
Construire un prédicteur de pression de ventilateur pour Google Brain
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Je voulais depuis longtemps participer sérieusement à une compétition Kaggle (je pense avoir fait quelques tests il y a quelques années mais rien de sérieux) ; je m’inscris toujours aux compétitions pour accéder aux données et jeter un œil au format par curiosité mais n’ai jamais pris les chances de participer à une.
Il y a quelques jours (écrivant ces lignes le 27/09/2021), Google ouvre avec Google brain une compétition autour de la prédiction de la pression du ventilateur. La date limite est d’un mois, donc pourquoi ne pas participer (calendrier court, quelques vacances dans le pipe).
Pour aborder la compétition, j’ai décidé d’aller dans le sens automl pour explorer les modèles (je donnerai plus de détails plus tard), et cet article sera divisé dans les sections suivantes :
- Description de la compétition
- Exploration du jeu de données et du modèle
- Soumissions finales
Description de la compétition
Pour cette section, cela va être un copier-coller des sections description, et data avec quelques mises à jour personnelles, donc n’hésitez pas à retourner aux racines de la compétition.
Description: Que font les médecins quand un patient a du mal à respirer ? Ils utilisent un ventilateur pour pomper de l’oxygène dans les poumons d’un patient sédaté via un tube dans la trachée. Mais la ventilation mécanique est une procédure intensive en clinicien, une limitation qui était particulièrement visible pendant les premiers jours de la pandémie COVID-19. En même temps, développer de nouvelles méthodes pour contrôler les ventilateurs mécaniques est prohibitivement cher, même avant d’atteindre les essais cliniques. Des simulateurs de haute qualité pourraient réduire cette barrière.
Les simulateurs actuels sont entraînés comme un ensemble, où chaque modèle simule un seul réglage de poumon. Cependant, les poumons et leurs attributs forment un espace continu, donc une approche paramétrique doit être explorée pour considérer les différences dans les poumons des patients.
En partenariat avec l’Université de Princeton, l’équipe de Google Brain vise à faire grandir la communauté autour du machine learning pour le contrôle de la ventilation mécanique. Ils croient que les réseaux de neurones et le deep learning peuvent mieux généraliser les poumons avec des caractéristiques variées que le standard de l’industrie actuel des contrôleurs PID.
Ok, donc cela va être amusant d’utiliser automl quand les techniques NN et deep learning semblent être le bon chemin (viens de lire cette description le 1er novembre)
Dans cette compétition, vous allez simuler un ventilateur connecté au poumon d’un patient sédaté. Les meilleures soumissions prendront en compte les attributs du poumon compliance et résistance.
Si réussi, vous aiderez à surmonter la barrière de coût du développement de nouvelles méthodes pour contrôler les ventilateurs mécaniques. Cela pavera la voie pour des algorithmes qui s’adaptent aux patients et réduisent le fardeau sur les cliniciens pendant ces temps nouveaux et au-delà. En conséquence, les traitements de ventilateur peuvent devenir plus largement disponibles pour aider les patients à respirer.
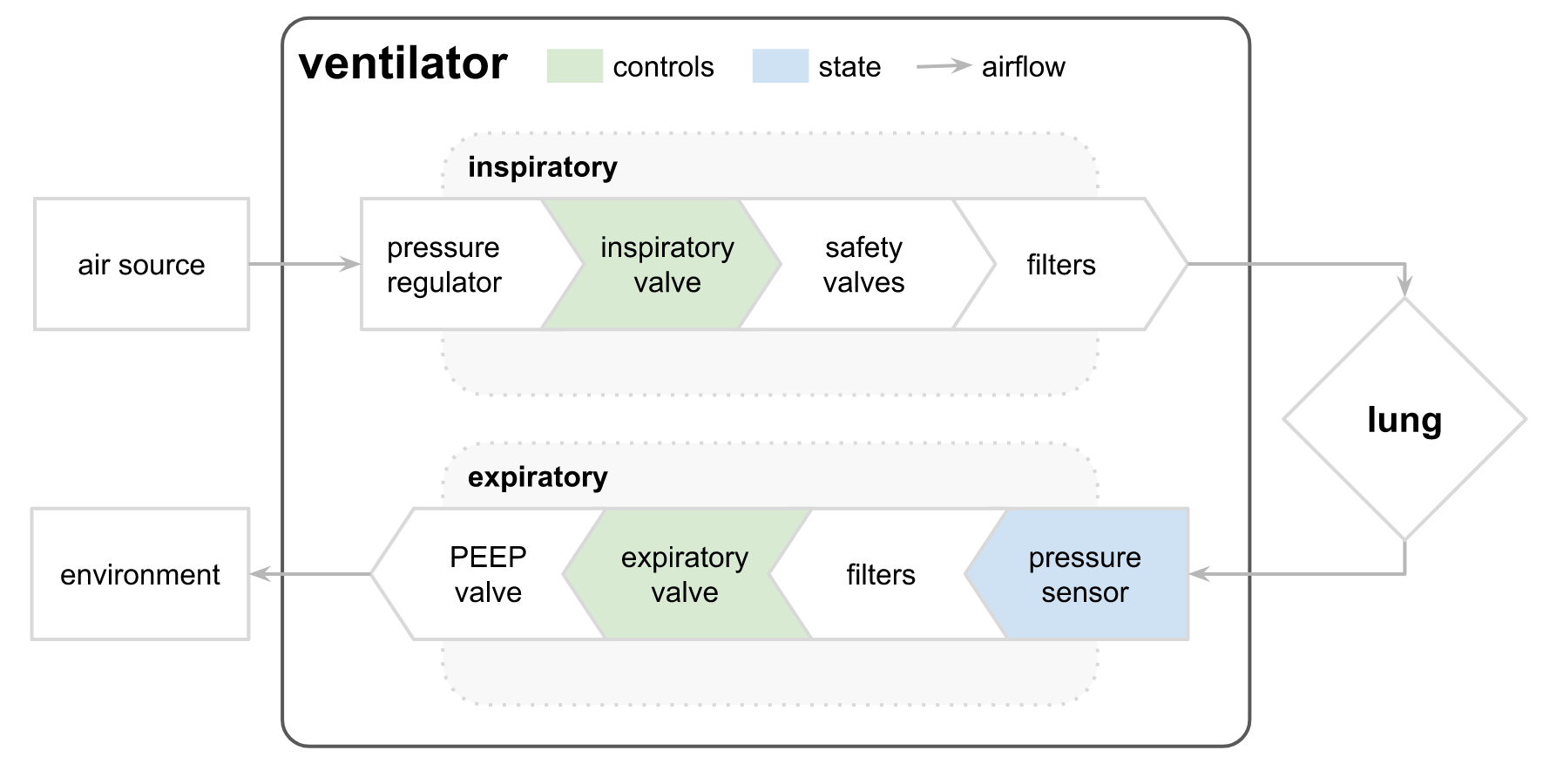
Données: Les données de ventilateur utilisées dans cette compétition ont été produites en utilisant un ventilateur open-source modifié connecté à un poumon de test bellows artificiel via un circuit respiratoire. Le diagramme ci-dessous illustre la configuration, avec les deux entrées de contrôle mises en évidence en vert et la variable d’état (pression des voies aériennes) prédite en bleu. La première entrée de contrôle est une variable continue de 0 à 100, représentant le pourcentage de la valve solénoïde inspiratoire ouverte pour laisser l’air entrer dans le poumon (c’est-à-dire, 0 est complètement fermé et aucun air n’est laissé entrer, et 100 est complètement ouvert). La deuxième entrée de contrôle est une variable binaire représentant si la valve exploratoire est ouverte (1) ou fermée (0) pour laisser l’air sortir.
Deux valeurs significatives semblent liées au statut des deux valves, avec une qui semble avoir un niveau de liberté plus élevé (valve inspiratoire) versus la valve exploratoire avec un statut OUVERT/FERMÉ.
Dans cette compétition, les participants reçoivent de nombreuses séries temporelles de respirations. Étant donné la série temporelle des entrées de contrôle, ils apprendront à prédire la pression des voies aériennes dans le circuit respiratoire pendant la respiration.
Chaque série temporelle représente une respiration d’environ 3 secondes. Les fichiers sont organisés de telle sorte que chaque ligne est un pas de temps dans une respiration et donne les deux signaux de contrôle, la pression des voies aériennes résultante, et les attributs pertinents du poumon décrits ci-dessus.
À partir des sources de données, il y a deux fichiers train.csv et test.csv, pour la compétition avec les colonnes suivantes :
- id - identifiant de pas de temps globalement unique à travers un fichier entier
- breath_id - pas de temps globalement unique pour les respirations
- R - attribut du poumon indiquant à quel point les voies aériennes sont restreintes (en cmH2O/L/S). Physiquement, c’est le changement de pression par changement de flux (volume d’air par temps). Intuitivement, on peut imaginer gonfler un ballon à travers une paille. Nous pouvons changer R en changeant le diamètre de la paille, avec un R plus élevé étant plus difficile à souffler.
- C - attribut du poumon indiquant à quel point le poumon est compliant (en mL/cmH2O). Physiquement, c’est le changement de volume par changement de pression. Intuitivement, on peut imaginer le même exemple de ballon. Nous pouvons changer C en changeant l’épaisseur du latex du ballon, avec un C plus élevé ayant un latex plus fin et plus facile à souffler.
- time_step - l’horodatage réel.
- u_in - l’entrée de contrôle pour la valve solénoïde inspiratoire. Varie de 0 à 100.
- u_out - l’entrée de contrôle pour la valve solénoïde exploratoire. Soit 0 ou 1.
- pressure - la pression des voies aériennes mesurée dans le circuit respiratoire, mesurée en cmH2O (seulement disponible dans le fichier train.csv car c’est la cible à prédire)
Donc de l’explication des données et du schéma :
- u_in est le statut de la valve inspiratoire (vert dans le schéma)
- u_out est le statut de la valve de sortie
- C est le type de poumon et R est la restriction des voies aériennes (RC peut être défini comme le type de poumon)
Donc un peu de bonnes informations pour définir le problème, mais je vous invite à regarder la grande discussion commencée par Chris Deotte de NVIDIA qui fait une grande description/connexion entre la description et les colonnes des jeux de données (part1, part2).
Dans ce cas, nous sommes dans un problème de régression essentiellement, et pour évaluer le côté Kaggle, la métrique est le MAE (il y a une explication et une implémentation ici).
La compétition était finie le 3 novembre, et pendant ce temps, vous pouvez classer votre soumission sur un classement public (qui représente 19% de l’ensemble de test). L’évaluation finale pour le classement se produira sur les 81% restants.
Commençons la compétition.
Exploration du jeu de données et du modèle
Dans cette section, il y aura une présentation de mes diverses explorations des jeux de données et des modèles ; je vais lier à tout ce texte les divers notebooks que j’ai produits (soyez avertis, ils sont bruts, sans commentaires et sans nettoyage) dans le repository.
Comme je l’ai dit dans l’introduction, j’ai travaillé avec des bibliothèques autoML pour explorer les modèles, alors faisons une introduction rapide sur le package utilisé (ils sont deux) :
- Le MVP mljar, je l’ai essayé il y a quelques mois dans cet article autour des outils ML, vraiment simple à utiliser avec beaucoup d’exploration et d’explication de la bibliothèque
- L’outsider FLAML développé par Microsoft, il y a beaucoup de points communs avec mljar, mais sa force est que sa sortie est plus légère (juste un modèle), donc il est défini comme léger.
Ils sont tous les deux excitants, et je voulais les comparer, donc voici quelques points :
- Il semble être difficile de faire plus d’entraînement étendu que 2-3 heures, le temps autorisé pour ce travail peut être défini dans le script) sur ma machine locale, tous les deux semblent avoir des processus qui sont interrompus par mon système (python killed)
- Avec des caractéristiques équivalentes comme entrée, le résultat est assez proche en termes de précision dans le MAE
Donc essentiellement, si vous voulez connaître la sortie autoML mieux, mljar est mieux, mais FLAML est plus léger pour le déploiement, donc cela dépendra de vos besoins.
Pour démarrer rapidement ma compétition, j’ai décidé d’aller dans deux sens :
- Faire une soumission aléatoire avec un MAE de 20.3117
- Et mettre le fichier train.csv brut sans traitement de données avec mljar et FLAML ; j’ai essayé avec plusieurs configurations pour les bibliothèques mais j’ai obtenu un MAE autour de 6.3518 (mieux que aléatoire)
Plongeons dans les données avec un notebook d’exploration ; avant de donner mes points clés, je vais présenter une respiration en détail.
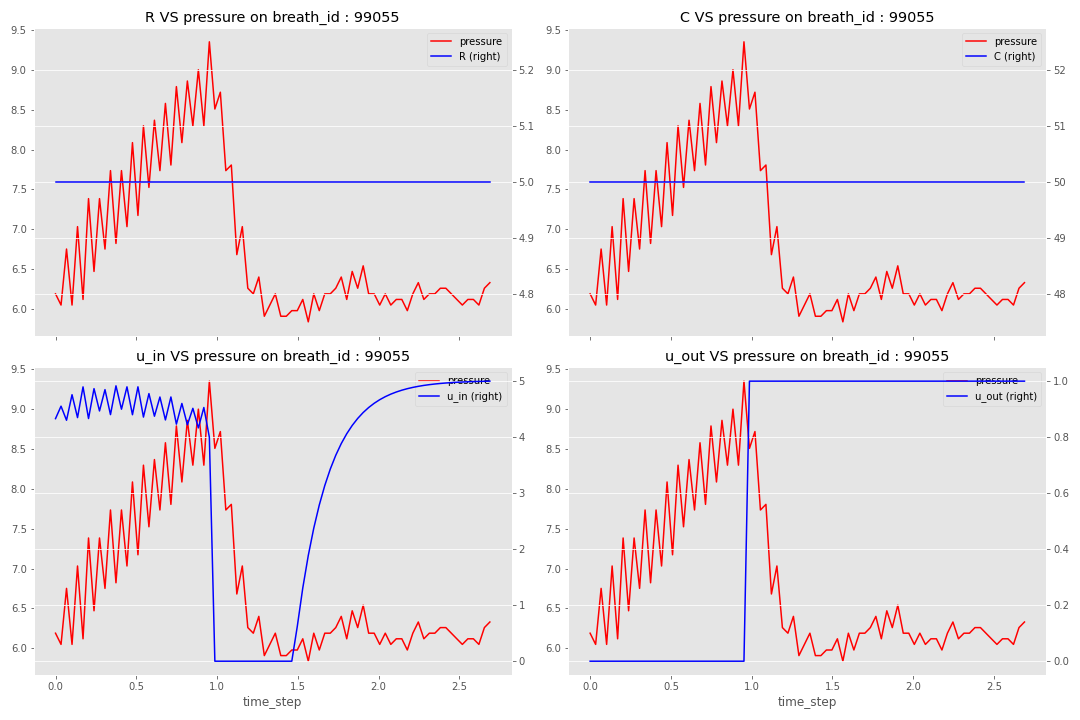
Il y a quelques points clés de cette analyse :
- Il n’y a pas de chevauchement entre le breath_id dans les fichiers train et test
- RC n’évolue pas dans une respiration (bien sûr)
- Il n’y a que neuf combinaisons de R_C, donc seulement neuf types de poumons, et ils semblent être divisés uniformément (comme 10% des données d’entraînement sur chaque type de poumon)
- La valve expiratoire semble être ouverte environ 1 seconde (⅓) de la respiration
- Une forte relation entre la pression et u_in X u_out
- U_in n’atteint pas toujours l’ouverture complète (moyenne à 23)
- Toutes les respirations ont 80 points
Après tout cela et dans ce notebook, j’ai commencé à développer quelques nouvelles caractéristiques pour les jeux de données basées sur cette analyse :
- J’ai commencé à construire u_in_norm basé sur le max de u_in dans la respiration
- Déterminer les tendances de u_in dans les derniers 1, 2 et 4 time_steps (tendances en arrière et en avant) ; cette tendance a été divisée par le delta entre le pas de temps actuel et l’autre dans la tendance (vraiment, je ne savais pas pourquoi je voulais avec quelque chose comme ça pour commencer)
- Une caractéristique liée à quand la valve expiratoire est ouverte (et depuis combien de temps)
J’ai commencé à réappliquer l’automl (1,2) sur ces données, et le MAE a commencé à atteindre 1.2 (fancy :)).
Pour la deuxième vague d’expérimentation, j’ai eu une idée autour de l’application de clustering sur les séries temporelles qui étaient u_in_norm. Je veux concevoir et utiliser des clusters comme caractéristiques pour mon entraînement (avec cela, le modèle peut sentir quel genre de série temporelle il était en train de faire face).
Il y a le flux global que j’ai mis en place dans ce notebook.
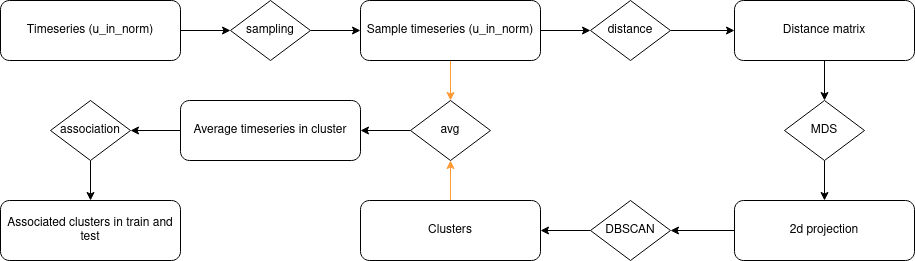
Le processus est inspiré de certains des travaux que j’ai faits dans mon travail précédent chez EDF que j’ai conçu quelque chose de similaire ; le processus est :
- Échantillonnage des séries temporelles (u_in_norm) avec 10% de l’ensemble de données entier
- Calculer le calcul de la matrice de distance entre les séries temporelles ; pour ce calcul, j’ai utilisé deux distances différentes (qui pourraient me donner deux caractéristiques) :
- Avec la matrice de distance, construire un espace 2D avec le MDS de scikit learn pour aider au clustering
- Construire des clusters avec la valeur par défaut du DBSCAN de scikit learn
- À partir des clusters, construire le noyau du cluster en faisant la moyenne des séries temporelles dans les clusters
- Trouver le noyau le plus proche sur toutes les séries temporelles dans les fichiers train et test
Ma première expérience sur u_in_norm peut être trouvée ici et n’a pas été très réussie (la projection par le MDS n’est pas très efficace), mais je réutiliserai cette approche plus tard dans mon exploration.
À ce point, j’allais partir pour une pause de 2 semaines, donc j’ai commencé à creuser un peu dans la section discussion de la compétition :
- J’ai extrait de cette recherche une discussion excitante autour d’un notebook pour calculer un modèle LSTM avec des caractéristiques qui ressemblaient à celles que j’ai construites mais meilleures. Avec ce nouveau ensemble de caractéristiques (que j’appelle spy features), j’ai atteint un MAE de 0.678.
- J’ai décidé de construire des ensembles de validation pour l’entraînement et l’évaluation du modèle.
À mon retour de vacances, j’ai commencé à ajuster les spy features en supprimant les dummies et en réimplémentant le clustering avec le u_in (1, 2) (redéclenché par une discussion qui semble avoir disparu). Ces nouveaux clusters peuvent être trouvés ici (des centaines de clusters), et le mélange de spy features et des clusters a atteint un MAE de 0.5683.
C’était le dernier point pour mon exploration ; voyons les soumissions finales.
Soumissions finales
Pour compléter cette compétition, j’avais deux choses en tête (le 1er novembre) à tester :
- Explorer le calcul d’un modèle par type (RC) du poumon (donc construire neuf modèles) avec les spy features (sans les dummies)
- Travailler sur l’ingénierie des caractéristiques de u_in et u_out et ajouter les spy features (sans les dummies)
Dans le premier chemin, c’est assez simple et vous pouvez trouver un script pour construire l’un des modèles (pour une valeur RC), et la soumission a atteint un MAE de 0.5299 (mais quelque chose à garder à l’esprit c’est que cela m’a pris 5 heures pour construire cette soumission).
Pour le dernier chemin, j’ai décidé de reconstruire des caractéristiques liées au régime global des valves dans la respiration (l’ingénierie des caractéristiques peut être trouvée dans la deuxième section du notebook). L’idée est de définir un pas de temps pivot :
- Pour u_in, le moment où la valve est la plus ouverte dans la respiration (atteint son maximum local)
- Pour u_out, le moment où la valve est ouverte
Basé sur ce pas de temps pivot, l’idée est de construire un régime où :
- Commence à -1 au début de la respiration pour atteindre 0 au pas de temps pivot
- Finit la respiration à 1
Il y a une illustration de la définition du régime pour une respiration spécifique.
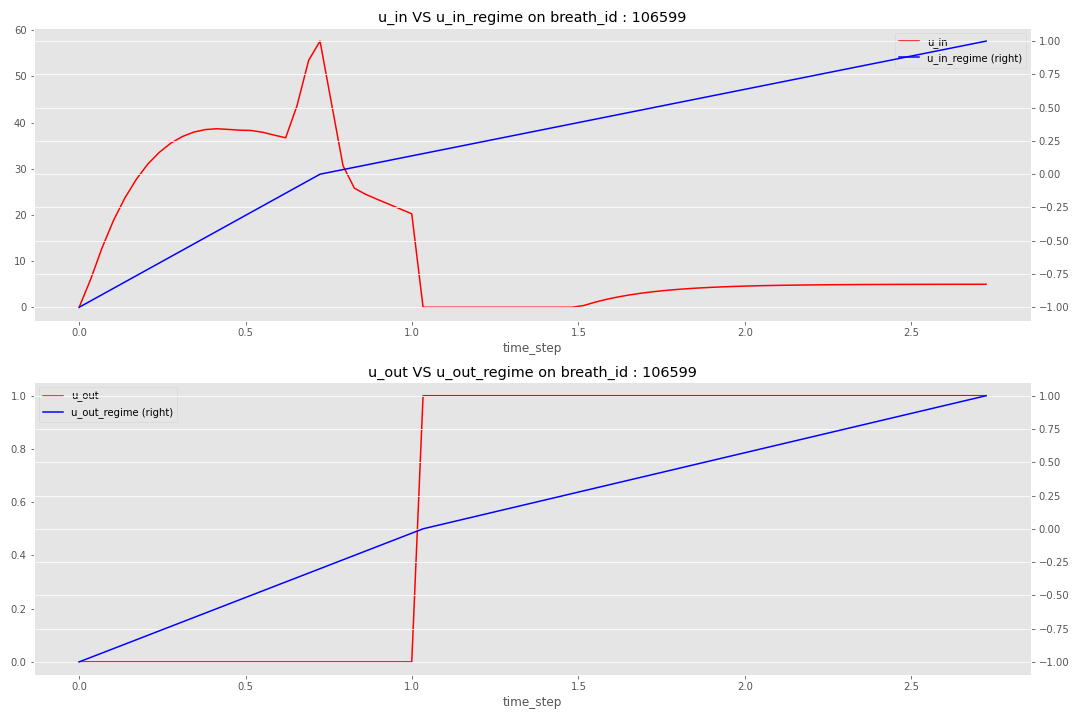
Avec ces nouvelles caractéristiques, vous pouvez trouver le code ici et avec ce nouveau modèle final, j’ai atteint un MAE de 0.554.
Conclusion et points clés
Alors quels sont les résultats, la solution gagnante a terminé la compétition avec un MAE de 0.0575, où ma meilleure solution a marqué à 0.5299 ; dans le classement global, je suis 1925 sur 2659 équipes participantes. Je serai honnête, je suis un peu triste de ma position sur le classement (je visais au moins la première partie du classement (dans le top 1300)), mais pour la configuration que je me suis mise en termes de temps et de bibliothèques, ce n’est pas si mal 😀.
Globalement je suis un peu content de ma première tentative à une compétition Kaggle, et j’ai appris quelques nouveaux trucs pour traiter les données efficacement et testé une nouvelle bibliothèque d’autoML. Si j’avais plus de temps, j’aurais :
- Exploré des chemins de deep learning avec LSTM, par exemple
- Pris plus de temps pour creuser dans la littérature des ventilateurs et des PID (retour aux cours d’automatisme à l’université)
Pour la solution gagnante, l’équipe derrière a commencé à faire un récapitulatif sur une discussion. Mais de ma compréhension de la solution et de ce que je lis sur Twitter, il semble qu’ils aient essayé de faire de l’ingénierie inverse du simulateur de ces données pour le gagner (Twitter thread sur le sujet). Donc il n’y a pas de sentiment raide pour moi sur cela “c’est le jeu, ma pauvre Lucette,” comme on dit en France.
Mais j’extrais quelques apprentissages de cette première expérience qui se nourrira pour les prochaines (parce qu’il y aura d’autres compétitions pour moi c’est sûr) :
- Construire des fonctions standard à partager entre les notebooks
- Exploiter l’infra Kaggle pendant les temps morts pour continuer à tester les modèles (rendre le code agnostique de son emplacement) et pas seulement utiliser une machine locale (tout fonctionne sur ma machine)
- Lire correctement la description (compétition + données) ; ajouter des notes comme je l’ai fait pour l’article peut convenir pour une vue claire et précise de l’objectif.
- Ne pas sous-estimer l’EDA et l’ingénierie des caractéristiques
- Une pause de deux semaines pendant une compétition d’un mois n’est pas une excellente idée
Références
- Kaggle — Compétition ventilator pressure prediction — Kaggle
- Kaggle — Données de la compétition — Kaggle
- Ventilateur open-source (pvp.readthedocs.io) — documentation
- Poumon de test bellows artificiel — Ingmar Medical — ingmarmed.com
- Discussion Chris Deotte partie 1 — Kaggle
- Discussion Chris Deotte partie 2 — Kaggle
- scikit-learn MAE — scikit-learn.org
- Dépôt GitHub kaggle-ventilator-pressure-prediction — GitHub
- mljar-supervised — GitHub — GitHub
- FLAML — GitHub — GitHub
- Notebook soumission aléatoire — GitHub
- Notebook soumissions mljar autoML — GitHub
- Notebook soumissions FLAML autoML — GitHub
- Notebook d’exploration — GitHub
- scikit-learn distances euclidiennes — scikit-learn.org
- DTAIDistance — documentation DTW — documentation
- scikit-learn MDS — scikit-learn.org
- scikit-learn DBSCAN — scikit-learn.org
- Notebook clustering u_in_norm — GitHub
- Section discussion de la compétition — Kaggle
- Notebook TensorFlow Bidirectional LSTM — Kaggle
- Discussion solution gagnante — Kaggle