour quiconque veut démarrer un système de recommandation dans une entreprise sans expérience dans ce domaine. Mais faites attention à quelques choses :
- Le prix : Il semble d’après les gens autour de moi que ce type de système est très facile à intégrer, mais peut devenir très coûteux rapidement.
- Les données : Comme avec tout service comme ça, soyez très conscient de comment vos données seront utilisées. Je ne me concentre pas sur la sécurité des données mais plus sur le fait que les données fournies (et les connaissances extraites) peuvent être utilisées par ce service pour devenir plus efficace. (Mise à jour 20240415, basé sur le repost de Recombee de mon article)
- La standardisation n’est pas tout : J’ai noté que sur le service premium de Recombee, il offre une solution sur mesure par leur équipe DS, donc cela illustre qu’une certaine personnalisation est nécessaire.
Comme je l’ai dit dans l’introduction, les algorithmes et les données n’étaient pas le focus de cet article, mais dans ma recherche, j’ai réussi à trouver une chose intéressante. Il semble qu’AWS Personalize ait été construit sur un HRNN (Hierarchical Recurrent Neural Networks), potentiellement quelque chose à creuser. Mais plus sérieusement, pour tout DS/MLE impliqué dans ce sujet, je ne pense pas que le focus du pipeline de système de recommandation devrait être sur l’algorithme lui-même, mais se concentrer plus sur :
- Feature engineering : Traiter les données utilisateur/item et extraire les features pertinentes.
- Embedding engineering : Extraire des informations d’un item à partir de différentes sources (image, texte, son, etc.).
À propos des LLM et Gen AI, je vois quelques points à garder à l’esprit :
- L’architecture transformers a commencé à impacter le monde des systèmes de recommandation il y a quelques années. Ma première rencontre était avec Transformers4Rec de NVIDIA en 2021. Cela semble être utile dans les applications réelles. Par exemple, Deezer a récemment fait une comparaison entre une architecture transformers et une architecture SVD sur une fonctionnalité spécifique de leur application. Cependant, comme avec les modèles basés sur le deep learning, leur efficacité doit encore être prouvée (d’après mon expérience, ils ne sont pas une solution universelle).
- Les LLM et modèles multimodaux sont très utiles pour générer des métadonnées pour les items en analysant les descriptions et actifs pour produire des tags. J’ai fait quelques tests pour classifier du contenu, et c’était assez efficace.
- La GenAI dans le monde des recommandations peut être très utile pour personnaliser et ajuster le contenu. AWS a embrassé cette approche en ajoutant des capacités d’IA générative à leur produit Personalize.
Enfin, il y a quelques points que j’ai suggérés qui peuvent aussi être importants dans la conception d’un système de recommandation :
- Avoir une définition claire du catalogue d’items est crucial. Comme suggéré dans diverses sections précédemment, savoir quels sont les items et comment ils sont définis dans votre application/écosystème est très important.
- Construire des segments d’items peut améliorer l’efficacité. Recombee construit cette définition, et je pense que cela peut aider dans la phase d’inférence (optimiser la phase de récupération en récupérant un pool d’items) et fournir des insights précieux sur l’utilisation de l’application en général.
- Le concept de rotation d’items : Faire tourner les recommandations pour inclure des items vus dans le passé peut augmenter l’engagement (je l’ai essayé ; croyez-moi). Si c’est basé sur le tracking, vous pouvez ajuster l’importance des items basée sur l’exposition passée d’un utilisateur (un bon exemple de l’importance du tracking utilisateur). Recombee offre la capacité de définir un facteur de rotation dans l’appel api de leur endpoint (rotation rate et rotation time)
- Pagination dans les recommandations : L’endpoint de Recombee offre la capacité de parcourir les recommandations. Cette fonctionnalité peut être utile quand vous avez besoin d’accéder rapidement à plus de contenu, et avoir un identifiant pour la recommandation produite est crucial. Elle peut être particulièrement utile dans les applications avec une utilisation intensive, comme un réseau social avec le fameux et controversé mécanisme de défilement infini.
J’espère que vous avez trouvé cette lecture aussi agréable que j’ai trouvé l’écrire, et si vous avez des retours ou des points à ajouter/commenter, n’hésitez pas à partager.
Au-delà de cet article, j’aime discuter de données, d’IA et de conception de systèmes—comment les projets sont construits, où ils réussissent et où ils échouent. Si vous voulez échanger des idées, remettre en question des hypothèses ou parler de vos propres projets, n’hésitez pas à me contacter. Je suis toujours ouvert pour une bonne conversation.
Références
- Practical Recommender Systems — manning.com
- les meilleures pistes d’artiste — developer.spotify.com
- Popular Item Recipe — AWS
- la logique populaire sur Recombee — docs.recombee.com
- meilleure première étape d’un projet ML est de ne pas faire de ML — developers.google.com
- Related Items Recipe — AWS
- Items to Item — docs.recombee.com
- Users to User — docs.recombee.com
- Related Products — help.shopify.com
- Complementary Products — help.shopify.com
- Get Related Artists — developer.spotify.com
- un article de Minmin Chen de Google — dl.acm.org
- un article de Yu Zhang du blog tech DoorDash — doordash.engineering
- user personalization recipe — AWS
- AWS — AWS
- Recombee — docs.recombee.com
- Spotify — developer.spotify.com
- concept de promotion — AWS
- boosted items — docs.recombee.com
- formats d’action typiques — docs.recombee.com
- offre une recette pour prédire la prochaine meilleure action — AWS
- un article d’Eugene Yan — eugeneyan.com
- variation à 4 étapes — Medium / Towards Data Science
- AWS Personalize — AWS
- Recombee — recombee.com
- un article intéressant — huyenchip.com
- Confidence — confidence.spotify.com
- un article — dl.acm.org
- fonctionnalités batch d’AWS Personalize — AWS
- article RecSysOps — Medium / Towards Data Science
- BBC — dl.acm.org
- le service premium — recombee.com
- HRNN — arXiv
- Transformers4Rec de NVIDIA — GitHub
- une comparaison entre une architecture transformers et une architecture SVD sur une fonctionnalité spécifique — arXiv
- produit Personalize — AWS
- construit cette définition — docs.recombee.com
- mécanisme de défilement infini — interaction-design.org
- parcourir les recommandations — docs.recombee.com