
Recently, I started to be involved in the organization of different meetups at MTL (pydata, mlops community); we have a big merger of teams around ML in production that is happening around me at Ubisoft, and I participated in a podcast of the mlops community. So I thought it would be a great moment to write a wrap-up around my experience at Ubisoft; this article will go through my background, job responsibilities, challenges faced, and recommendations for those looking to enter the exciting ML in production world.
The Odd Dataguy Origins
Did you get the reference?
I graduated in 2013 from Polytech Clermont Ferrand in engineering physics (specialization in energy), where I followed a master’s degree oriented around physics, as you can expect, and computer science was pretty far from me. Still, we had a few courses around C (I needed to improve, and he made me hate programming) or database management. In my last year, we applied a bit of programming around modelling around thermodynamics or fluid mechanics in Octave (and I started to see how it could be helpful, and I liked it).
Machine learning without knowing
I decided for my final year/internship project to go in the modelling pat to work at the CSTB in Sophia Antipolis, around energy consumption modelling to dimension energy storage in a context of a smart district powered by renewable energy. So I worked mainly in Matlab and started to apply some unsupervised technics (mostly finding some personas to build) to dig in data and create consumption simulations (if you are curious and not scared of french, there is a link to the presentation.
After my graduation, I decided to continue in this way around smart building applications, and I worked for different companies; the most famous ones are the CEA to build data acquisition systems and data analysis pipelines to create services around energy saving (it was mostly in python).

Smart home and beyond
After that that I moved to the UK (bugger …) to work at EDF; I was hired as a data scientist (kind of a new word in 2016) in a digital innovation team composed mainly of developers and data scientists; I work on this topic of energy saving and intelligent building, but a significant aspect was also to analyze trends in the digital world and data/ML to propose new solutions for the business around various topic (I work on e-learning platform recsys, to nuclear plant data analysis).

So there was a lot of prototyping in various languages, and with different services (started to work in the cloud with AWS), this experience was excellent to work with data scientist that pushes me in a new direction that my degree in physics (and to learn new approaches and verbatim). If you want to learn more about the projects at EDF or the CEA, you can look at my LinkedIn, where I explained the projects in more detail.
My experience with data science and machine learning in the smart home and energy sectors prepared me well for my role at Ubisoft, which started in July 2018, where I would help to build an ML platform for the company and operate machine learning pipelines in production.
Crafting the Future: Joining an ML Platform Team
In this section, I will share my experience of being part of a team at Ubisoft that builds an ML platform. The platform was previously called Merlin but will soon be rebranded with a new name. While I won’t delve into the technical details, I presented on the topic at pydata MTL last summer, and you can find the recap of my presentation here for more information.
Teamwork makes the dream work.
I joined Ubisoft in the summer of 2018, and the ML platform team initially consisted of two people, a team lead and a project/product manager/owner. Over the years, the team underwent significant changes, including an increase in headcount on the developer side.
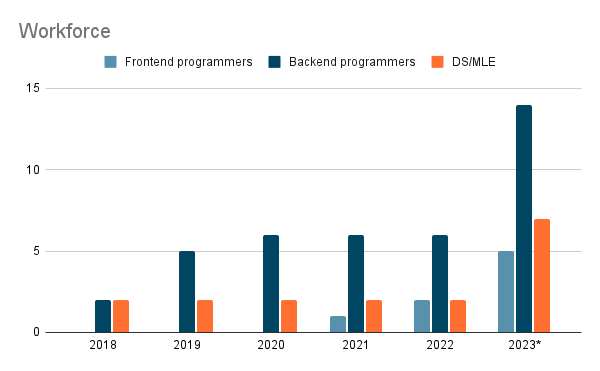
As discussed, most of the team comprises developers with
- Backend programmers can also be considered ML engineers platform (if we take the Shreya Shankar definition ). They work on all aspects related to infrastructure, data, and tooling.
- Frontend programmers are in charge of the portal that is the main entry point to our platform; these roles were added in 2021 and are composed of 2 developers, one on the front end and the other on the back end.
- A baseline of two data scientists (DS) / machine learning engineers (MLE) like me was here from 2018-2022
- In parallel with all the developers, you have team and project/product manager/owner organizing the team.
In 2023, there was a big merger within the Ubisoft data office teams responsible for ML in production. As a result, more people were added to build a new ML platform to extend the current use cases.
Being a part of a dynamic team that strives to deliver top-notch products and features is an exhilarating experience. However, it demands a new way of working using new tools, terminologies, and processes like Agile, Scrum and Jira. Our team’s workflow has undergone several transformations throughout the year, but some details from the last iteration before the merger are worth sharing:
- Our sprint cycle was two weeks long and divided into three parts- one for the platform developers, one for the portal developers, and one for the data scientists. Each sprint commences with a sprint planning meeting (for each part of the team), concluded by a sprint review that is open to internal users, and finally, a sprint retrospective meeting.
- We also have a weekly meeting to ensure smooth team coordination and communication.
- Each story is scored based on complexity, ranging between 1, 2, 3, and 5. The complexity of the task determines the number of points and not the time required. For instance, a simple task like sending an email would be assigned a score of 1, while a more complex one requiring several days of coding would be assigned a score of 5.
As one of the data scientists on the team, I am actively involved in testing new features and providing feedback to ensure our product’s continuous improvement.

Exploring the mlops landscape
Participating in an ML platform is an excellent opportunity to explore and test new technologies that can help accelerate the platform’s development. However, the tech landscape is ever-evolving and crowded, and choosing the best tools that suit your needs is challenging.

To navigate this landscape, I recommend reading articles by Lj Miranda and Mihail Eric, where they talk about their experiences browsing and classifying these kinds of tools.
At Ubisoft, I worked with various technologies and packages, including open-source solutions like mlflow and metaflow, managed services like Arize.ai (which I plan to write about soon), and cloud-based ML managed services like AWS sagemaker.
As a team, our goal is to assess each tested tool’s value and the estimated integration cost from the perspective of both a platform user (like a data scientist) and a platform builder (a developer). We first tested these tools with open data to gain insights and then moved to actual Ubisoft use cases to evaluate their effectiveness further.
Building an ML platform can be daunting, and organizations often must choose between building and buying their solutions. This debate raises several questions and concerns that must be addressed before embarking on such a project.
In a recent round table discussion about recommender systems organized by Tecton, Jacopo Tagliabue, an ML expert, shared his thoughts on the build-and-buy strategies around an ML platform. In addition, he provided an overview of the strategy presented in deploying a recommender system.
There is an overview of the strategy presented by Jacopo in a schema.
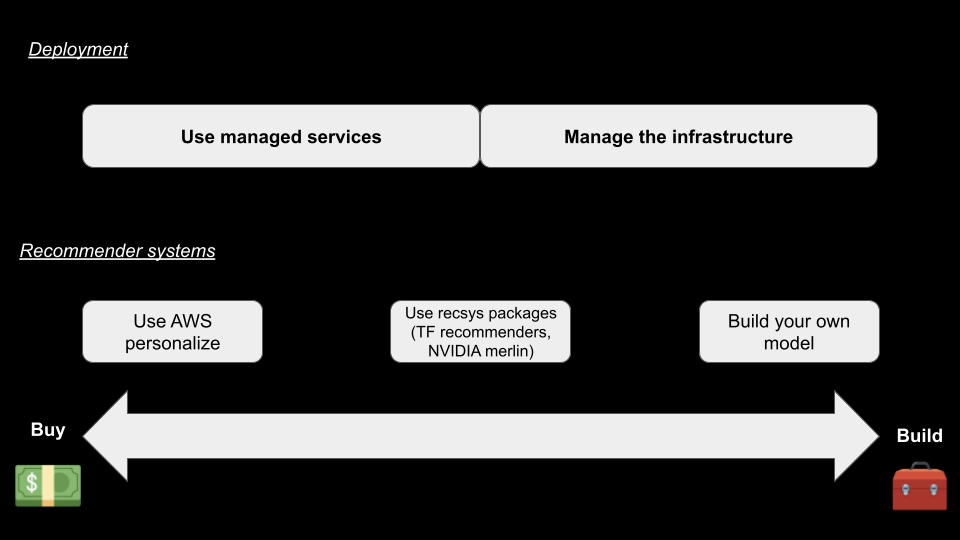
At Ubisoft, we focus on building our models using frameworks like Spark MLlib or TensorFlow, but when it comes to deployment, we are more on the manage our own infrastructure in a way.
Jacopo’s key point was that most companies should start with a BUY approach and then transition to a BUILD approach but never go back (unless there are extreme circumstances). This advice aligns with our experience at Ubisoft and could be valuable for other organizations navigating the same decision.
If you want to learn more about this topic, I recommend reading Chip Huyen’s excellent chapter on the build-and-buy strategies in her book Designing Machine Learning Systems.
Let’s discuss the fun part of an ML platform, customer support.
Support the internal clients
Building an ML platform for data scientists and ML engineers can be challenging, especially when it comes to adapting to the users’ varying levels of technical expertise.
Recently, Spotify published an article that sheds light on their strategies around ML in production. They built a schema that outlines the different roles involved in an ML in production project. However, I found the axis a little blurry, so I created my own version.
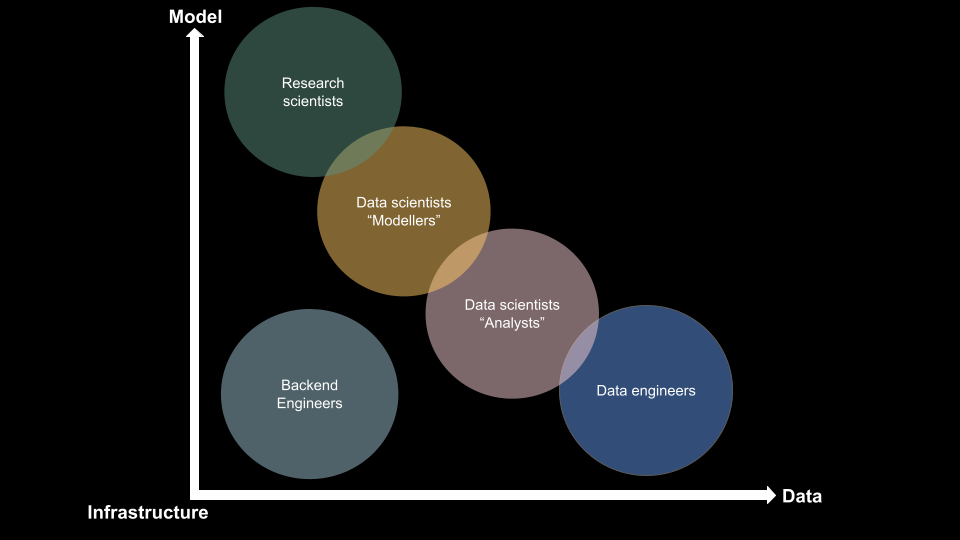
In my opinion, an ML in production project involves three main elements: data, model, and infrastructure. Different roles gravitate around these elements, including:
- Backend Engineers: Developers in charge of all the elements needed to build/use data and build/use models.
- Research Scientists: Experts focused on exploring new models and algorithms to improve the ML pipeline’s performance.
- Data Scientists (Modelers): Professionals who specialize in modelling phenomena in a set of data and have an extensive toolbox to support their work.
- Data Scientists (Analysts): Experts focus more on analyzing the data than modelling.
- Data Engineers: Developers who primarily work with data, ETL, and data organization.
However, where does an ML engineer fit into this schema? Different visions collide on this question.
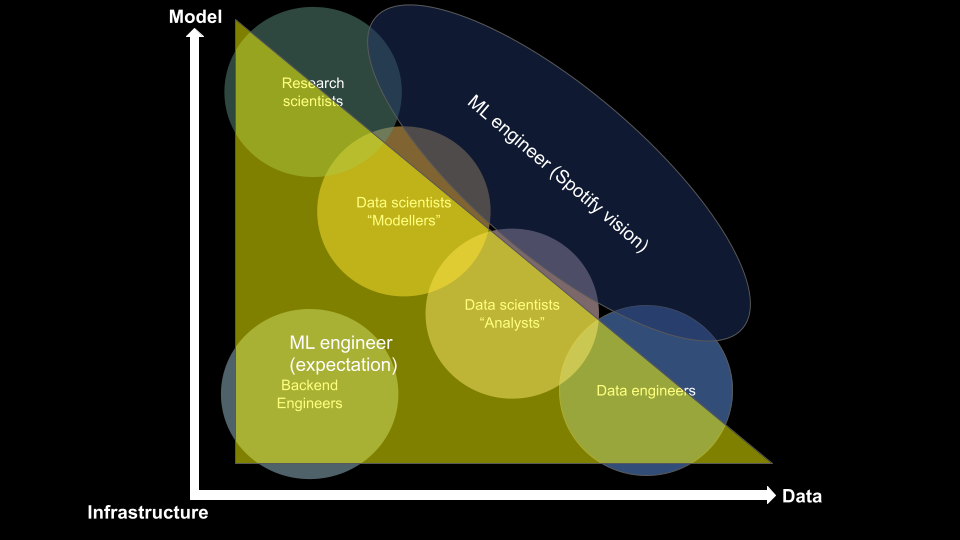
There are two different visions when it comes to the expectations of an ML engineer’s role:
- The first is a “jack of all trades” approach, where an ML engineer is expected to manage everything from infrastructure and data to model development. This approach is well-illustrated in an article by Chip Huyen, where she discusses the role of a full-stack data scientist 🦄.
- Spotify’s vision demonstrates that the second approach focuses on data and model development and drops the backend engineering aspect.
While Spotify’s vision is a good one, the role of an ML engineer is more akin to an octopus, with the head and body in the data scientist modeller role and tentacles reaching into specific circles based on the individual’s preferences and experience.

To ensure that most DS/MLE users understand our ML platform, we have implemented various approaches, including:
- Regularly updating and easily accessible documentation is integrated directly into our portal.
- Building end-to-end example pipelines to showcase how the platform can be used in simple projects.
- Wrapping MLOps tools behind functions to ease the integration of new tools in the future and allow users to focus on the most critical features of the tool (like we have done with mlflow).
- Utilizing internal conferences to promote the platform and its functionalities to other teams #EveAngelization (the french people will get it).
Let’s dive into my day-to-day job as a DS/MLE (🐙) at Ubisoft.
Design and operate machine learning pipelines in production 🔧
As a DS/MLE responsible for building recommender systems in a batch context for games, my daily job involves mainly:
- designing event processes: Get the correct event from the telemetry and make it useful in an ML pipeline
- exploring new algorithms: Choose the right features and hyperparameters for the model to make the correct predictions
- deploying and operating pipelines: Having a code base that can build predictions and be monitor
- monitoring performance: Having an alert mechanism in place to detect anomalies in the data or the predictions
- performing live experiments to test new models and assumptions.
Deploying applications like these is a rush at specific moments, particularly during feature releases and data or infrastructure migrations. After deployment, it is mainly maintenance and regular testing to reevaluate the usefulness of using ML for a specific feature in terms of cost vs. gain.
I briefly aboard my job because each bullet point could be an article on its own, but if you want to learn more, listen to my participation in the mlops community podcast.
The following section will discuss the challenges and lessons learned from my experience.
Ready Player ML: Challenges and lessons learnt
It will be more big bullet points than structure sections, as previously, so put your seat belt on.
Evaluation of ML systems over time: For this one, I will quote this tweet from Eugene Yan, a recsys expert at Amazon.
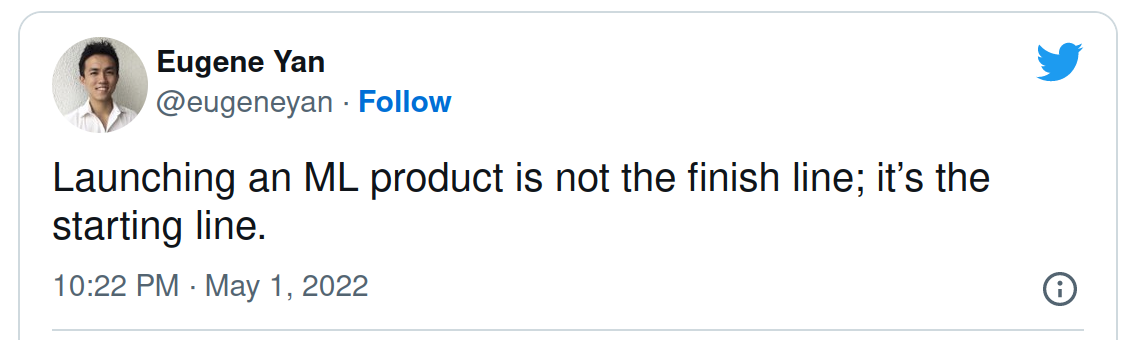
Agree with that; it’s essential to keep an eye on your pipeline and regularly evaluate the model performance to see if it’s worth it to run this pipeline and still worth it after X months (cost VS gain analysis). In the video game industry, as you can expect, a game can reach a plateau after a few months and spike at specific moments of the year (like Christmas), so choosing to activate some ML features is essential.
The video game industry is driven by creativity first: At their core, video games are not designed by data or machine learning. Instead, they are built to provide players fun, creativity, and unique experiences. However, building around data and machine learning is a recent development in the video game industry, and Ubisoft is progressing in this area.
There are also challenges related to the game lifecycle; it must pass certain milestones and priorities. This approach can lead to delays in the release or the cancellation of certain features. Incorporating machine learning into video games requires flexibility and close collaboration with game developers to demystify the use of these technologies.
If you are curious to learn more about the game development lifecycle, there is a great article from Ubisoft HERE that is explaining the different phases from conception, preproduction, production and operations (in general, we are more involved in the production and operations phases), with also this video.
Scalability first: One of the first things I learned when deploying machine learning pipelines was to test for scalability. Mainly working with Spark, before releasing a predictive feature like a recommender system (in a batch context), one of the checks I perform is to ensure that the pipeline can handle the load.
To test scalability, I leverage the usage data from other Ubisoft games regarding daily/monthly users and run the pipeline on fake data 1-10 times the volume of the most popular games. This approach provides security and comfort for the client who orders the predictive feature. Testing the machine learning part (such as making inferences) and the ETL part is essential.
Start simple: According to the first rule of the guide to ML in production from Google, starting small and straightforward is essential instead of jumping straight into complex models and techniques.
For instance, when building a recommendation feature, one could start with a popularity-based list or a simple association matrix before diving into heavy data engineering and modelling with random forests or deep learning techniques. This is especially important in the creative industry of video games, where building a culture around data and machine learning is still relatively new (build simple and plug quickly).

If you want to learn more about this concept, “Start simple” Eugene Yan has written a great piece on the topic with many testimonies and the concept of heuristics.
Data is your friend before your model: Data plays a critical role in MLOps, and there are several essential aspects to consider, such as data exploration, cleaning, visualization, feature engineering, splitting, pre-processing, and monitoring. Investing time and effort in data processing can have a significant impact on the performance of your models. In addition, working closely with data analysts ensures you are effectively using and processing the correct data.
However, it’s essential to be cautious about data quality and not solely rely on your data provider’s quality checks. Instead, it’s recommended to perform your checks at every step of the ETL or ML pipeline to ensure the accuracy and reliability of your data. This due diligence can help you make better predictions and avoid costly mistakes.

Lower your expectations on an ML platform: From my perspective, don’t expect an ML platform to solve all your problems out of the box. Stefan Krawczyk has a great analogy, where a platform should be seen as “anything you are building on top of” - in this case, an ML application.
I will go further by finding a metaphor that an ML platform in a company is like a workshop in a DIY club. There are a few statements linked to this metaphor:
- “I want this and that tech on your ML platform” - Are you expecting a workshop to have all possible tools available? It doesn’t scale in terms of cost and maintenance, and always keep in mind, why do you need this tool/tech?
- “You don’t offer this feature, I can’t work” - Don’t be stopped by that and hack your way. On the ML side, having the latest cutting-edge algorithms is optional to bring value with ML. From the MLOps side, leveraging some tools not initially made for it can bring quick value, like using a bobby pin to hold a nail (VS a nail holder).

This approach shows the team’s need behind an ML platform, and they can find the right tool to bring to the platform. Moreover, for everybody building an ML platform:
- “Don’t design a platform on hypothetical use cases”; you will waste time and energy for nothing.
- “Don’t be driven by papers and tech blogs only”. I will paraphrase a Netflix engineer who said at a conference, “An ML platform should be designed by business needs and NOT by DS/MLE/DEV expectations.”
87% of ML projects are not going to production: … because you are not friends with the right people. This statistic is often cited in discussions about machine learning in production, and comes from a VentureBeat article. While it’s true that MLE/DS professionals should be close to the business to understand the context and access the necessary data for ML integration, that’s only one side of the coin.
You also need to have a good working relationship with the programmer who will be integrating your application’s API.No matter how well-documented and easy-to-use your API is, the programmer who integrates it ultimately determines whether or not the project makes it to production. Therefore, offering them support through demos, personal tours, and involvement in business-related discussions is crucial to show them their work’s impact on the company.
Build or buy, the Eternal question: There are a few questions that can be connected to this topic, such as:
- “Should I build an ML platform?” Honestly, it depends on your budget and industry. I think it’s better to start with managed services, assess the cost, and weigh the trade-offs before deciding to build something.
- “If I am building an ML platform, should I have data scientists on my team?” Of course, you need power users, but whether they should be in your team is more of an organizational decision (and should be based on actual use cases).
- “If I am building an ML platform, should I hire developers interested in ML?” It’s a plus, but in 2023, it’s far from mandatory (especially when you can set everything up for ML in a few clicks on the cloud).
To conclude, here are some resources and people I found interesting to learn more about machine learning in production.
Cheat codes for MLOps
Throughout this article, I have shared various articles to support my explanations. However, I would like to take a moment to highlight some specific resources and individuals that can help you learn more about MLOps and machine learning in production.
Websites
- Made with ML: a website built by Goku Mohandas that shares knowledge about the field of machine learning in production.
- Full stack deep learning: A website that promotes a free course and a bootcamp around leveraging ML in production, with a strong focus on the industrialization of deep learning models.
- Udacity: A platform for e-learning that offers the Machine Learning Nanodegree Program, which provides a reasonable basis for understanding the machine learning world.
- Kaggle: A popular data science and machine learning platform featuring datasets, competitions, and code to learn from and improve skills.
- Tech blogs: Company resources where they are sharing good practices, like the one of Airbnb, Etsy or DoorDash
People
- Eugene Yan (Twitter, website): One of the best DS/ML online contributors with a great and efficient style. Interestingly, he always starts threads on Twitter to get inputs from his followers, making it an excellent place to learn new things.
- Chip Huyen (Twitter, Website): Behind a great website and book where she shares her point of view on the industrialization of ML solutions. She is also an instructor in the Stanford machine learning system design course, which is a perfect starting point.
- Jacopo Tagliabue (Twitter): Worked at Coveo before (its original company has been bought by Coveo) and now working on new projects. Very present on different podcasts and conferences, but his most exciting work is one of his papers at RecSys 2021 on not making pipelines too complex for ML in production.
- Ronny Kohavi (Twitter): Working at Ubisoft pushed me to do live AB testing, and he is one of the big names in experimentation and A/B testing. He has worked for companies like Microsoft and Airbnb, so he’s the person to follow if you want to learn more about these topics. Additionally, he participated in a book on the topic of AB testing.

Meetups/podcasts
- MLOps community: A great community with great founders/animators where you will always listen to some good stuff in their slack or podcast
- Apply tecton conference: Regular online conference around ML in production where practitioners share their experience
- Company podcasts: like the tech blog, they are great podcasts led by some companies like Gradient Dissident from weight and biases or Deezer tech podcasts
- Pydata Youtube: A place where pydata organizers are sharing records from various editions all around the world; one of my greatest findings was this video from hello fresh around MLOps
Final level
In conclusion, reflecting on my five years (ish) of experience at Ubisoft has been an insightful and fun experience. I’ve learned many valuable lessons about machine learning in production, such as buying before building ML platform components, starting simple the ML part, regularly evaluating your pipeline, and avoiding the FOMO around the latest ML techniques.
Looking ahead, I’m excited to see where the industry will go in the next five years, seeing recent breakthroughs with chatGPT, dalle etc. As machine learning continues to mature and become more accessible, we’ll see even more creative and innovative uses of the technology in the video game industry and beyond. I look forward to participating in this exciting journey and continuing to learn and grow as a DS/MLE (🐙).







{kind=link}