
Évaluation des systèmes de recommandation (métriques et modèles de base)
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Je me suis concentré sur ce sujet pendant les trois dernières années chez Ubisoft, mais je n’ai jamais trouvé de jeux de données appropriés à utiliser pour des expériences sur mon blog jusqu’à maintenant.
Cet article va lancer une série autour des systèmes de recommandation pour le contenu comme les films, séries TV, jeux vidéo, livres et musique. Avec tous ces confinements, j’ai recommencé à consommer du contenu sur plusieurs plateformes de streaming comme Netflix, Disney+, etc. Je voudrais plonger dans ce domaine pour construire des systèmes de recommandation et m’aider à organiser ma liste de visionnage de contenu.
Je ne vais pas expliquer les systèmes de recommandation car il y a de meilleures références comme ici si vous voulez en apprendre sur le concept. Je vais plutôt concentrer ce premier article sur le choix du processus d’évaluation, qui est critique pour tout algorithme de machine learning. Mais d’abord, commençons par les aspects techniques qui seront utilisés tout au long de cette série d’articles.
Configuration
J’ai construit un petit pipeline pour collecter les données d’un site web français appelé sens critique, où les utilisateurs peuvent partager leurs intérêts sur divers médias de divertissement tels que films, séries TV, jeux vidéo, livres et musique. Sur cette plateforme, les utilisateurs peuvent :
- Mettre en signet des contenus (dire qu’ils veulent le regarder, le jouer, etc.)
- Noter : donner un score entre 1 et 10 à un contenu
- Critiquer : comme une notation en donnant un score au contenu avec un texte de critique libre sur ce contenu
Pour construire des recommandations et gérer les interactions, j’ai créé un like index avec les règles suivantes :
- Si le score est entre 1 et 5, le like index sera 0
- Sinon (plus de 5 en score), le like index sera 1
Sur la communauté de ce site web, il y a des rôles de scout et d’abonné qui peuvent influencer l’affichage de votre contenu (les systèmes de recommandation fonctionnent sur ce site web) et vos intérêts pour impacter votre expérience.
Actuellement, j’ai un dump de données que j’ai collecté avec uniquement des critiques et des notes. Vous pouvez jeter un œil à quelques statistiques sur ce dump dans ce rapport datapane.
Définition des modèles de base et du premier modèle
En général, quand vous développez un système de recommandation (ou tout système ML), avoir au moins un modèle de base est une bonne idée. Dans mon cas, quand j’ai commencé à créer des systèmes de recommandation, j’ai généralement ces modèles de base en tête
- Recommandeur aléatoire (avec du contenu basé sur une période spécifique)
- Recommandeur de contenu le plus populaire (pareil avec du contenu trouvé sur une période spécifique)
Pour la popularité, il y aura deux modèles possibles :
- Popularité par occurrence
- Popularité par somme de critiques/notes positives (avec un like index égal à 1)
Ces modèles utilisent des approches basiques et ne devraient pas être difficiles à battre (#mostpopularrulestheworld), mais c’est toujours bon d’avoir ces modèles pour construire une base pour la construction de nouveaux modèles.
Dans ce cas, le premier système de recommandation que je vais construire et comparer à mes modèles de base est une approche simple mais toujours un bon départ. L’idée est de garder une trace du contenu avec lequel un utilisateur a interagi après une interaction ; le calcul est fait en faisant une agrégation de la somme du like index entre le contenu précédent et le contenu actuel.
Ce modèle offre un niveau minimal de personnalisation mais est toujours meilleur que les bases de référence sélectionnées. Le code lié à ces modèles peut être trouvé dans ce repository (travail en cours).
Regardons maintenant les métriques qui peuvent être utilisées pour évaluer les systèmes de recommandation (de mon point de vue).
Plongée dans les métriques
Pour l’évaluation des modèles précédents, les étapes seront :
- Construire des recommandations pour les personnes qui ont écrit une critique positive (avec un like index égal à 1) le 15 juillet 2021
- Les recommandations seront construites basées sur les données de toutes les activités qui se sont produites avant le 15 juillet
- Les recommandations peuvent prendre deux formes :
- Une plus académique/théorique avec les 25 meilleurs contenus à recommander (toutes catégories mélangées)
- Une plus réaliste avec les cinq meilleurs articles dans chaque catégorie possible, cela ressemble généralement à la chose nécessaire au travail (pas la plus optimale en termes de performance mais c’est lié aux contraintes UX/UI)
Le dernier point est basé sur mon expérience au travail ; vous ne servez généralement pas tous les articles classés et disponibles dans vos applications. Vous devez appliquer des règles alignées avec les contraintes UI/UX (comme vous ne pouvez afficher que X articles de cette catégorie dans ces tuiles spécifiques).
Avertissement:
- Le jeu de données actuel n’est peut-être pas le cas d’usage le plus optimal (focus sur les critiques positives simplifiées avec le like index) mais sera suffisant pour présenter les métriques.
- Les métriques ci-dessous sont, de mon point de vue, les plus utiles que j’utilise quotidiennement pour évaluer mes systèmes mais ne sont pas représentatives de toutes celles disponibles (voir les liens ci-dessous avec quelques ressources pour compléter cet article)
Tout le code utilisé dans cette section peut être trouvé ici (encore une fois travail en cours)
Basique et simple: Hit ratio
Celle-ci est simple, une liste de recommandations est construite pour un utilisateur. Le contenu qui va être aimé était-il dans cette liste :
- Si oui, hit ratio égale 1
- Sinon 0
Pour notre exemple actuel, voici à quoi cela ressemble (Plus grand est mieux) :
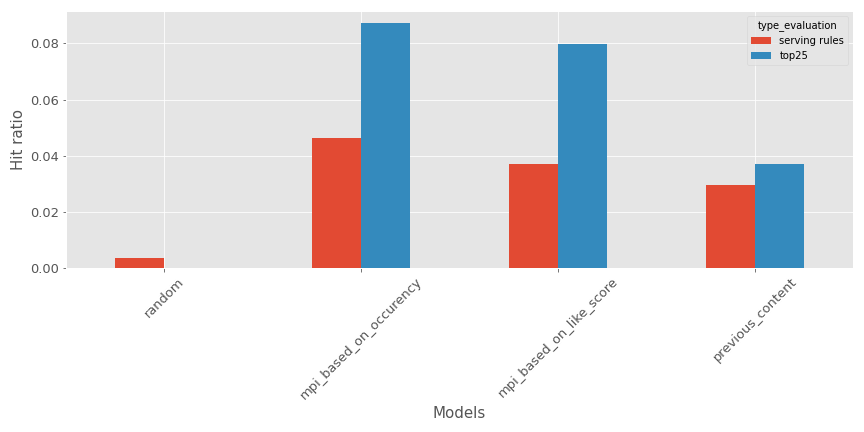
Pour le top 25 morceaux de contenu ou la liste contrainte avec des règles de service, le recommandeur de contenu précédent est un bon #3 derrière les modèles les plus populaires (#1 est celui basé sur l’occurrence du contenu)
De mon point de vue sur cette métrique, sont
- ✅
- est facile à comprendre
- S’adapte à l’application des règles spécifiques
- Fonctionne très bien pour évaluer les modèles déployés en production et servis à l’utilisateur
- ❌
- Pas d’impact de la place du contenu dans les recommandations (même si le contenu est premier dans la liste ou dernier)
Les inconvénients de cette métrique peuvent être contrebalancés par d’autres métriques que nous verrons plus tard.
Construire des recommandations est un problème de classification
Le problème de recommandation peut être vu comme un problème de classification ; vous avez des enregistrements étiquetés avec le contenu aimé et un utilisateur/interaction qui peut être augmenté avec des caractéristiques, alors pourquoi ne pas construire un classifieur basé sur cela ?
La configuration simple est répandue dans le monde du machine learning, donc toutes les métriques de ce domaine peuvent être utilisées (précision, rappel, etc.). Je ne vais pas énumérer toutes les métriques et vous encourage à regarder un package comme scikit learn si vous n’êtes pas trop familier avec ces métriques (avec le glossaire ML de google si vous voulez plus de détails). Mais de cette configuration de la classification, certaines métriques sont très couramment utilisées pour évaluer les systèmes de recommandation :
- mAP (pour mean Average Precision) et mAR (pour mean Average Recall), soyez méticuleux sur le nom et comment calculer les métriques qui peuvent être déroutantes, mais il y a une excellente ressource pour expliquer les métriques ici. Ce n’est pas une métrique que j’utilise habituellement, mais il y a des data scientists autour de moi qui l’ont utilisée, donc je pense que c’est bon de partager
- NDCG (pour Normalized Discounted Cumulative Gain), il y a une brève explication de la métrique et des éléments associés ; j’utilise habituellement l’implémentation trouvée dans ce repository.
Dans notre exemple actuel, voici à quoi cela ressemble (Plus grand est mieux) :
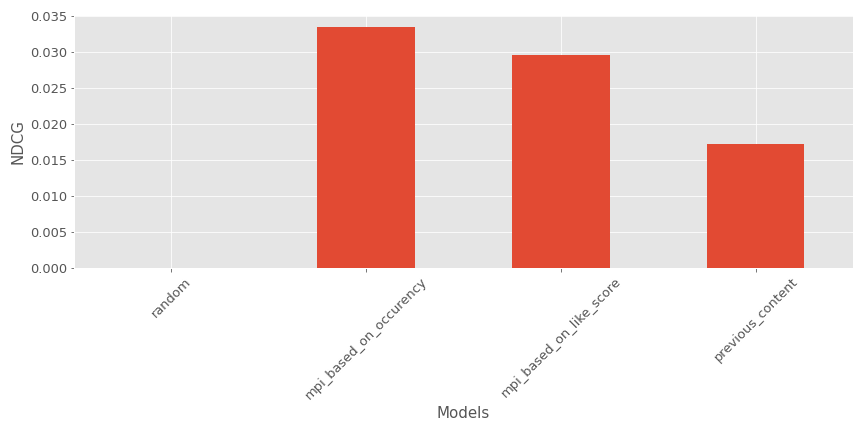
Encore une fois, le modèle est un bon #3 derrière les recommandeurs de contenus les plus populaires
Voici les avantages et inconvénients de NDCG :
- ✅
- Il prend en compte la position d’un élément dans la liste de recommandations.
- ❌
- Cela peut être difficile à expliquer pour les personnes non techniques
- Il ne peut pas être utilisé dans le contexte de règles spécifiques pour le calcul des recommandations
Cette métrique n’est pas parfaite, mais elle fournit plus d’informations sur la qualité des recommandations.
Construire des recommandations est un problème de régression
Si nous pouvons voir le problème de recommandation comme une classification, il peut aussi être vu comme un problème de régression si nous définissons le tuple utilisateur et contenu. Un score d’affinité peut être construit entre ces deux entités et prédit par un régresseur.
Dans mon contexte ici et en général au travail, je ne fais pas cela, mais peut-être dans de futurs articles j’essaierai de prédire le score qu’un utilisateur peut donner basé sur ses interactions passées (#teasing).
Les recommandations ne sont pas seulement basées sur l’efficacité
Les systèmes de recommandation ne devraient pas être évalués uniquement sur leur efficacité à optimiser les métriques de performance. Ils ont généralement du mal à combattre le facteur de popularité d’une application. Voici une illustration de l’effet de popularité dans mon jeu de données.
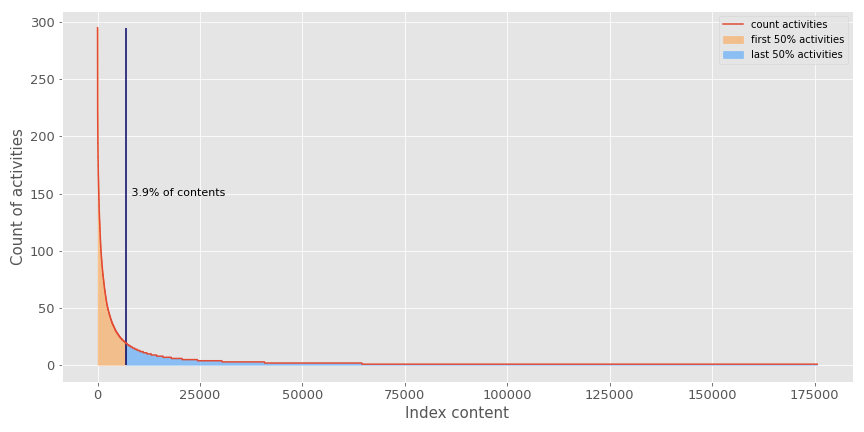
Comme vous pouvez le voir, moins de 4% du contenu représente 50% des activités enregistrées sur les milliers de contenus disponibles pour les utilisateurs. Cela illustre que :
- Les systèmes de recommandation sont un problème de classification très déséquilibré
- Les systèmes de recommandation peuvent être bloqués dans des boucles les plus populaires qui bloqueront le recommandeur à pousser des contenus qui pourraient intéresser nos utilisateurs (parce qu’ils ne sont pas populaires).
Avec cette nouvelle perspective, je trouve les métriques suivantes intéressantes pour évaluer si le système de recommandation explore tout le catalogue de contenus disponibles.
- Entropie : l’idée est de mesurer le désordre dans les recommandations produites ; le calcul est fait en calculant le ratio de différentes listes de recommandations construites versus la taille de l’ensemble de test. Voici une illustration pour notre exemple (Plus grand est mieux si vous voulez des recommandations diverses).
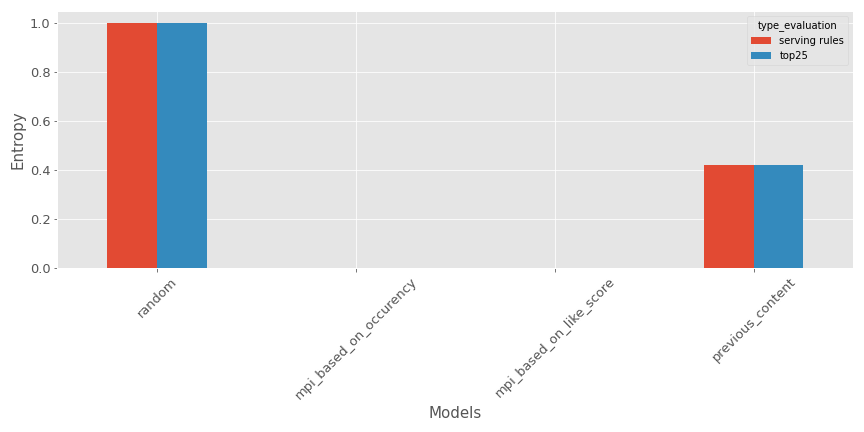
Comme prévu, le recommandeur aléatoire est super efficace, mais le modèle testé n’est pas si mal (au moins bien meilleur que les recommandeurs de contenus les plus populaires).
- Couverture du catalogue : la métrique calculera un ratio entre le nombre de différents contenus disponibles dans l’ensemble de test contre le catalogue total. Il y a une représentation pour les divers modèles (Plus grand est mieux si vous voulez des recommandations diverses).
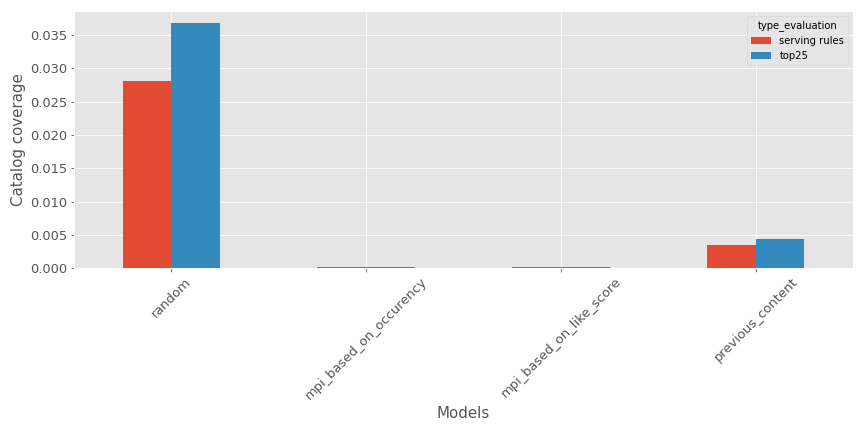
Encore une fois, comme prévu, le recommandeur aléatoire est super efficace, mais le modèle testé n’est pas si mal.
- Fraîcheur des recommandations : dans ce cas, la métrique évaluera la fraîcheur (à quel point c’est récent) des recommandations ; pour notre cas d’usage, j’utilise la date de publication moyenne des contenus dans les recommandations. Voici une représentation dans notre contexte.
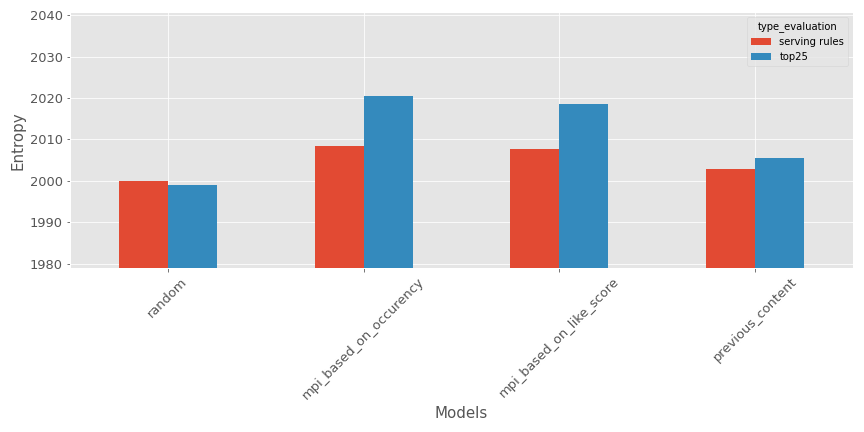
L’âge moyen des recommandations est supérieur à 2000, mais comme prévu, le recommandeur aléatoire semble produire les recommandations les plus anciennes. Je n’utilise généralement pas cette métrique car l’âge des articles sur lesquels je travaille n’est pas un gros problème, mais je pense que cela pourrait être très pertinent dans certains cas comme celui-ci.
Le recommandeur doit être déployé
Comme avec tout système de machine learning, vous voulez l’utiliser dans la vraie vie, donc c’est critique d’évaluer combien de temps il faut pour :
- Entraîner le modèle
- Faire l’inférence
Dans mon cas, pour le temps d’entraînement, l’évaluation n’aura pas trop de sens car ce sont les mêmes données sources sans trop de traitement (dans cette implémentation). Mais voici une comparaison du temps d’inférence sur ma période de test dans ce contexte de temps spécifique.
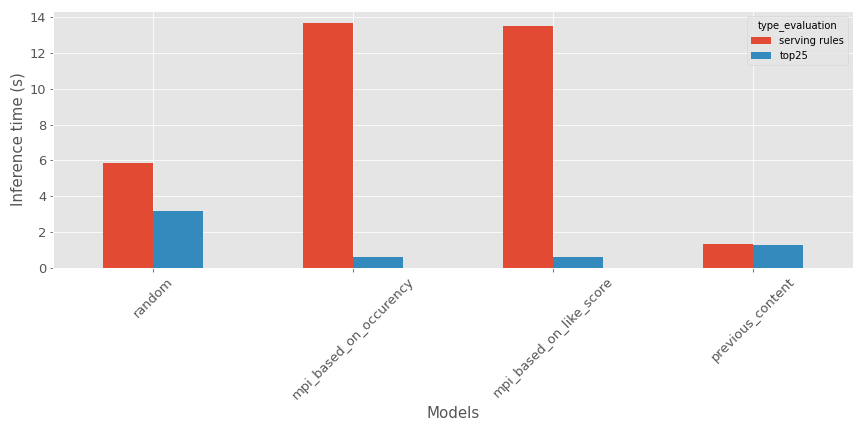
Basé sur le type d’évaluation :
- Pour les articles du top, le recommandeur aléatoire semble prendre plus de temps
- Pour les règles de service, le recommandeur de contenus les plus populaires semble prendre plus de temps
Le modèle n’est pas trop mal sur les métriques d’inférence.
Bonus: Taux de rafraîchissement
Au travail, je trouve parfois difficile d’évaluer les systèmes de recommandation et d’avoir des métriques qui intègrent les contraintes d’expérience utilisateur dedans.
Ma recherche sur le sujet m’a récemment conduit à une métrique utilisée lors du Spotify Million Playlist Dataset Challenge appelée recommended song clicks, que j’ai retravaillée pour mon cas d’usage.
L’idée est assez simple :
- Les règles UX sont d’avoir les top5 articles dans chaque catégorie ; tout sera affiché sur la page d’accueil
- Dans notre contexte d’évaluation, nous imaginerons qu’il y a un bouton de rafraîchissement (comme pour Spotify pour mettre à jour le contenu affiché et montrer le contenu suivant le mieux classé dans la liste)
- Pour l’évaluation, l’objectif est d’obtenir combien de clics vous aurez besoin pour obtenir le bon contenu affiché sur la page d’accueil.
- Si le nombre de clics dépasse un seuil prédéfini (dans mon cas, 10), la valeur sera fixée à 10
Voici un exemple de cette métrique pour mon contexte.
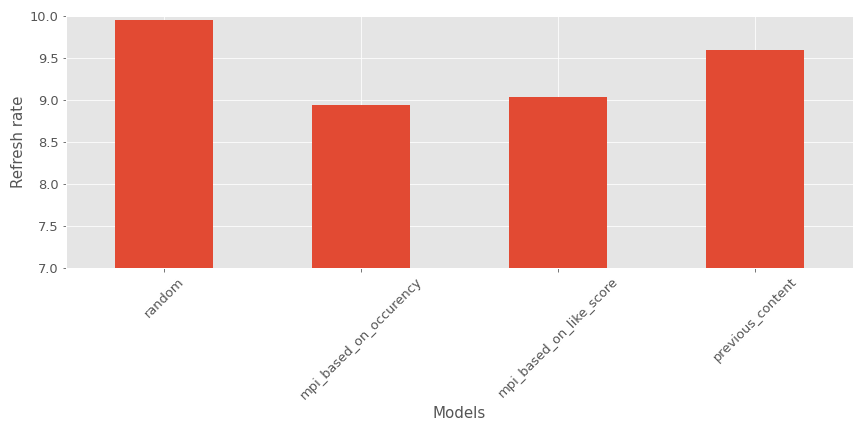
Comme nous pouvons le voir, les recommandeurs de contenus les plus populaires semblent performer mieux que les autres modèles.
Ma perspective :
- ✅
- Prend en compte la position d’un élément dans la liste de recommandations.
- Prend en compte les règles UI/UX
- Facile à comprendre
- ❌
- Le comportement utilisé avec le bouton de rafraîchissement n’est pas le bon dans l’application (donc cela peut biaiser l’évaluation, je pense)
Maintenant que nous avons vu certains KPI qui peuvent être utilisés pour évaluer l’efficacité d’un système de recommandation, parlons du processus d’évaluation.
Points clés généraux
L’une des grandes questions est comment faire la division de vos données de test et d’entraînement. J’ai trouvé trois approches dans la littérature :
- Division temporelle : une date pivot est définie, et toutes les données avant cette date sont utilisées pour l’entraînement, et les données à cette date et après sont utilisées à des fins de test. J’utilise habituellement cette méthode de division car je la trouve très proche de la réalité lors du déploiement d’un système de recommandation en ligne.
- Division aléatoire : toutes les données sont prises et divisées aléatoirement entre l’entraînement et le test. Je ne suis pas un grand fan de cette division quand vous travaillez dans des données en direct. Dans quel cas l’écosystème de recommandation est très sensible au temps (avec un comportement dépendant du jour de la semaine et de la sortie régulière de nouveau contenu).
- Division stratifiée : la division des données entre plusieurs groupes basés sur les attributs des utilisateurs pour respecter la distribution des utilisateurs dans la construction des ensembles d’entraînement et de test. Je ne l’ai jamais utilisée, mais cela peut avoir du sens.
Comme je l’ai mentionné précédemment dans la section de diversité des métriques, ne vous concentrez pas uniquement sur les métriques de performance comme le hit ratio et NDCG, si le système de recommandation qui est actuellement testé fait des prédictions très similaires au recsys qui tourne en production, le recsys testé aura de bons résultats (versus un modèle qui est peut-être très différent de celui en production et peut faire des recommandations très différentes).
Quelque chose à garder à l’esprit aussi pendant l’évaluation est d’avoir des métriques d’évaluation au niveau des sous-groupes. Il n’y a pas d’utilisateur moyen donc mesurer les métriques dans les prédictions pour différents sous-groupes (comme nouveau venu versus OG) donne plus d’informations sur les comportements des modèles.
Un autre aspect de l’évaluation des systèmes de recommandation est la sélection des périodes (en cas de division temporelle) ; de mon point de vue, avoir plusieurs contextes temporels est crucial dans un écosystème où beaucoup de contenu peut être publié au fil du temps. Quel est le bon nombre de contextes temporels ? Je ne sais pas mais gardez juste cela à l’esprit.
Une autre chose importante est de construire des archétypes d’utilisateurs et voir comment le recommandeur réagit à chacun. Cela fournit une excellente façon d’expliquer la sortie des modèles aux personnes non techniques et peut être très pertinent en plus de la connaissance d’expert (dans la création des contenus) pour valider le nouveau modèle (Netflix fait beaucoup de travail dans ce domaine).
Et enfin, il y a quelques ressources que je trouve assez pertinentes dans ce sujet d’évaluation, et qui pourraient être utiles pour votre recherche :
- L’un des articles autour de l’évaluation des systèmes de recommandation que vous verrez mentionné dans la plupart des articles d’évaluation
- Un package excitant avec beaucoup de métriques par Claire Longo
- Microsoft a un excellent repository de recommandation avec quelques notebooks liés à l’évaluation
- Je conseillerai aux gens de suivre les pistes autour de l’évaluation sur une conférence comme recsys
Conclusion
Pour rappel, ceci est une présentation de ma façon de voir l’évaluation des systèmes de recommandation, ce n’est pas parfait et peut être amélioré mais c’est ce que j’utilise pour évaluer mon modèle dans des contextes hors ligne et en ligne quotidiennement.
Les articles suivants se concentreront sur les modèles et le traitement des données mais feront toujours référence à celui-ci pour les définitions des métriques.
Références
- ici — manning.com
- sens critique — senscritique.com
- rapport datapane — datapane.com
- repository — GitHub
- ici — GitHub
- scikit learn — scikit-learn.org
- glossaire ML de google — developers.google.com
- ici — sdsawtelle.github.io
- métrique — Medium / Towards Data Science
- repository — GitHub
- Spotify Million Playlist Dataset Challenge — aicrowd.com
- Netflix — Medium / Towards Data Science
- articles — jmlr.csail.mit.edu
- package — GitHub
- Claire Longo — Medium / Towards Data Science
- repository — GitHub
- recsys — recsys.acm.org