
I’ve been interested to write about the “duality” between data scientist (DS) and machine learning engineer (MLE) roles because in my professional life, I often hear things like “I don’t need an MLE, but a DS,” or opinions stating “DS are the worst and MLE are the best.” A recent talk from Uber at the Apply Ops Conference last November seemed like a perfect starting point for this discussion.

The article will start with an analysis on the content presented by Uber and the roles in an ML project. It will be followed by an overview of the data scientist and machine learning engineer positions, concluding with my perspective on their “duality”.
Uber’s Blueprint: Unveiling the Roles and Phases in ML Project
In his talk, Min Cai from Uber presented their overall approach to applying Machine Learning (ML) in production, discussing their stack and vision for a project. The talk included an excellent diagram that I believe effectively summarizes the lifecycle of an ML project.
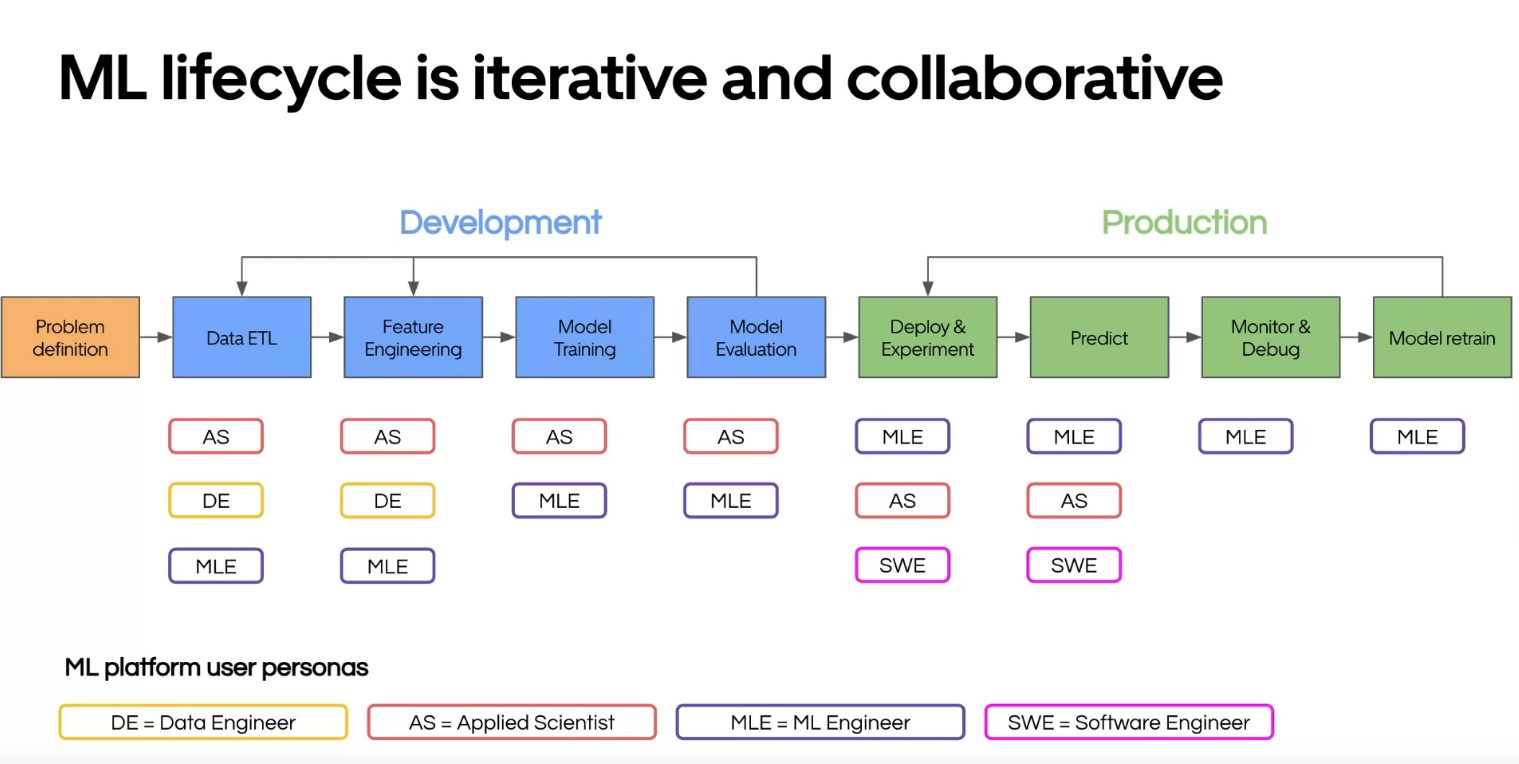
As you can see, the lifecycle of an ML project is usually divided into two main consecutive parts: development and production, following the problem definition. Based on the steps of the lifecycle, different roles can intervene:
- Applied Scientist: From my understanding, this is a data scientist, the main entry point for the development phase
- Data Engineer: Works alongside the applied scientist to set up the data processing and feature engineering.
- Machine Learning Engineer: The main entry point in the production phase
- Software Engineer: Only present in the Deploy and Predict steps of the production phase, they are more focused on integrating the predictions into the general system (where the ML-solved problem will occur).
The Data scientist and Machine Learning Engineer play central roles in the ML project lifecycle at Uber (built on top of their Michelangelo platform). However, what’s particularly interesting in this diagram is the ordering of the roles (the depth) in the steps. My interpretation is that the first row of roles are in charge of the design, the second row provides support or is consulted for the development of the component, and the third row is more about being informed. This setup can be seen as a kind of RACI or RAM, that are approaches to define role and responsibilities of the different actors in a project.
From Uber’s vision, we can deduce the following details:
- The Data Scientist: Not responsible for monitoring and model retraining, but focuses on the development of the model and feature engineering.
- The Machine Learning Engineer: At least consulted on feature engineering and supports model design, focusing their work on the operationalization of the model.
For me, their vision makes total sense and I think it’s a good snapshot of the current organization in an ML/data-centric company in 2023 for the technical roles in an ML project (excluding the PM and PO roles that might exist around it). However, to be honest, we notice some overlap between the two roles, and it would be interesting to see how this looks in more detail.
Data scientist: sexiest job of the 21st century, now what !?
“The sexiest job of the 21st century,” not my words, but those from an article in october 2012 by the Harvard Business Review by Thomas H. Davenport and Dj Patil.

I remember this phrase being quite popular in data scientist job listings between 2014-2016. Here’s a summary of the article that provides a clear picture of the role of a DS in 2012:
- A data scientist is someone who can process big, unstructured data with more than just simple math to extract value from it, defined as a new breed.
- The data scientist aims to solve business problems and do more than just build reports or give advice; they want to create customer-facing products.
- The article starts with the LinkedIn recommendation strategy and the work of Jonathan Goldman in 2006.
- Data scientists are often curious and apply techniques from other fields, like concepts from biology.
- In 2012, most data scientists didn’t have an academic background in data science, as it wasn’t a common field of study then, and they often came from unconventional backgrounds.
- They are in charge of the full pipeline, there is the origin of the full stack DS
- The article mentions the emergence of a second generation of DS (post-2012), with the start of university courses, potentially leading to a more affordable labor market.
- Data scientist need to be good communicator to share results and ideas to people that are less to none technical
This article was definitely a good summary of the role of a data scientist and was also a good predictor of how the job would become popular. Below is a Google Trends graph showing the web search frequency of the term “data scientist” worldwide.
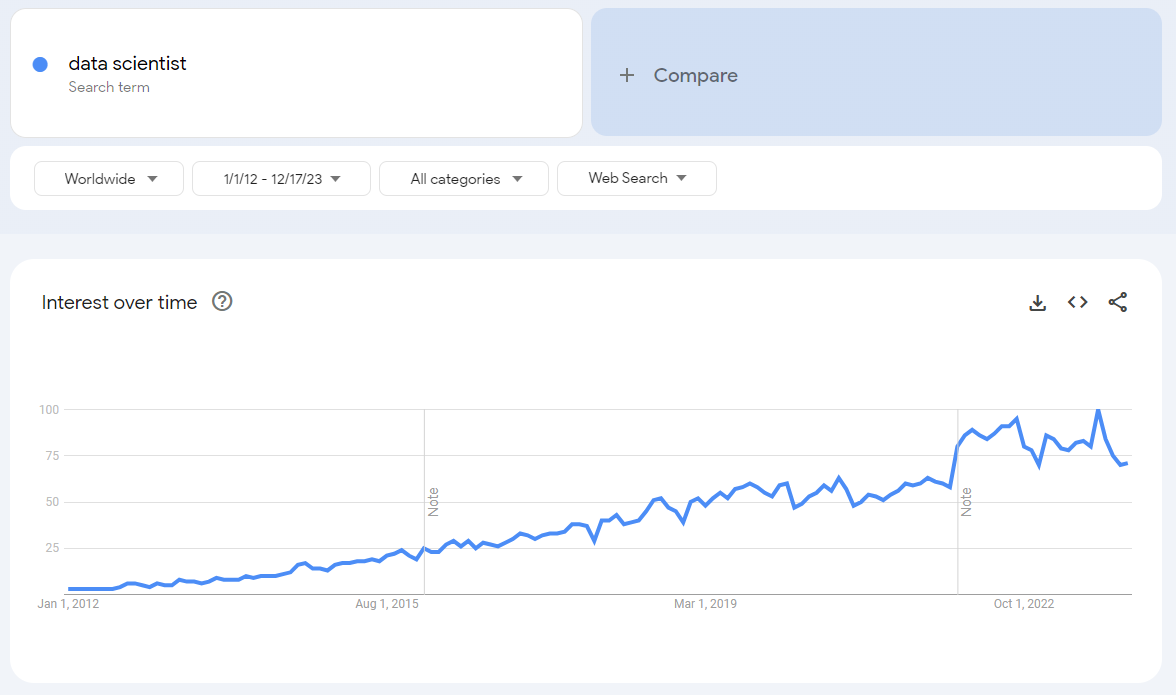
There’s a progressive interest over time since 2012, with a peak/plateau in the last year.
The authors revisited their topic last year (in July 2022, 10 years later in a pre-ChatGPT era) with the follow-up question in their article Is Data Scientist Still the Sexiest Job of the 21st Century?
Their article remains insightful and provides a good snapshot of the current reality of a data scientist, with several interesting points:
- They discuss the emergence of new roles around a data scientist to deliver an ML project, including data engineers, product managers, and ML/AI engineers.
- New tools have arrived for data scientists, reducing the need for coding skills; they no longer have to be full-stack wizards.
- The notion of model and data drift started to rise after the pandemic, influenced by new customer behaviors impacted by lockdowns.
- Questions around ethics and data privacy emerged following the Cambridge Analytica scandal.
- Online and university courses are struggling to capture the essence and true strengths of a data scientist, such as an exploration mindset and direct connection with business.
- Until 2029, data scientists are still expected to be highly sought after.
Excluding the last point, which can be debatable in this new era of Large Language Models (LLMs), the article effectively captures how the work has evolved for data scientists over the past 10 years.
But overall if I want to summarize the role a data scientist is to identify potential gain for the company that could need the usage of “big” data processing and or machine learning technics to deliver a solution to bring value to the business. This schema from the Door Dash techblog is catching the fact that data science is at the cross road of multiple element of computer science (but omitting all the communication aspect)
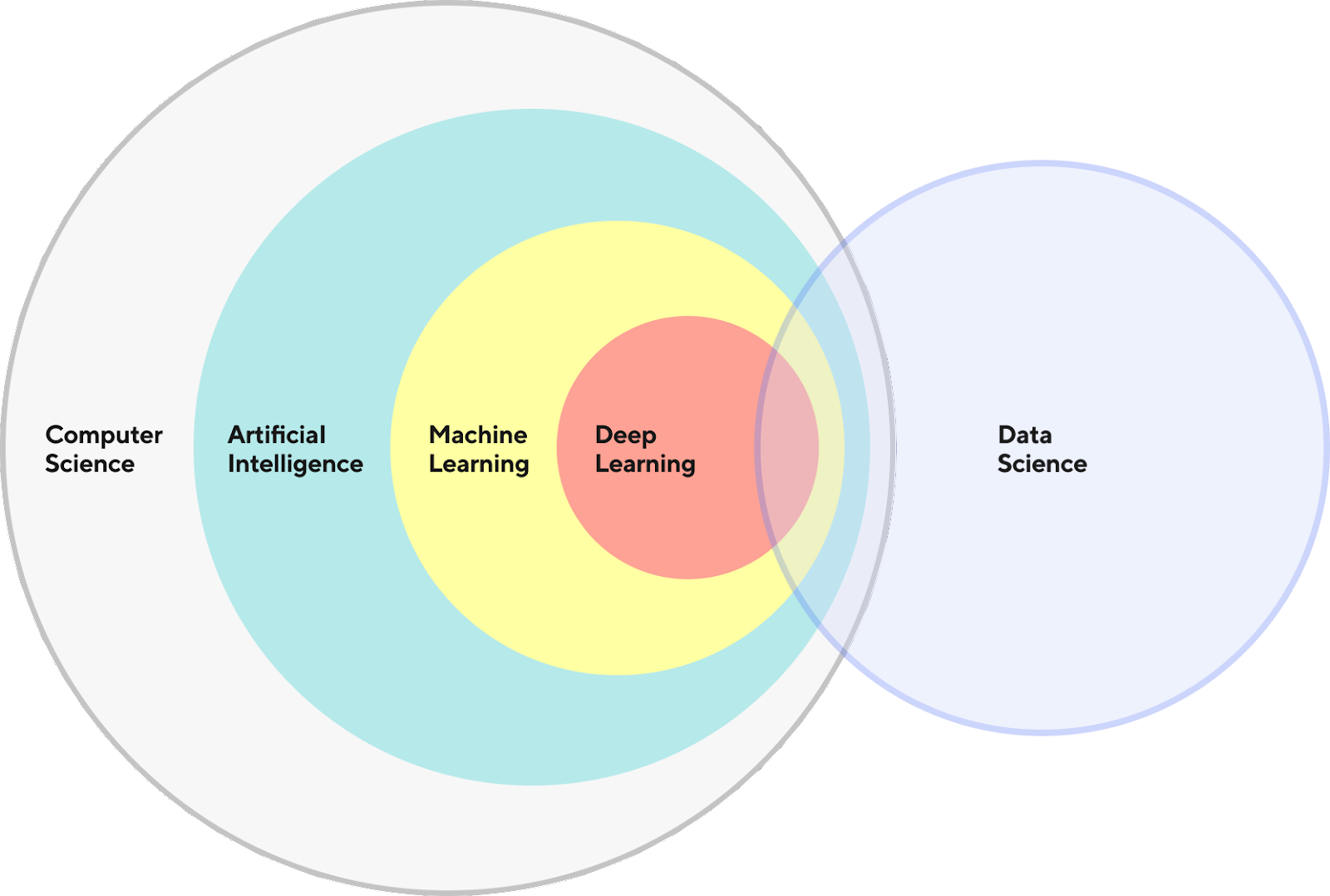
Now, let’s switch our focus to the role of the machine learning engineer.
Machine Learning Engineer: the new cool kid in the block !?
If we go back to our Google Trends analysis, looking at the search term “machine learning engineer” worldwide:
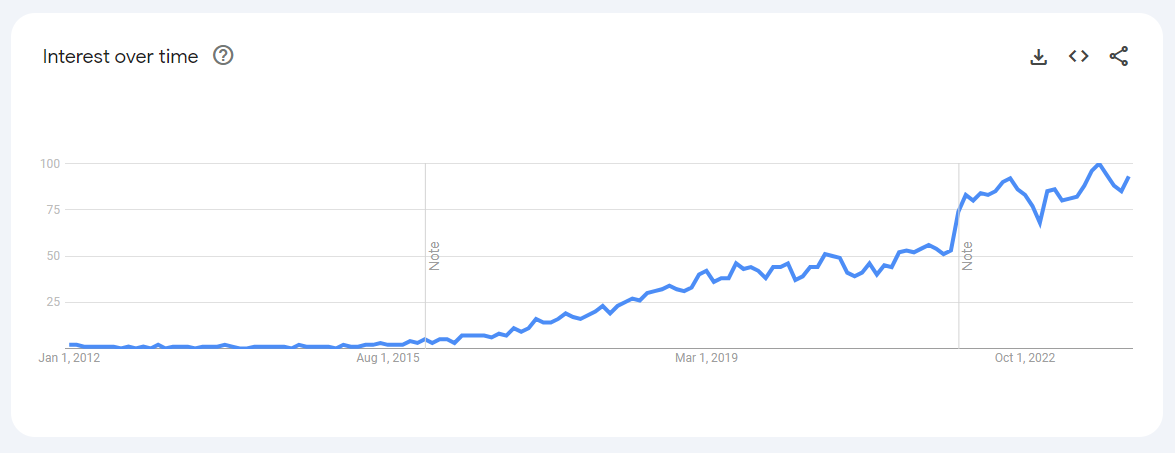
The term seems to have started appearing at the end of 2015 and beginning of 2016, similar to the trend for data scientists, but with a less steep progression. However, comparing the overall interest between the two terms:
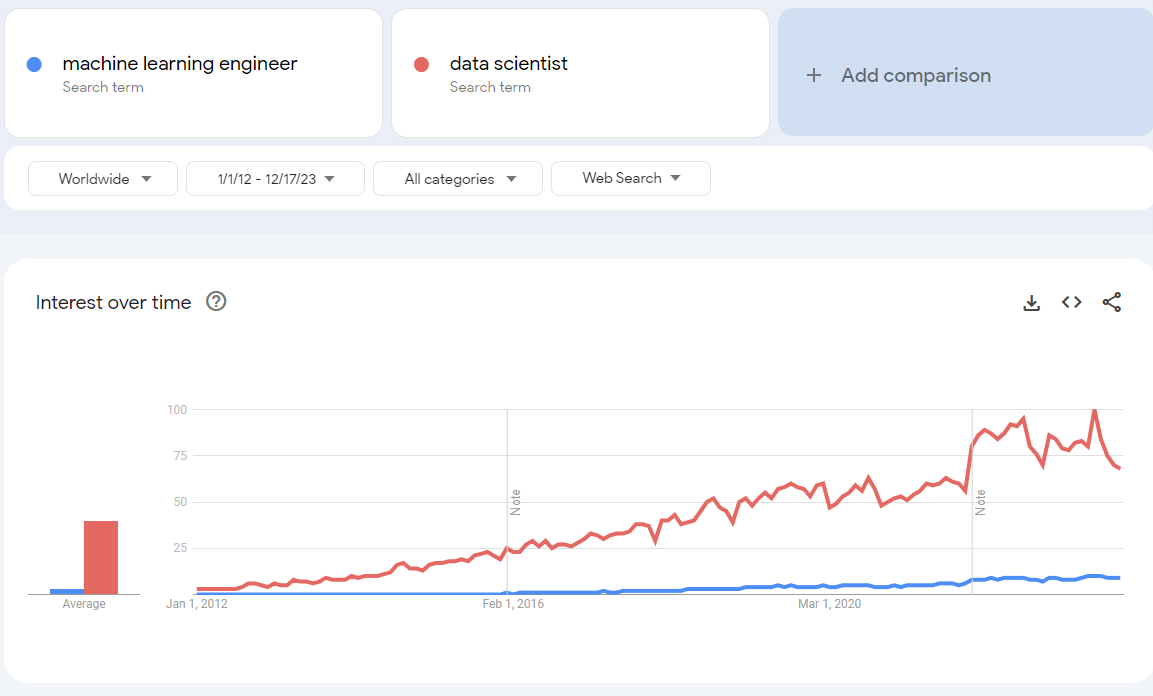
There is a clear lead in web searches for data scientists over machine learning engineers. So, why discuss machine learning engineers? Because they can play an important role in data/ML mature organizations.
A valuable resource on the role of machine learning engineers is an article by Shreya Shankar summarizing her first year of PhD, where she defines two types of MLEs: Task MLE and Platform MLE.
The Task MLE focuses on the productionalization of data scientist prototypes, responsible for building and maintaining ML pipelines and fixing them. This aligns with the same split between development (data scientist realm) and production (MLE realm) seen in the Uber schema.
On the other hand, the Platform MLE supports Task MLEs by automating parts of their job. They build components to streamline the deployment and monitoring of an ML pipeline/model but don’t play with the model’s input/output and architecture. This definition of a Platform MLE reminded me of the MLOps engineer (MLOE), I found an article from neptune.ai quoting Amy Bachir, a Senior MLOps Engineer at Interos Inc, on the difference between MLEs and MLOps engineers: “ML Engineers build and retrain machine learning models. MLOps Engineers enable the ML Engineers. They build and maintain a platform to enable the development and deployment of machine learning models through standardization, automation, and monitoring. MLOps Engineers reiterate the platform and processes to make machine learning model development and deployment quicker, more reliable, reproducible, and efficient.”
A good example of the tasks and tools built by an MLOps engineer is to look at the talk from Min Cal of Uber, which is similar to the presentation he gave at the Apply(ops) conference. Here, you can see all the parts of their NL stack/platform and a glimpse of the job deployment (including the configuration file), showing the work of an MLOps engineer.
So, returning to our discussion, to summarized the role of an MLE is focused on model operationalization and ensuring everything runs smoothly, a critical mission in ML-powered products where the data scientist is only building ML prototypes for features of an ML-powered product, and MLOps engineer build the tech/code fundations for these two profiles to work.
My Perspective on DS VS MLE
On paper and in data/ML-centered companies, the distinction between DS and MLE roles seems like a good setup. However, this distinction is largely theoretical. Most companies lack the maturity for a clean split, as shown in a whitepaper by Arize on ML Observability, where DS and MLE are often classified under the same umbrella.
My statement is this (excluding FAANG-like companies), in many companies:
The machine learning engineer is essentially a rebranded data scientist in terms of job title, but not in tasks(and that’s okay)
This rebranding allows companies to be more attractive by creating a new salary reference to attract candidates and following trends of job positions in large tech firms.
Is machine learning engineering just a buzzword?
No, it’s important (as seen in its critical role in big tech companies). However, I believe that currently, most companies don’t have enough ML workload to justify having machine learning engineers focused solely on the production side of ML projects. I see two main reasons for this:
- Time to Integrate an ML Prediction: Even with the simplest API for predictions, if it’s not a business priority, the project could be stalled for months or years (I’ve seen it happen).
- Experiment Mindset in a Company: A company might have implemented an ML system for predictions (like a recommender system), but if the business is happy with what it has and isn’t keen on exploring new possibilities, innovation stalls.
These reasons explain why companies like FAANG have dedicated machine learning engineers: they are more data/ML/experiment-driven, with clear needs, easy and modular ML integration, and a continuous drive to explore and innovate where other companies are still behind (but slowly building their thing).
Freshly graduated in machine learning/computer science: Which path should I take?
Your choice depends on your interests:
- DS: If you’re curious about finding and answering business needs
- MLE: If you’re keen on deploying proof of concept to production efficiently and managing live system
- MLOE: If you’re interested in enabling ML practitioners with the right technology stack and code.
And I see you, “I am interested by the three paths” , you can definitely go this road to try everything in parallel but be ready that you will have a lot on your plate.
Relevance of these jobs in the LLM Era
Data scientists and machine learning engineers are more relevant than ever, each addressing specific challenges:
- DS: How to integrate LLM into business solutions?
- MLE: How to monitor and fine-tune LLM?
- MLOE: How to make LLM widely available in a controlled manner (considering data privacy, training, and serving costs)?
Starting a company/team for ML powered products/services: When to hire these roles ?
Initially, hire a data scientist with a knack for building production pipelines. In 2023, it’s easier than ever to operate models behind managed services to deliver value quickly (though it may come at a cost).
Next, focus on hiring an MLOps engineer who will lay the technical and code foundations for future ML projects.
Should MLE be the last to hire?
Yes, hire MLEs last, as their role becomes crucial only when there is sufficient ML workload and that you need the data scientist to focus on other projects/subjects.
Is Data Scientist < Machine Learning Engineer?
The perceived hierarchy among job titles, such as Data Scientist versus Machine Learning Engineer, Data Analyst versus Data Scientist or Data engineer VS BI developer, often suggests that newer roles are inherently superior. This topic reminds me of an article by Cassie Kozyrkov about the role of the data analyst in the world of data science. It emphasizes the importance of not judging people by their job titles but rather by the quality and impact of their work and the skills they employ.
Closing notes
Exploring the roles of data scientists and machine learning engineers shows a diverse and complex landscape. Titles and definitions can differ across the industry, but the core of these roles lies in their unique contributions to a machine learning project in a company.

As the fields of machine learning and data science evolve, it’s the mix of skills, creativity, and flexibility that drives progress. The synergy between these roles is crucial. As the field matures, we might see more evolution and specialization, but the main goal stays the same: using data to discover new possibilities and solve complex challenges.





{kind=link}