
Un guide pratique pour packager un projet Python autour d'un jeu de cartes
Note: Cet article a été traduit avec Claude Code le 24 mars 2026. La version originale est disponible ici.
J’ai voulu écrire sur le packaging Python depuis un moment, mais le bon projet n’était jamais venu : mes packages professionnels sont propriétaires, et mes projets personnels sont des scrapers web dont je préfère ne pas parler.
Mais le dernier Noël, mes recommandations YouTube m’ont fait découvrir un très amusant jeu de cartes solo appelé Scoundrel, et j’ai pensé que ce serait un bon support pour illustrer mes « bonnes pratiques » sur la façon d’organiser et de configurer un dépôt Python pour qu’il soit packagé.
Cet article commencera par expliquer le jeu et la conception du packaging. Les sections suivantes parcourront l’organisation du code, la publication, les tests, la documentation et quelques conseils de clôture.
Qu’est-ce que Scoundrel ?
Scoundrel est un jeu de cartes solo de type rogue-like créé par Zach Gage et Kurt Bieg en 2011. C’est une sorte de solitaire dungeon crawler qui peut se jouer avec un jeu de cartes classique. Si vous voulez mieux comprendre le principe, je partage la vidéo que YouTube m’a recommandée sur le jeu.
Le jeu est simple et il semble avoir gagné beaucoup de popularité au cours de l’année passée, d’après les vidéos YouTube que j’ai vues sur le sujet.
Il existe de nombreuses implémentations de Scoundrel sous forme de jeu standalone (steam, itchio) ou en Python (benjamin-t-brown, marcs-sus, Lizzard1123) avec différents aspects qui couvrent la logique du jeu et ajoutent parfois des fonctionnalités pour entraîner des agents.
J’ai décidé de travailler sur ma propre implémentation, car j’ai pensé que ça pourrait être une bonne alternative à mon projet Suika Game abandonné/en pause pour construire un environnement amusant pour entraîner des bots. Ce sera plus simple, c’est sûr, mais l’objectif de ce package est :
- Créer une interface en ligne de commande basique avec rich
- Avoir un environnement qui peut s’interfacer facilement avec des scripts/agents Python
- Possibilité de jouer en mode headless (pour les agents) ou avec une UI (pour les humains)
- Possibilité de reproduire les parties avec une graine (seed)
- Configuration du donjon pour rester proche des concepts d’armes, de santé et de monstres du jeu, sans être lié à la configuration d’un jeu de cartes standard
- Fonctionnalités de logging pour l’analyse et l’entraînement d’agents
Sur cette base, plongeons dans la structure du dépôt.
PS : Comme vous le remarquerez, la logique du jeu a principalement été codée par Claude Code, car recoder une logique de jeu de cartes n’est pas la partie la plus fun de ce projet. J’ai fait ça dans mon travail pour des projets d’équilibrage sur NFL prime fantasy, donc j’étais content de laisser Claude s’en charger 😉.
Structure du projet, configuration & publication
Dans cette section, nous nous concentrerons sur l’organisation du code et sur la façon de rendre le package disponible au monde via PyPI (LA plateforme pour partager des packages Python).
Configuration du projet
Pour ce projet, je suis les lignes directrices disponibles sur le site de packaging Python, simplement adaptées pour un projet prêt à être déployé.
Voici la structure globale de mon projet
graph TD
A[pyscoundrel] --> B[.github/]
A --> C[docs/]
A --> D[src/pyscoundrel/]
A --> E[tests/]
A --> F[pyproject.toml]
B --> B1[scripts/]
B --> B2[workflows/]
Les répertoires clés sont :
- src/pyscoundrel/ : c’est là que toute la logique réside, nous y reviendrons un peu plus en détail, mais il contient toutes les fonctionnalités depuis la logique du jeu, l’UI, la gestion des agents, la reproductibilité, etc.
- tests/ : tous les scripts liés aux tests du code et aux tests d’intégration
- docs/ : où toute la documentation du package est hébergée
- .github/ : tout le code pour le CI/CD du projet
À la racine de tout cela se trouve un README.md qui explique l’objectif du package et les informations sur les fonctionnalités de base, mais l’élément le plus important est le fichier pyproject.toml qui lie ensemble le dépôt Python, l’environnement de test et PyPI.
Le pyproject.toml est un fichier de configuration contenant de nombreuses sections pour rendre le package facile à construire, tester et partager :
- [build-system] : définit le système de build utilisé pour packager votre code, j’ai utilisé setuptools qui est historiquement l’un des plus populaires, mais de nouveaux apparaissent comme hatchling ou flit_core (les backends de build derrière Hatch et Flit, respectivement) qui valent le détour (documentation).
- [project] : cette section est le hub de métadonnées du projet — nom, version, auteur, licence et dépendances s’y trouvent tous. C’est ce qui sera affiché sur la page PyPI. Une partie importante de cette section est celle des dépendances car elle définit les exigences minimales du package.
- [project.xxx] : de nombreuses sections pour définir diverses informations supplémentaires sur le package, les plus importantes pour moi sont :
- [project.optional-dependencies] : pour gérer les dépendances de l’environnement de développement
- [project.scripts] : pour créer une interface en ligne de commande, j’en ai créé une pyscoundrel (plus pour le fun que pour l’utilité vraiment)
- [tool.xxx] : une série de sections qui configurent les outils utilisés pour votre package, par exemple il y a une section setuptools pour configurer la phase de build. Nous reviendrons sur ces sections plus loin dans l’article.
Un champ de [project] qui mérite une mention à part entière : license. Choisir une licence n’est pas optionnel — publier un package sans licence signifie que personne ne peut légalement l’utiliser. Les choix les plus courants pour les packages Python open source sont :
- MIT : la plus permissive et la plus populaire. N’importe qui peut utiliser, modifier et redistribuer votre code, y compris dans des logiciels propriétaires, sans autre obligation que de conserver votre notice de copyright. Un bon choix par défaut pour les bibliothèques.
- Apache 2.0 : permissivité similaire au MIT mais ajoute une concession explicite de brevet, protégeant les utilisateurs des réclamations de brevet par les contributeurs. Courante dans les projets open source d’entreprise.
- GPL (v2 / v3) : copyleft — tout travail dérivé doit également être publié sous GPL. Cela garantit que le code reste ouvert, mais empêche son utilisation dans des logiciels propriétaires. Les packages PyPI sous GPL peuvent poser problème aux utilisateurs commerciaux.
Pour pyscoundrel j’ai opté pour MIT : c’est une bibliothèque de jeu, et imposer des restrictions d’utilisation ne ferait que compliquer les choses. Si vous hésitez, choosealicense.com propose une comparaison claire côte à côte. Une fois choisi, déclarez-la dans pyproject.toml avec license = {text = "MIT"} et déposez un fichier LICENSE à la racine du dépôt — PyPI et GitHub le mettent tous deux en évidence automatiquement.
Ce fichier est la clé du packaging, et il couvre l’organisation du dépôt. Regardons maintenant la structure du code dans src/
Organisation du code source
Voici une représentation simplifiée du dossier
graph TD
root["pyscoundrel/"]
root --> init["__init__.py"]
root --> main["__main__.py"]
root --> config["config.py"]
root --> game["game/"]
root --> agents["agents/"]
root --> dungeon["dungeon/"]
root --> logging["logging/"]
root --> models["models/"]
root --> ui["ui/"]
root --> utils["utils/"]
game --> g_init["__init__.py"]
game --> g_actions["actions.py"]
game --> g_engine["engine.py"]
game --> g_state["state.py"]
(Seul le sous-arbre game/ est développé ici pour la concision.)
La structure contient des dossiers avec des fichiers contenant tout le code. Dans ces dossiers se trouvent des fichiers __init__.py qui, dans un layout src avec setuptools, marquent chaque sous-package comme importable.
De manière générale, les modules regroupent des classes et des fonctions associées, en suivant les conventions de formatage standard.
Je mets en évidence ce code pour montrer les pratiques importantes/minimales :
- Les imports sont limités à ce qui est nécessaire, pas de
from xxx import * - Les imports sont en ordre alphabétique
- Chaque fonction/classe est documentée avec une docstring couvrant les entrées, les sorties et une explication de base
- Les paramètres d’entrée sont définis avec des valeurs par défaut
- Pas de déclarations de fonctions trop longues
Ce sont les standards minimaux ; nous y reviendrons plus tard.
Enfin, il y a un fichier __main__.py qui relie tout ensemble et permet d’exécuter Scoundrel depuis la ligne de commande.
Revenons maintenant à la phase de publication.
Construction et publication
Avec le dépôt prêt, la construction du package prend deux commandes.
L’étape de build lit pyproject.toml et produit deux fichiers nommés d’après le package et la version :
- .tar.gz : distribution source contenant le code + les métadonnées ; pip peut le construire à partir de celui-ci si aucune wheel n’est disponible pour la plateforme cible
- .whl : distribution binaire, package pré-construit qui peut être installé directement
La destination finale habituelle pour un package qui veut être partagé est PyPI, l’index des packages Python. Pour le rendre disponible, la configuration est assez simple et vous pouvez suivre les ressources de packaging.python pour configurer votre machine et votre espace PyPI.
La publication est généralement réalisée avec le package twine et ces lignes de commande.
Vous pouvez trouver mon package ici https://pypi.org/project/pyscoundrel/
NB : la pratique habituelle est de publier d’abord sur testpypi avant de pousser vers PyPI. Le risque est faible pour un projet personnel, mais pour tout projet avec de vrais utilisateurs, faites toujours un essai sur TestPyPI en premier.
PyPI est définitivement simple, mais encore une fois pas obligatoire. Vous pouvez aussi simplement partager le code sur un dépôt et laisser les gens faire l’installation, ou vous pouvez héberger le package sur d’autres services (par exemple chez Ubisoft nous utilisons Artifactory). Choisissez ce qui correspond le mieux à vos besoins de distribution.
Donc voilà, vous avez toutes les clés pour packager et partager votre code… presque. C’était juste la première étape. Voyons comment le rendre plus robuste, mieux testé et plus facile à maintenir.
Tests
À mesure qu’un package grandit, de nouvelles fonctions, des modules réorganisés et des valeurs par défaut modifiées apparaissent, donc la vérification manuelle ne passe plus à l’échelle. Les tests automatisés détectent des problèmes que vous ne repéreriez jamais à la main.
Les tests automatisés prennent deux formes : la première est le test unitaire, qui se concentre sur le test d’un seul élément du package à la fois, généralement une fonction d’une classe. La seconde est le test d’intégration, qui teste plusieurs éléments du package ensemble, comme plusieurs fonctions s’exécutant dans un ordre attendu.
Venant d’un background non-informatique et travaillant davantage sur la modélisation ML d’un système d’IA, j’avais du mal à comprendre pourquoi ces tests étaient importants et pas juste un fardeau à développer en plus du dépôt. D’anciens collègues (Frédéric James, Laurent Boucaud) m’ont montré la voie en illustrant que ces tests devraient être vus comme de la documentation pour votre projet, pas comme une couche superficielle à ajouter pour le fun.
Dans ce contexte, les tests devraient être vus comme :
- Tests unitaires : ils vous montrent comment chaque fonction/classe se comporte dans des situations/données fictives
- Tests d’intégration : ils vous montrent comment chaque bloc se comporte ensemble dans des scénarios développés par le créateur du package, ils vous présentent donc la portée du package et les scénarios attendus
Cela rend l’onboarding sur un projet beaucoup plus facile car la vraie documentation peut se concentrer sur le dessin d’une vue d’ensemble du projet, tandis que les tests servent de spécification détaillée et exécutable des composants individuels (tests unitaires) et de leurs interactions (tests d’intégration).
Ces tests automatisés peuvent être réalisés de la manière standard en utilisant unittest, mais l’une des solutions les plus populaires est pytest et c’est celle que j’utilise pour ce projet (avec une extension pytest-cov).
Tout le code de test peut être trouvé dans le dossier tests/ avec un dossier pour les tests unitaires et l’autre pour les tests d’intégration.
Si vous regardez de plus près l’organisation du code, vous remarquerez que dans les tests unitaires les dossiers imitent l’organisation du code dans le dossier src, car vous voulez tester tous les composants, tandis que l’intégration est structurée autour de divers ensembles de tests couvrant différents scénarios comme la reproductibilité d’une partie, le logging d’une partie, etc.
Jetez un œil au dépôt pour voir comment le code est structuré dans les deux cas, mais ce que vous devez garder à l’esprit c’est qu’en fin de compte vous voulez des assertions qui valident la sortie de la fonction ou de la série de fonctions testées dans un scénario. Voici quelques exemples de base extraits du dossier tests.
Je n’approfondirai pas la conception des tests ici, mais jetez un œil aux packages populaires et leurs suites de tests comme scikit-learn, numpy ou pandas, pour mieux comprendre ce que vous pourriez mettre en place selon votre cas d’usage.
La suite naturelle : quand dois-je arrêter d’ajouter des tests ? Jamais — ou plus précisément, seulement quand le package est figé en termes de systèmes d’exploitation et/ou de versions Python et/ou de fonctionnalités.
L’important c’est que vous devriez couvrir toutes les fonctions possibles de votre package et ajouter de nouveaux scénarios basés sur l’utilisation en temps réel et les bugs que vous rencontrez. Vous n’aurez pas tous les tests d’emblée, c’est un travail continu.
Exécuter pytest depuis la ligne de commande avec quelques options supplémentaires vous donne des rapports de couverture et un contrôle précis.
La deuxième option est plus détaillée car elle retourne une vue plus détaillée de comment les tests couvrent le code dans les différents fichiers. C’est plus pratique, et la troisième variante (avec --cov-fail-under) ajoute un seuil de couverture minimum. Si le seuil n’est pas atteint, le pipeline échoue.
Dans la configuration du packaging, pyproject.toml gère également les outils de test via des sections spécifiques :
- Section [project.optional-dependencies] avec une sous-section dev : donne la possibilité d’ajouter des dépendances supplémentaires à d’autres fins comme les tests ou les nouvelles fonctionnalités en développement
- Section [tool.pytest.ini_options] qui contiendra une configuration pour exécuter pytest, dans ce cas s’exécutera avec des conditions spécifiques
Avec les tests en place, couvrons les contrôles de qualité restants : formatage, documentation et sécurité.
Linting, documentation & audit des dépendances
Au-delà des tests, quelques choses sont souvent négligées : le formatage et le linting du code, la documentation et la sécurité des dépendances.
En Python, il existe des directives sur l’apparence du code en termes de longueur de ligne, complexité cyclomatique et formatage. Le guide de style le plus largement adopté est PEP 8. Pour aider les développeurs à le respecter, il existe des outils appelés linters et formateurs qui analysent le dépôt et signalent le code non conforme.
Le plus populaire est ruff, et les vérifications sont assez simples à configurer dans votre environnement de développement :
Les deux commandes retourneront un rapport sur la conformité du code avec les règles, pour que vous puissiez appliquer les changements nécessaires.
Avec un code propre et testé, la dernière étape est la documentation. Plutôt que de tout écrire manuellement, sphinx peut auto-générer la documentation de référence de l’API directement depuis les docstrings déjà dans votre code :
sphinx-build -W -b html docs/ docs/_build/html
Cette seule commande construit la documentation HTML complète. La sortie est pilotée par trois éléments dans votre dossier docs/ :
index.rst: le point d’entrée qui organise la navigationapi/: la référence API auto-générée, construite depuis toutes vos docstringsguides/: fichiers markdown écrits à la main pour des explications de plus haut niveau qui nécessitent plus de contexte qu’une docstring peut fournir
Cela garde tout au même endroit et réutilise le code que vous avez déjà écrit. Pour héberger la documentation HTML, l’option la plus populaire est readthedocs.io, bien que GitHub Pages ou des services similaires de votre hébergeur de dépôt fonctionnent tout aussi bien.
Une dernière chose : puisque votre package repose sur des bibliothèques tierces, il vaut la peine de vérifier qu’aucune d’entre elles ne contient de vulnérabilités connues. pip-audit fait exactement ça en une commande.
Un autre outil utile à avoir dans sa boîte à outils est vulture, qui analyse votre dépôt à la recherche de code mort — fonctions, classes, variables et imports non utilisés. Au fil des refactorisations, il est facile d’accumuler du code qui n’est jamais appelé. Vulture le détecte avant qu’il ne devienne de la dette technique.
Maintenant que tous les composants sont en place, voyons comment tout relier avec l’automatisation.
CI/CD
Exécuter toutes ces vérifications manuellement à chaque fois que vous poussez du nouveau code n’est pas réaliste. C’est là qu’intervient le CI/CD.
Le CI/CD automatise le chemin du commit local à la release publiée, en exécutant toutes les vérifications en cours de route. Dans mon cas j’utilise GitHub Actions.
Le CI est défini dans un fichier YAML. Voici un extrait :
Le pipeline va plus loin que simplement exécuter les vérifications montrées ci-dessus. Après les étapes de format, lint et sécurité, il y a un test matriciel qui exécute la suite complète de tests contre Ubuntu, Windows et Mac pour Python 3.10 à 3.13, pour s’assurer que le package est multiplateforme et indépendant de la version.

Le CI/CD gère également la publication : un workflow séparé pousse une nouvelle release vers PyPI, et une étape dans le CI principal maintient la documentation à jour. Pour gérer les versions je m’appuie sur des tags git combinés avec bump-my-version, qui met à jour toutes les références de version dans le dépôt en une seule commande.
Les numéros de version suivent le versionnage sémantique : MAJOR pour les changements cassants, MINOR pour les nouvelles fonctionnalités rétrocompatibles, PATCH pour les corrections de bugs.
Terminons avec quelques points finaux à garder à l’esprit lors de l’écriture d’un package Python.
Badges, logging & hygiène Git
La première chose qui m’a frappé en parcourant des packages Python bien maintenus était la rangée de badges de statut montrant d’un coup d’œil si le CI est vert, quelles versions de Python sont supportées et quelle est la dernière release.
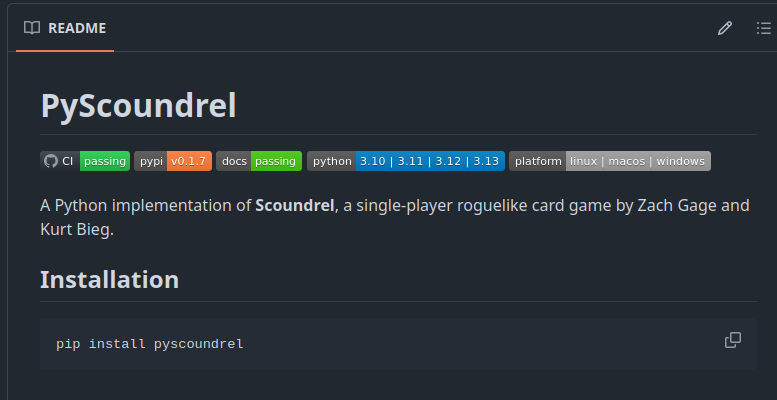
Les ajouter est simple : les badges CI, PyPI et docs tirent leur statut directement depuis les pipelines, tandis que les badges de version Python et de plateforme sont définis manuellement. Ce sont juste les bases, suffisantes pour donner à quiconque visitant le dépôt une lecture rapide de la santé du package et de la couverture OS/version.
Une question qui revient toujours : print ou logging ? Pour un package, utilisez toujours logging. Contrairement à print(), il vous donne des niveaux de sévérité (info, warning, error…), du contexte, et laisse l’appelant contrôler ce qui est affiché. print() a sa place, juste pas dans un package 😉.
Cet article a couvert les principaux outils, mais quelques fonctionnalités natives de git valent également la peine d’être connues : gitleaks pour attraper les secrets avant qu’ils n’atteignent le dépôt, et les git hooks et pre-commit pour automatiser les vérifications au moment du commit ou du push.
Enfin, quand devriez-vous vraiment vous embêter à packager plutôt que simplement partager un script ? Ma règle empirique se résume à trois questions :
- Réutilisation : utiliserez-vous ce code dans plusieurs projets ? Si oui, un package propre paie rapidement.
- Audience : le partagez-vous avec des personnes en dehors de votre équipe ? Un package versionné est beaucoup plus facile à distribuer que de re-partager des fichiers bruts à chaque changement.
- Contributeurs : d’autres personnes sont-elles impliquées ? Un package impose une structure et facilite l’onboarding.
Conclusion & prochaines étapes
C’est ma vision de la configuration minimale viable pour un package Python. Les développeurs expérimentés auront certainement plus à ajouter, mais j’espère que ça donne à quiconque commence un point de départ pratique.
Du côté de l’assistant IA : Claude a été un vrai contributeur à ce projet, gérant la majeure partie de la logique du jeu pendant que je me concentrais sur les tests et le déploiement. Il a fallu quelques itérations pour que la logique du jeu soit correcte, mais pour tout ce qui concerne les tests et le CI, ces outils sont vraiment forts quand vous leur donnez des lignes directrices claires. La barre de ce qu’un développeur solo peut livrer a augmenté.
Je prévois de continuer à explorer le packaging Python à travers le travail open source en ravivant d’anciens projets comme pysuika et en expérimentant avec de nouveaux comme folio.
Merci pour votre lecture et n’hésitez pas à me contacter si vous avez des questions.
Références
Le jeu
- Scoundrel — règles originales (PDF) — Zach Gage & Kurt Bieg
- Scoundrel Solitaire — Steam
- Scoundrel — itch.io
- benjamin-t-brown/scoundrel — GitHub
- marcs-sus/scoundrel-cardgame — GitHub
- Lizzard1123/scoundrel — GitHub
Packaging Python
- Choisir une licence — choosealicense.com
- Guide de l’utilisateur du packaging Python — Documentation PyPA
- Tutoriel : packager des projets Python — Documentation PyPA
- PyPI — Python Package Index
- TestPyPI — Python Package Index (instance de test)
- twine — PyPI
Tests
- unittest — Documentation de la bibliothèque standard Python
- pytest — Documentation officielle
- pytest-cov — PyPI
- Suite de tests scikit-learn — GitHub
- Suite de tests numpy — GitHub
- Suite de tests pandas — GitHub
Qualité du code & documentation
- PEP 8 — Guide de style pour le code Python — Python Enhancement Proposals
- ruff — GitHub
- Sphinx — Documentation officielle
- Read the Docs — Site officiel
- pip-audit — PyPI
- vulture — GitHub
- logging — Documentation de la bibliothèque standard Python
CI/CD & Git
- CI/CD — Wikipedia
- GitHub Actions — GitHub
- bump-my-version — PyPI
- Versionnage sémantique — semver.org
- gitleaks — GitHub
- Git Hooks — Documentation Git
- pre-commit — Site officiel
Autres outils
- rich — GitHub
Projet pyscoundrel
- pyscoundrel sur PyPI — PyPI
- pyproject.toml — GitHub
- tests/ — GitHub
- Workflow CI — GitHub
- Workflow de release — GitHub
Autres projets de l’auteur
- Suika Game — article sur les fondations — The Odd Dataguy
- pysuika — GitHub
- folio — GitHub