
Mon manuel Databricks
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
En décembre 2024, nous avons commencé à migrer de nos plateformes d’analyse et ML internes vers Databricks. Après des années de construction et de maintenance de notre propre stack, il est devenu clair qu’adopter une solution moderne et gérée nous aiderait à avancer plus rapidement et à nous concentrer sur la création de valeur.
- Pourquoi Databricks ? – Le contexte de notre changement
- Notes du DataBricklayer – Conseils pratiques sur l’utilisation de la plateforme
- Ressources pour en savoir plus – Cours et matériaux qui m’ont aidé à démarrer
Je prévois de le mettre à jour au fil du temps alors que je découvre de nouvelles fonctionnalités et meilleures pratiques, alors gardez-le dans vos favoris :)
Historique des modifications :
- 24 août 2025 : Première itération de l’article
Pourquoi Databricks ?
Avant de plonger dans Databricks (DBR/DBX), il est utile de fournir un contexte sur ma situation chez Ubisoft avant le changement. J’ai rejoint en 2018, lorsque l’entreprise était fortement motivée à gagner son indépendance et à suivre l’exemple d’Uber, qui promouvait sa plateforme ML interne, Michelangelo. Cela a conduit l’équipe qui m’a embauché à commencer à construire leur propre plateforme, appelée Merlin.
Si vous êtes curieux au sujet de Merlin, je l’ai présenté à PyData MTL en juin 2022. En bref, il a été construit sur plusieurs services AWS (mais pas SageMaker) et s’appuyait sur des outils open-source tels que MLflow.
![]()
La plateforme a apporté de la valeur pendant ses 3-4 premières années, mais en 2022, elle était clairement en retard par rapport aux standards ML modernes. Mon intervention à PyData a marqué ce tournant : une fusion d’équipe était imminente, motivée en partie par l’optimisation des coûts et la consolidation. Ces transitions sont souvent décisives — et pour la plateforme, c’était un moment critique. L’entreprise a décidé d’arrêter de construire des outils en interne et d’adopter plutôt des solutions gérées. C’est à ce moment que Databricks est entré en scène.

Je crois en l’avancement rapide, et Databricks rend cela possible. Dans notre cas, SageMaker aurait pu tout aussi bien fonctionner—j’ai même effectué des expériences en 2020 montrant cela. La vraie question est le coût : Databricks est-il moins cher qu’une équipe interne légère, même si elle avance plus lentement ? Le temps nous le dira. Ce qui est clair, c’est que notre équipe de plateforme ML a construit une base solide qui a donné d’excellents résultats et a ouvert la voie au déploiement de Databricks pour les projets ML.
À partir d’ici, laissez-moi partager quelques hacks, astuces et conseils pour travailler avec Databricks.
Notes du DataBricklayer
Je n’entrerai pas dans les détails de chaque composant de la plateforme ici — cela nécessiterait des articles dédiés. Au lieu de cela, je me concentrerai sur les piliers principaux de la plateforme : données et calcul, codage, et visualisation/machine learning, et les hacks, astuces et conseils que j’ai trouvés liés à eux.
Données et calcul
Créer un volume : Les Volumes ne sont pas bien annoncés sur la plateforme, mais ils sont très utiles. Dans mon cas, je les utilise pour stocker des images, déclencher des flux de jobs lorsqu’un fichier spécifique arrive dans le volume ou simplement stocker des fichiers au format CSV de manière plus persistante. Il n’est pas difficile de créer un volume, mais je voulais partager l’instruction create :
Dans mes projets, qui déploient généralement du code ETL et ML à travers plusieurs environnements et cibles, je trouve utile de pouvoir créer le même volume dans les schémas liés à chaque environnement du projet.
Format Delta : Le format Delta offre de nombreuses fonctionnalités, mais la plus utile est le voyage dans le temps avec les versions de table. Vous pouvez facilement revenir dans le temps en vérifiant la version de la table, ou un horodatage spécifique (qui n’est pas une colonne de la table)
J’utilise cette fonctionnalité pour vérifier l’état des prédictions précédentes pour un pipeline batch sans avoir à maintenir une table d’historique.
Liquid clustering : Au travail, nous avions l’habitude de partitionner certaines de nos grandes tables. Sur Databricks, vous pouvez clusteriser les tables en utilisant Liquid Clustering. Vous pouvez définir la clé de clustering ou laisser la table s’adapter elle-même (avec auto clustering).
J’ai compilé quelques commandes PySpark/SQL dans un gist pour interagir avec les tables liquid-clustered.
Convention de nommage de calcul : Il est utile de définir des conventions de nommage lors de la création de ressources de calcul. Par défaut, Databricks génère des noms basés sur votre nom d’utilisateur et la date de création, mais ceux-ci peuvent être longs et difficiles à lire. J’ai créé ma propre convention, inspirée de ce que nous utilisions sur la plateforme Merlin, et conçu ce schéma.
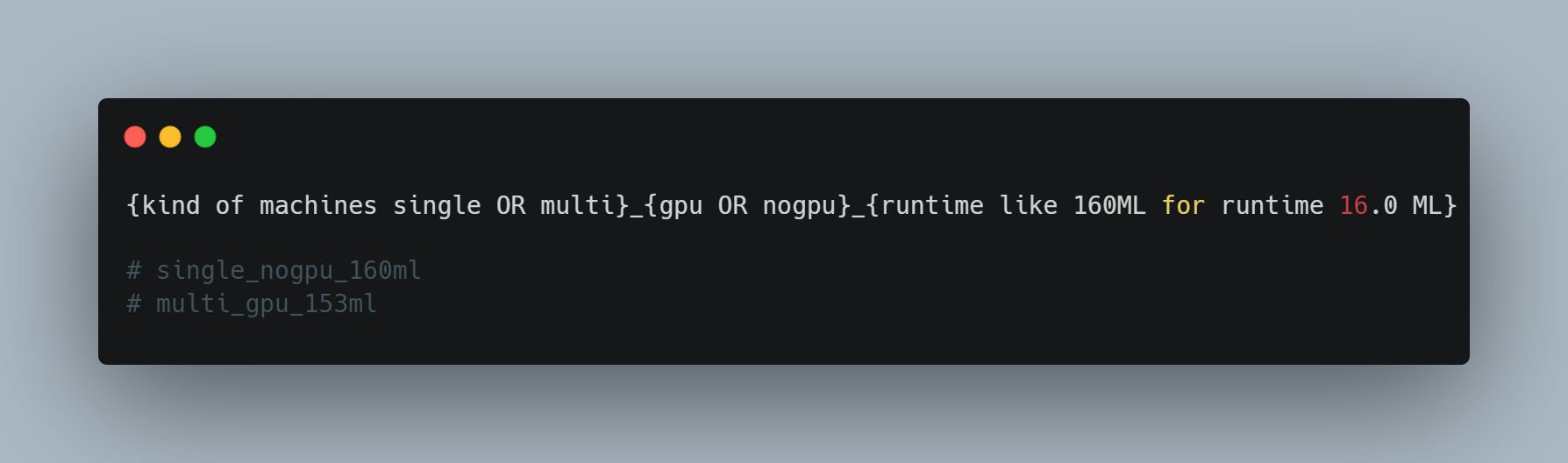
Cela facilite le suivi de vos ressources et le passage de l’une à l’autre, par exemple en utilisant la liste déroulante dans l’interface Web.
Seuil d’inactivité de calcul : Par défaut, Databricks définit le timeout à 20 minutes. D’après mon expérience, un meilleur seuil est de 120 minutes. Cela aide si vous allez à une réunion ou oubliez un job de longue durée, car cela évite d’attendre que la machine redémarre.
N’utilisez pas le runtime le plus récent : Databricks itère rapidement, publiant de nouveaux runtimes avec les dernières versions de Scala et Spark. Cependant, un petit délai dans l’adoption d’un nouveau runtime peut être bénéfique. Par exemple, en janvier 2025, lors de l’exploration de leurs ressources de système de recommandation, j’ai constaté qu’elles étaient basées sur le runtime 14.3 même si la version 16 était sur le point d’être publiée
Code
Sélection de fonctions Dbutils : Databricks Utilities (dbutils) est une bibliothèque intégrée, installée sur toutes les ressources de calcul déployées, avec de nombreuses fonctions pour interagir avec les composants Databricks
L’extrait de code ci-dessous montre mes fonctions préférées pour travailler avec ces derniers temps
Prototyper les jobs sur l’interface web d’abord :
Lors du déploiement d’un job Databricks via un data asset bundle (DAB), le fichier YAML de ressource contient la configuration du job. Ce fichier peut être long et avoir de nombreux niveaux d’indentation.

Mon conseil est de d’abord concevoir ces fichiers en utilisant l’interface Web de Databricks et le bouton “View as Code” en haut à droite. C’est également un moyen efficace d’explorer différents calendriers, déclencheurs, dépendances et mécanismes de condition.
Profil CLI Databricks : Dans mon travail, je dois interagir avec différents workspaces pour différents projets. Par conséquent, je dois m’identifier dans le CLI pour déployer du code dans ces workspaces facilement et changer rapidement. Une approche consiste à créer des profils CLI Databricks en utilisant la commande databricks auth, qui définit des variables localement comme ceci.
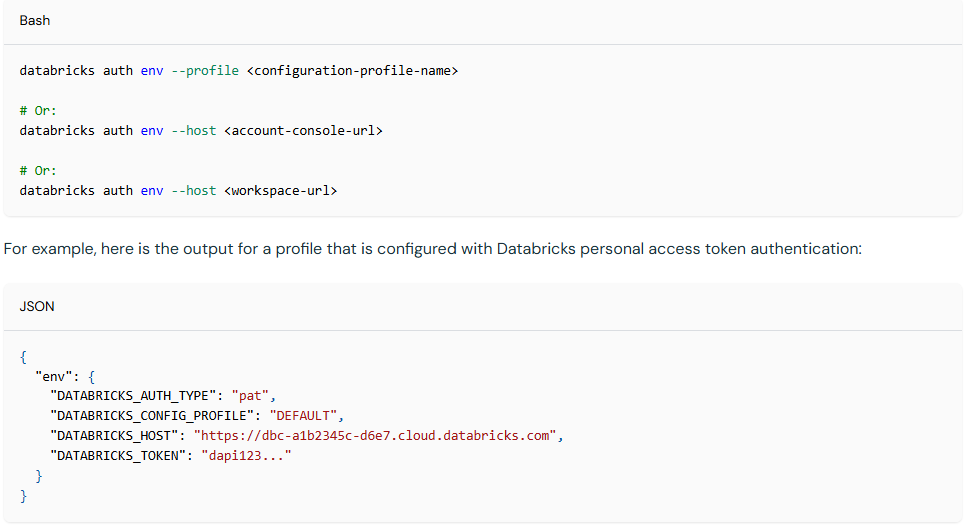
C’est très similaire aux profils AWS d’une certaine manière. La configuration peut être effectuée en quelques secondes, ce qui aide à éviter les maux de tête et garantit que le code est déployé au bon endroit.
Configuration DAB : Lors du déploiement de DAB, au-delà des fichiers de ressources qui contiennent l’organisation du job et le code déployé dans le dossier workflow, il y a aussi le fichier databricks.yml, qui contient la configuration générale du projet.

Dans le fichier databricks.yml, vous pouvez définir diverses variables d’environnement qui peuvent être personnalisées en fonction de l’endroit où le code sera déployé (staging, deploy et/ou dev/uat/prod). Vous pouvez ajuster la variable pour l’emplacement spécifique déployé. Habituellement, j’utilise la variable pour définir :
- Calendrier de job : Vous pourriez retarder ou accélérer certaines exécutions d’environnement de test
- Taille de ressource : Comme les workers min et max, utile pour réduire la ressource de calcul par défaut en UAT versus PROD, par exemple
- Schéma : L’emplacement où les données seront stockées pour le code s’exécutant dans l’environnement
- Jobs en pause/non en pause : Vous pourriez facilement désactiver l’exécution de tous les jobs
Déclencher des jobs depuis un autre job : Celui-ci est plus un hack, mais quand j’ai commencé à opérer des jobs, j’avais besoin d’enchaîner deux jobs après un autre et je ne connaissais pas la meilleure façon. Au début, j’ai utilisé la condition de déclenchement basée sur l’arrivée de fichier. J’ai complété mon premier job avec une étape qui écrivait un fichier factice dans un volume de schéma lié au prochain job.
Je ne pense pas que ce soit la meilleure approche, et après avoir discuté avec des collègues, j’ai appris que je pourrais probablement construire un job qui déclenche directement tous les jobs ensemble. Néanmoins, c’était un bon raccourci à l’époque.

Chargement en arrière de données avec des jobs : Celui-ci provient d’un conseil de mon collègue Simon. Lorsque vous devez charger en arrière des données pour un système (par exemple, toutes les données des jeux AC RPG précédents comme exemple aléatoire :) ), l’étape For Each dans les jobs Databricks est ma façon d’exécuter une tâche de manière répétée au sein d’un job.
Visualisation et Machine learning
Applications Databricks : C’est l’une des principales fonctionnalités killer de la plateforme. Déployer des applications web a toujours été un combat dans mon travail, du moins pour le faire de manière autonome. L’application Databricks a débloqué cela, tout en ajoutant également une couche de sécurité supplémentaire pour l’accessibilité des données, qui est souvent le principal point de douleur.
Déployer l’application est facile, mais parfois interagir avec les données peut être délicat. Databricks a facilité l’intégration en fournissant un dépôt GitHub et un cookbook d’applications pour aider avec cela.

La transition du développement local au déploiement en ligne n’est toujours pas fluide (je travaille actuellement sur quelques extraits de code pour améliorer cela). Cependant, cela permet déjà de nombreux nouveaux cas d’usage pour les data scientists.
Modèle de tableau de bord AI/BI : Databricks a son propre outil de visualisation BI appelé AI/BI. Il offre la possibilité de créer des tableaux de bord faciles à partager et fournit également une couche supplémentaire “d’exploration IA”.
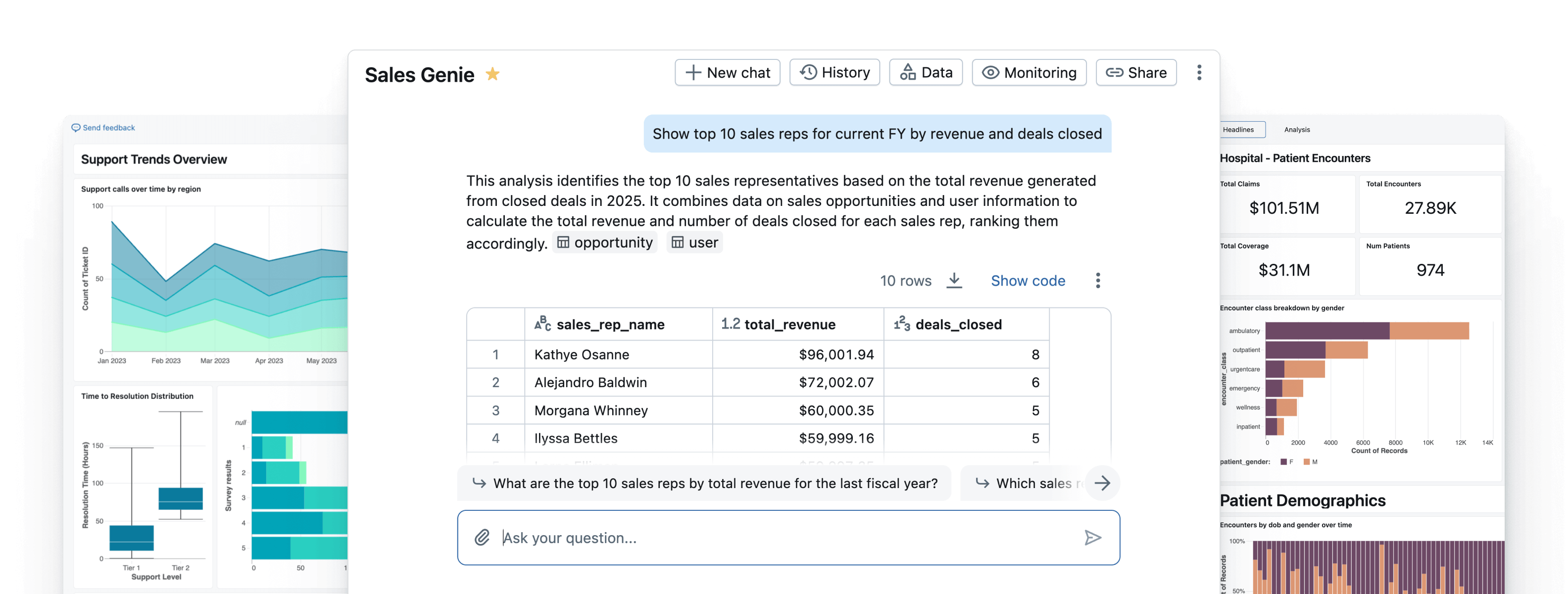
Au-delà de l’utilisation simple, je veux souligner la possibilité de créer des modèles à partir de tableaux de bord qui peuvent être exportés en tant que fichiers JSON. Ces exports incluent à la fois les instructions de dataset et les conceptions de figures, vous pouvez donc facilement réutiliser des tableaux de bord de projet en projet.
Interaction avec les LLM : Databricks, au-delà de vous permettre de déployer des LLM sur la plateforme, offre également la possibilité d’utiliser des modèles fondamentaux de différents fournisseurs tels que LLaMA, Mixtral, DeepSeek, Gemma, et plus récemment GPT OSS. C’est très simple : vous pouvez interagir via le client OpenAI en Python, ou en envoyant des requêtes HTTP à des points de terminaison spécifiques si vous préférez.
Mais la fonctionnalité la plus intéressante pour interagir avec les LLM est les fonctions SQL IA. Plusieurs types de fonctions servent différents objectifs (voir image).
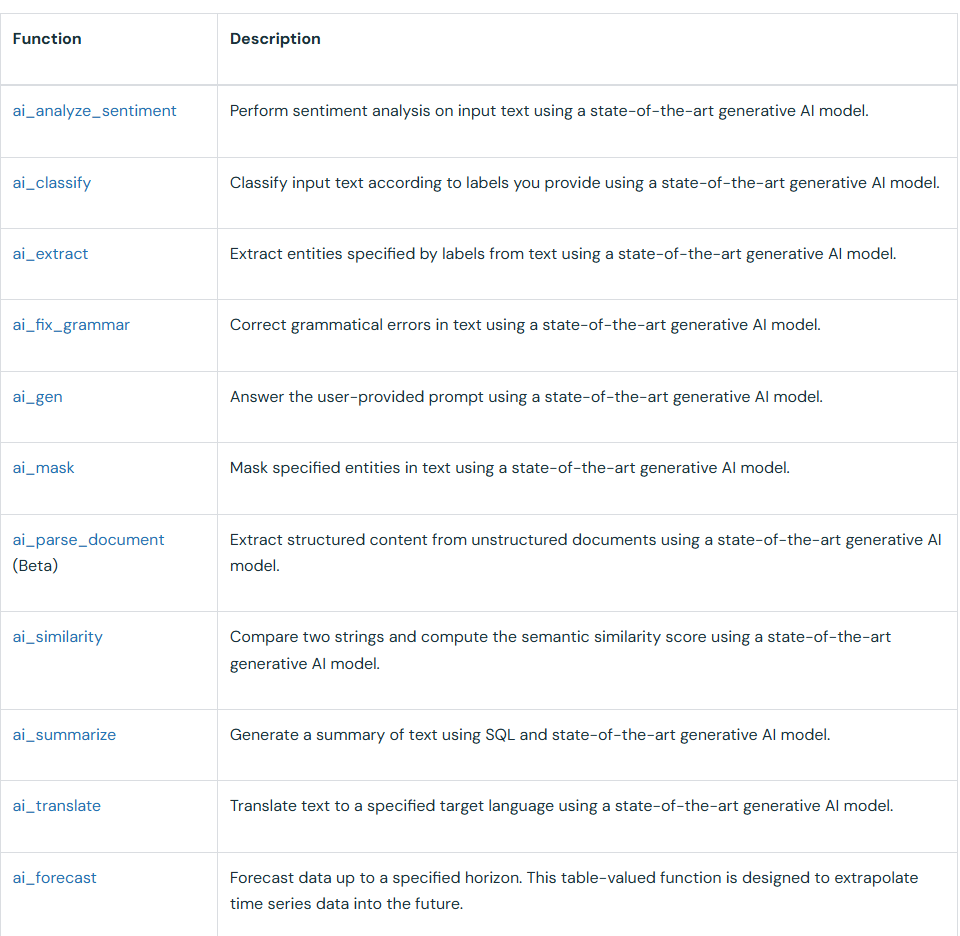
La plus intéressante est ai_query, qui est cachée de cette liste. Avec cette fonction, vous pouvez fournir le nom du modèle et le prompt que vous voulez appliquer au contenu stocké dans une colonne spécifique d’une table Databricks. Cela vous permet de faire facilement des appels en batch pour manipuler n’importe quelle table avec un LLM.
La ai_query peut également être intégrée dans une fonction UDF, qui peut ensuite être partagée avec d’autres. Cela rend vraiment pratique de versionner et réutiliser des fonctions à travers les projets.
Ressources pour en savoir plus
Lorsque nous avons commencé notre intégration sur Databricks, l’une des premières choses que l’équipe de plateforme nous a demandé de faire était d’explorer l’Académie Databricks pour en savoir plus sur la plateforme.
Pendant mon intégration, je me suis concentré sur les trois cours suivants :
- Databricks Fundamentals
- Data Preparation for Machine Learning
- Machine Learning in Production (V2) : Ce cours est actuellement retiré/en maintenance.
Ces ressources couvrent une grande partie des fondamentaux nécessaires pour opérer le machine learning en production sur la plateforme. Basé sur mon expérience de migration de projets ML vers Databricks et d’utilisation intensive de DAB, je recommande également de consulter des cours autour de DAB, tels que Automated Deployment with Databricks Asset Bundles, qui vous aide à mieux comprendre comment cela fonctionne.
Au-delà de passer des certifications ou de regarder des vidéos dans l’académie, pratiquer avec la plateforme est définitivement utile. Récemment, Databricks a annoncé la Databricks Free Edition, qui remplace leur Community Edition. Elle vous permet d’explorer certaines des principales fonctionnalités de la plateforme sans frais. L’expérience est limitée, mais je conseille fortement à toute personne postulant pour un poste de données chez Ubisoft (ou toute entreprise où Databricks fait partie de l’écosystème) de l’essayer.
Enfin, si vous voulez une autre perspective sur Databricks, je recommande vivement :
- Le cours MLops with Databricks par Maria Vechtomova et Başak Tuğçe Eskili de Marvelous MLOps. Il fournit une bonne introduction à MLOps sur Databricks en utilisant la Free Edition
- Jeter un œil aux replays des conférences AI + Data, qui compilent généralement des interventions d’utilisateurs externes de la plateforme avec des keynotes de Databricks
Et après
Alors, quelle est la suite pour moi ? Après avoir migré le côté machine learning de mes projets vers Databricks, la deuxième phase est de migrer le côté ETL/analytics. Je suis actuellement fortement impliqué dans le rebranchement de mes pipelines sur Databricks, mais il y a quelques choses à venir que je suis enthousiaste d’explorer :
- Service de modèle en direct : Mes projets utilisent actuellement uniquement le service de modèle en batch. J’ai un peu expérimenté avec quelques PoC autour du service de modèle en direct, et ce sera la prochaine grande étape pour comprendre comment opérer ce type de workflow sur Databricks.
- Améliorations MLflow : Curieusement, je n’ai pas encore beaucoup utilisé MLflow sur Databricks (bien que j’aie été un utilisateur intensif sur la plateforme précédente). Il y a plein de nouvelles fonctionnalités dans la dernière version qui seront utiles pour certains de mes projets
- Brick Agent et toute la stack LLM : C’était l’une des grandes annonces lors de la dernière conférence AI + Data, Databricks offre maintenant une collection de services autour de la création d’agents qui semble prometteuse basée sur le replay. Cependant, je n’ai pas encore de cas d’usage concret avec un système de données réel qui nécessite ce type d’application, donc j’attendrai la bonne opportunité pour expérimenter avec.

Au-delà de cet article, j’aime discuter de données, d’IA et de conception de systèmes—comment les projets sont construits, où ils réussissent et où ils peinent. Si vous voulez échanger des idées, remettre en question des hypothèses, ou parler de vos propres projets, n’hésitez pas à me contacter. Je suis toujours ouvert à une bonne conversation.
Références
- Volumes Databricks — Databricks
- Fonctionnalités du format Delta — Databricks
- Annonce du Liquid Clustering automatique — Databricks
- Comment construire un système de recommandation Wide and Deep évolutif — Databricks
- Databricks Utilities (dbutils) — Databricks
- Databricks Asset Bundles (DAB) — Databricks
- Profils CLI Databricks — Databricks
- Paramètres databricks.yml — Databricks
- Déclencheurs d’arrivée de fichier — Databricks
- Étape For Each dans les jobs Databricks — Databricks
- Modèles d’applications Databricks — GitHub
- Cookbook d’applications Databricks — apps-cookbook.dev
- Databricks AI/BI — Databricks
- Modèle de tableau de bord AI/BI (GitHub Gist) — GitHub Gist
- Aperçu des modèles fondamentaux — Databricks
- Fonctions SQL IA — Databricks
- Fonction ai_query — Databricks
- Académie Databricks — Databricks
- Cours Databricks Fundamentals — Databricks
- Cours Data Preparation for Machine Learning — Databricks
- Cours Machine Learning in Production (V2) — Databricks
- Cours Automated Deployment with Databricks Asset Bundles — Databricks
- Databricks Free Edition — Databricks
- Marvelous MLOps — marvelousmlops.io