
Over the past few months, I’ve been experimenting with speech-to-text technology, specifically applying OpenAI’s Whisper to transcribe podcasts. This article is a collection of those experiments, aimed at sharing key findings and practical insights that could benefit others in the field or those just beginning their journey in speech-to-text applications.
![]()
Context
So, I’ve had this idea for a few months to explore creating transcripts of various French podcasts that I listen to when doing tasks that don’t require too much focus. These include podcasts focused on writing and humor like the floodcast or un bon moment, and those about the entertainment industry like origami or realise sans trucage
These podcasts are very diverse in tone, humor, and content, but they are always a good source of recommendations for various content that can be interesting to discover. For example, I recently discovered:

- this game Mosa Lina

You might ask why I want to get the transcripts ? to make summaries ? Actually, the overall ideas are more around 2-3 things (ranging from okay to crazy):
- Create an engaging base of text (for me) to train my NLP techniques
- Leverage machine learning to automatically extract content recommended in my favorite podcasts
- Use LLM to create totally fictional episodes (as some might say, “C’est comme Black Mirror”)
The most interesting use case for me was definitely the second one. It comes from the fact that this work to store the recommendations can sometimes be done by the community, but at some point, the data source might stop being updated. I wanted to see if I could add some automation to the process that could be useful for me (and anyone who likes the content of these podcasts).
This work around transcript was also pretty align with a recent new feature of Spotify to propose a time synced display of the podcast transcript during a listening
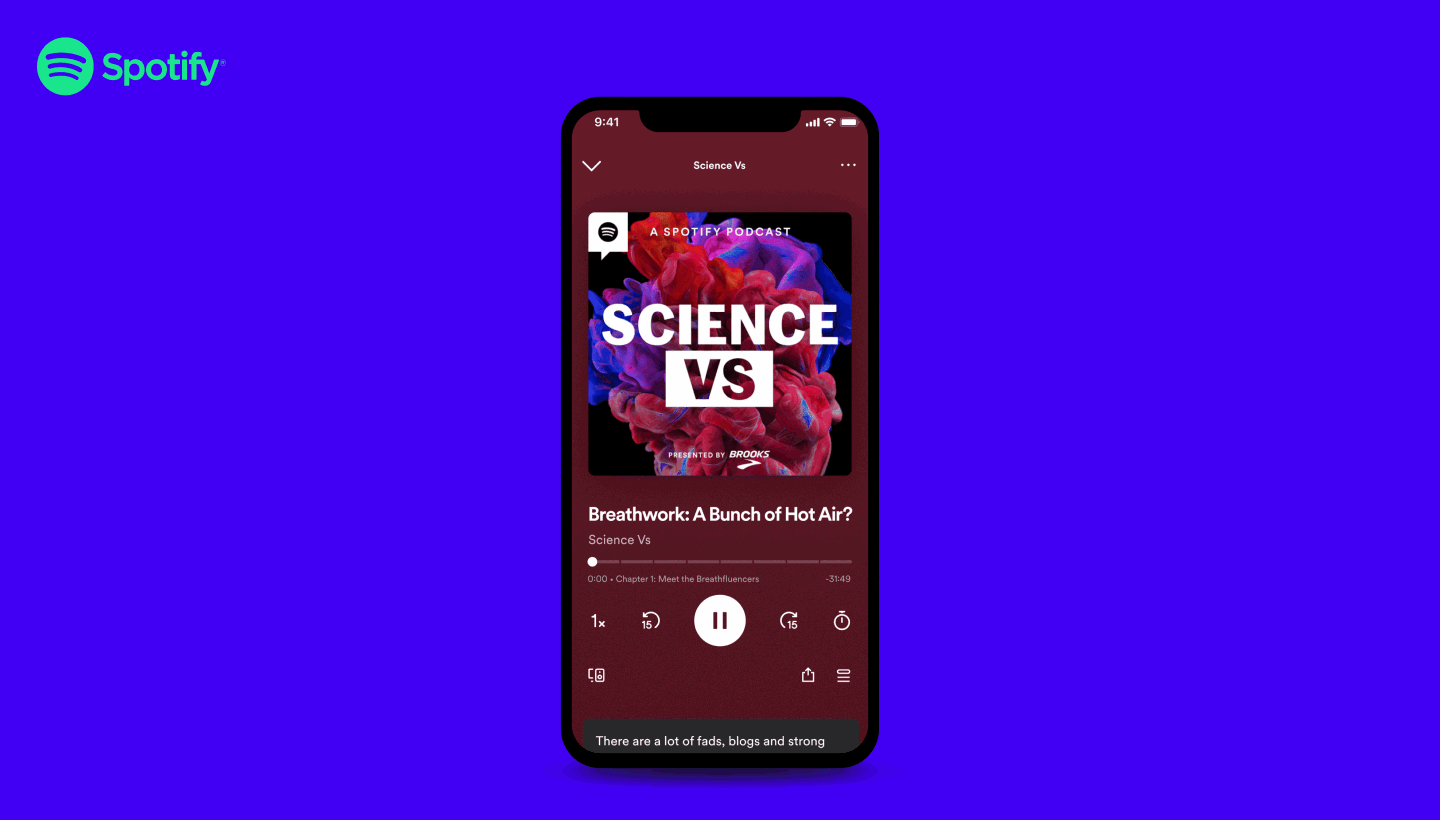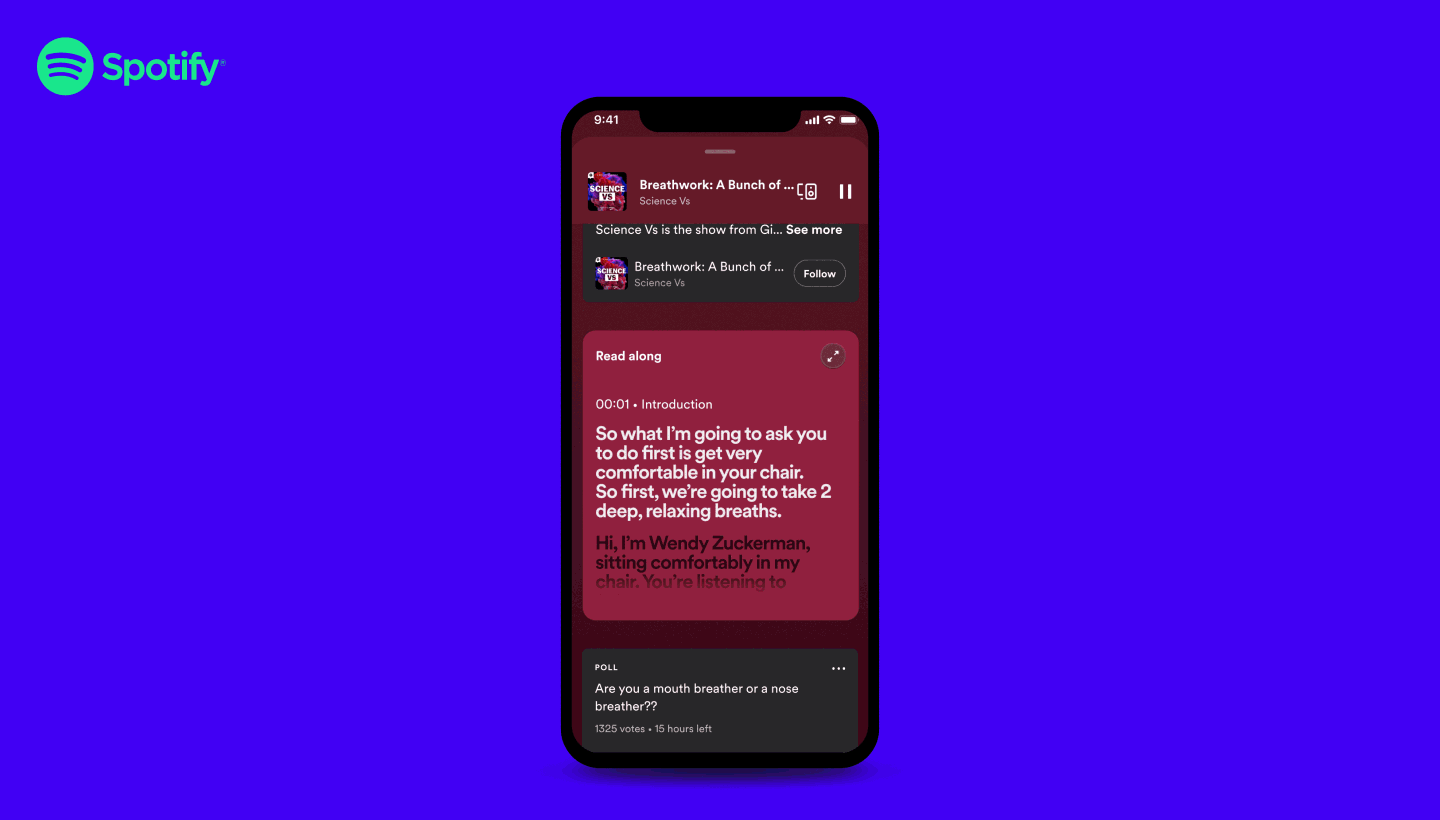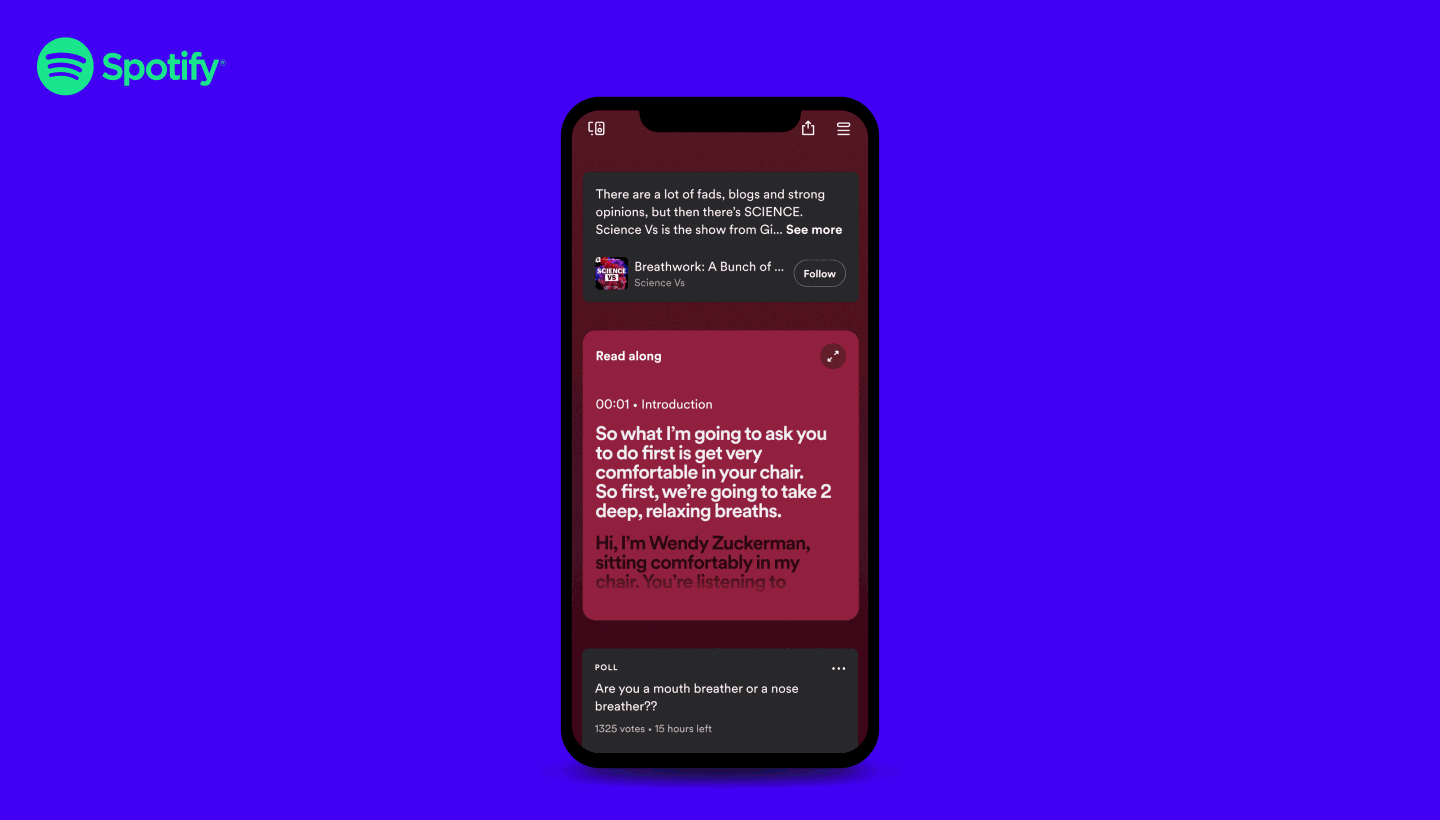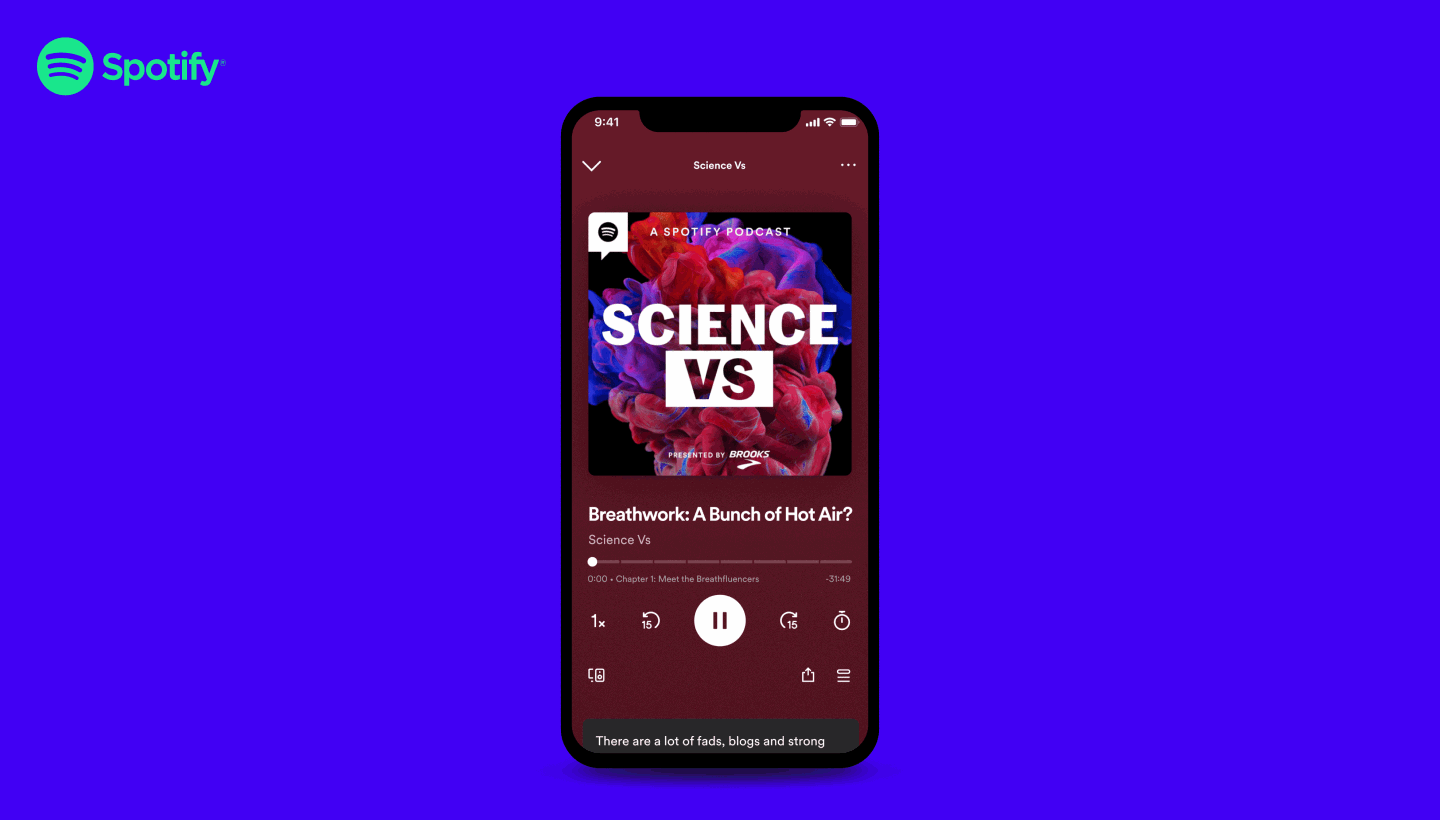
That’s is a pretty cool feature but not available automatically on all the podcast and you still need to be in the right setup to see the content display.
So now the question is , Where do i start ? and the first word that come to my mind is Whisper.
Whisper: What Is It?
Whisper is an automatic speech recognition (ASR) model from OpenAI. It aims to be a highly accurate, multilingual transcription tool. Whisper was trained using a huge dataset of about 680,000 hours of spoken audio. This audio is multilingual and comes from various sources on the web. The dataset’s diversity in languages, accents, and environments helps make the system robust and versatile. It can transcribe and translate many languages into English.
The technology behind Whisper involves an encoder-decoder Transformer. It works like this: the input audio is cut into 30-second pieces, turned into a log-Mel spectrogram, and then processed through an encoder. After that, a decoder takes over to predict the text caption. This process includes special tokens for different tasks. Here’s a quick overview of the process:
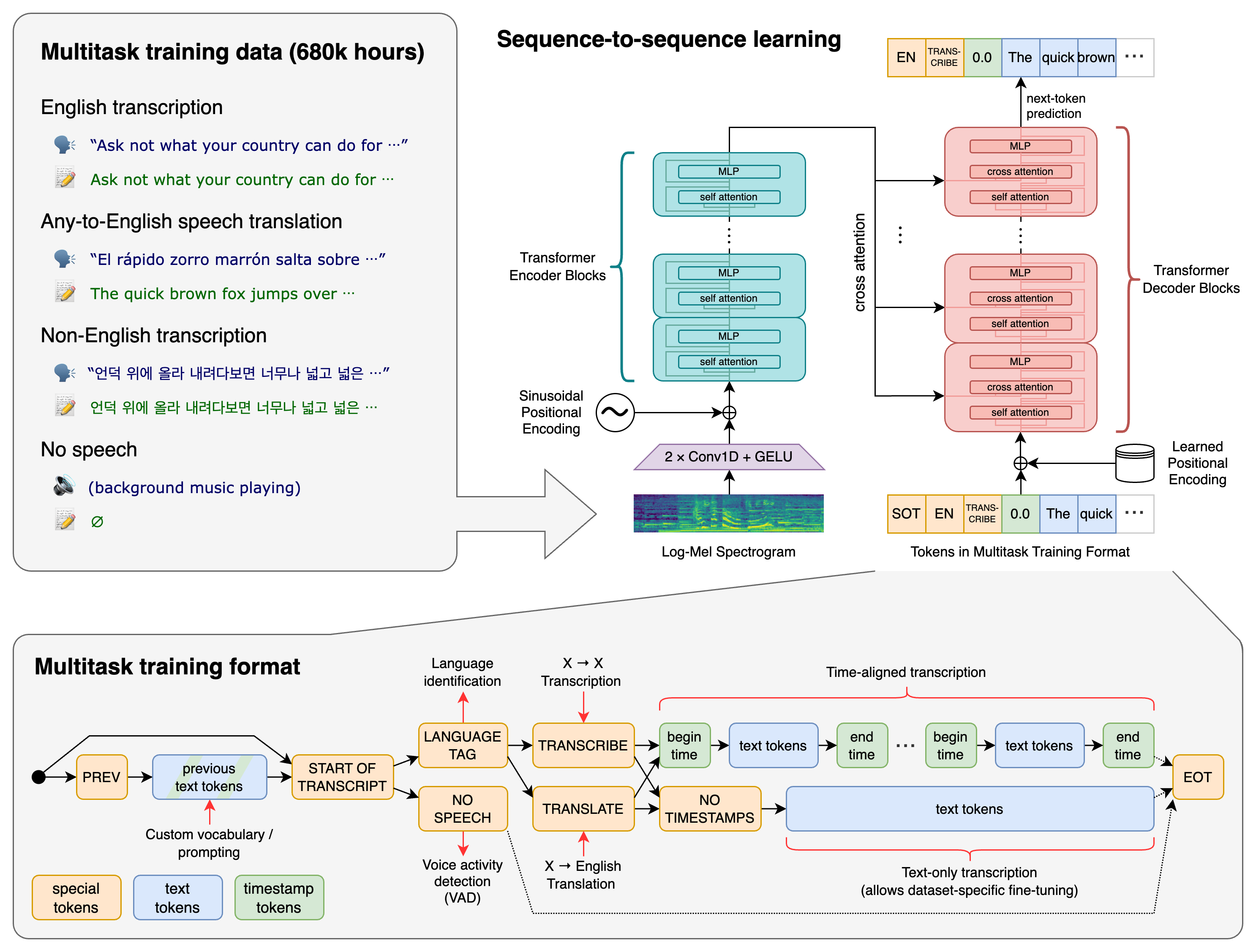
The model is available in sizes ranging from tiny to large and in different versions, there is also dedicated model for english you can find more details on the models in the model card HERE.

The latest is version 3 for the large size. This version added more frequency bins to the spectrogram and introduced a new language (cantonese). More details can be found in this GitHub discussion..
Whisper is quite popular, and there are many tutorials showing how to use the model in different ways to produce transcripts or translations to and from English. I was curious to try it out myself, especially in my French context but first I needed to see how to use this model.
Different Flavors of Whisper
To start my experiment, I wanted to explore the different ways to use Whisper, and there were many options.
Local Deployment
The first choices that came to mind were the OpenAI Python package and Hugging Face model usage. Both are easy to install with pip install and can run on CPU or GPU (which is recommended for this kind of model).
Disclaimer: My current setup for this test is a Dell XPS 9500 series with GeForce GTX 1650 Ti as a GPU. I had a rough experience setting up and using CUDA on this machine for this test, and I plan to write a small piece on this topic soon. :)
So, with this setup, how does the code look?
Local Whisper
Overall, the process is very straightforward, except for the step to get the log_mel_spectrogram (I tried the transcribe method of the model, but it didn’t work) before making the inference.
My current local setup doesn’t allow me to go beyond the base configuration.
Local Hugging Face Whisper
In this case, there might be slightly more configuration needed to set up the model, but the pipeline method of the Transformers package really simplifies future experiments by using the pipeline task automatic-speech-recognition to standardize the operation of this kind of model.
My current local setup doesn’t allow me to go beyond the medium configuration (which is a larger model than the official OpenAI package).
Now, let’s move on to cloud deployment.
Endpoint Deployment
In this scenario, you can easily deploy the same configuration on a larger machine and access the big models on Big GPUs. However, I wanted to explore the idea of having an easily accessible endpoint with the model operated on the side.
The most obvious choice for me was to use the endpoints from Hugging Face. There are two options: the Serverless Inference Endpoint (for quick prototyping) and the Dedicated Inference Endpoint (production-ready).
I chose the dedicated option because I wanted a more robust solution. It’s worth noting that Hugging Face also offers ways to deploy models via AWS SageMaker, and they recently partnered with Google Cloud.
Regarding the dedicated inference endpoint, if you’re interested in how to deploy models using Hugging Face’s endpoint, Abhishek Thakur’s tour is a great resource.
It presents the feature in detail for an LLM deployment. After deploying a model, you’ll find code snippets explaining how to use the freshly deployed model (as shown in the screenshot).
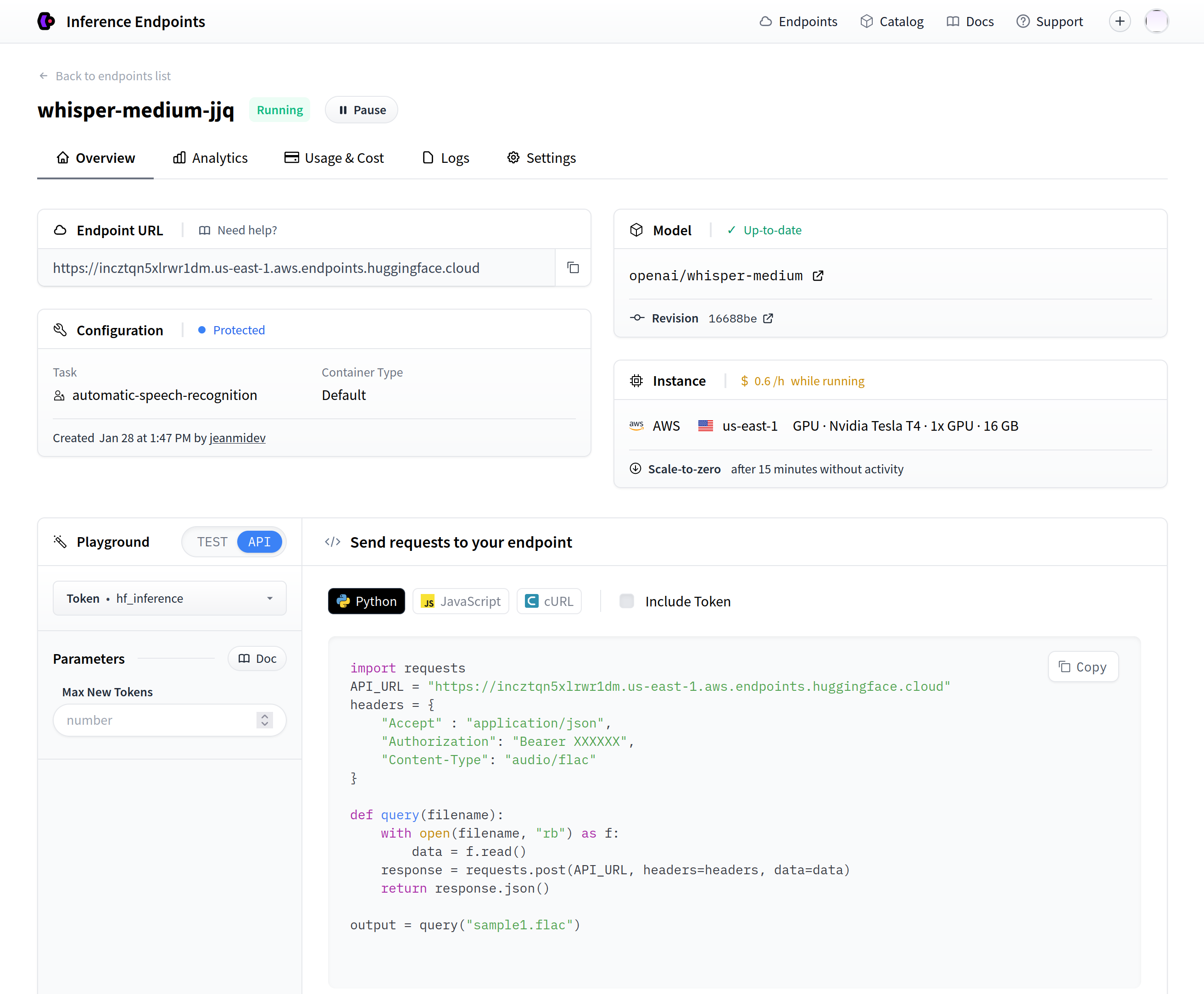
The API call to reach the endpoint is straightforward: just send the audio file’s bytes to the endpoint, and you’ll get the transcript (in the example, it’s a FLAC file, but MP3 files are also acceptable with the header "Content-Type": "audio/x-mpeg-3").
Notes: I am really impress by the overall UI/UX experience to serve model with the Hugging Face endpoint, it’s super clear with the right level of information to make test quickly (for any MLops enthusiast this is super exciting)
Setting up the model is simple, but this method doesn’t allow setting the language during inference. There’s no ability to set general kwargs like with the local Hugging Face setup (unless I missed something), so the returned transcript might not be in the expected language (it could be in English or another language based on the version).
This limitation is significant if you’re looking for an out-of-the-box solution, but there are alternative ways to make it work. For example, some Hugging Face members have fine-tuned Whisper for specific languages, like bofenghuang for French.
Now let’s look at the OpenAI API.
OpenAI API
To interact with the OpenAI API, I use the Python wrapper HERE for audio transcription with Whisper.
It’s important to note that the current API:
- Is limited to the whisper-1 model (likely the first version and the large multilingual one).
- Allows you to inject a prompt into the request to provide context for the transcription (great for continuing a transcript from a previous one or validating tone).
- Includes the concept of temperature (sampling temperature), where closer to 0 will be more deterministic and closer to 1 will be more random.
- Has a maximum file size of 25MB (compared to the 30-second limit in a local setup, so longer files are definitely a plus, but I’m curious about how they process larger files).
Let’s conclude with some alternatives for operating Whisper models.
Alternative paths to use Whisper
Earlier, when discussing the cloud Hugging Face endpoint, I mentioned people building fine-tuned models and open-sourcing them. I’d like to highlight some other implementations of Whisper.
In the local path, thanks to Wadie Benkirane from my team who follows the topic, there are two interesting packages:
- Whisper C++: This is an efficient implementation of Whisper’s weights behind a C++ API, ideal for quick results. It’s especially effective for live streaming of audio on limited devices (there’s a nice demo on a smartphone). I tried it out, and it’s great, but it seems you need to use FLAC files for local files.
- Faster-Whisper: Another C++/Python implementation using CTranslate2 that seems like an efficient way to enable transformer inference.
For the cloud path, I noticed two services:
- Deepgram offers excellent services around speech and voice treatment (similar to Whisper but not limited to it).
- Lemonfox.ai provides the ability to operate open-source models from GPT to Whisper-like models.
This list is not exhaustive, so stay tuned for more Whisper alternatives.
Now it’s time to experiment with all these solutions.
Experimentations
To experiment with podcasts, I decided to select three episodes from my podcast collection to test with Whisper.

My goal is to test how scalable the different flavors of Whisper can work, my context is very in a batch (offline!?) manner so no real time or small on demand needs but more process a few hours of podcast and to backload hundred of hours some time.
The experiment will first involve building segments for transcription and then exploring the generation of transcripts to compare:
- time to make an inference
- the quality of the transcription
- the cost of the inference
Process the Audio
The main tool for this audio processing is a Python package called Pydub. The package hasn’t been updated in a while (last commit was two years ago), but it’s still widely used and works well in 2024.
To process podcast audio, the simplest approach could be to cut the podcast into small chunks based on timestamps. However, I wanted to approach this more methodically. A podcast is not a song and usually has silences, so my process will be to divide the podcast into multiple chunks based on the presence of silence.
How to Detect Silence? Pydub has a method called silence.detect_silence that can process Pydub audio and return timestamps (in milliseconds) of segments without silence. This function has three parameters:
min_silence_len: Length of the silence in milliseconds, set to 1000 ms (1 second).silence_thresh: The upper bound for how quiet is silent in dBFS (decibels relative to full scale), set to -16 dBFS (based on some readings and tests).seek_step: Interaction scale set to 1 step/1ms (the default value).
With this approach, we can annotate the silences in podcast audio. Based on that, I decided to create segments of a specific length that should contain periods without silence. Here’s my function to build the timecodes related to a podcast episode based on the detected silence.
I applied this audio processing to create different versions of the timecodes based on the desired length of segments (with segments of 6, 15, 30 seconds and 1, 2, and 5 minutes).
Let’s move on to Whisper for the evaluation of the transcription.
Benchmark
In my experiment, I used segments of 21 to 27 seconds to align with the original Whisper paper (trained on 30-second chunks). The evaluation focused on the time to generate a transcript and the quality of predictions. Five segments from each file were selected for this evaluation, and each operation was executed 10 times for a reliable assessment of duration and transcription quality. The results, including transcriptions and audio files, can be found HERE.
My benchmark tested the following Whisper flavors:
- Tiny, base, and small local Whisper from OpenAI’s Python package on my local machine
- Tiny, base, small, and medium local Whisper from Hugging Face OpenAI weights on my local machine
- Medium Whisper fine-tuned for French (bofenghuan model), deployed on a dedicated endpoint on Hugging Face
- Medium, largeV2 and largeV3 Whisper from Hugging Face OpenAI weights, deployed on a dedicated endpoint on Hugging Face
- OpenAI Whisper API
So there is an overall comparison of the duration for the different flavors to make the inferences
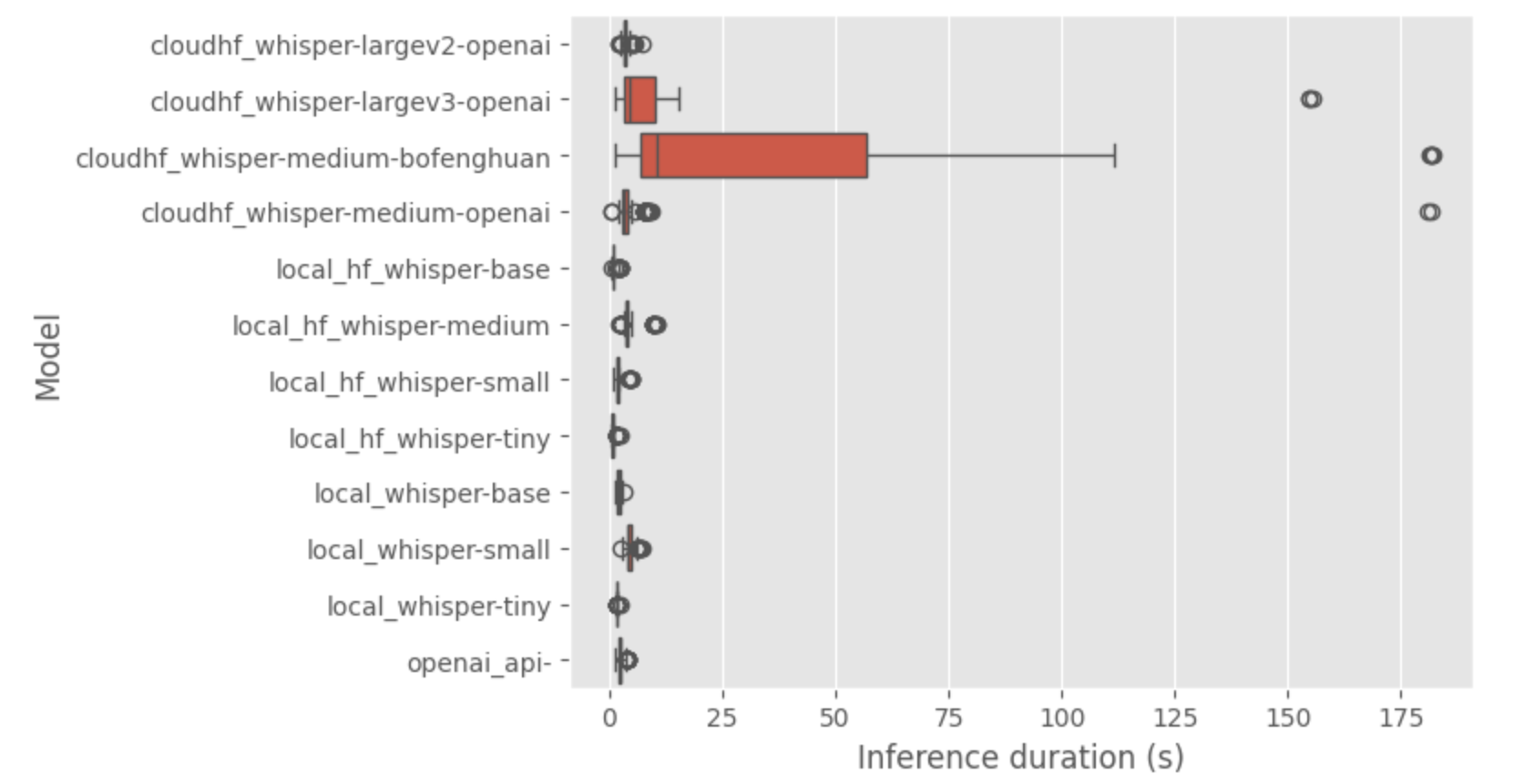
The most obvious observations are:
- the medium whisper fined tune model has a very long inference in general
- medium and large-v3 from openAI have a correct average inference time but there is some outliers (only coming in the endpoint of Hugging face weirdly some error). By looking on the transcript from these flavors, I noticed empty transcript so definetly these endpoints sometime are not responsive and that explain the outliers.
I will put a small red flag on the dedicated endpoint are they don’t seem to handle well batch processing like I am doing for this benchmark, I guess you will need to tweak the endpoint (and price) to better fit a production scenario.
Let’s zoom on the fastest models (without fliers for the HF endpoints).
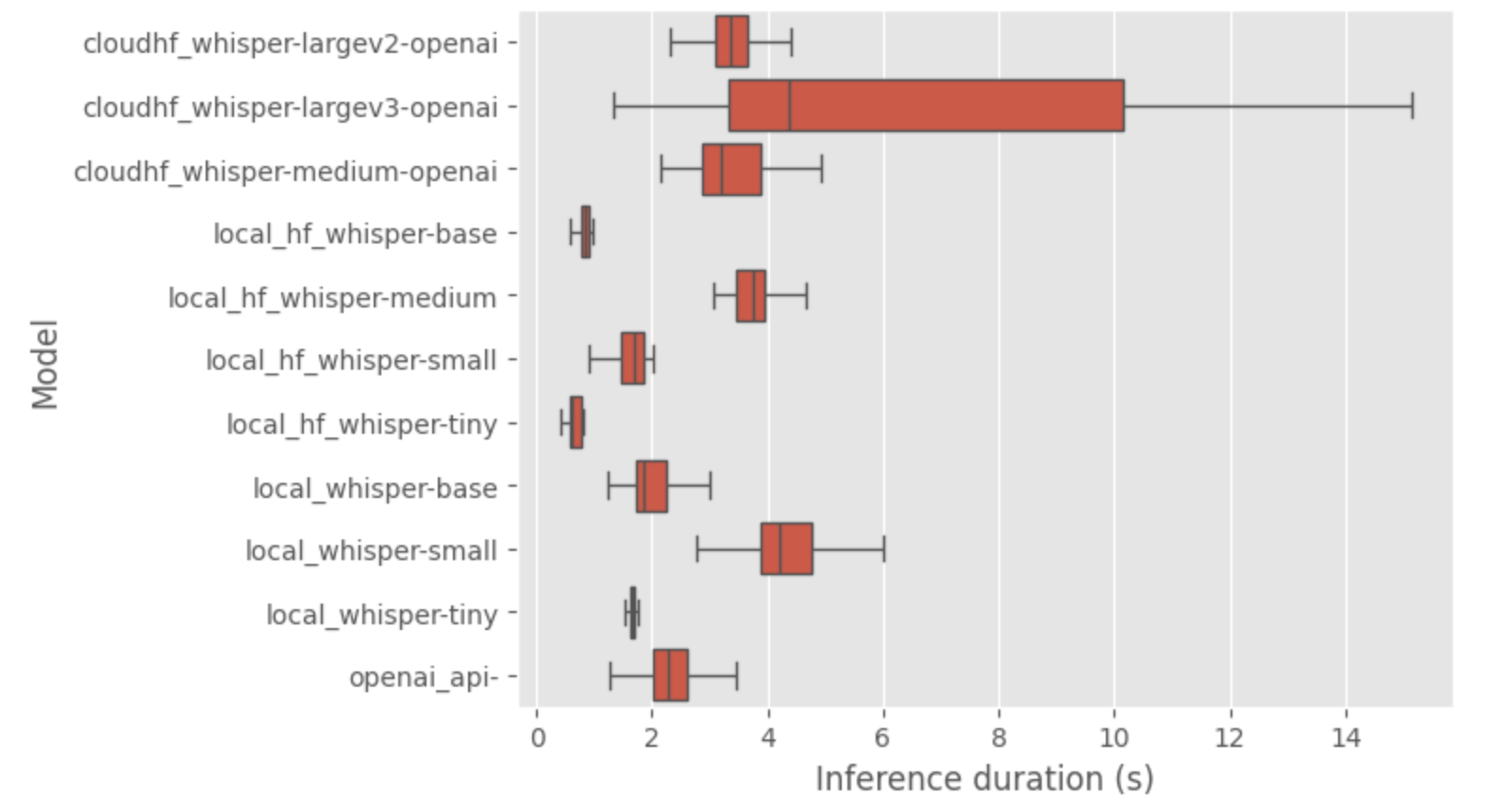
So from this analysison the inference times and transcript quality, I noticed:
- OpenAI large models showed good inference times.
- The quality of transcripts improved with larger models; the medium size is a good start for local deployment.
- The inference time from the local native whisper implementation are higher then on the hugging face one (I think my inference method is wrong)
- Repetitions in transcripts were noted (on small and large model transcript), aligning with known model limitations.
So that was my benchmark of the segment evaluation, once again if you are curious on the data and transcripts there is everything HERE so you can make your own opinion on the data produced.
Let’s evaluate now the computation cost.
Computation cost evaluation
The goal is to make an estimation of the good stack to operate whisper and make the production of transcript. So there is my current options for the evaluation:
- OpenAI API: No additional stack required, costs 0.006 $ per minute of transcription.
- Hugging Face Dedicated Endpoint: Nvidia Tesla T4 (1 GPU with 16GB VRAM), costs 0.6 $ per hour of uptime or (0.0002$ per second of uptime).
- AWS EC2 Instance: Nvidia Tesla T4, costs 0.53 c$ per hour of uptime or (0.00015$ per second of uptime).
- Local Setup (Focusing on the Graphics Card):
- NVIDIA GeForce RTX 4070 SUPER (12GB RAM) = $600.
- NVIDIA GeForce RTX 4080 (16GB RAM) = $1200.
So there is an estimation of the cost per hour of audio transcripted in the case we analyse the audio in a sequence 30 seconds at the time.
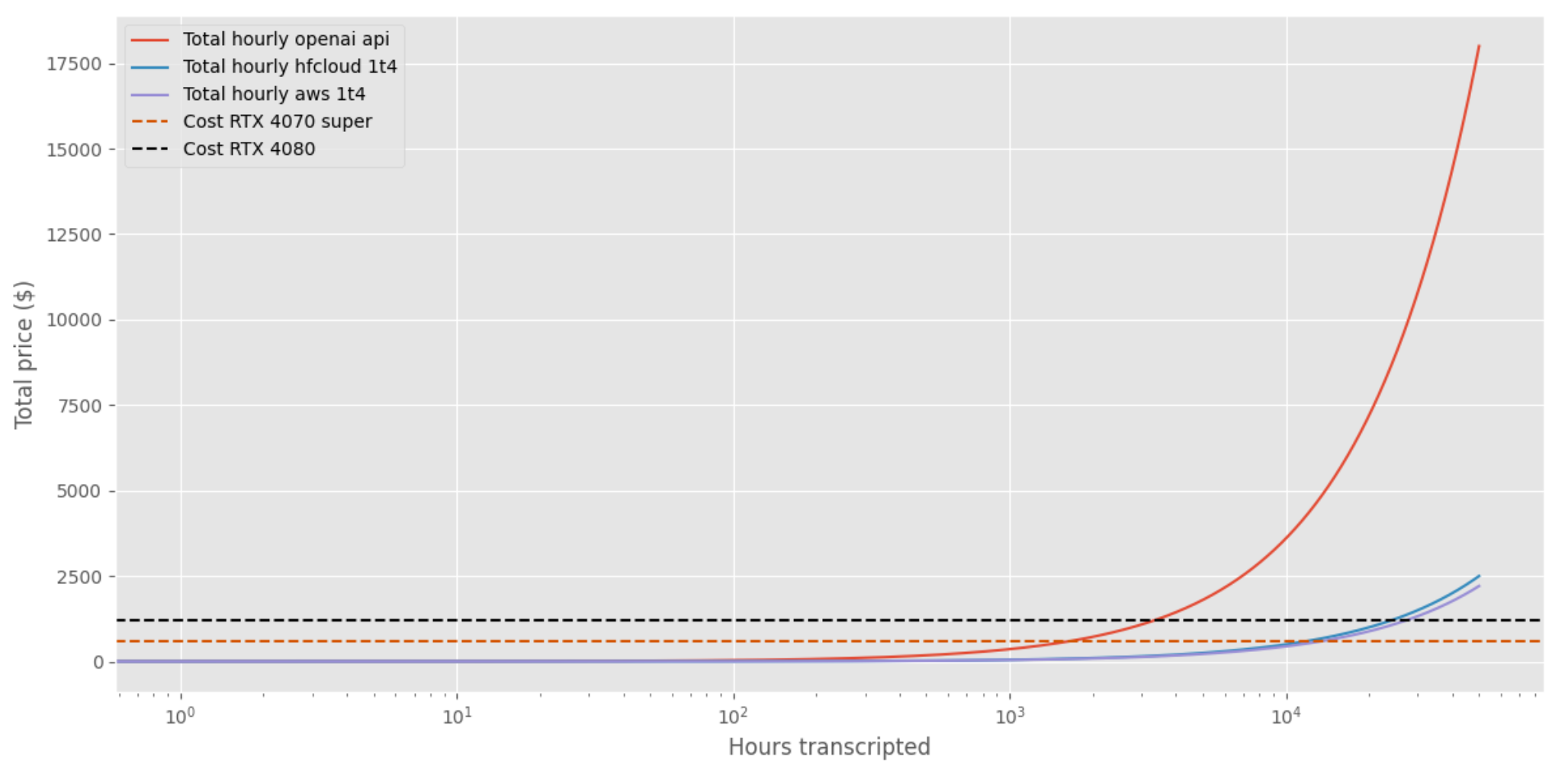
Overall, I note that:
- Local Setup with RTX: To justify the investment over using the OpenAI API or a cloud setup, one would need to transcribe thousands of hours. Thus, upgrading to an RTX may not be cost-effective for my usage.
- T4 Cloud Setup: Appears more cost-effective than the OpenAI API. With an expected 7 seconds to transcribe 1 minute of audio, the cost is around 0.001$ per minute transcribed – 6 times cheaper than the OpenAI API.
It seems that the better deal is to deploy a model on GPU machine in the cloud and that the openAI API is maybe a quick but expensive win.
I wanted to conclude this section by a final test for the openAI API to test if the inference times was the same for any size of audio to transcript (because maybe it’s a feature)
There is a benchmark of the api with various duration of audio (repeated 10 times for each duration)
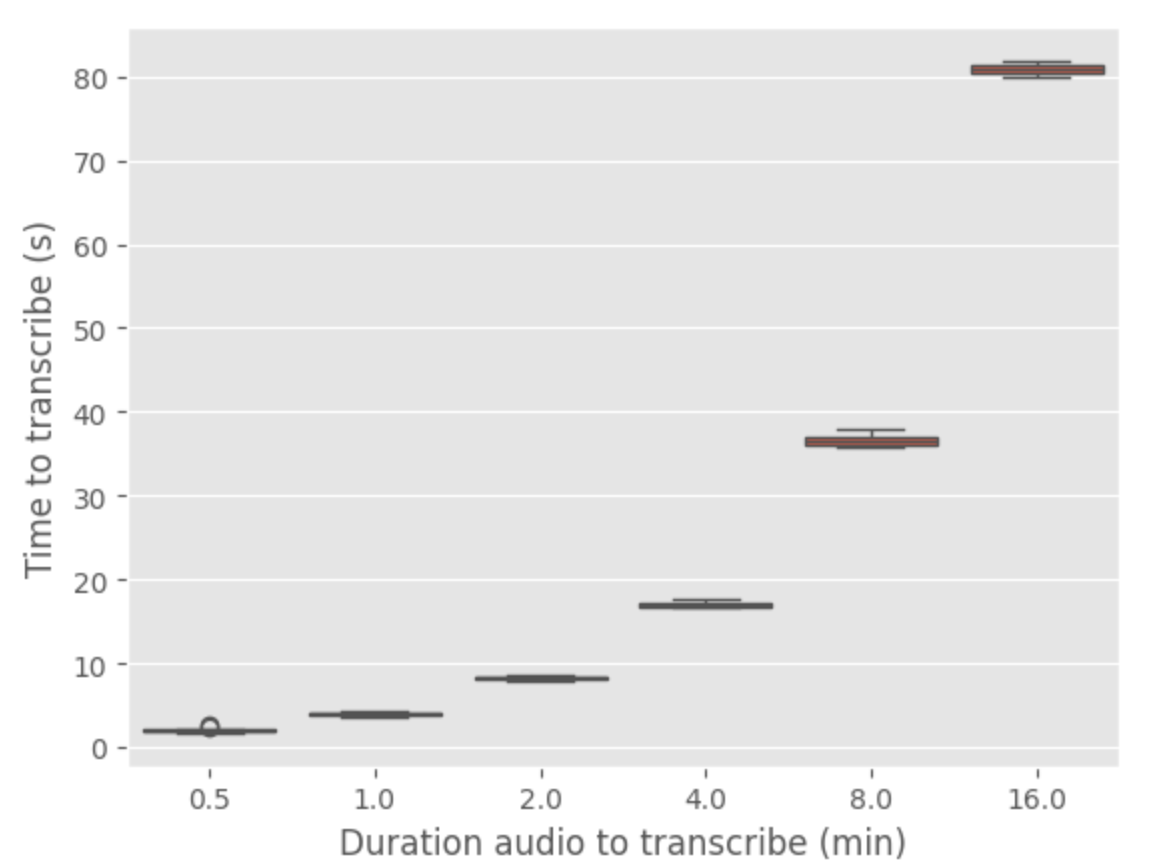
It seems that there is a linear relationship between the duration of audio and transcription time. The transcription time is approximately 5 times the duration of the audio to be transcribed. So the api is not offering an acceleration of the analysis of an audio file (and it still unknwon how they are processing the input audio file)
You can find the files and result used in this test HERE.
Conclusion
The choice between local setup, cloud deployment, or using the OpenAI API depends heavily on the volume of transcription needed and budget constraints. For high-volume transcription, a local setup with a powerful GPU like the RTX 4070 or 4080 might eventually become more cost-effective (but not for me)
However, for moderate or low-volume needs, Cloud solutions (to host a GPU machine) are the most cost effective and more practical and budget-friendly option. OpenAI API is great for prototyping but in the long run can become pricy.
Closing Notes and Future Directions
This project gives me great insights into model deployment and benchmarking in a field that I am not familiar with an interesting model of openAI.
The output of my benchmark illustrated that deploying it’s own model on a hardware in the cloud is the most cost efficient option, but the openaI API is good to make prototype and small demo.
Looking ahead, there are several interesting directions that I will explore in the future:
1. Enhanced Audio Processing:
- Speaker Separation: Develop or used a method to isolate and focus on individual voices within a podcast. This could enhance the clarity and relevance of the transcriptions.
- Streaming Approach: Consider treating audio as a continuous stream rather than dividing it into segments, potentially simplifying the process and making it more dynamic.
- Higher Audio Quality: Investigate the feasibility of using FLAC files instead of MP3s for better audio quality, though this may have technical constraints.
- Audio Library Alternatives: Explore other audio processing libraries like Librosa, which might offer more features and better maintenance compared to Pydub.
2. Focused Model Development:
- Building an Annotated Dataset: Manually collect recommendations from podcast episodes to create a dataset that links episodes or specific segments to topics or themes.
- Tailored Model for French Language: Given Whisper’s multilingual capabilities but French is far to be the best model (cf repository) , fined tuning or using a model specifically tailored to the French language could significantly improve accuracy in this context.
- Exploring Whisper Alternatives: Investigate other speech-to-text models like Wav2vec 2.0 to compare performance and suitability for the project’s needs.
- LLM for Transcript Analysis: Utilize large language models (LLM) for analyzing and post-processing transcripts. The OpenAI API documentation, for instance, demonstrates how to improve reliability with GPT-4. This approach could be particularly useful for bridging gaps between segments or adding context to the transcriptions (and there is also the prompt option to explore in the openaI api wrapper)
These future steps looks interesting and I hope to have time to dig more on this topic, stay tuned 🔉👂.






{kind=link}