
In this article, I am going to present a pipeline that I built a few weeks ago to collect data (text and pictures) from the website Turo and the process to clean the data collected to use it in an image classifier project.
Disclaimer: This data is for my usage ( I don’t own it ), so I am not sharing it.
Concept of the project
I started a few weeks ago to think to dive more in detail in deep learning, and I wanted to start a project around image classification.
Most of the articles that I am reading in the subject are using all the same datasets as for the mnist dataset (the handwriting number), deepfashion (collection of clothes labelled), or the dog breed classifier.
These datasets are suitable, but I wanted to work on something different and at this moment:
- I discovered at the same time the Turo platform that is a platform where people can rent a car from other people in North America (and it seems to run pretty well).
![]()
- I was starting to play to Forza Horizon 4 on PC from Playground games.

I discovered a few weeks ago two datasets on the same kind of topics
- The one of Stanford related to the car pictures by reading this article of Bhanu Yerra
- This GitHub repository of Nicolas Gervais
But I wanted to increase my game in terms of scraping, so I decided to build my scraper of the Turo website.
In an offer of Turo, I just realized that there are pictures annotated with the kind of car.
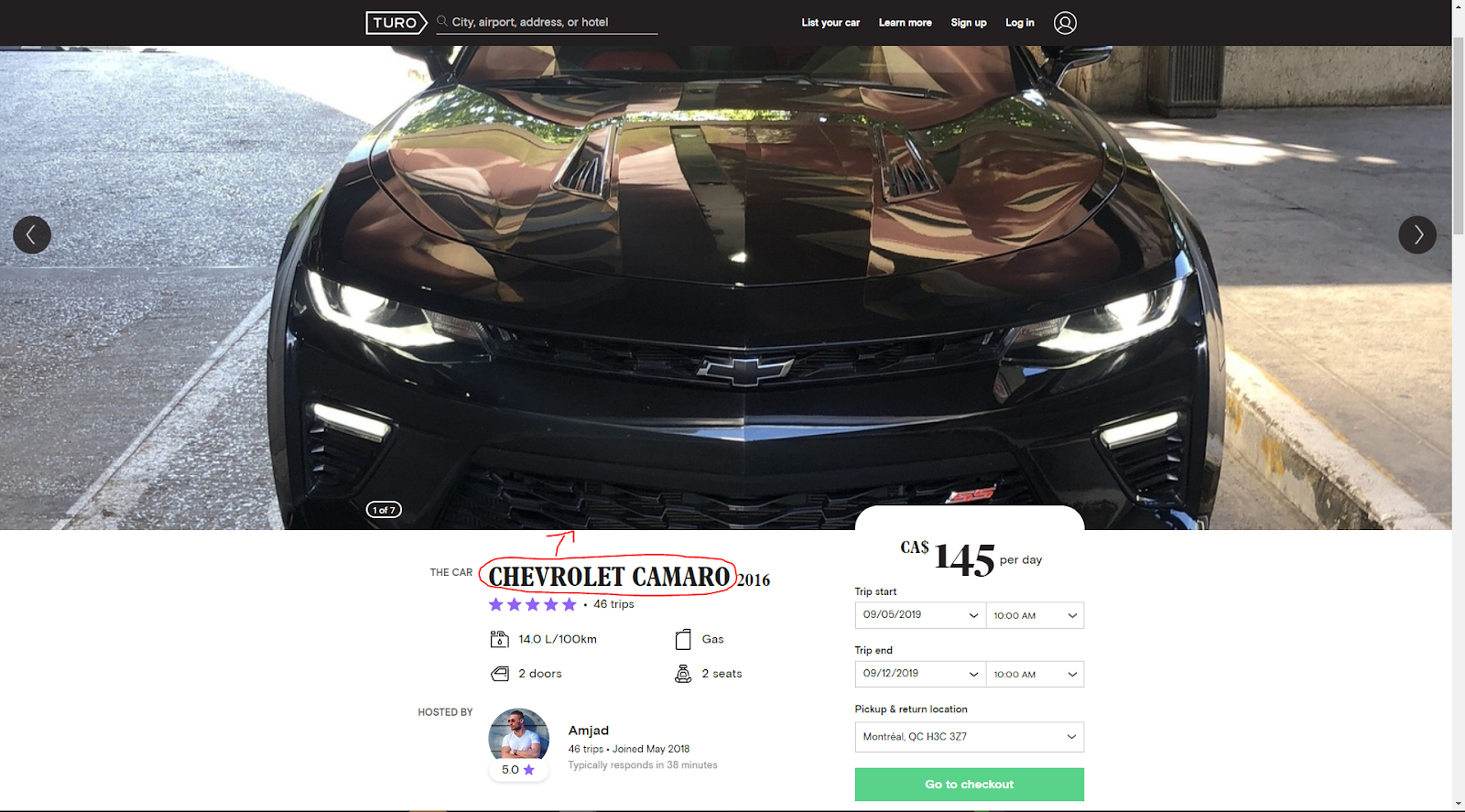
So why not using the website as a source for a dataset for image classification to build a car detection system.
To execute the extraction of the data from the website, I can not use the same approach with Beautiful Soup from my article on the Crossfit open because:
- The URL is not very obvious to fill, so I need to automatize my Turo research
- There is some scrolling to do to get all the ads displayed on a result page
I can still use Beautiful Soup to get the data from the source page, but I need to associate this package with another package called Selenium to automate the research on Turo.
Presentation of the packages
In this part, I am going to give a brief introduction to the libraries that I used to crawl all along Turo.
Beautiful Soup
Beautiful Soup is a package “for pulling data out of HTML and XML files. It works with your favourite parser to provide idiomatic ways of navigating, searching, and modifying the parse tree. It commonly saves programmers hours or days of work”.

With this package after the collection of the source page online, you can segment all the HTML tags and research inside to collect the information that you need. In my opinion, this package is an excellent start to begin web scraping with Python, and there are plenty of useful resources on the subject.
Selenium
This package can be seen as a web browser automation package.

This package allowed a Python script to open a web browser like Firefox, fill fields on a webpage, scroll on the webpage, and click on buttons as a human can do.
Let’s dive know on the data pipeline.
Presentation of the data pipeline
Overview
In term of data collection, I decided to focus my data collection on the most significant North American cities, so I took:
- The central town for the US states that contains at least 1 million people
- The 15 most populated cities in Canada
There is a map of the panel of cities that I am scraping data.
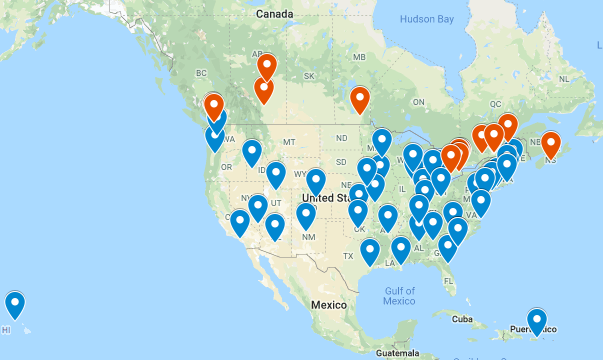
It represents 60 cities (in blue the US and red Canada), like that I have multiple types of environments (mountains, sea) and kind of different weather that can induce various kinds of vehicles.
The idea is to collect every 6 hours the new offers from 5 cities that are picked randomly on the list of the cities. The storage of the data received is made :
- In local, all the pictures are saved on the scraping machine
- In AWS, I am using a dynamodb table to store the information from the offers scraped (id, details on the offer) to always have the info available on the offers saved
I ran this pipeline for approximately two weeks, and I downloaded around 164000 images.

Let’s now have a look more in detail on the script that is doing the data collection with Selenium and Beautiful Soup.
Collection the offers
First of all, to collect this data, I need to have a way to give a city and get the offers that are currently available.
There is a code that can collect offers for the city of Montreal.
As we can see:
- the usage of the Selenium is passing by the declaration of a driver that can control the web browser to do the navigation on the website
- With the object driver, I can set up my script to fill a specific field defined by an id in this case
js-searchFormExpandedLocationInputand send the key to this particular input (in this case the location in the city field)
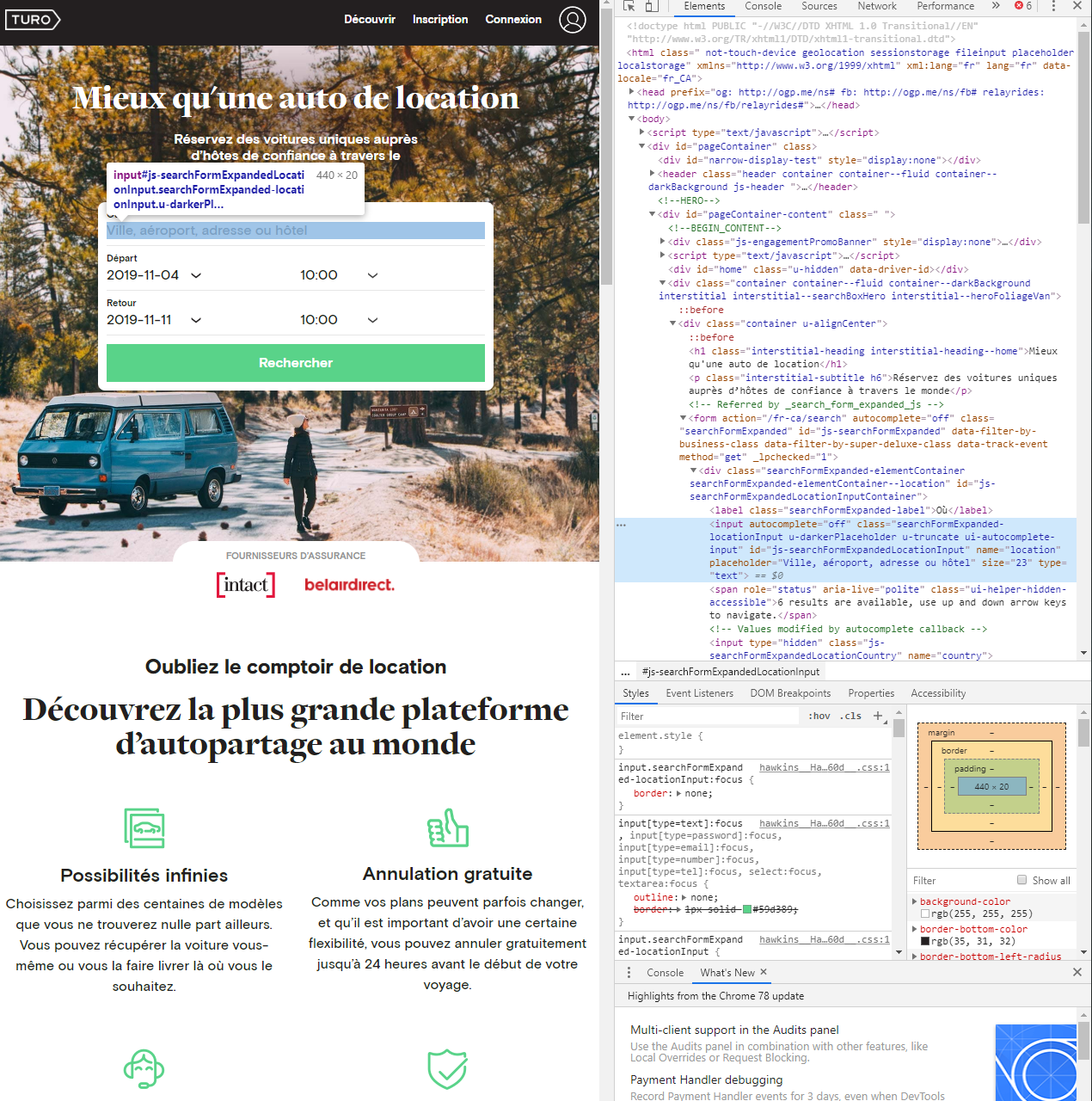
- Another piece of Selenium is the direct interaction with the buttons (need to find the button on the page and activate it) on the page.
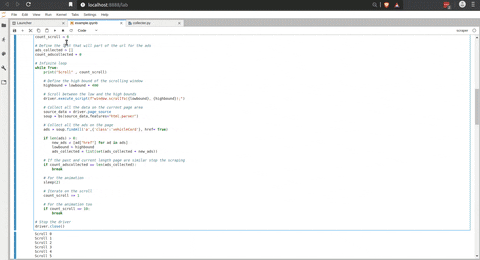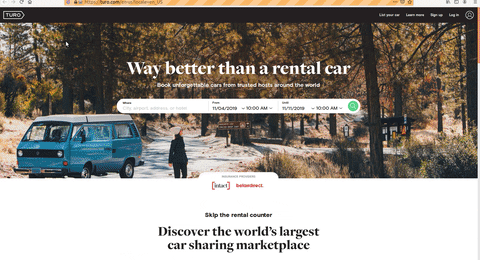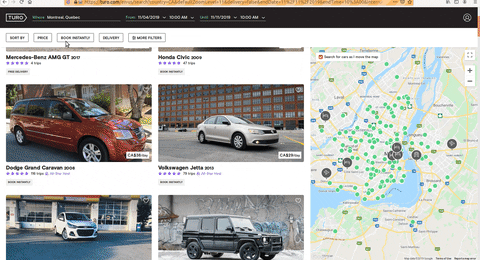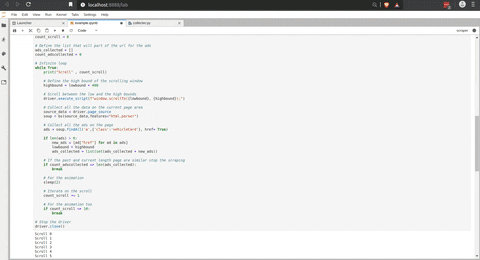
For the scrolling on the page, it’s a little bit tricky; I used the method of Michael J Sandersto scroll on an “infinite page”.
Between each scroll, I am using Beautiful Soup to collect all the offers that were on the page.
There is an animation of the script in action.
After that, I am just applying a filtering on the offers that I never saw before (that are not in my dynamodb table) and using a new process to collect the data from a specific offer.
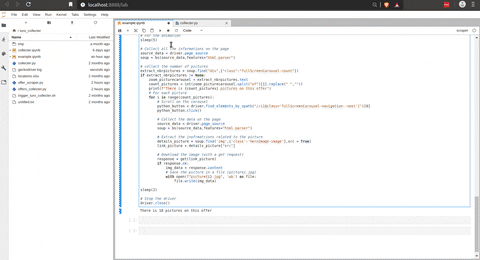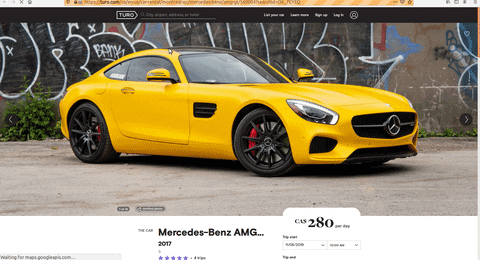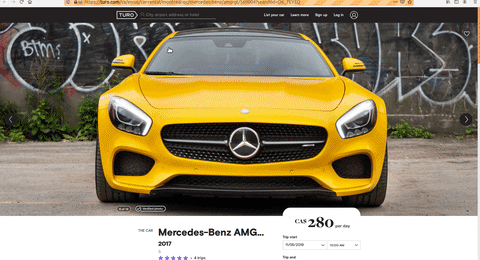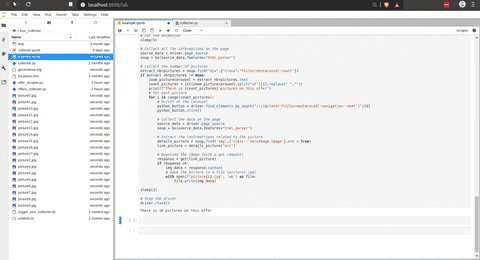
Collect the pictures
There is the script to collect the data for an offer.
The tricky part of this script is to collect the URL of the pictures on the offer. The following screenshot illustrates that the pictures are stored in a carousel.
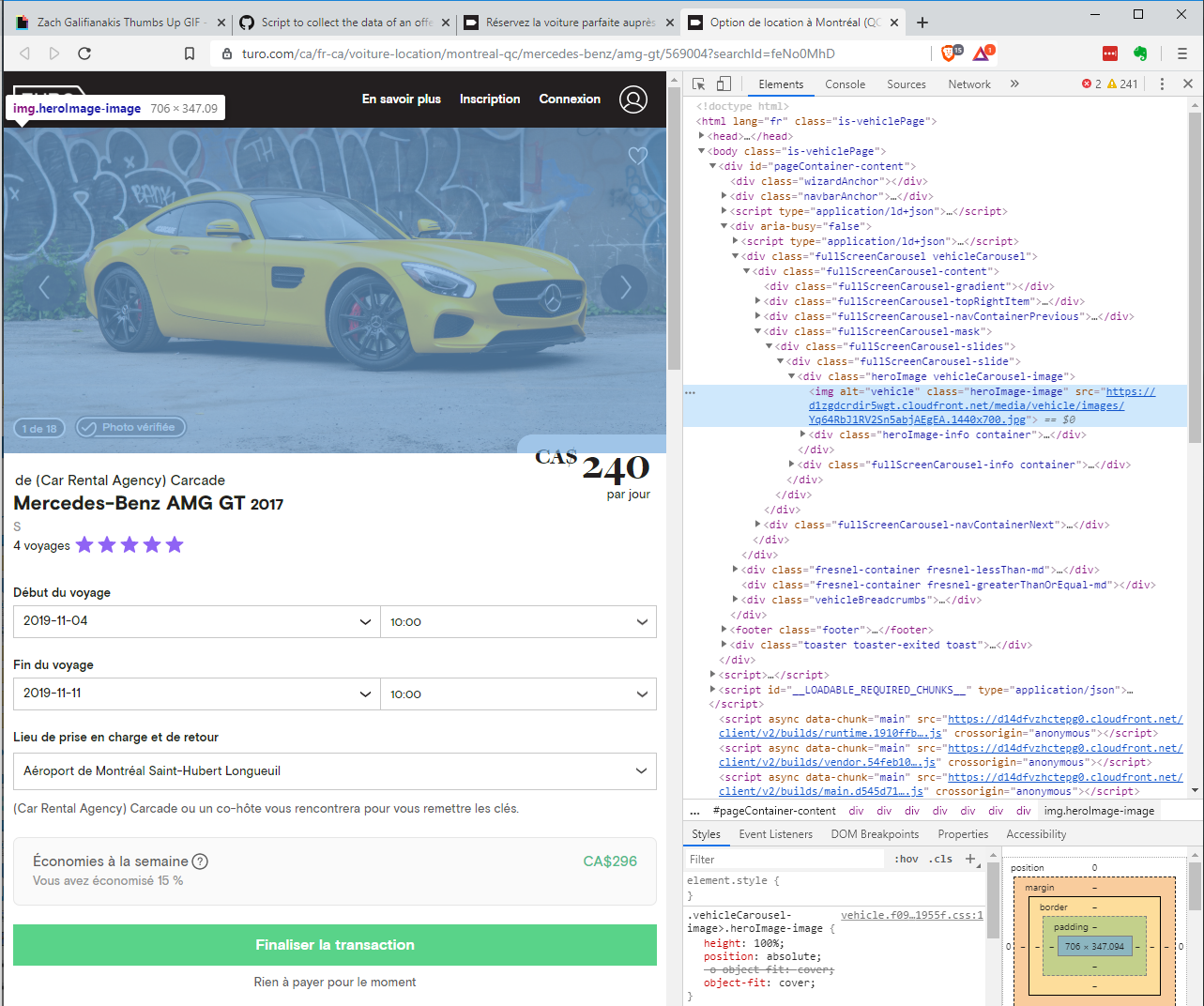
I am using the same trick then with the validation button on the front page, and with that, I can easily collect all the URL of the pictures and, with a GET request, download them on my machine. There is an animation of the previous script in action.
If you want to run the scripts, I am inviting you to set up a python environment with the configuration that is on this Github repository (on a Linux machine).
Let’s now have a look at the data preparation of the dataset.
From a ze(raw) dataset to an hero dataset for an image classifier
With my scraper, I collected a lot (164000 ish) of pictures on the website Turo associated with their car offers. That’s a good number to start, but all of these pictures are not usable, for example, the interior of the car.

There is a lot of these pictures, so I need to do some cleaning on this raw dataset.
Description of the cleaning pipeline
The process behind this pipeline is to:
- Detect all the objects on the image of the raw dataset
- Apply some rules based on the objects detected in the picture to select the right images
- Crop the vehicle on the image and store it in a new file
There is a brief illustration of the process
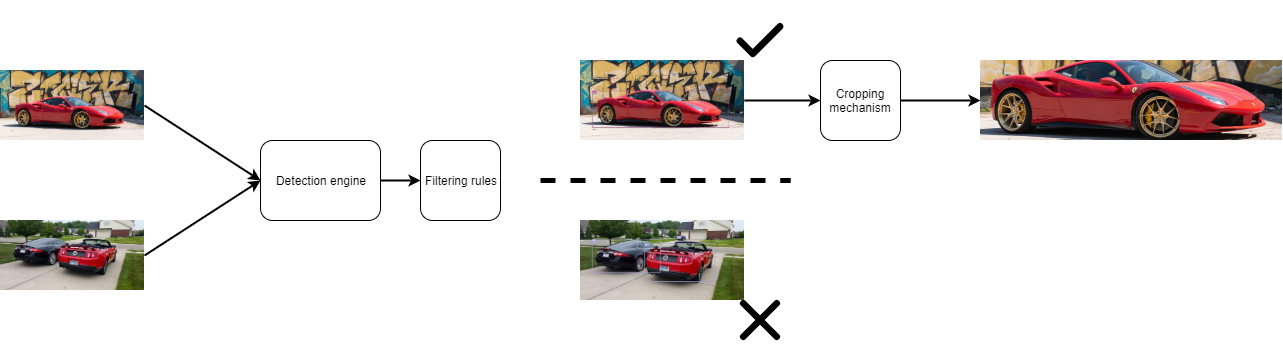
The trickiest part of this pipeline was the detection engine; for this part of the pipe, I decided that I can use a pre-made model. There is a significant amount of models that can be found online to execute the task to detect objects on an image.
The implementation that seems the most efficient to use is the one made by Chris Fotache on Pytorch.
For the filtering rules, it was simple; a good picture of a car can is defined with:
- only one vehicle (car or truck) on the image
- the confidence index of the detection of the vehicle should be higher than 90%
After the filtering rules, it happened that only 57000 pictures were usable.
Let’s see how the labelling of these pictures.
Final step : Resizing and labelling
The final step to complete the dataset is to resize the pictures and have labels for the classification.
Resizing
From all of these pictures that have been selected, two things are noticeable
- they have different sizes (in term of height and length)
- they are in colour (so there have 3 channels for the primary colours)
In the following figure, there is a representation of the height and length of the pictures.
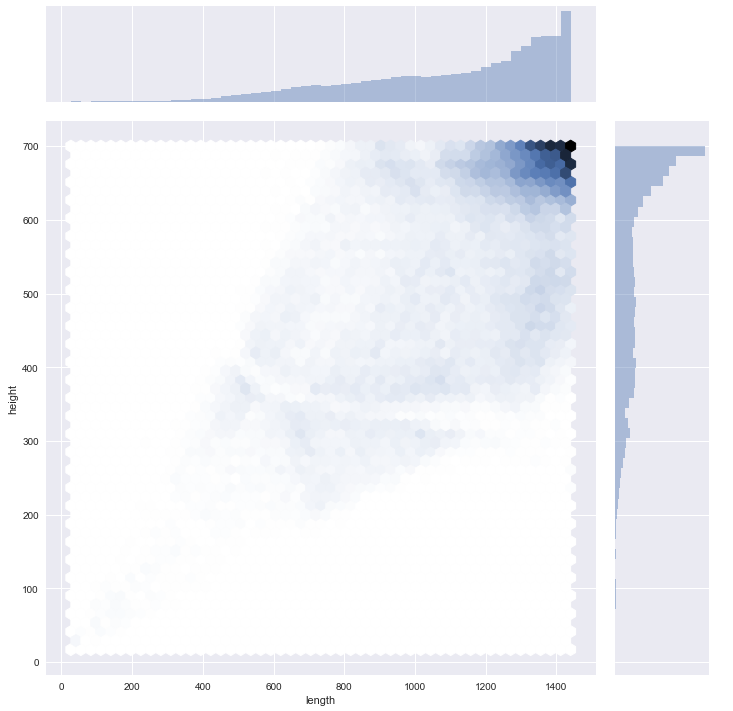
The pictures have propers resolutions, but I need to uniformize them to make useable by every pipeline for classification. I built the following piece of code to resize the pictures (and this function can make them black and white).
I tried multiple configurations of size for my dataset in terms of pixels for the height and length.
Let’s have a look now on the labelling.
Labelling
There are two obvious labelling for this dataset :
- the manufacturer with 51 possible labels
- the model with 526 possible labels
In the following figure, there is a visualization of the count of models per manufacturer.
As we can see, there is a lot of manufacturers and models, and it is a hard start to have so many labels (I think). I decided to build my “labelling mechanism.”
I build two kinds of labelling:
- one for a binary classifier
- one for a multiclass classifier
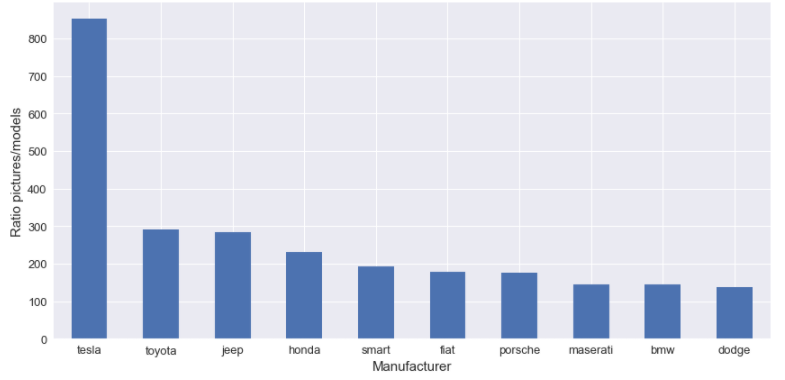
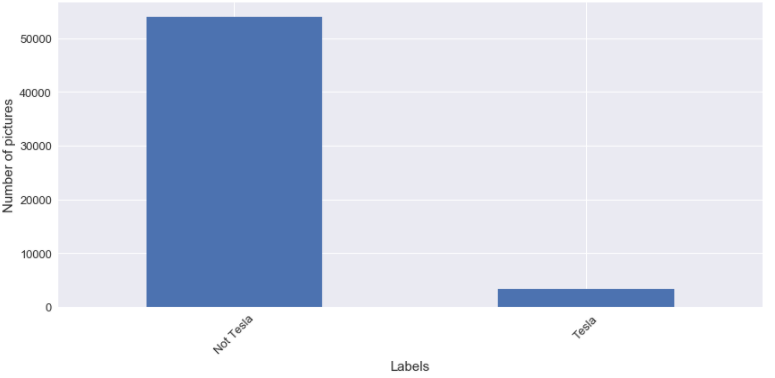
For the binary classifier, I pick one specific manufacturer and one specific model. For the manufacturer, I decided to choose Tesla; the first reason it is trendy online and the second reason Tesla has an unordinary ratio between the number of pictures for the number of models available, as we can see in the following figure.
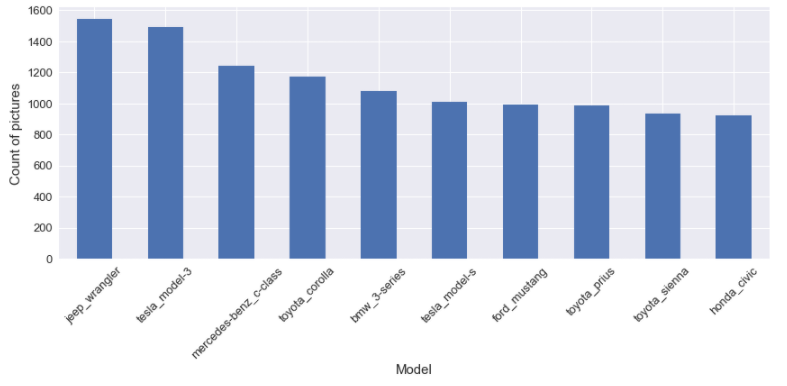
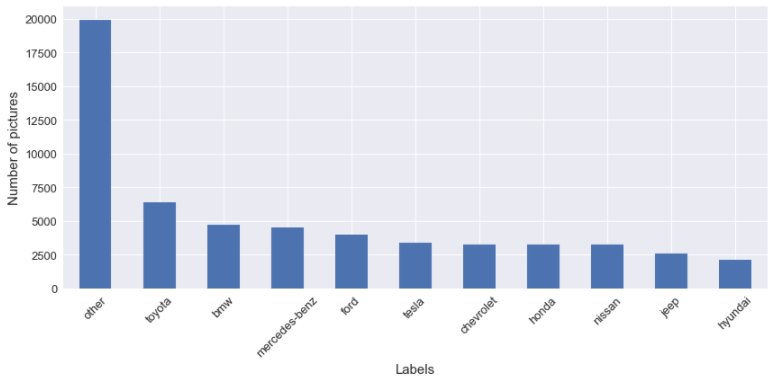
For the model, I decided to choose the Ford mustang because I like Ford mustang nothing else. But let’s be honest, it’s one of the models that is the most popular in the dataset, as we can see in the next figure of the top10 most popular models.
Let’s talk about the multiclass classifier; for this case, I use a straightforward approach for the labelling. The idea is to take the top X most popular manufacturer/model, and if the manufacturer/model of the picture is not in the top X, his label assigned is other. I build the labels for the :
- top 10 manufacturer/model
- top 25 manufacturer/model
- top 50 manufacturer/model
- top 100/200/400 models
Now a lot of different labels are available for the pictures. Still, for my first work on the image classifier, I am going to focus my test with the binary labels and the top10 manufacturer/model.
To complete this article, I just want to talk about something, and it’s about the balancing of the dataset. For the label that I selected, I can tell you that classes to predict are not balanced at all. In the following figures, there is an illustration of the unbalancing of the dataset.
When I am going to use these labels for the image classification, I am going to test the impact to balance the classes for the training.
Stay tuned and don’t hesitate to give some feedback.
##







){kind=link}