
Déployez votre pipeline de données avec Docker et AWS ECS
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
J’ai récemment décidé d’expérimenter avec des conteneurs Docker pour construire des applications autonomes afin d’optimiser le flux d’opération de mes différents pipelines de données/scraper. J’ai une expérience limitée avec Docker ; je l’ai utilisé dans quelques PoC dans mon précédent emploi et quelques tests de bibliothèques comme NVIDIA Merlin. Cet article décrira mon expérience et les composants de l’un de mes pipelines fonctionnant dans un conteneur Docker dans AWS.
Vue d’ensemble du pipeline
L’application que je veux livrer est un pipeline typique que j’exploite pour obtenir des données pour mes projets secondaires. Ce pipeline vise à atteindre une source de données, collecter de nouvelles données et les stocker quelque part dans le cloud ; dans la figure suivante, il y a un aperçu du pipeline.
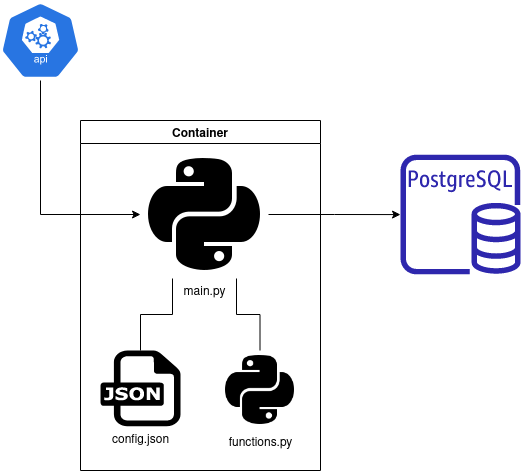
L’idée du pipeline est d’appeler une API pour récupérer de nouvelles informations via le script main.py qui enregistrera de nouvelles données dans l’instance PostgreSQL sur AWS (dans une base de données dédiée).
J’ai configuré cette instance PostgreSQL pour un projet futur, et la configuration est minimale (j’ai utilisé la configuration par défaut pour un niveau gratuit AWS pour commencer). Je recommande fortement d’utiliser pgadmin pour l’interaction manuelle avec les différentes bases de données de votre instance (j’ai créé la base de données pour ce projet en quelques clics).
Le script principal collectera les informations d’identification (informations utilisateur) pour atteindre la base de données via le fichier config.json (pour construire les informations d’identification, j’ai utilisé une commande CREATE USER avec un mot de passe sur pgadmin) et écrire les nouveaux contenus dans la base de données. De plus, le script main.py appelle des fonctions externes écrites dans le fichier functions.py, une liste de fonctions qui peuvent être réutilisées dans d’autres parties du projet global (je prévois d’en faire un package plus accessible dans le futur pour maintenir et déployer).
PS: Pendant la conception de cette application, j’ai trouvé la chaîne YouTube de John Watson Rooney ; il y a d’excellentes explications sur la façon de structurer votre code dans un contexte de scraper comme dans cette vidéo.
Le conteneur est composé de tout ce code ; si vous voulez voir plus de détails sur la structure des fichiers, il y a un lien vers le dépôt.
Voyons maintenant le conteneur plus en détail.
Construire le conteneur
Dans la description de cet article, je mentionne Docker et conteneur, mais qu’est-ce qu’un conteneur ? D’après la documentation Docker, un conteneur est
“une unité logicielle standard qui regroupe le code et toutes ses dépendances, de sorte que l’application s’exécute rapidement et de manière fiable d’un environnement informatique à un autre. Une image de conteneur Docker est un package logiciel léger, autonome et exécutable qui comprend tout ce qui est nécessaire pour exécuter une application : code, runtime, outils système, bibliothèques système et paramètres.”
C’est une définition assez cool, hein !? En mes mots, un conteneur est juste une application fonctionnant comme autonome dans un coin d’un serveur en totale indépendance, et qui peut être déployée sur toutes sortes de machines :). Cette approche, de mon point de vue, est efficace et était un excellent substitut pour une machine virtuelle qui est (pour moi !?) une machine entière (OS + application) où le conteneur est juste l’application directement. Si vous voulez en savoir plus sur la différence entre conteneur et machines virtuelles, il y a une vidéo intéressante d’IBM ou la section conteneur du cours 5 full stack deep learning.
Tout d’abord, j’avais besoin d’installer Docker CLI sur ma machine ubuntu, et j’ai suivi ce tutoriel.
PS: dans ce tutoriel, ils conseillent de sudo l’installation, mais après pour moi, je dois sudo sur toutes mes commandes docker, donc peut-être pas le mouvement le plus brillant à faire.
Avec tout configuré, parlons du conteneur ; comme mentionné précédemment, il y a actuellement le script principal, avec une dépendance de fonctions et un fichier de configuration pour l’exécution. Ces fichiers sont à la racine du projet. Parallèlement au code pour l’exécution, nous avons besoin d’avoir :
- Informations sur l’environnement python pour l’exécution, j’ai construit un fichier requirements.txt avec les dépendances. Il y a une copie du requirements.txt
requests==2.25.1
beautifulsoup4==4.9.3
# psycopg2==2.9 # commented to highlight the usage of binary
psycopg2-binary==2.9.3
SQLAlchemy==1.4.39
pandas==1.1.3
joblib==1.1.0Cet environnement utilise pyscopg2 pour interagir avec la base de données et mettre à jour des informations sur certains éléments. Malheureusement, le package de base est incompatible, et la version binaire doit être installée pour fonctionner sur un conteneur docker.
- Une configuration pour le conteneur dans le fichier DockerFile. Ce fichier est comme un script bash avec les différentes étapes à exécuter. Il y a une copie du fichier.
FROM python:3.6.12-slim-buster
WORKDIR /app
COPY requirements.txt requirements.txt
RUN pip3 install --upgrade pip
RUN pip3 install -r requirements.txt
COPY . .
CMD [ "python3", "main.py", "--config", "config.json"]
#CMD [ "python3", "main.py", "--config", "config.json", "--debug"] # To test the code in debug modeDans le DockerFile, il y a les différentes étapes à exécuter :
- Définir la saveur de l’application ; dans ce cas, une application python 3.6
- Création d’un répertoire de travail
- Installation des dépendances avec pip
- Exécution d’une commande python3
Cette dernière commande est composée de deux arguments, un lié à l’emplacement du fichier de configuration et l’autre au mode d’exécution (en mode debug, ce qui est pratique pour tester le pipeline entier). Il y a un exemple de la fonction pour analyser les arguments dans le script principal.
import argparse
def get_arguments():# Function to get the argument provided with the python cmd
parser = argparse.ArgumentParser(description='Collect new data')
parser.add_argument('--config', type=str, help='Location of the configuration file of the pipeline', default="./config.json")
parser.add_argument('--debug', help='Boolean to determine the mode of execution', action="store_true")# To manage boolean
args = parser.parse_args()
return argsLa gestion d’un argument booléen peut ne pas être évidente, donc je voulais le partager ici. Si vous voulez plus de détails, regardez l’échantillon dans le dépôt GitHub encore une fois.
Pour exécuter le conteneur, vous devez être dans le même dossier et exécuter la première commande pour construire le conteneur et la deuxième pour l’exécuter.
# Build the container
sudo docker build --tag sc-collect-new-data .
# To test the execution
sudo docker run sc-collect-new-dataTout est configuré ; voyons comment le déployer dans le cloud.
Livrer le conteneur sur le cloud
J’ai décidé de sauter la méthode traditionnelle old-school EC2 pour déployer sur AWS. Je voulais avoir une stack qui pourrait répondre aux besoins car généralement, pour ce genre de projet, il n’y a pas besoin d’avoir pendant des jours une machine qui fonctionne parce que, dans les applications de scraping, il y a deux éléments clés :
- Avec la ruée du lancement, beaucoup de données à collecter, mais après quelques jours, cela peut être moins de données
- Parfois le pipeline peut casser (dépasser l’appel API par minute)
Une excellente alternative pour avoir un serveur à temps plein fonctionnant est d’exploiter un service comme ECS pour exécuter des conteneurs et utiliser AWS Fargate comme moteur de calcul sans serveur (merci, @Antoine Leproust et @Geoffrey Muselli, pour le brainstorming rapide du matin sur le sujet).
Je ne suis pas un expert sur ce sujet, donc si vous voulez en savoir plus sur les technologies, regardez la documentation ou cette vidéo Techworld with Nana qui récapitule le service pour lancer un conteneur sur AWS.
Revenons au projet :)
Tout d’abord, pour exploiter ECS, je dois déployer le conteneur dans le cloud, et il y a un service d’AWS appelé ECR qui est comme votre banque de conteneurs. Les deux commandes suivantes étaient les plus critiques pour interagir facilement avec le service.
#Create a repository
aws ecr create-repository --repository-name sc-collect-new-data
#Make the connection between AWS and Docker
aws ecr get-login-password --region us-east-1 | sudo docker login --username AWS --password-stdin accountid.dkr.ecr.region-code.amazonaws.comPS: important le lien de connexion est lié à votre compte AWS et région (défini par l’accountid et le code de région
Construisons et déployons le conteneur avec les commandes suivantes.
#Build the container with the right tag for the deployment
docker build --tag accountid.dkr.ecr.region-code.amazonaws.com/sc-collect-new-data .
#Push the container
docker push accountid.dkr.ecr.region-code.amazonaws.com/sc-collect-new-dataPS: J’ai mis toutes les 3 commandes précédentes dans un script bash pour faciliter le processus de déploiement avec juste une commande.
L’étape finale du déploiement est comment configurer le travail dans ECS ; il y a deux étapes principales :
- J’ai configuré un cluster ECS sur l’UI AWS en quelques clics, et j’ai utilisé les valeurs par défaut.
- Créer une tâche avec l’outil de définition de tâche (cf image, besoin de pointer vers le conteneur dans ECR, et pour l’étape 2, j’ai utilisé les valeurs par défaut)
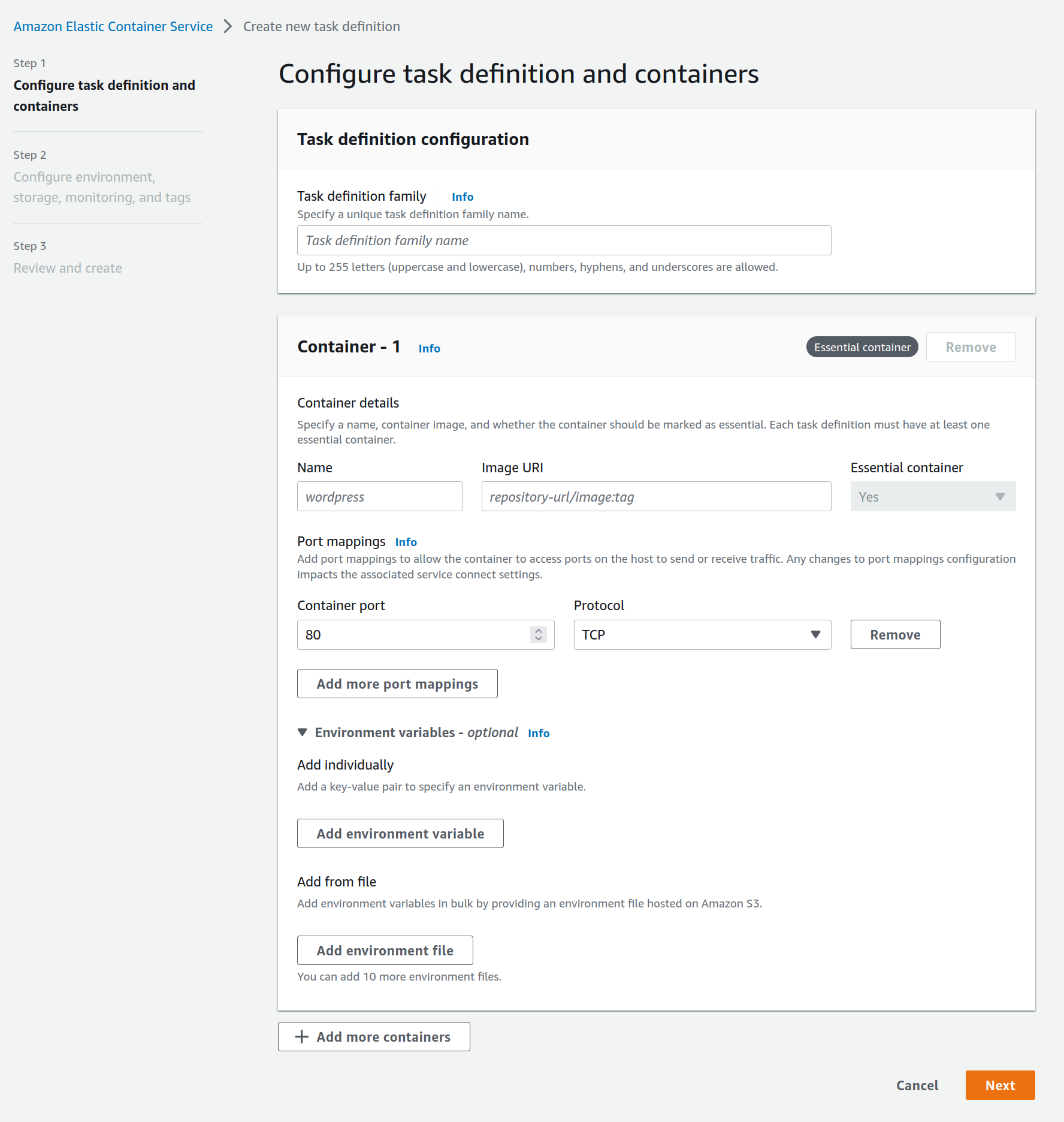
L’AWS CLI ou boto3 peut également être utilisé pour ces deux étapes. Tout est prêt pour le calcul ; planifions-le.
Je n’ai pas trouvé d’option pour planifier une tâche depuis ECS, donc j’ai décidé de construire une application Chalice (je l’ai utilisée dans le passé pour mon article sagemaker et scrapper Twitter, donc si vous voulez quelques exemples de code). Dans ce cas, il y a la structure globale du code des applications chalice.
from chalice import Chalice, Rate
import boto3
app = Chalice(app_name='ecs_task_checker')
@app.schedule(Rate(7, unit=Rate.DAYS))
def every_week(event):
for task_definition in ["name-of-the-task"]:
check_task(task_definition)
@app.schedule(Rate(1, unit=Rate.HOURS))
def every_hour(event):
for task_definition in ["name-of-the-task"]:
# for task_definition in []:
check_task(task_definition)L’idée est d’avoir différents lambdas basés sur la fréquence de mises à jour de mon pipeline pour redéclencher la tâche au cas où elle serait inactive. Le script teste le statut de la tâche et redéclenche si nécessaire. J’ai basé la fonction sur des articles riches en ressources comme celui-ci.
def check_task(task_definition):
client = boto3.client("ecs",
region_name="us-east-1",
aws_access_key_id="aws_access_key_id",
aws_secret_access_key="aws_secret_access_key"
)
paginator = client.get_paginator('list_tasks')
response_iterator = paginator.paginate(
PaginationConfig={
'PageSize':100
}
)
task_running = False
for each_page in response_iterator:
for each_task in each_page['taskArns']:
response = client.describe_tasks(tasks=[each_task])
if (response["tasks"][0]["group"].replace("family:", "") == task_definition) and (response["tasks"][0]["lastStatus"]):
task_running = True
break
if task_running:
break
if not task_running:
print("Relaunching the task")
response = client.run_task(
taskDefinition=task_definition,
launchType='FARGATE',
cluster='default',
platformVersion='LATEST',
count=1,
networkConfiguration={
'awsvpcConfiguration': {
'subnets': [
'subnet-id',
],
'assignPublicIp': 'ENABLED',
'securityGroups': ["security_group_id"]
}
}
)La chose critique à retenir est le groupe de sécurité et le sous-réseau qui nécessite la configuration appropriée pour répondre aux exigences de la base de données à atteindre.
Et voilà, il y a un pipeline de données dans un conteneur fonctionnant sur le cloud de manière sans serveur.
Conclusion
Dans l’ensemble, cela a été une expérience intéressante de travailler avec Docker pour standardiser le déploiement de mon pipeline de données. De plus, cela me donne un point de départ pour les projets de données suivants en ayant un squelette d’environnement et une structure de mon code (je vois également beaucoup d’améliorations).
Les conteneurs Docker sont une façon passionnante de travailler et, pour mon domaine ML, une excellente façon d’emballer votre pipeline. ECR et ECS avec Fargate sont un excellent combo pour opérer votre conteneur efficacement, mais d’après ce que je vois, l’utilisation de GPU semble impossible.
Il y a toujours des débats animés sur ce qu’un data scientist devrait savoir sur la façon de déployer des pipelines et des modèles (un bon article sur le sujet de Chip Huyen ICI), et je pense que travailler sur ce projet était un moment parfait pour :
- Mieux comprendre la structure d’un conteneur ; honnêtement, je l’ai trouvé assez simple à utiliser dans ce contexte (et je pense qu’exécuter un travail d’entraînement pour un projet ML ne sera pas plus difficile)
- Déployer des conteneurs dans le cloud ; je ne suis pas familier avec Kubernetes, mais des services comme ECS sont robustes et un bon départ pour les gens qui veulent déployer des pipelines.
Références
- pgadmin — pgadmin.org
- Documentation PostgreSQL — CREATE USER — postgresql.org
- Dépôt GitHub docker-container-data-pipeline-template — GitHub
- Documentation Docker — Qu’est-ce qu’un conteneur ? — docker.com
- VMware — Qu’est-ce qu’une machine virtuelle ? — vmware.com
- Full Stack Deep Learning 2022 — Leçon 5 : Déploiement — fullstackdeeplearning.com
- Installation Docker Desktop sur Ubuntu — docker.com
- AWS ECS — AWS
- AWS Fargate — AWS
- AWS ECR — AWS
- AWS Chalice — aws.github.io
- Travailler avec ECS en Python avec boto3 — hands-on.cloud
- Chip Huyen — Infrastructure data science — huyenchip.com