
Initiation aux bases de données graphe avec neo4j et Beat Saber
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Une introduction à la base de données graphe Neo4j appliquée au contenu UGC de Beat Saber
Dans cet article, il y aura une introduction à la base de données graphe Neo4j, exploiter la technologie à des fins d’analyse et de recommandation.
Qu’est-ce qu’une base de données graphe ?
Une base de données graphe est caractérisée par les composants suivants :
- Nœuds
- Arêtes
Un nœud peut être défini comme l’entité dans le graphe, et il est défini par ses propriétés, ses arêtes qui sont les connexions entre les nœuds et qui peuvent contenir des propriétés aussi. La base de données graphe est très utile pour mieux comprendre les relations entre les individus et leurs interactions, peut-elle remplacer les autres bases de données ? Non, cela dépendra de votre cas d’utilisation (il n’y a pas de base de données unique pour toutes les gouverner).
Je suis un Pythoniste, donc en Python, il y a différentes façons d’utiliser/faire des bases de données graphe comme networkx (l’une des bibliothèques les plus populaires) par exemple, mais dans mon cas et pour cet article, je vais me concentrer sur l’outil fourni par neo4j.
J’ai commencé à utiliser neo4j dans mon précédent emploi chez EDF, pour un PoC autour des chatbots et je voulais vraiment écrire un article dessus. J’ai trouvé la suite de logiciels offerts par neo4j vraiment cool et facile à utiliser, mais pour faire cela, j’avais besoin de trouver un bon cas d’utilisation et nous y voilà.
Définition du cas d’utilisation
J’ai écrit il y a quelques semaines un article autour de la récupération d’informations musicales sur les chansons UGC (contenu généré par l’utilisateur) de Beat Saber et j’ai trouvé beaucoup d’informations intéressantes sur le site Web qui héberge les chansons.
Sur ce site Web, je peux collecter des données liées aux chansons et aux membres du site Web. Dans le cas d’une chanson, plusieurs éléments d’information peuvent être collectés (cf figure suivante).
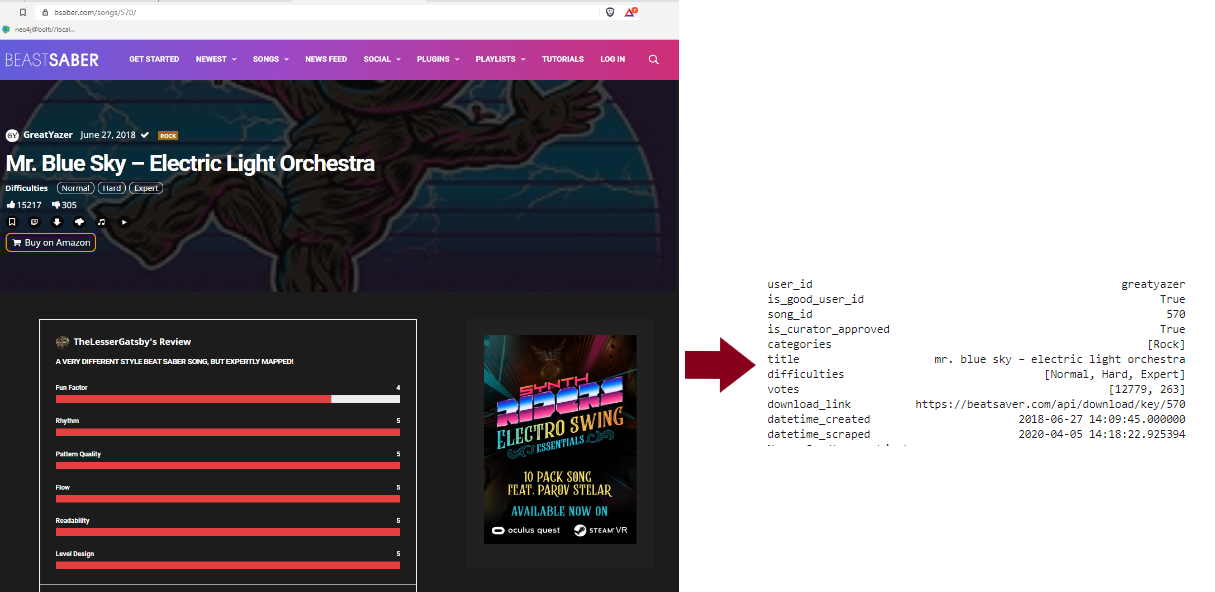
Il y a des informations comme :
- Le créateur (la date de création)
- La difficulté du niveau dans le fichier associé à la page
- Les votes positifs/négatifs
- Les catégories de la chanson (rock, pop, etc.)
- Si la chanson a été approuvée par un curateur (Label de qualité !?)
Pour un utilisateur, il y a aussi beaucoup d’informations collectées (cf figure)

Il y a des informations liées à :
- Les chansons que l’utilisateur a mises en favoris
- Les chansons que l’utilisateur a évaluées (Merci à @golbut pour les conseils d’attente)
- Qui sont ses amis sur la plateforme
- Quels utilisateurs sont suivis et par qui il est suivi (comme sur Twitter, etc.)
Comme nous pouvons le voir, il y a beaucoup d’informations et honnêtement, et ce jeu de données est en quelque sorte configuré pour construire des systèmes de recommandation.
Construisons la base de données graphe et faisons quelques analyses dessus.
Conception de la base de données
À propos de la configuration pour cette expérience, j’ai utilisé le neo4j desktop sur Windows pour déployer facilement des bases de données graphe et j’utilise une base de données graphe neo4j avec la version 4.0. Pour écrire tous mes nœuds et relations, j’utilise le package python neo4j.
Une chose importante pour accéder à la base de données, vous pouvez le faire par Python avec le package mentionné précédemment ou vous pouvez accéder à une application web pour exécuter votre requête directement sur votre navigateur par cypher (si vous appelez le bon port et avez la bonne authentification bien sûr).
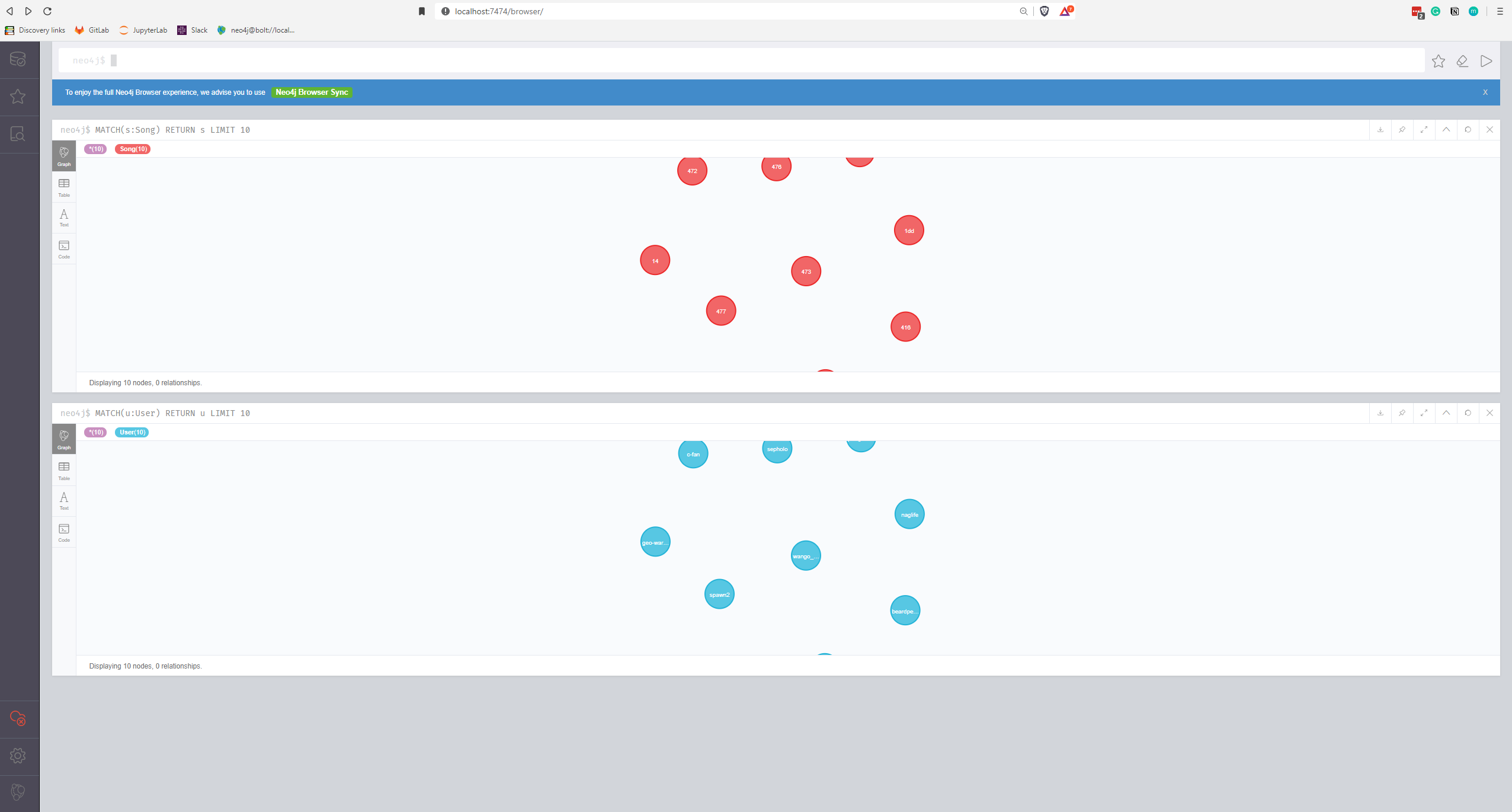
Maintenant, revenons à la conception du graphe.
Pour ce cas d’utilisation, il y aura deux types de nœuds, un pour l’utilisateur et un pour les chansons et le déploiement est assez facile, j’ai utilisé le script suivant par exemple pour déployer un nœud utilisateur.
En termes de relations, elles sont de différents types :
- BUILT pour définir la relation entre la chanson et le créateur
- IS_FRIEND_WITH pour définir l’amitié entre un utilisateur et un autre utilisateur
- IS_FOLLOWED_BY pour définir la relation de suivi entre un utilisateur et un autre utilisateur
- FOLLOWS pour définir la relation de suivi entre un utilisateur et un autre utilisateur
- BOOKMARKED pour définir la relation entre une chanson et un utilisateur, si l’utilisateur veut garder une trace d’une chanson, cela pourrait être pour une bonne ou une mauvaise raison
- REVIEWED pour définir la relation entre une chanson et un utilisateur, si l’utilisateur veut donner plus de détails sur une chanson par différents critères (cf image)

Dans le cas d’une relation, c’est très similaire à la déclaration de nœud, il suffit de construire la requête qui fera la connexion entre les nœuds (et vous pouvez ajouter des propriétés à la connexion comme pour un nœud).
Pour ce graphe, voici la configuration produite par les scripts :
- 111 176 nœuds
- 2 423 715 relations
Pour vous représenter l’organisation d’une portion du graphe, une simple requête a été exécutée sur le graphe pour accéder aux données d’un utilisateur spécifique.

Il y a une bonne visualisation des chansons mises en favoris par cet utilisateur, et la connexion avec un autre utilisateur.
Commençons à faire quelques analyses sur ce graphe.
Plongée dans le graphe
Un bon aperçu pourrait être de voir le nombre différent d’entités dans le graphe.
La requête pour demander cette information est assez longue, facile à comprendre mais longue. Une fonctionnalité intéressante de la base de données graphe neo4j est que certaines bibliothèques peuvent être installées et il y en a une intéressante appelée APOC (pour Awesome Procedures On Cypher) qui est une collection de procédures pour analyser les données efficacement.
Cette façon de demander des informations est plus efficace (1s pour le brut et 5ms pour la version APOC). En termes de résultats, il y a un compte d’éléments par entité.

Ce tableau donne une bonne vue des entités dans le graphe :
- Plus d’utilisateurs que de chansons, mais toujours beaucoup de chansons
- l’étude de la relation BUILT est une illustration que peut-être le scraping des chansons/utilisateurs n’est pas parfait (et oui je sais qu’il y a quelques problèmes pour collecter le user_id dans la page de chanson).
- Les relations ami/suivre/suiveur ne sont pas trop nombreuses (ce n’est pas un réseau social, c’est un site Web pour partager des niveaux pour BeatSaber…)
- Les utilisateurs ont mis en favoris beaucoup de chansons et ont construit plusieurs relations (plus de 2 000 000) et cela a plus de sens pour un site Web qui héberge des niveaux pour BeatSaber.
- La relation REVIEWED, le nombre est assez petit par rapport aux favoris, mais les connexions nécessitent plus d’engagement (écrire une critique) que juste ajouter une chanson à vos favoris
L’analyse des utilisateurs (et ce sera la même chose pour les chansons) est une agrégation des relations par utilisateur afin de compter le nombre de relations liées à chaque utilisateur.
Du point de vue de l’utilisateur, la distribution des relations liées aux amis/suivre/suivi est très petite (la majorité des utilisateurs n’en ont pas), même remarque pour les critiques, mais pour les favoris, c’est plus intéressant.
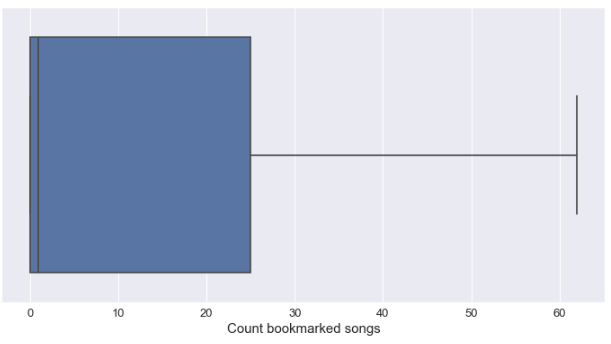
La plupart des utilisateurs (plus de 50%) ont plus d’une chanson en favoris et plus de 25% ont plus de 20 chansons en favoris. La fonctionnalité de favoris est utilisée par une majorité d’utilisateurs sur le site Web.
Pour la chanson, la même logique que précédemment, voici le code pour faire l’agrégation.
L’analyse se concentrera sur :
- Le nombre de fois que la chanson a été mise en favoris
- Le nombre de votes positifs/négatifs et de votes en général
(le nombre de critiques a été ignoré car la majorité des chansons n’ont pas de critique)
Dans le graphique suivant, il y a une représentation de la distribution des informations.
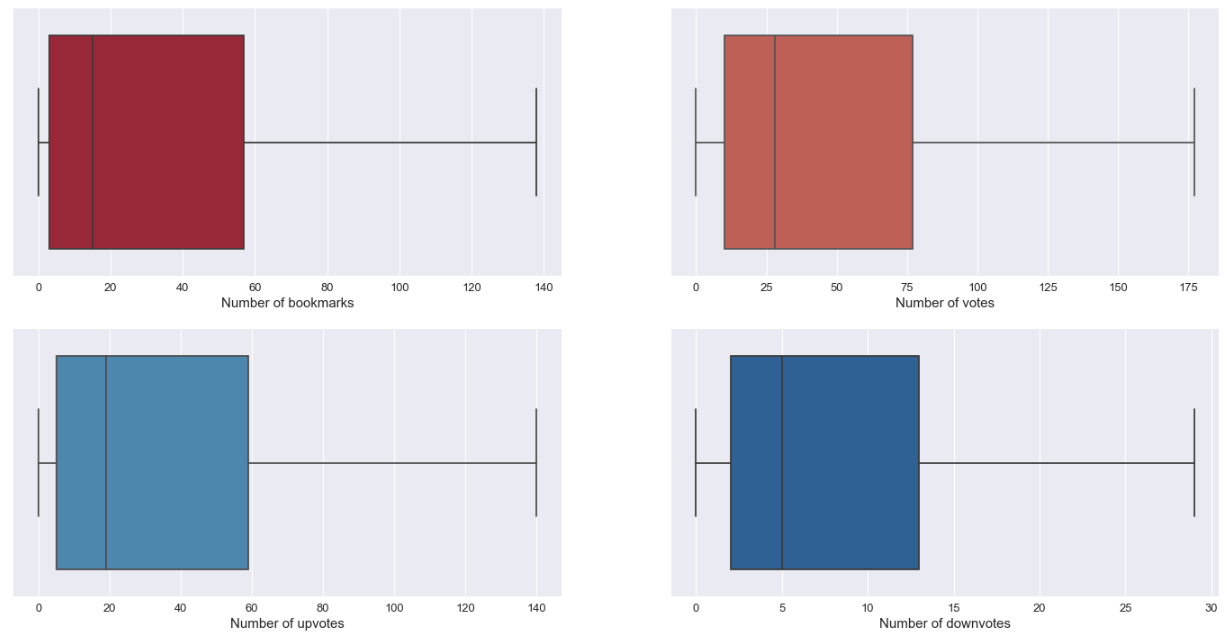
L’interaction entre l’utilisateur et les chansons sur les votes et les favoris est intéressante :
- La plupart des chansons ont été mises en favoris au moins une fois
- La fonctionnalité de votes semble moins utilisée que les favoris, mais c’est toujours quelque chose
- Il y a plus de votes positifs sur les chansons que de votes négatifs (les gens semblent plus intéressés à donner un vote positif qu’un vote négatif)
Avec ces informations sur les nœuds et les arêtes, commençons à construire des systèmes de recommandation.
Construire un système de recommandation à partir d’une base de données graphe
L’objectif de cette tâche est de construire un système qui aidera les gens à trouver des personnes à suivre ou à devenir amis.
La façon la plus simple pourrait être de faire simplement une recherche simple sur le graphe de l’ami de votre ami (ou le suivi de votre suivi).
C’est vraiment simple à mettre en place, pas d’algorithme, juste une simple navigation sur le graphe, mais il y a encore quelques limitations à cette méthode :
- Besoin d’avoir au moins un ami qui a des amis pour que ce soit utile (pour ce jeu de données, ça pourrait être difficile)
- Il n’y a pas de vrai classement sur cette méthode, c’est plus comme “vous êtes dans le cercle de connexion avec ces personnes”
Dans ce cas d’utilisation, je pense que quelque chose d’un peu plus intelligent peut être construit et pour cela, demandons de l’aide à Paul Jaccard.
Le système de recommandation utilisera la similarité de Jaccard pour déterminer la similarité entre deux utilisateurs basée sur les chansons qui ont été mises en favoris. Pour rendre quelque chose plus formel, si notre jeu de données ne contenait que 10 chansons, il y a une représentation des relations de favoris entre les deux utilisateurs A et B.
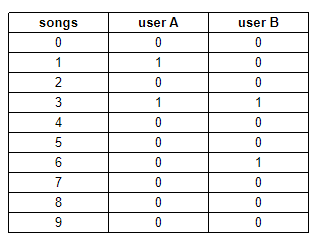
Pour calculer la similarité de Jaccard (basée sur 1, 2), vous devez calculer
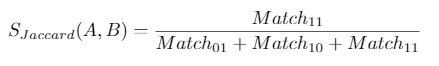
Avec :
- Match11 : le nombre de chansons mises en favoris par A et B
- Match01 : le nombre de chansons mises en favoris seulement par B
- Match10 : le nombre de chansons mises en favoris seulement par A
Donc dans ce cas :
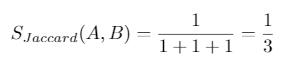
C’est une mesure de similarité, peut-être pas la meilleure, mais toujours un bon début et devinez quoi, il y a une implémentation dans une bibliothèque de neo4j appelée Graph Data Science (GDS) et c’est vraiment facile à utiliser.
Ce script calcule la similarité de Jaccard pour l’utilisateur défini par user_id et recherche l’utilisateur le plus proche basé sur leurs favoris. Le temps nécessaire pour calculer les recommandations est très similaire à l’ami d’amis (environ 2 secondes).
Récapitulons les résultats.
Retour d’expérience et prochaines étapes
Dans cet article, je voulais dessiner le grand tableau sur la base de données graphe et l’appliquer à certaines données personnelles. Honnêtement, c’est vraiment amusant de travailler avec une base de données graphe (de neo4j), le langage pour construire la requête est assez graphique pour rechercher la connexion et il y a beaucoup de bibliothèques pour soutenir les développeurs à exécuter des procédures complexes (APOC et graph data science).
Ma prochaine étape avec ce jeu de données est de l’utiliser dans un contexte plus classique/relationnel pour tester des algorithmes de recommandation/clustering avec différents types d’évaluations (implicite/favoris et explicite/évaluées).
Avec la base de données graphe, je vais plonger plus dans la fonctionnalité d’APOC et GDS pour tester de nouveaux algorithmes (comme une détection de communauté par exemple) et pourquoi ne pas essayer de faire des expériences comme dans le livre Graph algorithms.
Références
- networkx — networkx.github.io
- neo4j — neo4j.com
- neo4j desktop — neo4j.com
- package python neo4j — neo4j.com
- APOC — neo4j.com
- Paul Jaccard — Wikipedia
- 1 — Wikipedia
- 2 — manning.com
- Graph Data Science — neo4j.com
- algorithmes — neo4j.com
- Graph algorithms — neo4j.com