
Retour de la conférence Apply(ops) 23
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
À la mi-novembre, la conférence Apply(ops) 23, organisée par Tecton et Demetrios Brinkmann, a eu lieu. Habituellement, j’écris un résumé d’une page pour mes coéquipiers pour partager les apprentissages et les bonnes références, que je poste également sur LinkedIn. Cependant, cette fois-ci, j’ai décidé d’écrire un article car j’ai trouvé les diapositives et les discours pleins de bons conseils.
Comme l’événement était hébergé par Tecton, il y a eu des démos en direct de leurs produits et des retours de clients. Je n’inclurai pas ceux-ci dans mon récapitulatif (bien que le contenu soit précieux) car je veux garder mon résumé plus axé sur l’apprentissage que sur les démonstrations de produits.
Parcours de la plateforme AI chez Uber (Uber)
Intervenant : Min Cai, ingénieur distingué de l’ingénierie de plateforme, d’après son profil LinkedIn, semble être le chef technique derrière Michelangelo (la plateforme ML interne) et Horovod (un framework d’apprentissage profond distribué, construit sur TensorFlow, PyTorch, etc.)*
La présentation s’est principalement concentrée sur l’origine et la direction de la plateforme ML interne, Michelangelo. Cette plateforme semble avoir inspiré de nombreuses entreprises, y compris Ubisoft (je sais j’y étais), à construire leurs propres stacks ML. Ils ont commencé à travailler avec le ML en 2015 parce qu’ils avaient besoin d’un système capable de prendre des décisions complexes en temps réel (Uber compte environ 137 millions d’utilisateurs actifs mensuels dans 10 000 villes), interagissant avec des éléments du monde réel (comme les chauffeurs, les restaurants, les magasins, le trafic) et des éléments numériques. Cette citation capture leur vision du machine learning.

Ils sont plus proches d’une entreprise de type Alphabet que Netflix, mais ils voient toujours qu’une plateforme AI/ML centralisée peut accélérer l’adoption du ML.
Ils ont partagé quelques exemples de cas d’usage, tels que l’intégration des travailleurs (création d’un compte pour un chauffeur, un restaurant, etc.), la recommandation de trajets (véhicules et trajets), et la recommandation de restaurants/nourriture. Ils ont présenté quelques chiffres liés aux projets ML, notamment :
- Environ 5,3k modèles en production
- 700 cas d’usage déployés
- 10M de prédictions par seconde en pic
Dans la première section de la présentation, Min a partagé l’évolution de la plateforme en utilisant un diagramme très informatif (l’axe Y représente le nombre de cas d’usage).
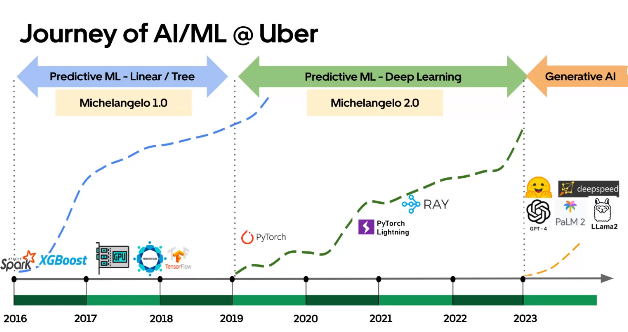
D’après la voix off et le diagramme, il semble que :
- Avant 2019, l’apprentissage profond n’était utilisé que pour les applications de voiture autonome.
- Il y a eu un changement entre deux itérations de Michelangelo, mais les deux itérations se sont chevauchées pendant environ 6 mois.
- le passage à l’apprentissage profond en 2019 vient du fait que les modèles d’arbres sont bons mais les réentraîner était difficile et non évolutif (un modèle par ville VS un modèle mondial avec l’apprentissage profond)
- Leur section Gen AI (en 2023) ne semble pas avoir été suivie par Michelangelo (ma compréhension est qu’il est encore trop tôt pour construire une nouvelle itération).
Min a également présenté plus de détails sur le flux de travail sur Michelangelo, en se concentrant sur les concepts de Canvas et Studio. Voici une illustration montrant ce qu’est un canvas :
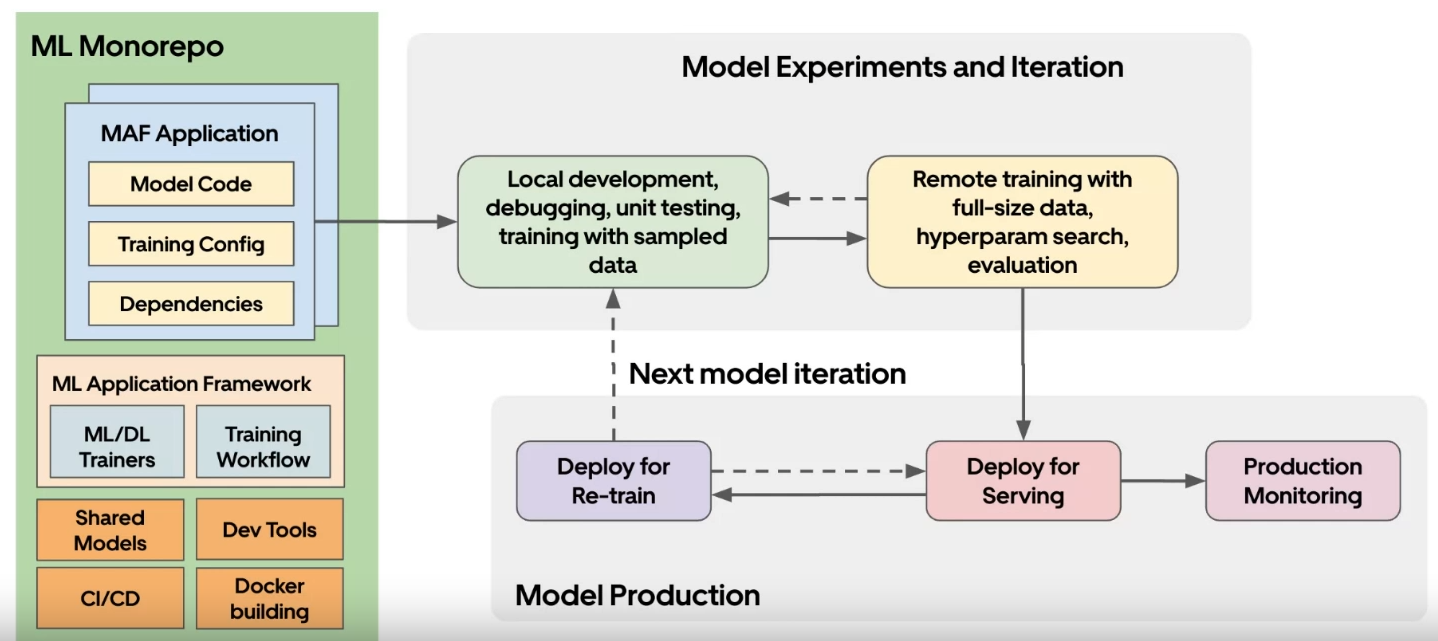
Le canvas est le framework d’une application ML. Il connecte les différentes parties de la plateforme et organise le code qui s’exécutera. Cela inclut de nombreux fichiers de configuration et SDK pour utiliser la plateforme. Le Studio offre une approche UI/UX plus intégrée pour faire du ML sur Michelangelo. Il connecte divers composants UI et le canvas. Voici un aperçu du flux du Studio avec un regard sur l’UI, qui semble très simple (pas sûr de sa flexibilité d’utilisation)
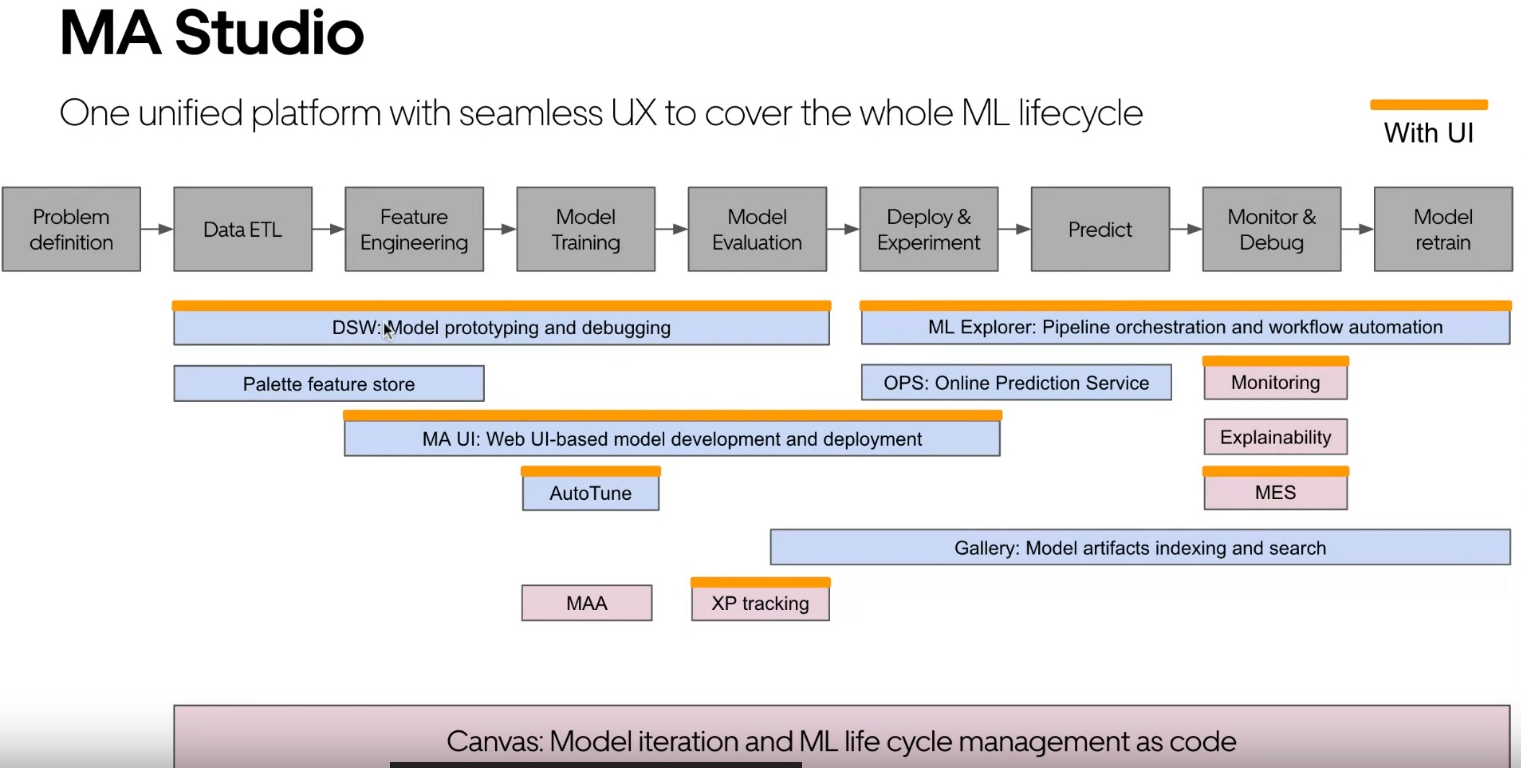
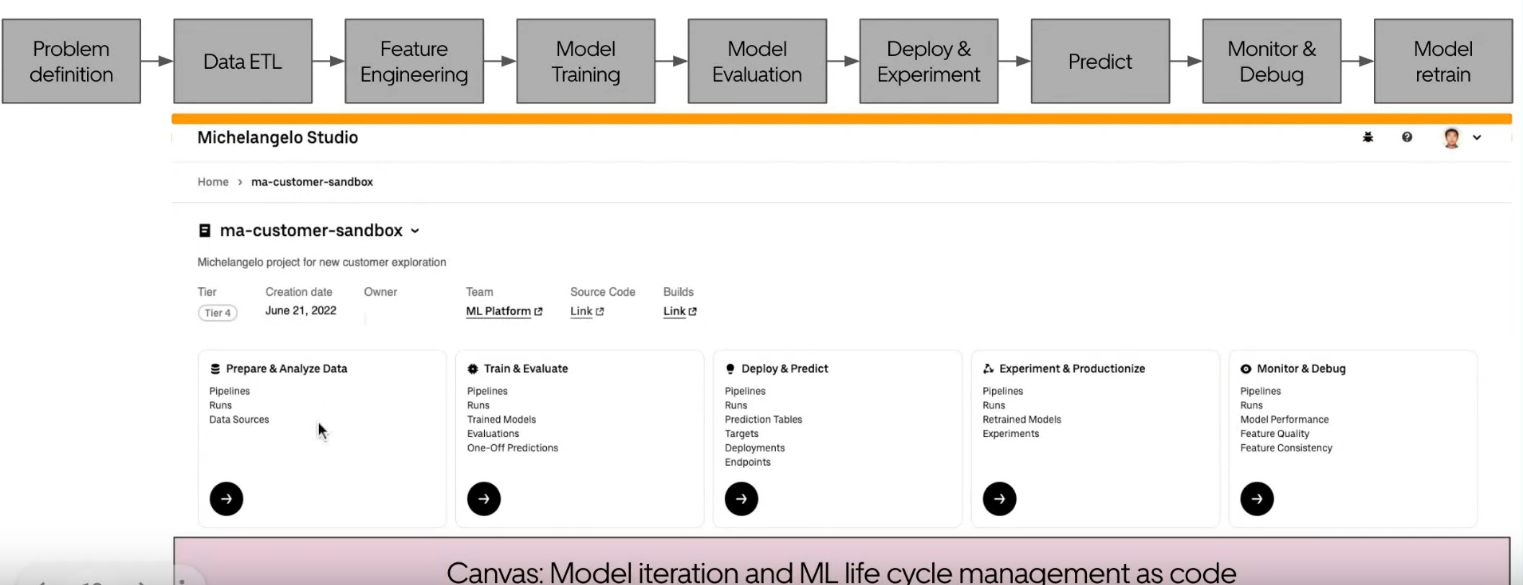
Enfin, ils ont parlé de leur vision pour GenAI. Ce n’était pas très clair (comme c’est le cas dans toute l’entreprise), mais Min a souligné quelques points intéressants dans leurs diapositives :
- Utiliser des modèles open-source comme LLama2 ou Falcon.
- Utiliser également des modèles privés comme GPT-4 et Palm-2.
- Ils ont commencé à intégrer GenAI dans leur studio, y compris le concept d’ingénierie de prompt.
- L’idée d’un graphe de connaissances semble importante dans leur vision.
- Il y a une carte des emplois d’Uber (excluant les travailleurs) et les sources de données impactées par GenAI.
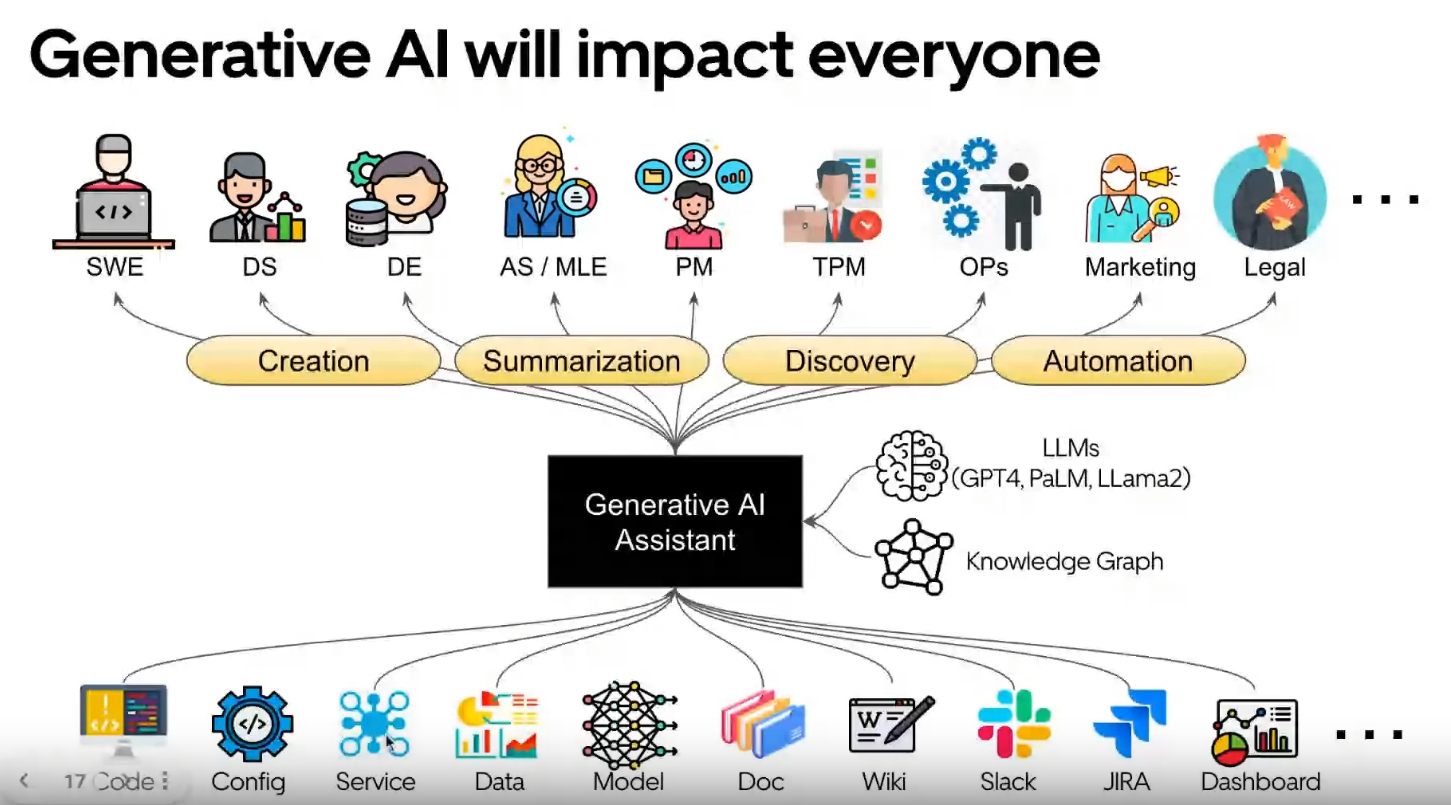
Si vous voulez en savoir plus sur la vision d’Uber, Min a fait une excellente présentation à la conférence Scale 2023 (où la plupart du contenu de cette présentation est plus du contenu supplémentaire).
ML dans un environnement multi cloud (Lidl)
Intervenant : Dr. Rebecca Taylor, qui est actuellement la chef technique pour la personnalisation chez Lidl, discutera de la façon de gérer le machine learning dans un environnement multi-cloud.
Un environnement multi-cloud, c’est quand vous utilisez plus d’un service cloud. C’est différent d’un cloud hybride, qui combine une infrastructure sur site avec un service cloud. Le cloud hybride était populaire il y a environ 10 ans.
L’approche multi-cloud semble gagner en popularité :
- Rebecca mentionne que 65% des entreprises sont dans cette situation, basé sur cette source de 2014.
- J’ai fait quelques recherches rapides pour voir si cette tendance a changé et j’ai trouvé une enquête 2023 de Hashicorp. Elle montre que 76% des répondants utilisent une configuration multi-cloud.
Le besoin d’une approche multi-cloud peut être dû à des raisons historiques et techniques (comme dans le déploiement ML, l’accès à des services spécifiques). Il y a des avantages et des inconvénients à passer au multi-cloud, que j’ai résumés dans ce tableau.

Avec cet état d’esprit multi-cloud, il est important d’avoir de bonnes couches d’abstraction, et d’avoir certaines considérations à l’esprit lors du passage d’un chemin à un autre :
- Avoir une bonne compréhension des contraintes business et ops (latences critiques)
- Estimer les occurrences de certaines actions (entraînement du modèle < mises à jour des caractéristiques < inférence du modèle)
Rebecca a également pris le temps de lister différentes technologies qui peuvent être intéressantes dans une configuration multi cloud :
- terraform et opentofu pour la gestion des ressources
- kubernetes et kubeflow
- prometheus et Grafana pour la surveillance
- mlflow pour la gestion des modèles et zen-ml
- Feast comme feature store (elle a invité à ne pas en construire un mais à en acheter un)
- Kafka pour la file de messages open source
Elle a conclu sa présentation avec une technologie d’entreprise et a souligné que databricks fonctionne bien dans une configuration multi cloud, Tecton comme un feature store tout-en-un (qui fonctionne avec databricks, SnK etc) et Zenml cloud.
Construire une stratégie MLOps chez le plus grand fournisseur de solutions alimentaires au monde (Hello Fresh)
Intervenants :
- Benjamin Bertincourt, responsable de l’ingénierie AI et ML chez Hello Fresh
- Michael Johnson, directeur AI et ML chez Hello Fresh
Hello Fresh, un leader dans l’industrie de la livraison de nourriture/kits repas, a une forte culture de machine learning (ML) et la partage ouvertement avec le monde. Erik Wildman (ancien directeur produit chez Hello Fresh) a fait une présentation impressionnante sur leur vision du MLOps il y a quelques mois.
En revenant à la conférence, ils semblent avoir une forte culture et ont partagé quelques chiffres impressionnants sur leurs réalisations ML :
- Ils ont une plateforme MLOps (il y a une petite note de bas de page qui me rappelle quelque chose).
- Plus de 2500 modèles entraînés par semaine.
- 1506 caractéristiques pour 73 vues de caractéristiques.
- Plus de 65 data scientists/ingénieurs ML soutenus.
Notes : Leur plateforme pour MLOps est construite sur Databricks (avec AWS) et Tecton pour le feature store. Elle supporte principalement les prédictions hors ligne (en mode batch) mais ils développent également des cas d’usage d’inférence en direct avec SageMaker et des endpoints Databricks (abstraits derrière une couche pour l’utilisateur, car ils ne devraient pas s’en soucier).
La présentation a souligné l’importance de construire une plateforme MLOps dans une entreprise. Elle incluait une illustration claire du passage en production.
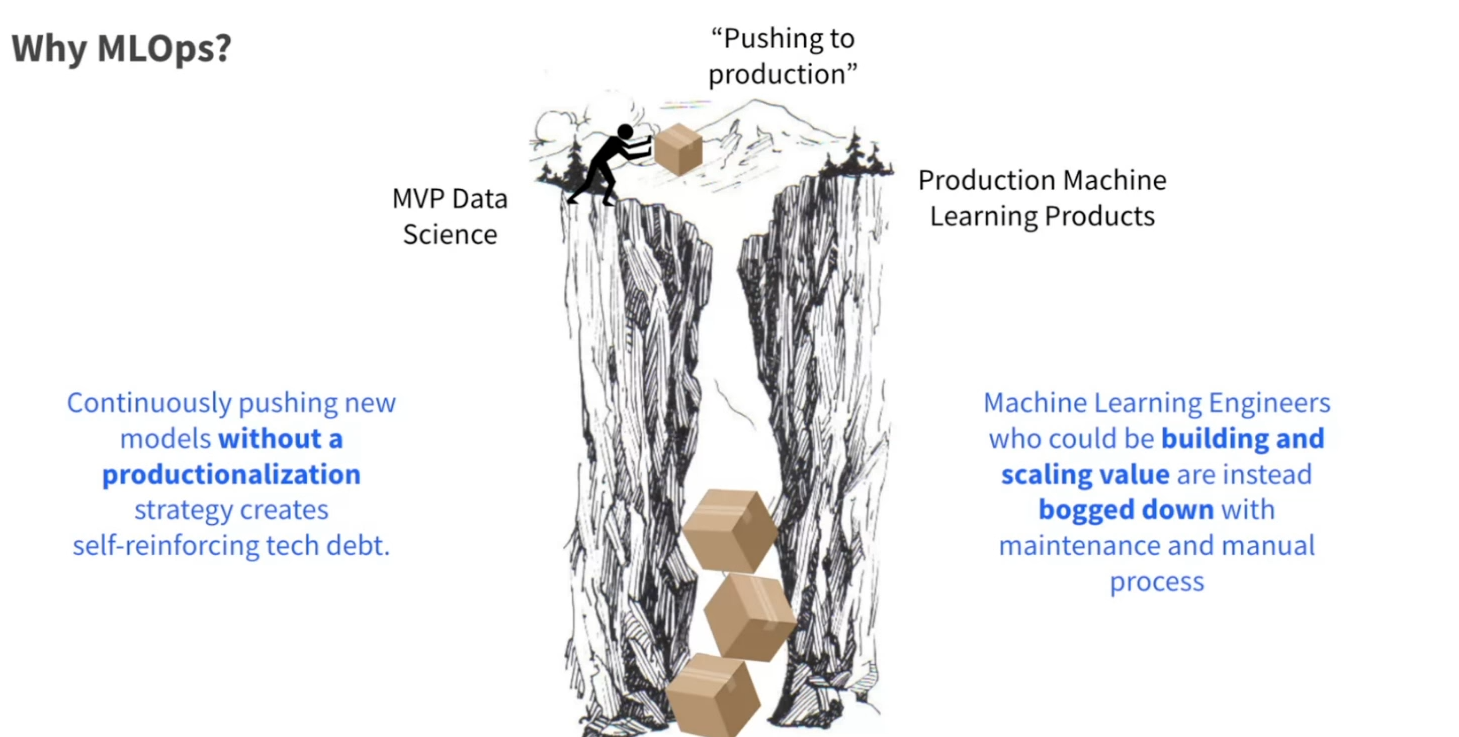
Les raisons d’adopter MLOps et une solution centralisée sont :
- Accélérer le temps de mise en production.
- Augmenter la réutilisabilité.
- Réduire les coûts de maintenance.
- Réduire le besoin de compétences approfondies en infrastructure.
- Se concentrer sur l’ingénierie des caractéristiques et la sélection de modèles dans les projets ML d’un point de vue DS/MLE.
- Automatiser 80% des processus standard, tout en rendant les 20% restants faciles à gérer.
Ils ont partagé des insights sur leur approche dans le choix d’éléments pour leur stack.

Ils ont également décrit différentes couches dans leur stack, répondant à divers rôles :
- Data Scientist : Offre une API de haut niveau, se concentrant sur la vitesse et l’utilisabilité pour une expérimentation facile.
- ML Engineer : Fournit une API de bas niveau, permettant un réglage fin de multiples paramètres pour l’optimisation du modèle.
- MLOps Engineer : Implique une couche d’intégration, créant des abstractions pour aligner les services et les technologies avec les exigences du domaine.
Certains concepts intéressants ont été définis dans la présentation :
- Makerspace VS Factory :
- Makerspace : Développement flexible et rapide nécessitant une expertise pour maintenir.
- Factory : Déploiement évolutif et rapide, facile à maintenir mais moins flexible.
- Front et Back Office :
- Front Office : Livre rapidement avec ce qui est sur l’étagère, facile à utiliser.
- Back Office : Plus flexible avec un ensemble général d’outils disponibles pour soutenir le front office.
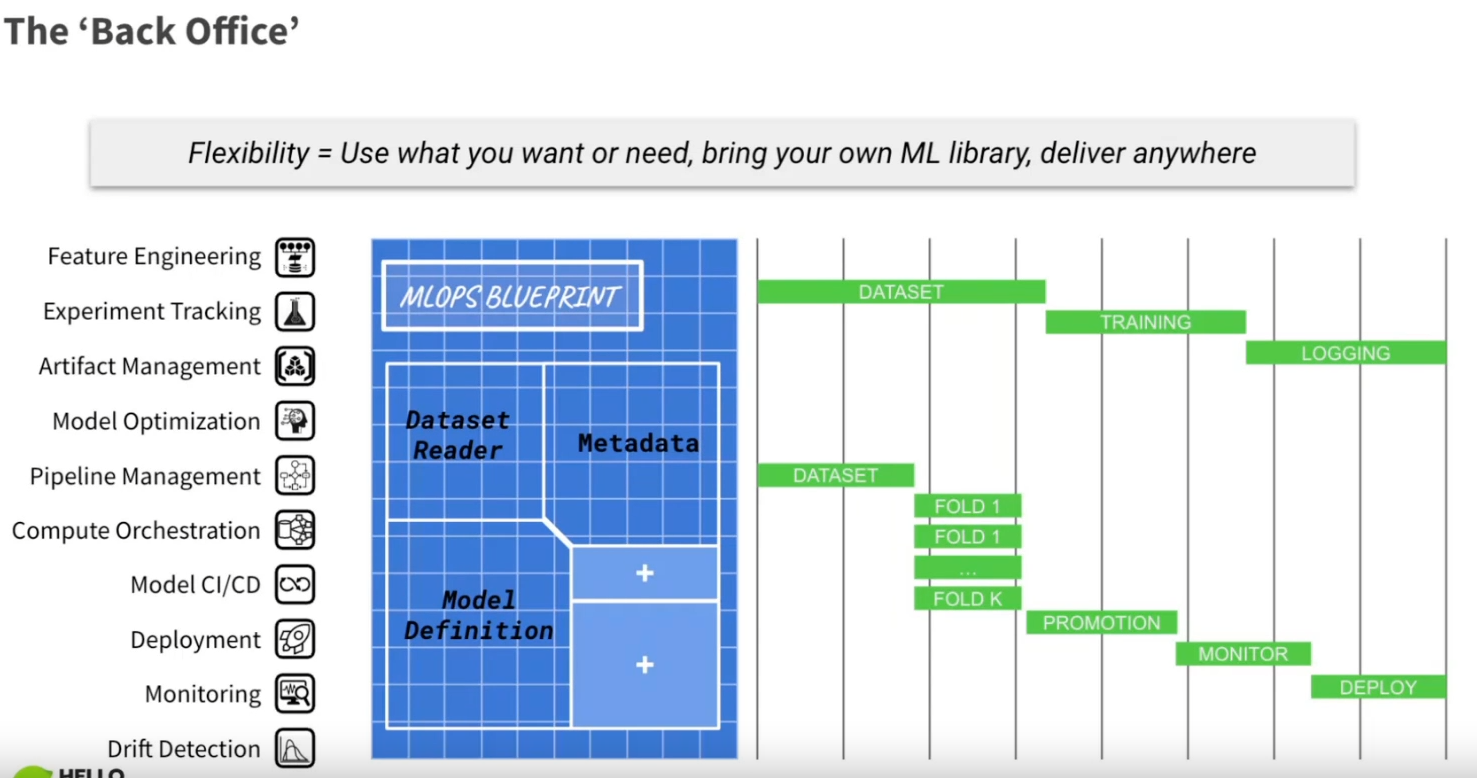
Notes : La définition du blueprint MLOps pour un modèle, composé d’un lecteur d’ensemble de données, de quelques métadonnées et d’une définition de modèle, n’est pas nouvelle mais bonne à voir représentée comme cela (et il y a de la place pour ajouter de nouveaux composants).
Enfin, ils ont partagé quelques points clés à retenir :
- Se concentrer sur la qualité des données.
- Définir une stratégie claire et des principes directeurs.
- La partie technologique n’est pas l’aspect le plus difficile.
- Faire des hackathons (sur des sujets réels) avec des data scientists/MLE pour construire votre plateforme (pour collecter les vrais besoins)
LLMs, temps réel et autres tendances dans l’espace ML de production (Databricks/Tecton)
Disclaimer : Ceci est une discussion entre Ali Ghodsi cofondateur et CEO de Databricks et Mike Del Balso cofondateur et CEO de Tecton, donc ils vendent des solutions qui peuvent être utilisées pour opérer des projets ML.
J’ai collecté quelques points intéressants de cette discussion que je pense valent la peine d’être mentionnés :
- Les plateformes de données seront perturbées par l’IA : elles doivent être infusées avec le machine learning, conduisant possiblement à une réécriture complète avec le ML à l’esprit.
- Les LLMs (Large Language Models) causent des perturbations UI/UX significatives : Au lieu de cliquer sur un bouton spécifique pour faire un travail, pourquoi ne pouvons-nous pas simplement demander ce que nous voulons ?
- L’IA prendra le contrôle de nombreux domaines : Il y a eu une discussion notable sur l’assistance IA et sa similitude avec un copilote d’avion :
- Pourquoi y a-t-il encore un pilote dans un avion ? Un système peut être excellent pour maintenir un certain cap, mais la supervision humaine et les compétences sont nécessaires pour certaines opérations (et juste par sécurité).
- Il y a des limites aux LLMs : Bien qu’ils soient bons pour certaines tâches, pour les tâches ML classiques comme les modèles de régression, d’autres méthodes sont toujours meilleures et plus efficaces.
- Construire vs Acheter : La citation clé de la présentation était, “Si vous voulez le construire vous-même, vous devez le vendre aux clients.”
- La tendance des configurations de plateforme ML en interne s’estompera probablement.
- Les entreprises utilisant des outils open source pourraient s’éloigner de ce modèle à l’avenir en raison des coûts élevés (beaucoup de contributeurs sont des employés), mais c’est toujours un bon moyen de recruter des employés potentiels.
- Il y a eu un point intéressant sur les innovations majeures ne venant souvent pas des principales entreprises technologiques de l’époque, comme la transition d’IBM (ordinateurs) → Microsoft (OS) → Google (moteur de recherche) → OpenAI (LLMs) → ?
- Il est notable que l’architecture transformer derrière le GPT d’OpenAI a été originellement développée par Google mais est restée largement inexploitée.
- Conseils pour quelqu’un qui commence sa carrière :
- Utiliser l’IA générative et essayer de trouver des domaines où elle pourrait perturber votre travail (parce qu’elle le fera probablement).
- Se concentrer sur la création de logiciels intelligents.
Cette discussion était super intéressante mais gardez le disclaimer du début de la section.
Évolution du système de classement des annonces chez Pinterest (Pinterest)
Intervenants : Aayush Mudgal, Senior Machine Learning Engineer chez Pinterest (également mentor de startup dans adtech et edtech)
Cette présentation s’est concentrée sur les stratégies pour développer des systèmes ML comme le système de recommandation chez Pinterest. Le ML touche de nombreux aspects de l’application, affectant des millions d’utilisateurs.

Les milliards d’Épingles posent des défis dans le contexte du système de recommandation. Aayush a présenté une chronologie de leur déploiement de système de recommandation.
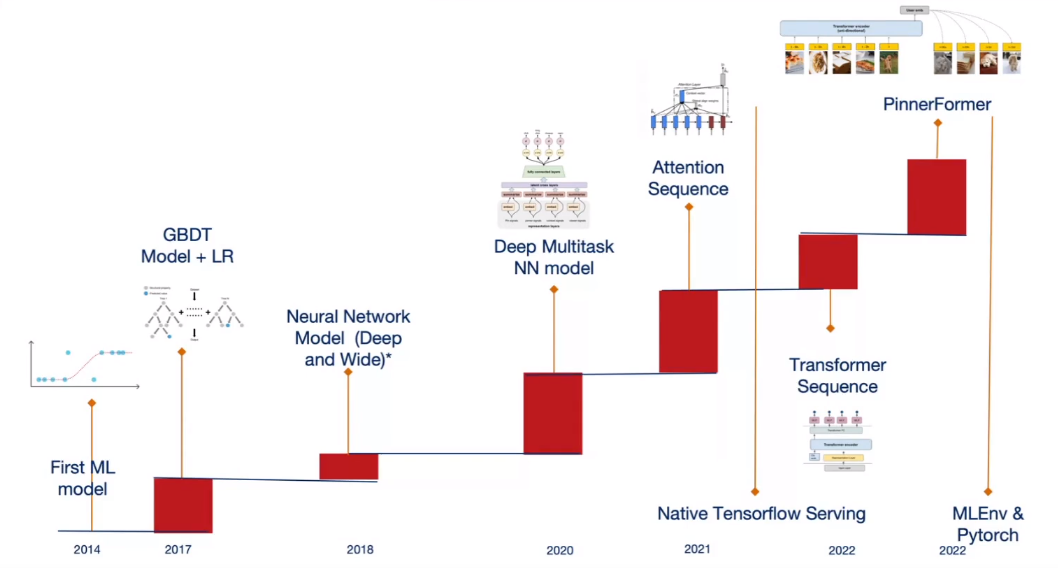
Ils ont commencé à utiliser leur premier modèle en 2014 (quatre ans après la sortie de Pinterest), suivi en 2017 par leurs premiers arbres boostés et régression logistique. Ces modèles devaient être convertis en C++ pour le déploiement.
Après 2017, ils ont exploré l’utilisation de l’apprentissage profond pour résoudre le problème que les modèles d’arbres boostés et de régression logistique sont difficiles à entraîner (car ils ne supportent pas l’entraînement incrémental). Ils ont décidé de passer à l’apprentissage profond mais ont dû travailler extensivement sur leur stack pour gérer ces modèles.
En 2020, ils ont déployé leur premier modèle multi-tâches, suivi en 2021/2022 par leur modèle basé sur l’attention/transformer construit sur Tensorflow. En 2022, ils ont publié Pinnerformer (un transformer + modèle multitâche, prédisant les interactions des utilisateurs avec les Épingles), et ont également introduit un nouvel environnement basé sur Pytorch (appelé Mlenv).
Il a également souligné quelques points de douleur pour une plateforme ML, comme la difficulté de mettre à niveau les logiciels et le matériel, et le besoin de multiples domaines d’expertise (comme TensorFlow et PyTorch) pour soutenir les utilisateurs.
Les insights de leur plateforme actuelle incluent :
-
Un feature store personnalisé avec des capacités comme les caractéristiques partagées, le backfilling, la couverture, les alertes et une UI pour suivre l’utilisation des caractéristiques.
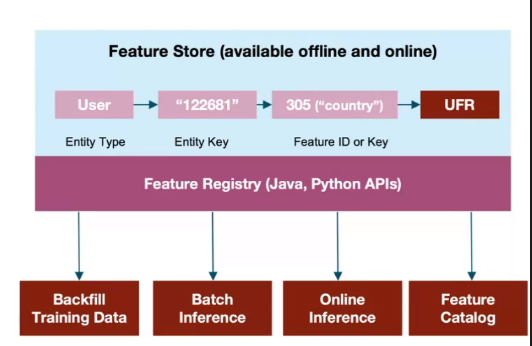
- Utilisation de mlflow pour le déploiement de modèles (registre de modèles + serveur de modèles scorpion).
- Un framework ML unifié basé sur PyTorch appelé MLenv pour simplifier les opérations de modèles, comportant des blocs de construction, une intégration MLOps standardisée, et CI/CD + Image Docker en tant que service. Ce framework est utilisé dans 95% des travaux d’entraînement.
- Flux de travail ML templatisés : Ils ont créé un système appelé EZflow qui permet de mettre à jour un pipeline en modifiant simplement un fichier de configuration (construit sur Airflow).
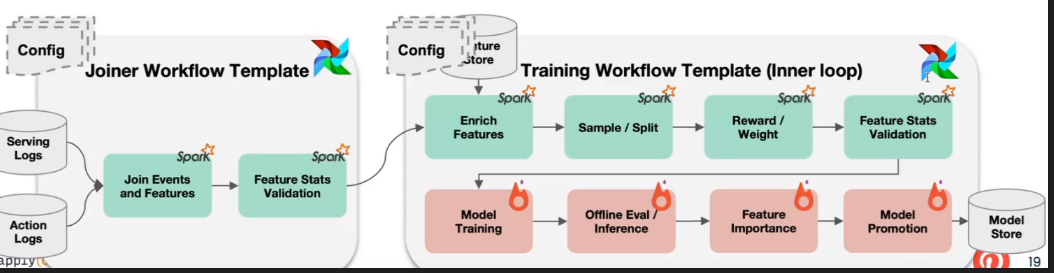
Les statistiques autour de leur plateforme sont impressionnantes :
- 100s de PBs de données d’entraînement.
- ~1500 exécutions de flux de travail par jour.
- ~3000 travaux d’entraînement par jour.
Il a également partagé quelques défis chez Pinterest (qui peuvent ralentir le déploiement ML) :
- Les changements rapides dans le ML peuvent rapidement rendre les modèles obsolètes.
- Le besoin de connaître et maintenir de nombreux langages et frameworks.
- Les revues de code et les réunions.
- Devise : Scaler d’abord et apprendre en dernier
- L’ingestion de données pour le modèle, similaire à la lutte de Netflix (mais Ray pourrait aider à l’accélérer).
Panel : Machine Learning de production pour Recsys : Défis et meilleures pratiques
Intervenants : *Ce panel a été modéré par Mihir Mathur de Tecton et incluait :
- Morena Bastiaansen, Data Scientist chez Get Your Guide
- Christopher Addy, Head of Machine Learning Engineering, Generative AI Lab @ eCommerce chez Pepsi Co
- Ian Schweer, Staff Software + Machine Learning Engineer chez Riot Games
Le panel s’est concentré sur 4 sujets : la portée de leurs systèmes de recommandation, les outils utilisés, la boucle de feedback de ces systèmes et les défis dans leur exploitation.
==Portée de leurs systèmes de recommandation==
- Morena (Get Your Guide) :
- Se concentre sur l’optimisation du taux de conversion et des réservations par client.
- Service en temps réel des prédictions (comportement en session).
- Chris (Pepsi Co) :
- Se concentre sur les revenus, car les gains potentiels dans cette métrique justifient le passage à un nouveau modèle en production.
- Service en direct de leur modèle.
- Ian (Riot) :
- Se concentre sur l’amélioration de l’expérience globale du jeu (plus de temps de jeu) et sur la bonne réception des fonctionnalités du jeu par les joueurs (analyse des sentiments sur les forums).
- Déploie leur modèle (avec environ 100 caractéristiques) dans le build du jeu
==Outils de Machine Learning==
- Morena (Get Your Guide) :
- Utilisation de Tecton Feature Store et Databricks : le feature store filtre les recommandations précédemment vues et stocke les embeddings des descriptions de produits (produites par BERT, réduites avec PCA).
- Spark pour le traitement des données et LGBM pour le modèle.
- MLflow pour le stockage et le versioning des modèles.
- Airflow pour planifier les travaux.
- Construit leur propre framework d’expérimentation.
- BentoML pour le service des modèles.
- Chris (Pepsi Co) :
- Kubeflow pour entraîner leur modèle (hebdomadaire, pas de vrai problème de démarrage à froid).
- API simple pour servir dans l’univers PepsiCo.
- Prévoit d’utiliser des embeddings visuels.
- Ian (Riot) :
- Utilise beaucoup Spark.
- Utilise Databricks.
- Nécessite la conversion du modèle en C++.
👆 Si vous êtes curieux d’en savoir plus sur le stack technique de Riot et les modèles qu’ils utilisent (qui ne sont pas typiques dans le paysage MLops), Ian a fait une excellente présentation au Data Council il y a quelques mois. 👇
==Boucle de feedback et défis==
- Morena (Get Your Guide) :
- Faire des tests A/B est essentiel pour évaluer le modèle créé.
- Avoir une faible latence est important pour le service en direct.
- Chris (Pepsi Co) :
- La création du modèle est la partie la plus facile.
- Gérer la politique interne pour opérer le modèle est la partie la plus difficile (vous devez apporter les plus gros chiffres).
- Être proche des utilisateurs.
- Ian (Riot) :
- Limiter la mémoire du modèle dans le jeu (donc vous ne pouvez pas charger tous les arbres d’une forêt aléatoire, par exemple).
- Construire la prédiction du modèle au niveau de l’article (et non d’un joueur) comme pour la recommandation de gameplay de champion
- Ne pas casser le jeu (comme le modèle est intégré, des problèmes pourraient survenir, et les corrections sont plus difficiles).
Conclusion
Cette conférence était pleine de connaissances, et je voulais vraiment me concentrer sur les apprentissages essentiels avec quelques ressources connexes. Ce qui était le plus impressionnant était les statistiques sur l’utilisation de la plateforme ML dans les entreprises. J’ai résumé cela dans ce tableau (avec quelques extrapolations) :
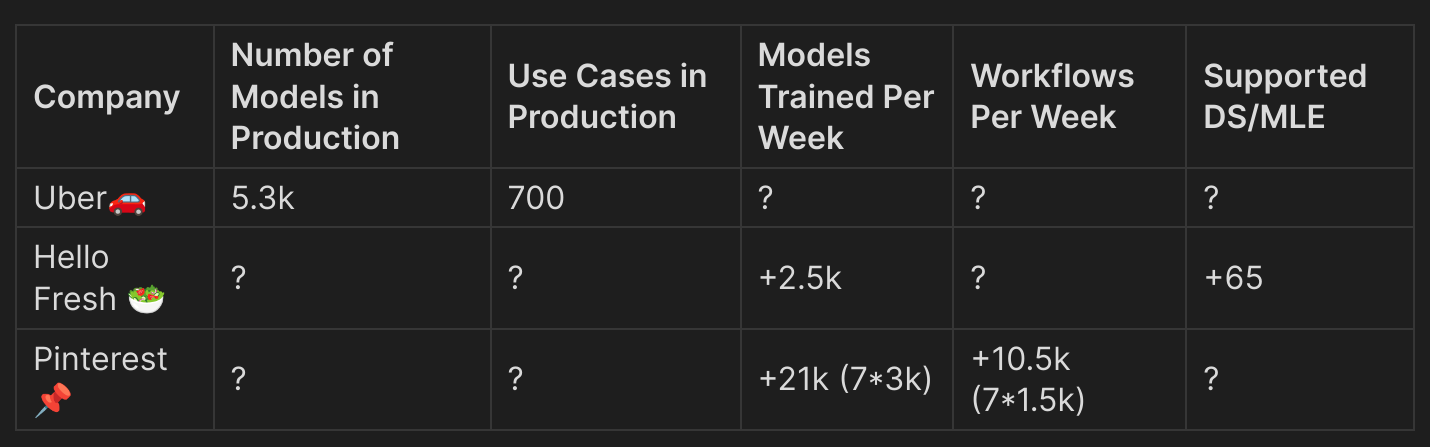
Le nombre de modèles construits et utilisés est vraiment impressionnant (si les chiffres sont exacts). Je pense que cela illustre d’une certaine manière comment le ML est démocratisé dans leurs entreprises mais cela soulève aussi la question de savoir si tous ces travaux sont vraiment nécessaires (mais je suppose que oui mais sur mon travail je ne vois pas ce genre de chiffres).
Au-delà de cet article, j’aime discuter de données, d’IA et de conception de systèmes - comment les projets sont construits, où ils réussissent et où ils échouent. Si vous voulez échanger des idées, remettre en question des hypothèses ou parler de vos propres projets, n’hésitez pas à me contacter. Je suis toujours ouvert à une bonne conversation.
Références
- conférence Apply(ops) 23 — tecton.ai
- Michelangelo (la plateforme ML interne) — uber.com
- Horovod (un framework d’apprentissage profond distribué, construit sur TensorFlow, PyTorch, etc.) — GitHub
- cette source de 2014 — business2community.com
- enquête 2023 de Hashicorp — hashicorp.com
- terraform — terraform.io
- opentofu — opentofu.org
- kubernetes — kubernetes.io
- kubeflow — kubeflow.org
- prometheus — prometheus.io
- Grafana — grafana.com
- mlflow — mlflow.org
- zen-ml — zenml.io
- Feast — feast.dev
- Kafka — kafka.apache.org
- Pinnerformer — arXiv
- MLenv — Medium / Towards Data Science
- la lutte de Netflix — arXiv
- Get Your Guide — getyourguide.com
- Riot Games — riotgames.com
- BentoML — bentoml.com