
Récupération d'informations musicales avec LibROSA et Beat Saber
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Dans cet article, je vais illustrer certains des travaux autour de l’information musicale sur lesquels je travaille depuis les dernières semaines appliqués à un jeu spécifique Beat Saber.
Beat Saber, qu’est-ce que c’est ?
Beat Saber est un jeu de rythme en Réalité Virtuelle (VR) sorti en 2018 par Beat Games qui, soit dit en passant, a été récemment acheté par Facebook. Le principe du jeu est que dans votre casque VR, vous êtes immergé dans un monde 3D où vous devez détruire les blocs et éviter les obstacles (alignés avec la chanson jouée). Je vous invite à regarder la dernière vidéo qu’ils ont publiée sur leur chaîne YouTube pour comprendre la logique derrière le jeu.
Pour moi, c’est LE JEU QUI MONTRE À QUEL POINT LA VR EST COOL, et c’est un incontournable pour ceux qui sont curieux de la VR (le jeu est disponible sur la plupart des casques du marché).
Le jeu a une liste de pistes qui ont été créées par Beat Games, et elles sont cool, mais sur PC il y a une communauté qui développe ses propres pistes pour le jeu (UGC) avec la chanson de leur choix, le principal endroit où cet utilisateur publie du contenu est bsaber.com.
Le site Web semble être toléré par Beat Games, et je pense que c’est ce qui rend le jeu populaire.
J’ai décidé il y a quelques semaines de construire un scraper des chansons sur ce site Web (même travail que dans mon article précédent, toujours pas le propriétaire donc je ne partage pas) pour plusieurs choses :
- Dans cet endroit, j’ai un marché où j’ai des utilisateurs qui proposent et notent du contenu, donc un endroit parfait pour construire un jeu de données autour d’un moteur de recommandation
- Quand j’ai regardé le catalogue massif du site Web, la plupart de mes chansons préférées n’étaient pas là, alors pourquoi ne pas construire à partir des chansons actuelles disponibles un système ML qui pourrait construire des niveaux basés sur la chanson que vous voulez utiliser.
Sur ce dernier point, quand j’ai présenté mon idée à certains de mes amis, ils m’ont redirigé vers le travail d’OXAI et leur projet DeepSaber, et oui, c’est ça (c’est incroyable ce qu’ils ont accompli). Je prévois d’utiliser le travail qu’ils ont fait pour m’aider à construire mon système dans le futur (mais j’ai encore besoin de monter en compétence sur le deep learning).
Ma première hypothèse pour travailler sur le recommandeur et le générateur était d’analyser directement les pistes et les chansons produites par la communauté, commençons par la chanson.
Description de la situation
L’un des packages les plus populaires en Python pour faire de l’analyse musicale s’appelle libROSA, et je vous invite à regarder la présentation qui a été faite par Brian McFee sur le package.
Pour cet article actuel, j’utilise la version 0.7 du package.
Pour illustrer les concepts autour de l’analyse musicale, mes références principales sont :
- Les définitions/schémas trouvés dans le livre fundamentals of music processing de Meinard Muller qui semble être la référence dans le domaine du traitement musical

- La chaîne YouTube 3Blue1Brown qui fait un travail fantastique pour expliquer les concepts scientifiques (Mon Dieu, j’aurais aimé avoir ce genre de ressources quand j’étais étudiant en ingénierie)

- Cet excellent dépôt fait par Steve Tjoa, un ingénieur de Google que je recommande vivement ; qui mélange libROSA, le livre de Mueller et d’autres ressources autour de la récupération d’informations musicales.
J’ai décidé de choisir deux chansons pour être mes cobayes :
- L’une des chansons électro les plus cool sorties au cours de la dernière décennie était Midnight city de M83
- L’autre, vous allez me détester c’est Toss a coin to your Witcher de Sonya Belousova & Giona Ostinelli (Je sais que la chanson était sortie de votre tête, mais maintenant elle est de retour)
Ces deux chansons ont des genres différents, et je pense qu’elles pourraient être un bon départ car leurs avis d’utilisateurs sont bons sur bsaber.com. Commençons l’analyse des chansons.
Récupération d’informations musicales
La chanson utilisée en arrière-plan d’un niveau dans Beat Saber peut être vue (comme toutes les chansons) comme un signal audio. Voyons quelques concepts.
Amplitude
Le son génère un objet vibrant qui cause un déplacement et une oscillation des molécules d’air qui produisent des régions locales de compression et de raréfaction, dans le livre de Mueller, il y a une illustration claire de ce phénomène.
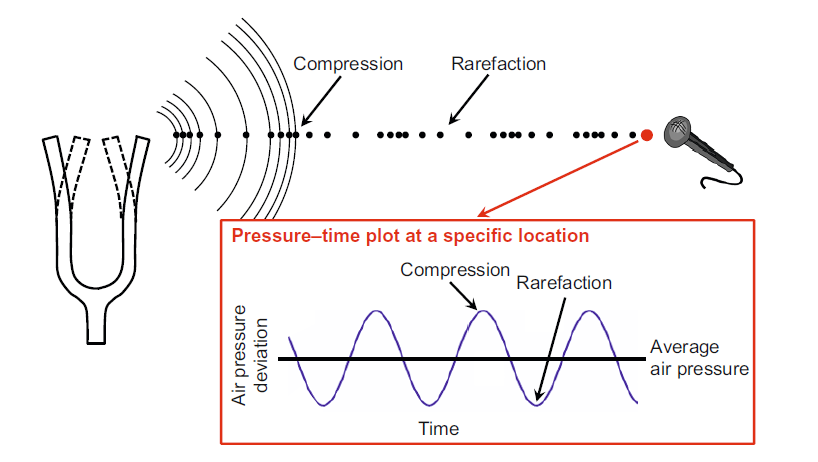
L’enregistrement sonore équivaut à capturer les oscillations de la pression de l’air à un moment spécifique (la périodicité de la capture s’appelle le taux d’échantillonnage sr). Dans LibROSA pour construire ce genre de diagramme, vous pouvez utiliser cette commande :
import librosa
# Pour charger le fichier, et obtenir l'amplitude mesurée avec le taux d'échantillonnage
amplitude, sr = librosa.load(path_song)
# Pour tracer le graphique pression-temps
librosa.display.waveplot(amplitude, sr=sr)Et pour nos deux chansons, voici leur graphique pression-temps.
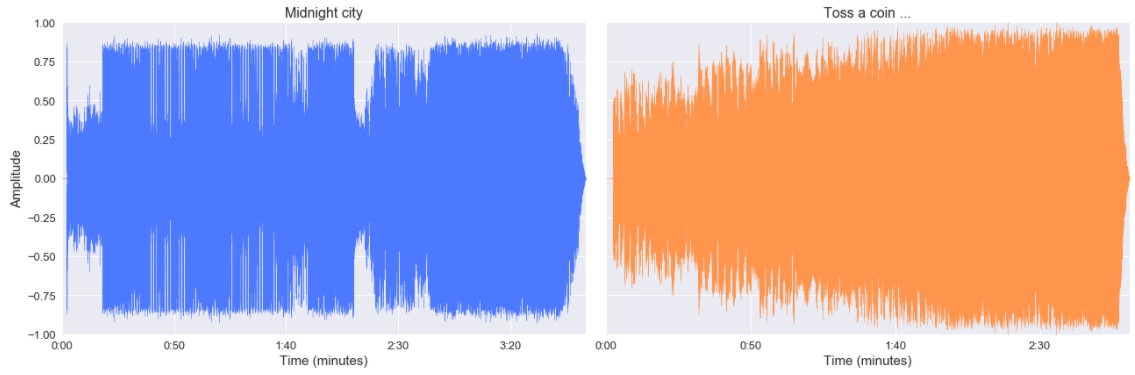
Comme nous pouvons le voir, les deux chansons ont des formes d’onde différentes, la chanson de M83 semble avoir plus de phases que celle de The Witcher (avec des périodes “calmes” au début et autour de deux minutes). Cette visualisation offre une bonne illustration, mais zoomons (au milieu des chansons).
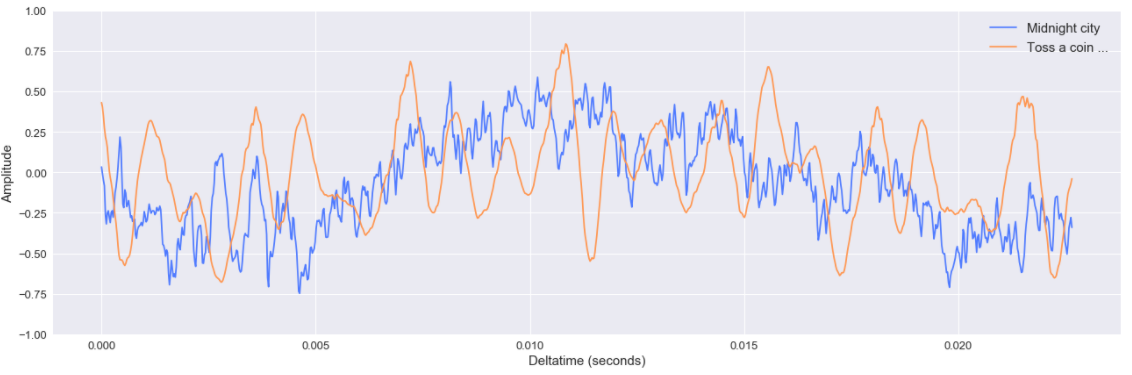
Comme nous pouvons le voir, Midnight city semble plus complexe (bruyante ?) en termes d’oscillation de l’amplitude que celle de The Witcher (mais rappelez-vous toujours que c’est sur une période spécifique de la chanson)
Donc maintenant nous avons quelque chose de plus tangible à analyser avec les niveaux Beat Saber, mais un fait crucial est que ces signaux sont assez complexes, et peut-être qu’il pourrait être utile de les rendre plus simples alors appelons mon ami Fourier.
Transformée de Fourier
Le principe derrière la transformée de Fourier est de décomposer un signal complexe en combinaison de multiples signaux. Je ne veux pas faire toute la théorie derrière le processus (cauchemar scolaire), mais je vous invite à regarder une excellente ressource faite par 3Blue1Brown sur le sujet (merci à mes collègues au Royaume-Uni pour le lien) c’est 20 minutes mais ça vaut le coup.
L’idée avec la transformée est de détecter les signaux simples cachés dans la chanson et d’estimer leur intensité. Pour exploiter cette opération avec libROSA, vous pouvez facilement utiliser ce morceau de code.
###
# Construire la transformée de Fourier
X = librosa.stft(amplitude)
# Appliquer une conversion de l'amplitude brute en décibel
Xdb = librosa.amplitude_to_db(abs(X))
# Construire un spectrogramme
librosa.display.specshow(Xdb, sr=sr, x_axis="time", y_axis="hz")Ce code nous fournit un graphique appelé spectrogramme qui est une représentation du temps versus une fréquence avec une échelle de couleur liée à la puissance du signal (définie par la fréquence). Voici le spectrogramme de nos deux chansons.
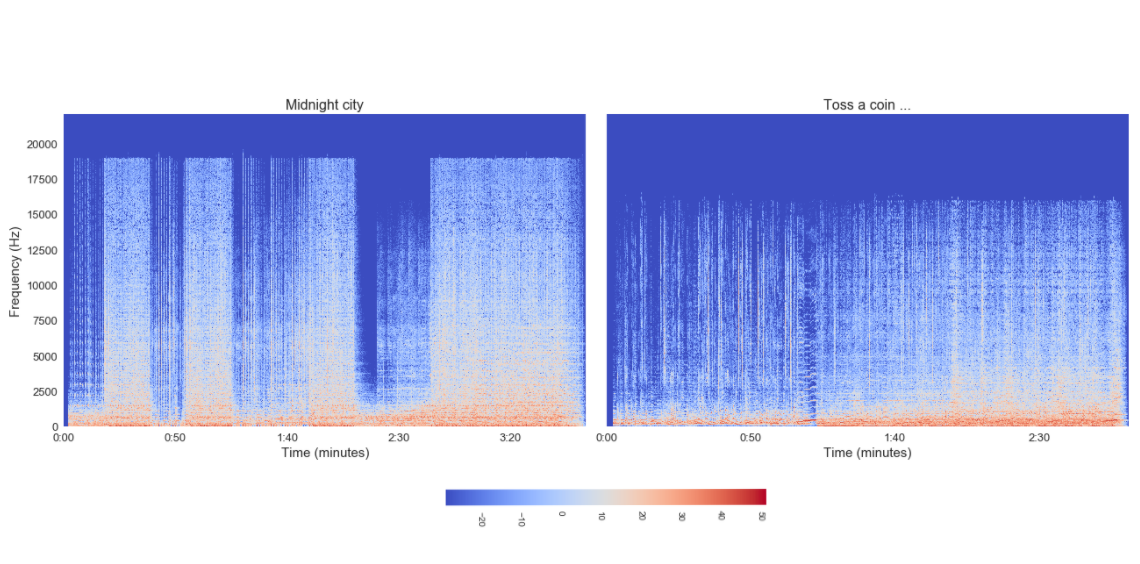
Comme nous pouvons le voir, les deux chansons partagent un spectrogramme très différent :
- Midnight city semble être une chanson composée de signaux avec une fréquence plus élevée que celle de The Witcher
- The Witcher semble plus bruyant que Midnight city ; je ne sais pas comment expliquer ce que je vois
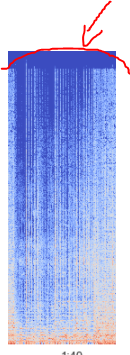
Ce genre de silhouette est présent dans The Witcher mais pas comme celui-ci. Mais le signal même décomposé reste compliqué à analyser (à cause de sa complexité). Pourquoi ne pas le décomposer entre accompagnement et voix.
Séparation voix et accompagnement
Pour faire cela, j’aurais pu utiliser des scripts préfabriqués qui peuvent être trouvés sur le package libROSA, mais ma recherche, quand j’ai commencé à travailler sur ce projet, m’a mené à un article de blog technique de Deezer qui a open-sourcé un outil appelé spleeter.
 Deezer a publié ceci fin 2019 construit sur TensorFlow v1. Je n’ai pas trouvé le papier ou la présentation faite lors d’ISMIR 2019 (grande conférence autour de la récupération d’informations musicales). Si vous voulez entendre les résultats de la séparation (et c’est bon) sur Midnight city et toss a coin, vous devez aller sur ce lien pour télécharger les fichiers séparés dans le dossier spleeter.
Deezer a publié ceci fin 2019 construit sur TensorFlow v1. Je n’ai pas trouvé le papier ou la présentation faite lors d’ISMIR 2019 (grande conférence autour de la récupération d’informations musicales). Si vous voulez entendre les résultats de la séparation (et c’est bon) sur Midnight city et toss a coin, vous devez aller sur ce lien pour télécharger les fichiers séparés dans le dossier spleeter.
Quel est l’impact d’un point de vue amplitude ?
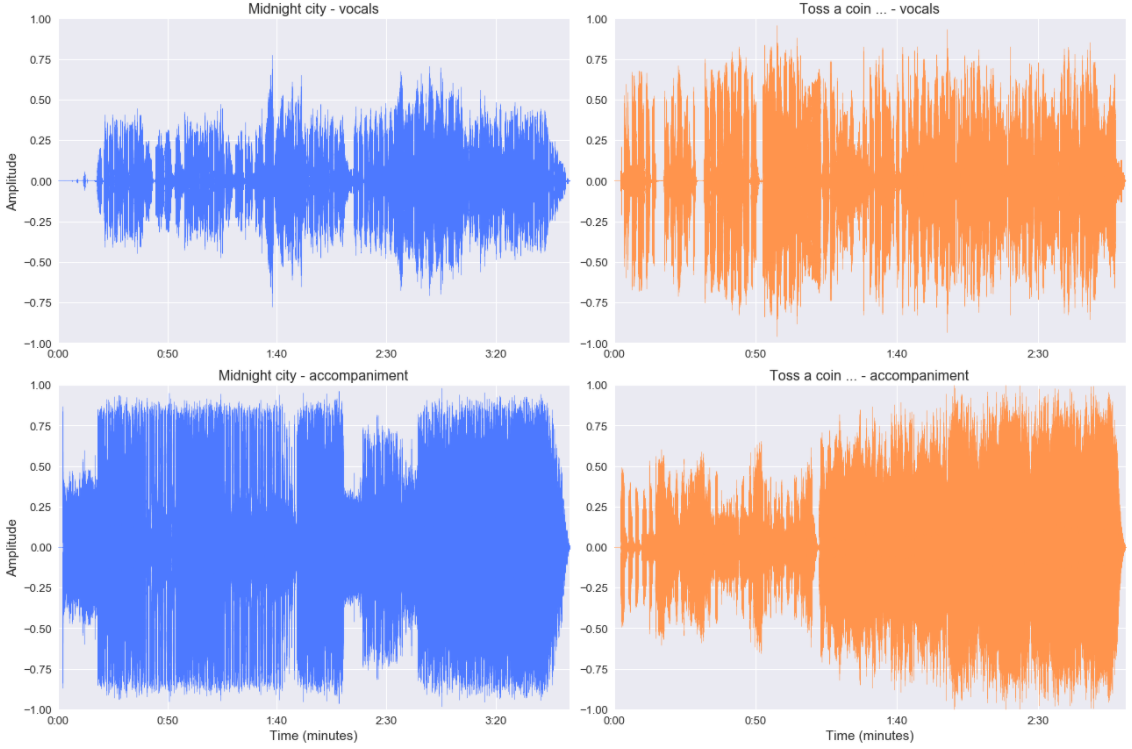
Les signaux sont moins compliqués d’un point de vue général mais toujours très bruyants. (et le zoom illustre toujours cela).
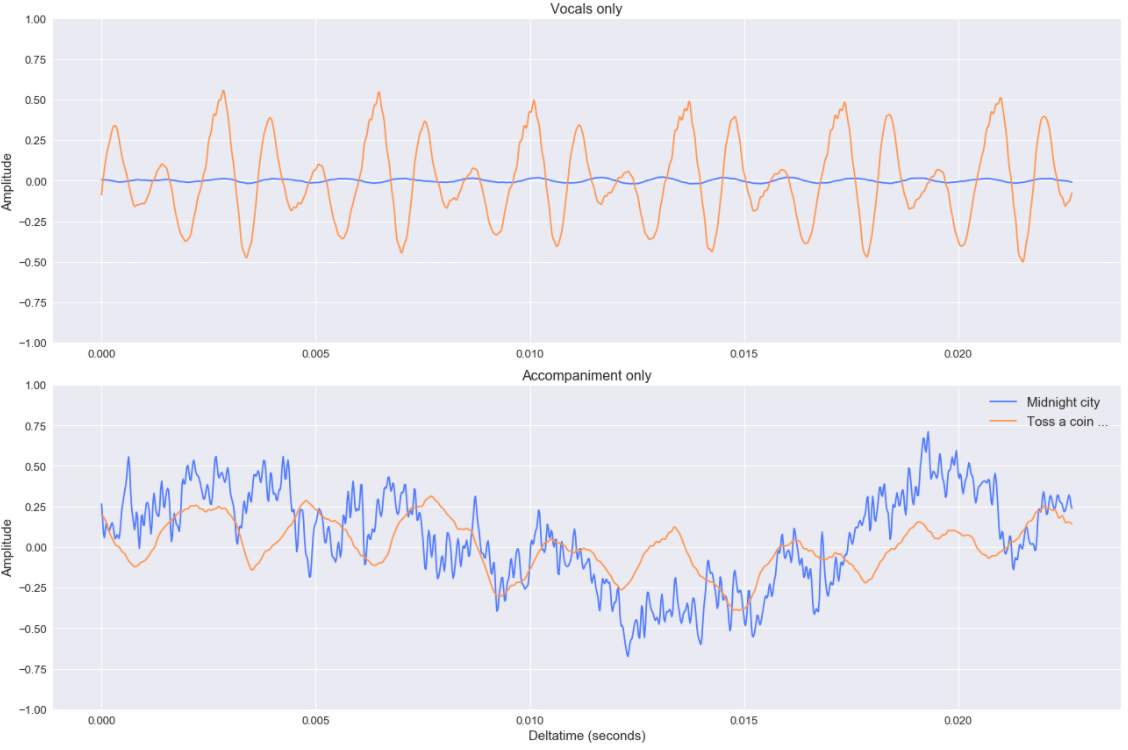
Néanmoins, je pense que ce type de séparation peut être utile dans le contexte de la construction de pistes basées sur l’amplitude de la chanson.
Commençons maintenant à croiser les données de la piste Beat Saber et de la chanson.
Plongée dans le côté Beat Saber
À partir des fichiers téléchargés de bsaber.com, j’ai la chanson que j’ai analysée précédemment et les niveaux (avec les notes, obstacles, etc.). Pour cet article, je vais juste analyser la piste normale et le nombre de notes publiées par seconde sur cette piste (pas le type de notes).
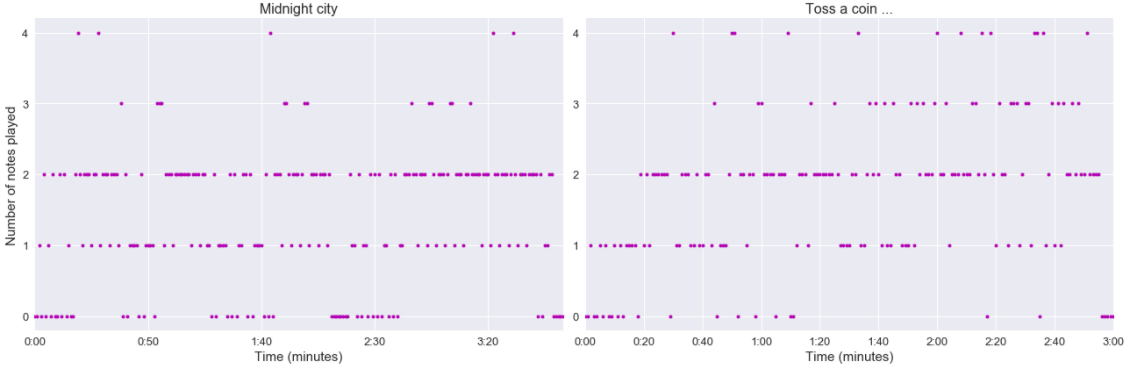
Comme nous pouvons le voir, il y a plusieurs phases sur les notes affichées par seconde dans les chansons, mais ajoutons l’amplitude des chansons dans cette figure. En passant, pour comparer l’amplitude à une échelle de seconde, j’ai dû faire une agrégation par seconde (avec une moyenne de la valeur absolue de l’amplitude).
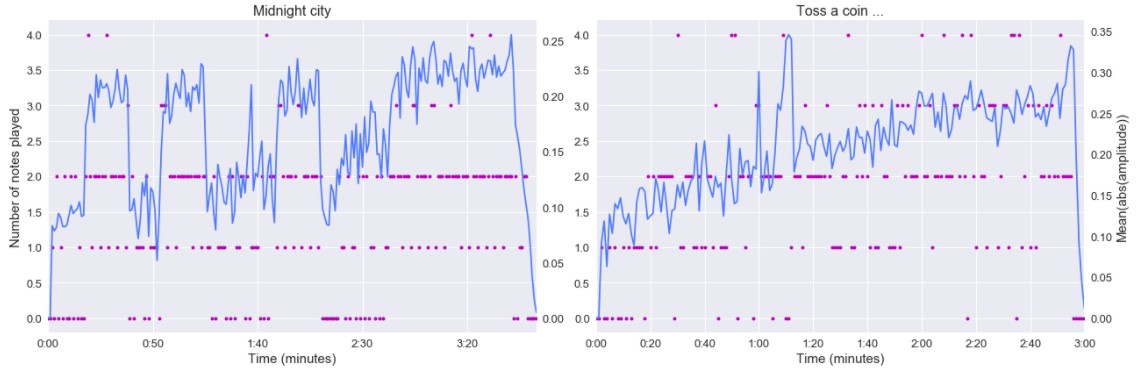
Le nombre de notes jouées semble être hautement dépendant de l’amplitude du signal. Dans Midnight city, nous pouvons distinguer la période de calme avec les 0 notes jouées et la période plus intense avec une amplitude plus élevée. Pour The Witcher, l’analyse est moins claire, mais nous pouvons toujours voir quelques phases dans l’apparition des notes. Concentrons-nous maintenant sur les voix.
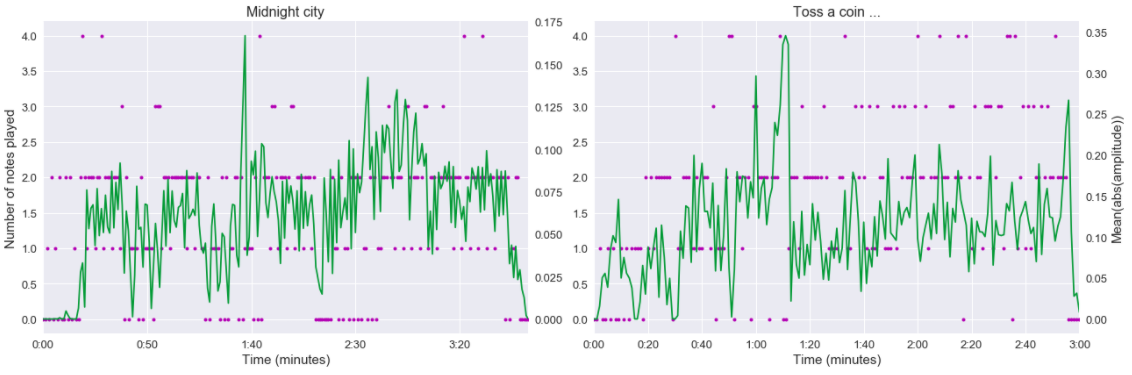
D’après cette analyse, la piste sur Midnight city ne semble pas affectée par les paroles, et pour The Witcher, il y a un impact notable des voix autour d’une minute. Pour finir, je vais croiser le spectrogramme avec les notes jouées (j’ai toujours dû faire une agrégation par seconde, j’ai décidé dans ce cas de prendre le max).
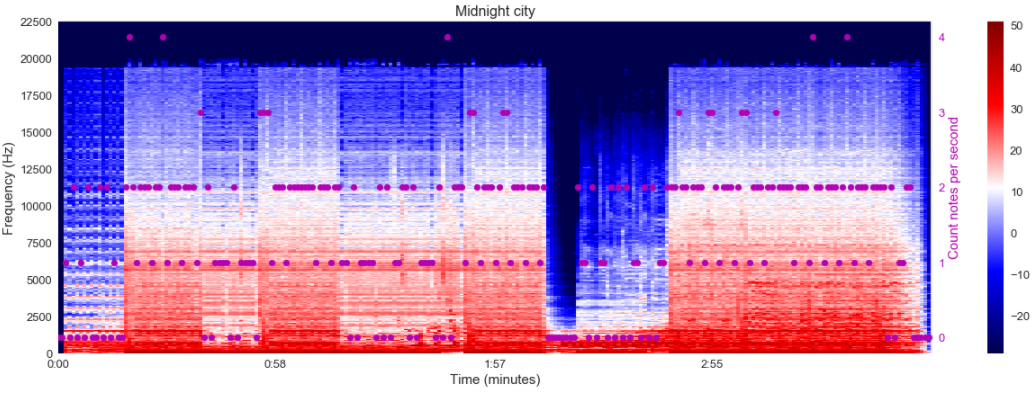
Du spectrogramme de Midnight city, il y a un modèle intéressant qui semble apparaître, la zone de la chanson qui a plus de hautes fréquences semble avoir moins de moments 0 notes que celle avec une fréquence plus basse.
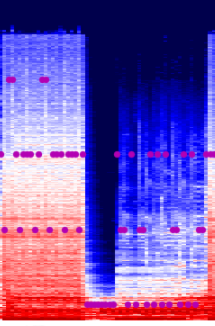
Pour The Witcher, le spectrogramme est peut-être moins expressif.
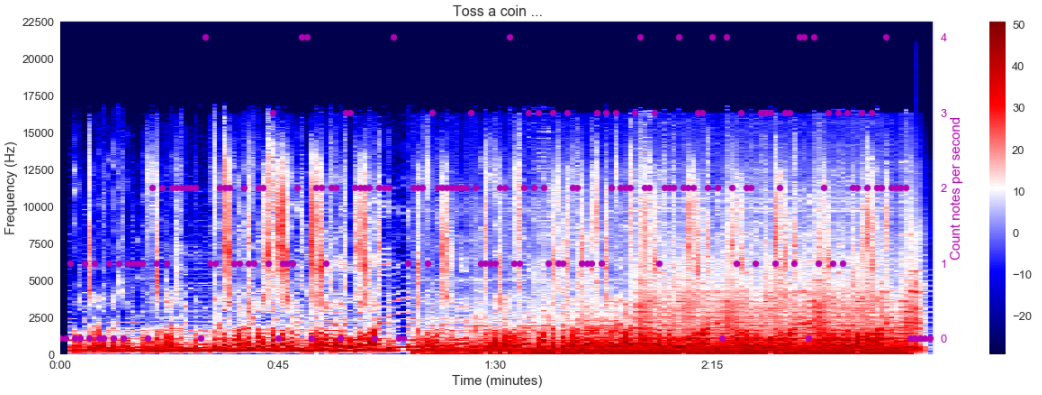
Dans l’ensemble, de mon point de vue, l’analyse du spectrogramme peut donner des aperçus passionnants qui pourraient être peut-être utiles pour construire un modèle pour des pistes basées sur la chanson.
Conclusion
Cet article était une brève introduction à l’analyse musicale ; il y a un domaine à explorer, et essayer de construire des systèmes comme un moteur de recommandation ou des constructeurs de pistes autour de cela va être amusant.
 Pour mes prochaines étapes sur ces sujets :
Pour mes prochaines étapes sur ces sujets :
- Construire un scraper plus robuste pour collecter des données plus propres autour des évaluations des utilisateurs
- Faire une analyse globale de toutes les chansons (basée sur toutes les nouvelles données collectées)
- Analyser en profondeur le travail fait par OXAI autour de la construction de pistes (ils ont basé leur système sur quelque chose initialement basé sur Dance Dance Revolution)
- Plonger dans les conférences sur la récupération d’informations musicales pour en apprendre plus sur ce sujet
- Construire des moteurs de recommandation ….
Références
- Beat Saber — beatsaber.com
- Facebook — oculus.com
- bsaber.com — bsaber.com
- OXAI — oxai.org
- projet DeepSaber — oxai.org
- libROSA — librosa.github.io
- fundamentals of music processing — springer.com
- dépôt — GitHub
- Steve Tjoa — stevetjoa.com
- article de blog technique — deezer.io
- Dance Dance Revolution — arXiv