
Data scientist & Machine learning engineer : Décoder les rôles
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Je souhaitais écrire sur la “dualité” entre les rôles de data scientist (DS) et de machine learning engineer (MLE) car dans ma vie professionnelle, j’entends souvent des choses comme “Je n’ai pas besoin d’un MLE, mais d’un DS”, ou des opinions affirmant que “Les DS sont les pires et les MLE sont les meilleurs”. Une présentation récente d’Uber lors de la conférence Apply Ops en novembre dernier m’a semblé être un point de départ parfait pour cette discussion.

L’article commencera par une analyse du contenu présenté par Uber et des rôles dans un projet ML. Il sera suivi d’un aperçu des postes de data scientist et de machine learning engineer, concluant avec ma perspective sur leur “dualité”.
Le modèle d’Uber : Dévoiler les rôles et phases d’un projet ML
Dans sa présentation, Min Cai d’Uber a présenté leur approche globale pour appliquer le Machine Learning (ML) en production, discutant de leur stack et de leur vision d’un projet. La présentation comprenait un excellent diagramme qui, je pense, résume efficacement le cycle de vie d’un projet ML.
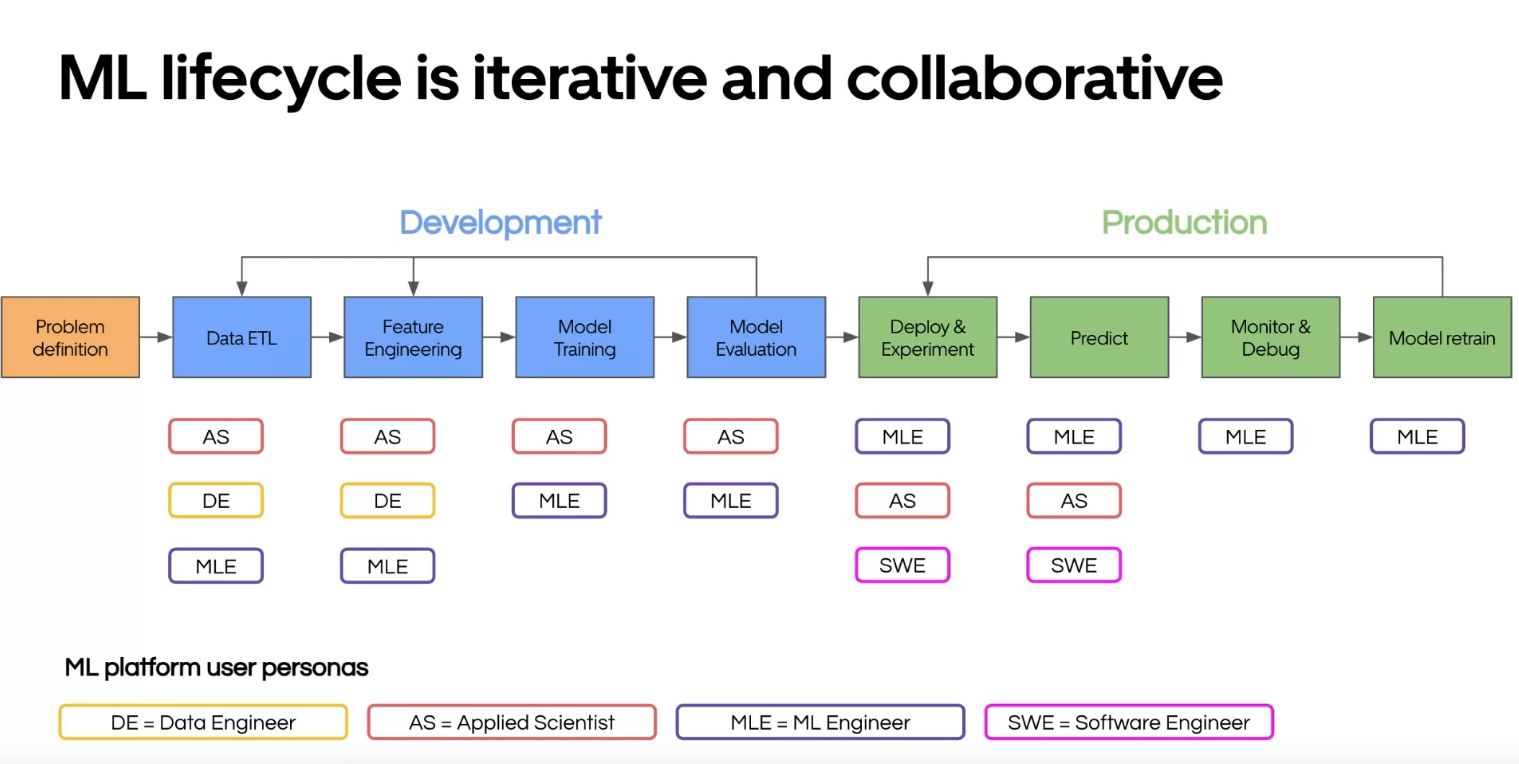
Comme vous pouvez le voir, le cycle de vie d’un projet ML est généralement divisé en deux parties consécutives principales : le développement et la production, suivant la définition du problème. Selon les étapes du cycle de vie, différents rôles peuvent intervenir :
- Applied Scientist : D’après ma compréhension, c’est un data scientist, le principal point d’entrée pour la phase de développement
- Data Engineer : Travaille aux côtés de l’applied scientist pour mettre en place le traitement des données et l’engineering des features.
- Machine Learning Engineer : Le principal point d’entrée dans la phase de production
- Software Engineer : Présent uniquement dans les étapes de déploiement et de prédiction de la phase de production, ils sont plus concentrés sur l’intégration des prédictions dans le système général (où le problème résolu par ML se produira).
Le Data scientist et le Machine Learning Engineer jouent des rôles centraux dans le cycle de vie du projet ML chez Uber (construit sur leur plateforme Michelangelo). Cependant, ce qui est particulièrement intéressant dans ce diagramme, c’est l’ordre des rôles (la profondeur) dans les étapes. Mon interprétation est que la première rangée de rôles est en charge de la conception, la deuxième rangée fournit un support ou est consultée pour le développement du composant, et la troisième rangée est plutôt informée. Cette configuration peut être vue comme une sorte de RACI ou RAM, qui sont des approches pour définir les rôles et responsabilités des différents acteurs dans un projet.
De la vision d’Uber, nous pouvons déduire les détails suivants :
- Le Data Scientist : N’est pas responsable du monitoring et du réentraînement du modèle, mais se concentre sur le développement du modèle et l’engineering des features.
- Le Machine Learning Engineer : Au moins consulté sur l’engineering des features et soutient la conception du modèle, concentrant son travail sur l’opérationnalisation du modèle.
Pour moi, leur vision est tout à fait logique et je pense que c’est un bon instantané de l’organisation actuelle dans une entreprise ML/data-centric en 2023 pour les rôles techniques dans un projet ML (excluant les rôles de PM et PO qui pourraient exister autour). Cependant, pour être honnête, nous remarquons un certain chevauchement entre les deux rôles, et il serait intéressant de voir à quoi cela ressemble plus en détail.
Data scientist : le métier le plus sexy du 21e siècle, et maintenant !?
“Le métier le plus sexy du 21e siècle”, ce ne sont pas mes mots, mais ceux d’un article d’octobre 2012 par la Harvard Business Review par Thomas H. Davenport et Dj Patil.

Je me souviens que cette phrase était assez populaire dans les offres d’emploi de data scientist entre 2014-2016. Voici un résumé de l’article qui donne une image claire du rôle d’un DS en 2012 :
- Un data scientist est quelqu’un qui peut traiter de grandes données non structurées avec plus que de simples mathématiques pour en extraire de la valeur, défini comme une nouvelle race.
- Le data scientist vise à résoudre des problèmes business et à faire plus que simplement créer des rapports ou donner des conseils ; ils veulent créer des produits orientés client.
- L’article commence avec la stratégie de recommandation LinkedIn et le travail de Jonathan Goldman en 2006.
- Les data scientists sont souvent curieux et appliquent des techniques d’autres domaines, comme des concepts de la biologie.
- En 2012, la plupart des data scientists n’avaient pas de formation académique en data science, car ce n’était pas un domaine d’études courant à l’époque, et ils venaient souvent de parcours non conventionnels.
- Ils sont en charge de l’ensemble du pipeline, c’est l’origine du DS full stack
- L’article mentionne l’émergence d’une deuxième génération de DS (post-2012), avec le début des cours universitaires, conduisant potentiellement à un marché du travail plus abordable.
- Les data scientists doivent être de bons communicants pour partager les résultats et idées avec des personnes moins ou pas du tout techniques
Cet article était définitivement un bon résumé du rôle d’un data scientist et était aussi un bon prédicteur de la façon dont le métier allait devenir populaire. Ci-dessous se trouve un graphique Google Trends montrant la fréquence de recherche web du terme “data scientist” dans le monde.
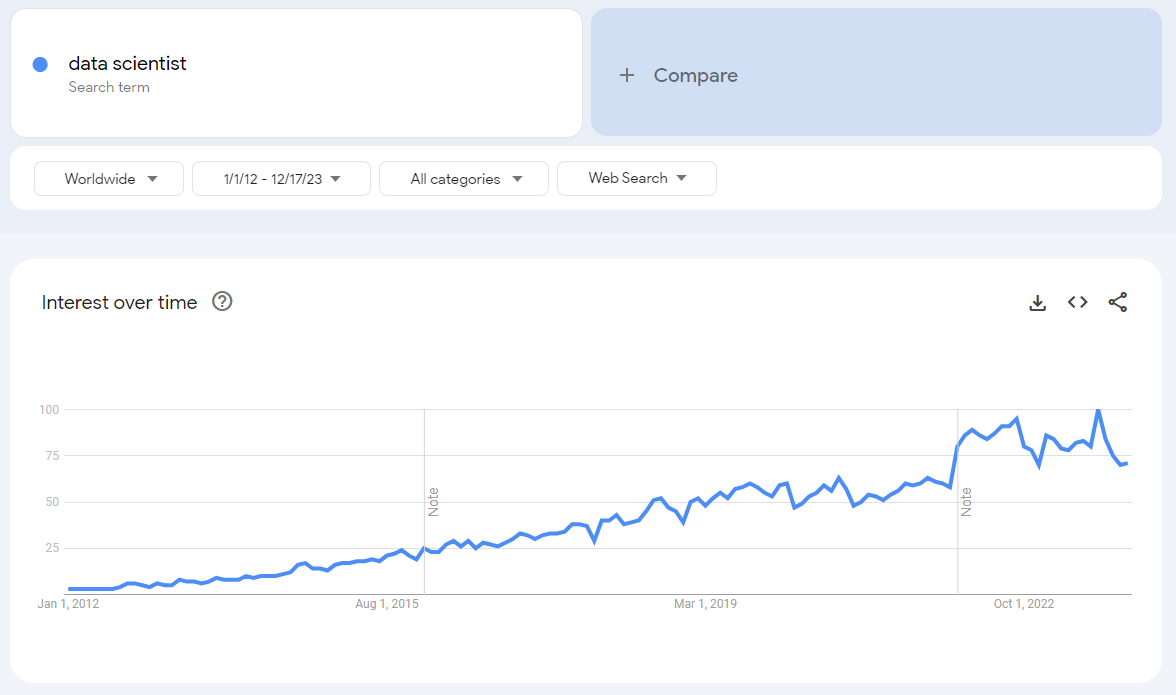
Il y a un intérêt progressif au fil du temps depuis 2012, avec un pic/plateau la dernière année.
Les auteurs ont revisité leur sujet l’année dernière (en juillet 2022, 10 ans plus tard dans une ère pré-ChatGPT) avec la question de suivi dans leur article Is Data Scientist Still the Sexiest Job of the 21st Century?
Leur article reste perspicace et fournit un bon instantané de la réalité actuelle d’un data scientist, avec plusieurs points intéressants :
- Ils discutent de l’émergence de nouveaux rôles autour d’un data scientist pour livrer un projet ML, y compris les data engineers, les product managers et les ML/AI engineers.
- De nouveaux outils sont arrivés pour les data scientists, réduisant le besoin de compétences en codage ; ils n’ont plus besoin d’être des magiciens full-stack.
- La notion de model drift et data drift a commencé à émerger après la pandémie, influencée par de nouveaux comportements de clients impactés par les confinements.
- Des questions autour de l’éthique et de la confidentialité des données ont émergé suite au scandale Cambridge Analytica.
- Les cours en ligne et universitaires peinent à capturer l’essence et les vraies forces d’un data scientist, comme un état d’esprit d’exploration et une connexion directe avec le business.
- Jusqu’en 2029, les data scientists devraient toujours être très recherchés.
Excluant le dernier point, qui peut être débattable dans cette nouvelle ère des Large Language Models (LLMs), l’article capture efficacement comment le travail a évolué pour les data scientists au cours des 10 dernières années.
Mais globalement, si je veux résumer le rôle, un data scientist est d’identifier les gains potentiels pour l’entreprise qui pourraient nécessiter l’utilisation de traitement de données “volumineuses” et/ou de techniques de machine learning pour livrer une solution apportant de la valeur au business. Ce schéma du blog tech de Door Dash capture le fait que la data science est au carrefour de multiples éléments de l’informatique (mais omet tout l’aspect communication)
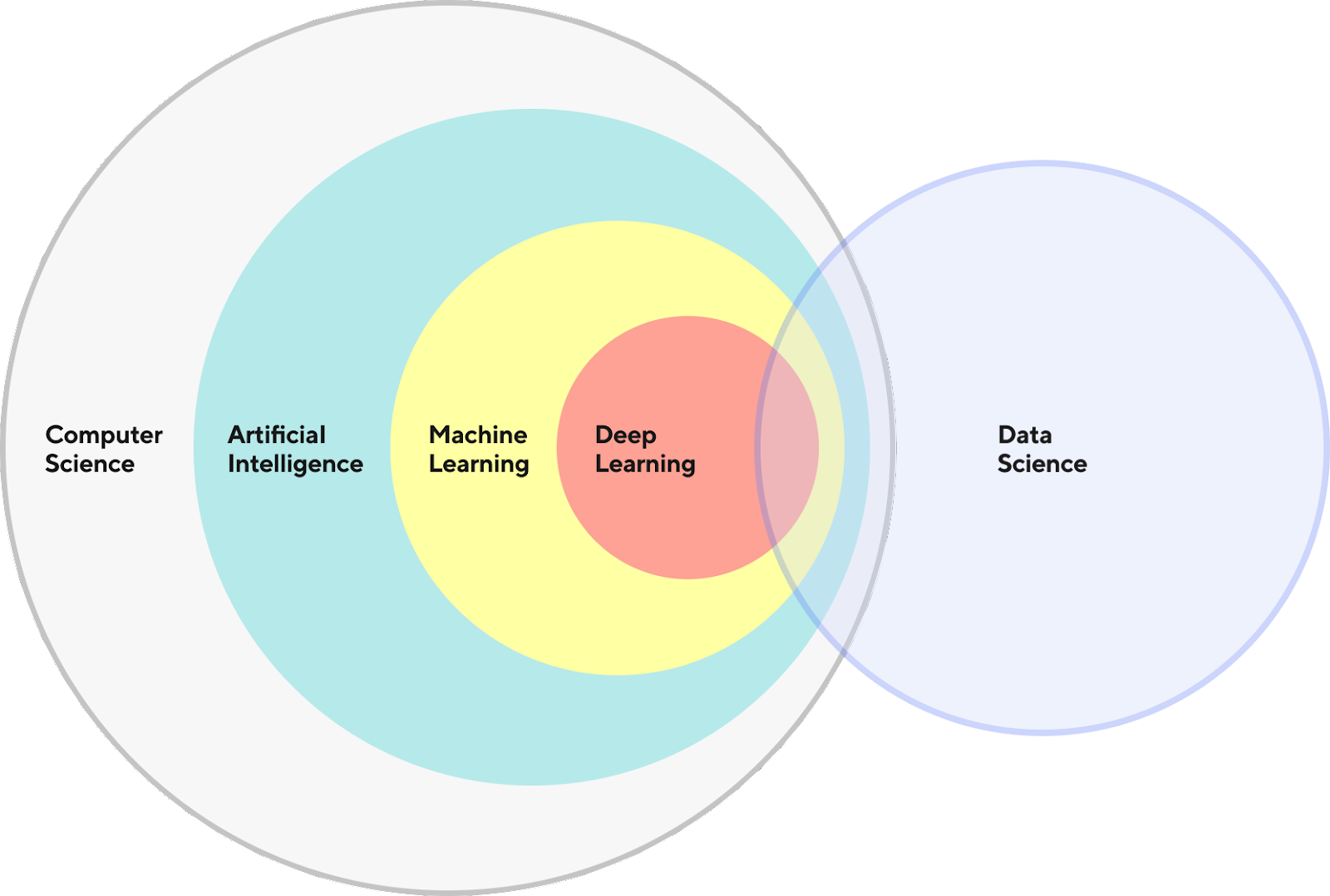
Maintenant, concentrons-nous sur le rôle du machine learning engineer.
Machine Learning Engineer : le nouveau petit génie du quartier !?
Si nous revenons à notre analyse Google Trends, en regardant le terme de recherche “machine learning engineer” dans le monde :
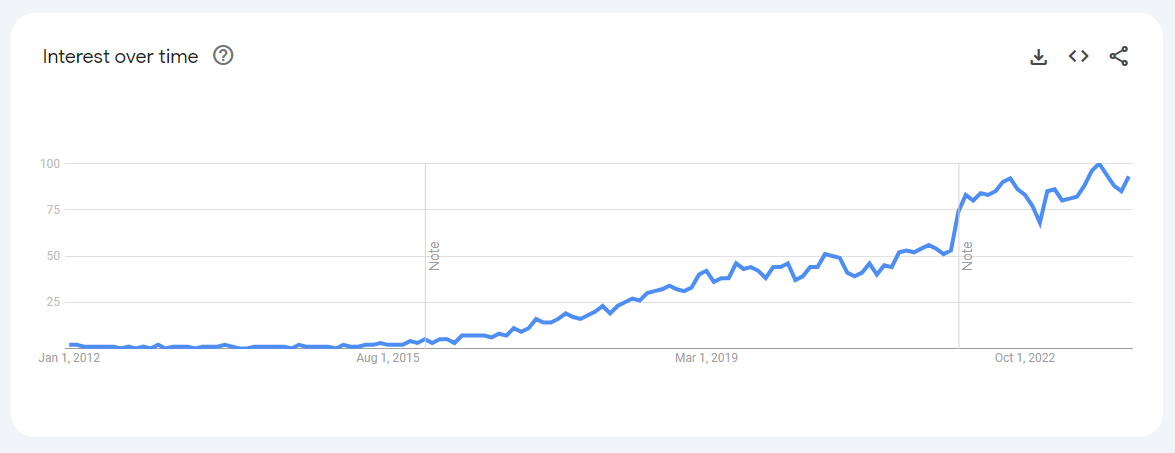
Le terme semble avoir commencé à apparaître à la fin de 2015 et au début de 2016, similaire à la tendance pour les data scientists, mais avec une progression moins forte. Cependant, en comparant l’intérêt global entre les deux termes :
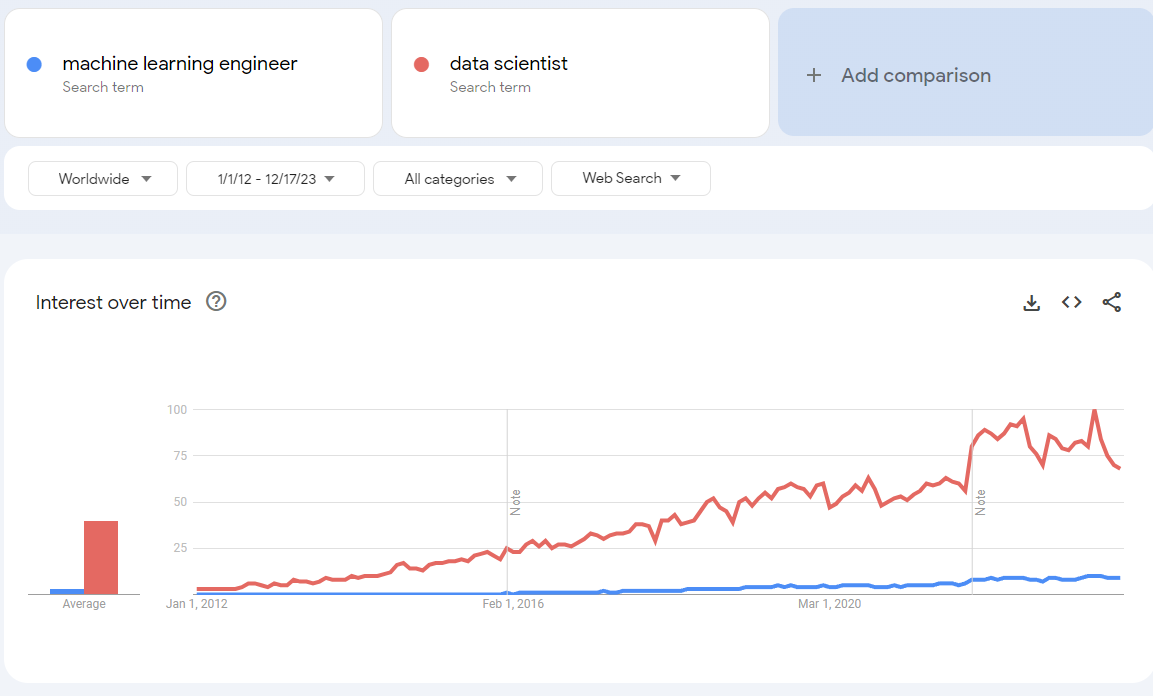
Il y a une avance claire dans les recherches web pour les data scientists sur les machine learning engineers. Alors, pourquoi discuter des machine learning engineers ? Parce qu’ils peuvent jouer un rôle important dans les organisations matures en données/ML.
Une ressource précieuse sur le rôle des machine learning engineers est un article de Shreya Shankar résumant sa première année de doctorat, où elle définit deux types de MLEs : Task MLE et Platform MLE.
Le Task MLE se concentre sur la mise en production des prototypes de data scientist, responsable de la construction et de la maintenance des pipelines ML et de leur correction. Cela correspond à la même division entre développement (domaine du data scientist) et production (domaine du MLE) vue dans le schéma Uber.
D’autre part, le Platform MLE soutient les Task MLEs en automatisant des parties de leur travail. Ils construisent des composants pour rationaliser le déploiement et le monitoring d’un pipeline/modèle ML mais ne jouent pas avec l’entrée/sortie du modèle et son architecture. Cette définition d’un Platform MLE m’a rappelé l’ingénieur MLOps (MLOE), j’ai trouvé un article de neptune.ai citant Amy Bachir, Senior MLOps Engineer chez Interos Inc, sur la différence entre les MLEs et les ingénieurs MLOps : “Les ML Engineers construisent et réentraînent les modèles de machine learning. Les MLOps Engineers permettent aux ML Engineers de faire leur travail. Ils construisent et maintiennent une plateforme pour permettre le développement et le déploiement de modèles de machine learning par la standardisation, l’automatisation et le monitoring. Les MLOps Engineers réitèrent la plateforme et les processus pour rendre le développement et le déploiement de modèles de machine learning plus rapides, plus fiables, reproductibles et efficaces.”
Un bon exemple des tâches et outils construits par un ingénieur MLOps est de regarder la présentation de Min Cai d’Uber, qui est similaire à la présentation qu’il a faite à la conférence Apply(ops). Ici, vous pouvez voir toutes les parties de leur stack/plateforme NL et un aperçu du déploiement de jobs (y compris le fichier de configuration), montrant le travail d’un ingénieur MLOps.
Donc, en revenant à notre discussion, pour résumer, le rôle d’un MLE est axé sur l’opérationnalisation du modèle et s’assurer que tout fonctionne bien, une mission critique dans les produits alimentés par ML où le data scientist ne construit que des prototypes ML pour les fonctionnalités d’un produit alimenté par ML, et l’ingénieur MLOps construit les fondations tech/code pour que ces deux profils travaillent.
Ma perspective sur DS VS MLE
Sur le papier et dans les entreprises centrées sur les données/ML, la distinction entre les rôles DS et MLE semble être une bonne configuration. Cependant, cette distinction est largement théorique. La plupart des entreprises manquent de maturité pour une séparation nette, comme le montre un livre blanc d’Arize sur ML Observability, où DS et MLE sont souvent classés sous le même parapluie.
Ma déclaration est la suivante (excluant les entreprises type FAANG), dans de nombreuses entreprises :
Le machine learning engineer est essentiellement un data scientist rebaptisé en termes de titre de poste, mais pas en termes de tâches(et c’est OK)
Ce rebranding permet aux entreprises d’être plus attractives en créant une nouvelle référence salariale pour attirer les candidats et en suivant les tendances des postes dans les grandes entreprises technologiques.
Le machine learning engineering n’est-il qu’un mot à la mode ?
Non, c’est important (comme on le voit dans son rôle critique dans les grandes entreprises technologiques). Cependant, je pense qu’actuellement, la plupart des entreprises n’ont pas suffisamment de charge de travail ML pour justifier d’avoir des machine learning engineers concentrés uniquement sur le côté production des projets ML. Je vois deux raisons principales à cela :
- Temps pour intégrer une prédiction ML : Même avec l’API la plus simple pour les prédictions, si ce n’est pas une priorité business, le projet pourrait être bloqué pendant des mois ou des années (je l’ai vu se produire).
- État d’esprit d’expérimentation dans une entreprise : Une entreprise peut avoir implémenté un système ML pour les prédictions (comme un système de recommandation), mais si le business est satisfait de ce qu’il a et n’est pas désireux d’explorer de nouvelles possibilités, l’innovation stagne.
Ces raisons expliquent pourquoi des entreprises comme FAANG ont des machine learning engineers dédiés : elles sont plus orientées données/ML/expérimentation, avec des besoins clairs, une intégration ML facile et modulaire, et une volonté continue d’explorer et d’innover là où d’autres entreprises sont encore en retard (mais construisent lentement leur truc).
Fraîchement diplômé en machine learning/informatique : Quelle voie dois-je prendre ?
Votre choix dépend de vos intérêts :
- DS : Si vous êtes curieux de trouver et de répondre aux besoins business
- MLE : Si vous êtes désireux de déployer des preuves de concept en production efficacement et de gérer des systèmes en direct
- MLOE : Si vous êtes intéressé par l’habilitation des praticiens ML avec le bon stack technologique et code.
Et je vous vois, “Je suis intéressé par les trois voies”, vous pouvez définitivement suivre cette route pour tout essayer en parallèle mais soyez prêt à avoir beaucoup dans votre assiette.
Pertinence de ces métiers à l’ère des LLM
Les data scientists et machine learning engineers sont plus pertinents que jamais, chacun abordant des défis spécifiques :
- DS : Comment intégrer les LLM dans les solutions business ?
- MLE : Comment monitorer et affiner les LLM ?
- MLOE : Comment rendre les LLM largement disponibles de manière contrôlée (en considérant la confidentialité des données, les coûts d’entraînement et de service) ?
Créer une entreprise/équipe pour des produits/services alimentés par ML : Quand embaucher ces rôles ?
Initialement, embauchez un data scientist avec un talent pour construire des pipelines de production. En 2023, il est plus facile que jamais d’opérer des modèles derrière des services gérés pour livrer de la valeur rapidement (bien que cela puisse avoir un coût).
Ensuite, concentrez-vous sur l’embauche d’un ingénieur MLOps qui posera les fondations techniques et de code pour les futurs projets ML.
Les MLE devraient-ils être les derniers à embaucher ?
Oui, embauchez les MLEs en dernier, car leur rôle devient crucial seulement lorsqu’il y a suffisamment de charge de travail ML et que vous avez besoin que le data scientist se concentre sur d’autres projets/sujets.
Est-ce que Data Scientist < Machine Learning Engineer ?
La hiérarchie perçue entre les titres de poste, comme Data Scientist versus Machine Learning Engineer, Data Analyst versus Data Scientist ou Data engineer VS développeur BI, suggère souvent que les nouveaux rôles sont intrinsèquement supérieurs. Ce sujet me rappelle un article de Cassie Kozyrkov sur le rôle du data analyst dans le monde de la data science. Il souligne l’importance de ne pas juger les gens par leurs titres de poste mais plutôt par la qualité et l’impact de leur travail et les compétences qu’ils emploient.
Notes de conclusion
Explorer les rôles des data scientists et des machine learning engineers montre un paysage diversifié et complexe. Les titres et définitions peuvent différer dans l’industrie, mais le cœur de ces rôles réside dans leurs contributions uniques à un projet de machine learning dans une entreprise.

Alors que les domaines du machine learning et de la data science évoluent, c’est le mélange de compétences, de créativité et de flexibilité qui stimule le progrès. La synergie entre ces rôles est cruciale. À mesure que le domaine mûrit, nous pourrions voir plus d’évolution et de spécialisation, mais l’objectif principal reste le même : utiliser les données pour découvrir de nouvelles possibilités et résoudre des défis complexes.
Au-delà de cet article, j’aime discuter de données, d’IA et de conception de systèmes—comment les projets sont construits, où ils réussissent et où ils échouent. Si vous voulez échanger des idées, remettre en question des hypothèses ou parler de vos propres projets, n’hésitez pas à me contacter. Je suis toujours ouvert pour une bonne conversation.
Références
- RACI ou RAM — gartner.com
- article d’octobre 2012 par la Harvard Business Review — hbr.org
- Is Data Scientist Still the Sexiest Job of the 21st Century? — hbr.org
- blog tech de Door Dash — doordash.engineering
- article de neptune.ai — neptune.ai
- ML Observability — arize.com
- un article — Medium / Towards Data Science