
In mid-November, the Apply(ops) 23 conference, organized by Tecton and Demetrios Brinkmann, took place. Usually, I write a one-page summary for my teammates to share learnings and good references, which I also post on LinkedIn. However, this time, I decided to write an article instead as I found the slides and speech full of good tips.
As the event was hosted by Tecton, there were live demos of their products and client feedback. I will not include these in my recap (though the content was valuable) because I want to keep my summary focused more on learning than on product demonstrations.
Journey of the AI platform at Uber (Uber)
Speaker: Min Cai, distinguished engineer of platform engineering, from his LinkedIn profile, seems to be the tech lead behind Michelangelo (the internal ML platform) and Horovod (a distributed deep learning framework, built on top of TensorFlow, PyTorch, etc.)*
The talk mainly focused on the origin and direction of the internal ML platform, Michelangelo. This platform seems to have inspired many companies, including Ubisoft ( I know i was there), to build their own ML stacks. They began working with ML in 2015 because they needed a system capable of making complex decisions in real-time (Uber has around 137 millions monthly active users in 10 000 cities), interacting with both real-world elements (like drivers, restaurants, shops, traffic) and digital elements. This quote captures their vision of machine learning.

They are closer to an Alphabet-like company than Netflix, but they still see that a centralized AI/ML platform can accelerate ML adoption.
They shared some examples of use cases, such as earner onboarding (setting up an account for a driver, restaurant, etc.), rides recommendation (vehicle and trips), and restaurant/food recommendation. They presented some numbers related to ML projects, including:
- Around 5.3k models in production
- 700 use cases deployed
- 10M peak predictions per second
In the first section of the talk, Min shared the evolution of the platform using a very informative diagram (the Y-axis represents the number of use cases).
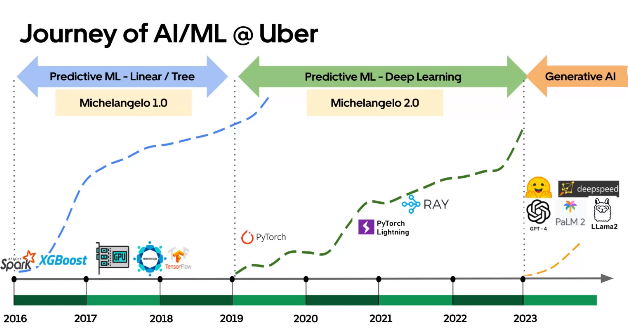
From the voiceover and the diagram, it seems that:
- Before 2019, deep learning was only used for self-driving car applications.
- There was a switch between two iterations of Michelangelo, but the two iterations overlapped for about 6 months.
- the switch to deep learning in 2019 comes from the fact that the tree model are good but to retrain it was challenging and not scalable (one model per city VS one model worldwide with deep learning)
- Their Gen AI section (in 2023) doesn’t seem to have been followed by Michelangelo (my understanding is that it’s still too early to build a new iteration).
Min also presented more details about the workflow on Michelangelo, focusing on the concepts of Canvas and Studio. There is an illustration showing what a canvas is:
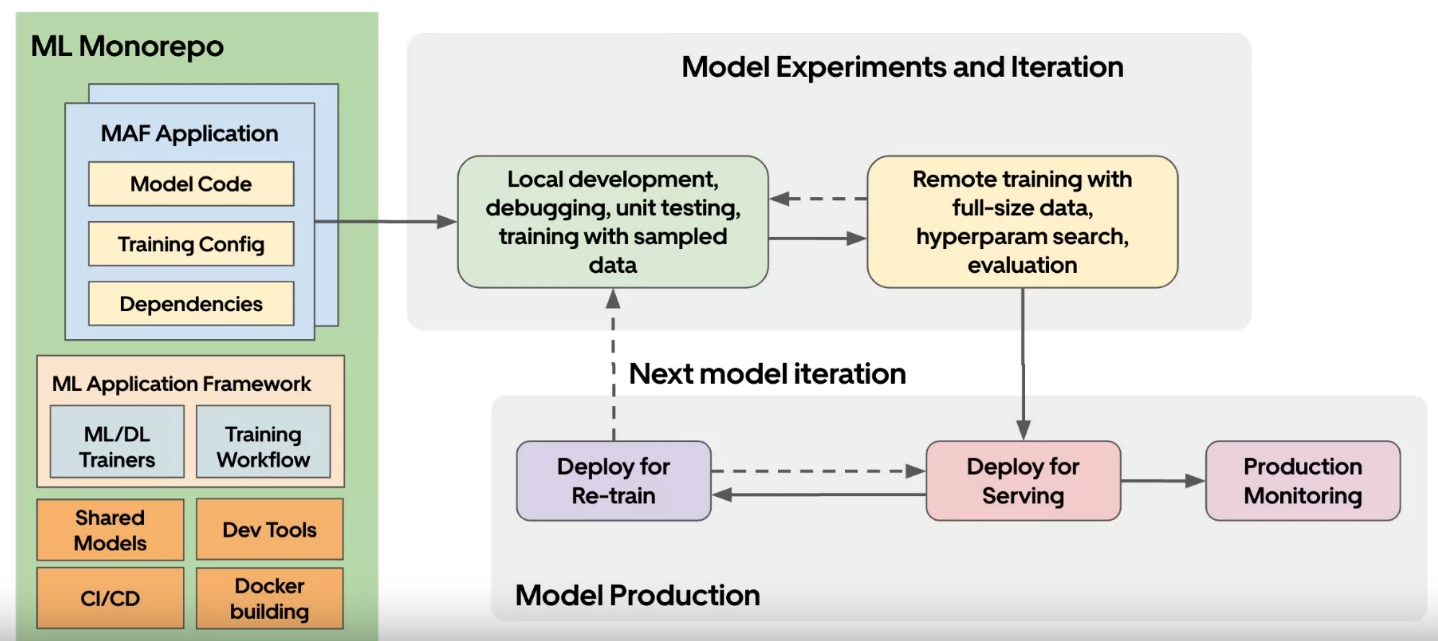
The canvas is the framework of an ML application. It connects the different parts of the platform and organizes the code that will run . This includes many configuration files and SDKs for using the platform. The Studio offers a more integrated UI/UX approach to doing ML on Michelangelo. It connects various UI components and the canvas. There’s an overview of the Studio’s flow with a look at the UI, which seems very simple (not sure how flexible it is to use)
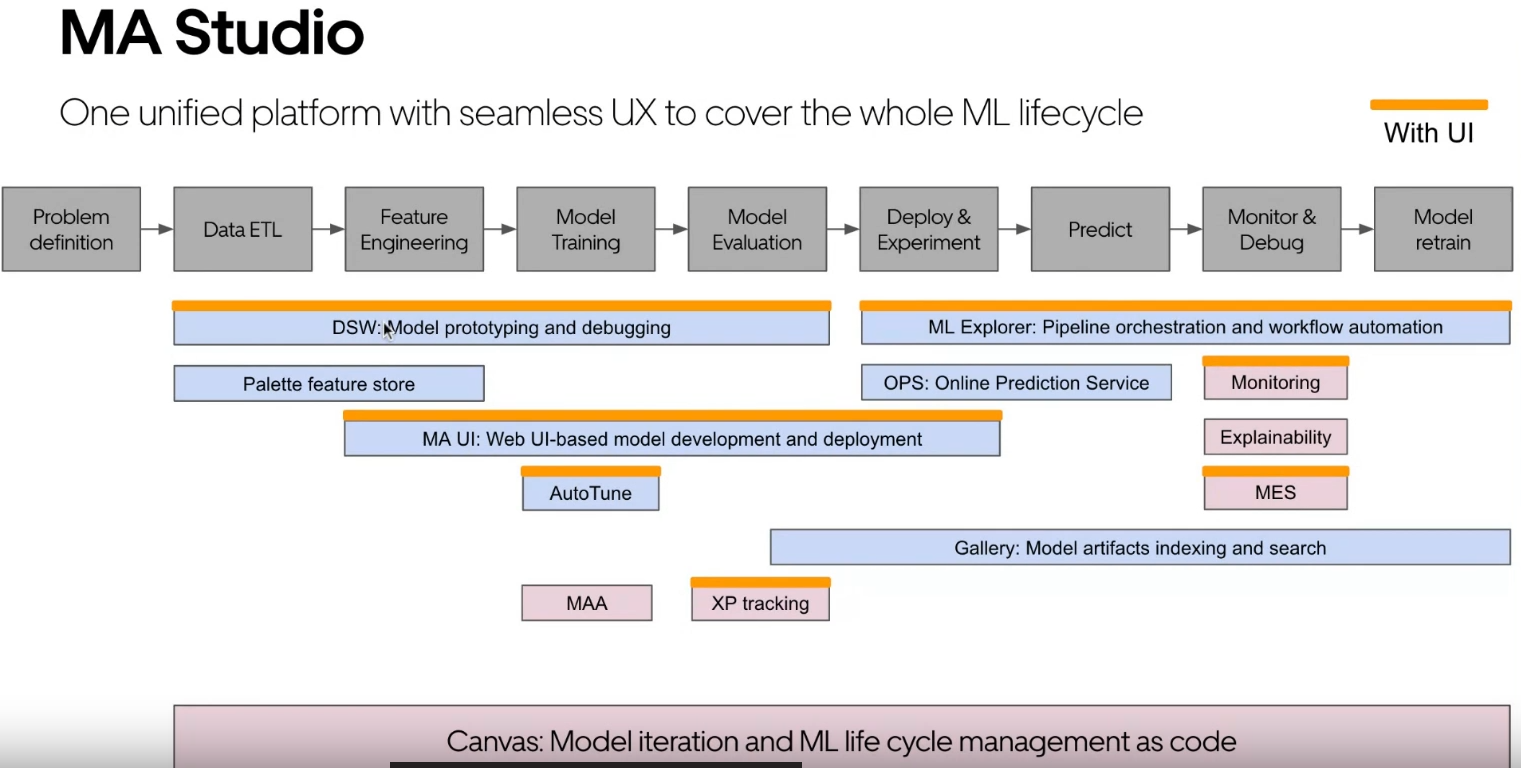
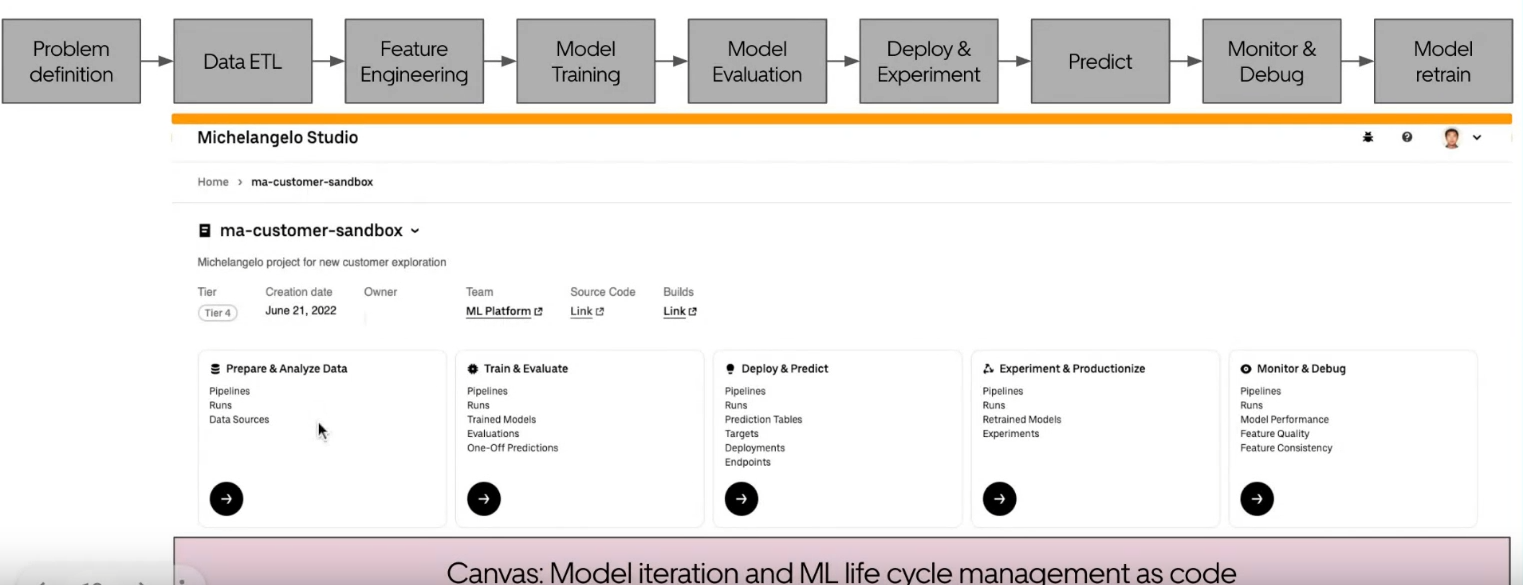
Finally, they talked about their vision for GenAI. It was not very clear (as it is in the whole company), but Min pointed out some interesting things in their slides:
- Use open-source models like LLama2 or Falcon.
- Also use private models like GPT-4 and Palm-2.
- They have begun integrating GenAI into their studio, including the concept of prompt engineering.
- The idea of a knowledge graph seems important in their vision.
- There is a map of Uber’s jobs (excluding earners) and the data sources impacted by GenAI.
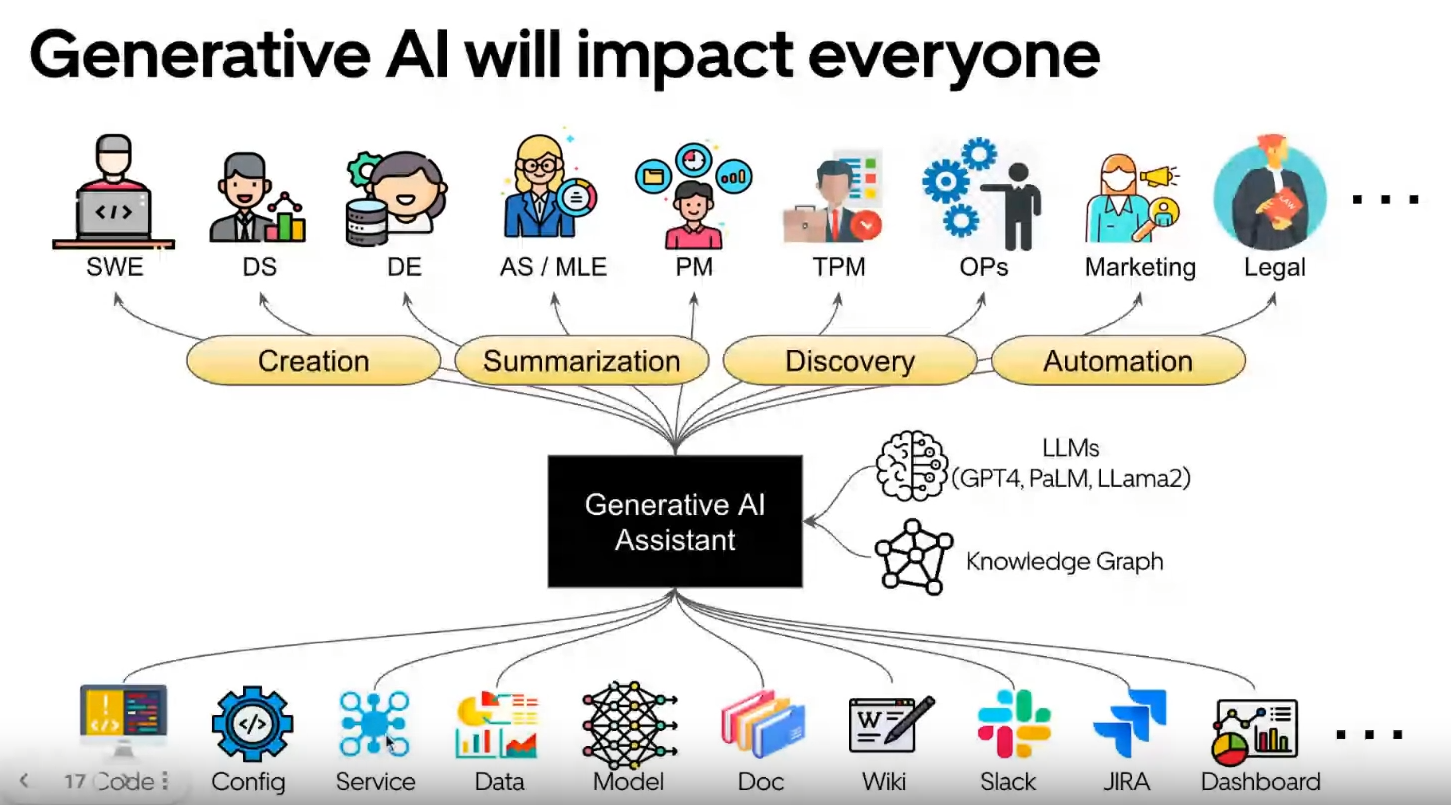
If you want to learn more about Uber’s vision, Min gave a great talk at the Scale 2023 conference (where most of this talk’s content is plus some extra content).
ML in a multi cloud environment (Lidl)
Speaker: Dr. Rebecca Taylor, who is currently the tech lead for personalization at Lidl, will discuss how to manage machine learning in a multi-cloud environment.
A multi-cloud environment is when you use more than one cloud service. It’s different from a hybrid cloud, which combines on-premises infrastructure with one cloud service. The hybrid cloud was popular about 10 years ago (😓 …).
The multi-cloud approach seems to be gaining popularity:
- Rebecca mentions that 65% of companies are in this situation, based on this 2014 source.
- I did some quick research to see if this trend has changed and found a 2023 survey from Hashicorp. It shows that 76% of the respondents use a multi-cloud setup.
The need for a multi-cloud approach can be due to historical and technical reasons (like in ML deployment, accessing specific services). There are pros and cons to going multi-cloud, which I’ve summarized in this table.

With this mindset of multi cloud it’s important to have good abstractions layer, and to have some considerations in mind when going a path to another:
- Having a good understanding of the business and ops constraints (latencies critical)
- Estimate the occurrences of certain actions (model training < features updates < model inference)
Rebecca took also some time to list different techs that can be interesting in a a multi cloud setup:
- terraform and opentofu for resource management
- kubernetes and kubeflow
- prometheus and Grafana for monitoring
- mlflow for model management and zen-ml
- Feast as a feature store (she invited to not build one but buy one)
- Kafka for open source messaging queue
She concluded his talk with an entreprise tech and highlight that databricks work well in a multi cloud setup, Tecton as an all in one feature store (that work with databricks, SnK etc) and Zenml cloud.
Building an MLOps Strategy at the World’s Largest Food Solutions Company (Hello Fresh)
Speakers:
- Benjamin Bertincourt, AI and ML engineering lead at Hello Fresh
- Michael Johnson, director AI and ML at Hello Fresh
Hello Fresh, a leader in the food/meal kit delivery industry, has a strong machine learning (ML) culture and openly shares it with the world. Erik Wildman (former Product Director at Hello Fresh) made an impressive presentation about their vision on MLOps a few months ago.
Returning to the conference, they seem to have a strong culture and shared some impressive figures about their ML achievements:
- They have one MLOps platform (there’s a small footnote that remind me something 😉).
- More than 2500 models trained weekly.
- 1506 features for 73 feature views.
- Over 65 data scientists/ML engineers supported.
Notes: Their platform for MLOps is built upon Databricks (with AWS) and Tecton for the feature store.It mainly supports offline predictions (batch manner) but they are also developing live inference use cases with SageMaker and Databricks endpoints (abstracted behind a layer for the user, as they should not worry about that).
The presentation emphasized the importance of building an MLOps platform in a company. It included a clear illustration of moving to production.
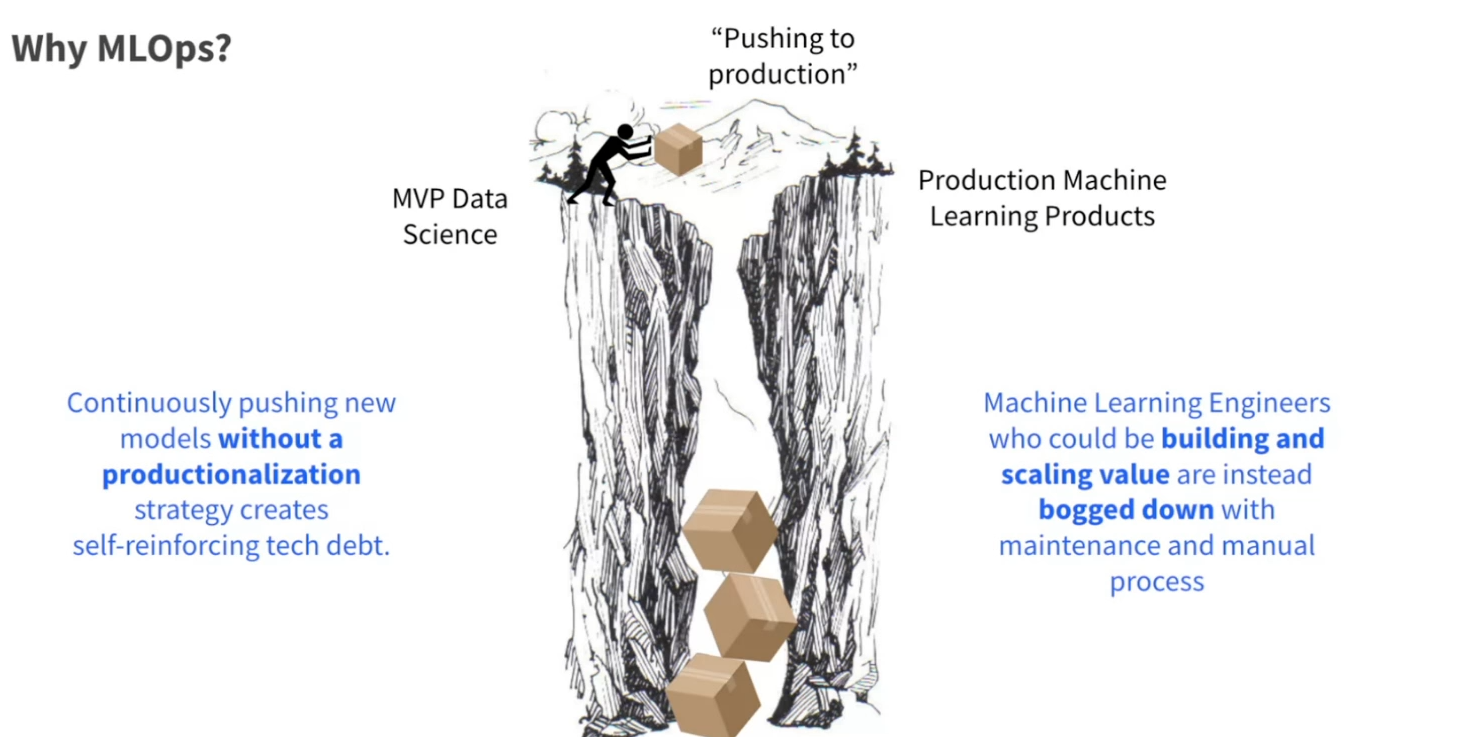
The reasons for adopting MLOps and a centralized solution are:
- Speed up time to production.
- Increase reusability.
- Lower maintenance costs.
- Reduce the need for extensive infrastructure skills.
- Focus on feature engineering and model selection in ML projects from a DS/MLE perspective.
- Automate 80% of standard processes, while making the remaining 20% easy to manage.
They shared insights about their approach in choosing elements for their stack.

They also outlined different layers in their stack, catering to various roles:
- Data Scientist: Offers a high-level API, focusing on speed and usability for easy experimentation.
- ML Engineer: Provides a low-level API, enabling fine-tuning of multiple parameters for model optimization.
- MLOps Engineer: Involves an integration layer, creating abstractions to align services and technologies with domain requirements.
Some interesting concepts were defined in the presentation:
- Makerspace VS Factory:
- Makerspace: Flexible, fast development requiring expertise to maintain.
- Factory: Scalable, fast deployment, easy to maintain but less flexible.
- Front and Back Office:
- Front Office: Delivers quickly with what is on top of the shelf, easy to use.
- Back Office: More flexible with a general set of tools available to support the front office.
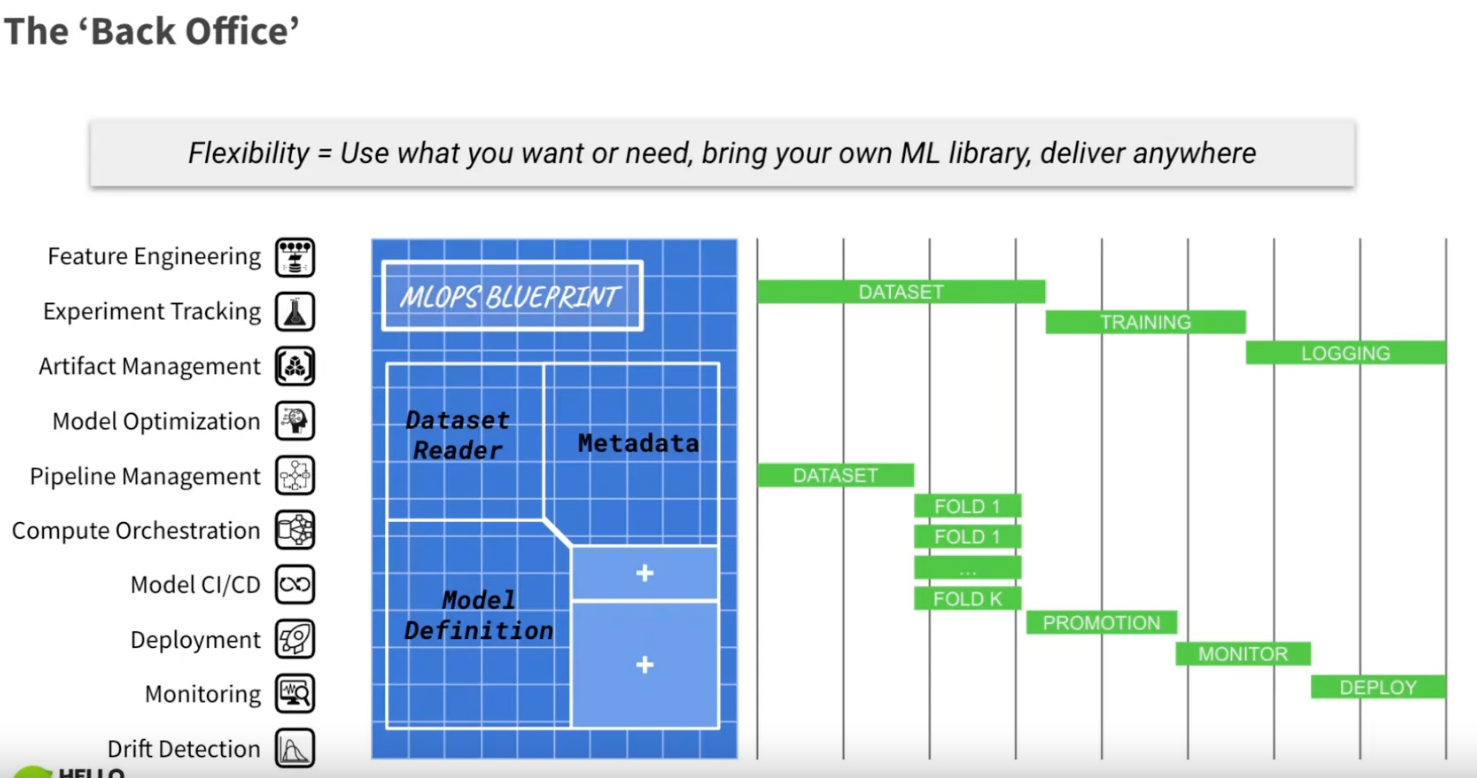
Notes: The definition of the MLOps blueprint for a model, composed of a dataset reader, some metadata, and model definition, is not new but good to see represented like it (and there is room to add new components).
Finally, they shared some key takeaways:
- Focus on data quality.
- Define a clear strategy and guiding principles.
- The technology part is not the most difficult aspect.
- Do hackathon (on real subjects) with data scientists/MLE to build your platform (to collect real needs)
LLMs, Real-Time, and Other Trends in the Production ML Space (Databricks/Tecton)
Disclaimer: This is a discussion between Ali Ghodsi co-founder and CEO of Databricks and Mike Del Balso co-founder and CEO of Tecton, so they are selling solutions that can be used to operate ML projects.
I collected a few interesting points from this discussion that I think are worth mentioning:
- Data platforms will be disrupted by AI: they need to be infused with machine learning, possibly leading to a complete rewrite with ML in mind.
- LLMs (Large Language Models) are causing significant UI/UX disruptions: Instead of clicking a specific button to do a job, why can’t we simply ask for what we want?
- AI will take over many areas: There was a notable discussion about AI assistance and its similarity to an airplane co-pilot:
- Why is there still a pilot in a plane? A system can be great at maintaining a certain course, but human supervision and skills are needed for some operations (and just by security).
- There are limits to LLMs: While they are good for certain tasks, for classical ML tasks like regression models, other methods are still better and more efficient.
- Build vs. Buy: The key quote of the talk was, “If you want to build it yourself, you need to sell it to customers.”
- The trend of in-house ML platform setups will likely fade away.
- Companies using open source tools may move away from this model in the future due to high costs (many contributors are employees), but it’s still a good way to scout potential employees.
- There was an interesting point about major innovations often not coming from the leading tech companies of the time, like the transition from IBM (computers) → Microsoft (OS) → Google (search engine) → OpenAI (LLMs) → ?
- It’s notable that the transformer architecture behind OpenAI’s GPT was originally developed by Google but remained largely unexploited.
- Advice for someone starting their career:
- Utilize generative AI and try to find areas where it could disrupt your job (because it likely will).
- Focus on creating intelligent software.
This chat was super interesting but keep the disclaimer of the beginning of the section.
Evolution of the Ads Ranking System at Pinterest (Pinterest)
Speakers: Aayush Mudgal, Senior Machine Learning Engineer at Pinterest (also a startup mentor in adtech and edtech)
This presentation focused on strategies to develop ML systems like the recommender system at Pinterest. ML touches many aspects of the application, affecting millions of users.

The billions of Pins pose challenges in the context of the recommender system. Aayush presented a timeline of their recommender system deployment.
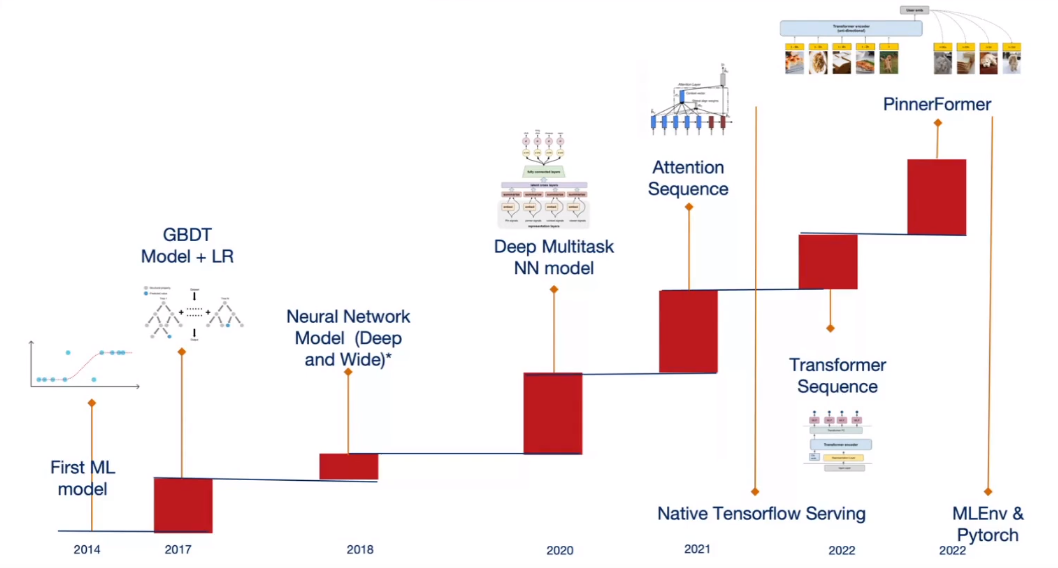
They started using their first model in 2014 (four years after Pinterest’s release), followed in 2017 by their first boosted trees and logistic regression. These models had to be converted to C++ for deployment.
After 2017, they explored using deep learning to address the problem that boosted tree and logistic regression models are hard to train (as they don’t support incremental training). They decided to switch to deep learning but had to work extensively on their stack to manage these models.
In 2020, they deployed their first multi-task model, followed in 2021/2022 by their attention/transformer-based model built on Tensorflow. In 2022, they released Pinnerformer (a transformer + multitask model, predicting user interactions with Pins), and also introduced a new environment based on Pytorch (caled Mlenv).
He also highlighted some pain points for an ML platform, like the difficulty in upgrading software and hardware, and the need for multiple expertise areas (like TensorFlow and PyTorch) to support users.
Their current platform insights include:
- A custom feature store with capabilities like shared features, backfilling, coverage, alerting, and a UI to track feature usage.
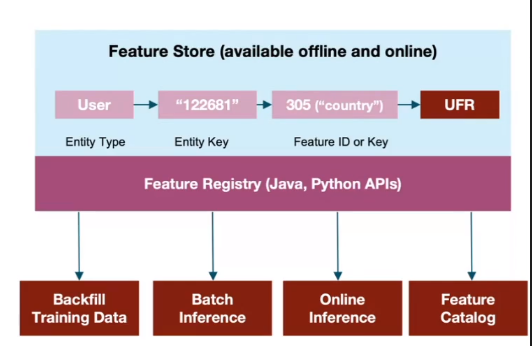
- Use of mlflow for model deployment (model registry + scorpion model server).
- An unified PyTorch-based ML framework called MLenv to simplify model operations, featuring building blocks, standardized MLOps integration, and CI/CD + Docker image as a service. This framework is used in 95% of training jobs.
- Templatized ML workflows: They created a system called EZflow that allows updating a pipeline by just modifying a config file (built on top of Airflow).
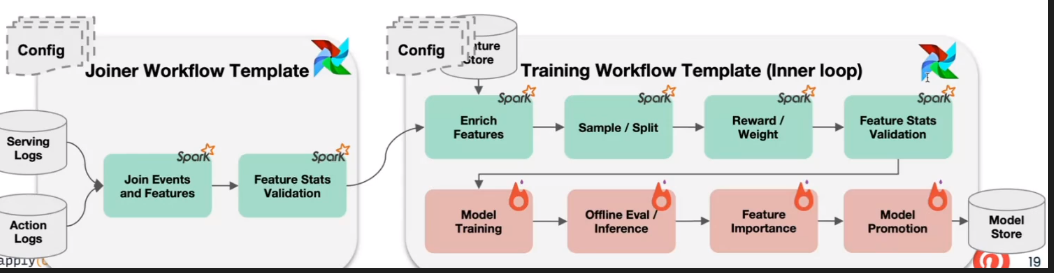
Statistics around their platform are impressive:
- 100s of PBs of training data.
- ~1500 workflow runs per day.
- ~3000 training jobs per day.
He also shared some challenges at Pinterest (that can slow the Ml deployment):
- Rapid changes in ML can quickly make templates obsolete.
- The need to know and maintain many languages and frameworks.
- Code reviews and meetings.
- Motto: Scale first and learn last
- Data ingestion for the model, similar to Netflix’s struggle (but Ray might help speed it up).
Panel: Production Machine Learning for Recsys: Challenges and Best Practices
Speakers: *This panel was moderated by Mihir Mathur from Tecton and included:
- Morena Bastiaansen, Data Scientist at Get Your Guide
- Christopher Addy, Head of Machine Learning Engineering, Generative AI Lab @ eCommerce at Pepsi Co
- Ian Schweer, Staff Software + Machine Learning Engineer at Riot Games
The panel focused on 4 topics: the scope of their recommendation systems, the tools used, the feedback loop of these systems, and the challenges in operating them.
==Scope of their recommendation systems==
- Morena (Get Your Guide):
- Focuses on optimizing the conversion rate and bookings per customer.
- Real-time serving of predictions (in-session behavior).
- Chris (Pepsi Co):
- Focuses on revenue, as potential gains in this metric justify switching to a new model in production.
- Live serving of their model.
- Ian (Riot):
- Focuses on improving the overall game experience (more play time) and ensuring good reception of game features by players (sentiment analysis on forum).
- Deploys their model (with around 100 features) in the game build
==Machine Learning tools==
- Morena (Get Your Guide):
- Use of Tecton Feature Store and Databricks: the feature store filters out previously seen recommendations and stores embeddings of product descriptions (produced by BERT, reduced with PCA).
- Spark for data processing and LGBM for the model.
- MLflow for model storage and versioning.
- Airflow to schedule jobs.
- Built their own experimentation framework.
- BentoML for model serving.
- Chris (Pepsi Co):
- Kubeflow for training their model (weekly, no real cold start problem).
- Simple API for serving in PepsiCo universe.
- Plans to use visual embeddings.
- Ian (Riot):
- Uses a lot of Spark.
- Using Databricks.
- Requiring conversion of model to C++.
👆 If you’re curious to learn more about Riot tech stack and the models they use (which are not typical in the MLops landscape), Ian made a great presentation at the Data Council a few months ago. 👇
==Feedback loop and challenges==
- Morena (Get Your Guide):
- Doing A/B testing is essential to evaluate the created model.
- Having low latency is important for live serving.
- Chris (Pepsi Co):
- The model creation is the easiest part.
- Managing internal politics to operate the model is the hardest part (you have to bring the biggest numbers).
- Being close to the users.
- Ian (Riot):
- Limiting the model’s memory in the game (so you cannot load all the trees of a random forest, for example).
- Build model prediction at the item level (and not a player) like for recommendation for champion gameplay
- Don’t break the game (as the model is built in, problems could occur, and fixes are more difficult).
Conclusion
This conference was full of knowledge, and I really wanted to focus on the essential learnings with some related resources. What was most impressive was the statistics about the ML platform usage in companies. I summarized that in this table (with some extrapolations):
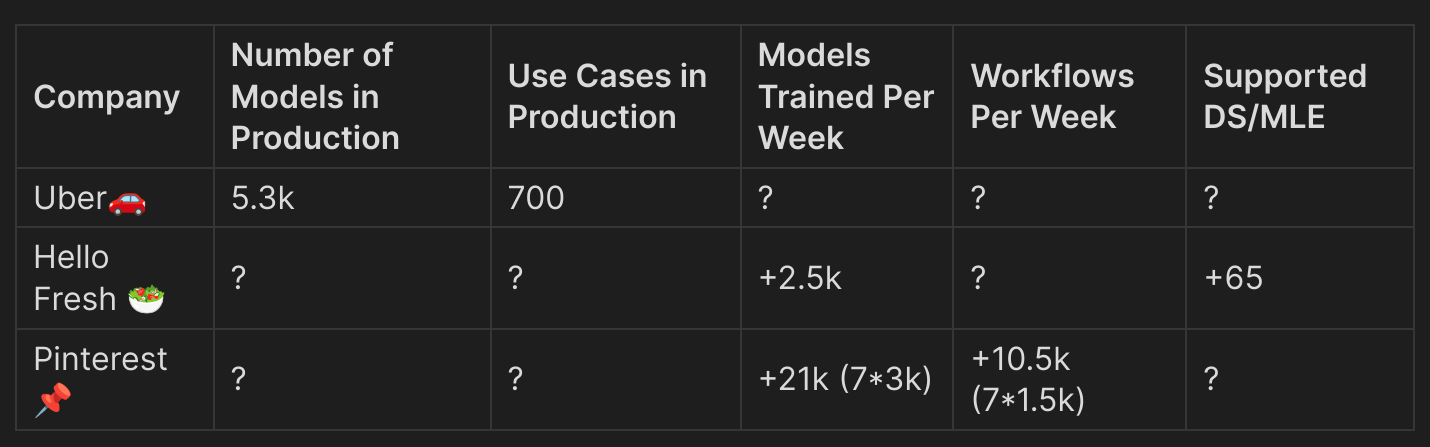
The number of models built and used is really impressive (if the numbers are accurate). I think this in a way illustrates how ML is democratized in their companies but It also raises the question of whether all these jobs are really necessary (but I guess it is but on my job I don’t see this kind of numbers😁).






%2023%20conference){kind=link}