
This article will dig into a Python package about the recommender system on my radar. The package is defined as a Python scikit package to build and analyze recommender systems built on explicit ratings where the user explicitly rank an item, for example, a thumb up on Netflix (like in the following picture with the Formula 1 tv-show on my account).
The article will be focused on the main features of the package that I will apply to the dataset sens critique that I am building for a few months for my experimentation around recommendations (cf previous article)
The Surprise package used for this article is 1.1.1.
Data management
To leverage the Surprise package, you have multiple paths possible:
- Using built-in datasets: the movielens-100k/1m and jester (some jokes dataset) are available
- Or use your dataset, you can load files or a pandas dataframe
The package is flexible and easy to use, but you need to respect some formatting when you manipulate your dataset; the columns of your tabular data need to be ordered like that.
- User
- Item
- Rating
- Timestamp (optional)
This format is very common for a recommender dataset but still good to have that in mind.
For this article, I decided to continue my experiment with the same data sources as in my previous article on the metrics for evaluation, just changing the time frame. Therefore, there is a datapane report on the data used for this experiment.
The idea will be to use all the reviews/ratings I have until the 1st of January 2022 and predict the rating associated with a pair user/item the week after.
For the experiment, I also drag in training set a few fake users that will be some user archetypes (but I will explain them more in detail when needed) to help analyze the models produced during the model exploration.
An essential element is that the data need to be formatted in a Surprise format; there is an illustration of the process for pandas Dataframe.

The format is convenient because it will encode the user and item identifier to fit the needs for the construction of the model in the training (and this encoding will be kept after the computation of the recommendation).
To build this model, let’s first look at what’s in the toolbox of Surprise in terms of algorithms.
Model exploration
In Surprise, most of the algorithms are structured around the recommender systems’ collaborative filtering (CF) approaches; there is a lesson of Stanford on this kind of algorithms that can be used as a good baseline for ML practitioners.
In the package, there are the groups of algorithms available:
- Random
- Baseline
- Matrix factorization
- KNNs
- Slope one
- Co clustering
I will not detail the different models but provide some resources if you are interested in knowing more about them (all the papers behind these groups are here).
Random: This algorithm is pretty simple and gives a random prediction for the rating of a pair user/item based on the distribution of the rating in the training set (that should be normal)
Baseline: In this group of algorithms, there are two algorithms available:
- ALS (Alternating Least Square), which is very popular in collaborative filtering which is a very popular technic to make CF, there is a video that explains the implementation in pyspark (that I am using in my day to day)
- SGD (Stochastic Gradient Descent): Quite of a well-known algorithm in machine learning, but there is a quick refresher just in case.
If you want to learn more about these algorithms, there is more explanation in the article at the source of their implementation.
Matrix factorization: On this group of models, there are 2.5 different algorithms:
- SVD (Single Value Decomposition), this algorithm is a dimensionality reduction technic; here is a good article of Carleton college on the subject. This method has been popularised by the Netflix prize-winning solution of Simon Funk. The .5 is related to the SVD++ version of the SVD that is also detailed in Koren’s article.
- NMF(Non-negative Matrix Factorization): The principle of this algorithm is very similar to the SVD, and the implementation is based on the following articles The Why and How of Nonnegative Matrix Factorization and Stability of Topic Modeling via Matrix Factorization. If you want more details, there is a video explanation.
KNN: For this group of algorithms, the process is a derivate of the k-nearest neighbours algorithm but applies on the rating user, item, and there is a different implementation possible, as we can see on the documentation. This video has a breakdown of the approach behind this group of algorithms.
A critical parameter (if we are going further than the number of neighbours) is the similarity function is also very important.
Slope One & Co-clustering: For these two algorithms are kind of unique but make echoes to the other algorithms in the package, there are more details in the paper behind the implementation:
Finally, on this package, as in the scikit legacy, there is also the possibility to have interesting strategies to train models with:
- Cross-validation iterator: Ability to do Kfolds etc., but I will highlight an iterator called LeaveOneOut that is very smart in the context of building collaborative filtering models (leave on the testing set x rating for a user in the training set)
- Grid search: Grid search to find the parameters
There are plenty of scripts in the GitHub repository to illustrate how to use them.
Now let’s see how the algorithms can fit the dataset of sens critique.
Build a recommender
As mentioned at the beginning of the article, the goal of this experimentation is to build a good ranker of pair user, item in the sens critique; I decided to focus only on three models:
As the model built can estimate the potential explicit rating that a user can give to an item, I decided to focus my parameter search by optimizing the metric rmse. Still, I will also log the training time and the time to compute the testing period. For my exploration and to make it more efficient, I built a quick system with:
- hyperopt to optimize my parameter search
- log my results in mlflow to make my parameter selection after that.
There is a Gist of code to present the process for the NMF
To compare the performance of the models, I decided to use
- the random predictor of the package to make a random rating
- A ConstantScorer will give all the pair user/item the same rating.
There is a representation of the rmse for the selected models and the baselines.
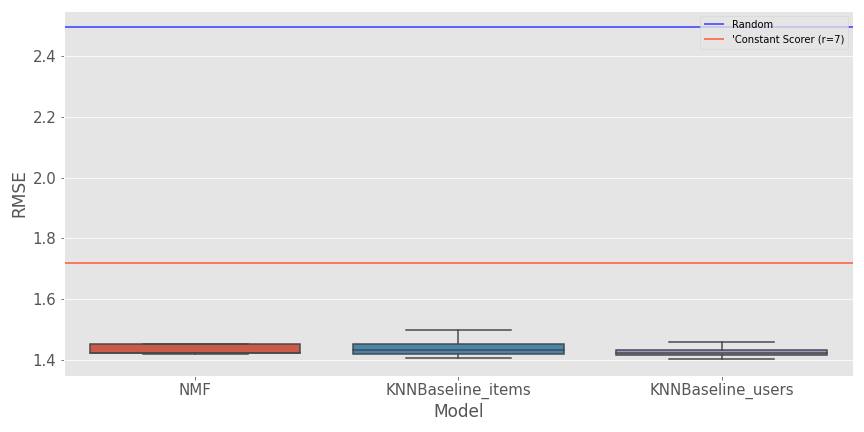
Overall it seems that the 1.4 barrier is hard to beat (on the time and space of search I allocated), and the three algorithms seem to have very close results. The result is not crazy (not having something under an RMSE of 1), but the system learns relationships between user and item compared to the baselines model. In this second graph, there is a comparison of the evaluation time and training time for the different experiments.
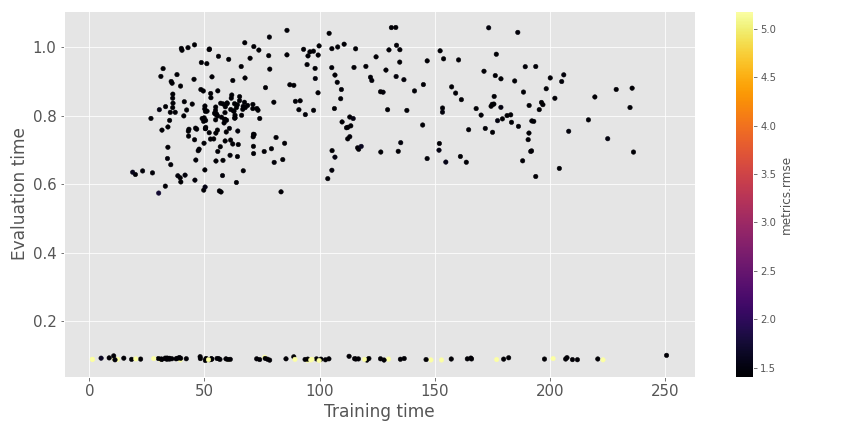
The times are not so long as we can see with our 1 million row training set :).
To better understand the models’ predictions, I decided to take the best model of each algorithm and evaluate how they are working on the archetypes. These archetypes are users that have a specific taste and rank specific items; there are the details on the archetypes: :
- Marvel fanboy: A user that like a lot of movies of the marvel cinematic universe and doesn’t like content from the DC universe

- RPG lover: A user that loves RPG games in general but not too much the other big regular game (like FIFA or call of duty)
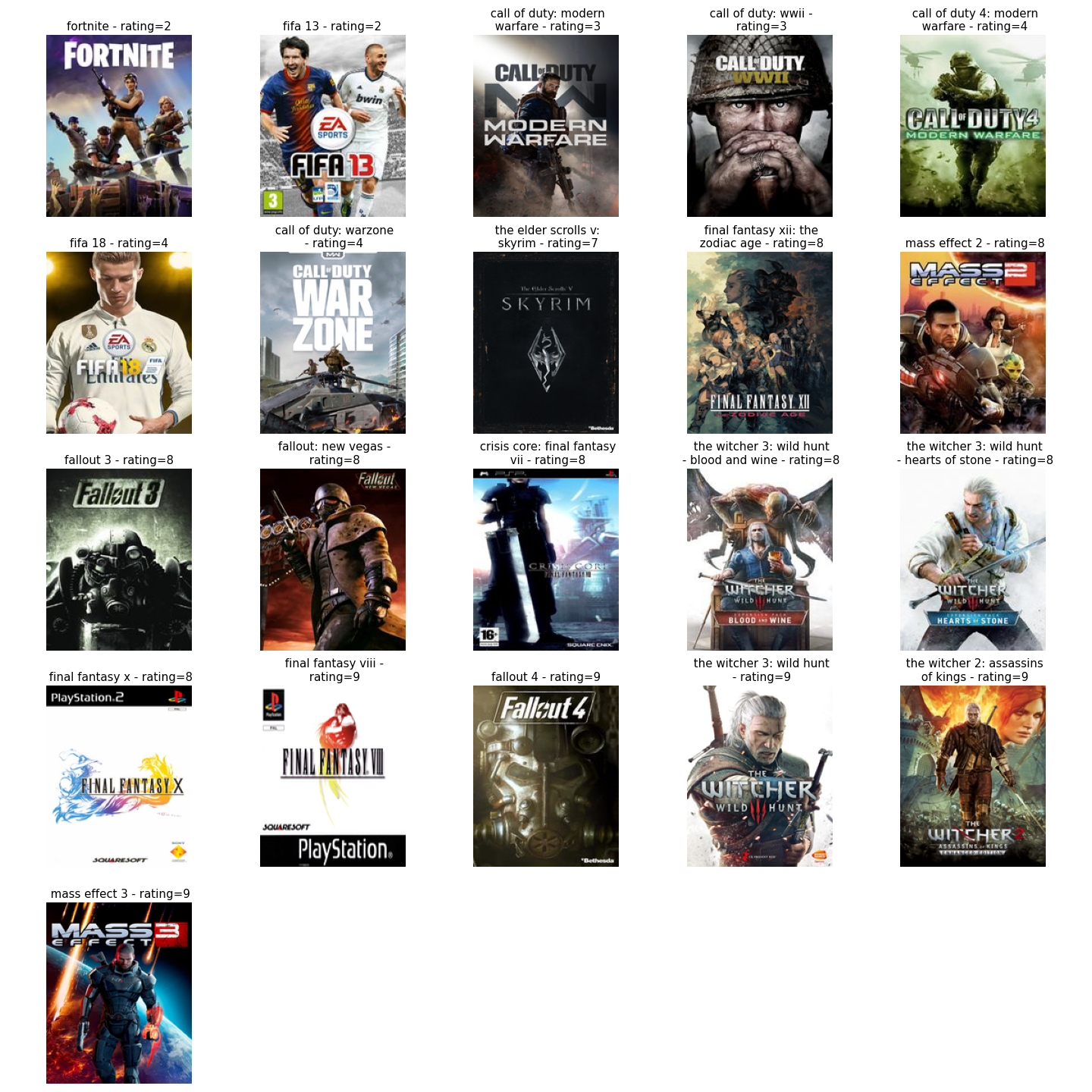
- French connoisseur: User that is loving old french movies, but not the other kind of movies (tried to take movies from the MCU and popular not french movies)

To build recommendations (as a first iteration), the idea now is to rank the catalogue and find the item with the best rating predicted by the model. There is a gist to present the function of computation.
Noithing reallt fancy, I am just using the model computed before with the catalog of items that I am ranking. So now let’s see the recommendations of the NMF for the archetypes.

Very similar for each archetype (except the witcher in the history of the RPG fan). There are recommendations from the KNN baselines (items) for the archetypes.

Once again, very close conclusion than for the NMF … And to conclude, there are recommendations from the KNN baseline (users).

There is a little bit of diversity in this case, but the recommendations don’t make too much sense (except for Chrono trigger for the RPG fan).
The results of these predictions pretty choked me, but I think that it can come from multiple things:
- I optimized the scoring of the pair content user in my hyperparameter search, not trying to optimize recommendation prediction metrics (like hit ratio or NDCG)
- The dataset is very uncommon, I think, for the recommendation world with more content than users, so some biased can come from it.
From this last point, I dug a little bit more into these contents, and I noticed the following details.
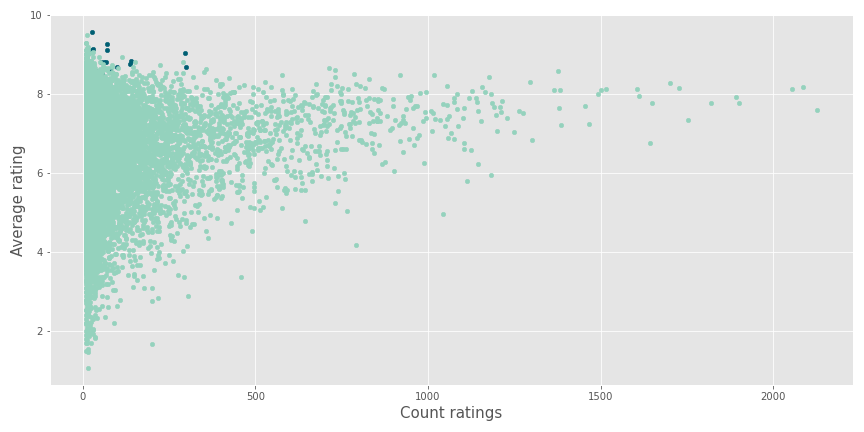
The contents recommended (in dark blue) look like outliers with some reviews and an excellent average rating.
So the computation of recommendations must be reworked (the current method is not scalable and not accurate) and a possible path is the two steps/stages recommender system.
Build a two-step recommender system
This approach is trendy in recommender systems, usually facilitating the computation in an online manner. Eugene Yan makes a great article on the subject.
Let's explore how recsys & search are often split into:
— Eugene Yan (@eugeneyan) June 30, 2021
• Latency-constrained online vs. less-demanding offline environments
• Fast but coarse candidate retrieval vs. slower and more precise ranking
Examples from Alibaba, Facebook, JD, DoorDash, etc.https://t.co/zTsfElLw1z
The idea behind this process is to have two phases during the computation with:
- Retrieval: Find the suitable content (candidates) for the user to be ranked
- Ranker: Rank the candidates
On my last two recsys recaps(2020, 2021), I mentioned some papers around this kind of pipeline that I will encourage you to read also, but they are more advance than the pipeline that I am going to design.
This approach is very efficient in optimizing the computation of recommendations and avoiding the local minima in the dataset.
So to build this process, we need to build a good retriever of candidates, and Surprise with the algorithms using similarity measures (like the KNNs model) are good candidates to do this part. There is the gist of code.
It’s straightforward to extract the nearest neighbours of a user or an item from a model based on the algorithms. To illustrate that, I used the KNN items from before to get the five closest items of the following contents.
- The game Uncharted 2
- The tv show Wandavision
- The movie the dark knight
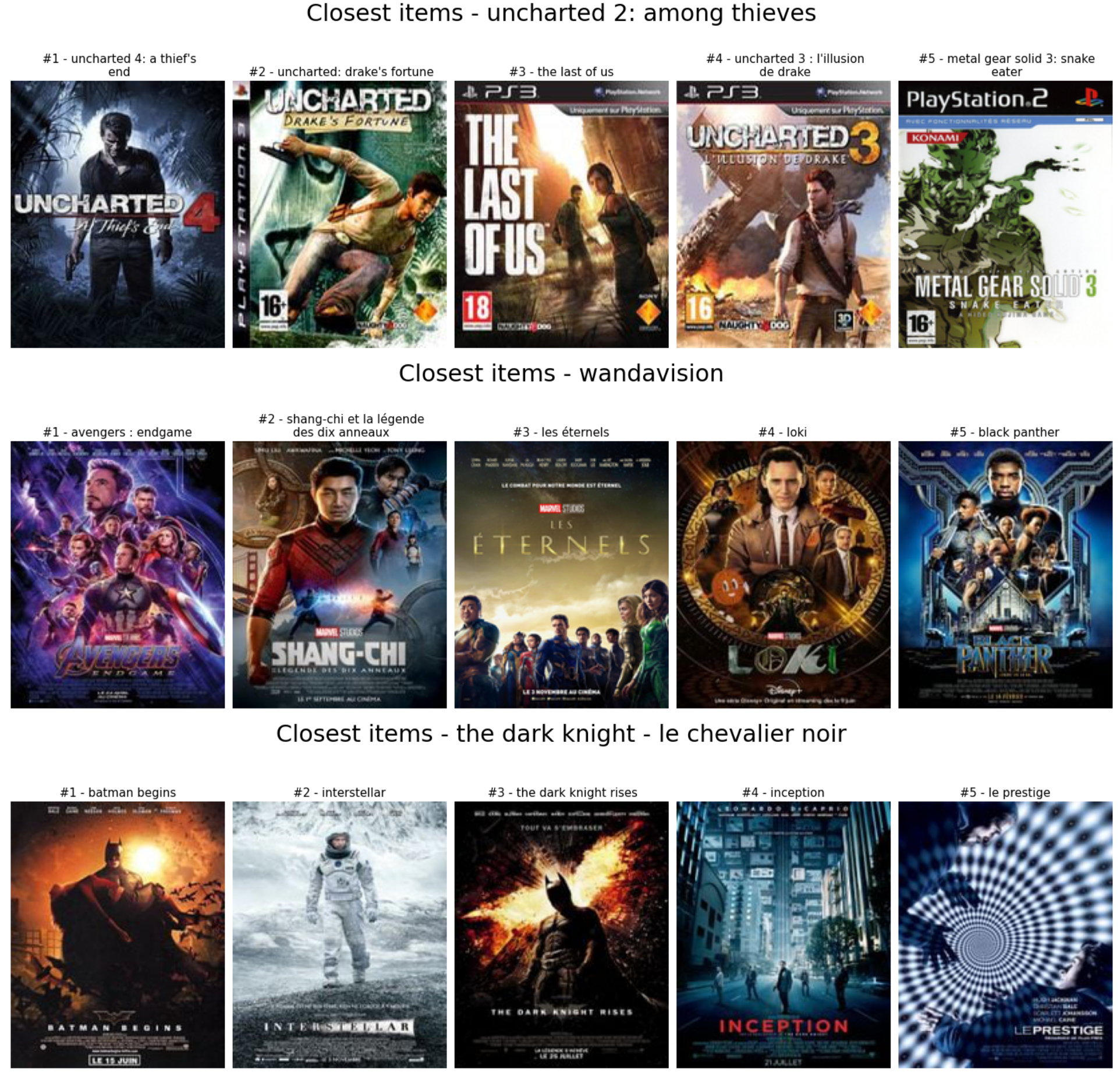
As we can see, the association of the closest items is pretty efficient by:
- Associated to Uncharted 2, the games of the Uncharted’s saga + metal gear solid 3 and the last of us (produced by the same people as Uncharted) that were exclusive games for the PlayStation
- Wandavision is linked to the recent releases of the Marel cinematic universe (movie or tv show)
- The dark knight is associated with Nolan’s Batman trilogy of Nolan plus some other movies of Christopher Nolan
With this retriever, I designed the following recommender system.
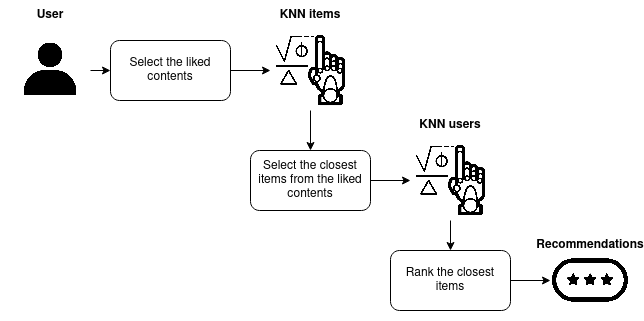
The flow is :
- A retriever that will select the ten closest items of contents liked with a rating superior to 5) by a user (selection of our candidates)
- A ranker: Score the candidate for the user and select the best one as the recommendation
There is the gist for the computation.
There is the output of the recommender system on the archetypes.
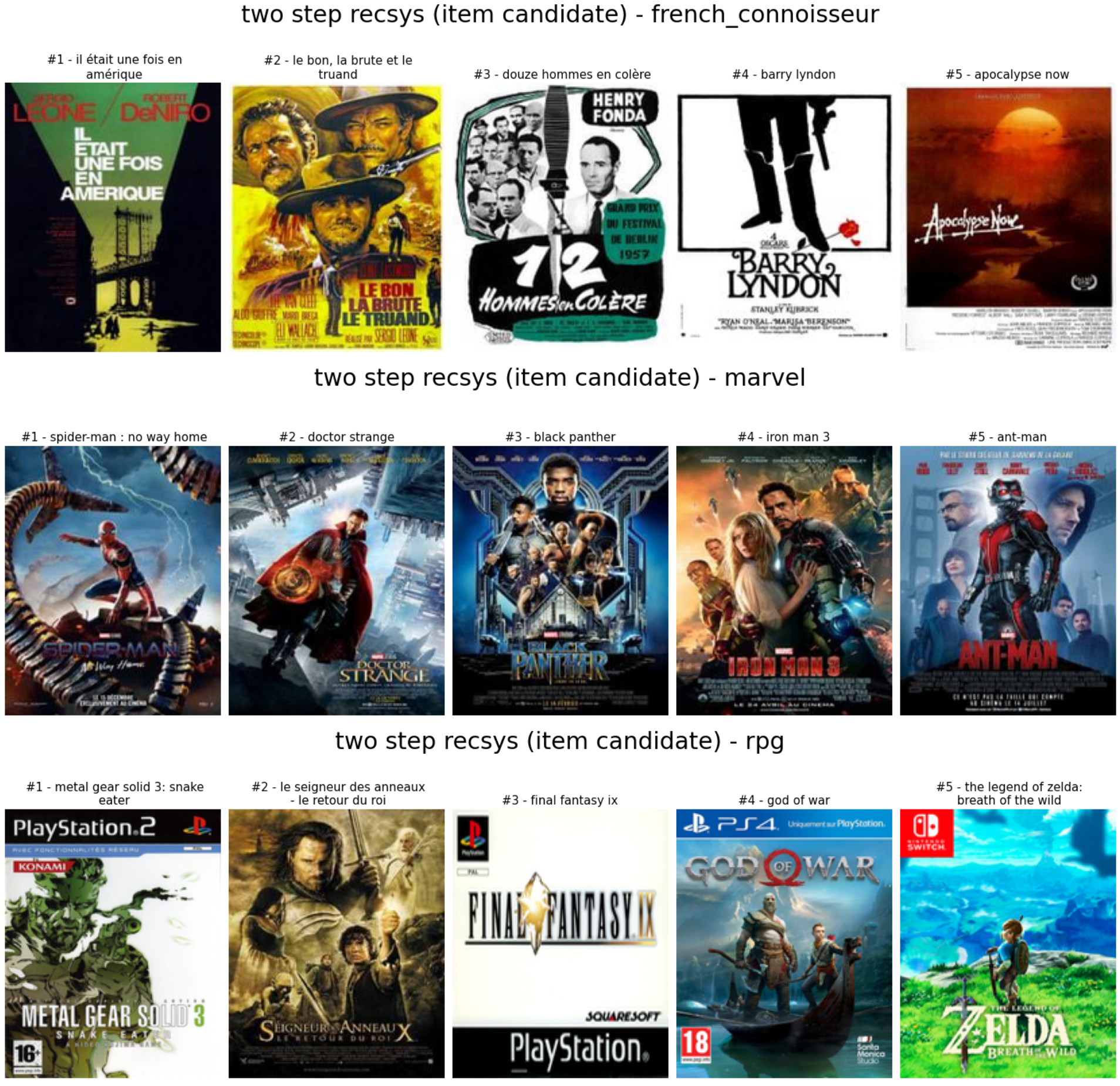
As we can see:
- For the french connoisseur: not so many french movies, but there are a lot of old classic movies from the same period of the various like of the persona
- For marvel: selection of marvel movies, good job
- For the RPG lover: mitigated, I will say good call for the lords of the ring and final fantasy IX, I think, and there is also good video games
Globally the results are not so bad for this last recommender system, but I am thinking that putting more effort into the model exploration could also bring more value.
Conclusion
Overall from that experimentation, I liked working with the Surprise package, easy to use extensive in terms of algorithms and tools for training. There is also an accuracy component that I didn’t use but can be used pretty quickly. I will strongly recommend this package for everybody working in the recommender system area.
The two-stage recommender system is an area of the recommender system that I would like to dig more into because I found it efficient and it seems super adapt for this dataset with a lot of content to predict.







{kind=link}