
Être plus productif et autonome pour produire des applications ML avec AWS Sagemaker
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Dans cet article, il y aura un aperçu du service AWS Sagemaker. L’idée sera de voir de mon point de vue DS comment le service peut résoudre les goulots d’étranglement des data scientists rencontrés pendant le développement d’un système ML.
Description de la situation ML
Pour tester le service, je vais me mettre dans la situation suivante : je suis un data scientist travaillant pour le site Web hearthpwn, un site Web communautaire où les membres partagent des decks pour le jeu de cartes Hearthstone.
Mon environnement de développement actuel est une vieille machine Linux avec la configuration actuelle :
- CPU : Intel(R) Xeon(R) CPU W3565 @ 3.20GHz
- RAM : 16Go de DDR quelque chose (rien de récent)
- GPU : Lol, qu’est-ce que vous pensiez
Je dois travailler sur un classificateur de deck car la plupart des utilisateurs n’associent pas un deck avec un archétype, et cela dégrade la navigation sur le site Web. J’ai actuellement un pipeline construit par les ingénieurs de données, qui déverse avec un processus chaque jour les decks scorés et les decks à scorer et quelques informations sur les cartes.
Ce cas d’utilisation est principalement un copié-collé de celui que j’ai utilisé dans mon article pour metaflow, juste reformulé pour l’article.
J’ai développé une preuve de concept élémentaire pour construire un estimateur d’archétype de deck ; vous pouvez trouver le code ici. Les étapes du processus sont :
- Traitement : Collecter les données de deux fichiers, un pour entraîner le modèle et un échantillon de données à scorer et faire l’encodage nécessaire sur les données utilisées pour entraîner un modèle, l’évaluer et les données à scorer.
- Entraînement : Entraîner, le modèle de forêt aléatoire le plus basique avec scikit-learn
- Évaluation : Faire quelques évaluations de la précision du modèle avec des métriques personnalisées (un héritage total de mon processus de recommandeur et peut-être pas utile du tout, mais qui s’en soucie)
- Scoring : Scorer l’ensemble de scoring avec le modèle et construire une prédiction
Donc maintenant, quelles sont mes problématiques en tant que data scientist :
- J’ai besoin de puissance de calcul (CPU plus puissant, accès à un GPU) car ma machine locale est dépassée, et je dois tester rapidement d’autres modèles sans gérer tous les environnements, etc.
- Je dois exécuter mon code à distance pour construire un modèle et faire des prédictions quotidiennement.
- Je dois explorer un peu plus mes données, mais je n’ai pas le temps.
Et c’est là qu’AWS Sagemaker peut m’aider à concurrencer ces problèmes.
Machine prête pour le ML nécessaire !? : Instances de notebook Sagemaker et Sagemaker studio
Le moyen le plus simple d’obtenir une machine prête à faire du travail ML ou DS est d’utiliser l’instance de notebook de Sagemaker. La configuration est relativement facile depuis le portail AWS.
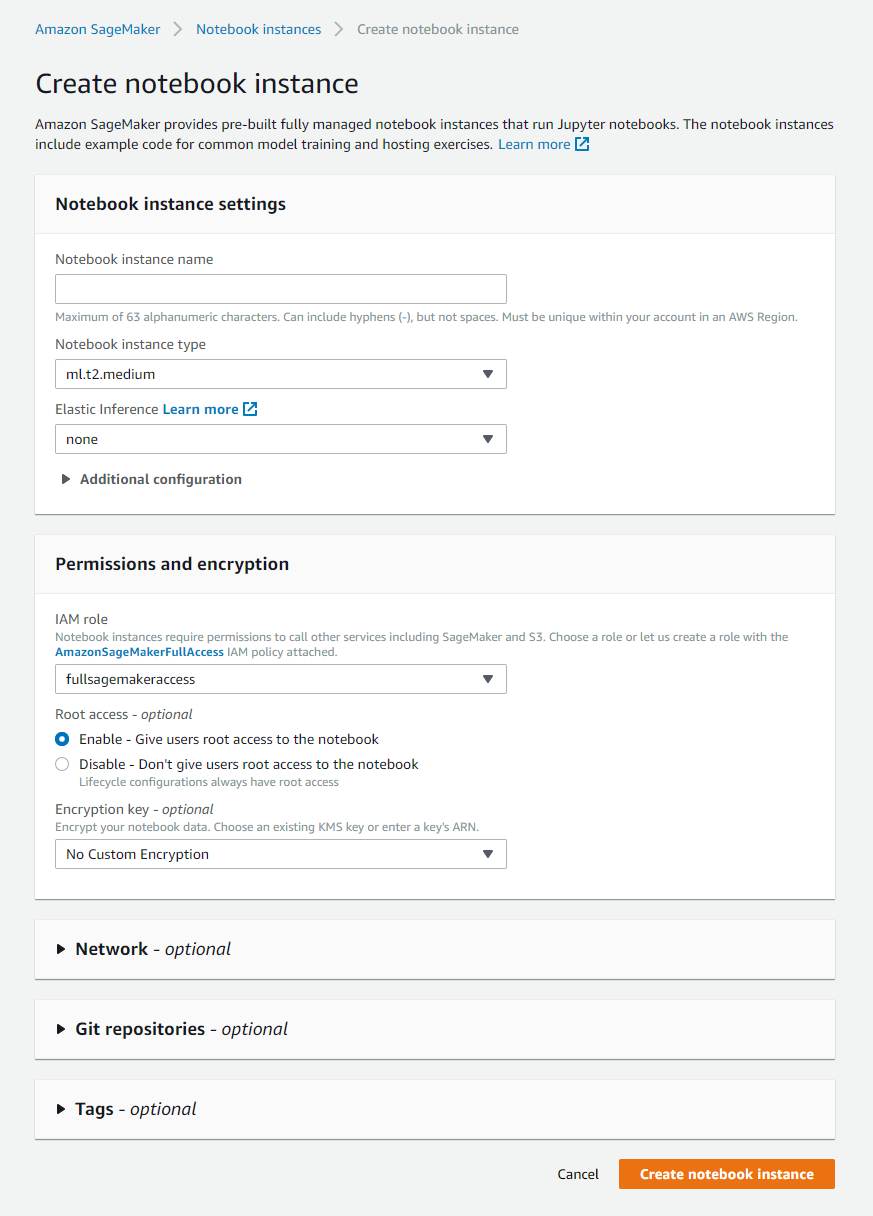
L’instance de notebook offre la capacité de :
- Sélectionner la machine dont vous pouvez avoir besoin pour exécuter vos calculs (contrôle total sur sa configuration ; il y a un aperçu ici de ce qui est disponible)
- L’espace disque disponible
- Donner un rôle pour accéder à d’autres services d’AWS (dans mon cas, j’ai utilisé l’accès complet à sagemaker)
- Connecter l’instance à un dépôt (code commit ou d’autres services comme Gitlab)
- Contrôle sur la connectivité (vpc, etc.)
Dans mon cas, j’ai décidé sur mon expérimentation de lancer un m4.large (machine très standard). Néanmoins, comme vous pouvez le voir sur le nom des instances disponibles, il a un préfixe ml, et c’est l’illustration de deux choses intéressantes :
- La machine est accessible via les portails Jupyter ou Jupyterlab.

- L’image installée sur la machine est ubuntu prête à utiliser l’image ML avec de nombreux noyaux préparés pour faire du traitement ML (avec ou sans fonctionnalité GPU si l’appareil en a un).
Ces noyaux ressemblent à ceux disponibles dans l’AMI de deep learning, une image utilisable sur chaque machine AWS et à jour sur les versions des bibliothèques disponibles.

La première configuration est un peu plus longue, mais après cela, l’instance de notebook est facilement arrêtée et redémarrée en moins de 5 minutes, et une chose cruciale est qu’aucune donnée n’est perdue après un redémarrage (persistance de l’espace de travail). Mais il y a un hic, toutes les données sauvegardées sûrement, mais tout ce qui est lié au système comme la création d’environnement conda, les variables d’environnement sont perdues après un redémarrage. Néanmoins, Amazon est intelligent, et ils ont développé une fonctionnalité pour “sauvegarder” ce genre d’informations, et cela s’appelle configuration de cycle de vie.
Ces scripts sont utilisés lorsque vous démarrez (redémarrez) le notebook ou lors de l’initialisation de l’instance pour définir des éléments système spécifiques pour l’utilisateur. Comme vous l’avez remarqué dans mon cas, j’ai mis une variable d’environnement liée à l’emplacement des données sur S3. Avec cette configuration de cycle de vie, je peux dire à chaque démarrage de définir la variable d’environnement AWS_SAGEMAKER_S3_LOCATION.
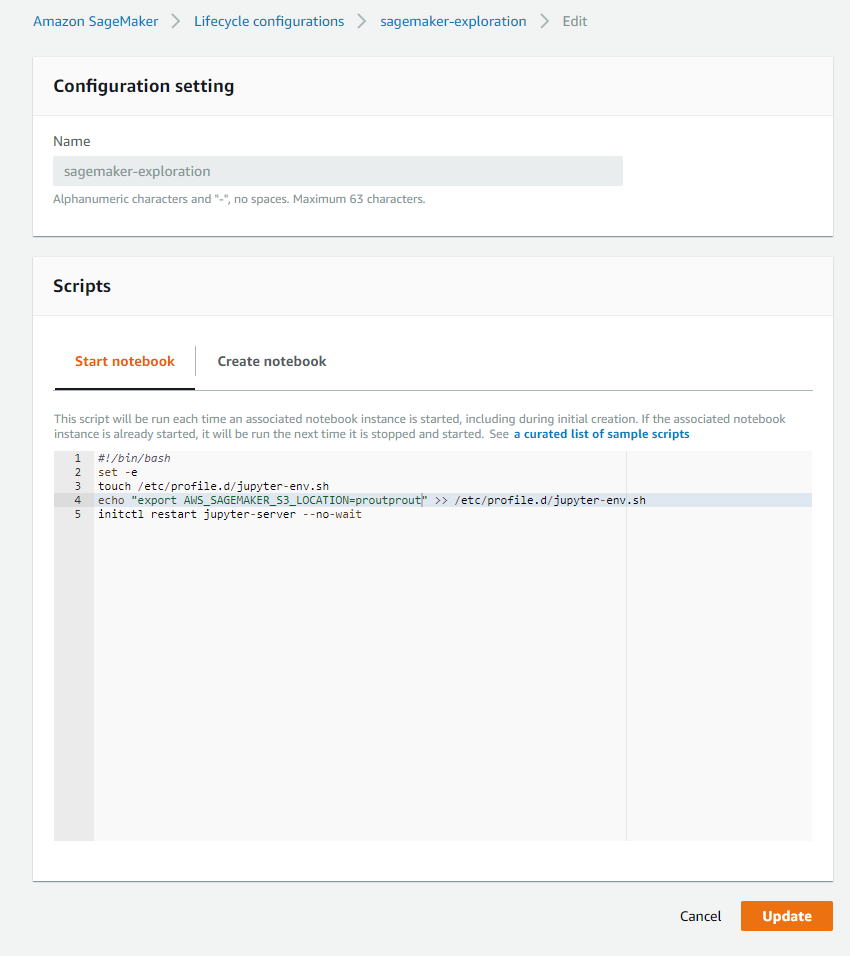
Il y a de nombreux exemples dans ce dépôt pour définir divers éléments comme un environnement conda.
L’instance de notebook est une fonctionnalité cool et peut aider les data scientists à configurer facilement l’infra pour le calcul GPU, la parallélisation, etc. Dans notre cas, il y a un gain précieux en passant de notre machine locale au m4 large. Il y a une comparaison (sur dix exécutions) de la durée de chaque phase pour chaque type de machine.
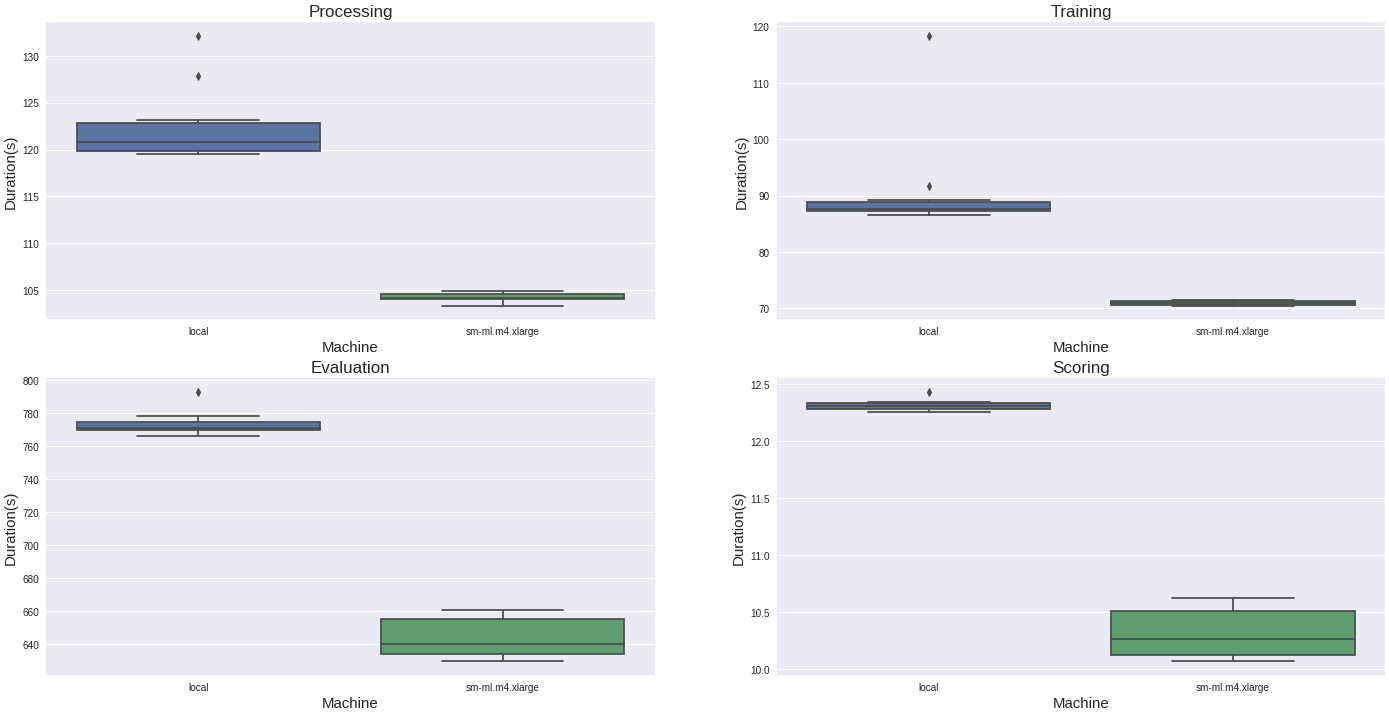
Le changement de machine offre une diminution de 20% du temps de calcul sur chaque phase, donc c’est bien.
Mais Amazon a publié une autre solution pour interagir avec les notebooks et l’instance EC2, et ça s’appelle Sagemaker studio, mais ce service me mitigue. C’est intéressant car il offre toutes les choses liées au notebook mentionnées précédemment. Avec un twist, vous pouvez lancer plusieurs machines en fonction de votre besoin pour chaque noyau.
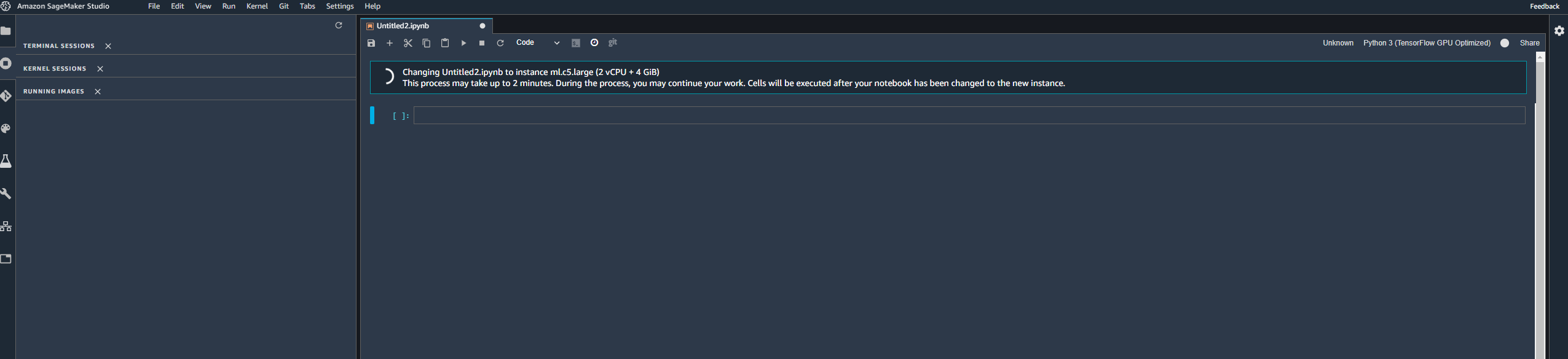
(comme dans ce cas, j’ai décidé d’utiliser un autre type de machine avec mon noyau TensorFlow)
Le choix de la machine semble limité, et je sens que c’est un gouffre financier lors de l’exécution de certains tests. Néanmoins, je suppose que ce service cible une entreprise qui doit gérer plusieurs utilisateurs qui ont besoin de changer de machine régulièrement selon leurs besoins.
Intéressant vraiment, mais je préfère toujours l’instance de notebook classique.
Jetons maintenant un œil aux jobs Sagemaker.
Exécuter du code ML à distance !? Les jobs Sagemaker
Dans mon cas, je voudrais exécuter les différentes parties de mon code depuis ma machine locale mais sans utiliser les ressources qui sont sur le cloud, et c’est là que les jobs Sagemaker peuvent aider. Vous pouvez trouver tout le code que j’ai construit ici, mais ce tutoriel inspire le processus global. Pour cet article, je vais me concentrer sur une seule partie pour expliquer les concepts derrière les jobs.
Commençons par le mécanisme qui va déclencher le job à distance.
Il y a deux points principaux sur le code :
- La définition du processeur : Dans ce cas, notre code utilise un processeur scikit-learn (mais il y en a un pour d’autres frameworks) ; vous pouvez sélectionner la version du framework et sur quelle machine il peut fonctionner. Le processeur, quand il va exécuter des jobs, va faire fonctionner une machine avec la version de scikit learn nécessaire (je présume que c’est basé sur des conteneurs et construit au-dessus d’AWS batch)
- L’exécution du processeur : Depuis l’initialisation, il y a principalement trois parties à cette exécution : Emplacement du code à exécuter, les entrées (ProcessingInput) qui sont définies par où se trouve les données (localement ou à distance) à utiliser et où elles seront sur la machine qui va exécuter le code, les sorties (ProcessingOutput) même logique que l’entrée et les paramètres : Vous pouvez ajouter des paramètres/arguments pour votre exécution
Jetons un coup d’œil rapide au format du job.
Il n’y a pas trop de grande affaire ; il suffit de mettre à jour comment gérer l’entrée et la sortie par de simples déclarations qui pointeront vers les entrées/sorties définies par la destination/source précédemment (il y a un schéma rapide pour connecter les deux scripts).
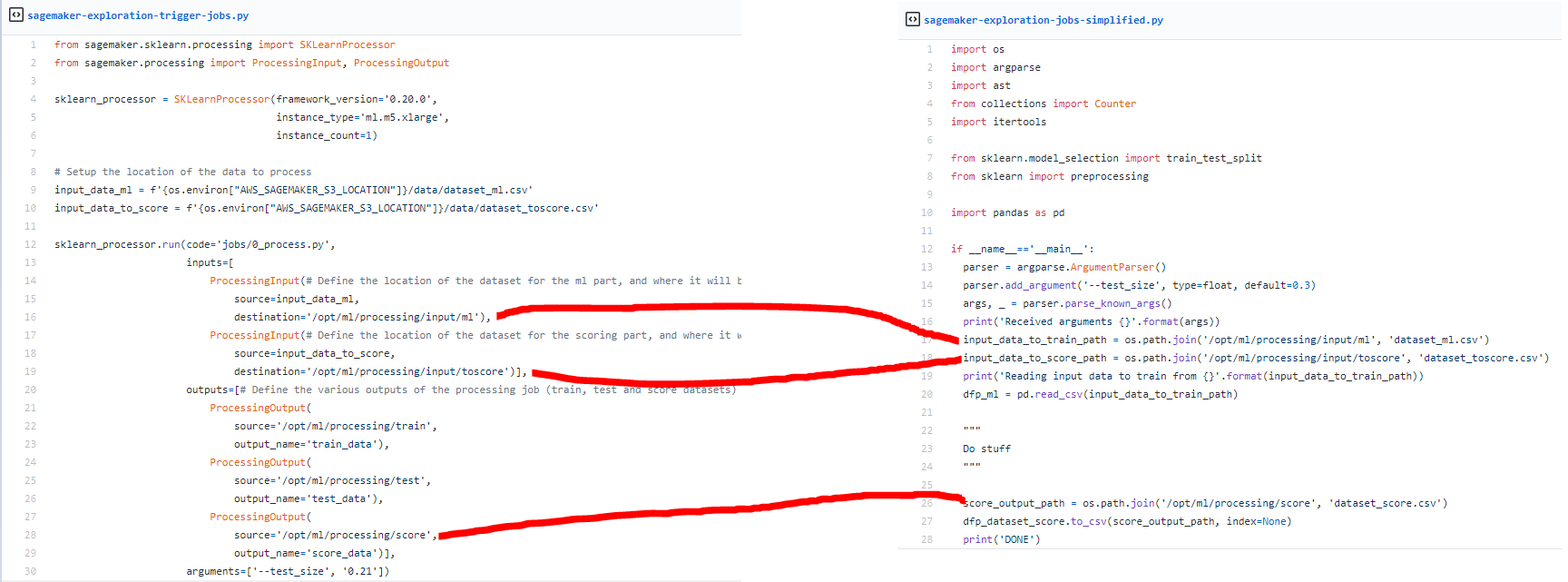
Honnêtement, je trouve le processus des jobs simple et direct et plein de potentiel pour faire une recherche de grille avec ce processus sans bloquer une machine pour le faire. Et une autre chose cool est que vous pouvez collecter des informations sur les sorties et l’exécution globale du job (utile pour connecter les jobs).
Et en termes de performance de ce service, je serai honnête, à machine équivalente sur Sagemaker, les jobs sont un peu plus longs car il y a la configuration de la machine, mais ce n’est pas une augmentation folle (comme 10% de temps en plus).
Si vous regardez plus au tutoriel que j’ai mentionné précédemment pour le job d’entraînement, j’ai utilisé un job d’entraîneur. Dans ce cas, c’est très similaire en termes d’entrée et de fonctionnalité, mais sur l’exécution, le job de l’entraîneur semble plus lent. Sur le notebook, la valeur moyenne pour les temps d’entraînement est d’environ 72 secondes sur les jobs d’entraîneurs ; c’est environ 372 secondes ; je suppose que les jobs peuvent être utilisés dans un contexte d’inférence, donc leur configuration est assez différente mais honnêtement, utilisez juste le processeur et pas l’entraîneur du framework.
Et pour finir, jetons un œil à une sorte de fonctionnalité d’assistant pour les data scientists, le composant autoML de Sagemaker
Besoin d’assistance !? Sagemaker autopilot et expérience
L’autopilot est l’une des fonctionnalités qui a été publiée l’année dernière. Cette fonctionnalité fait écho à un mouvement appelé autoML dans le monde du machine learning. L’idée est de donner les données à un système, ces données doivent être composées de toutes les informations disponibles pour faire les prédictions, et le plus important quelle colonne doit être prédite et le système fera toute l’ingénierie des fonctionnalités et l’estimation de bons candidats de modèle pour faire la prédiction (essentiellement le travail d’un data scientist).
Quoi et vous voulez promouvoir ça !? Oui, pourquoi pas, je vous conseille de lire cet article de Bojan Tunguz qui dresse un bon portrait des problématiques autoML. Revenons au service autopilot. Je ne vais pas montrer mon expérience en détail, mais mon notebook de déclenchement est ici ; mais j’ai suivi ce tutoriel et le résultat est assez impressionnant.
Après quelques minutes, le script vous offre deux notebooks, un avec une analyse du jeu de données et un avec le prédicteur pour le problème lié au jeu de données ; je devrai vous inviter à y jeter un œil, mais essentiellement :
- Le premier notebook montre quelques opérations effectuées sur l’entrée (avec quelques stats) ; dans mon cas, le jeu de données était assez simple, donc pas de vraie ingénierie de fonctionnalités, mais si vous lancez le processus dans les données de cet article, vous verrez plus de détails sur l’ingénierie des fonctionnalités.
- Le deuxième notebook est plus le processus derrière la construction d’un modèle pour construire un prédicteur multi-classes et tous les modèles qui sont utilisés (et comment le servir rapidement)
Honnêtement, je trouve l’initiative cool. C’est facile à configurer, mais je ne suis pas sûr que ce soit super impressionnant. En termes de traitement, c’est en quelque sorte la même chose faite d’un jeu de données à un autre (force brute xgboost) avec une grosse machine, et la taille du jeu de données d’entrée ne pourrait pas dépasser 5Go (et c’est petit de mon point de vue). Un autre point à garder à l’esprit est que cette fonctionnalité autopilot est directement intégrée dans le studio Sagemaker avec le concept d’expérience.
Néanmoins, je pense que cette approche pourrait être une autre façon de construire un modèle de référence pour comparer avec d’autres approches construites par des humains (avec plus de détails dans l’ingénierie des fonctionnalités et la prédiction) et trouver le bon ajustement.
Conclusion
Dans l’ensemble, mon exploration d’AWS Sagemaker a été agréable ; j’ai trouvé qu’AWS s’attaque vraiment à ce qui pourrait être nécessaire pour un data scientist pour travailler dans le cloud (repérage facile de machine, prêt pour l’image ML et déclencher le travail à distance).
Mais il y a beaucoup d’autres services dans Sagemaker que je n’ai pas utilisés :
- Le workflow humain : pour offrir la capacité d’annoter et d’évaluer la prédiction par un humain (toujours le meilleur outil d’annotation et de vérification)
- La marketplace : Endroit où vous pouvez utiliser un modèle pré-entraîné (gratuit ou en les payant), plutôt cool pour faire du transfer learning dans le domaine du DL.
- Les jobs d’inférence pour exécuter un job de prédiction par lots et une prédiction en direct, passionnant, mais je pense qu’un pipeline de niveau production a plus de contraintes qu’un service de modèle derrière une API (mais cool que ce soit là).
Pour conclure, et je veux être clair sur ce service, il y a une contrepartie de tous ces services faciles à utiliser, une taxe Sagemaker essentiellement pour une machine similaire pour une instance de notebook, vous payez 40% de plus. AWS n’est pas un ‘sponsor’ pour les gens qui veulent faire du ML, et il y a beaucoup de services pour commencer à travailler sur des trucs ML DS avec peu de coût (Kaggle ou Google Colab). Cette taxe n’est pas une mauvaise chose pour moi, vraiment, mais gardez juste ça à l’esprit.
Bonus : Interagir avec les services AWS depuis Slack avec AWS Chalice (et l’API slack)
En écrivant cet article, j’en avais marre d’aller toujours sur le portail, entrer mon code en deux étapes, aller dans le menu sagemaker pour lancer l’instance de notebook (utiliser des portails est ennuyeux quand vous devez aller dans beaucoup de fenêtres, mettre du code, etc. à chaque fois). J’ai décidé de voir l’effort pour déployer une application qui fera toute l’interaction entre AWS et un service que j’utilise dans un workflow quotidien comme Slack (j’ai entendu dire que c’était difficile).
J’ai creusé un peu sur Internet et mon travail basé sur ces deux ressources, un article de Paweł Hajduk et un autre article de Yogesh Ingale autour de l’utilisation d’AWS chalice avec Slack.
Je connaissais un peu Chalice ; c’est comme un mélange entre Flask et Zappa (c’était mon super combo il y a quelques années pour déployer des API sur AWS). J’ai essayé il y a quelques années pour sauver mon cul à la fin d’un sprint quand j’ai décidé de déployer une fonctionnalité (et mon PM m’a dit de ne pas le faire 😀). Ce package est super intéressant et invite les gens qui ne sont peut-être pas familiers avec l’API à y jeter un œil pour expérimenter avec.
Le processus pour cette application est simple ; j’ai construit trois endpoints pour trois commandes slash :
- Start_notebook, commande slash pour lister le statut de toutes les instances de notebook sagemaker, et si un nom valide d’un notebook est donné, le notebook sera démarré.
- Connect_notebook, commande slash pour obtenir une URL pré-signée pour se connecter à une instance de notebook en cours d’exécution.
- Stop_notebook, commande slash pour arrêter une instance de notebook en cours d’exécution.
Voici le résultat de quelques interactions avec l’application.
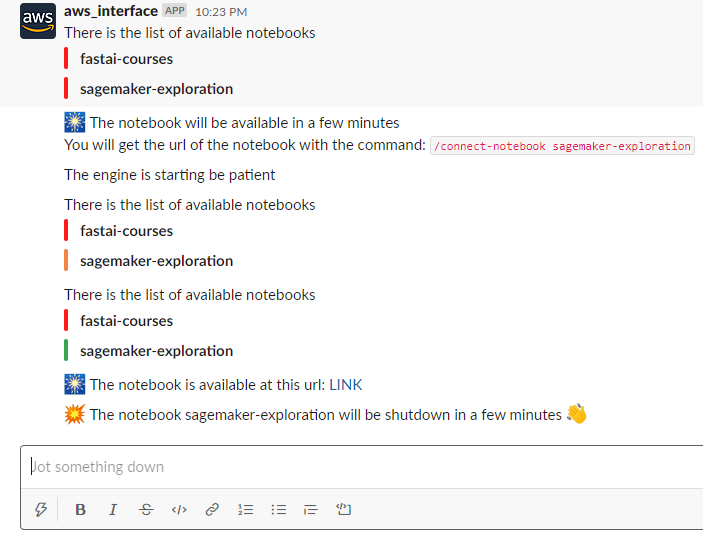
Vous pouvez trouver le code de mon application dans ce dépôt et il y a une démo des commandes utilisées ici.
Références
- AWS Sagemaker — AWS
- hearthpwn — hearthpwn.com
- cet article — Medium / Towards Data Science
- ce tutoriel — AWS
- un avec une analyse du jeu de données — GitHub
- un avec le prédicteur — GitHub
- cet — AWS
- Kaggle — Kaggle
- Google Colab — colab.research.google.com
- article — pattern-match.com
- article — Medium / Towards Data Science
- AWS chalice — GitHub
- Flask — flask.palletsprojects.com
- Zappa — GitHub
- dépôt — GitHub