
For this article, I am going to describe my hands-on on a new library that has open-sourced recently by Netflix to operate and version machine learning / data science pipeline called Metaflow.
The idea of this article is to :
- Have an overview of the package
- Details with two examples the features of the package (and go further than the tutorials)
Overview of Metaflow
Metaflow is a package developed by Netflix, they started to work on it a few years ago (around 2016), and open-sourced in 2019. The idea of Metaflow is to offer a framework for data scientists to build a data science/machine learning pipeline quickly, and that can go smoothly from development to production.
I am inviting you to watch the presentation of Ville Tuulos of Netflix at AWS reinvent 2019.
The big question at Netflix behind this package was
What is the hardest thing for a data scientist in its daily job ?”
The engineers of Netflix were expecting to listen to access large datasets, significant computing power and usage of GPU, but the answer (two years ago) was different. One of the most significant bottleneck was the data access and the move from PoC to production.
In the following figure, there is a visualization of the interest of data scientists and the infrastructure needs in an ML/DS process.

In this article that announces Metaflow, there is one quote that I think is defining the moho behind Metaflow:
The infrastructure should allow them to exercise their freedom as data scientists, but it should provide enough guardrails and scaffolding , so they don’t have to worry about software architecture too much.
The idea is to offer a safe path for the data scientist in their work without compromising their creativity. This framework needs to be easy to use and offer access to significant computing power without having to put hands on the infrastructure.
Let see more the design of the framework.
Design of Metaflow
Metaflow is a Python library that is only running on Linux, mostly inspired by Spotify Luigi, and designed around DAG. In the following figure, there is a representation of a typical flow on Metaflow.
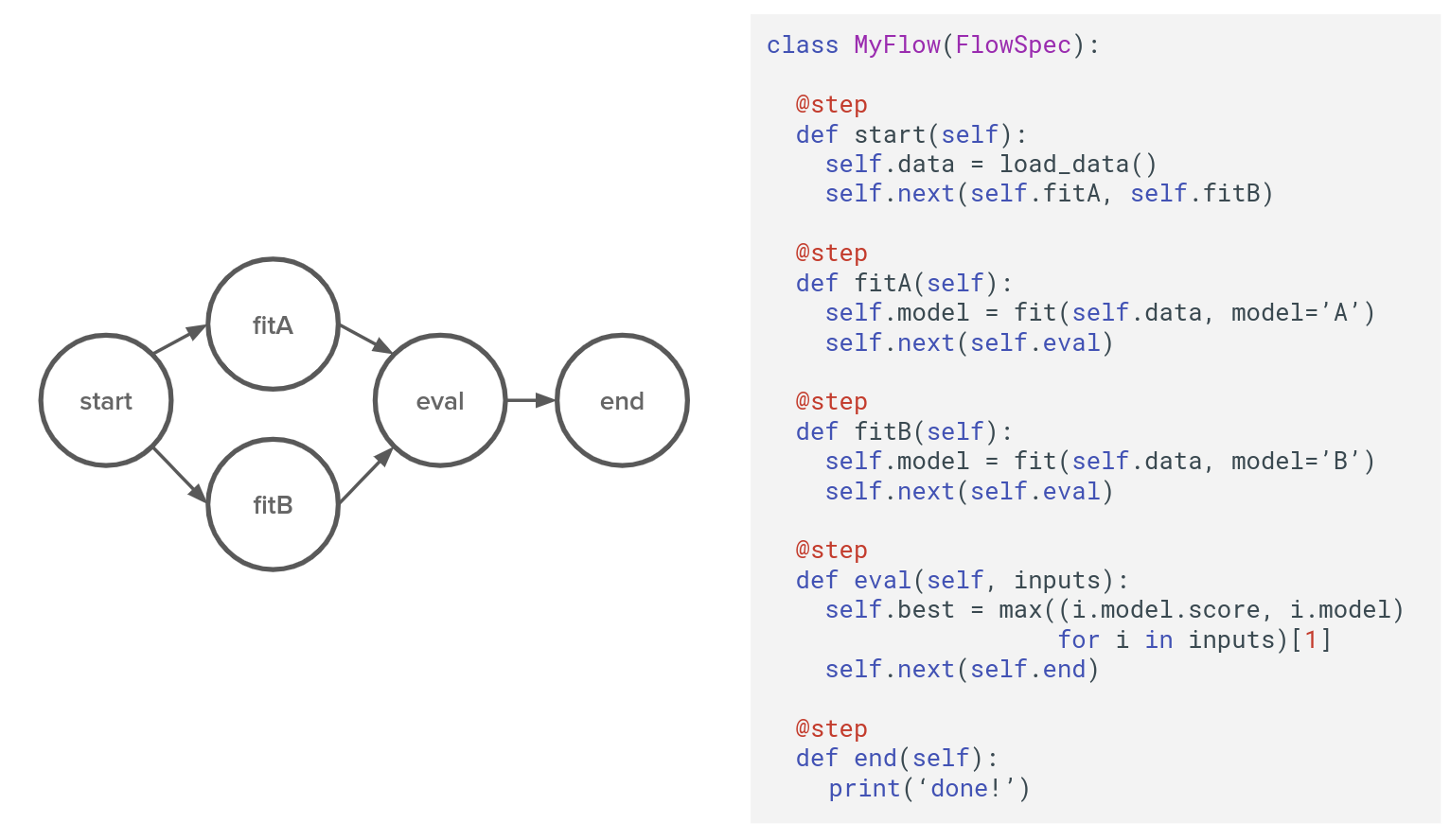
The DAG is structured around :
- Flow: the instance that is managing all the codes for the pipeline. It is a Python object in this case class MyFlow(Flowspec)
- Steps: parts of the flow, delimited by decorator @step, they are python functions in the MyFlow object, in this case, def start, fitA, fitB, eval, end.
- Transitions: links between the steps they could be of different types (linear, branch and for each); there are more details on the documentation.
Let’s talk about the architecture now. In the following figure of Netflix, there is a view of the components.
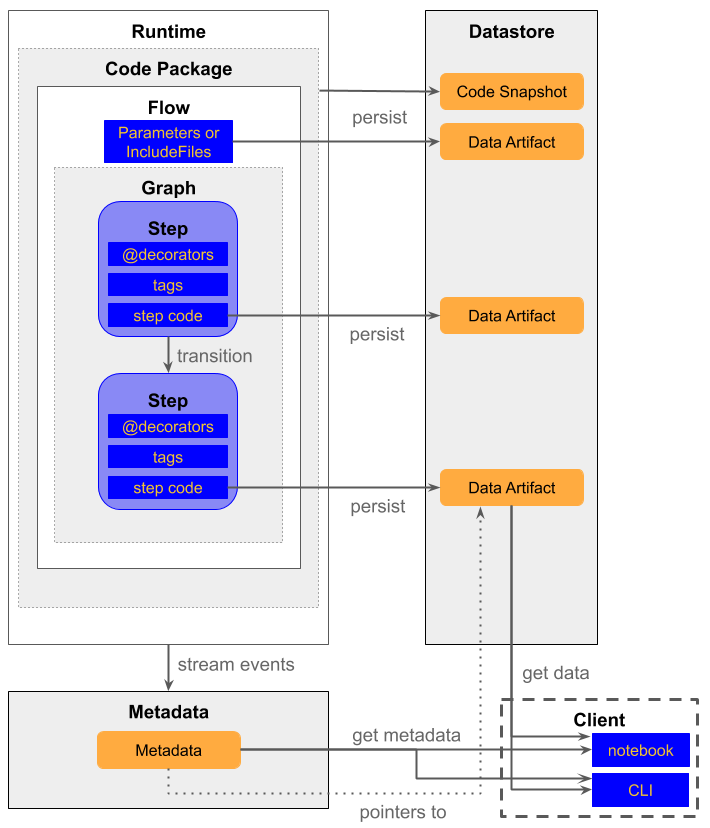
There are 3 components around the flow:
- The datastore that is the place where all the data (data artifact) generated all along the flow are stored
- The metadata is the place where the information on the execution of the flow are stored
- The client is the component that is the connection to access the data in the datastore and get information on the flow from the metadata
For me, one of the central part that is handling the core of Metaflow is the decorator. It is a Python feature that permits to update the property of a python object without modifying his structure, and I am inviting you to read this article of Data camp on the subject.
In Metaflow, there are multiple decorators, well explained in this section of the documentation. Still, for me, the most important are the ones that I am going to explain in the next part.
Hands-on on MetaFlow
I built a simple flow to illustrate the decorators and the branches’ transitions. The code of flow is in this repository ( decorator_experimentation folder); the flow is looking like that.
And there is a visual illustration of the flow.
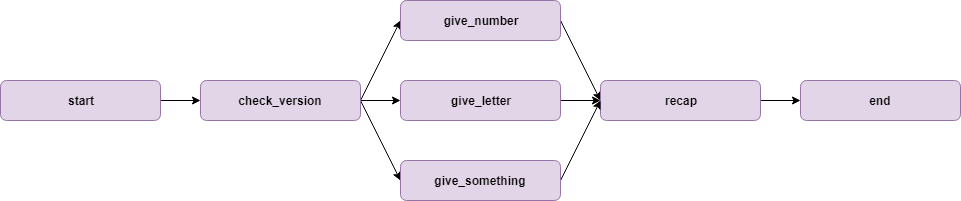
This goal of the flow is to :
- Test the version of Python and Pandas in the start step,
- Test (again !?) the version in Python and Pandas in the check_version step
- Execute a 3 branches transition that is going to give a random number (give_number), letter (give_letter), or number/letter (give_something)
- A join step called _recap _to print the products of the previous steps,
- An end step that is going to display (again !?) the version of Python/Pandas
The regular check of the version of Python/Pandas is to illustrate two specific decorators.Let’s start by the standard execution of the script; to execute this flow, you need to run the following command in the folder of the script.

There is the log produced by the script.
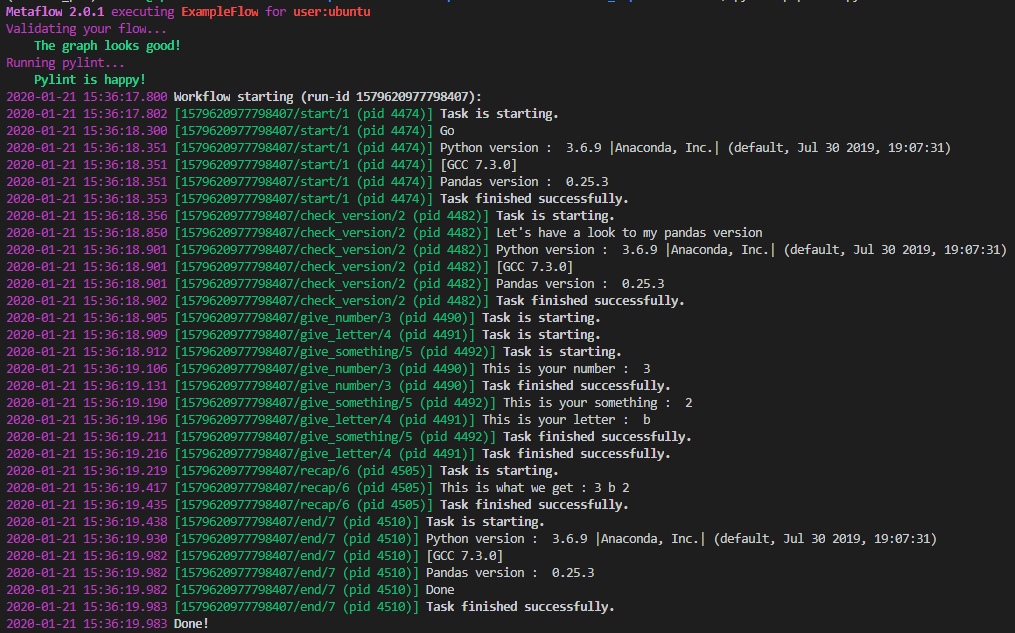
As we can see on the log, the version of Python is 3.6.9 and Pandas is 0.25.3. Let’s test the @conda_base decorator. Just need to uncomment a line and execute the following command line.
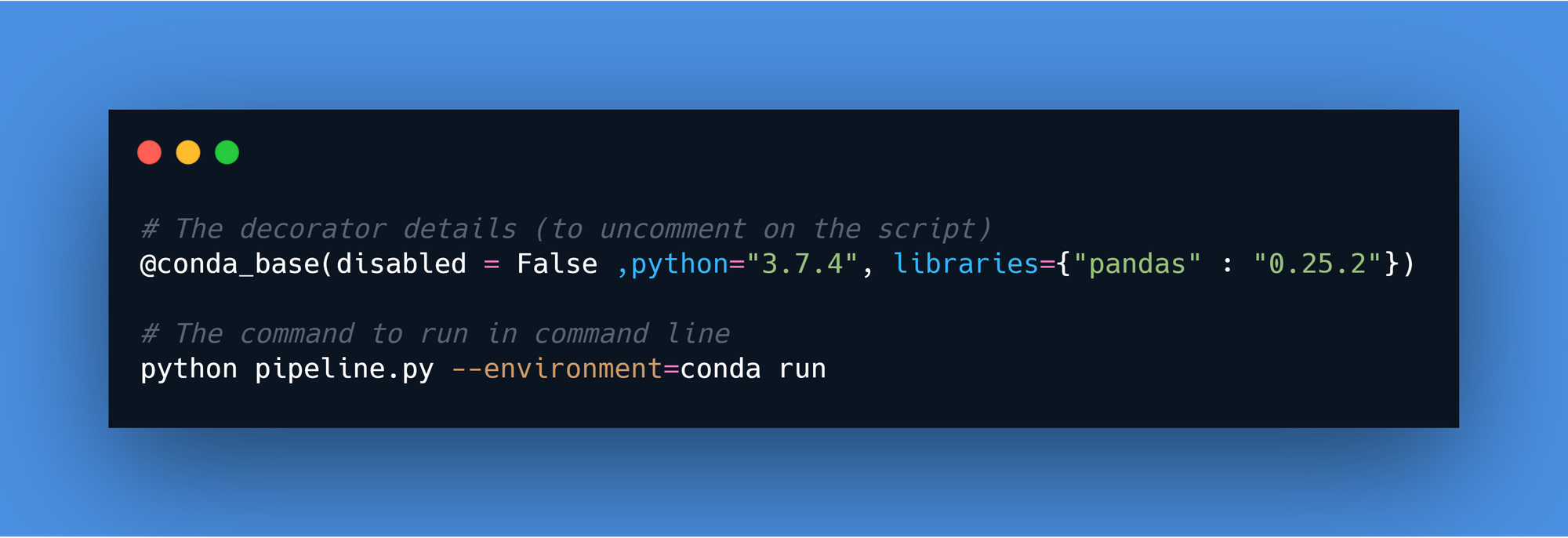
This decorator applied a new version of Python on the flow, in this case, 3.7.4, with a new version of Pandas (0.25.2). There is the log produced by the pipeline.
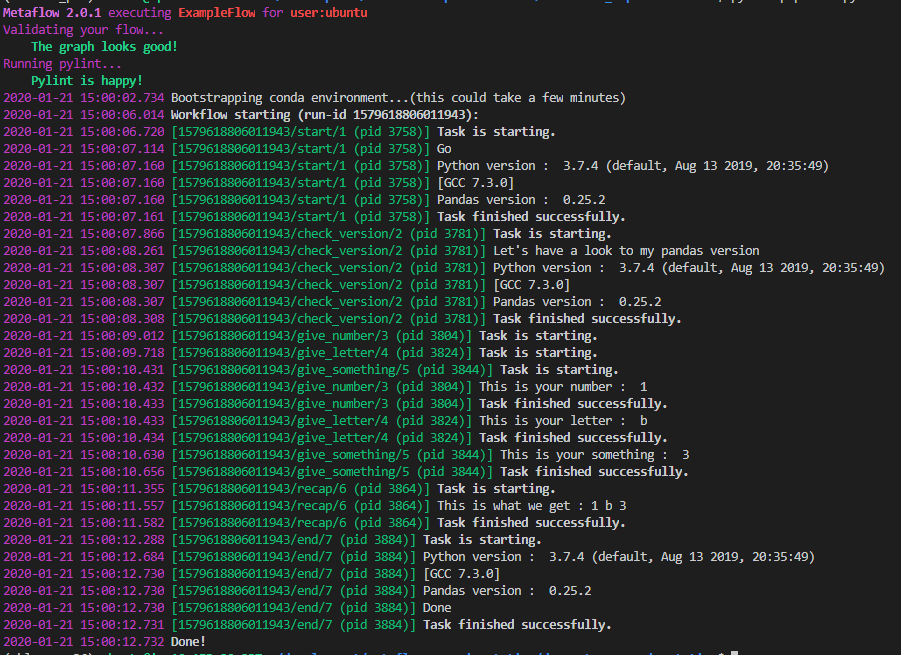
As I said, there is now a new version of Python/Pandas used to execute all the flow. To finish, let’s see the @conda decorator.
This one is like the @conda_base, but only for a step, in this case, I am modifying the python version to 3.6.8 just for this specific step (with a random version of Pandas, I know it looks stupid, but It’s just for test).
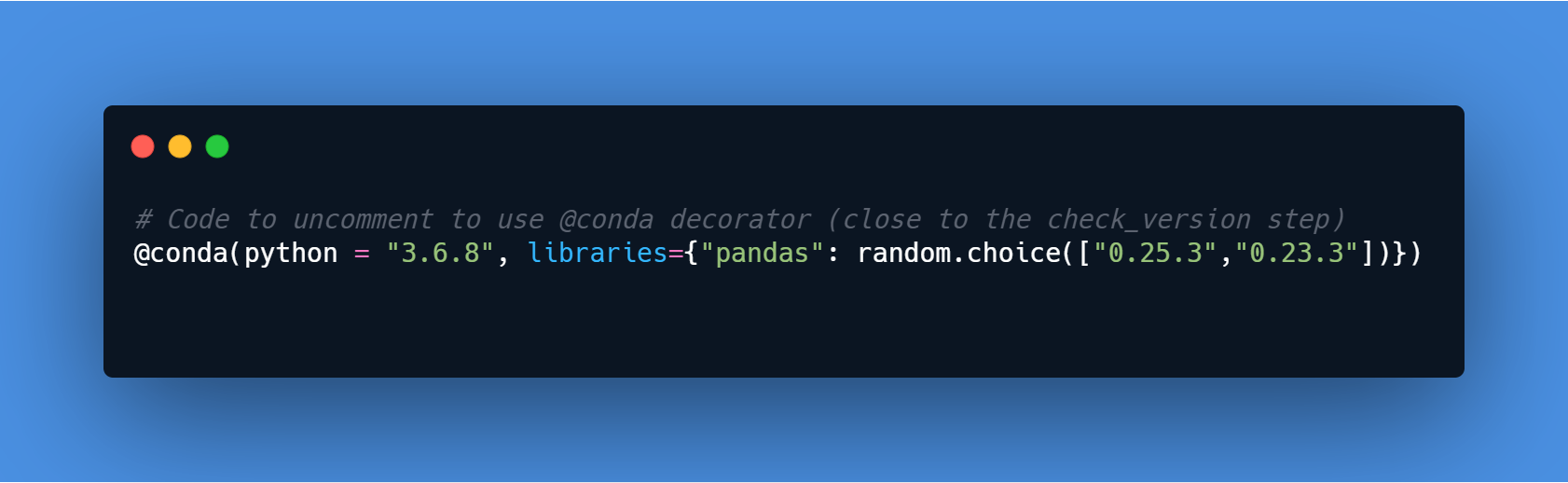
And in the log, we can see that there is a new version of Python/pandas applied just for the check_version step.
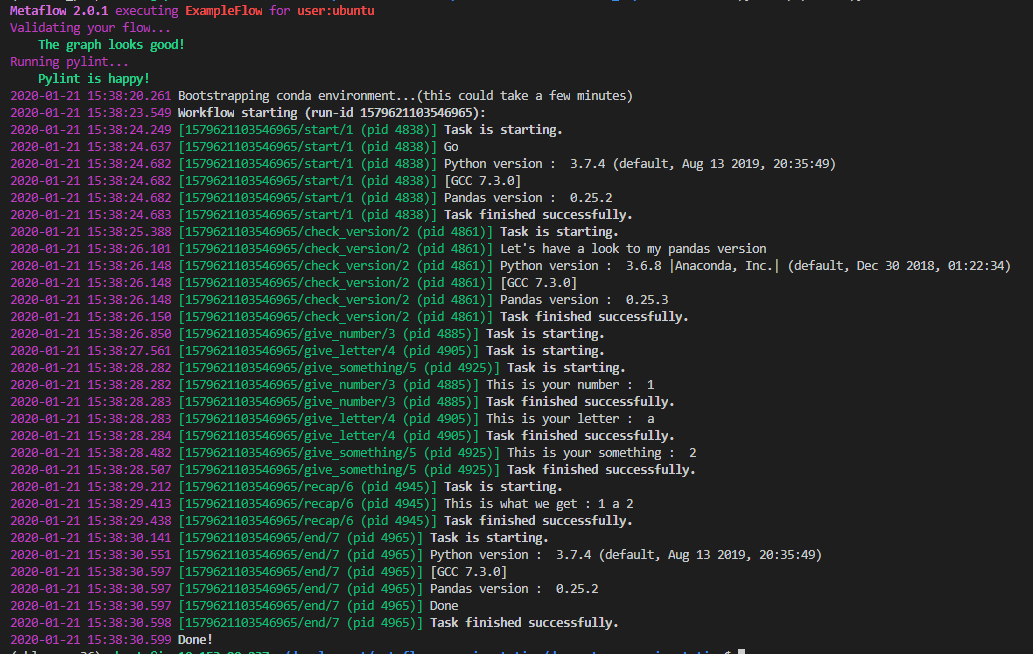
I think that this test illustrates the usage of Metaflow to version the environment used for the execution of a flow or a step. The strength of Metaflow is to offer the flexibility to a data scientist to set up precisely the environment needed to execute code without having to set up a conda environment or a container.
There is more than these decorators in the package like:
- The one for the execution like @retry,@timeout,@catch,@resources
- The AWS one (@batch) that I am going to come back to them later.
Let’s see a data science/machine learning flow designed with Metaflow.
Build an archetype predictor for Hearthstone with Metaflow
A few weeks ago, I built a dataset related to Hearthstone, the card game of Blizzard. I invite you to have a look at it if you don’t have a clear vision of the game.
One aspect that I avoided in the previous article was the notion of archetype. These archetypes are based on the hero selected and the cards in the deck, there is multiple kind of archetype, and some are most popular.
In the dataset presented in the previous article, 40% of the decks have no archetype associated, so I wanted to start to build an archetype predictor based on the card used (It’s a dummy system just to test the flow of Metaflow).
In the following figure, there is a representation of the flow that I designed to test Metaflow (the code is in the folder related to Hearthstone in this repository).

The idea of this flow is to build a Random forest predictor of the archetype based on the top cards of the archetype that we want to assign to the one that have no archetype. I think that the code is clear enough, so I am not going to enter too much in details of the execution because it’s not exciting. I am going to take time to analyze the result of multiple runs with the client of Metaflow.
Monitoring of the flow and executions
The data produced during the different executions of the flow are stored in a data store in a local storage (in a /metaflow hidden folder on your working directory). Still, all the results can be accessed directly in a notebook. I am going to put the “processing part” of the artifacts of the different runs in a gist.
The goal is to compute the time of execution, collect the first sample of the training set, and the information on the best model produced by the HPO (accuracy and parameters). There is a screenshot of the processing.

As we can see, there is a lot of information that is versioned during the execution of the flow. I am really like this versioning of all the data produced during a pipeline for reproducibility and debugging it’s excellent.
Let’s now have a look at the AWS part of Metaflow.
And the cloud ?
Metaflow gives you all the processes to set up your AWS environment in their documentation. Still, I am lazy, and they can give you access to an AWS sandbox (with restricted resources to test the features on the cloud) just by signing up on the website.
After a few days, you have access to the sandbox ( I would like to thanks again Metaflow support to have granted my access a little bit more longer to their sandbox to make some presentations around me).

To set up the connection to the sandbox is straightforward, just need to add a token in a command line of Metaflow. After that, all your backend is:
- Datastore on S3
- Metadata store in a database type like RDS
- Computation on your local machine or the AWS batch service
- Notebook in Amazon Sagemaker
Two options are used to access AWS computation from your local machine:
- Use the attribute --with batch with the run command, like that all your flow uses AWS batch as the computing resource
- If you want to execute only specific step on AWS, and using the power of your local machine for the other task, you can use the AWS decorator @batch at the declaration of your step
I found this approach of cloud management compelling and easy to use and the switch between local computation to cloud computation is straightforward. To illustrate the cloud computation, I just screenshotted the CPU usage on my instance that is running my Metaflow code versus the kind of run that I executed.
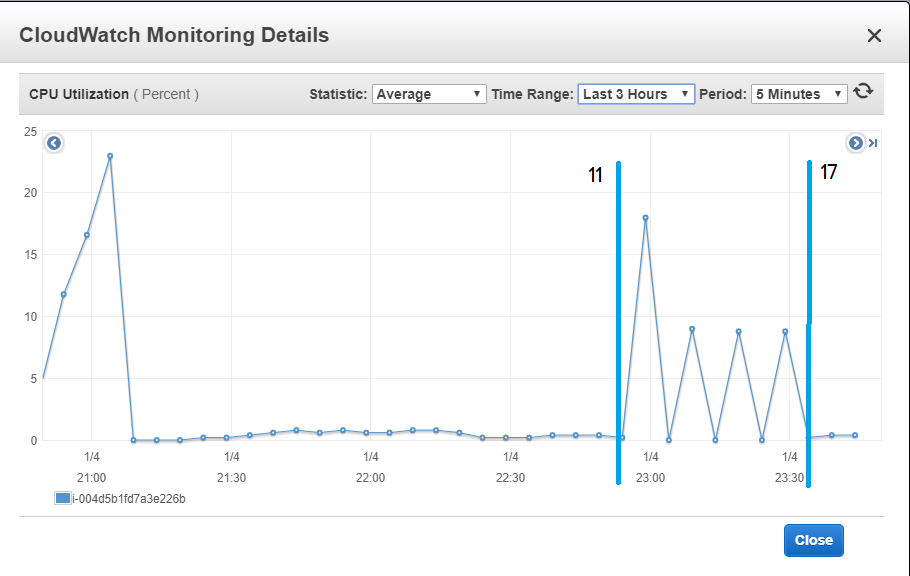
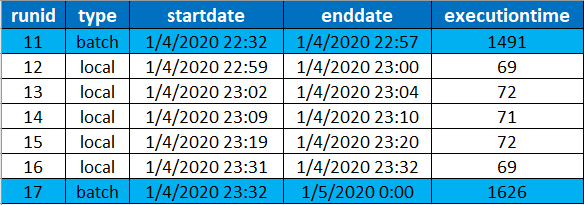
I think that it is a good illustration of the fact that my local machine is not used to do the computation versus the local run (between the boundaries of the run 11 and 17.
And now the final question on Metaflow can it work with mlflow.

Don’t cross the flows !?
No please do it, I added in the other script the mlflow layer to my HPO. I just am adding in my mlflow logs information related to my Metaflow run. There is a screenshot of the logs of mlflow.
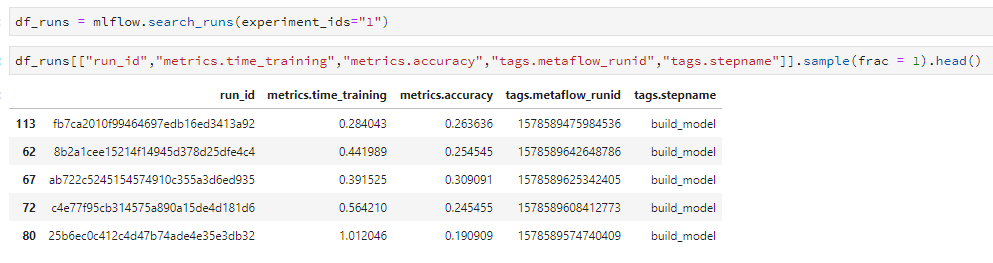
The two versioning framework seems to work great together. So today, we can do the monitoring of your pipeline with Metaflow, logs your model and do the deployment with mlflow on any cloud platform support.
Feedback
Metaflow is a framework that has been developing for data scientist it offers:
- Versioning of all the artifact produced in a machine learning DS pipeline
- An easy usage of the cloud and the possibility to easily parallelized job
It’s a great job that has been done by Netflix and open-sourced. More elements are coming on Metaflow like:
- The R package
- The ability to use AWS steps as a scheduler (but it’s not here yet, so I think that it shows that it is not a so easy technology to use).
- The model deployment with Sagemaker, they are going to cover another aspect of mlflow (on AWS).
The only drawbacks that I have on Metaflow are:
- The conda decorator is building a lot of conda environment in your python environment so it can look messy
- The framework looks very entitled to AWS so not open to other cloud platform (but on the GitHub seems that some people are trying to make it working for GCP for example)
- Spark seems totally out of the plan
I am going to follow the evolution in Metaflow, but honestly, the first try was good, and I am inviting you to try it and make your own opinion.







{kind=link}