
Former un maître du jeu Suika : Créer le terrain de jeu
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
L’année dernière, j’ai commencé à explorer le monde des moteurs de jeu pour approfondir mon expérimentation/exploration du domaine du machine learning. Je me suis amusé à explorer Unity, mais je voulais prendre du recul pour explorer les algorithmes et approches pour entraîner des agents de jeu plus en détail avant de me concentrer sur la construction d’un environnement (type dev de jeu !?).
Pour ce faire, je voulais commencer avec un jeu simple basé sur la physique parce que c’est amusant, mais je voulais éviter les projets récurrents Tetris, Super Mario Bros, Flappy Bird ou Dino game. Ce sont des jeux amusants, ne vous méprenez pas, mais ils peuvent manquer d’originalité pour moi. Le Noël dernier, j’ai découvert le jeu Suika Game, ou Watermelon Game, qui je pense est le candidat parfait pour cette expérience. Cet article se concentrera principalement sur :
- Expliquer le jeu et la configuration
- Développer les premiers agents, qui seront mes agents de base pour de futures expériences (afin d’entraîner un maître Suika).
PS : Je sais que je ne suis pas le seul à avoir abordé ce jeu comme projet ML
Suika quoi ?
C’est un jeu vidéo de puzzle japonais par Aladdin X, qui combine les éléments de jeux de puzzle tombants et fusionnants. Le jeu a été développé à l’origine pour les projecteurs numériques de l’entreprise en avril 2021 et, en raison de son succès initial, sorti sur le Nintendo eShop en décembre 2021 au Japon. Après avoir gagné en popularité, il a été rendu disponible mondialement en octobre 2023. Le concept provient d’un jeu de navigateur chinois intitulé “Merge Big Watermelon” qui est sorti en janvier 2021.
Le jeu implique que le joueur essaie de construire un score élevé en laissant tomber des fruits dans un conteneur sans les faire déborder. Pour gagner des points, le joueur doit combiner deux fruits identiques, ce qui crée un nouveau fruit dans le cycle de fruits du jeu. Il y a un lien vers une version web ICI avec plein de variantes (comme une de Taylor Swift)
Pour moi, c’est une sorte de mashup basé sur la physique entre Tetris et Puzzle Bobble, facile à jouer mais difficile à maîtriser. Avec cela en tête, j’ai décidé de commencer ma propre implémentation en Python, et après 2-3 heures de codage, voici où j’en suis arrivé.

Donc, gérer le spawn et la chute des fruits n’était définitivement pas difficile, mais ma lutte a commencé quand j’ai voulu ajouter de la physique à la chose (car pygame n’est pas un moteur physique). Donc, j’ai décidé de chercher sur internet des implémentations existantes, et ma recherche m’a conduit à cette vidéo par OB1 (la chaîne YouTube semble avoir des trucs plutôt cool).
Il a présenté sa propre implémentation du jeu, avec un repository associé. Toute la physique de la balle/particule exploite un autre package appelé Pymunk, spécialisé en physique 2D.
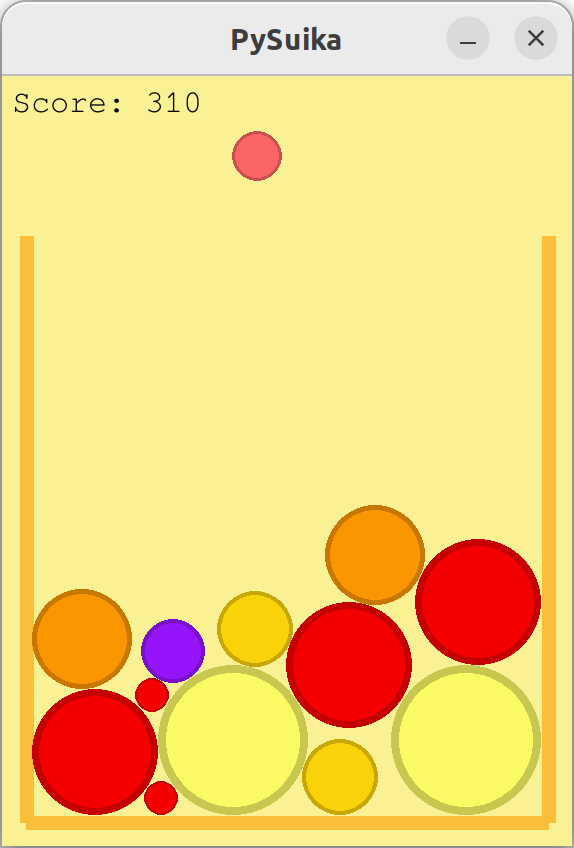
J’ai fait quelques ajustements à l’implémentation originale pour qu’elle soit jouée par une machine et non un humain (à l’origine vous devriez utiliser votre souris), et maintenant j’ai tout pour continuer mon expérimentation.
Design de gym et d’agent
La fondation de mon expérience sera le gym où l’agent exécutera des actions pour jouer au jeu, et ces actions seront enregistrées avec le statut de l’environnement. Dans notre cas, l’environnement est composé du conteneur de fruits avec les fruits précédemment tombés, le score et le prochain fruit à tomber.
Mon gym est assez limité à une configuration comparé à d’autres comme celui d’OpenAI (qui semble avoir changé de leadership récemment), qui contient beaucoup d’environnements différents. Une “session de gym” ressemble à ça.
import gymnasium as gym
env = gym.make("LunarLander-v2", render_mode="human")
observation, info = env.reset(seed=42)
for _ in range(1000):
action = env.action_space.sample() # this is where you would insert your policy
observation, reward, terminated, truncated, info = env.step(action)
if terminated or truncated:
observation, info = env.reset()
env.close()
Une instance d’un environnement peut être configurée où un agent général peut interagir avec lui à des étapes spécifiques. À la fin du jeu, vous pouvez réinitialiser l’environnement. Notez qu’il y a aussi la notion de récompense dans ce gym, qui illustre son utilisation dans les applications d’apprentissage par renforcement.
C’est un design vraiment soigné. Je visais à avoir quelque chose qui ressemble à ça, mais mon design est plus simple.
Le script exécutant l’environnement est appelé simulation et peut être exécuté avec différents paramètres :
agent: pour définir le type d’agent qui va s’exécuter.scenario: un chemin vers un fichier qui définit le scénario de fruits qui tomberont (expliqué plus tard).
Le paramètre scenario vous permet de fournir un motif spécifique de fruits qui tomberont pendant la simulation. J’ai configuré un motif de 1000 fruits. Si la simulation va au-delà de ces 1000 fruits, une affectation aléatoire se produira (comme si vous n’aviez fourni aucun scénario). Je veux fournir un motif de scénario pour offrir une capacité de rejouabilité simple à ma configuration, permettant des comparisons logiques (pour comparer des motifs typiques et voir comment l’agent se comporte dans un contexte similaire).
Dans le script, après la déclaration de l’agent, l’environnement va jouer, et c’est là que la magie commence (toutes les 2 secondes).
L’idée générale est que dans l’environnement nous allons :
- Vérifier les états des particules (alias fruits), ce qui signifie leur position dans le conteneur et le type de fruit.
- Construire une observation qui sera composée de :
- Les états des fruits
- Le fruit qui doit être lâché
- Le score
- Le timestamp
- Basé sur l’observation, l’agent prendra une action pour déplacer le fruit à un endroit spécifique.
- L’observation sera sauvegardée dans un buffer.
Cette boucle continuera jusqu’à la fin du jeu (si vous atteignez le haut du conteneur). Dans ce cas, le buffer sera sauvegardé dans un fichier CSV avec les différentes informations collectées dans le buffer pendant l’exécution.

Un autre aspect de l’environnement pour entraîner l’agent est la capacité de multithreader différents jeux en parallèle. Dans mon cas, j’ai décidé d’utiliser un script bash pour exécuter différents jeux en parallèle (pas plus de 4). Mon approche est brute force, mais elle fait le travail pour l’expérience sur mon ordinateur portable.
Maintenant discutons de la partie amusante, l’agent.
Pour commencer, je vais utiliser la définition de l’agent trouvée dans le livre Artificial Intelligence: A Modern Approach. Grand merci à Nguyen Nguyen de m’avoir présenté le livre, et au vide-grenier d’Ubisoft qui m’a donné l’opportunité d’acheter la 2e édition. Dans ce livre, les auteurs définissent un agent comme :
Un agent est tout ce qui peut être considéré comme percevant son environnement à travers des capteurs et agissant sur cet environnement à travers des actuateurs.
Très théorique, et ils ont aussi un joli schéma dans la figure.
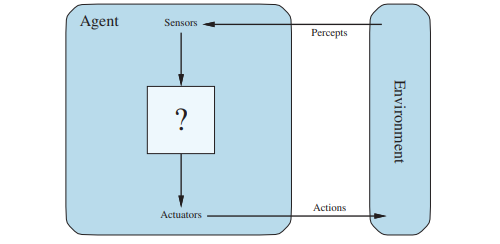
Donc dans mon cas, l’agent percevra le fruit à lâcher, le statut du conteneur et le score. Son action sera de déplacer le fruit et de le lâcher. Plutôt facile, non ? :)
Je vais être honnête avec vous, je trouve ma configuration de la perception quelque peu triche parce qu’elle est très intégrée dans l’environnement (car je collecte toutes les données directement de l’environnement). Vous pourriez vous attendre à ce qu’un agent n’ait pas ce niveau d’intégration dans la vraie vie, mais dans l’industrie du jeu vidéo, c’est la réalité. Les agents sont branchés directement dans le moteur, donc ils n’ont pas besoin de percevoir le jeu de l’extérieur (comme le ferait un joueur humain).
En revenant à l’agent lui-même, la “boîte point d’interrogation” appelée programme d’agent implémente la fonction d’agent pour traiter les données des capteurs en actions via les actuateurs. C’est là que l’intelligence (artificielle ?) a lieu.
Il existe plusieurs types d’agents définis dans le livre, tels que les agents basés sur des objectifs, les agents réflexes et les agents utilitaires. Je vous recommande fortement de regarder le livre si vous voulez plus de détails là-dessus. Dans mes futures expériences, j’essaierai de creuser ces concepts plus en détail et d’appliquer certains algorithmes derrière eux dans de futurs articles
Donc nous avons le gym/environnement, et nous avons l’agent. Codons les premiers agents.
Premiers agents : Random & Baseline
Pour commencer, je voulais créer des agents simples avec des règles très simples derrière le programme d’agent pour établir une base de référence pour de futures évaluations utilisant des techniques ML plus avancées.
Mon premier agent, que nous appellerons Random, est simplement un système qui lâchera le fruit aléatoirement dans le conteneur. Oui, je sais que c’est ennuyeux, mais les résultats ne sont pas si mauvais.
Mon deuxième agent, appelé Baseline, est un modèle simple basé sur des règles avec les règles suivantes :
- Si le fruit à tomber trouve une paire dans le conteneur de fruits, le faire tomber vers le fruit similaire le plus proche.
- Si aucun fruit ne correspond dans le conteneur, le lâcher aléatoirement.
J’ai inclus le code ici si vous êtes curieux :
Ces modèles de base peuvent interagir avec l’environnement et commencer à jouer à Suika par eux-mêmes. Pour cet environnement, je peux voir différentes métriques pour évaluer comment l’agent se comporte : le score du jeu et le nombre d’étapes dans un jeu (ou une série de jeux).
J’ai mené un petit benchmark des agents dans deux contextes : un dans une série de 10 jeux aléatoires et le second dans un scénario pré-fait, Scénario 10. J’ai compilé les résultats des agents dans les deux graphiques suivants.
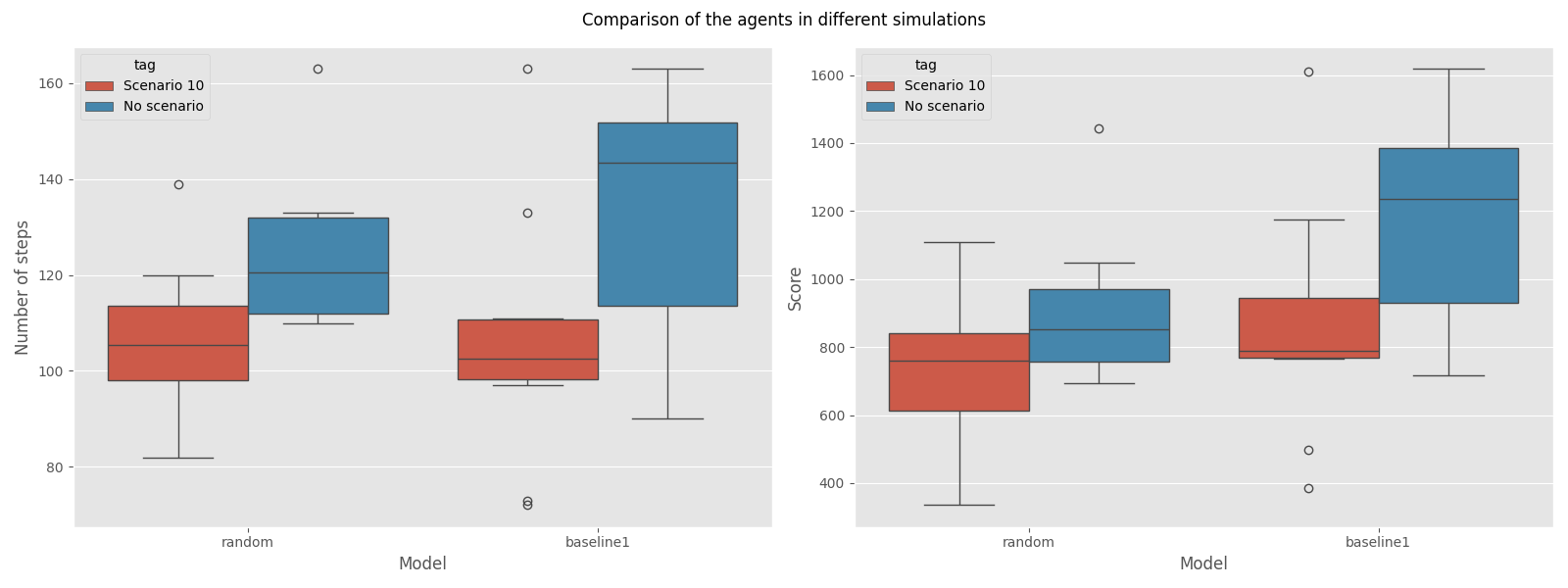
Globalement, il semble que :
- Dans le contexte de jeu aléatoire, le Baseline est légèrement meilleur que le Random, mais leurs scores moyens sont assez proches (environ 800).
- Dans le contexte du Scénario 10, le modèle Baseline a des jeux plus longs et génère plus de points (900 vs 1200).
Donc la grande question est, comment ces agents se comportent-ils par rapport à un joueur humain ? D’après ma compréhension et mon expérience :
- Un joueur moyen (comme moi) semble atteindre un score entre 1800 et 2500 dans les jeux aléatoires.
- Les meilleurs scoreurs de la semaine actuelle sont plus proches de 4000 (mais légèrement en dessous).
Donc nos baselines sont loin d’atteindre un joueur moyen, ce qui signifie qu’il y a de la place pour l’amélioration (et l’apprentissage de trucs) :)
Prochaines étapes
Cet article/projet n’était qu’une mise en bouche, et je continuerai à travailler dessus dans les semaines suivantes avec un focus plus sur le développement de programme d’agent.
Je vois les étapes suivantes devant moi :
- Exploration d’algorithmes :
- Benchmarker le nouvel agent contre la baseline actuelle et le joueur moyen (2000), et le meilleur scoreur (4000).
- J’ai en tête les algorithmes génétiques, l’apprentissage par renforcement, l’apprentissage supervisé, et peut-être les LLM (parce que ça semble être la chose en ce moment) à explorer dans le futur.
- Amélioration de l’environnement :
- Gérer l’accélération du temps pour exécuter des expériences plus rapides (= plus d’expériences).
- Passer de l’agent embarqué dans l’environnement à l’environnement embarqué dans l’agent.
- Déploiement de la simulation et de l’environnement d’entraînement (pourquoi pas !?)
Pour être honnête, je me concentrerai principalement sur l’exploration d’algorithmes, donc restez à l’écoute pour de futurs posts sur le sujet.
Au-delà de cet article, j’aime discuter de données, d’IA et de conception de systèmes—comment les projets sont construits, où ils réussissent et où ils échouent. Si vous voulez échanger des idées, remettre en question des hypothèses ou parler de vos propres projets, n’hésitez pas à me contacter. Je suis toujours ouvert pour une bonne conversation.
Références
- Tetris — Wikipedia
- Puzzle Bobble — Wikipedia
- repository associé — GitHub
- Pymunk — pymunk.org
- celui d’OpenAI — GitHub
- leadership récemment — gymnasium.farama.org
- Artificial Intelligence: A Modern Approach — aima.cs.berkeley.edu
- la chose en ce moment — GitHub