
In this article, there will be a description on the Recsys conference that happened in September 2020 virtually (Thanks Ubisoft to have offer me the ability to attend 😀). The content of this article is split between:
- Overview
- Papers selection
- Recsys challenge
Overview
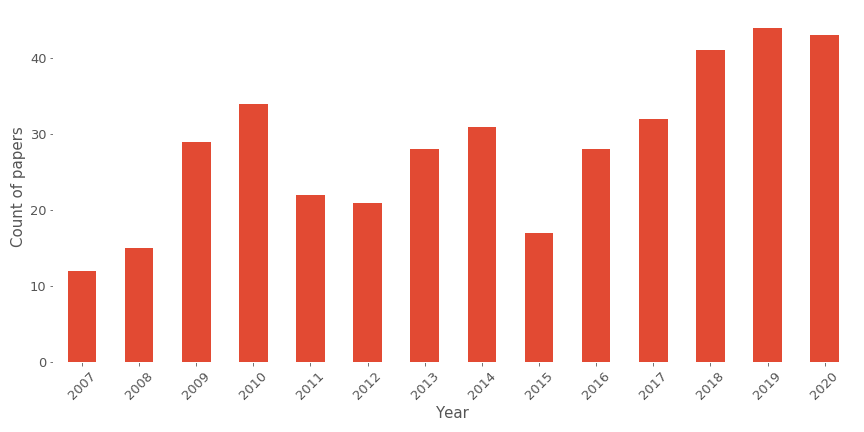
Recsys is part of the ACM(Association of computing machinery) conference and is defined as THE conference on recommender systems worldwide. Many big tech companies are sponsoring this kind of event from Netflix and Google, and generally, the location of the event is altering between Europe and America. For the 2020 edition, the conference should have happened in Brasil, but thanks to Covid, it switched to a virtual edition. The conference started in 2007, so this was the 14th edition.
The conference is kind of classic with a mix between long papers, short papers, posters, tutorials and workshops, and in terms of long papers acceptance, there is 21% of papers submitted that are selected.
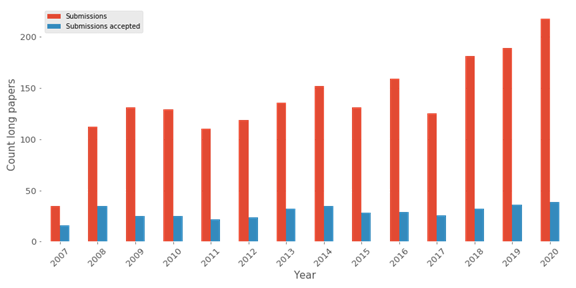
This figure gives a good vision of the gain of the conference’s popularity with an increase in the submissions. Still, overall if we are considering all the papers presented during this conference, there is an increase (cf next figure).
Every year the tracks on the conferences are evolving, and this year there is the main tracks presented:
- Real-world applications (III)
- Evaluating and explaining recommendations
- Novel machine learning approaches (III)
- Fairness filter bubbles ethical concern.
- Evaluation and unbiased recommendation
- Understanding and modelling approaches
The subjects are very different, but I like that they have real-world application tracks (with three sessions).
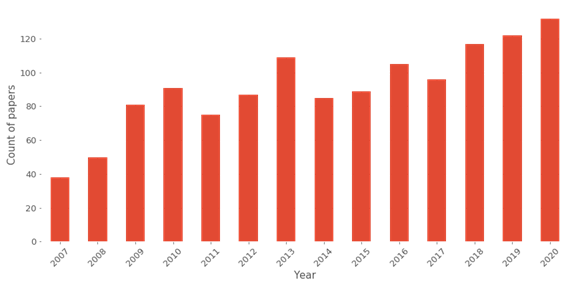
So as we can see in the graph, there are around 130 papers on the edition, I will now summarise all the papers, but there are selections of the papers that I am finding quite attractive.
Papers selection
I will just shoot on this section 9 apers that I find interesting and connected to others.
Behaviour-based Popularity Ranking on Amazon Video
This paper, written by Lakshmi Ramachandran of Amazon video, is a good illustration that the most popular item is an excellent approach to personalization, but let’s put that under steroids. The setup for Amazon video for people to navigate in the content is to use the search bar or the discovery section.

The paper’s idea is: Based on all our users’ interaction data and information related to the shows, how can we predict if the videos will be streams by people?

The predictor is built with a tree-based model. The interaction on the videos is weighted with the usage of the content’s upload date (the item features are essential in this context because Amazon is offering live sports content). Amazon did some experiments and found that its approach boosted the streaming of content and negatively impacted the platform’s non-streamable content.
Balancing Relevance and Discovery to Inspire Customers in the IKEA App
Another big trend in this recsys conference and the past talks was contextual bandit usage (and some RL approach in general) to make content recommendations (not directly related to monetization features of an app) displayed. Ikea makes the paper that is naming this section, and it’s a good illustration of the approach of a bandit for the recommendation of images displayed.

One of the challenges encountered by this approach is finding the balance between the recommendations’ relevancy versus discovering the content in the items that can be displayed. In the context of Ikea, it seems that the approach brings a good impact on the click with an increase of 20% against a classic collaborative filtering approach (why not, I am still intrigued by the stats because to make CF approach, you need at least one interaction versus bandit where we can display stuff randomly and the paper is kind of foggy so….).

From the lab to production: A case study of session-based recommendations in the home-improvement domain
This paper is one of the best articles of the conferences because it offers the point of view of real-world applications that I can encounter at Ubisoft; it has written by a company (relational AI) that I am presuming is doing ML consultancy for the Home Depot, and they try to build session-based recommender system based with a sequential model, it was the occasion to discover a lot of new models.
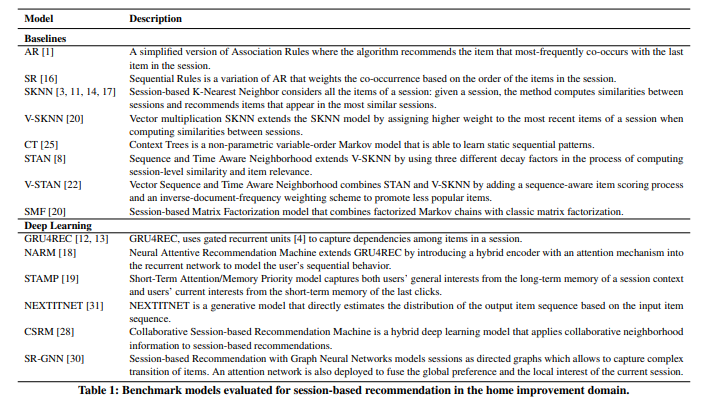
And I like their way to evaluate the model offline with the addition of human experts on it to see if the recommendations produced make sense and are good enough. A must-read if you want my opinion on it.
On Target Item Sampling in Offline Recommender System Evaluation
This paper offers a good question on evaluating the model offline by applying some filtering to predict the output. This situation can happen because, for some scalability issues/time constraints, you need to make some decisions, and this can happen. Rocío Cañamares that is one of the authors of the paper and presenter during the conference made a test on the movie ens and illustrated the impact of sampling the output to predict.
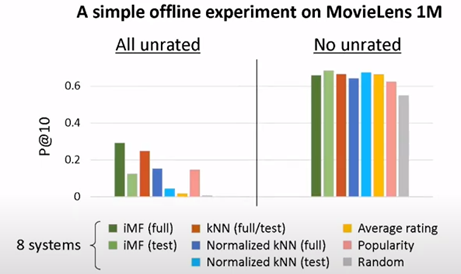
For me, the fact to reduce the pool of items will have a direct impact on the model (algorithms and parameters) but what I like about this article is the way to compare the effect of the dataset used for the training on all the models. They are using the Kendallscore to reach the leaderboard of the model versus the dataset (illustration of the dataset).
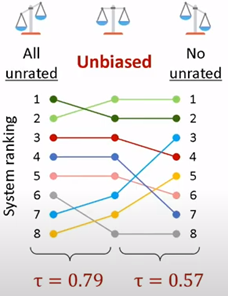
Another aspect of the evaluation of the model and their execution is for a specific interaction on the testing set; some traditional metrics are computed like the MAP@k or the NDCG@k on each record of the testing set, so the idea is to compare each model of the leaderboard how many toes there is on the records and the evaluation.
Are We Evaluating Rigorously? Benchmarking Recommendation for Reproducible Evaluation and Fair Comparison
As usual, at this conference, there is a lot of papers around evaluation, there is a quick study on the keywords in the documents and the ‘evaluat’ stem.
But this year, there is a good overview of the practice in various papers in different conferences from:
- The dataset

- the metrics

- The baseline model

- the dataset splitting
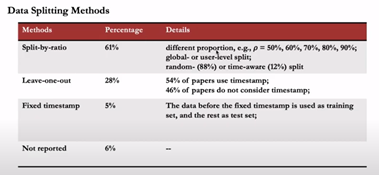
The paper is kind of a metanalysis on the way to evaluate and build a pipeline to benchmark models. One of the outputs is that sometimes these papers can be hard to reproduce, so that’s why Zhu sun and his teams that build this paper made a framework that can help make this evaluation daisyREC. Honestly, the second-best paper at the conference and even if on every iteration of the conference, some teams are doing the same thing to build an evaluation framework, but it’s always interesting.
Investigating Multimodal Features for Video Recommendations at Globoplay
This paper is fascinating because we are entering the paper with more R&D. The goal of this paper is made by a Globoplay’s team (kind like a big network in brazil, I call it the Brasilian canal+). They developed a recommender system for content (videos) based on content attributes.
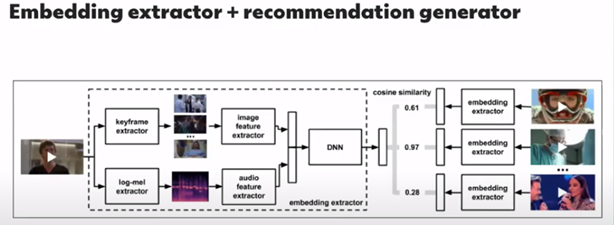
The idea is to analyze the video and audio of content to extract some features of the content. They used two pre-trained models for the features extraction (c3d,sport1M for the video + VGG google audioset for the audio) to build this features generator. An exciting aspect of the recommender’s test was to make the fake user interface to test the recommendations produced by the content creator and the user of the globoplay platform. The model seems to have been used, and it seems to have brought some improvement against the TF-IDF approach.

Quickshots
- The Embeddings that Came in From the Cold: Improving Vectors for New and Rare Products with Content-Based Inference
Still, the problem of cold-start like that has been tackle in the previous article, but how can we recommend items that are rare in a pool of objects? This team develop a project inspired by worod2vec cold prod2vec.

The model used behind is using metadata and popularity to build the recommendations, but what I like is the way to evaluate the recommendations (no need to find the exact items, but something close in terms of metadata is enough)
- Contextual and Sequential User Embeddings for Large-Scale Music Recommendation
In this paper on Spotify, there is another application of the next song’s sequence prediction to play based on the moment of the day and the type of device used.
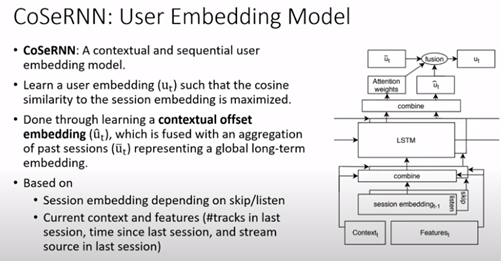
The model can generate user embeddings and is used in nearest neighbours’ searches.
- Neural Collaborative Filtering vs. Matrix Factorization Revisited
In this last paper of the selection, there is a comparison of the classic matrix factorization versus neural collaborative filtering to produce recommendations. It was interesting to compare how to compute the similarity function (dot product for MF versus MLP for NCF); MLP is seen as a solution to approximate all functions. Still, the MLP seems not to do a good job or need to be very complicated in our case.

The paper is not against the usage of NN in general, but it’s just highlighting that this technic that seems very popular is not so optimal, so used with caution.
Recsys challenges
Another significant component of the RecSys conference is a competition that is starting a few weeks ahead of the summit, but the winner is more or less crowned during this conference; there is a diagram from one of the hosts of the workshop around the challenge.
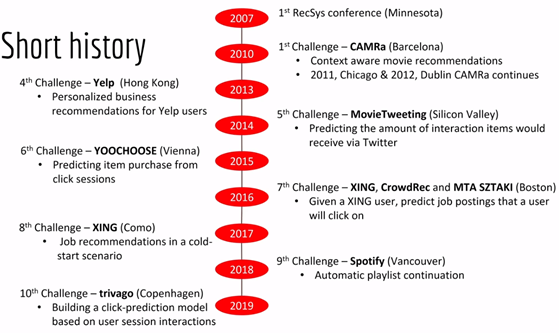
The format of this kind of competition is kind of a classic setup of a Kaggle competition. As you can see in terms of data providers for each competition, some big-name from Yelp, Spotify, and recently, Twitter was the data provider.
A brief description of the past competition setup shows an excellent article from one of the organizers on the problem to be solved and the winning solutions. But I will still do a quick summary of the challenge and some key finding:
- Competitions: predict for a specific user if it will engage (retweet, reply or like) with a tweet based on his Twitter profile (reader), the Twitter profile of the author
- The winning solution is some “GPU porn” with Nvidia cool suite rapids, based on xgboost and top features engineering (I need to write an article on these libraries)
- Deep learning seems to not perform well in comparison to the Nvidia solution.
- An excellent approach to evaluate his dataset and his features is to use adversarial validation to avoid overfitting.
I am super impressed by the solutions developed I will invite to have a look on the top3 solution in the Twitter article but there is still something to keep in mind that this approach is maybe not perfect for a live inference (need to respond in milliseconds) but always good knowledge that can be useful in a batch prediction context.
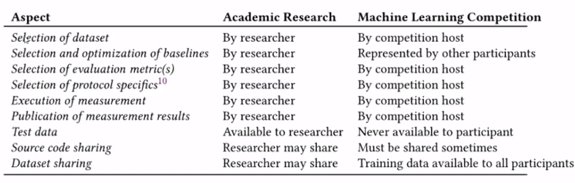
To conclude, deep learning (DL) technics don’t seem to perform well, and there was a discussion. So underperformance of these technics on challenge seems to come from:
- The format of the data used for this challenge is not aligned with what is needed for DL technics to perform well. Usually, a specific time window of data is used so it could impact the training.
- A second aspect is the hyperparameter optimization/ grid search; to do that with DL technics, it’s trickier than with classical technical. It takes more time, so this is maybe not aligned with a competition (Kaggle ?)
- And the difference of setup for a challenge competition and an academic paper could be another reason for underperformance (there is a representation of the difference of setups)
Conclusion
From this conference, there is plenty of exciting things that I keep in mind:
- Bandit and sequence approaches are taking some places.
- Video game applications were kind of shy this session (just one paper that was an echo of some paper on past conferences)
- There is plenty of new ideas to evaluate model during grid search (Kendall score) and dataset (adversarial validation)
- Kind of lack of papers on live experimentation results ( i can understand that can be difficult)
- The expert (someone not ML technical) in some projects seems to have an impact on the selection of the model by mockup fake UI
- Building a simulation environment to test RL and non RL approaches is a thing to do







{kind=link}