
Retour de Recsys 2022
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Bonjour, c’est l’automne et qui dit automne dit période RecSys, et cette année Seattle était l’endroit où il fallait être. J’ai assisté numériquement à la conférence (Merci Ubisoft), et dans cet article, je vais récapituler les articles/posters que j’ai trouvés intéressants.
Construire des moteurs de recherche plus intelligents
Les systèmes de recommandation et les moteurs de recherche sont des applications étroitement liées et classées comme applications de découverte (Eugene yan), et j’ai trouvé que cette année il y avait des ressources passionnantes sur le sujet.
Learning Users’ Preferred Visual Styles in an Image Marketplace (Shutterstock)
Dans cet article, Shutterstock présente leur moteur de recherche basé sur une jointure avec un système de recommandation. L’idée est d’utiliser le moteur de recherche classique comme générateur de candidats (comme un système de recommandation à deux étapes) et, après avoir utilisé un “recsys de style visuel” pour ordonner ces candidats.
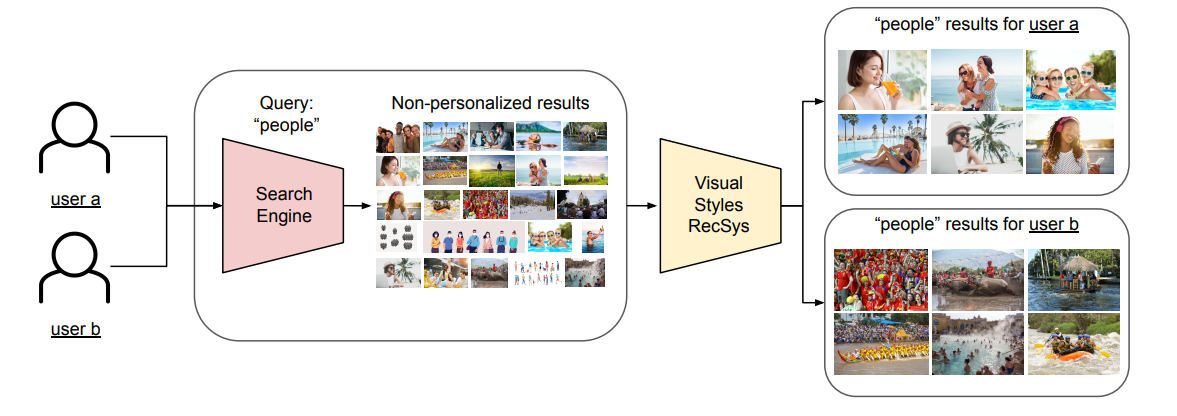
Les fonctionnalités dans le “recsys de style visuel” sont intéressantes ; il utilise le type d’abonnement (primordial dans ce type de modèle commercial car le catalogue sera différent) et l’userid car ils voulaient également encoder l’identité des utilisateurs. De plus, il y a des fonctionnalités autour de la couleur, de l’angle et du style pour l’image (pas trop de détails sur la façon dont ils construisent ces fonctionnalités).
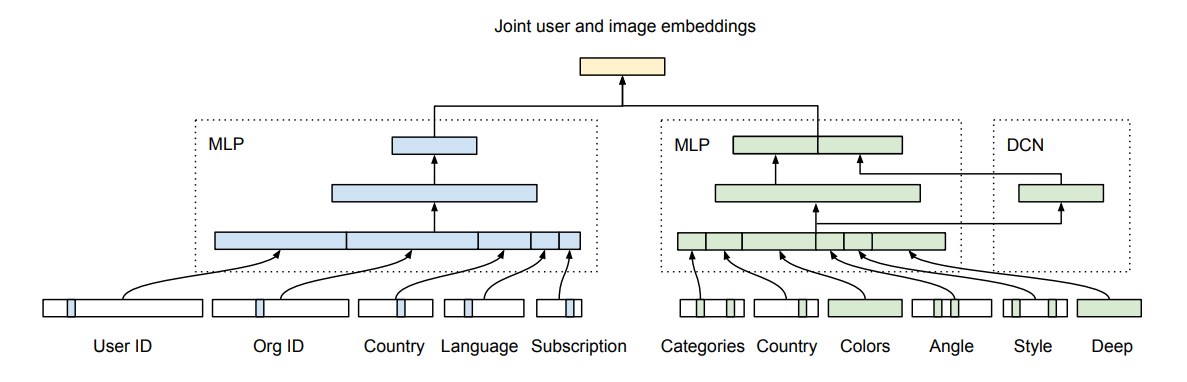
Le processus est ingénieux et, je pense, assez efficace pour le calcul ; malheureusement, il n’y avait rien sur l’industrialisation car il semble qu’ils commencent juste à le tester en direct (mais ils prévoient de communiquer les résultats).
PS: Récemment, Shutterstock a publié un excellent article sur leur approche pour construire des recommandations (et ils ont présenté ce projet). Très haut niveau mais quelques découvertes notables :
- Ils utilisent metaflow et TensorFlow recommenders
- Shutterstock fournit des services de conseil en IA
- Ils ont des articles de blog intéressants autour des couleurs et d’autres sujets ; c’est une excellente façon de promouvoir les travaux
Augmenting Netflix Search with In-Session Adapted Recommendations (Netflix)
Dans ce cas, la recherche est basée sur plusieurs facteurs ; il y a une représentation des données d’entrée.
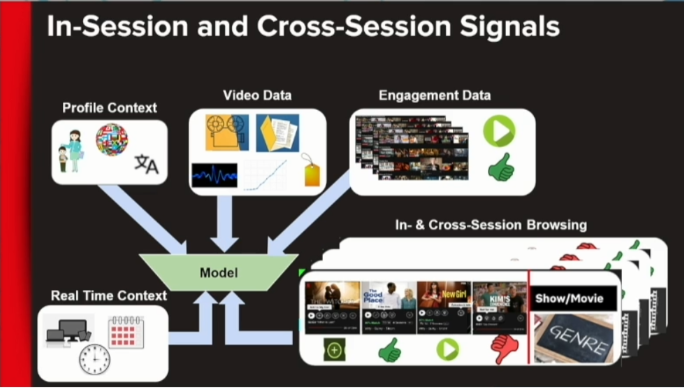
La partie passionnante est qu’ils utilisent les informations sur l’utilisateur mais aussi les informations en session ; leur stack est représentée dans l’article semble standard, et j’ai découvert un concept de serveur JIT (just in time). Malheureusement, le modèle sous le capot est assez flou ; ils semblent avoir testé “des architectures RNN simples, LSTM, LSTM bidirectionnel et transformateur”. D’un autre côté, le système semble avoir augmenté les métriques hors ligne de 6% (cela semble petit, mais je serais curieux de le voir en ligne).
Dans cette présentation, il y avait des mentions de deux articles perspicaces de Netflix :
- Le premier autour des Challenges in Search on Streaming Services: Netflix Case Study, semble lister quelques éléments critiques pour concevoir un système de recherche (m’a donné quelques idées pour expérimenter sur des projets secondaires)
- Un autre article sur la conception du système de recherche chez Netflix ressemble aux détails qui manquaient dans l’article précédent, donc un bon ajout.
Les transformateurs unis
Ils ont commencé à faire leur trou il y a quelques années, mais ils brillent sur cette édition.
A Systematic Review and Replicability Study of BERT4Rec for Sequential Recommendation (Glasgow university)
Un article de l’université de Glasgow sur la façon d’exploiter d’autres architectures de Transformers pour construire de meilleurs systèmes de recommandation, les transformeurs pour recsys était une tendance importante l’année dernière, et cet article met en évidence deux choses :
- Reproduire les résultats des articles n’est parfois pas possible #humainaprèstout
- D’autres architectures semblent faire un excellent travail en termes de performance.
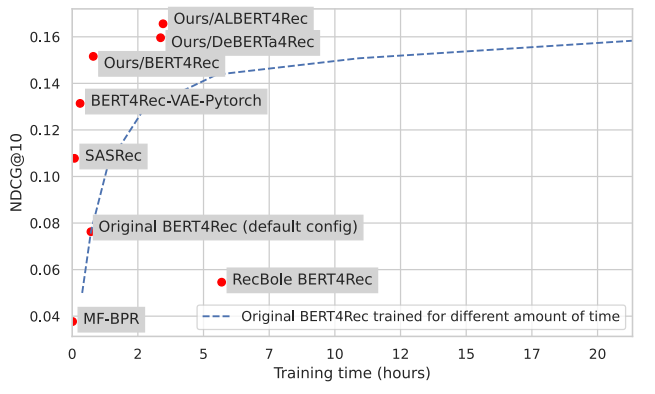
Il semble être (plus difficile !?) meilleur, plus rapide (plus fort !?).
Je ne suis pas familier avec les transformeurs #dlnoob, mais cet article est étonnant pour attraper quelques architectures passionnantes.
Il y a un dépôt GitHub associé à ces deux derniers articles ICI.
Rethinking Personalized Ranking at Pinterest: An End-to-End Approach (Pinterest)
Cet article est un excellent ajout à une série d’articles que Pinterest a commencée sur leur blog tech il y a quelques semaines. Dans cet article, il y a une représentation de l’une de leurs approches pour construire un système de recommandation d’images/épingles.
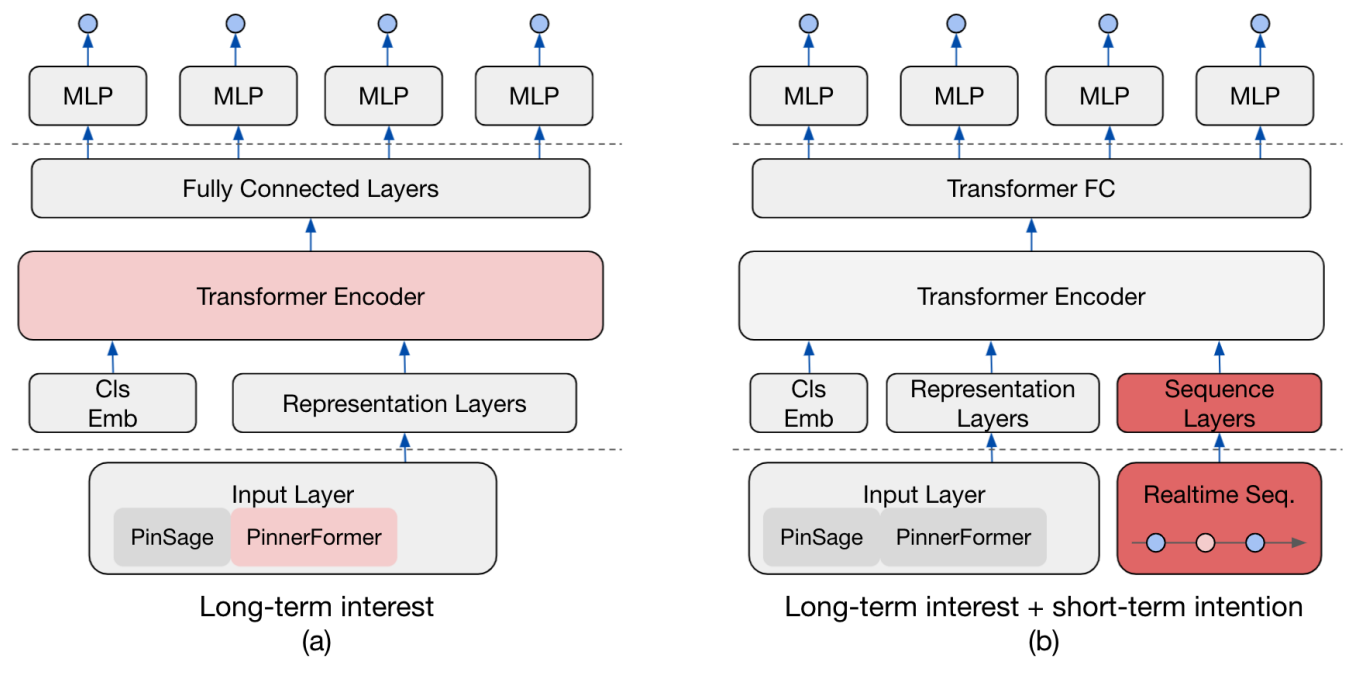
L’idée du système de recommandation est de mélanger des modèles qui construiront des fonctionnalités à long terme et à court terme. Ensuite, ces fonctionnalités seront injectées dans un transformateur pour produire des recommandations (il semble avoir été appliqué dans le flux d’accueil et les annonces d’épingles liées).
La partie passionnante est la conception des fonctionnalités :
- Long terme : ils construisent deux composants appelés pinnerformer et pinsage pour traiter les événements
Pour pinnerformer, ils ont un processus pour extraire des fonctionnalités des interactions de la dernière année.
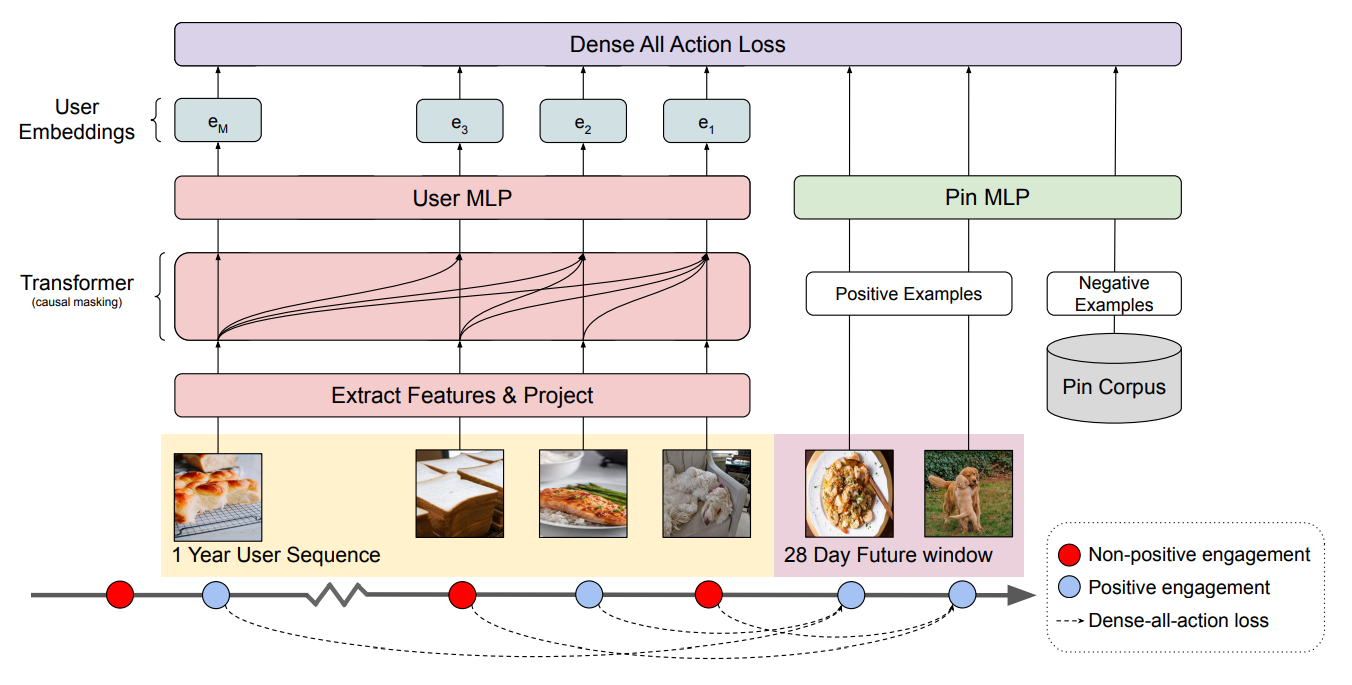
Pour pinsage, ce n’est pas détaillé dans l’article, mais il y a plus de détails sur leur blog ICI qui exploitent le CNN graphique pour traiter les données.
- Court terme : le processus os court détails, mais ils semblent exploiter des embeddings impressionnants de pinsage sur les actions récentes (et pas les plus récentes, mais ils font du fenêtrage temporel car le système était trop réactif)
Le processus a un impact positif sur l’expérience de l’utilisateur, avec un gain d’environ 7 à 15% selon la configuration du recsys.
Ce travail est également une bonne illustration de leur façon d’optimiser le calcul avec GPU ; ils ont construit un excellent article sur leur blog tech (ICI), et il y a un tableau de comparaison des gains basé sur le type de modèles (sa taille) et la mise à niveau de l’infrastructure.
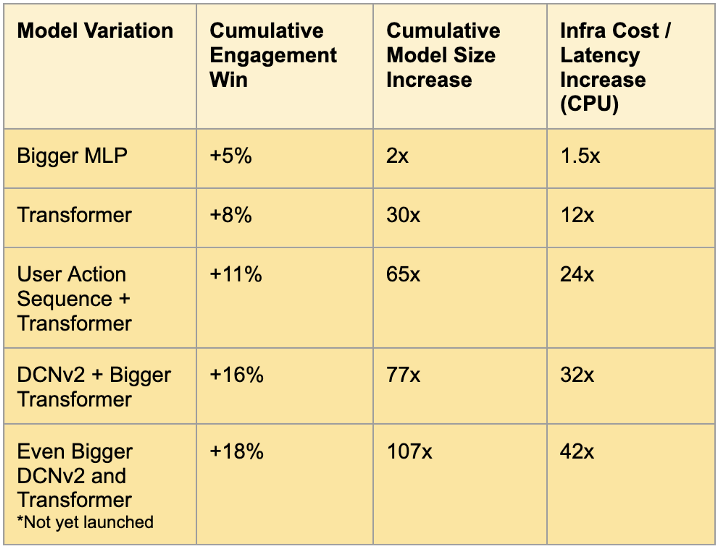
Il commence à être intéressant de déployer de gros modèles sans une augmentation significative des coûts.
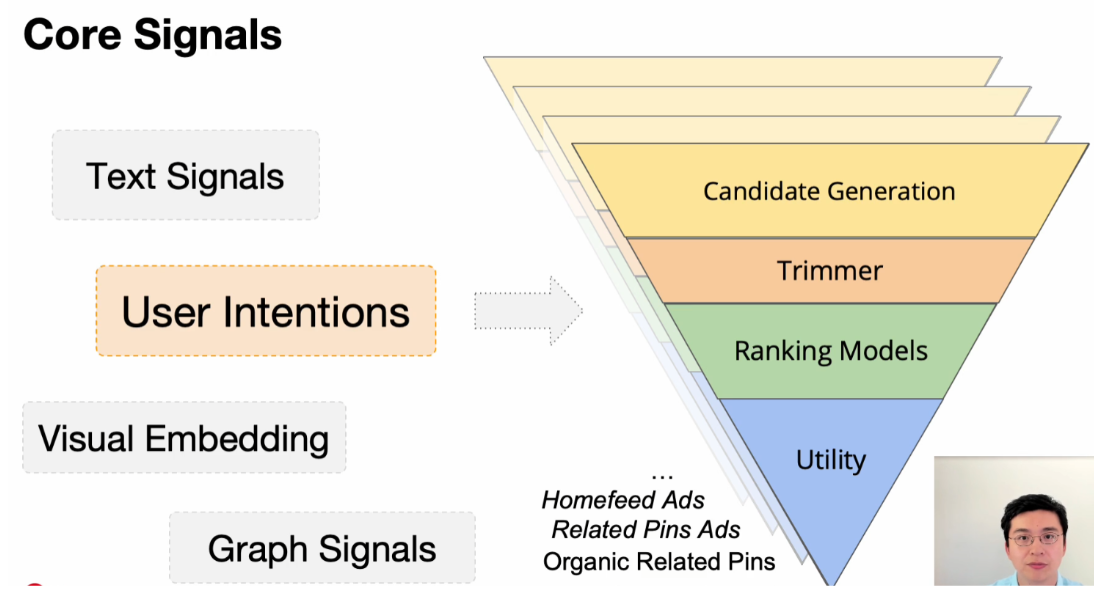
PS: dans la vidéo, ils ont également une excellente façon de diviser un système de recommandation en quatre niveaux/étapes/steps dans une pyramide.
BRUCE - Bundle Recommendation Using Contextualized item Embeddings (University of the Negev)
Dans cet article, les auteurs ont abordé le problème de la recommandation de bundles d’articles ; la situation peut être complexe. Le cœur de l’approche du modèle est basé sur les Transformers, mais ils ont conçu différentes approches pour l’alimenter.
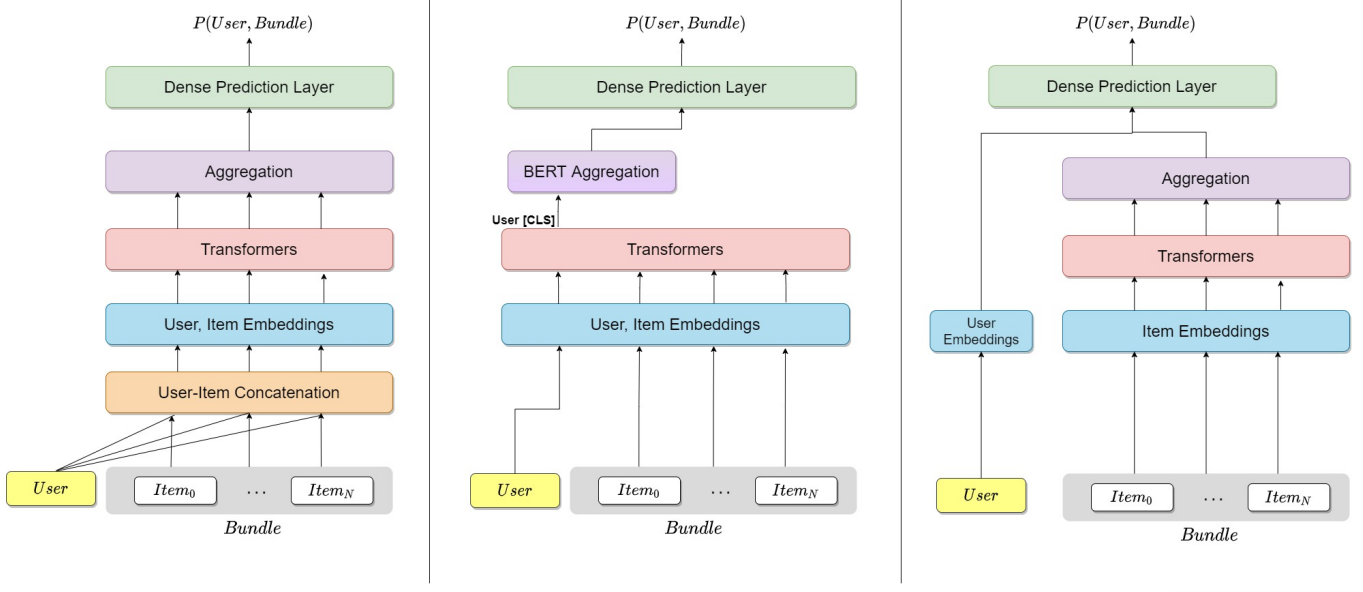
Leurs résultats semblent prometteurs, avec une amélioration des métriques de précision entre 20% et 36%.
A Lightweight Transformer for Next-Item Product Recommendation (Wayfair)
Encore une fois, un autre transformateur (je pense que nous avons plus d’articles dans cet article avec le modèle Transformer que les films Transformers), mais celui-ci avait une petite tournure intéressante liée au déploiement et à l’évaluation.
Le modèle est basé sur l’implémentation SAS2Rec (de Wang-Cheng Kang et Julian McAuley). Le recsys ingère la séquence des articles vus, a réussi à catégoriser à partir d’une projection des embeddings d’articles les articles de la même catégorie (basé sur leur prix, popularité, style et fonctionnalité).
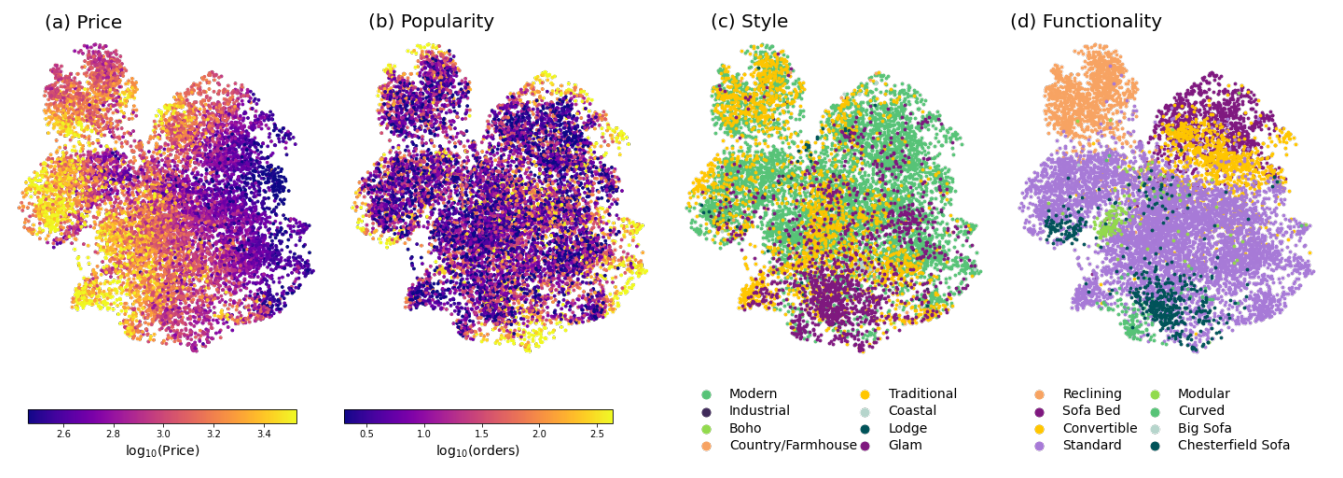
J’aime cette façon de visualiser l’embedding. Mais les parties les plus importantes de cet article sont :
- Le déploiement de ce modèle dans différentes zones du globe semble montrer des résultats et des performances différents, ce qui peut avoir du sens car le catalogue peut être différent, et les besoins.
- Ils soulignent que le rappel et le ndcg ne sont pas si formidables pour l’évaluation hors ligne, et MRR (mean reciprocal rank) est adéquat dans leur contexte.
PS: Wayfair semble avoir un techblog très solide avec beaucoup de sujets de l’IA à l’UI/UX.
Au-delà et autour des systèmes de recommandation
Il y a une compilation d’initiatives passionnantes pour améliorer votre expérience de système de recommandation.
Personalizing Benefits Allocation Without Spending Money (Booking.com)
Le concept de recommandation de réduction est un domaine passionnant pour les entreprises vendant des offres. Pour une entreprise de réservation d’être capable de garder l’utilisateur dans la boucle de leur site web pour l’ensemble de leur voyage est un excellent mouvement pour garder leur client à long terme. Le principal problème avec la réduction est que potentiellement l’entreprise peut perdre de l’argent en faisant trop ou de trop grandes réductions ; l’article (principalement la présentation de l’article car l’article est assez léger) de booking discute de cet aspect.
Derrière l’optimisation de la réduction se trouve l’utilisation de techniques sous la modélisation d’uplift, qui vise à prédire le CATE (Conditional Average Treatment Effect). Ensuite, sur une base de travail plus humaine, essayez de prédire l’impact d’un changement sans déployer, ce qui est très similaire à l’analyse causale et une excellente alternative aux tests AB.

Même si l’article n’est pas très détaillé, Booking a fait un excellent travail de démocratisation de leur travail :
- Il y a un excellent tutoriel disponible sur leur blog tech sur le sujet de la personnalisation ICI (modélisation d’uplift ICI)
- Ils ont un dépôt GitHub sur un package appelé upliftML qui peut aider à faire quelques tests ICI.
C’est une façon passionnante d’optimiser les tests et de limiter les risques potentiels avant de déployer un test en production. Cependant, je ne suis toujours pas sûr de la précision qu’il peut avoir avant de soumettre la réduction recommandée (j’ai besoin d’en lire plus à ce sujet).
Outils autour de recsys: Quelques initiatives intéressantes autour de meilleures explications des recommandations ; il a toujours été intéressant d’être plus transparent avec les personnes utilisant un système de recommandation pour l’un de leurs projets.
RepSys: Framework for Interactive Evaluation of Recommender Systems (Czech Technical University in Prague)
Surveiller un système de recommandation, selon le contexte (en direct ou par lots pour le service), peut être écrasant car vous pouvez calculer de nombreuses métriques, avoir un niveau d’agrégations différent et beaucoup d’informations à afficher. Dans ce projet, ils proposent un outil qui peut aider à plonger dans la performance des prédictions d’une manière très interactive et peut également simuler des prédictions en entrant des données d’entrée ; il y a quelques captures d’écran de l’outil.
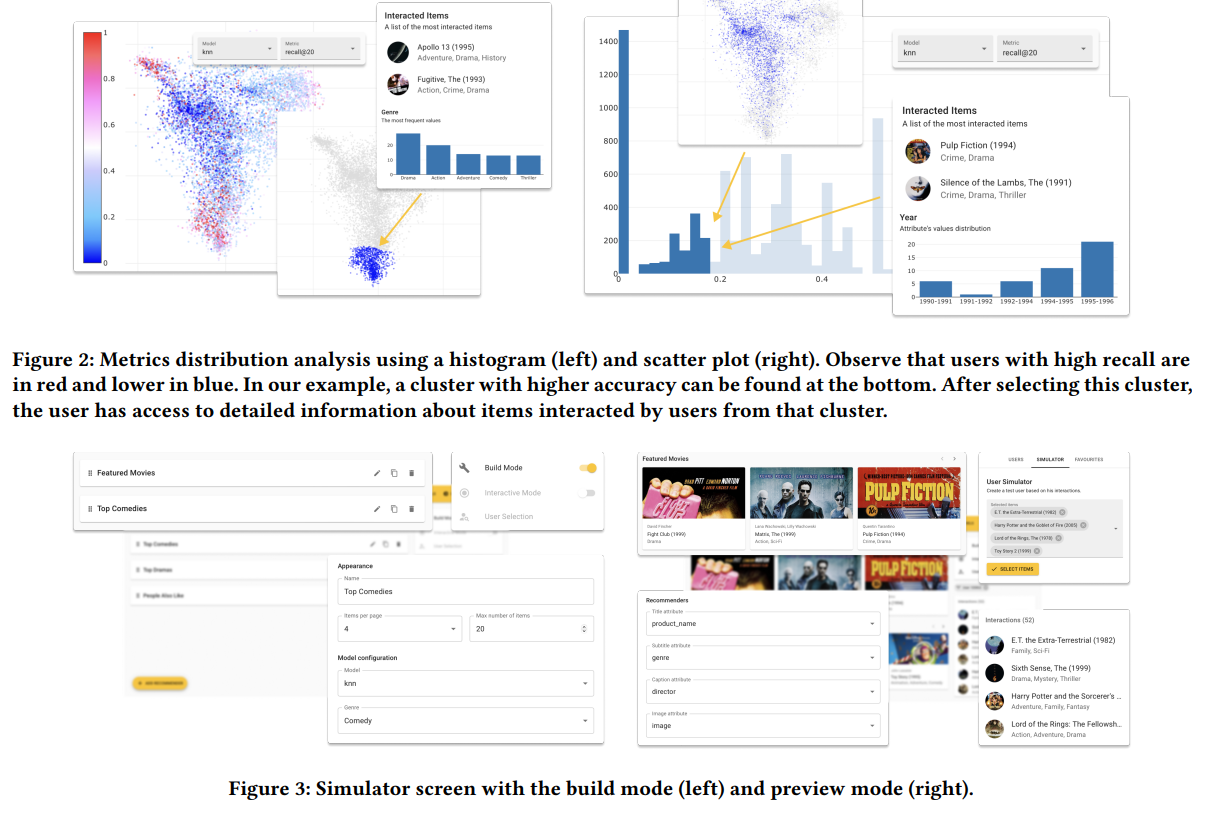
Honnêtement, pour les personnes travaillant sur des outils/pipelines de surveillance autour de recsys peut être un bon point de départ pour trouver des métriques etc.
Who do you think I am? Interactive User Modelling with Item Metadata (University of Antwerp)
Pour celui-ci, l’outil est plus pour étudier l’impact d’un article spécifique dans la prédiction de recommandations. Cet article est un excellent exemple d’outil interactif pour aider les propriétaires de fonctionnalités d’un système de recommandation à mieux comprendre les prédictions produites par un recsys. Il y a une démo en direct ici et une capture d’écran de l’UI.
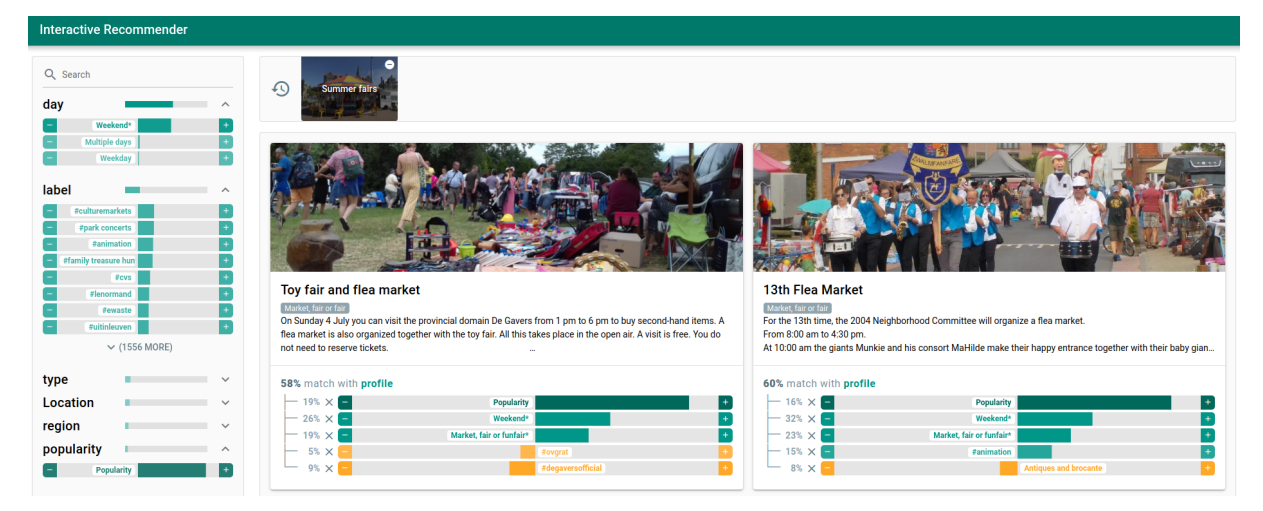
Sous le capot, il y a un modèle appelé TEASER, un système de recommandation hybride basé sur le feedback implicite (il semble basé sur un modèle appelé EDLAE avec quelques ajustements).
Mise en évidence de la tech et du framework: Une sélection rapide d’articles liés à la tech et aux frameworks pour construire un système de recommandation.
TorchRec: a PyTorch domain library for recommendation systems (Meta)
Cet article est très bref dans le contenu, et je pense que c’est une réponse au package TensorFlow recommenders annoncé il y a quelques années à Recsys. Pourtant, je pense que c’est une illustration parfaite du poids de Pytorch dans la communauté en 2022. Par conséquent, je suis curieux de voir comment ce wrapper autour de PyTorch sera utilisé dans le futur.
Building and Deploying a Multi-Stage Recommender System with Merlin (NVIDIA)
Celui-ci est une excellente compilation des travaux de NVIDIA autour de leur framework Merlin pour opérer le deep learning recsys en production. C’est une compilation d’articles sur leur blog tech ; ils ont un diagramme exemplaire pour un système de recommandation à quatre étapes.
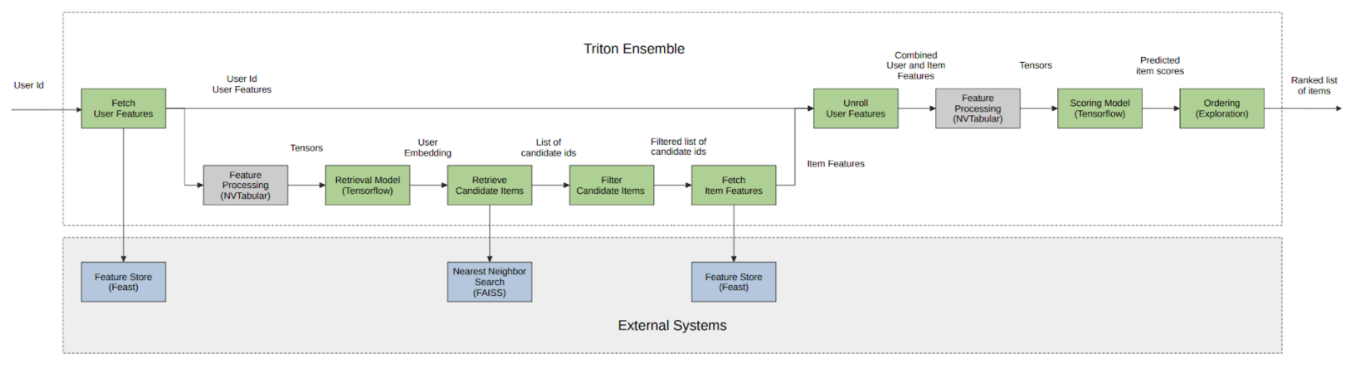
Ajuster d’autres choses que votre algorithme
Il y a plus que des algorithmes pour faire de grands systèmes de recommandation ; cette section est un exemple parfait de choses à essayer.
Effective and Efficient Training for Sequential Recommendation using Recency Sampling (Glasgow university)
Un article qui fait une excellente introduction au paysage des systèmes de recommandation utilisant des techniques d’apprentissage profond et avec une bonne comparaison de modèles, précision VS temps d’entraînement (évitez le point bleu car c’est un spoiler).
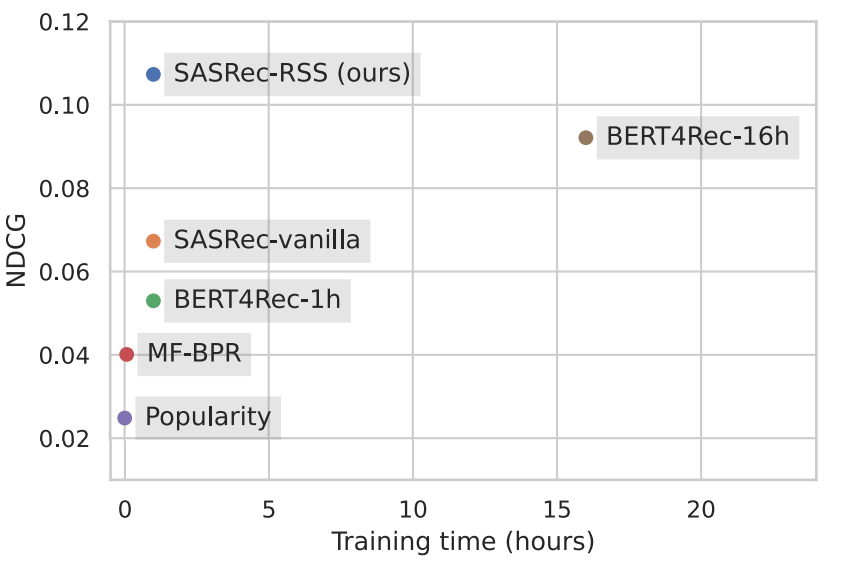
L’idée est de traiter la séquence d’articles en les pondérant en fonction de leur position dans la séquence puis d’appliquer des techniques d’apprentissage profond classiques.
L’entraînement du modèle était également limité à 1 heure, et ils ont réussi à construire un modèle qui semble plus performant dans la plupart de leurs cas.
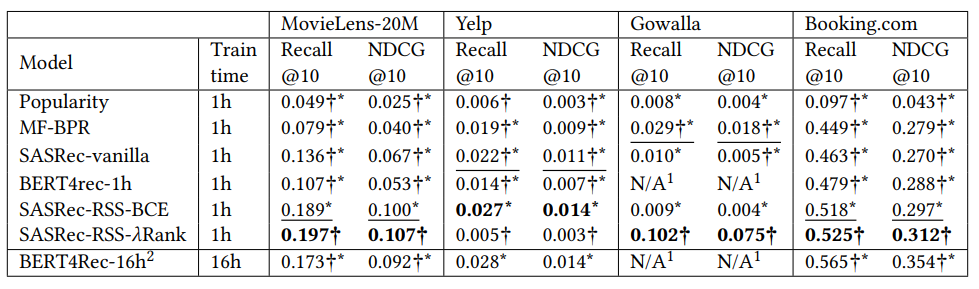
L’expérimentation sur booking n’a pas été réussie, mais la contrainte liée à l’emplacement de la réservation (pas dans le modèle) pourrait l’expliquer.
Dans l’ensemble pour moi, qui monte actuellement en niveau sur l’apprentissage profond. Cependant, j’ai trouvé cet article une excellente source pour commencer l’idée de pondérer l’article avec une fonction simple appelée importance de la fonctionnalité de récence est assez intelligente.

De mon point de vue, je pense aussi que peut-être pondérer par popularité ou âge de l’article est intéressant aussi (parce que le système de recommandation d’articles les plus populaires est toujours un bon départ).
Don’t recommend the obvious: estimate probability ratios (Amazon)
Cet article illustre le problème de la longue traîne et l’impact du biais de popularité dans un système de recommandation. De plus, cette approche offre une vision de réduction de l’impact de la popularité sur la conception d’un système de recommandation. L’équipe a testé différentes stratégies d’échantillonnage et a voulu illustrer l’impact sur les métriques. Enfin, il y a un exemple de la production pour le même modèle, mais avec différentes stratégies d’échantillonnage appliquées.
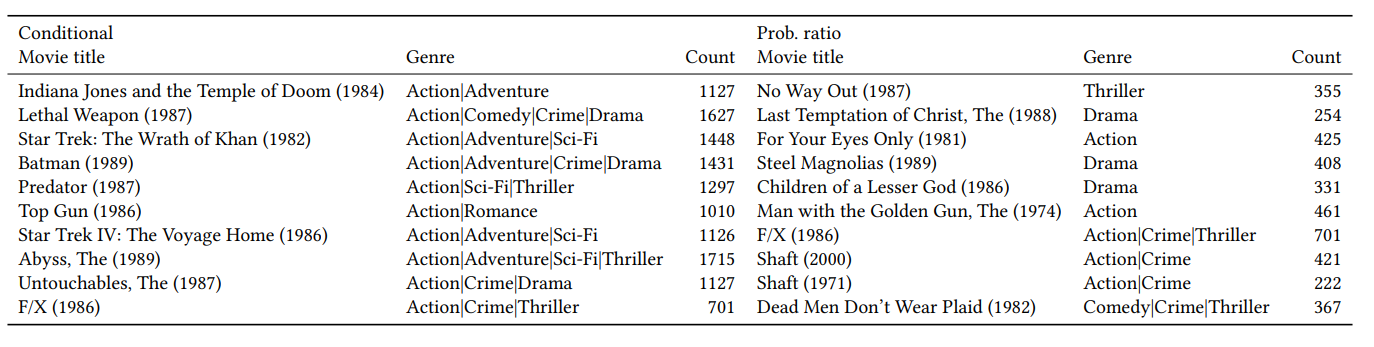
Cela peut être constructif pour servir des utilisateurs de niche avec des goûts spécifiques. Pourtant, les auteurs de l’article avertissent que cela peut également augmenter le risque de construire des recommandations nuisibles pour le public de masse (toujours le compromis de l’exploration VS exploitation).
Discovery Dynamics: Leveraging Repeated Exposure for User and Music Characterization (Deezer)
Cet article ne se concentre pas sur les systèmes de recommandation mais illustre un phénomène très répandu dans les plateformes de streaming musical : l’effet de simple exposition. La définition formelle de cet effet est L’intérêt des utilisateurs a tendance à augmenter avec les premières répétitions et atteint un pic, après quoi l’intérêt diminuera avec les expositions ultérieures, résultant en une forme de U inversé).
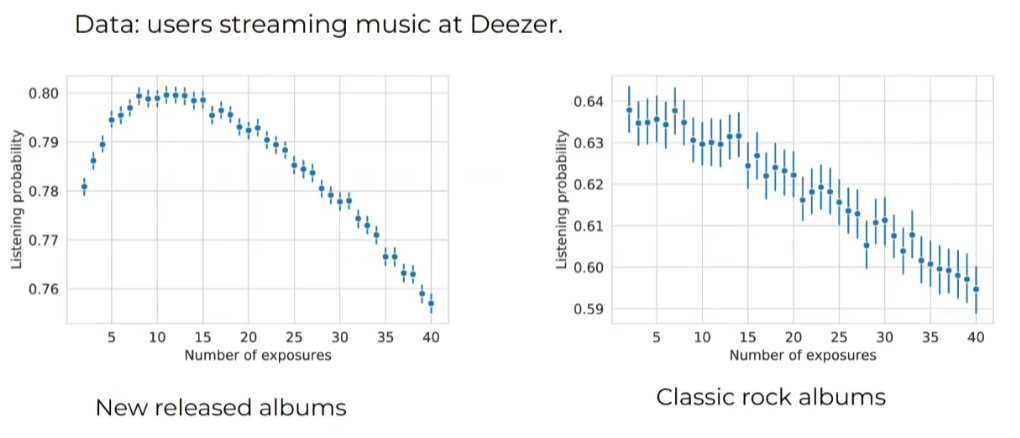
C’est particulier aux services de streaming musical, mais je l’ai trouvé intéressant à souligner car mesurer cette exposition est essentiel dans la conception des systèmes de recommandation.
Towards the Evaluation of Recommender Systems with Impressions (Politecnico di Milano)
Cela peut être lié au précédent d’une certaine manière. Pourtant, j’aime voir des articles liés à l’exploitation de l’impression/interaction d’articles comme entrée de systèmes de recommandation, avec une liste de modèles qui pourrait être un bon point de départ.
Les cool misfits
Parfois vous ne pouvez pas mettre les choses dans des boîtes, et ces articles font partie de ce mantra.
Optimizing product recommendations for millions of merchants (Shopify)
Cette présentation/article montre leur approche pour construire des systèmes de recommandation en tant que service qui peuvent aider des millions de marchands sur leur plateforme.
Les approches utilisées derrière sont simples sur le papier (fréquemment achetés ensemble, articles similaires, articles de collections similaires). Leurs tests à la boutique semblent être des divisions 50/50 avec des tests AA (une illustration parfaite de leur approche dans le tableau suivant).
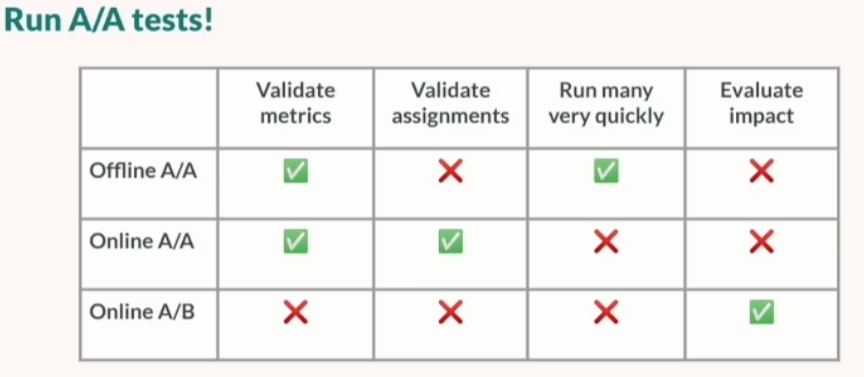
Leur cas d’usage est particulier, mais ils ont des stratégies astucieuses à tester sur différents segments et à jouer sur différents modèles sur les tuiles d’une boutique (Multi-arm bandit est votre ami)
Et je viens juste de réaliser que c’est Kim Falk du livre practical recommender systems chez manning.
Flow Moods: Recommending Music by Moods on Deezer (Deezer)
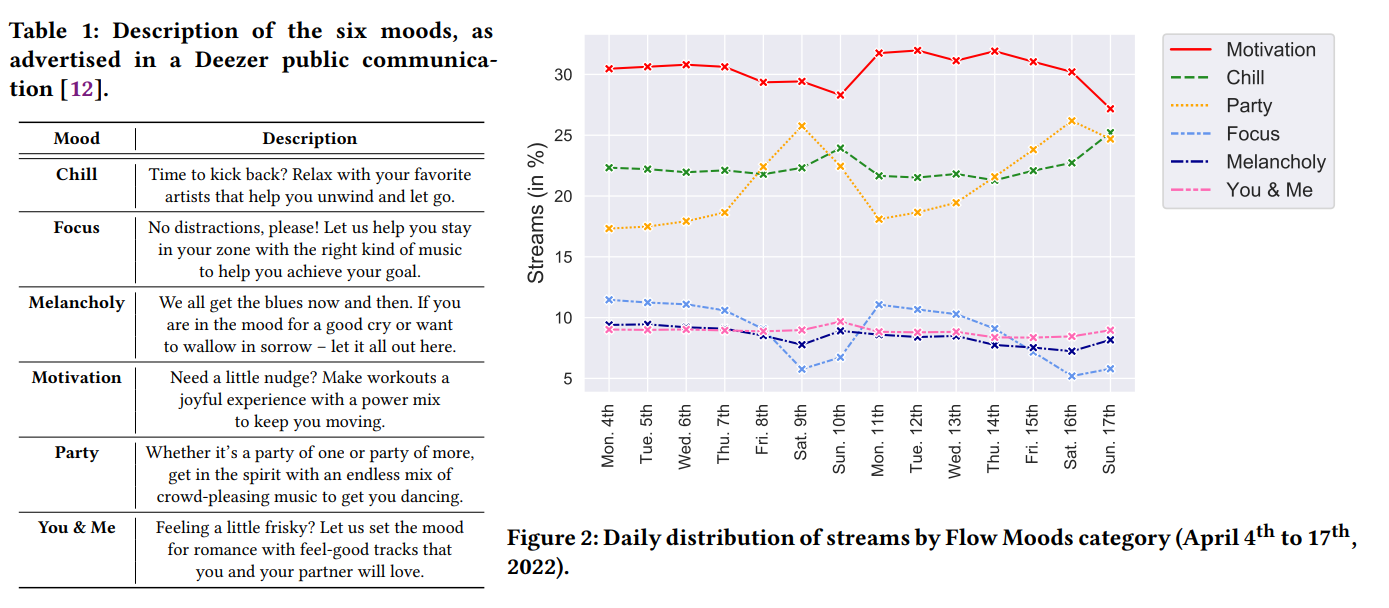
Habituellement, Deezer vient à Recsys avec des articles super ; comme d’habitude, celui-ci est cool (je pense mon préféré). Tout d’abord, ils expliquent le processus derrière leur fonctionnalité Flow : construire des recommandations basées sur vos données et une entrée d’humeur par l’utilisateur (6 valeurs sont possibles).
Ils semblent avoir étiqueté des chansons avec des experts musicaux avec ces humeurs et construit des classificateurs avec ces données. Le traitement de la chanson est fait avec musicnn, et ils ont construit un classificateur par humeur qui créera des données pour la génération de playlist.
Une analyse de la consommation de chansons basée sur le jour de la semaine est fascinante à regarder, avec un pic de chansons de fête pendant le week-end et la concentration jouée de moins en moins pendant la semaine.
Recsys Challenge, qu’est-ce qui s’est passé?
Cette année, le défi recsys était autour de “recommandations de mode ; étant donné une séquence de vues d’articles, les données d’étiquette pour ces articles, et les données d’étiquette pour tous les articles candidats, la tâche est de prédire l’article acheté dans la session.”
Le défi était organisé avec dressipi et si vous voulez en savoir plus sur la compétition et la configuration des données, regardez leur site web ; c’est bien documenté (et il y a aussi l’article).
Il y a le top3 des soumissions de cette compétition :
#3: A Diverse Models Ensemble for Fashion Session-Based Recommendation (Nvidia)
Le roi est tombé … à la troisième place :), une approche fantastique autour du mélange de différents types de modèles et d’architecture dans un système de recommandation à 3 étapes (cf image)
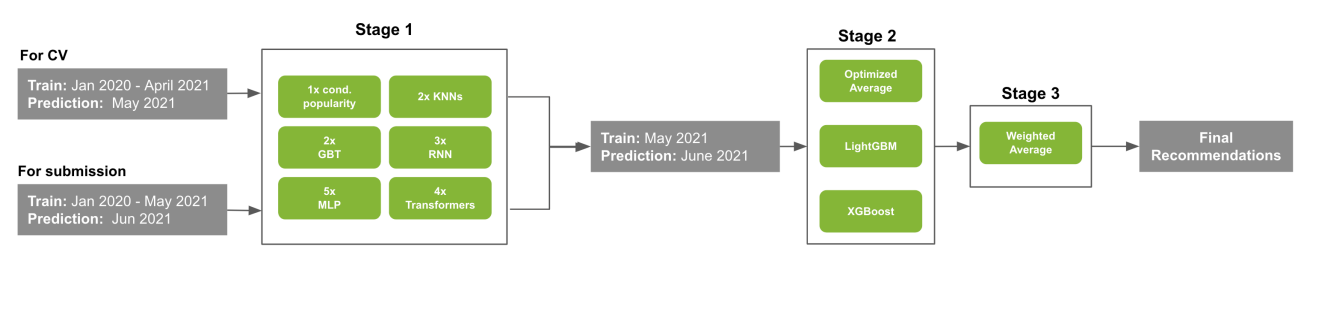
Une façon formidable de construire des recommandations si vous voulez mon avis, et cela pourrait s’adapter dans des recommandations par lots (parce que dans un contexte en direct, cela pourrait être délicat à utiliser en termes de latence et d’échelle).
#2: Session-based Recommendation with Transformers (layer6)
Le transformateur voit la voie à suivre ; cette équipe a essayé plusieurs types d’architecture et de modèles.
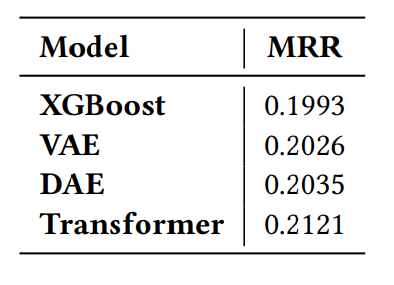
Malheureusement, au moment de la rédaction de ce récapitulatif, l’article n’est pas disponible gratuitement comme l’autre, donc cela va être une supposition qu’il n’y a pas de transformateur sur celui-ci, plus de réseau neuronal graphique et d’arbre.
Récapitulatif
Malheureusement, je n’ai pas participé aux ateliers en direct comme l’année dernière, mais globalement il y a les principaux points à retenir de cette édition de la conférence recsys.

Ils semblent avoir fait leur place partout (sauf à la première place du classement du défi 😜), c’est une excellente approche ; j’ai récemment trouvé un excellent point fort d’Andrew Trask sur l’un des éléments derrière Transformer appelé attention, donc je pense que cela pourrait être un excellent départ pour en apprendre plus sur la théorie.
Mais dans l’ensemble, si je voulais choisir mon top 3 d’articles de cette conférence, je mettrais en évidence :
- Flow mood de Deezer
- Moteur de recherche basé sur les préférences visuelles de Shutterstock
- Échantillonnage de récence des recommandations de séquence de l’université de Glasgow
La conférence, comme d’habitude, était incroyable et a donné d’excellentes idées pour de futurs projets.
Références
- Learning Users’ Preferred Visual Styles in an Image Marketplace — dl.acm.org
- Eugene yan — System Design for Discovery — eugeneyan.com
- Augmenting Netflix Search with In-Session Adapted Recommendations — dl.acm.org
- Challenges in Search on Streaming Services: Netflix Case Study — arXiv
- Conception du système de recherche chez Netflix — dl.acm.org
- A Systematic Review and Replicability Study of BERT4Rec for Sequential Recommendation — dl.acm.org
- Dépôt GitHub bert4rec_repro — GitHub
- Rethinking Personalized Ranking at Pinterest: An End-to-End Approach — dl.acm.org
- Blog tech Pinterest Engineering — Medium / Towards Data Science
- PinSage : un nouveau réseau de neurones convolutif graphique — Medium / Towards Data Science
- Inférence ML accélérée par GPU chez Pinterest — Medium / Towards Data Science
- BRUCE - Bundle Recommendation Using Contextualized item Embeddings — dl.acm.org
- A Lightweight Transformer for Next-Item Product Recommendation — dl.acm.org
- Techblog Wayfair — aboutwayfair.com
- Personalizing Benefits Allocation Without Spending Money — dl.acm.org
- Booking.ai personnalisation en pratique — booking.ai
- Dépôt GitHub upliftML — GitHub
- RepSys: Framework for Interactive Evaluation of Recommender Systems — dl.acm.org
- Who do you think I am? Interactive User Modelling with Item Metadata — dl.acm.org
- Article EDLAE — proceedings.neurips.cc
- TorchRec: a PyTorch domain library for recommendation systems — dl.acm.org
- Building and Deploying a Multi-Stage Recommender System with Merlin — dl.acm.org
- Blog tech NVIDIA Merlin — Medium / Towards Data Science
- Effective and Efficient Training for Sequential Recommendation using Recency Sampling — dl.acm.org
- Don’t recommend the obvious: estimate probability ratios — dl.acm.org
- Discovery Dynamics: Leveraging Repeated Exposure for User and Music Characterization — dl.acm.org
- Towards the Evaluation of Recommender Systems with Impressions — dl.acm.org
- Liste de modèles pour recsys avec impressions — arXiv
- Optimizing product recommendations for millions of merchants — dl.acm.org
- Practical Recommender Systems chez Manning — manning.com
- Flow Moods: Recommending Music by Moods on Deezer — dl.acm.org
- Dépôt GitHub musicnn — GitHub
- dressipi — dressipi.com
- Site web RecSys Challenge 2022 — recsyschallenge.com
- Article RecSys Challenge 2022 — dl.acm.org
- #3: A Diverse Models Ensemble for Fashion Session-Based Recommendation — dl.acm.org
- #2: Session-based Recommendation with Transformers — dl.acm.org
- #1: Industrial Solution in Fashion-domain Recommendation by an Efficient Pipeline using GNN and Lightgbm — dl.acm.org
- Attention and Augmented Recurrent Neural Networks — distill.pub