
Hello in this article, I am going to give some leads on how to create web scraping system that has been used to collect some data from the Crossfit games website of Reebok
Introduction to Crossfit
The Crossfit is defined as
a strength and conditioning program consisting mainly of a mix of aerobic exercise, calisthenics (body weight exercises), and Olympic weightlifting
This program seems to have been invited in the 2000’s by Greg Glassman and Lauren Jenai, and the sport is licensed under the name of CrossFit, Inc.
I invite you to take a look to some videos on the Crossfit Inc channel on youtube to have a better view of what could be the exercises to do during a session.
In my case I am practicing crossfit since August 2017, three times per week and I liked it honestly when I started I was looking the sport as some brutes that were doing gym exercises at high intensity.
More seriously, I was a little bit afraid by the intensity of the exercises that from my point of view could hurt people pretty badly, but this sport is made for everybody no need to be Superman to practice crossfit.
The strength is that every exercise can be scaled in term of weight, movement in function of your need (physical condition, injuries) but the only goal is to complete the exercise. Never giving up could be the motto of crossfit.
The selection for the world cup championship is quite simple, there is 3 phases in the process:
- The Open , everybody can participate to this qualification, the division are defined by age and gender and if you are not on an affiliate gym that can validate your performance you can film it and send it to the organisers.
- The Regionals , where the best from the Open will compete to be selected for the Games
- The Games , the world cup
For this article, the data collection will be only the open 2018 data that can be found at this address.The Open are defined by:
- a period of 5 weeks, where every week a new wod (workout of the day) is announced
- there are 4 days to try to make the best score to the wod
So why I want to use this case for my introduction to web scraping:
- I read a cool article on the scraping of the Crossfit games website
- I found the presentation of the leaderboard quite limited in term of comparison
- I wanted to make a web scraping exercise for a long time
So let’s dive in it.
Web scraping 101
In this case I decided to scrap the following elements:
- the leaderboard pages for this article we will just be working on the result for 2018 but if you want the approach for the previous year I invite you to look this article on the topic
- the athletes pages, because every athlete has a page with some interesting informations
- the gym pages that contains some details on the location of the gym
To collect the data from this website, I used the package called Beautiful Soup, that is quite popular for the web scraping in Python. In the following sections there will be a description of the data collected and the code associated.
You can find all functions explained in this part in this GitHub repository.
The leaderboard
There is no proper need to scrap the webpage, the API that is used by the frontend can be called directly by a simple get request. Thanks to @pedro to notice that. There is just a need to mention in the request:
- the code of the division
- if the leaderboard concerns the scaled or not scaled athletes
- the page of the api (that you can get form the request of the first page)
This is the request to execute.

The athlete pages
In this case the athlete page looks like the screenshot in the following figure

And at then bottom of the page, there is some benchmark for some exercises.

So I decided to scrap the page for all the athletes that participated to the open during the last 5 years and that represent more than 700000 pages to scrap, to optimise the collection I decided to parallelise the process and I used the following code to get the data for one page.
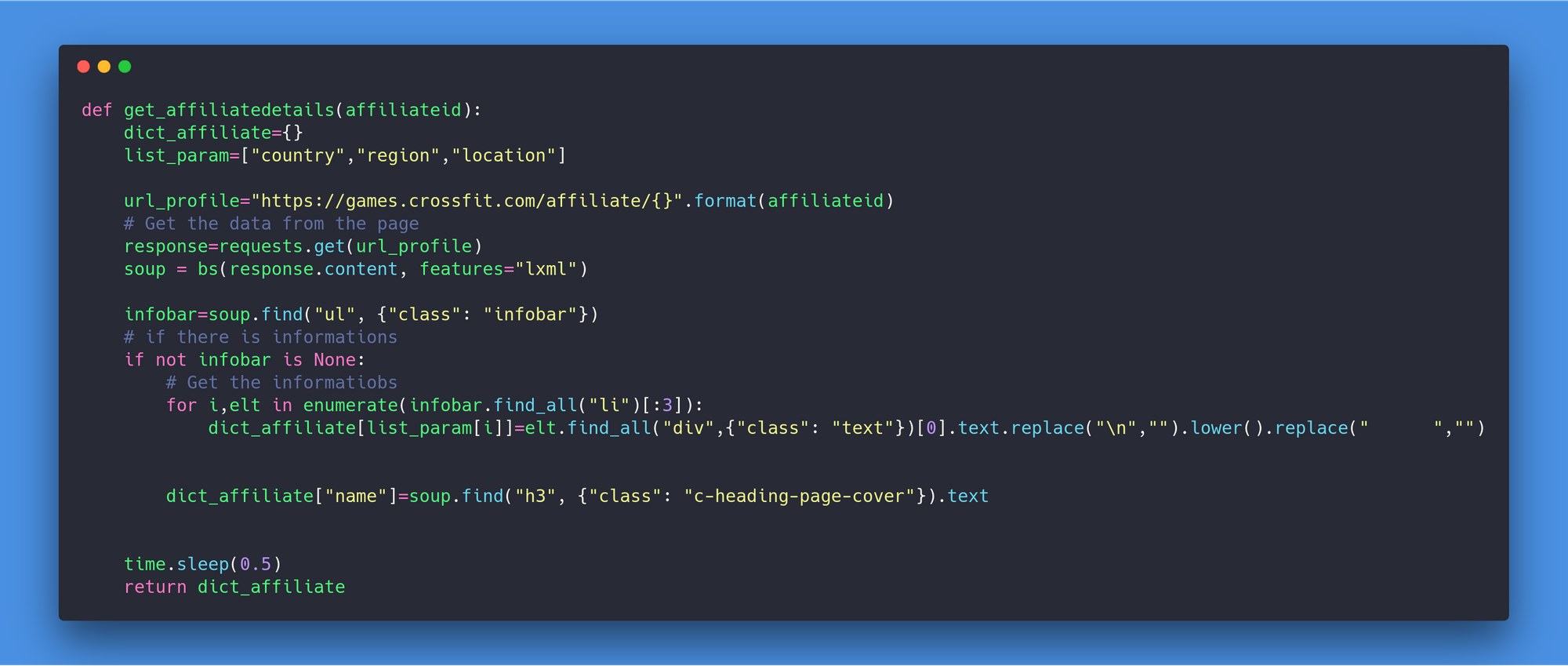
The gym pages
In the case of the gym page, the amount of informations to collect is less important than for the athletes, in the following figure there is a screenshot of the page of a gym.
The script will focus on the details on the header of the page, that concern the location. The number of pages to scrap in this case is around 10000 pages, and the following code has been used to do that.
Ethic behind the process
As you have read there is a lot of data that have been collected by my system, the question is This is legal or not ?.
If I am referring to the common belief, it’s on internet so it’s free that’s fine well it seems that it’s more complicated than that if I refer to this article, it seems that I did something illegal because I didn’t respect the term of use of the website so I decided to contact Crossfit Inc to warn them of what I have done and get their feedback on it (I contacted the organisation by their form, and some email address related to privacy etc).
29 April 2018 : I have no feedback from them on this subject.
From my point of view, I think that’s say until i didn’t publish personal informations on the athletes and the sell the dataset but who knows ?
Let’s have a look on some global insights of the dataset.
You can find all functions explained in this part in this GitHub repository.
Insights on the Open 2018
Overview
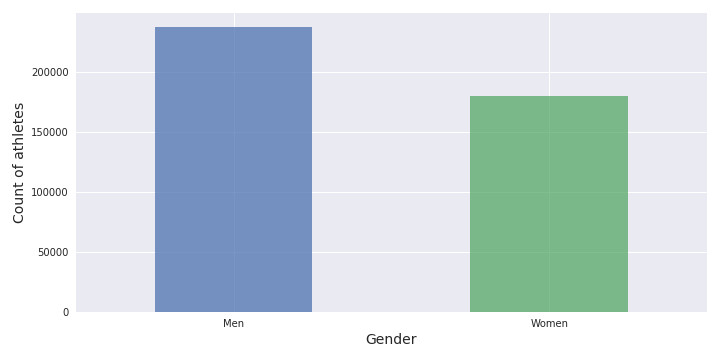
In this part, it will be mostly a very general overview on the Open event. The analysis will start by the gender repartition.
It is good to see that there is quite a similar number of men (56.8%) and the women (43.2%) (similar as what I can see during my training) that was engaged in the Open. Let’s see now the repartition of the age.

The distribution of the age is quite similar between the gender, the athletes with an age greater than 60 are considered as outliers. Another point to notice is that the average age of the athletes is greater than 30 years old, this is could be maybe the mark of:
- need of experience to participate to the Open (but I will not bet on that)
- the price to be a member of a box is too high
- the video rating is not very well promoted
The following distribution graph is a good illustration of this age segmentation.

This is the illustration of the age segmentation that can be related to the income. Let’s see now the athletes data.
Analysis of the athletes
I used for this a part of the data from the athletes pages, I filtered the outlier data that doesn’t respect the BMI (Body Mass Index) that are not between 13 and 83, and some wrong weight and height values. There is a visualisation of the morphology.

The general physic of the athlete seems to be:
- a weight around 80 kg
- a height around 180 cm
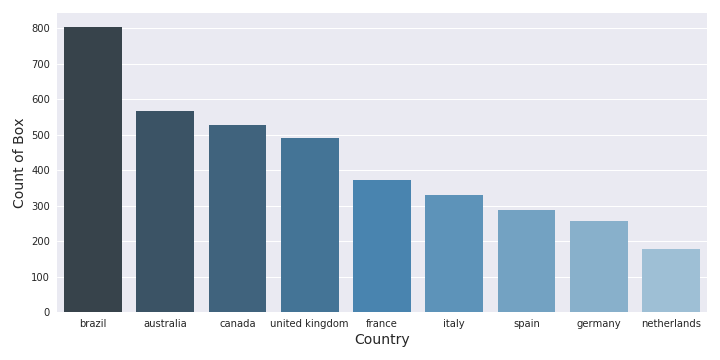
In term of country repartition, the USA is leading the way. In the following figure there is a count of the number of athletes engaged in the event in the USA and the top 10 others countries.

I think there is no comment to do on the popularity of the crossfit in the USA, if I zoom more on the other countries there is some interesting insights. In the following figure, there is more details on the top 10 countries (in term of number of athletes) without the USA.

As we can see there is:
- there is a huge gap between the USA and the second country (like 200 000 athletes)
- the second country with the most important number of athletes it’s not a country it’s the association of all the athletes that was just filming their wod.
- a clear interest from the athletes in Brazil and part of the commonwealth
- the number of athletes engaged in Europe is less important
Let’s see now some details on the gym that was scoring the athletes.
Analysis of the gym/box data
So to be clear the USA have an important number of gyms/athletes engaged in the event. In the following there is a comparison between the number of gyms in the USA and the number of gyms and the 9 others countries with the more gym engaged.

The USA is crushing the other countries literally. In the following figure, there is an illustration of the number of gyms in the others countries.

Number of gyms in the others top10 countries
It’s interesting to see that (there is a lot of similarity between the athlete number and the gym number, that’s normal):
- Brazil has an important number of gyms
- the Commonwealth (Canada,UK,Australia) is present
- France is leading Europe in the ranking (but the Italy is close)
I can continue to make a lot of graphs with this data, so I decided to make an interactive dashboard that I can make evolved easily at any time and for that I will use Tableau
Dashboard on Tableau Public
Tableau Public is a service that have been by a company developed in 2003 in Mountain view based on the work of Stanford university (vizQL). The company was introduced in 2013 at the NYSE and count 2400 employees (2015 number).
There are different products developed by a Tableau, but the purpose of this tool is to facilitate the exchange of data informations across the business by the creation and the sharing of the dashboard.
I invite to take a look on their website to have more details on the products, for this project I used Tableau public to create the following dashboard.
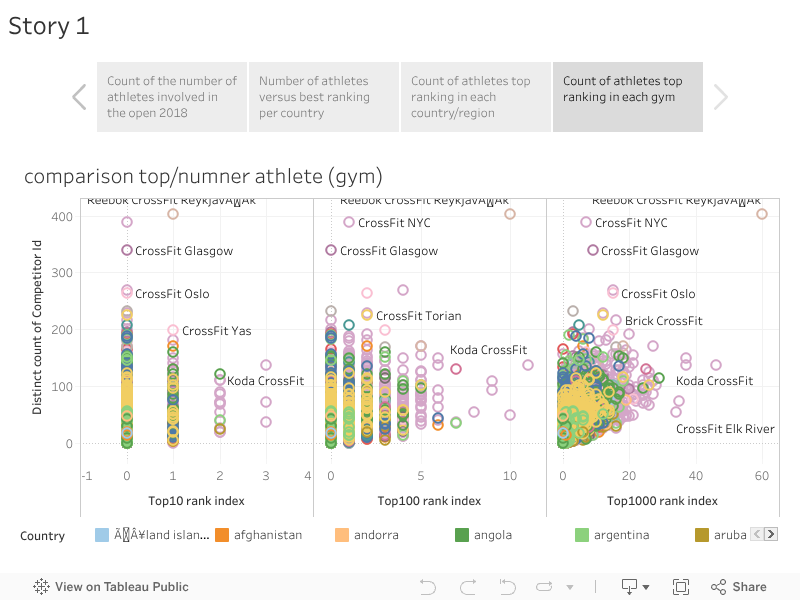
Tableau dashboard
To finish I wanted to go further on the data and just focused on the benchmark exercises, to try to find a connection between them.
Relationship between the exercises
To analyse the data, I had to eliminate the outliers value so to do that I add the choice:
- use the dbscan to detect the outliers after normalisation of the data (efficient but a little bit long to apply it on all the athlete with the data)
- use the statistic approach based on the quantile and delete the value that were below the 5% quantile limit and above the 95% quantile
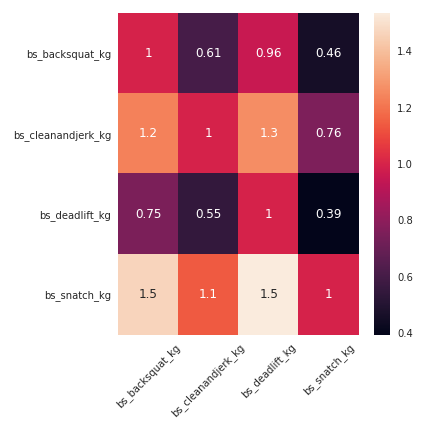
I visually found some correlation between the exercise, as the following figure illustrates the relation.

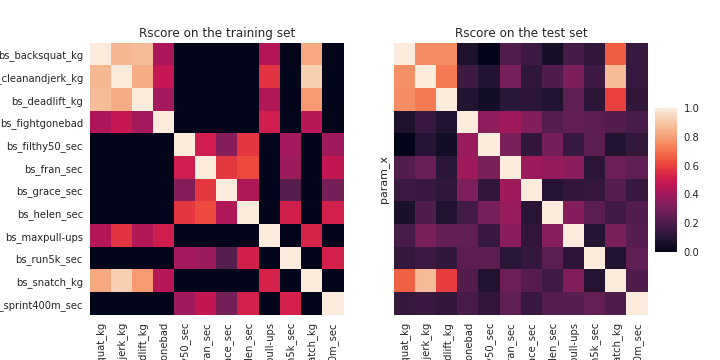
So I wanted to apply the research of correlation (a linear relation) to all the exercises, I applied a linear model on 1,000 athletes, and I tested the model on 250 athletes to see if the model was good enough. I used the r score as an index to evaluate the efficiency of the models.
On the training set, the exercises that involved to carry some weight was highly correlated to each other, the exercises that involved a duration showed a correlation that was less important. When the models have been applied on the test set, the correlation for the weight exercises was still good but the exercises with time was definitely overfitting on the training set. In the following figure there is an illustration of the linear model for the exercises associated to the weight.
To have a better idea of the impact of a weight modification on one exercise, I created a table that make the conversion of for a weight modification on one exercise to a another.
Conclusion and next steps
This project was superinteresting, the scraping of a website is definitely very practical to collect data, and there was some insights to get from this dataset (by a quick analysis).
The next steps for this project are:
- create a Kaggle dataset (if Reebok is OK)
- create some kind of API that will use this data to give training advices
- based on the pictures available on the athletes profile, as the age and the gender are right create a model to determine from the face of someone his gender and age (age range)
- add more historical data on the table (I scraped the past 5 years but the format of the past data is a little bit different) and maybe add regionals and games data
- improve and build other dashboards







{kind=link}