
Pourquoi 95% des projets d'IA 'échouent' — et comment y remédier
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
J’avais cette idée depuis un moment d’écrire sur les défis du monde réel de la construction et de l’exploitation de systèmes comme les systèmes de recommandation qui mélangent données et ML — pas les algorithmes ou l’ingénierie des fonctionnalités, mais les réalités désordonnées et humaines qui font ou défont ces projets. Récemment, ce rapport du MIT sur les projets d’IA a été publié et a attiré une large attention médiatique.
L’article a un gros titre accrocheur mais est rempli de choses dont je voulais discuter dans mon article, c’était donc l’occasion parfaite de rebondir sur l’article et de discuter des systèmes et des raisons pour lesquelles ils échouent ou réussissent.
Les cinq W de l’article
En guise d’introduction, soyons journalistes et écrivons les 5W de cet article.
- Qui : L’article est signé par Aditya Challapally, Chris Pease, Ramesh Raskar et Pradyumna Chari, sous l’initiative de recherche MIT Nanda, qui fait partie du MIT Media Lab dirigé par Ramesh Raskar.
- Quoi : Basé sur plus de 300 initiatives d’IA, 52 interviews d’organisations et 153 réponses de sondages de leaders de l’industrie.
- Quand : Le rapport est basé sur des travaux menés entre janvier et juin 2025. Je me concentre ici sur le rapport préliminaire disponible en ligne.
- Où : MIT.
- Pourquoi : Explorer le potentiel d’un web intelligent décentralisé et comment les systèmes d’IA s’intègrent dans les entreprises.
Maintenant, plongeons dans le cœur de l’article : qu’est-ce qu’un projet d’IA ?
Définir le ‘projet d’IA’
L’article semble clairement axé sur les projets d’IA et les applications d’IA générative. Mais qu’est-ce exactement qu’un ‘projet d’IA’ — simplement une initiative d’intelligence artificielle ? Lorsqu’on cherche en ligne, il n’y a pas beaucoup de définitions formelles, mais il existe plusieurs références aux systèmes d’IA, qui peuvent être définis comme :
- Selon l’AI Act : un système basé sur une machine conçu pour fonctionner avec différents niveaux d’autonomie et qui peut présenter une adaptabilité après le déploiement, et qui, pour des objectifs explicites ou implicites, déduit de l’entrée qu’il reçoit comment générer des sorties telles que des prédictions, du contenu, des recommandations ou des décisions pouvant influencer des environnements physiques ou virtuels.
- Selon le NIST : un système d’ingénierie ou basé sur une machine qui peut, pour un ensemble donné d’objectifs, générer des sorties telles que des prédictions, des recommandations ou des décisions influençant des environnements réels ou virtuels. Les systèmes d’IA sont conçus pour fonctionner avec différents niveaux d’autonomie.
Ces définitions mettent en évidence le concept d’une machine avec un certain niveau d’autonomie pour atteindre des objectifs en produisant divers types de sorties.

J’ai quelques indices de projets ML remontant à 2018 :) donc voici le premier raccourci fait par les médias généralistes qui mettent tous les “projets d’IA” dans le même panier.
D’après mon expérience, je préfère arrêter de faire une distinction stricte entre les systèmes d’IA ou de ML et parler plutôt de systèmes de données. Un système de données prend des données sous différentes formes (brutes ou traitées) provenant de diverses sources et produit de nouvelles données ou informations. Le système lui-même est composé de :
- un moteur : où le traitement des données d’entrée a lieu
- une couche d’intégration : la partie finale qui rend les données traitées accessibles
Les deux éléments fonctionnent sur leurs propres technologies, et les technologies diffèrent entre un système de recommandation chez Netflix, ChatGPT d’OpenAI ou un tableau de bord. Mais en fin de compte, ces systèmes génèrent de nouvelles données pour s’améliorer et qui aident l’entreprise à évoluer dans une certaine direction.
Examinons maintenant le grand chiffre inquiétant qui effraie les médias.
95% d’échec ? Pas vraiment.
Le titre provient de ces deux citations
95% des organisations obtiennent un retour nul. Les résultats sont si fortement divisés entre les acheteurs (..) et les constructeurs (…) que nous l’appelons le Fossé GenAI.
5% des pilotes d’IA intégrés extraient des millions de valeur, tandis que la grande majorité reste bloquée sans impact mesurable sur le P&L (…)
Si vous lisez attentivement, ces projets n’échouent pas réellement — ils obtiennent un retour nul ou ne montrent aucun impact mesurable sur le P&L. Donc les entreprises ne gagnent ni ne perdent d’argent — ce n’est pas un échec total de mon point de vue.
Dans l’article, il y a aussi le graphique suivant comparant les technologies qui sont étudiées, pilotées et implémentées avec succès :
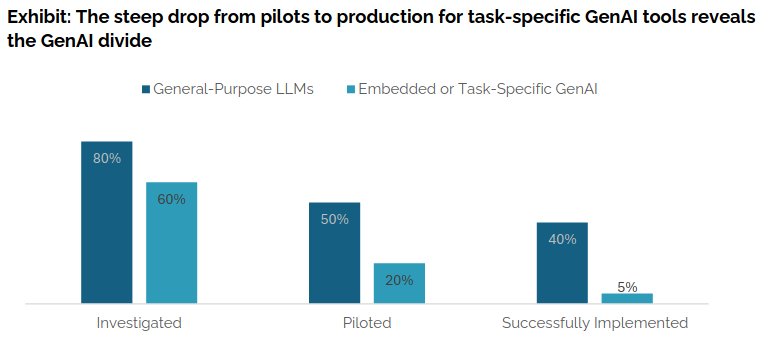
Comme nous pouvons le voir, les LLMs à usage général (par exemple, ChatGPT, Copilot) montrent un succès relativement élevé dans l’implémentation (40%), tandis que les approches spécifiques aux tâches restent beaucoup plus basses (environ 5%).
L’article souligne également :
Mais ces outils améliorent principalement la productivité individuelle, pas la performance P&L.
Ainsi, alors que les entreprises perçoivent des avantages de GenAI au niveau individuel, l’impact sur la performance commerciale reste encore limité.
Dans l’ensemble, les chiffres de l’article du MIT ne sont pas si mauvais. Et la vision “doomer” autour des projets d’IA n’est pas nouvelle pour être honnête, il y a 5 à 10 ans le taux d’échec était déjà autour de 85%, selon une étude Gartner de 2018.

Donc au final, une métrique de succès doit être définie pour déterminer si un projet est réussi.
La mesure clé du succès : le ROI
Concevoir des résultats quantifiables est essentiel lorsque vous voulez déterminer comment un système fonctionne. Vous avez besoin de KPI qui impactent directement le flux de trésorerie de l’entreprise — que ce soit du point de vue du consommateur, où vous pouvez influencer son parcours, ou du point de vue de l’employé, où vous pouvez améliorer son travail pour apporter de la valeur.
Le rapport capture bien cette idée :
50% des budgets GenAI vont aux ventes et au marketing, mais l’automatisation du back-office offre souvent un meilleur ROI.
Les ventes et le marketing dominent non seulement en raison de la visibilité, mais aussi parce que les résultats peuvent être mesurés facilement.
Être capable de segmenter les KPI est essentiel : certains vous aideront à concevoir de meilleurs systèmes, tandis que d’autres vous guideront dans le suivi de la santé financière de vos initiatives (comme le ROI), vous devez donc trouver un bon équilibre mais gardez à l’esprit que le ROI sera le décideur final.
Mais les grandes questions qui restent en suspens après avoir lu cet article et la notion de ROI :
- Combien est un bon ROI ?
- Combien de temps pour mesurer un ROI ?
Combien est un bon ROI ?
Quel est le nombre magique pour un bon ROI ? Dans l’article, ils n’en fournissent aucun, juste impact mesurable sur le P&L.
Microsoft a publié une étude interne suggérant 3,5x ROI comme référence pour les projets d’IA. Cette étude est arrivée dans certaines de nos discussions l’année dernière pour évaluer l’efficacité de nos initiatives de données, et soyons honnêtes, les chiffres sont élevés et la méthodologie est discutable.
Le vrai point reste que vous devez être capable de mesurer ce ROI et de comparer vos coûts de fonctionnement et investissements par rapport au retour sur investissement qu’il apporte.

Si je mets mes chiffres sur la table concernant ce qu’est un bon ROI pour un système, je définirai une échelle de ROI (parce que vous avez besoin de nuances) comme cela :
- D (ROI < 1) : Vous coûtez plus que vous ne livrez — valeur négative.
- C (1.0 – 1.05) : À peine positif. Petits gains (0–5%), mais au moins dans la bonne direction.
- B (1.05 – 1.1) : Solide. Comparable aux rendements moyens du marché boursier américain (5–10% par an).
- A (1.1 – 1.5) : Fort. Vous apportez 10–50% de revenus en plus — valeur ajoutée claire.
- S (1.5 – 2.0) : Excellent. 50–100% de flux de trésorerie en plus — rare et impressionnant.
- 🤯 (ROI > 2) : Exceptionnel. Plus de 100% de retour. Mais vérifiez toujours comment les KPI sont mesurés — si cela semble trop beau pour être vrai, cela pourrait l’être.
Au-delà de la valeur pour définir un bon ROI, il est également essentiel de définir une période de mesure.
Combien de temps pour mesurer un ROI ?
En lisant l’article du MIT, je me demande quelle était la période de mesure pour le P&L pour l’étude ?
Ce que vous devez garder à l’esprit, c’est qu’il est important de mesurer l’efficacité d’un système en continu dès le premier jour (et avec le coût avant la sortie du projet comme investissement). Dans ma présentation au Data Engineering and ML Summit l’année dernière, j’ai présenté une diapositive liée à une étude de trois mois sur le ROI de certains projets de personnalisation qui avaient été déployés depuis plusieurs années. L’idée était d’évaluer les systèmes de recommandation par rapport à une ligne de base de base (articles les plus populaires, non personnalisés).

Cela a montré, par exemple, que certains projets lancés cinq ans plus tôt avaient atteint un stade où la base d’utilisateurs était moins réceptive aux recommandations, et les coûts opérationnels étaient plus élevés qu’une simple ligne de base, nous avons donc décidé de passer à la ligne de base.
Pour le projet le plus rentable, nous avons décidé d’aller au-delà de l’analyse de trois mois et de mener un test A/B sur une année complète. Avoir une année complète de données nous a permis de détecter des effets plus petits sur de nouveaux KPI, et de capturer des variations saisonnières dans les KPI, montrant que le système était plus efficace pendant certaines périodes (lorsque les utilisateurs étaient plus réceptifs et que le catalogue fonctionnait mieux).
Mesurer l’impact à long terme est essentiel pour prendre la bonne décision, mais le ROI n’est pas tout.
Le facteur brillant != Visibilité
Cette idée a été mentionnée dans les citations précédentes concernant l’investissement en ventes et marketing, mais d’autres soulignent le même point :
En termes de focus fonctionnel, l’investissement dans les outils GenAI est fortement concentré. Comme les dépenses GenAI ne sont pas encore formellement quantifiées dans les organisations, nous avons demandé aux cadres d’allouer un hypothétique 100$ à différentes fonctions. Les fonctions de ventes et de marketing ont capturé environ 70 pour cent de l’allocation du budget IA dans les organisations de notre enquête.
Malgré 50% des budgets IA qui vont aux ventes et au marketing (d’après l’estimation théorique avec les cadres), certaines des économies de coûts les plus spectaculaires que nous avons documentées provenaient de l’automatisation du back-office. Alors que les gains du front-office sont visibles et appréciés du conseil d’administration, les déploiements du back-office ont souvent livré des périodes de récupération plus rapides et des réductions de coûts plus claires
Ces citations mettent en évidence une réalité difficile dans la conception de systèmes de données : il y a toujours un facteur brillant. Les systèmes visibles orientés utilisateur obtiennent plus de traction auprès de la haute direction, tandis que les systèmes de back-office — moins visuels mais souvent plus impactants sur l’efficacité — ont du mal à gagner la même visibilité.
Dans l’industrie du jeu vidéo, c’est particulièrement clair. Par exemple, il est beaucoup plus cool de livrer un projet qui fait parler et bouger quelque chose dans un jeu que d’optimiser un processus de back-office ou d’ajuster le contenu d’un menu.

Mais ne vous méprenez pas — le facteur brillant n’est pas une mauvaise chose en soi. Il est souvent lié aux technologies ou approches émergentes, et il aide à attirer l’attention. Cependant, il peut aussi biaiser la prise de décision, car la haute direction peut ne pas vouloir “rater le train du hype”.
Dans l’article, ils mentionnent des projets non visibles. J’ai trouvé la formulation légèrement dévalorisante pour les projets de back-office. Pourtant, le mot visibilité est important.
La visibilité est essentielle lorsque vous travaillez sur des systèmes de données. Il est important de saisir chaque opportunité de présenter votre système. Même si le projet n’est pas “brillant”, il est toujours précieux de mettre en évidence les réalisations clés, le ROI et les résultats. Ces moments de visibilité vous donnent l’occasion de faire des connexions, car d’autres parties de l’entreprise peuvent être intéressées par votre projet.
L’apprentissage clé est d’équilibrer le portefeuille de systèmes. Certains devraient avoir un fort facteur brillant, tandis que d’autres se concentrent sur l’efficacité et l’optimisation du back-end — mais dans les deux cas, vous devez les rendre visibles. (Et honnêtement, chez Ubisoft, nous sommes bons pour maintenir cet équilibre.)
L’intégration est la principale barrière
Lors de la conception de systèmes dans de grandes entreprises, au-delà du problème du travail non visible, il existe également de multiples obstacles qui peuvent survenir en cours de route. Le graphique ci-dessous met en évidence les principaux (y compris certains dont nous avons discuté dans les sections précédentes)

Le dernier point (le plus important) dans le graphique “réticence à adopter de nouveaux outils” peut être lié à une autre citation (ou mythe démystifié) de l’article :
La plus grande chose qui retient l’IA est la qualité du modèle, le légal, les données, le risque → Ce qui la retient vraiment, c’est que la plupart des outils d’IA n’apprennent pas et ne s’intègrent pas bien dans les flux de travail
L’étape d’intégration est souvent négligée ou non priorisée, mais c’est exactement ce qui augmente le taux d’échec. Vous pouvez avoir d’excellents prédicteurs/générateurs, mais s’ils ne peuvent pas être utilisés dans les systèmes existants de l’entreprise, le projet ne réussira pas.
Par exemple, lorsque nous avons commencé à travailler sur notre plateforme ML précédente chez Ubisoft, il était crucial pour l’équipe de s’intégrer avec le SDK interne qui interagit avec les services en ligne de l’entreprise. Cette intégration a pris des mois, avec plusieurs comités examinant les formats de points de terminaison, etc. — cela s’est même produit avant que nous ayons déployé nos ressources de calcul. En priorisant l’intégration, nous avons assuré que notre système ML vivait dans la même réalité que les programmeurs en ligne dans l’entreprise. Cela a rendu l’adoption de nos systèmes de prédiction par lots beaucoup plus fluide.
Travailler sur l’intégration est essentiel — et devrait être une priorité absolue, mais ne passez pas trop de temps dessus non plus ou vous manquerez des opportunités.
Livrer rapidement
Pour conclure l’analyse de l’article : tout est dans le titre. Pour concevoir des systèmes de données, il est important de les livrer rapidement. Ce point est fortement soutenu par les citations suivantes :
Les startups qui franchissent avec succès le Fossé GenAI obtiennent des victoires petites et visibles dans des flux de travail étroits, puis se développent. Les outils avec une faible charge de configuration et un temps de valorisation rapide surpassent les constructions d’entreprise lourdes
Dans les interviews, les utilisateurs d’entreprise ont rapporté des expériences constamment positives avec des outils grand public comme ChatGPT et Copilot. Ces systèmes ont été loués pour leur flexibilité, leur familiarité et leur utilité immédiate. Pourtant, les mêmes utilisateurs étaient massivement sceptiques vis-à-vis des outils d’IA personnalisés ou proposés par des fournisseurs, les décrivant comme fragiles, sur-conçus ou mal alignés avec les flux de travail réels. Comme l’a dit un CIO, ‘Nous avons vu des dizaines de démos cette année. Peut-être une ou deux sont réellement utiles. Les autres sont des enveloppes ou des projets scientifiques.
L’apprentissage clé est simple : concentrez-vous sur l’essentiel et faites fonctionner un système aussi vite que possible. Ensuite, itérez pour le rendre plus complexe et l’adapter aux besoins des parties prenantes. Ne sur-concevez pas votre système au départ (ce n’est pas un projet scientifique)
Terminons cet article avec peut-être des sujets moins sexy : l’impact environnemental et la gestion de projet.
Conseils et astuces de gestion de projet
Comme pour tout déploiement de système, vous devez avoir des pratiques de gestion de projet en place. Quelques astuces que je trouve pertinentes :
-
Définir une matrice RACI : Pour tout système de données que vous développez, définissez des responsabilités claires en utilisant une matrice RACI. Ne vous concentrez pas uniquement sur le système lui-même — incluez également ses entrées et sorties pièces/parties prenantes dans le cadre de la responsabilité.
-
Documenter le système : La documentation est la partie ennuyeuse, mais elle est essentielle. Documentez ce qu’est le système, à quoi il se connecte et où il s’inscrit. Une approche utile consiste à utiliser des “cartes”. Vous pouvez avoir deux cartes principales : une carte système et une carte modèle. Pour l’inspiration : les cartes système de Meta et les cartes modèle de Hugging Face comme référence
-
Revues post-mortem : Le suivi du ROI est essentiel, mais il est également utile de faire des post-mortems à intervalles réguliers (par exemple, tous les X mois). Ces sessions sont une bonne occasion de réunir tous ceux qui sont liés au projet, des parties prenantes aux fournisseurs de données. Elles vous permettent de passer en revue comment le système s’est comporté (particulièrement utile car de nouvelles personnes rejoignent souvent l’environnement), de mettre en évidence les résultats d’expériences en direct récentes, de capturer les leçons apprises — à la fois positives et négatives — et de définir les prochaines étapes claires.

Impact environnemental
Je n’épilogue pas trop sur ce point — car si vous lisez cet article, vous êtes probablement déjà au courant des nombreuses études sur l’impact environnemental de tels systèmes et le risque d’atteindre un plateau technologique. Une excellente lecture sur ce sujet est l’article de Gaël Varoquaux, Alexandra Sasha Luccioni et Meredith Whittaker : “The Hype, Sustainability, and the Price of the Bigger-is-Better Paradigm in AI.”
Soyez responsable lors du déploiement de votre système : suivre le ROI améliore non seulement l’efficacité mais réduit également l’impact environnemental. Cela vous pousse vers l’utilisation de moins de puissance, de modèles plus petits et de conceptions plus efficaces — ce qui, au final, profite à tous et à la planète.

Notes de clôture
Dans l’ensemble, l’article du MIT est plein d’informations précieuses — c’est juste que les médias se sont concentrés sur la première page et les grands chiffres effrayants.
Si je devais faire un TL;DR sur le succès des projets d’IA : concentrez-vous sur l’intégration et la livraison rapide, surveillez les coûts de l’idée à la production, et évitez le travail invisible. Et pour vous la prochaine fois que vous entendrez que XX% des projets d’IA échouent, demandez : ont-ils mesuré le ROI ? Se sont-ils intégrés ? Ou ont-ils simplement chassé le facteur brillant ?
Au-delà de cet article, j’aime discuter des données, de l’IA et de la conception de systèmes — comment les projets sont construits, où ils réussissent et où ils ont du mal à réussir. Si vous voulez échanger des idées, remettre en question des hypothèses ou parler de vos propres projets, n’hésitez pas à me contacter. Je suis toujours ouvert pour une bonne conversation.
Références
- State of AI in Business 2025 Report (MIT) — mlq.ai
- Initiative de recherche MIT Nanda — media.mit.edu
- Loi IA de l’UE — Article 3 Définitions — artificialintelligenceact.eu
- Cadre de gestion du risque IA du NIST — nist.gov
- Gartner : Près de la moitié des DSI planifient de déployer l’IA (2018) — gartner.com
- New Study Validates the Business Value and Opportunity of AI — microsoft.com
- Matrice RACI (Matrice d’attribution des responsabilités) — Wikipedia
- Comment l’IA alimente les expériences sur Facebook et Instagram — Cartes système — ai.meta.com
- Cartes modèle Hugging Face — Hugging Face
- The Hype, Sustainability, and the Price of the Bigger-is-Better Paradigm in AI — arXiv