
Doctor Who - Aperçu de NLTK
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Bonjour, j’écris ce rapide article pour :
- présenter un dataset que j’ai construit au cours des dernières semaines
- obtenir un aperçu de certaines fonctionnalités de nltk
Qui êtes-vous ?
Doctor Who est une émission de télévision britannique, de science-fiction qui a débuté en 1963, produite par la BBC, le programme raconte l’histoire du Docteur, un alien (avec une forme humaine) qui voyage dans l’univers dans sa machine à voyager dans le temps / vaisseau spatial appelé le Tardis (une cabine de police).
Pendant ce voyage dans l’espace et le temps, le Docteur est suivi par des compagnons de la Terre car il a une certaine préférence pour la planète Terre (c’est très pratique, n’est-ce pas). Le Docteur est très intelligent, drôle, etc. mais les deux principales caractéristiques du personnage (qui proviennent de sa race alien les time lords) sont :
- Il est en quelque sorte immortel
- Quand il meurt, il revient à la vie dans une nouvelle forme humaine (très utile pour la fin de contrat). Chaque régénération conserve la mémoire de la forme précédente mais il a un nouveau look et un nouveau comportement. Mais ce processus de régénération est limité en nombre d’itérations
En termes de spectacle, il y a deux phases qui peuvent être définies (c’est mon terme donc s’il vous plaît les fans de Doctor Who ne m’exterminez pas) :
- L’ère classique de 1963 à 1989
- L’ère moderne de 2005 à maintenant
De mon côté, j’ai découvert Doctor Who vers 2010, donc je suis plus un gars de l’ère moderne et je ne suis pas très familier avec l’ère classique, mais ce que j’aime avec l’ère moderne, c’est qu’ils réimportent la légende de l’ère classique et font un rafraîchissement et une mise à jour (comme redesigner les ennemis du docteur par exemple).
Quoi qu’il en soit, ce spectacle est un diamant de la culture pop britannique, des références aux acteurs, et si vous aimez la science-fiction, cela vaut vraiment la peine de le regarder.
Donc maintenant plongeons dans les données de ce projet.
Présentation du dataset
Donc soyons honnêtes, ce dataset a été inspiré par cet autre dataset axé sur l’émission de télévision Les Simpsons.
J’ai scrapé des données de différents sites web :
- Les scripts des épisodes proviennent du site web chakoteya où on peut trouver pour chaque épisode tous les dialogues, etc.
- Les notes de chaque épisode de l’ère moderne proviennent d’IMDB
- Les informations sur les épisodes proviennent du doctor who guide et contiennent des détails sur l’épisode, la distribution du casting ou de l’équipe.
Ce dataset donne différents détails sur le spectacle et peut être utile pour déterminer l’impact de certains événements spécifiques dans la production qui pourraient avoir impacté la note sur IMDB.
Par exemple, dans la figure suivante, il y a une représentation de la note des différentes saisons dans l’ère moderne.
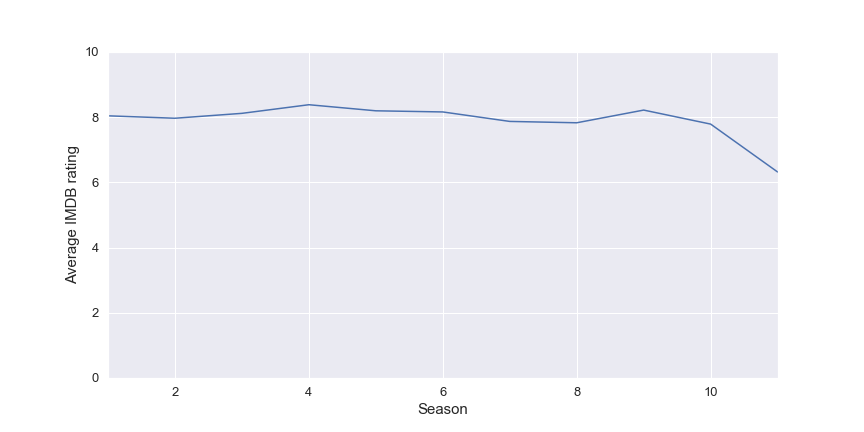
Il semble que toutes les saisons aient une note vraiment proche de 8 mais la dernière semble être moins appréciée par le public, je pense qu’il pourrait y avoir deux raisons à cela :
- Le showrunner historique Steven Moffat qui a relancé le spectacle en 2005 a quitté la production donc le nouveau ton pourrait ne pas convenir au public
- Le nouveau docteur est une femme, c’est la première fois dans le spectacle et après l’annonce il y a eu un shitstorm/bad buzz sur internet sur l’actrice et comme la note sur IMDB est basée sur les utilisateurs, le bad buzz peut impacter la note (biaisée par les haters)
Jetons maintenant un œil sur le casting du spectacle, je voulais voir s’il y avait des noms qui ressortaient entre les deux ères du spectacle et un nombre assez important, sur les 3146 acteurs il y a comme 1362 acteurs qui semblent être dans les deux ères, le docteur est celui qui semble avoir le plus d’acteurs récurrents mais c’est facile avec les épisodes anniversaires (et le personnage peut voyager dans le temps lol)
Si nous concentrons cette analyse sur les acteurs qui sont dans les deux ères, nous pouvons voir qu’une bonne partie de ces acteurs sont les acteurs vocaux pour certains personnages non humains comme la voix pour le Dalek jouée par Nicholas Briggs par exemple).
Plongeons dans les scripts des épisodes pour commencer à faire une analyse de texte avec NLTK.
Analyse des scripts avec NLTK
Pour faire l’analyse du script, je vais utiliser le package NLTK qui est défini comme
“une plateforme de premier plan pour construire des programmes Python pour travailler avec des données de langage humain. Elle fournit des interfaces faciles à utiliser pour plus de 50 corpus et ressources lexicales telles que WordNet, ainsi qu’une suite de bibliothèques de traitement de texte pour la classification, la tokenisation, le stemming, le tagging, l’analyse syntaxique et le raisonnement sémantique, des wrappers pour des bibliothèques NLP de qualité industrielle”
Pour cette partie, je vais suivre le tutoriel sur NLTK fait par datacamp, pour faire du traitement des scripts (tokenisation, nettoyage des stopwords et normalisation lexicale) avant de commencer à faire l’analyse du texte.
Mon analyse sera divisée en 3 parties :
- Obtenir les mots les plus utilisés et la concordance des mots
- Dessiner des wordcloud pour certains personnages spécifiques
- Faire une analyse de sentiment
Mots les plus utilisés et concordance
D’abord après la tokenisation des différentes phrases et mots et passer les filtres stopwords sur les éléments, nous pouvons voir que les 10 mots les plus populaires sont :
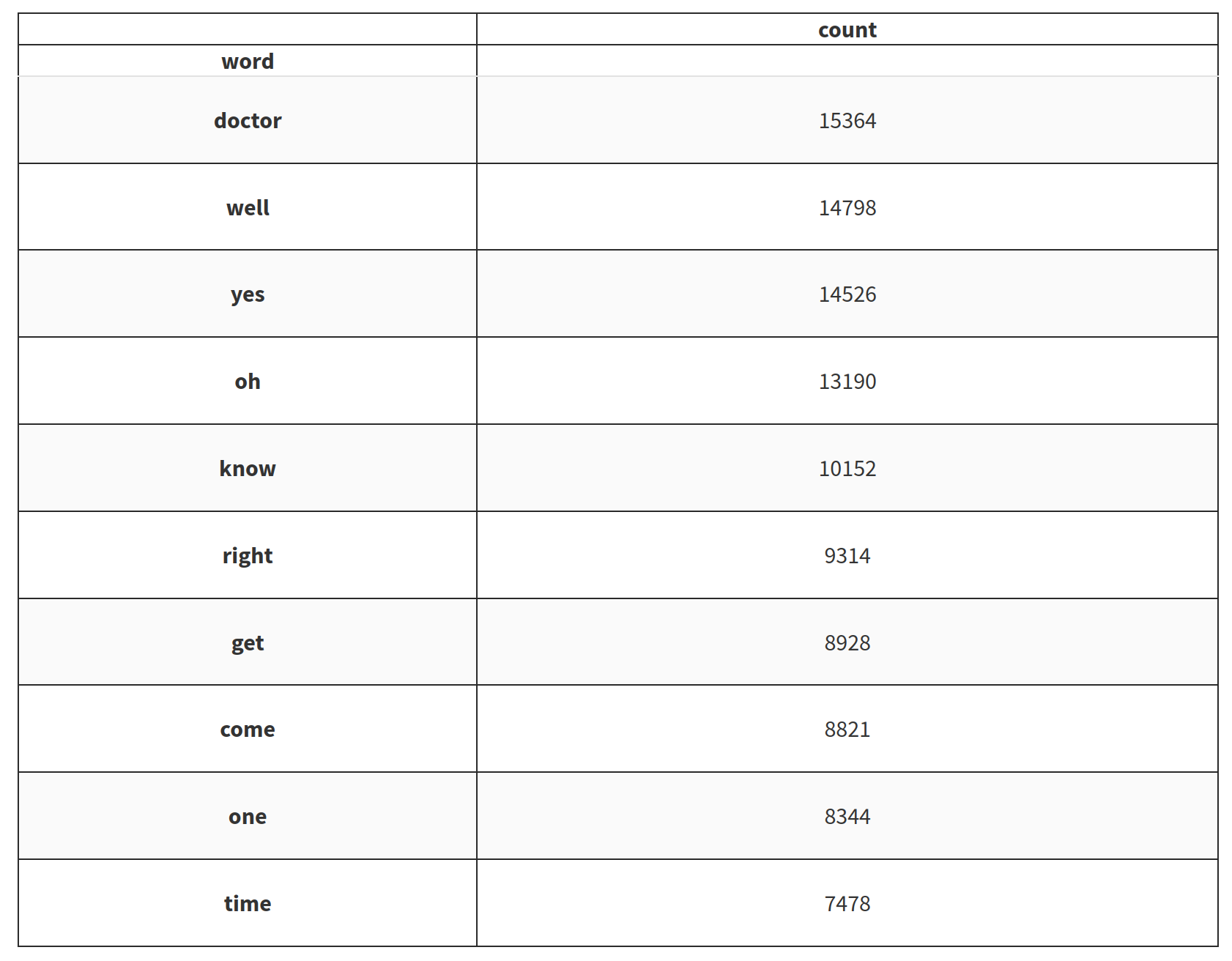
Et devinez quoi, doctor est le mot le plus populaire donc maintenant enquêtons sur la concordance du mot doctor avec des mots avant et après et comptons les occurrences. Voici le top 20 des mots qui semblent les plus liés au mot doctor.
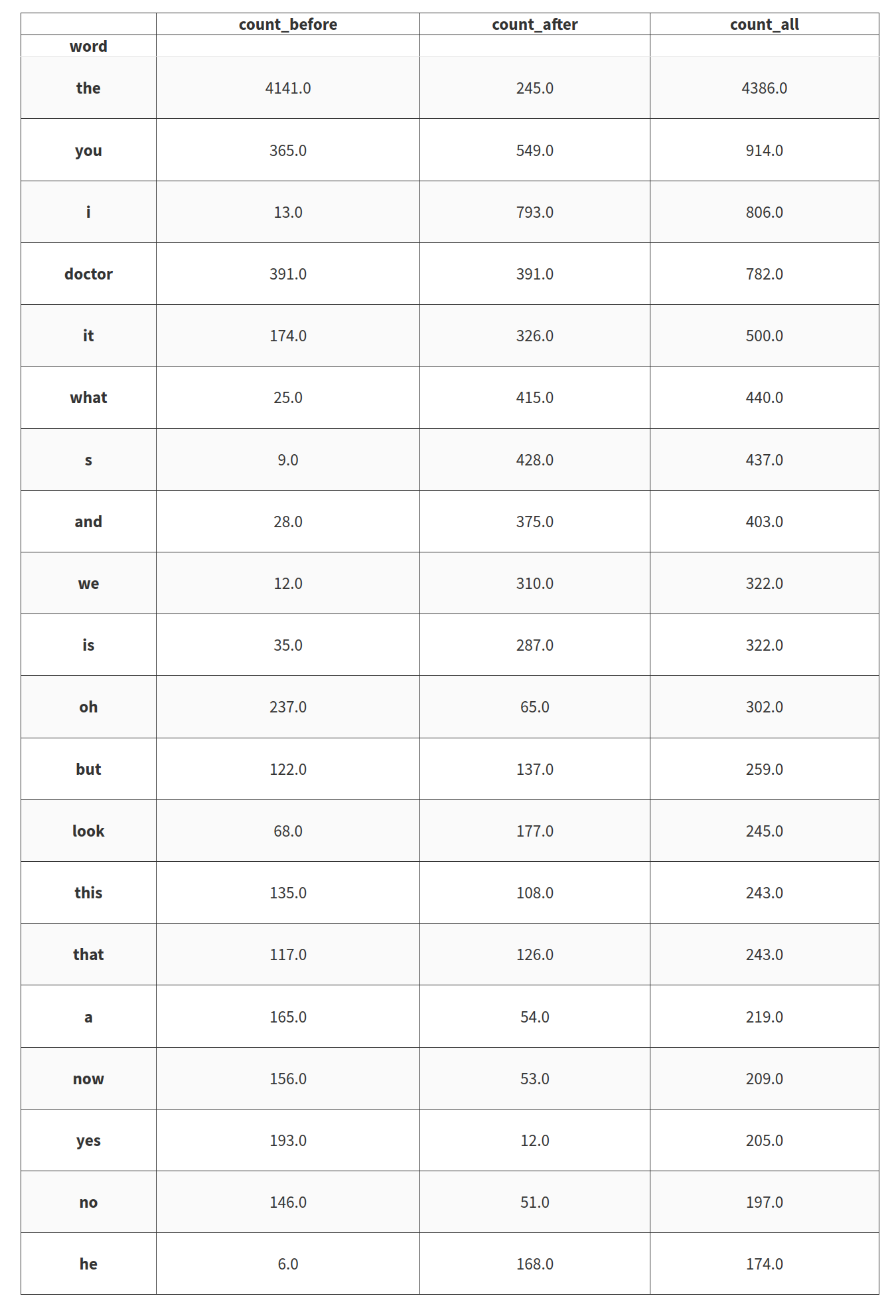
Drôle de voir que “the” est un bon candidat pour les mots qui sont le plus liés à doctor mais c’est triste que “who” ne soit pas dans le top 20 (il est #34). Voyons maintenant les mots utilisés par certains personnages spécifiques.
Wordcloud
Dans cette partie, je vais déterminer le mot le plus utilisé pour une sélection de personnages (avec un wordcloud inspiré de cet article)
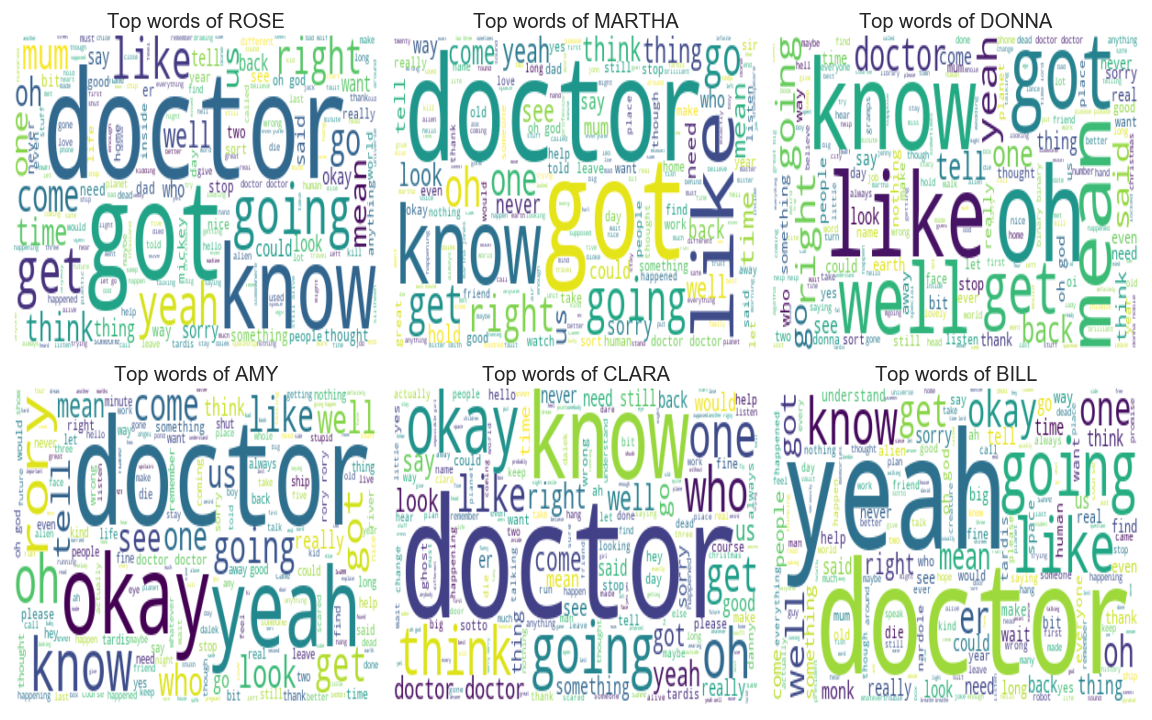
Comme nous pouvons le voir, doctor est un mot récurrent dans la bouche d’un compagnon du docteur. Voyons maintenant le mot dit par ces boîtes de conserve folles de Dalek.

Exterminate est l’un des mots les plus utilisés par les daleks dans le spectacle, ils veulent essentiellement tout détruire.
Faisons maintenant une petite analyse de sentiment sur les scripts
Utilisation d’un analyseur de sentiment
Je vais utiliser l’analyseur de sentiment qui peut être trouvé sur NLTK appelé Vader sentiment analyser
Le Vader analyser provient d’une publication de 2014 et il se réfère au Valence Aware Dictionary and sEntiment Reasoner , et vous pouvez trouver un article intéressant sur le sujet. Cet analyseur prêt à l’emploi est très utile, dans la figure suivante il y a l’évolution du discours dit par le docteur pendant un épisode de la première saison.
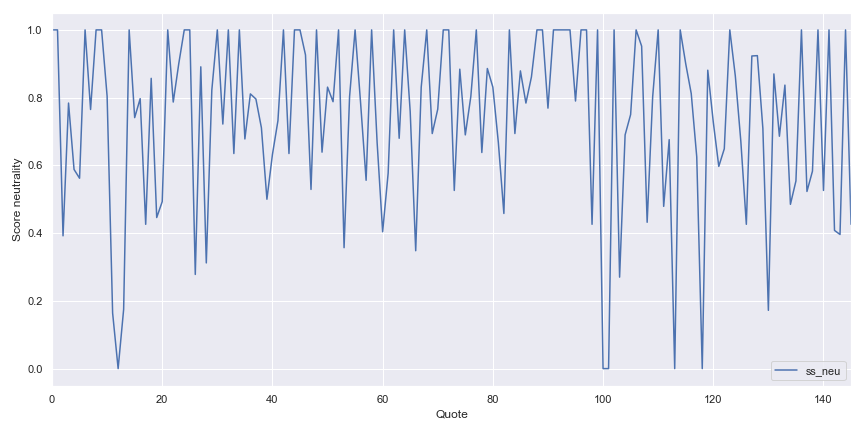
Comme nous pouvons le voir, les citations du docteur passent par différentes phases pendant un épisode mais la plupart du temps le docteur est neutre dans son discours. Dans la figure suivante, il y a une autre illustration du sentiment dans la citation du docteur avec un graphique de la positivité et de la négativité de la citation.
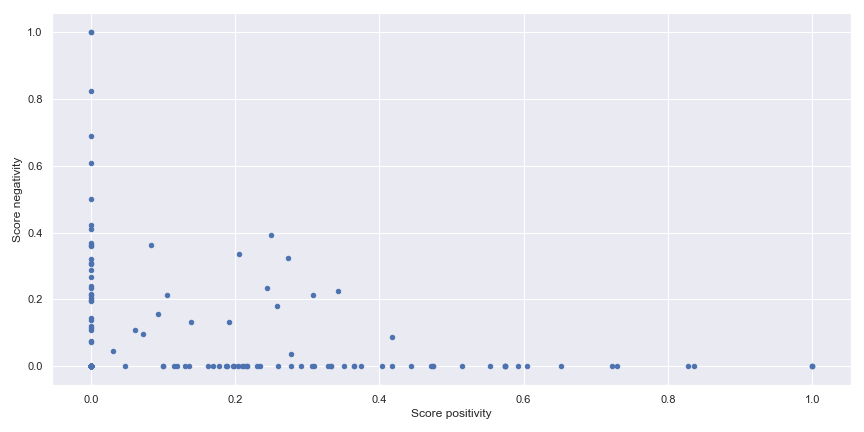
Conclusion
Cet article était une introduction à mon dataset kaggle avec une très brève introduction pratique à NLTK, j’ai quelques idées sur les choses à faire avec ce dataset et je vais définitivement l’utiliser pour faire des expériences autour du NLP dans le futur. N’hésitez pas à me contacter si vous avez des remarques sur le dataset, les applications, etc.
Références
- Dataset Doctor Who sur Kaggle — Kaggle
- The Simpsons by the Data (Kaggle) — Kaggle
- Scripts Doctor Who sur Chakoteya — chakoteya.net
- Doctor Who Guide — guide.doctorwhonews.net
- NLTK — nltk.org
- Text Analytics for Beginners using NLTK — datacamp.com
- Word Cloud en Python — datacamp.com
- VADER Sentiment — GitHub
- Using VADER to handle sentiment analysis with social media text — t-redactyl.io