
Démarrez votre projet de séries temporelles (analyse, prévision et détection d'anomalies) avec Kats
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Récemment, j’ai entendu parler d’un package développé par Facebook research (META research !?) appelé KATS, publié par l’équipe Infrastructure Data Science de Facebook fin de l’année dernière, défini comme “un toolkit pour analyser les données de séries temporelles, un framework léger, facile à utiliser et généralisable pour effectuer l’analyse de séries temporelles.”
Les séries temporelles sont loin d’être le type de données que j’utilise quotidiennement, mais je voulais l’essayer pendant quelques semaines, mais je n’ai pas trouvé le jeu de données pour tester le package complet qui est composé de ces composants principaux :
- Prévision et le kats.model
- Détection et le kats.detector
- TS features
- Utilitaires
Alors j’ai décidé d’utiliser trois jeux de données pour expérimenter ce package et travailler sur les cas d’usage suivants :
- Construire des modèles de référence pour une compétition de prévision de séries temporelles
- Détecter les anomalies dans les séries temporelles liées aux crimes à Montréal
- Extraire les caractéristiques de séries temporelles sur la consommation énergétique des ménages
Mais avant de plonger dans les cas d’usage, il y a une étape préalable pour utiliser ces fonctions.
Notes:
- Ce package au moment de la rédaction est dans sa version 0.1, donc du code pourrait devenir obsolète à l’avenir.
- Les fonctions utilitaires sont mises de côté dans cette évaluation
Prérequis: Construire un jeu de données de séries temporelles
Pour chaque pipeline lié aux séries temporelles avec KATS, vous devrez construire votre série temporelle au format TimeSeriesData de KATS. Il y a un gist qui présente la conversion d’un dataframe pandas vers une série temporelle KATS.
Ce qu’il est essentiel de garder à l’esprit, c’est que :
- Une colonne time doit être fournie, pas besoin d’un format datetime/timestamp, une chaîne transformable suffit
- Dans ce cas, j’ai choisi seulement une colonne, mais plusieurs colonnes peuvent être fournies
- La série temporelle a des fonctionnalités comme un dataframe pandas pour ajouter et découper des lignes ou une fonction de tracé auto-construite (cf figure suivante)
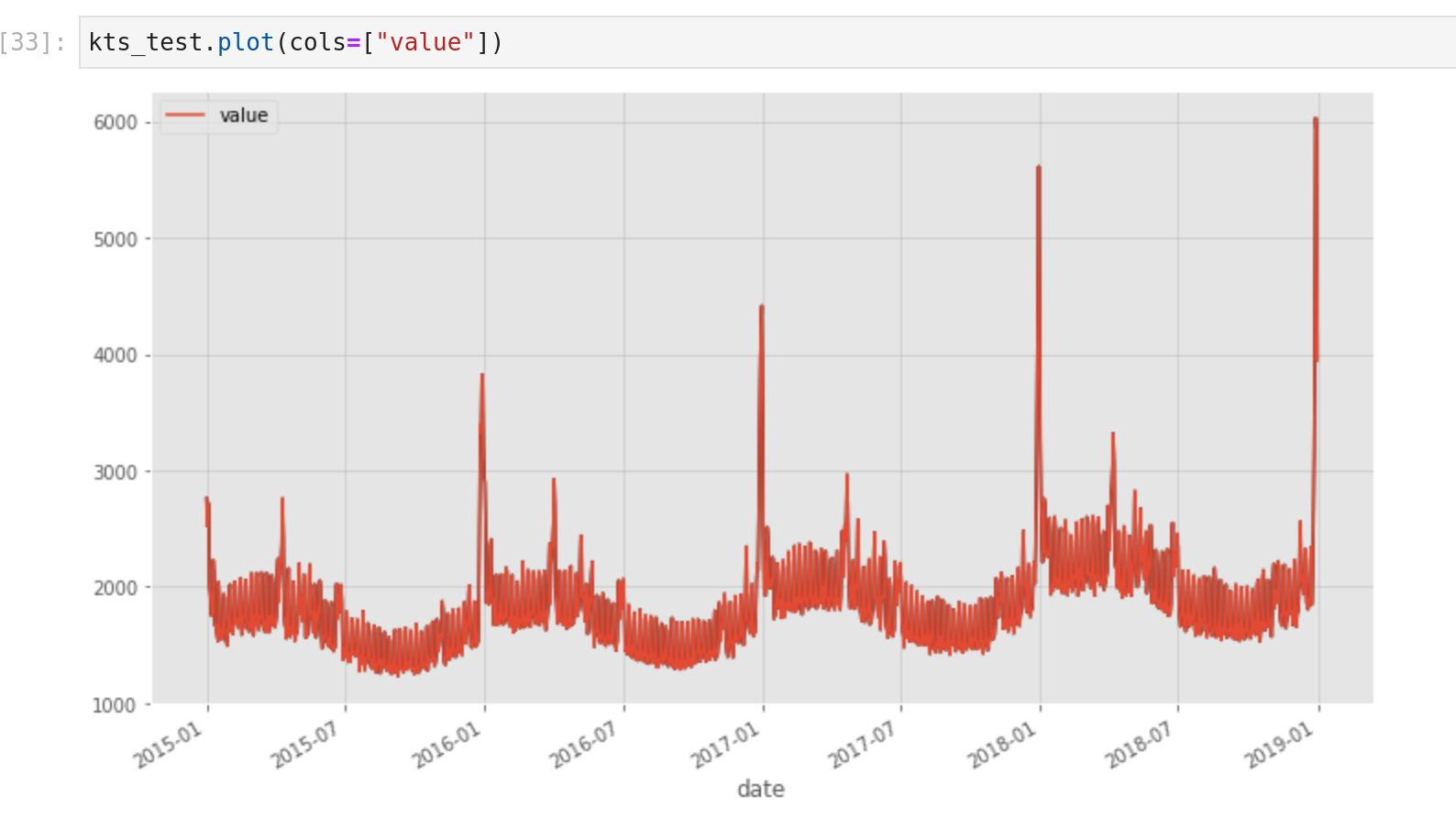
Avec ce nouveau type de données qui ressemble à un dataframe pandas plus sophistiqué/structuré, tout est prêt pour plonger dans les composants de KATS.
Prévision avec KATS
Pour cette expérimentation, je vais exploiter les composants kats.models pour construire des modèles de référence dans le dernier playground de janvier de Kaggle.
Dans cette compétition, l’objectif est de construire un système de prévision pour un magasin dans le nord de l’Europe dans trois pays (Finlande, Suède et Norvège) qui ont deux types de magasins (KaggleRama et KaggleMart) pour trois types d’articles (Mug, autocollant et chapeau).
Les données pour entraîner le modèle sont le nombre de ventes sur chaque territoire, type de magasin et type d’articles entre le 31/12/2014 et le 30/12/2018, et prédire l’année 2019 sur le même type de produit dans le même marché. Par conséquent, j’ai créé une colonne catégorie concaténation entre pays-type_magasin-type_article pour construire des modèles.
En termes de modèles disponibles, il y a de nombreux modèles disponibles (cf kats.models) de Prophet le modèle de prévision de séries temporelles interne à LSTM, ARIMA et d’autres approches faites votre choix :). Cependant, je voulais lancer rapidement une exploration en utilisant certains modèles avec des valeurs par défaut dans une catégorie.
Le flux est très simple et me donne la possibilité de choisir les modèles suivants :
- Prophet
- Theta
- Holtwinters
- Régression (linéaire et quadratique)
Il y a un résultat d’une sortie d’un modèle prophet pour une catégorie.
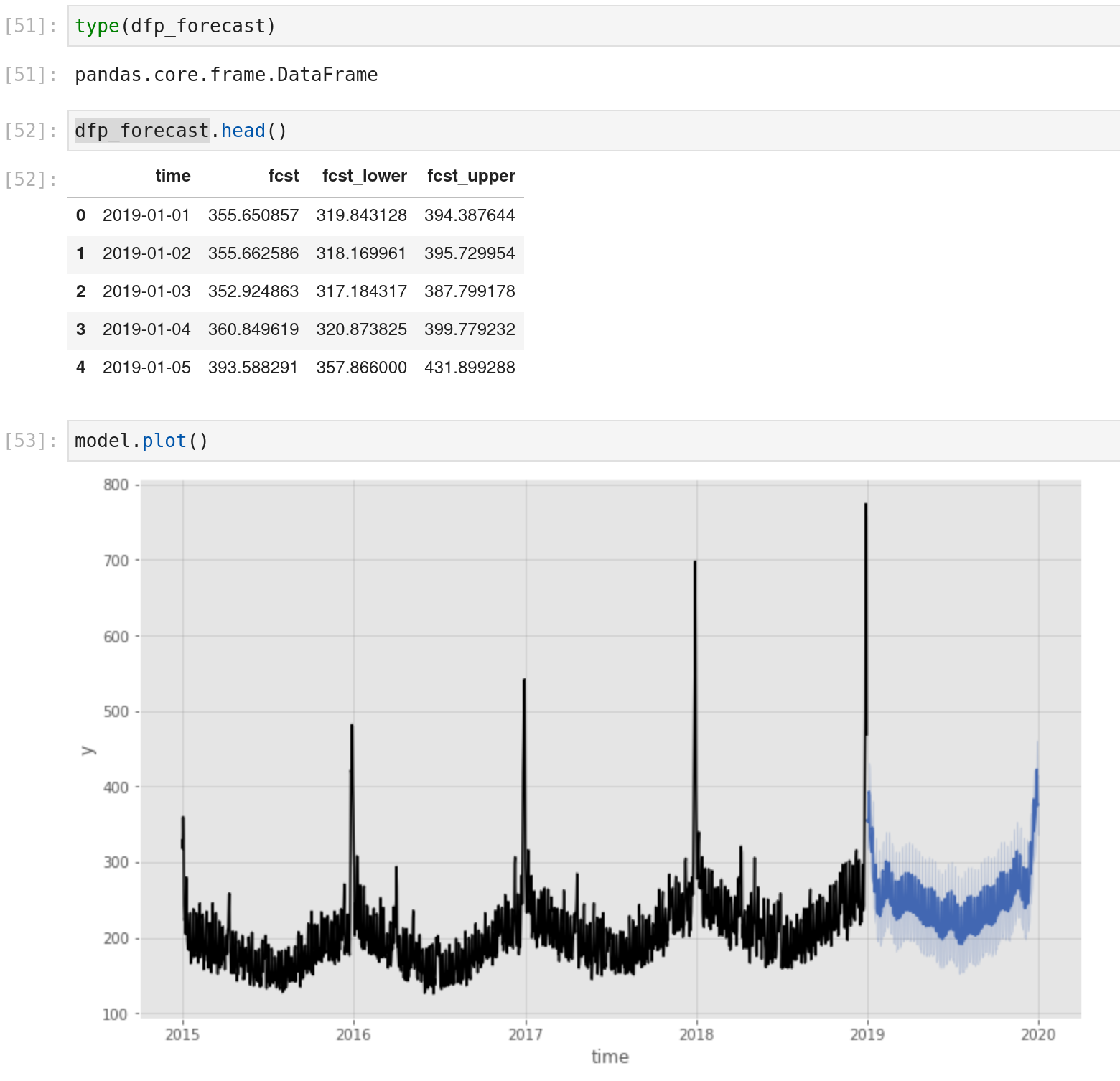
Ces modèles étaient les plus basiques sans besoin d’ajouter de paramètres par défaut, à partir de ma première expérience avec le package :
- Une façon très similaire d’initialiser le modèle avec les attributs params de la fonction modèle lors de la déclaration
- La fonction predict donne la possibilité de définir le nombre de jours dans le futur pour faire la prédiction (la façon d’entraîner et de prédire est très similaire au package Prophet de Prophet)
- Le model.predict fournit également la fonction de tracé des données d’entraînement et de la prévision
- Certains modèles prévoient différents types de sorties (prédiction avec une borne basse et haute, par exemple), donc vérifiez la sortie :)
Avec ce format, j’ai commencé à construire un tas de soumissions pour la compétition en construisant un modèle pour chaque catégorie et en concaténant tout ; il y a un classement des premières soumissions.
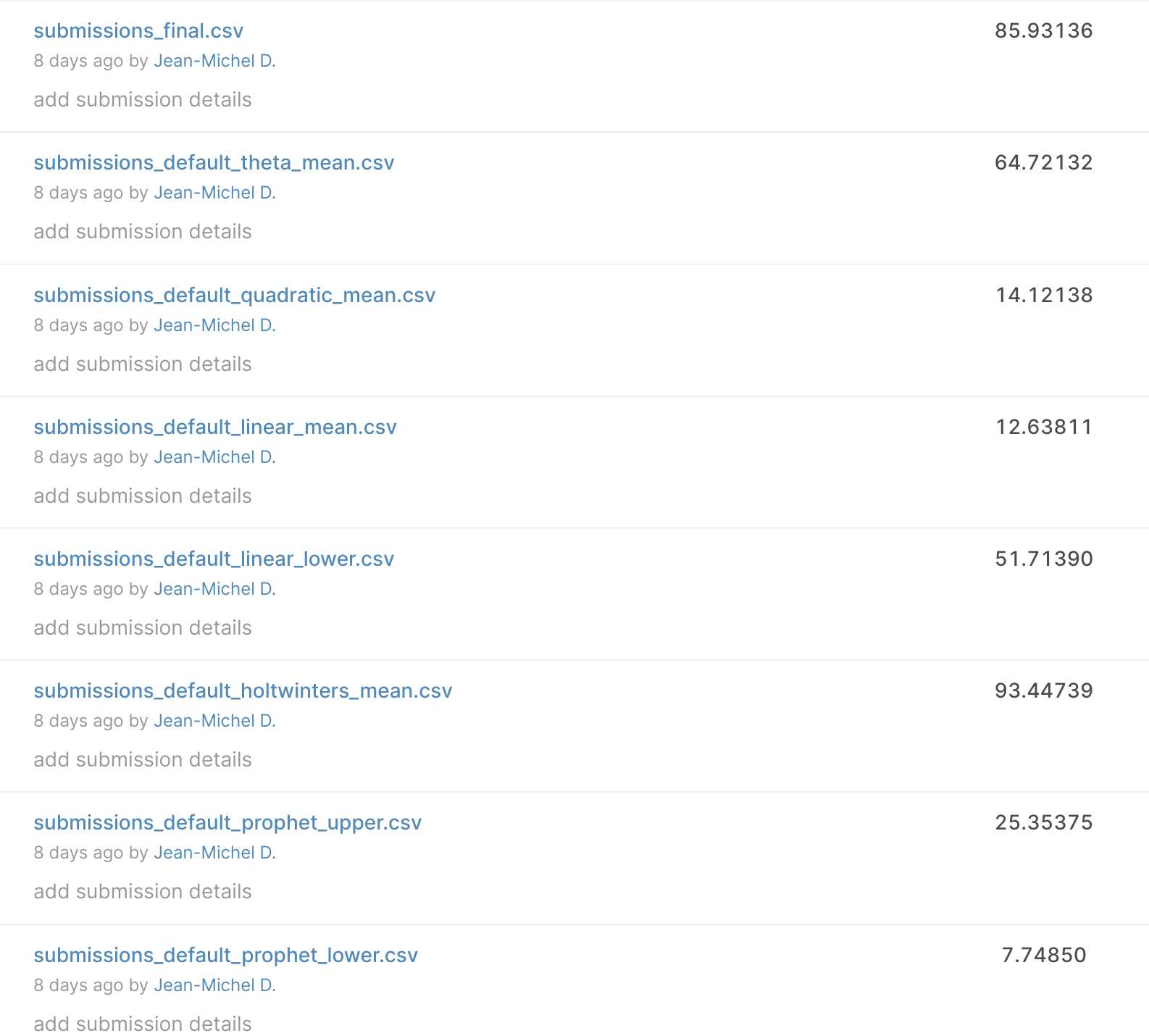
J’arrive à avoir un SMAPE (métrique d’évaluation de la compétition) de 7,7 ; actuellement, le meilleur modèle sur le classement public est 3,9, donc pas si mal pour un premier modèle (merci prophet borne inférieure).
Pour conclure mon expérience avec les composants de prévision, je vais examiner deux approches pour trouver les paramètres/modèles appropriés :
- Exploiter le méta-apprentissage (inspiré par ce tutoriel) pour trouver les paramètres corrects pour une liste de modèles
- Optimisation des hyperparamètres pour un modèle multivarié (inspiré par ce tutoriel)
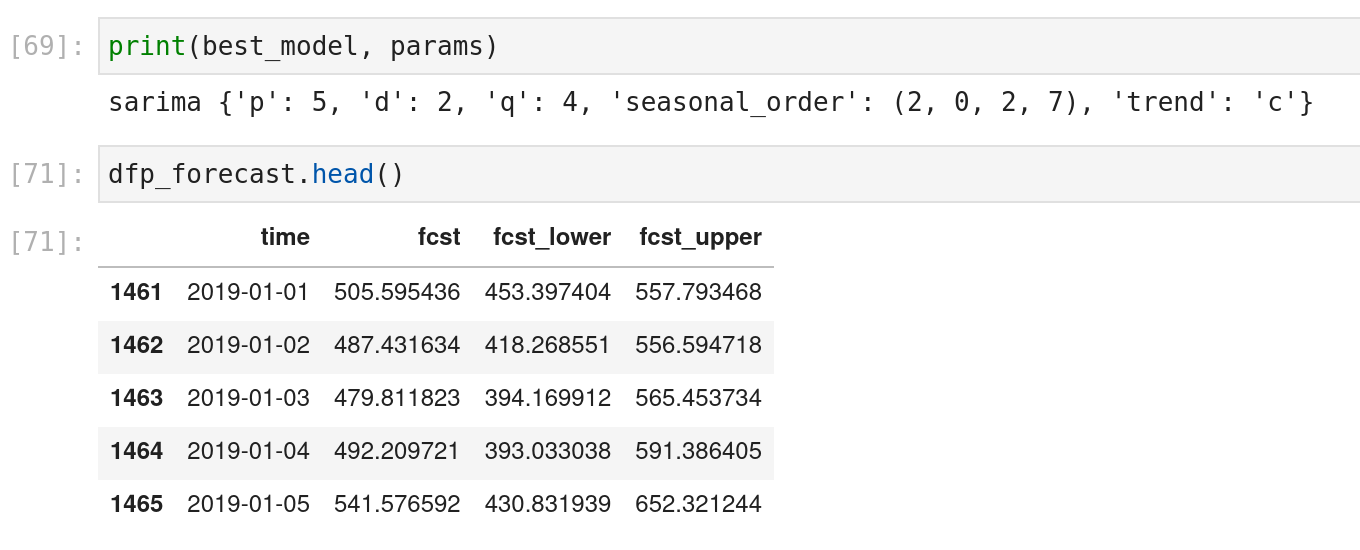
Méta-apprentissage: Le processus utilisé dans ce package est détaillé dans cet article de Facebook, mais l’idée derrière le méta-apprentissage est d’entraîner un modèle pour apprendre à partir de la sortie des modèles qui essaient de faire vos prédictions et trouver les paramètres appropriés à utiliser (un peu comme un entraîneur personnel). Si vous voulez en savoir plus sur cette façon d’entraîner un modèle, regardez cet article sur machinelearningmastery.
Et la sortie des scripts avec le nom du meilleur modèle et ses paramètres associés
Optimisation des hyperparamètres: Pour cette expérience, l’idée était de tester un nouveau type de modèle pour les optimiser. Le modèle multivarié “est une extension multivariée du modèle autorégressif (AR) univarié. Il capture les interdépendances linéaires entre plusieurs variables en utilisant un système d’équations. Chaque variable dépend non seulement de ses propres valeurs retardées, mais aussi des valeurs retardées d’autres variables” ; fondamentalement, plusieurs colonnes sont fournies pour construire un modèle de prévision pour chaque colonne.
Il y a globalement mon flux pour le test.
L’idée est de :
- Préparer le jeu de données (dah)
- Construire un espace de paramètres ; je me concentre uniquement sur un paramètre qui est un choix différent de valeurs ; j’ai trouvé la définition d’un espace de paramètres très similaire à ce qui peut être fait avec hyperopt
- Définir une fonction d’évaluation pour surveiller la prédiction sur le test
- Déclencher la recherche et afficher les résultats de la recherche
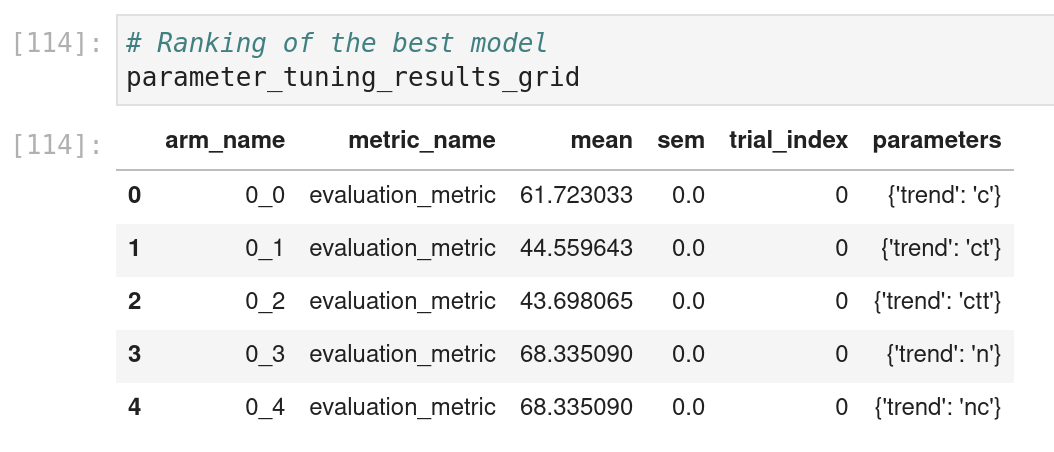
Dans ce cas, je n’utilise pas le package entier, mais il y a aussi l’utilisation d’un package de Facebook appelé AX ; j’ai rencontré l’un des développeurs de ce package autour de l’expérimentation lors d’une conférence, et c’est intéressant de le voir mentionné dans KATS.
Pour être honnête et revenir à la compétition Kaggle, ces deux approches pour optimiser le modèle n’ont pas apporté trop de valeur au classement (mais je n’ai pas mis trop d’efforts dans la recherche).
Plongeons maintenant dans une autre fonctionnalité du package autour de la détection d’anomalies
Détection d’anomalies
Ces fonctions sont sous les fonctions kats.detector, comme la prévision, plusieurs façons de détecter des anomalies dans une série temporelle sont possibles, et l’appel est élémentaire. Pour tester cette fonctionnalité, je vais l’appliquer dans la série temporelle que j’ai utilisée dans mon article autour de l’analyse causale et prophet en R pour détecter les anomalies dans les crimes de Montréal (moments amusants).
Il y a un gist pour expliquer la première approche pour détecter quelques points de changement dans la série temporelle de tous les crimes.
Et globalement, il y a une représentation de la sortie avec les fonctions intégrées.
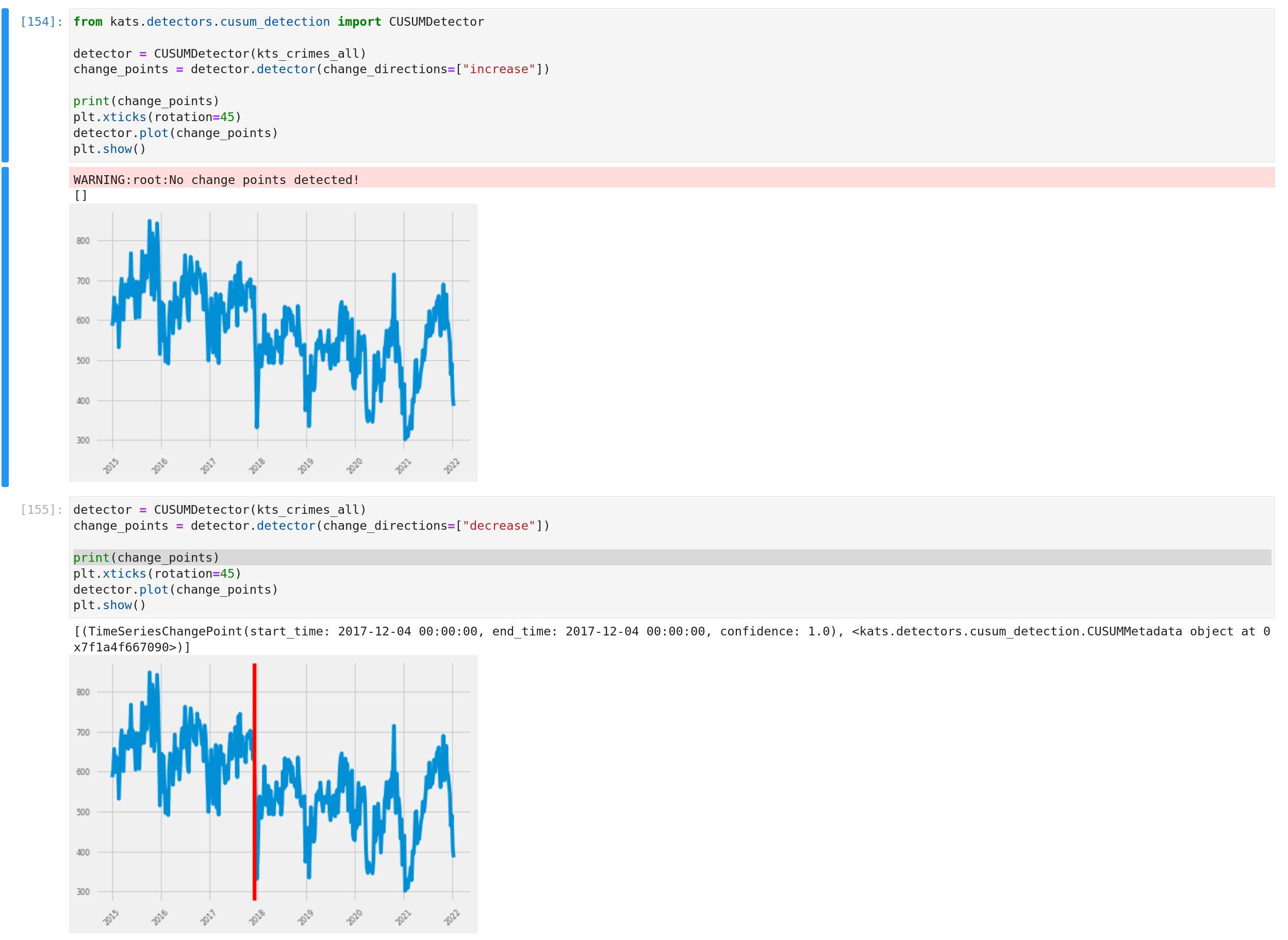
L’idée du détecteur est de fournir le type de phénomène que nous voulons détecter (une augmentation ou une diminution) et la sortie s’il y a quelque chose à afficher sur le graphique avec les fonctions intégrées (j’ai changé le style de matplotlib parce que les points de changement sont rouges).
Il est également possible de fournir une fenêtre d’intérêt au détecteur pour concentrer la détection et d’appliquer une détection d’anomalies de fenêtre glissante (avec la méthode de votre choix, dans ce cas, la somme cumulée)
Il y a les résultats.
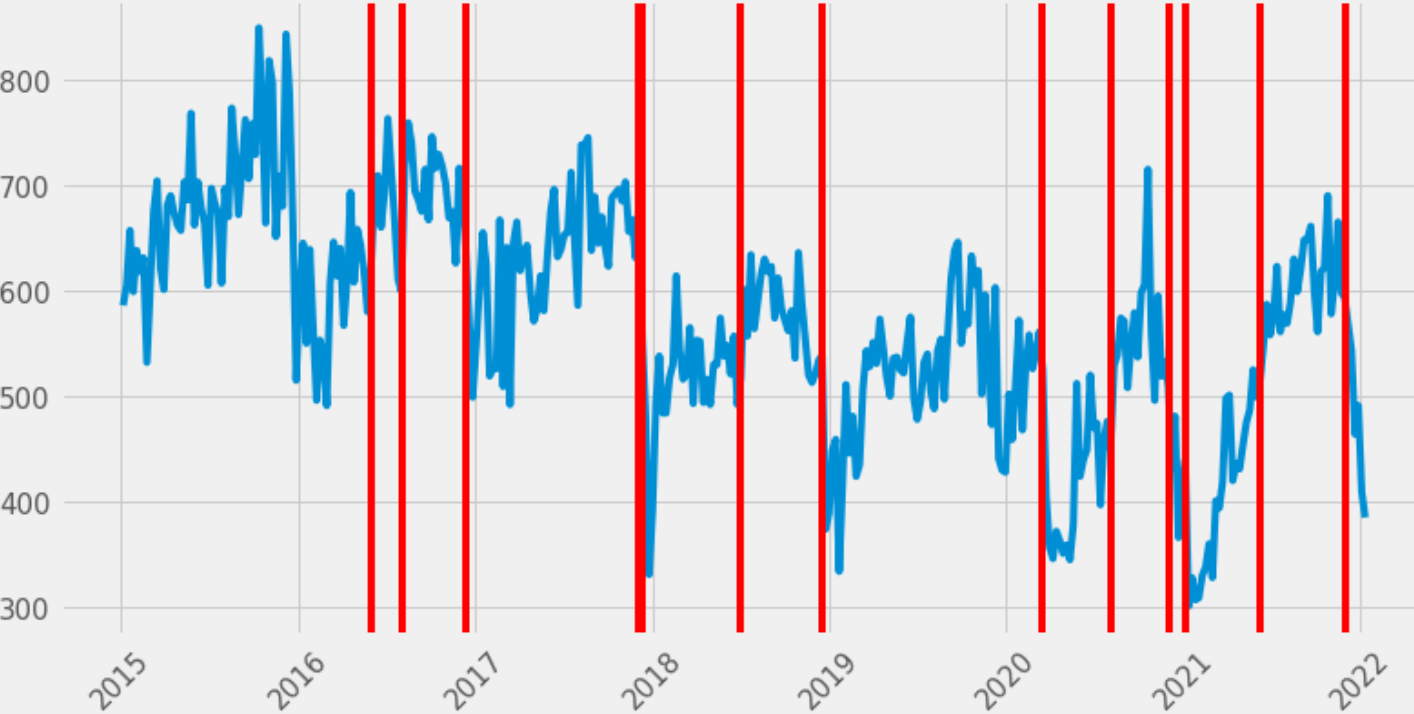
De nombreuses anomalies sont détectées le long des données historiques, et quelques anomalies sont liées au confinement covid (cf mon article à ce sujet).
Il y a deux fonctionnalités sur le détecteur (exemple ici) également disponibles, mais je n’ai pas trop creusé :
- Détecteur de tendance
- Détection de valeurs aberrantes
Pour conclure, voyons le composant autour de l’extraction de caractéristiques d’une série temporelle.
Séries temporelles et ingénierie des caractéristiques
Je vais utiliser les données liées à mon jeu de données Kaggle autour de la consommation énergétique des ménages à Londres et construire une caractéristique de série temporelle pour les ménages. Il y a un gist simple pour illustrer le flux.
Et à la fin, vous pouvez accéder à beaucoup d’informations sur une série temporelle
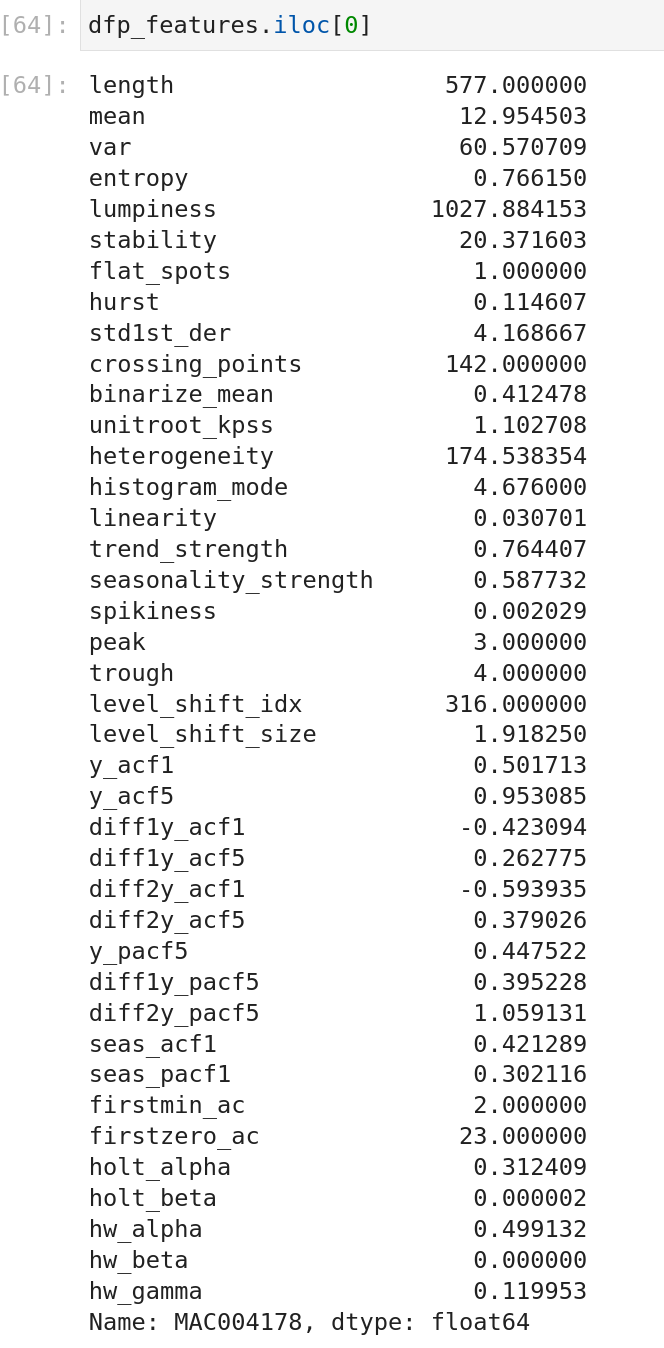
Tant de fonctionnalités sont disponibles ; il serait terrible de toutes les décrire, donc je vous invite à regarder la documentation avec toutes les références, mais vous pouvez également limiter la portée des fonctionnalités à afficher.
J’ai fait une comparaison rapide de l’entropie de la caractéristique et de ses valeurs extrêmes.
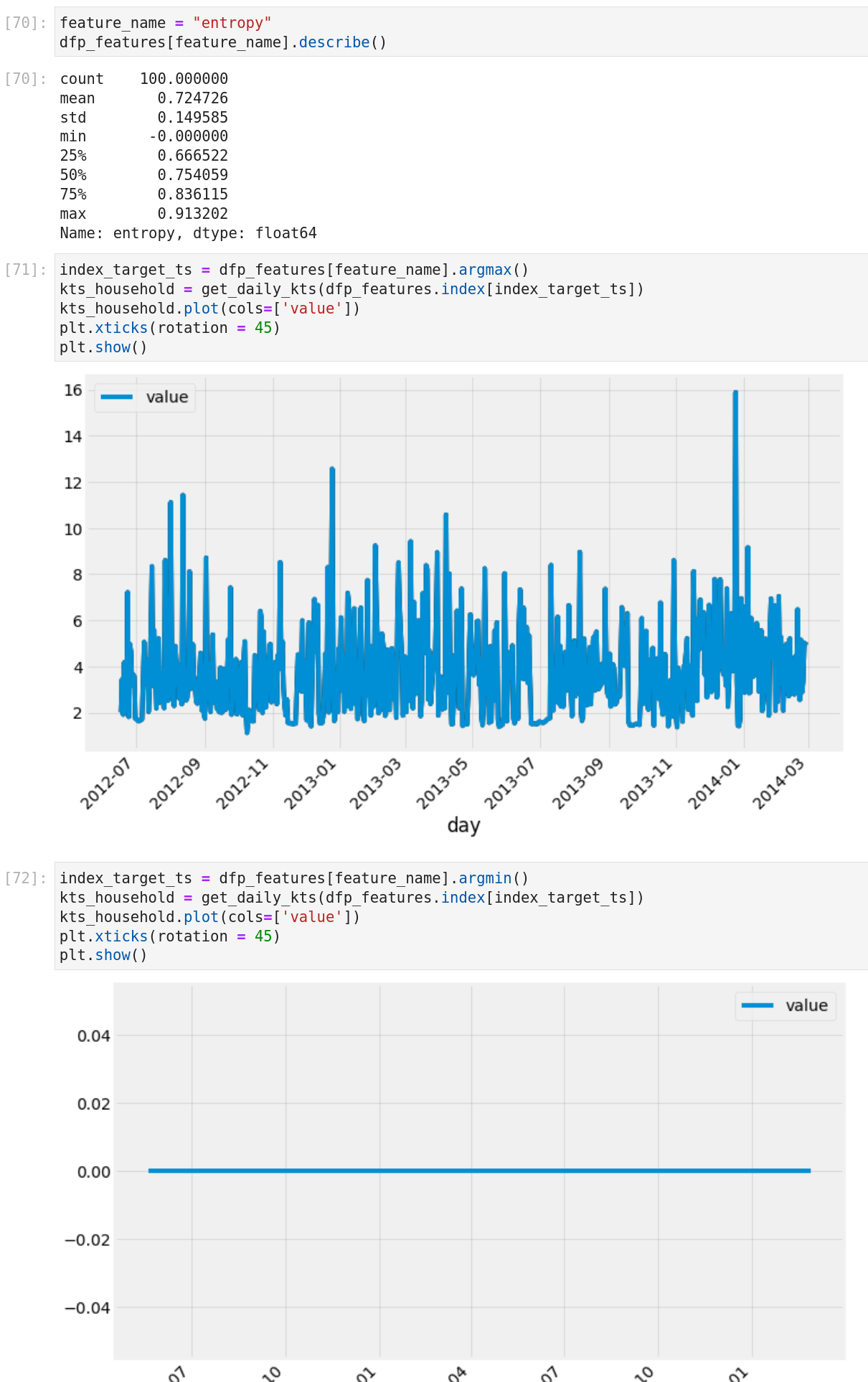
Donc un moyen facile de détecter une série temporelle de ligne plate, par exemple.
Conclusion
C’était une exploration simple du package kats que j’ai faite pendant cet article, et si vous voulez plus d’informations sur le fonctionnement du package, vous pouvez regarder tous les tutoriels et la documentation. J’ai aimé mon expérience avec le package, et dans l’ensemble, mes principaux points à retenir sur ce package sont :
- Pour exploiter le package, vous devez convertir la série temporelle dans un format kats (mais c’est simple)
- Construire un modèle de prévision est très facile, très similaire à ce qui était possible avec prophet mais étendu à de nombreuses approches différentes pour faire de la prévision
- Détecter les anomalies est si simple
- Si vous ne savez pas quelles caractéristiques peuvent être extraites d’une série temporelle (pour faire du clustering, par exemple), tsfeature est votre point de départ
Références
- KATS — facebookresearch.github.io
- kats.models — facebookresearch.github.io
- kats.detectors — facebookresearch.github.io
- kats.tsfeatures — facebookresearch.github.io
- Format TimeSeriesData — facebookresearch.github.io
- Kaggle Tabular Playground Series Janvier 2022 — Kaggle
- Article Prophet — peerj.com
- LSTM pour la prévision de séries temporelles — machinelearningmastery.com
- ARIMA pour la prévision de séries temporelles avec Python — machinelearningmastery.com
- API Python Prophet — facebook.github.io
- SMAPE — Wikipedia — Wikipedia
- Tutoriel méta-apprentissage (Kats) — GitHub
- Tutoriel optimisation des hyperparamètres (Kats) — GitHub
- Article méta-apprentissage de Facebook — arXiv
- Méta-apprentissage sur machinelearningmastery — machinelearningmastery.com
- Modèle multivarié Kats — facebookresearch.github.io
- hyperopt — hyperopt.github.io
- AX — ax.dev
- Article modèle Theta — sciencedirect.com
- Holt-Winters forecasting simplified — orangematter.solarwinds.com
- Régression linéaire et quadratique — digfir-published.macmillanusa.com
- Tutoriel détection Kats — GitHub
- Jeu de données Kaggle — Smart Meters in London — Kaggle
- Tutoriels Kats sur GitHub — GitHub
- Package Prophet — facebook.github.io