
Mon parcours d'une décennie dans les données et l'IA
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
L’année passée a été tumultueuse, marquée par des changements d’équipe, des réorganisations et d’autres événements. C’était aussi l’année où j’ai célébré une décennie de travail dans le domaine de la data science. Durant cette période, j’ai travaillé pour quatre entreprises dans trois pays (France, Angleterre et Canada) et dans diverses industries, en commençant dans le secteur de l’énergie et en transitionnant vers l’industrie du jeu vidéo il y a six ans et demi.
En regardant en arrière sur ces 10 années, j’ai recueilli des apprentissages et des expériences clés. J’ai décidé de les résumer dans cet article—alors allons-y.
Au-delà du buzz : Classifier les technologies émergentes
Travaillant comme data scientist dans plusieurs industries depuis 10 ans, j’ai été intégré dans des équipes axées sur l’innovation. Cela m’a permis d’explorer et de partager de nouveaux outils et algorithmes, tant en interne qu’en externe. Pour garder la tête froide face au battage médiatique entourant les nouvelles entreprises, outils, frameworks et algorithmes, j’ai trouvé crucial de développer un système de classification pour toutes ces nouvelles informations.
Cycle du battage et radar technologique
Cette section se concentrera sur deux représentations établies utilisées pour la classification. La première est le cycle du battage de Gartner, qui décrit comment les attentes pour une technologie évoluent dans le temps avant qu’elle n’atteigne finalement un plateau de productivité. Le pic caractéristique du cycle du battage au milieu illustre comment les attentes peuvent devenir gonflées, pour ensuite décliner aussi rapidement qu’elles ont augmenté. Un exemple parfait est le dernier cycle du battage publié par Gartner, qui se concentre sur l’IA pour 2024.
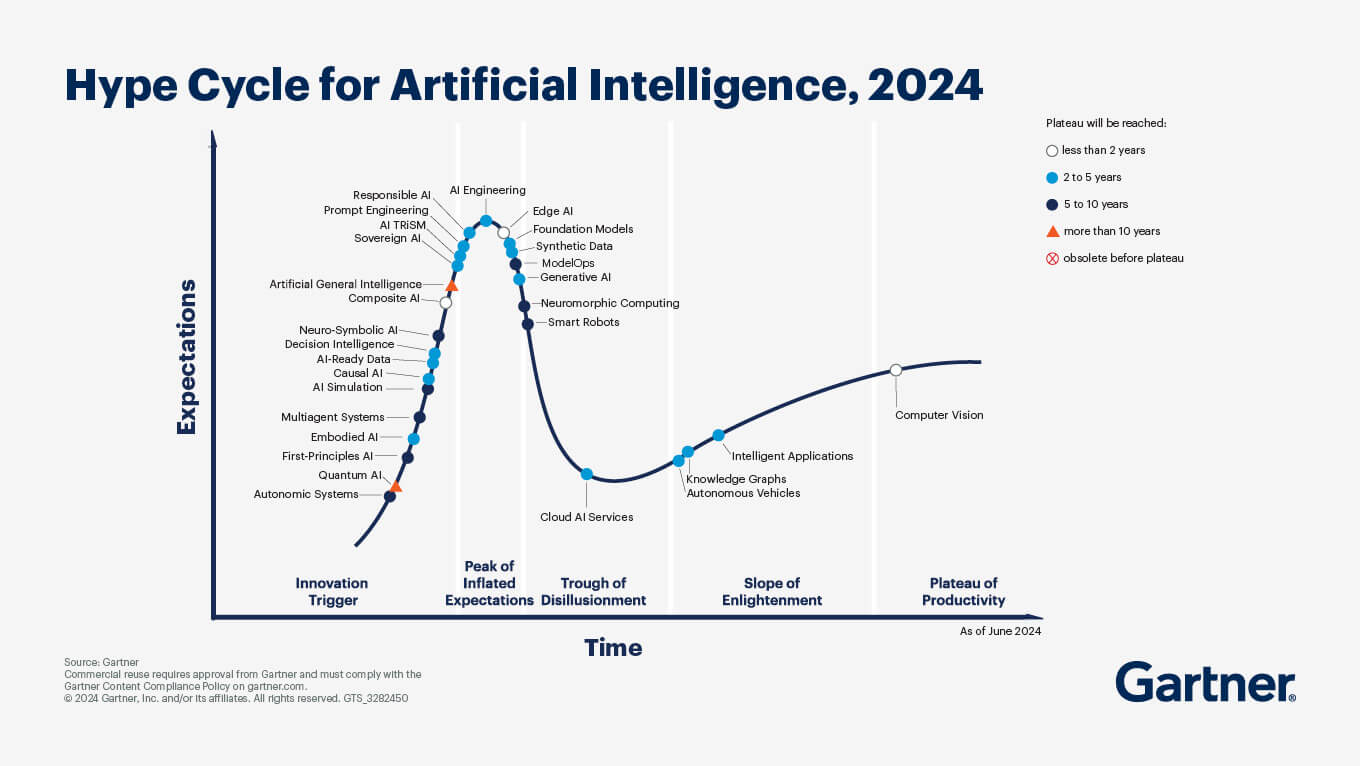
L’idée clé n’est pas seulement la forme de la courbe, mais de savoir où se situe une technologie sur celle-ci au fil du temps. Gartner a récemment introduit un code couleur pour estimer quand les technologies atteindront le plateau de productivité.
Mais au-delà du cycle du battage, que beaucoup de gens utilisent comme référence commune, il existe une deuxième classification que j’ai trouvée intéressante et peut-être moins commune : le radar technologique de Thoughtworks. Je l’ai découvert en lisant une série d’articles de LJ Miranda sur la classification des outils MLOps.

Le concept consiste à diviser le radar en quadrants, chacun représentant une catégorie de technologies (par exemple, logiciels, langages). Dans chaque quadrant, les technologies sont positionnées en fonction de leur statut d’adoption recommandé :
- Plus proche du centre signifie que la technologie devrait être adoptée ou essayée.
- Plus loin du centre implique que la technologie devrait être évaluée ou mise en attente.
Cette vue est plutôt bonne et LJ Miranda a fait une version modifiée dans son article, mais elle garde l’essence de l’adoption recommandée.
D’accord, mais au-delà du framework et de la visualisation, quelles sont mes réflexions sur tout ce battage autour des données/IA ?
Mon avis sur la classification du battage
Au début, quand j’écrivais cette section, je voulais construire mon propre framework qui était une sorte de mashup entre le cycle du battage et le radar.

Rétrospectivement, je réinventais probablement la roue, mais après avoir passé des heures à le créer dans Procreate, je voulais le garder. Mais quand même, derrière tous ces frameworks, il y a une question à laquelle il faut essayer de répondre :
Quand cette technologie peut-elle être utile et utilisée pour mon entreprise et pas juste être une démonstration ?
Une technologie spécifique à un moment spécifique peut sembler non pertinente. Par exemple, les architectures d’apprentissage profond à la fin des années 1980 étaient intéressantes mais non applicables. Cependant, les systèmes utilisant des architectures d’apprentissage profond font maintenant partie de notre vie quotidienne.
Catégoriser la technologie par sa disponibilité pour la production est utile pour la planification de la feuille de route produit/projet. Par exemple, en 2020, un client de notre plateforme ML a insisté pour utiliser un modèle d’apprentissage profond pour construire un système de recommandation, comme le faisait Facebook. Cependant, après quelques explorations et tests, nous avons déterminé que ce n’était pas une priorité, car il n’y avait aucune preuve dans la littérature que cette technique offrait un avantage à ce moment-là. Il est donc important de garder la tête froide dans cette industrie et de se concentrer sur ce qui peut apporter de la valeur rapidement (première règle du machine learning : n’utilisez pas le machine learning), mais gardez quand même l’esprit ouvert pour l’avenir (règle du 80-20 en gros)
Mais au-delà du battage des domaines, parlons d’organisation.
Naviguer les défis d’organisation des données
Avant de rejoindre Ubisoft, je faisais partie d’équipes plus petites qui avaient des missions variées. Ces équipes ne travaillaient pas sur une stack de données traditionnelle ; au lieu de cela, elles expérimentaient et créaient leurs solutions pour livrer leurs projets, et honnêtement cela semble raisonnable de le faire, mais on pouvait voir beaucoup de chevauchement et de duplication de travail qui auraient pu être évités. Cependant, je pense que j’ai rejoint Ubisoft au moment parfait car j’ai pu être témoin de comment une grande entreprise, non axée sur les données mais favorable aux données, pouvait structurer sa stratégie de données pour être plus efficace.
D’un réseau à un maillage
En 2018, je suis devenu membre de l’équipe DNA d’Ubisoft, qui se concentrait sur le soutien de la production de jeux en créant des outils de données comme des tableaux de bord KPI, des visualisations 3D et des plateformes analytiques. D’autres équipes chez Ubisoft développaient également des outils de données pour divers départements, y compris le marketing, les RH et le juridique. Avec plus de 15 000 employés dans le monde, les besoins en données étaient divers.
Après quelques années, un bureau de données centralisé a été établi pour consolider les équipes de données, prévenir la duplication et optimiser les processus. En théorie, cela semblait être une bonne idée ; cependant, en réalité, la centralisation a conduit à une incompréhension de la consommation de données et a désensibilisé les départements au coût réel de l’utilisation des données. Par exemple, les praticiens des données comme les analystes ont été retirés de leur département et assignés au bureau de données, ce qui a créé une déconnexion entre le travail sur les données et le département (combien cela coûte, ce qu’il faut pour obtenir ces chiffres essentiellement)
Au cours de l’année passée, il y a eu un changement vers une stratégie de données plus fédérée, plutôt qu’un retour en arrière complet. Dans ce modèle, un bureau de données central fournit la gouvernance, les outils et les API à différentes zones de l’entreprise, avec des représentants du bureau de données garantissant que leurs intérêts sont pris en compte, comme dans ce schéma.
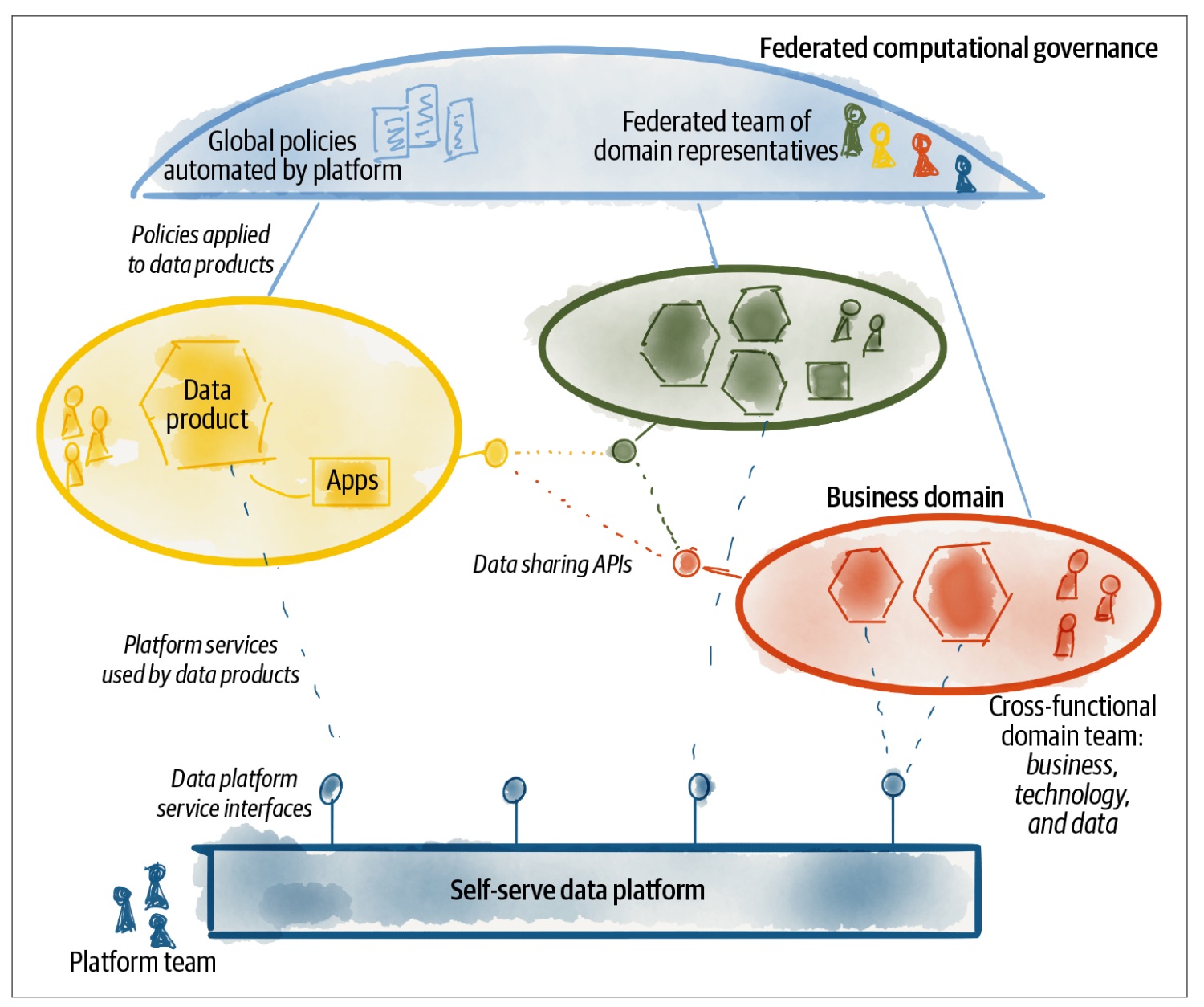
Ce concept n’est pas nouveau et s’inspire du concept de maillage de données, comme détaillé dans le livre de Zhamak Dehghani “Data Mesh: Delivering Data-Driven Value at Scale.” (recommandé par notre direction générale) d’où j’ai tiré la figure précédente. Cette structure organisationnelle semble prometteuse, mais j’ai encore quelques interrogations (auxquelles seul le temps répondra, je suppose).
- Quels types de rôles sont nécessaires pour faire fonctionner cette fédération ? Je vois des titres d’emploi comme stratège de données et gestionnaire de données émerger. À mon niveau, je ne vois pas comment ces rôles impacteraient directement mon travail, mais je suppose qu’ils faciliteraient les interactions entre les domaines dans ce modèle fédéré.
- Quels mécanismes peuvent être mis en place pour empêcher les équipes de faire cavalier seul ? Je n’ai pas fini de lire le livre Data Mesh, donc peut-être qu’il aborde ce point, mais d’après mon expérience, il y a toujours quelque chose que les équipes utiliseront pour justifier de faire cavalier seul (généralement une tendance technologique).
La structure organisationnelle idéale pour une équipe de données au sein d’une entreprise dépend de la taille de l’entreprise et de l’organisation actuelle. Dans une entreprise de 100 employés, une équipe de données centralisée pourrait être appropriée. Trouver le bon équilibre est crucial mais difficile. Cependant, il y a une question en suspens.
Qu’en est-il d’une organisation IA ?
Comment l’IA s’intègre-t-elle dans tout cela ? Pour être honnête, je commence à voir des organigrammes avec des titres préfixés par IA comme Directeur de programme d’IA générative, VP des programmes IA, ou Gestionnaire de programme IA, et je ne peux m’empêcher de penser à ce tweet de 2018 quand je vois IA dans un titre d’emploi 😁
L’émergence de rôles IA soulève quelques questions pour moi.
Les projets IA devraient-ils être sous la gouvernance du bureau de données ? Un grand oui, car l’IA n’est qu’un sous-produit des données ; comme le reporting, il semble normal qu’ils suivent des règles et une logique de fédération similaires à travers l’entreprise (avec une politique matérielle spécifique, car l’entraînement et le service de modèles sont des tâches très spécifiques).
Avez-vous besoin d’un Chief AI Officer ? Étant donné l’importance croissante des applications IA dans la stratégie de l’entreprise, et selon la taille de l’entreprise et sa charge de données/IA, je crois que ce rôle pourrait être précieux.
Quelles seront les tâches et le mandat d’un Chief AI Officer ? Laissez-moi vous concevoir une offre d’emploi
- Diriger les initiatives IA internes en tant que coordinateur principal, alignant les projets IA avec les stratégies et objectifs commerciaux globaux.
- Superviser les Product Owners/Product Managers IA dans toutes les divisions de l’entreprise, garantissant un développement de produits cohérent et un alignement stratégique.
- Collaborer étroitement avec les responsables des départements Données, IT et Sécurité pour livrer des systèmes IA robustes, évolutifs et sécurisés, tout en respectant les meilleures pratiques de l’industrie et les normes de conformité.
- Communiquer efficacement avec la direction générale et les responsables techniques dans diverses unités commerciales pour favoriser la compréhension et l’adoption des solutions IA, traduisant des concepts techniques complexes en insights commerciaux actionnables.
- Se tenir au courant des tendances émergentes et des avancées dans le paysage IA, identifiant les opportunités et menaces potentielles, et adaptant les stratégies en conséquence.
- Allouer du temps également entre la promotion et le développement de solutions IA innovantes avec un fort potentiel de succès et le déploiement de systèmes IA prouvés (section 1 plateau de productivité), fiables pour répondre aux défis commerciaux existants et rêver un peu
Mais dans l’ensemble, en résumé, je pense que ce rôle est principalement responsable de la coordination et de l’amélioration de l’efficacité IA au sein de l’entreprise. Il ne devrait avoir aucun développeur directement sous ses ordres. Si je me réfère à ma visualisation du battage pour représenter les technologies, il existe différents cônes de discussion autorisés pour ce rôle.

Il devrait se concentrer sur le travail avec les développeurs pour utiliser et discuter des technologies prêtes pour la production ou presque prêtes qui peuvent apporter de la valeur tout en vendant une vision à la direction générale (être le “gars du battage”) mais en mettant quand même en avant ce qui est en production.
En conclusion, j’ai été témoin de cette transformation au sein d’une entreprise de jeux vidéo, mais il est important de noter que de nombreuses entreprises restructurent leur approche des données/IA, Yves Caseau de Michelin et Michel Lutz de Total Energies sont deux sources précieuses d’informations sur cette tendance, car ils partagent fréquemment des perspectives intéressantes sur le sujet de l’organisation dans les grands groupes.
Maintenant, plongeons dans le cœur de mon travail, les projets et quelques apprentissages autour d’eux.
Cycle de vie du projet
Tout au long de ma carrière de 10 ans, j’ai eu l’occasion de travailler sur un large éventail de projets. Ces projets peuvent être globalement catégorisés en deux types principaux : les projets de preuve de concept (PoC), les produits minimum viables (MVP ou PoC++ avec des données/flux utilisateur réels) et les projets qui ont été déployés avec succès en production (version mise à l’échelle d’un MVP).
J’ai été impliqué dans de nombreux projets PoC, principalement pendant mon temps au CEA et à EDF. Mon rôle actuel chez Ubisoft a déplacé mon attention vers des projets de production, avec quelques PoC ici et là (qui sont généralement plus proches du MVP). Je n’entrerai pas trop dans les détails sur la façon dont j’organise mes projets, car cela a beaucoup changé au fil des ans, mais je pense que j’écrirai quelques articles à ce sujet plus tard. Pour l’instant, je me concentrerai sur la façon dont les projets peuvent être lancés et les conclusions générales.
Hackathon
Durant mon temps chez EDF et Ubisoft, j’ai été impliqué dans de nombreux hackathons, à la fois en tant que participant et en tant qu’organisateur. C’était une nouvelle expérience pour moi, mais j’ai découvert les hackathons comme un excellent moyen de lancer des projets. Au fil du temps, j’ai identifié trois types distincts.

Hackathons libre pour tous : Ces hackathons sont principalement axés sur le team building et l’exploration, sans objectifs spécifiques ou buts de production.
- Exemple : Nous avons organisé un hackathon pour les data scientists locaux utilisant notre plateforme ML. L’objectif était d’explorer des projets IA qui pourraient être implémentés sur notre plateforme, en utilisant les données disponibles. Bien que de nombreuses idées intéressantes aient émergé, aucune n’a été implémentée en raison d’un manque d’adhésion commerciale.
- Avantages : Liberté d’explorer et d’expérimenter
- Inconvénients : Les résultats peuvent ne pas être actionnables ou mener à des projets de production.
Hackathon axé sur la technologie : Un hackathon collaboratif avec un plus grand nombre de programmeurs “hardcore”. L’accent est mis sur l’utilisation d’une technologie spécifique pour répondre à un ou plusieurs besoins commerciaux ou objectifs de feuille de route.
- Exemple : Notre équipe de plateforme ML explorait des capacités de prédiction en direct, incluant le service de modèles et l’ingénierie de caractéristiques. Nous nous sommes associés à une équipe expérimentée dans les technologies de streaming comme Kafka pour expérimenter des flux possibles pour livrer des fonctionnalités de prédiction en direct
- Avantages :
- Explorer des technologies nouvelles et intéressantes
- Générer de nouvelles idées commerciales
- Inconvénients :
- La configuration technique peut prendre du temps
- Potentiellement moins engageant pour les data scientists, car un ML complexe et de l’ingénierie de données peuvent ne pas être requis initialement
Hackathons axés sur le business : Ces hackathons, auxquels j’ai principalement participé chez EDF, sont divisés en deux phases principales avec une idéation où les sponsors commerciaux présentent des idées et les développeurs de notre équipe fournissent un soutien sur la technologie qui peut être utilisée (appareils ou logiciels) pour concevoir plusieurs sujets pour la deuxième phase qui est le hackathon lui-même
- Exemple : Un hackathon s’est concentré sur le soutien aux installateurs de compteurs intelligents. Pendant la phase d’idéation, nous avons conçu plusieurs projets, y compris un simulateur VR (vidéo 360) pour tester le stress des installateurs en utilisant Unity.
- Avantages :
- Idéation appropriée
- Orienté business et aboutit à des résultats actionnables.
- Inconvénients :
- Plus de préparation
- Moins de liberté, car les sujets sont définis à l’avance.
Les hackathons peuvent être un excellent moyen de lancer des projets internes et de générer de nouvelles idées au sein d’une entreprise. Bien qu’il existe plusieurs façons de structurer un hackathon, j’ai trouvé que le format axé sur le business tend à donner les meilleurs résultats. Dans ce format, les problèmes ou défis à aborder sont définis à l’avance par le côté commercial de l’organisation. Cela garantit que les solutions développées pendant le hackathon sont directement alignées avec les objectifs stratégiques de l’entreprise et ont un chemin clair vers l’implémentation.
Maintenant, parlons de la gestion de projet elle-même.
Gestion de projet
Au-delà de l’aspect technique, achever un projet avec succès nécessite de gérer efficacement les ressources et le temps. Voici quelques leçons clés que j’ai apprises.

Gestionnaires de projet : En 2018, j’avais des sentiments mitigés sur la nécessité des gestionnaires de projet. Bien que j’aie eu de bonnes et de mauvaises expériences avec eux, je questionnais leur rôle d’intermédiaires entre les équipes techniques et les clients.
Cependant, chez Ubisoft, j’ai commencé à voir la valeur des gestionnaires de projet dans les grandes organisations. Ils facilitaient la communication avec les clients, promouvaient notre travail au sein de l’entreprise et aidaient à établir des cadres pour de nouvelles initiatives. Ce rôle est particulièrement efficace lors de la gestion de plusieurs projets et de l’assurance de leur lancement rapide. Cependant, les gestionnaires de projet ne sont pas seuls responsables de ces tâches ; ils collaborent avec d’autres (je veux dire des gens comme moi) pour atteindre ces objectifs.
Apprentissages : La familiarité avec les méthodologies de gestion de projet (par exemple Agile, Scrum, Kanban) et les outils (par exemple Jira, Asana) est essentielle pour tout praticien de données ou d’IA afin de gérer efficacement leur temps et de livrer des projets dans les délais (et de travailler en bons termes avec les gestionnaires de projet). Je n’entrerai pas trop dans les détails de mes expériences avec ces méthodologies et outils, mais voici quelques points clés à retenir.
- Divisez votre travail en tâches : Les tâches devraient idéalement être complétées en une semaine, car cela indique qu’elles peuvent être divisées en tâches plus petites et plus gérables. Ma répartition typique du travail implique des tâches qui peuvent être complétées en une heure (par exemple, envoyer un email, mettre à jour la documentation), un jour, ou une semaine.
- Documentez autant que possible : Documenter votre système et vos expériences est un aspect crucial, bien que moins excitant, du travail. Par exemple, créer un document résumé d’une page pour votre client est essentiel après quelques semaines de travail sur tout projet PoC, MVP ou production.
- Soyez un optimiste conditionnel : Lorsque vous travaillez avec des clients, vous devriez être optimiste sur votre calendrier proposé, mais incluez toujours des conditions qui doivent être remplies pour atteindre ce calendrier. La disponibilité des données est un exemple courant d’une telle condition.
- Git et tâches : Lier les merge requests et les tâches est une bonne pratique pour segmenter le travail et maintenir la traçabilité, ce qui à son tour documente le développement du projet.
- Cycle de vie : Planifier une feuille de route pour tout projet est crucial, mais il est tout aussi important de considérer les divers aspects de la mise hors service d’un projet, qui seront discutés dans une section ultérieure.
La crédibilité dans l’industrie des données/IA au-delà de la pure connaissance technologique dépend de la compréhension de ces méthodologies et outils, car ils sont couramment rencontrés sur le lieu de travail et illustrent de bonnes capacités de planification
Standardisation
Durant mes 5 premières années chez Ubisoft, j’étais intégré dans une équipe produit responsable du développement d’une plateforme ML. Après avoir déployé plusieurs projets de recommandation, un besoin de standardisation des flux de travail s’est fait sentir. De nombreux éléments étaient réutilisables entre les projets, rendant la standardisation précieuse—mais décider jusqu’où aller était un défi.

En 2022 et début 2023, l’une de mes principales tâches était de simplifier l’utilisation de notre plateforme ML en contribuant à notre package de code inner source pour interagir avec les composants de la plateforme ML. Les développeurs avaient déjà établi un cadre pour faciliter l’empaquetage du code. Nous avons beaucoup appris de ce travail de standardisation.
- Déterminez votre audience : Adaptez la standardisation à votre audience
- Préempaquetez les fonctions souvent utilisées : Notre focus principal tournait autour des interactions d’entrée et de sortie entre les divers composants de la plateforme. Cela incluait tout, des interactions de stockage de données à notre serveur MLflow et toutes les fonctions qui étaient utilisées quotidiennement.
- Soyez agnostique technologiquement : Le code préempaqueté devrait abstraire les composants de la plateforme, nous permettant de nous concentrer sur la fonctionnalité désirée plutôt que sur la technologie sous-jacente. Je fournirai des exemples spécifiques dans la section suivante.
- Construisez un projet exemple : Ces extraits de code fournissent une illustration complète de la façon d’utiliser les fonctions préempaquetées de la plateforme du début à la fin, servant de point de départ idéal.
- Ne vous concentrez pas sur la partie ML : On nous a demandé d’empaqueter notre code ML ; cependant, cela devrait être votre dernière étape. La plupart des packages open-source actuels fournissent déjà un niveau d’abstraction suffisant, et le bon extrait de code suffit pour comprendre la logique de la partie ML d’un projet.
- Documentation en tant que code : Lier la documentation directement au code est essentiel. Sphinx est un excellent outil pour cela en Python.
Après avoir établi ces pratiques de standardisation, des questions se posent inévitablement concernant la promotion, la maintenance et l’évolution de ces standards. À mon avis, les bureaux de données/IA devraient être responsables de la gestion de ces standards, mais je n’ai pas encore vu de plan concret à long terme pour y parvenir (pas une tâche facile)
Passons maintenant à un sujet plus concret, la stack technique.
Ne vous attachez pas à la stack
Mes outils et technologies ont évolué naturellement au fil du temps. De 2014 à 2018, j’ai principalement travaillé sur ma machine locale (ordinateur portable Windows, Raspberry Pi, ou Macbook Pro), utilisant occasionnellement le cloud pour certaines applications. Je n’avais pas de stack de machine learning dédiée pendant cette période. En 2018, j’ai commencé à travailler sur des projets de production chez Ubisoft, où j’ai commencé à utiliser davantage le cloud et à travailler dans des environnements distribués avec Spark pour gérer les jobs ETL, l’analyse et les pipelines de machine learning. J’ai également utilisé des machines GPU pour explorer des systèmes basés sur l’apprentissage profond et des outils de machine learning pour simplifier ma charge de travail pendant l’exploration et le déploiement de projets, comme on peut s’y attendre quand on fait partie de l’équipe de plateforme ML.
Cette progression montre comment le domaine a changé et mûri au cours des 10 dernières années, mais elle m’a appris qu’il est important de ne pas trop s’attacher à une stack technique spécifique, ce qui ouvre plusieurs points de discussion.
Le paradoxe Build VS Buy : mon expérience de plateforme ML
En tant que membre d’une équipe construisant une plateforme ML, j’ai été dans une position unique pour expérimenter le dilemme commun de construire versus acheter auquel les entreprises font face aujourd’hui.
 (merlin tenant un merlan dans le style de Michel-Ange)
(merlin tenant un merlan dans le style de Michel-Ange)
Le produit de plateforme ML, Merlin, a démarré en 2018. Son développement était motivé par des besoins internes chez Ubisoft, qui commençait à voir des solutions de fortune pour opérer des pipelines de machine learning sur la plateforme analytique. Le projet s’est inspiré de la plateforme ML Michelangelo d’Uber, qui détaillait le concept et les avantages d’avoir une plateforme ML.
En 2019-2020, la plateforme a commencé à prendre forme, s’intégrant dans les écosystèmes de données et en ligne d’Ubisoft, elle a soutenu ses premiers clients et a bien performé. À ce moment-là, des outils ML open-source étaient facilement disponibles, et les fournisseurs de cloud n’étaient pas aussi axés sur les solutions ML qu’ils le sont aujourd’hui, donc construire une solution personnalisée sur AWS, notre principal fournisseur de cloud pour cette partie du groupe, était logique.
Les besoins de nos clients et la vision de l’entreprise ont continué à piloter l’évolution de notre plateforme ML au-delà de 2020. Cela s’est produit malgré la disponibilité de nouvelles solutions MLOps et versions de fournisseurs de cloud, telles que l’édition 2020 d’AWS SageMaker, et des couches tierces comme Databricks, qui ont relevé la barre pour les plateformes ML (nous avions commencé à faire un benchmark à ce moment-là). Mi-2023, dans l’ère post-COVID, l’entreprise est entrée dans une phase d’optimisation des coûts, qui incluait des fusions d’équipes et une restructuration de toute l’organisation des données. La stratégie de plateforme de données a également été réévaluée, passant d’un modèle “construire” à “acheter” pour soutenir plus efficacement les besoins d’analyse et de machine learning de l’entreprise. Par conséquent, nous migrons actuellement vers Databricks sur Azure.
Question à 1000000$ : Devrais-je construire ou devrais-je acheter ?
Compte tenu de mon expérience, quelles sont mes réflexions sur l’évolution de la plateforme ML ?
- Du point de vue de l’utilisateur final, la plateforme avait initialement du sens et était un ajout précieux au portefeuille d’outils de données/IA. Mais à mesure que les standards évoluaient rapidement, suivre le rythme avec des ressources humaines limitées est devenu difficile.
- Du point de vue d’un ancien membre de l’équipe de plateforme ML, cette nouvelle configuration peut sembler moins intéressante et stimulante. Bien qu’il puisse être difficile à accepter, le rôle implique principalement l’intégration de l’outil (un autre type de défi comme le dira la direction)

Cependant, je pense que plus généralement, la décision d’aller dans une direction ou une autre peut être déterminée en posant une question très simple :
- Combien de temps pouvez-vous attendre pour déployer de nouvelles fonctionnalités avec les ressources allouées ?
- Quel est votre coût de maintenance du produit après le déploiement ?
Les entreprises affirment souvent qu’une stratégie est meilleure que l’autre, comme par exemple David Heinemeier Hansson a partagé ses expériences pour quitter l’infrastructure basée sur le cloud, ou le site web de Databricks présente des histoires de clients mettant en avant les avantages de leur produit. En fin de compte, la décision finale se résume au temps, à l’argent et aux décisions de la haute direction, mais j’aimerais également souligner quelques éléments qui devraient être pesés dans votre décision :
- Lors de la décision de construire ou d’acheter des solutions, il est important de considérer l’expérience et les intérêts de votre équipe. Cependant, soyez conscient des conflits d’intérêts potentiels qui pourraient influencer leur décision. De plus, évaluez la volonté générale de votre équipe d’expérimenter de nouvelles solutions.
- La robustesse des solutions construites et achetées dépend de faire des hypothèses claires sur les packages ou fournisseurs potentiels. Construire des benchmarks appropriés est essentiel. En 2020, nous avons effectué cet exercice pour évaluer les fournisseurs potentiels pour notre plateforme ML.
Au-delà de la décision de construire ou d’acheter, il y a quelque chose d’important qui commence par un M que les gens oublient de vous présenter.
Vous savez qu’il y a toujours la migration
Ce n’est pas ma citation, mais un ancien VP de données l’a dit un jour—et c’est absolument vrai. Pour illustrer, voici une diapositive de mon intervention au DEML Summit 2024.
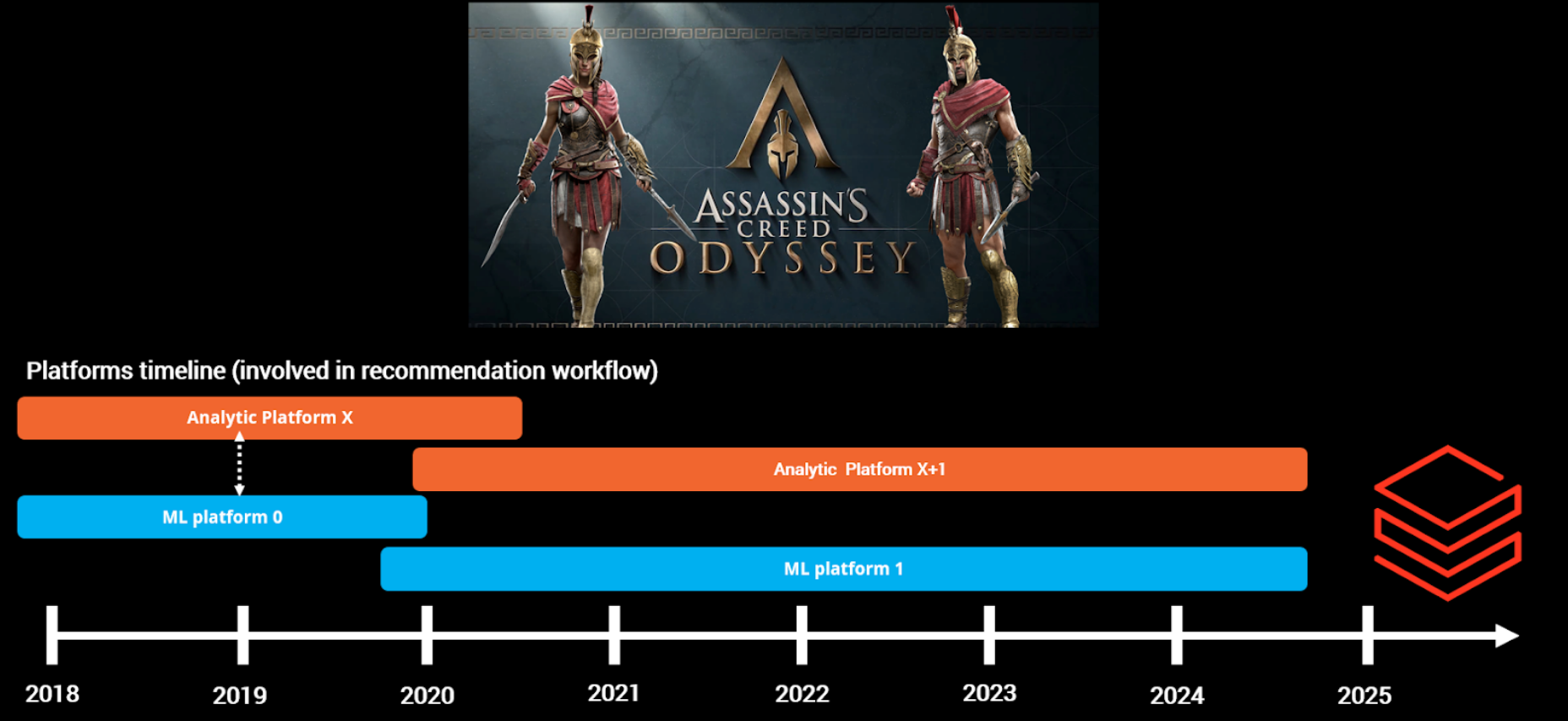
Le côté analytique et ML a vu beaucoup de migrations au cours des six dernières années, suivant généralement un cycle de 2-5 ans car cela semble être une norme attendue dans l’industrie (pas de source appropriée). Bien que les améliorations technologiques et de coût justifient généralement ces migrations, elles peuvent quand même être risquées. Cependant, d’après mon expérience en tant qu’utilisateur final, elles ont généralement été réussies.
Bien que ceux qui sont en charge puissent avoir des histoires plus intéressantes à raconter sur le processus de migration, de mon point de vue alors que j’aide les gens à embarquer de nouveaux utilisateurs sur la plateforme ML et migre quelques-uns de mes projets sur les nouvelles plateformes, il y a quelques points qui peuvent être pertinents à avoir en tête :
- Crédit à la fondation existante : Reconnaissez le travail qui a déjà été fait, même s’il n’était pas parfait.
- Sandbox : Développez un environnement où les utilisateurs peuvent expérimenter avec une version d’essai du nouvel outil en utilisant des données d’exemple.
- Projet test : Assurez-vous d’avoir un projet test pour essayer l’ensemble du processus, dans notre cas, nous avons utilisé notre jeu qui n’est pas trop petit mais pas trop grand non plus
- Valeur du projet : Évaluez la valeur de migrer certains projets en déterminant s’ils sont toujours pertinents (j’élaborerai plus tard)
- Réunions d’embarquement : De brèves réunions d’une heure étalées sur 1 ou 2 semaines sont efficaces pour introduire et embarquer de nouveaux utilisateurs sur des aspects spécifiques du système.
- Canaux de communication : Établissez un canal de communication direct pour les questions, pas quelque chose de partagé entre les personnes mais dédié à un projet spécifique
- Migration locale d’abord : Commencez par les collègues locaux d’abord—il est toujours plus facile de soutenir les personnes dans le même fuseau horaire avant de s’attaquer aux migrations mondiales.
En plus de ces informations, il y a quelque chose qui peut simplifier l’intégration d’un nouvel outil dans votre stack technique.
Construire ou acheter peu importe, encapsulez-le
De mon point de vue, être capable de créer un logiciel qui s’intègre avec les outils d’entreprise existants est une stratégie intelligente. Comme illustré par mon paradoxe construire-versus-acheter, les circonstances peuvent changer et cela peut arriver rapidement. Cependant, si ce wrapper logiciel privilégie la fonctionnalité plutôt que le fournisseur de cloud spécifique ou l’outil avec lequel il interagit, il peut simplifier les tests et les transitions futures. Voici un exemple rapide pour démontrer ce point.
Durant mon temps dans l’équipe de plateforme ML, j’ai travaillé sur un module de suivi ML pour le wrapper python de la plateforme ML. Cette solution était conçue pour être compatible avec les exigences techniques de plusieurs équipes utilisant divers outils dans l’entreprise, comme MLflow et ClearML. Le focus principal du module était sur la fonctionnalité d’une solution de suivi ML car la plupart des outils ont une hiérarchie similaire comme le serveur de suivi, les métriques d’artéfacts et ainsi de suite, voici une capture d’écran de la documentation.

Bien que la construction de ce wrapper ait été relativement simple pour moi, développer d’autres fonctionnalités qui sont plus étroitement intégrées avec les données par exemple peut être considérablement plus difficile car vous devez trouver le bon format pour que ce wrapper soit aussi pérenne que possible.
C’est tout pour mon expérience de stack technique. Travailler avec les données et l’IA n’est pas gratuit, et les décisions financières devraient être considérées au niveau du projet. Regardons maintenant comment les décisions sont prises à mon niveau pour soit aider un projet à évoluer soit décider de l’arrêter.
Money, money, money, Must be funny, In the rich man’s world
Alors que la technologie évolue rapidement et que les coûts peuvent augmenter rapidement, les questions autour du coût et du retour sur investissement (RoI) deviennent de plus en plus critiques lors du travail sur des projets, il y a donc différents aspects à cette question du RoI.
Évaluation continue
J’ai déployé des projets de production chez Ubisoft, principalement des systèmes de recommandation en jeu. Ces projets ont dû s’adapter aux plateformes changeantes et fonctionnent encore aujourd’hui. Cependant, il est important d’évaluer la pertinence continue de ces systèmes au fil du temps et pour ce faire votre meilleur ami est le test AB.
Je crois qu’il est crucial d’avoir toujours un groupe de contrôle qui ne reçoit pas de sortie de votre système (dans ce cas, le système de recommandation). Ce groupe devrait plutôt recevoir des fallbacks par défaut, soit de votre client d’application (une liste par défaut) soit du système lui-même. J’ai écrit un court article à ce sujet si vous êtes intéressé à en savoir plus sur ma perspective sur les fallbacks pour les systèmes de recommandation.
Lors d’un test AB, quelque chose de crucial est d’identifier vos indicateurs de performance clés (KPI) que vous aimeriez utiliser pour comparer les populations. Bien que vos KPI devraient principalement être liés aux dépenses ou aux finances, qui peuvent ensuite être comparés à vos coûts d’exploitation (incluant l’infrastructure et les ressources humaines), il est également pratique de suivre certaines métriques non monétaires. Par exemple, bien que la plupart de mes projets puissent être liés aux dépenses, je suis également des métriques d’engagement plus générales, telles que les clics et les visites car cela peut aider à concevoir des décisions UI/UX.
La fonctionnalité de plateforme ML introduite début 2023 pour analyser les coûts de projets individuels nous permet maintenant d’évaluer correctement le RoI des projets et de répondre à la question de pertinence du projet soulevée précédemment. Nous avons effectué un test A/B de 3 mois pour comparer l’impact des recommandations personnalisées (utilisant un ranker classique) versus une solution de fallback présentant les éléments les plus populaires des 7 derniers jours, dans différents projets de mon portefeuille et voici la comparaison globale dans un graphique.

Le résultat des projets peut varier considérablement comme vous pouvez le voir ; certains projets s’avèrent être très précieux, tandis que d’autres peuvent seulement atteindre le seuil de rentabilité, et pour certains peuvent même nécessiter d’être terminés. La capacité de suivre les coûts est essentielle lors du déploiement de toute application de données ou d’IA.
Mais il y a toujours les questions en suspens, combien de retour devrait justifier de continuer dans une direction spécifique.
Combien de retour est suffisant ?
En revenant à la section précédente, nous avons utilisé une règle simple pour déterminer quels projets devraient être coupés : tout projet qui ne générait pas deux fois son coût était basculé en mode fallback
D’où venait ce chiffre ? Nous avons fait une estimation éclairée. 🙂 (ou comme on dit en France, ça sortait de notre chapeau)

Je n’étais pas sûr d’avoir plus à ajouter, mais il y a quelques mois, je suis tombé sur une étude IDC (sponsorisée par Microsoft) qui circulait au travail. Produite en 2023, l’étude a interrogé plus de 2 000 “décideurs IA” sur leurs expériences dans la construction de projets IA. Voici les principales conclusions :
- Le retour sur investissement moyen en IA est de 3,5 dollars pour 1 dollar investi. Notamment, les 5% d’entreprises les plus performantes investissant dans l’IA ont vu un retour de 8 dollars pour chaque dollar investi.
- Les déploiements IA se produisent au rythme suivant, avec 92% prenant un an ou moins à implémenter, et 40% des entreprises déployant l’IA en moins de 6 mois.
- Le retour sur investissement moyen commence à apparaître dans les 14 premiers mois.
Pour moi, c’est LE point clé à retenir : Les projets IA génèrent en moyenne un retour de 3,5$ pour chaque dollar investi. Cependant, il y a quelques mises en garde :
- Nous manquons l’écart-type pour les résultats. Sans cela, une moyenne seule ne fournit pas une image complète.
- Nous ne connaissons pas le type d’applications IA analysées. Par exemple, le temps de déploiement rapporté semble extrêmement long comparé à ce que nous vivons typiquement lors du déploiement d’un projet (au moins pour le composant IA lui-même).
Bien que 3,5x soit légèrement plus élevé que notre facteur actuel de 2, ce n’est pas une différence extrême. Cela dit, utiliser un tel multiplicateur devrait être fait avec prudence. Il est facile de quantifier les retours financiers directs (par exemple, 1$ dépensé vs 1$ gagné), mais les impacts indirects (comme une solution de reporting utilisée pour prendre des décisions) sont plus difficiles à mesurer. Une méthodologie appropriée ou une approche de benchmarking devrait être établie avant de commencer un projet.
Pour conclure cette section, je veux également souligner une réalité dans un projet IA.
Vous n’avez pas encore besoin d’un plus gros bateau IA
J’ai volé et modifié un titre d’article de Jacopo Tagliabue, qui était plus autour de la stack technique pour opérer un système de recommandation en production, mais j’ai trouvé qu’il pouvait aider à définir cette section.
Dans le domaine de l’IA, de nouveaux modèles avec des performances améliorées sont constamment publiés. Bien qu’il soit vrai que ces avancées peuvent rapidement rendre les modèles existants obsolètes, la réalité est que les gains de performance deviennent de plus en plus marginaux. Pendant ce temps, les coûts associés à l’entraînement et au service de ces modèles augmentent exponentiellement.
Pour soutenir cette affirmation, je me référerai à un article de Gael Varoquaux, Alexandra Sasha Luccioni, et Meredith Whittaker de l’année dernière appelé “The Hype, Sustainability, and the Price of the Bigger-is-Better Paradigm in AI.” L’article compare différents éléments de modèles du temps d’entraînement et de la taille du modèle par exemple

coût d’inférence et consommation d’énergie

La méthodologie derrière ces figures pourrait être questionnée je suppose, mais elles soulignent quand même que nous atteignons une limite de performance. Si nous nous concentrons uniquement sur les nouveaux développements, le retour sur investissement des projets diminuera en raison de coûts de fonctionnement plus élevés pour un gain marginal (mais il faut le mesurer car à un moment donné le modèle peut être plus performant à exécuter).
Par conséquent, les data scientists et les ingénieurs en machine learning devraient être questionnés sur le bénéfice global et la valeur de toute demande d’infrastructure et de ressources supplémentaires, pour exécuter de nouveaux modèles pour un projet spécifique.
Arrêtons de discuter d’argent mais plus du facteur humain dans tout cela.
Facteur humain
Les domaines des données et de l’IA ont tendance à attirer les introvertis, donc la touche humaine peut ne pas être un élément instinctif dans une expérience de travail mais croyez-moi c’est essentiel.
Avertissements :
- La section suivante sera au format à puces et ne reflète que mes expériences personnelles travaillant pour ces entreprises.
- Désolé à l’avance pour les références à The Office à venir dans l’illustration – je suis actuellement en train de le regarder à nouveau.
Management

Dans mes dix ans en tant que data scientist, je n’ai jamais eu de rôle de management formel—à part encadrer des stagiaires et accueillir de nouveaux membres d’équipe. Et honnêtement, je suis d’accord avec ça. Je crois que gérer les gens est une compétence unique, surtout avec les changements apportés par la pandémie COVID et le passage au travail à distance/hybride/bureau, que nous aimons ou non.
Mes diverses expériences professionnelles m’ont exposé à des styles de management variés, qui m’ont donné des insights précieux du point de vue d’un subordonné :
- 1:1 : Des discussions régulières avec votre manager sont cruciales pour votre croissance. Ces réunions individuelles devraient être dédiées à votre développement, alors venez préparé. Le format peut varier (par exemple, 30 minutes bi-hebdomadaire, 45 minutes hebdomadaire, en personne ou à distance) mais assurez-vous qu’elles sont focalisées et précieuses. Évitez les distractions ; c’est votre temps pour grandir.
- Management accessible : Il est bénéfique d’avoir des discussions impromptu avec la haute direction. J’ai trouvé que mes managers jusqu’au niveau +2 sont accessibles dans chaque entreprise pour laquelle j’ai travaillé, donc saisir l’opportunité de discuter avec eux est toujours une bonne idée.
- Projet ≠ Humain : Les gestionnaires de projet et les gestionnaires de personnes nécessitent des compétences différentes ; vous ne pouvez pas gérer les gens de la même façon que vous gérez un projet.
- Feedback 360 : Le processus de feedback 360 chez Ubisoft est vraiment bon. Il a fourni une opportunité d’évaluer l’année passée et de planifier l’avenir, ainsi que d’évaluer les collègues et les managers.
- Vérification de santé mentale : Vérifiez régulièrement que vous avez une feuille de route claire et questionnez où vous allez (de manière constructive) si vous ne l’avez pas.
- Mise à jour de la direction : Les mises à jour bihebdomadaires et les rapports de statut trimestriels de la haute direction sont un bon moyen de rester informé sur la direction du groupe (je déteste quand la haute direction est silencieuse, c’est le pire)
- Malchance dans une réorg : Si vous vous retrouvez avec un manager qui n’a pas de plan clair pour vous (possiblement en raison d’une réorganisation), il est crucial d’être attentif à tous les points mentionnés précédemment.
Je crois que je deviendrai éventuellement un manager, mais je ne suis pas pressé. Quand le moment viendra, j’utiliserai certainement des ressources en ligne telles que le dépôt GitHub de Benjamin Rogojan, qui contient une richesse de contenu compilé sur le sujet.
Cependant, au-delà d’être simplement géré, j’ai travaillé pour de grandes entreprises françaises avec plus de 10 000 employés dans le monde. Par conséquent, il est crucial de considérer le facteur humain non seulement au niveau individuel mais aussi d’un point de vue plus large du groupe.
Faire partie d’un groupe

L’interaction au sein d’un groupe peut se produire à différents niveaux, comme au sein des équipes ou des divisions. Malgré ces différents niveaux, le comportement global du groupe devrait rester cohérent. Voici quelques points clés à retenir :
- Soyez gentil : Donnez du feedback de la manière dont vous aimeriez le recevoir, vous allez faire des évaluations pour vous ou vos pairs, alors soyons constructifs
- Partager c’est prendre soin : Partagez votre travail et vos connaissances ! Ne laissez pas vos contributions passer inaperçues !
- Groupes de partage de connaissances : Il est essentiel de rejoindre et d’être actif dans des clubs de lecture ou d’autres groupes de partage de connaissances dans votre entreprise pour favoriser l’échange interne et la collaboration.
- Message adapté : Adaptez votre communication à votre audience. Vous collaborerez avec des experts techniques (DS/MLE) et d’autres programmeurs, ainsi qu’avec des parties prenantes moins techniques, plus orientées business. Adaptez toujours votre style de présentation et gardez les choses aussi simples que possible.
- Soyez un ambassadeur pour votre entreprise : Cherchez toujours des opportunités de présenter votre travail à l’extérieur. Bien que cela puisse sembler intimidant, la plupart des grandes entreprises ont un processus pour approuver les présentations externes, et les restrictions sont souvent moins compliquées que vous pourriez le penser. Je me suis également impliqué dans l’organisation de meetups, un excellent moyen de gagner en visibilité,
- Activités de team building et événements : Je sais que parfois cela peut être difficile mais ces opportunités sont excellentes pour le networking et construire des relations qui pourraient bénéficier aux futurs projets.
- Soyez le gars du stand-up : Prendre en charge des tâches pas sexy démontre la fiabilité, le travail d’équipe et le dévouement à un objectif plus large.
- Soyez un pâtissier : Les gens aiment manger des pâtisseries faites maison, croyez-moi
D’accord, je suppose que c’était la dernière section sur le travail, et parlons maintenant du temps libre.
Au-delà du 9 à 5
Cette prochaine section pourrait être un peu controversée, du moins c’était un sujet sensible pour certains de mes collègues. Elle contient quelques suggestions pour des activités après le travail (mais toujours liées aux données et à l’IA)
Projets parallèles de codage Depuis l’obtention de mon diplôme, j’ai passé une partie de mon temps libre sur des projets personnels. Au début, je me suis concentré sur le développement de compétences pour améliorer mes perspectives d’emploi en 2014. Bien que j’aie eu une compréhension de base de Scilab et Matlab, j’ai priorisé l’apprentissage de Python au début de ma recherche d’emploi en raison de sa demande dans l’industrie

L’apprentissage continu est la clé de la croissance, et les projets parallèles peuvent aider à combler le fossé entre ce que vous apprenez au travail et ce que vous devez savoir. Ils vous permettent d’apprendre à votre propre rythme, sans la pression d’heures de travail supplémentaires. Il est important de documenter vos progrès, en vous concentrant non seulement sur le code, mais sur l’ensemble du projet.
Je comprends que personne ne veut faire du travail supplémentaire pendant son temps libre—cela peut ressembler à plus de travail. Cependant, je crois que les projets parallèles contribuent à la croissance personnelle et peuvent même améliorer vos tâches quotidiennes. En fin de compte, vous travaillez pour vous-même, à votre propre rythme.
Le projet parallèle idéal devrait s’aligner avec vos intérêts personnels et vous enseigner de nouvelles compétences. Évitez de travailler sur des projets de base qui se trouvent couramment dans les portfolios de développeurs ou les cours de data science. Par exemple, récemment j’ai travaillé sur des projets que j’ai connectés à mon intérêt pour le jeu vidéo Marvel Snap (1,2) ou trouver de bons films à regarder (1,2). La plupart du temps aussi, vous devrez également construire un pipeline de données pour collecter certaines données donc c’est aussi une bonne pratique en général.
Enfin, participer à des compétitions Kaggle et gérer des datasets peut être un moyen précieux de développer de nouvelles compétences, même s’ils peuvent ne pas être représentatifs de la plupart des travaux effectués par les data scientists et les ingénieurs en machine learning. S’engager avec des communautés actives comme Kaggle peut fournir des expériences d’apprentissage précieuses.
Construire une présence en ligne et locale
L’émergence récente de créateurs de contenu dans le domaine des données et de l’IA est évidente sur des plateformes comme LinkedIn et YouTube. De nombreux professionnels dans mon domaine deviennent de plus en plus visibles, contribuant à cette tendance croissante donc créer une présence en ligne est un bon atout.

J’utilise principalement mon blog et les réseaux sociaux (par exemple, LinkedIn, Reddit, et plus récemment, BlueSky) pour maintenir une présence en ligne.
Bien que les réseaux sociaux soient utilisés pour suivre les tendances, le focus de mon travail est sur mon blog, que j’ai commencé à la suggestion d’un ancien collègue d’EDF au Royaume-Uni (coucou Alex Nicol). Mon blog est l’endroit où je partage certains de mes projets parallèles et insights de l’industrie, et il est facilement déployé avec le framework Jekyll.
Je ne poursuis pas souvent les tendances ou le buzz en ligne (pas de salaire ou de post [nom de technologie] est mort pour moi). Au lieu de cela, je me concentre sur le traitement de questions ou de pensées que j’ai eues précédemment (écrire pour votre moi passé). Par exemple, j’ai écrit un article sur la factorisation matricielle parce que c’est un sujet récurrent dans mon travail, et j’aurais aimé avoir une telle ressource quand j’ai commencé à travailler sur les systèmes de recommandation.
J’ai commencé à m’engager avec les communautés locales à Montréal en m’impliquant avec divers groupes de meetup il y a deux ans. Établir une présence locale a été un objectif pour moi, et je crois que m’engager avec ma communauté tech locale sera précieux à long terme.
Et après ?
En 2013, je n’aurais jamais deviné que je travaillerais dans les données et l’IA pour Ubisoft dix ans plus tard. Mon poste actuel de data scientist implique un mélange de logiciel, d’ingénierie de données, d’analyse de données, de machine learning et de gestion de projet. J’apprécie la variété de mon travail et la chance d’appliquer mes compétences dans différents domaines et industries.
J’aime vraiment concevoir et livrer des systèmes de données/IA complets et prendre la responsabilité de leur évolution. Je trouve particulièrement passionnant de travailler sur des fonctionnalités de personnalisation, surtout compte tenu des avancées récentes dans ce domaine. Par exemple, la recherche de mes collègues français sur la création de personnages intelligents avec des LLM ou le travail de Spotify sur le mélange de personnalisation et d’IA générative, démontrent que c’est un excellent moment pour travailler dans l’industrie de l’IA.
Et quel est mon plan pour les 10 prochaines années ? Bon timing, c’était le moment de l’évaluation au travail il y a quelques semaines donc voici ma section comment vous voyez-vous dans le futur ? Aperçu très large de mon plan de carrière sur 10 ans
- Court terme (1-3 ans) : Continuer à être un data scientist MLE pratique pour livrer des produits de données et ML
- Moyen terme (3-7 ans) : Diriger une équipe technique pour opérer des produits ML (et de données)
- Long terme (7-10 ans) : Devenir une sorte de responsable, directeur, CXO, VP autour des données et de l’IA
Mais si nous nous concentrons davantage sur le court terme, voici les principales tâches que j’aimerais faire dans mon travail quotidien
- Collaborer avec les équipes Données, Design, Gestion de produit, Production et Ingénierie pour explorer les opportunités IA pour transformer la production de jeux.
- Concevoir et développer des systèmes de données/IA pour améliorer l’expérience utilisateur.
- Collaborer avec les ingénieurs pour déployer des solutions.
- Collaborer étroitement avec le Design pour innover et intégrer des solutions de données/IA pour augmenter le flux de travail de conception de l’application.
- Rechercher et prototyper des technologies IA pour repousser les limites
- Améliorer la littératie données/IA de l’entreprise.
- Contribuer en tant que membre clé à déterminer la vision et la stratégie pour les données/IA.
Au-delà des tâches sérieuses listées ci-dessus et de ce que je fais actuellement, je peux explorer des activités parallèles comme le conseil ou l’enseignement car je pense que je commence à avoir une expérience pertinente qui mérite d’être partagée au-delà de mon 9 à 5 (j’ai commencé à donner quelques interventions pour certaines formations mlops). Je pense également à créer du contenu YouTube/Twitch basé sur mes projets parallèles ; je suis inspiré par le travail d’Andrej Karpathy et j’ai déjà commencé à créer des podcasts générés par IA à partir de quelques articles sur Spotify #TheOddDataCast, donc on verra comment ça se passe.
J’espère que vous avez trouvé cela intéressant et informatif. Je sais que j’ai couvert beaucoup de choses, et ce n’était peut-être pas parfaitement clair. Cela déclenchera probablement du contenu supplémentaire à l’avenir, donc restez à l’écoute !
Au-delà de cet article, j’aime discuter de données, d’IA et de conception de systèmes—comment les projets sont construits, où ils réussissent et où ils peinent. Si vous voulez échanger des idées, remettre en question des hypothèses, ou parler de vos propres projets, n’hésitez pas à me contacter. Je suis toujours ouvert à une bonne conversation.
Références
- Hype Cycle for Artificial Intelligence — gartner.com
- Thoughtworks Technology Radar — thoughtworks.com
- Navigating the MLOps Landscape (Part 3) — ljvmiranda921.github.io
- Règles du Machine Learning — Règle 1 — google.com
- Data Mesh : Delivering Data-Driven Value at Scale — oreilly.com
- Uber Michelangelo Machine Learning Platform — uber.com
- The Big Cloud Exit FAQ — hey.com
- Databricks Customer Stories — Databricks
- Documentation Sphinx — sphinx-doc.org
- New Study Validates the Business Value and Opportunity of AI — microsoft.com
- You Do Not Need a Bigger Boat — arXiv
- The Hype, Sustainability, and the Price of the Bigger-is-Better Paradigm in AI — arXiv
- Data Team Handbook — GitHub
- Marvel Snap Decks and Cards Dataset — Kaggle
- Comment le nouveau prototype d’IA générative d’Ubisoft change le récit pour les PNJ — ubisoft.com
- Contextualized Recommendations Through Personalized Narratives Using LLMs — research.atspotify.com