
Construire un classifieur d'images avec fastai
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
J’ai récemment commencé à prototyper un classifieur d’images au travail, et ce travail m’a conduit au package fastai que j’avais dans mon backlog de bibliothèques depuis longtemps. Il y a deux ans, j’ai construit un pipeline pour collecter les données de turo pour construire un classifieur d’images, et je ne l’ai jamais utilisé, donc c’est le moment parfait pour lier la bibliothèque fastai et le jeu de données pour écrire un court article.
Configuration des données
J’ai construit un scraper pour le site web Turo (Airbnb pour la location de voitures). En conséquence, j’avais une quantité décente d’images avec plus de 57 000 pour environ 51 fabricants de voitures.

Cependant, pour l’évaluation du modèle, je ne voulais pas prendre d’images de celles collectées il y a deux ans, donc j’ai décidé d’en construire de nouvelles.
Ces jeux de données sont composés des photos de 100 offres de la ville d’Austin scrapées à différentes dates :
- testing 1 : 6 septembre
- testing 2 : 13 septembre 2021
Sans sélection spécifique sur le type de voiture, juste celle disponible quand la recherche a commencé.
Comme mentionné dans mon article original, ces données sont brutes, donc le sujet n’est pas clairement défini (comme plusieurs voitures dans l’image, ou la voiture n’est pas centrée) ; j’ai reconstruit pour cela un recadreur pour sélectionner la voiture sur l’image et écarter les images qui contiennent plus d’une voiture ou pas de voiture pour le classifieur d’images qui analysera l’image (confiance sur la détection supérieure à 95%).
Il y a une illustration du processus avant/après du recadreur (et le code est ici)

Avec cette approche, nous avons quatre jeux de données (deux bruts et deux recadrés) disponibles pour les tests ; plongeons dans le framework pour prototyper le classifieur.
Fastai: Making neural nets uncool again
Le titre n’est pas de moi mais le slogan sur le site web fastai.
Le fastai est une initiative créée par Jeremy Howard et Dr. Rachel Thomas qui sont des scientifiques très réussis, et je vous conseille de regarder l’une de leurs conférences ; c’est toujours super intéressant (jetez un œil à la section about si vous voulez plus de détails sur leurs expériences). Je dirais qu’il y a deux piliers à cette initiative qui veut démocratiser le deep learning au maximum de personnes dans le monde entier :
Avant de parler de ces piliers, si vous n’êtes pas familier avec le concept de deep learning, je vous invite à regarder cette excellente vidéo de 3blue1brown sur le sujet.
Les cours sont principalement maintenant soutenus par le contenu de ce livre. Vous pouvez trouver une version notebook sur Github ici, ces cours sont excellents, et je vous invite à les suivre comme une bonne introduction pour le deep learning, plus orientée codeur que mathématiques par le prisme de l’utilisation du framework fastai.
Le framework était, pour moi dans la première lecture, comme le Keras de PyTorch (parce que c’est en quelque sorte construit au-dessus de PyTorch comme Keras l’était pour TensorFlow au début). Après les tests avec la bibliothèque, je changerai ma définition pour un wrapper autour des fonctions PyTorch et une fonction utilitaire de gestion des données (peut-être PyTorch lightning est plus le Keras de PyTorch, mais je n’ai jamais creusé dessus).
Le package est excellent de toute façon (et je ne veux pas commencer à entrer dans une guerre d’église Tensorflow VS Pytorch) ; pour ce test, mon premier focus a été sur ce chapitre du livre où vous commencez à prototyper un classifieur d’ours.
Il y a deux parties dans ce notebook, la première est l’accès aux données et l’augmentation des données, et la seconde est la construction du modèle :
- Accès aux données et augmentation des données : cette partie concerne les dataloaders et les datablocks (modèles de chapeaux pour les dataloaders). Le dataloader aidera à interpréter les emplacements de fichiers et à faire des augmentations de données si nécessaire (le notebook est super clair, donc plongez dedans si vous voulez comprendre la fonction plus). Pour cela, je vais aller avec les dataloaders suivants
cars = DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=42),
get_y=parent_label,
item_tfms=Resize(128))
cars = cars.new(item_tfms=Resize(128), batch_tfms=aug_transforms(mult=2))
dls = cars.dataloaders(path, bs=16)Je vais avec la même transformation finale que dans le notebook (avec seulement une différence de taille de lot différente parce que j’ai rencontré des problèmes à un moment donné).
- Pour la partie ML, rien de différent que sur le notebook, mais je vais prendre du temps pour expliquer les différentes fonctions.
learn = cnn_learner(dls, resnet34, metrics=[error_rate])
learn.fine_tune(4)Il y a deux fonctions dans ce snippet :
- cnn_learner : cette fonction est pour “construire un convnet” à partir du dataloader dls et avec l’architecture resnet18 et pour le construire utilisé le error rate comme fonction de perte pour améliorer le modèle pendant l’entraînement. Cette description peut sembler un peu complexe (la partie convnet), mais je vais prendre du temps dans la partie suivante pour définir (ou donner des clés) un convnet mais gardez à l’esprit que c’est une famille d’algorithmes de deep learning. La sortie de cette fonction est cette variable learn qui est le modèle.
- Learn.fine_tune : cette fonction du modèle (héritée de la classe originale Learner du framework fastai) est là pour affiner le convnet à notre but, dans ce cas, cette prédiction du fabricant de la voiture avec 51 classes.
Alors maintenant regardons comment le modèle performe dans deux configurations :
- Avec un échantillon des données (10%)
- Avec le jeu de données complet
La métrique d’évaluation va être :
- Précision moyenne de la prédiction sur les ensembles de test : si la prédiction sur le fabricant est la bonne (1) ou pas (0) sur tous les enregistrements (plus élevé est mieux)
- Temps d’entraînement : temps pour entraîner (fine-tune est plus précis, je pense) du modèle en secondes
Rien de fantaisiste, mais je pense que c’est parfait juste pour commencer à prototyper quelque chose. Pour le temps d’entraînement il y a les résultats :
- Échantillon : 192 sec
- Complet : 2002 sec
En termes de précision pour les différents ensembles de test, il y a les métriques :
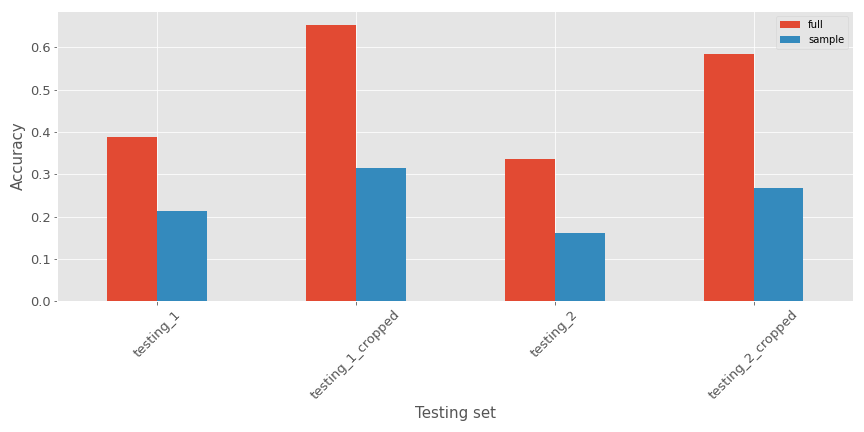
Comme prévu :
- Les modèles performent moins bien sur l’ensemble de test non recadré (attendu car les données d’entraînement ressemblent plus à celui recadré)
- Le modèle avec le jeu de données complet semble performer mieux sur tous les ensembles de test
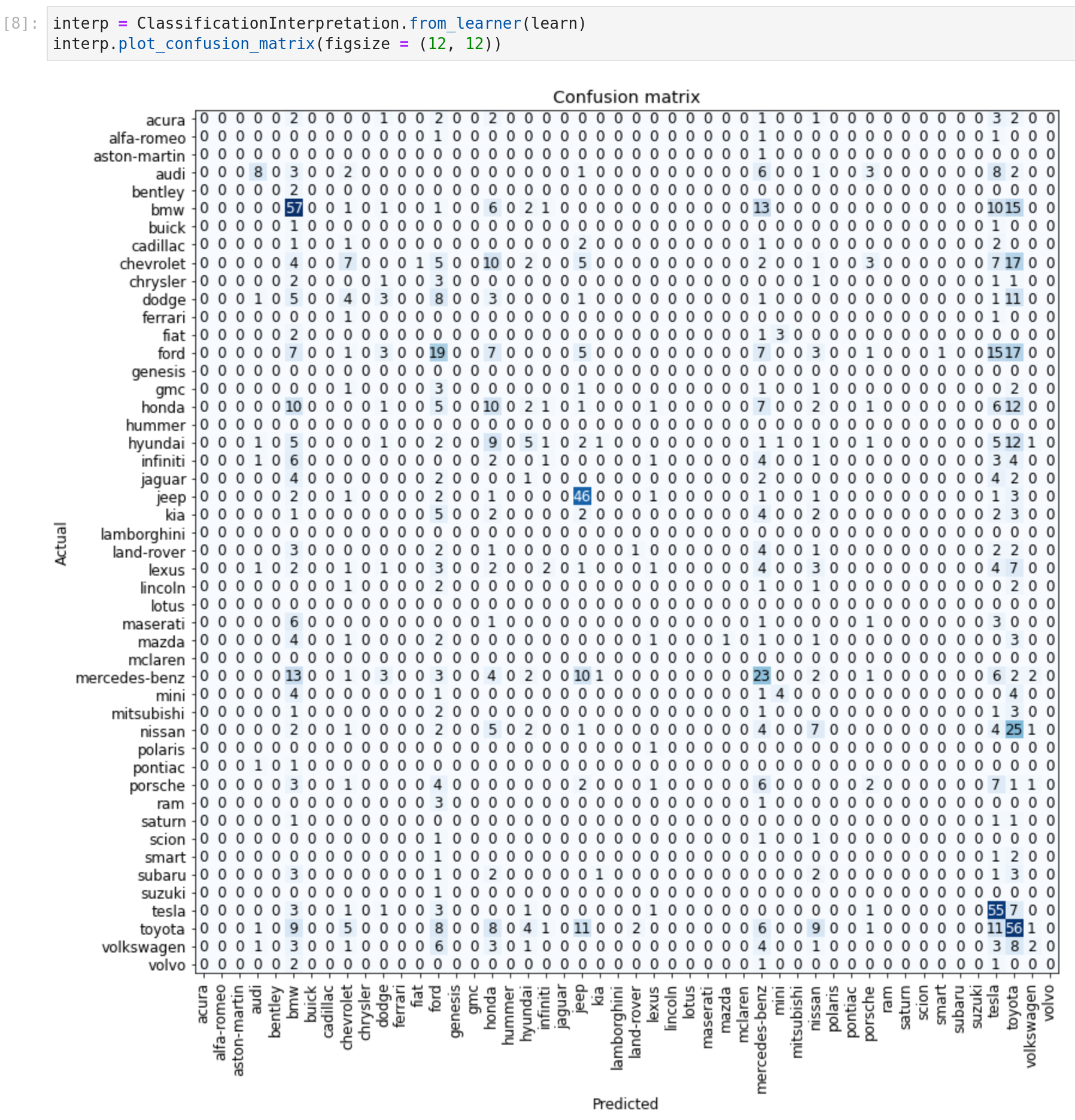
Le package contient d’autres fonctions pour plonger plus dans la sortie du modèle comme par exemple :
- Tracer la matrice de confusion liée au classifieur
- Obtenir les images avec la plus grande erreur/perte

Donc il y a une première version intéressante, mais pouvons-nous la rendre meilleure.
Réseau de neurones à convolution et recherche de grille
Pour mieux comprendre, je vais expliquer toutes les théories derrière ce type de réseau de neurones… ou pas. J’ai une ressource parfaite qui fera un meilleur travail que moi pour expliquer ; si vous ne connaissez pas encore, Brandon Rohrer construit une très grande collection de cours autour du ML, et il y a une leçon sur CNN, avec un récapitulatif Youtube.
Les principales couches de ce genre de modèle sont :
- Couches de convolution
- Couches de pooling
- Couches Relu
Il y a une “version simplifiée” du cours de Brandon Rohrer d’un CNN (succession des différentes couches)
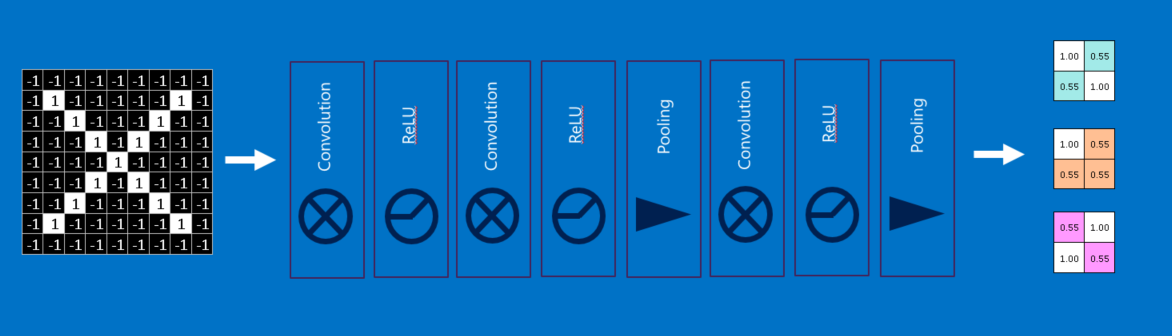
Donc j’espère que cet aperçu de CNN vous a donné les bonnes informations pour comprendre la structure ; si vous voulez une explication fastai plus sur CNN, je vous invite à regarder ce chapitre du livre fastai avec une explication plus pratique.
À partir du code original du livre, l’architecture utilisée était resnet18 ; si vous voulez une explication sur les différents resnet (qui sont juste une sous-famille de CNN qui existe je vous invite à jeter un œil à :
- Cet article de Kenichi Nakanishi qui aborde la conception de resnet (avec fastai).
- Ce notebook sur le livre
Commençons à ajuster le modèle que nous avons utilisé dans la section précédente en modifiant quelques paramètres :
- L’architecture
- Le nombre d’époques
- Le taux d’apprentissage de base
Pour faire la recherche plus rapide, je n’utiliserai que les données d’entraînement échantillonnées.
Dans ce graphique de coordonnées parallèles, vous pouvez voir l’impact des divers paramètres sur la précision du modèle.
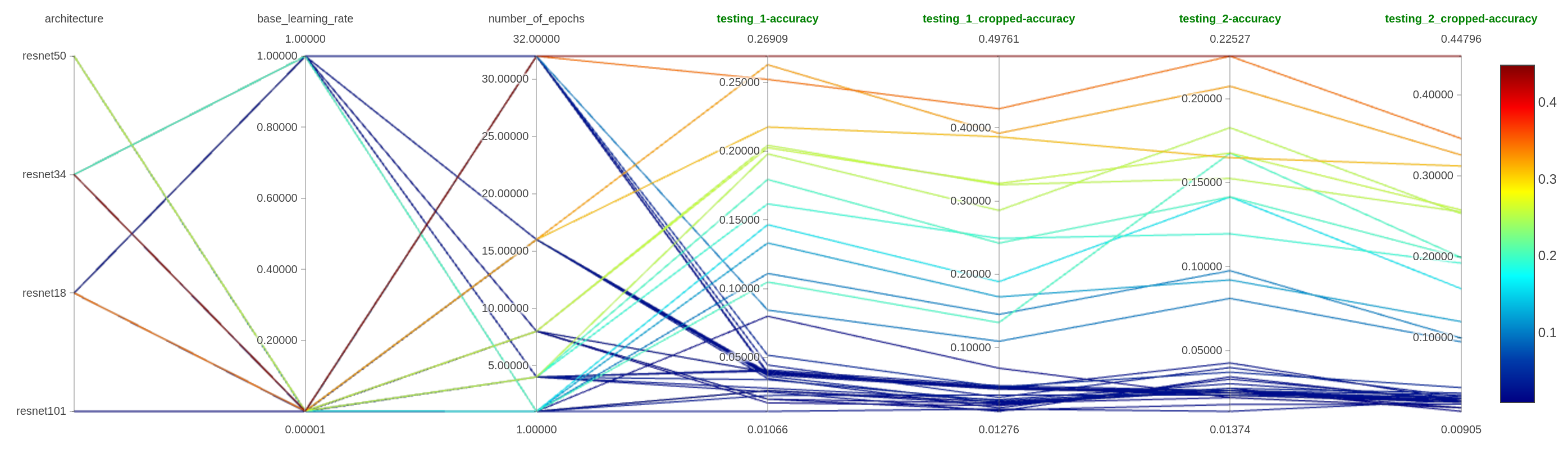
Tous les tests avec resnet50 et resnet101 se sont arrêtés prématurément pour des problèmes de mémoire sur mon GPU.
Comme nous pouvons le voir :
- Exploiter les différentes architectures semble un excellent paramètre à ajuster (dah), mais plus x sur le resnetx semble plus de problèmes
- Le nombre d’époques est également essentiel (dah) ; il y a un mécanisme pour arrêter l’entraînement si le modèle ne semble pas apprendre basé sur l’évolution de la fonction de perte.
- Pour le taux d’apprentissage, il semble que des valeurs plus petites sont plus efficaces (dah)
Je vais exécuter une expérience finale sur le resnet en appliquant le base_lr de la méthode lr_find (0.002, semble une bonne valeur de la fonction) sur un modèle basé sur resnet34 avec l’ensemble de données entier et 32 époques. Il y a une comparaison de la précision des différents modèles (j’ai ajouté le meilleur modèle de la recherche de grille et l’expérience finale)
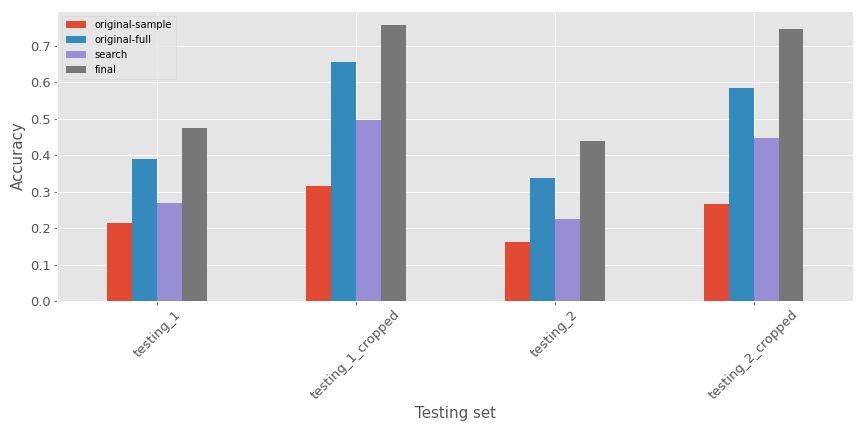
Maintenant nous avons cela semble avoir une précision décente ; si vous voulez utiliser ce modèle ajusté, vous pouvez le trouver ici avec un notebook pour commencer à l’utiliser, il y a un aperçu du résultat.
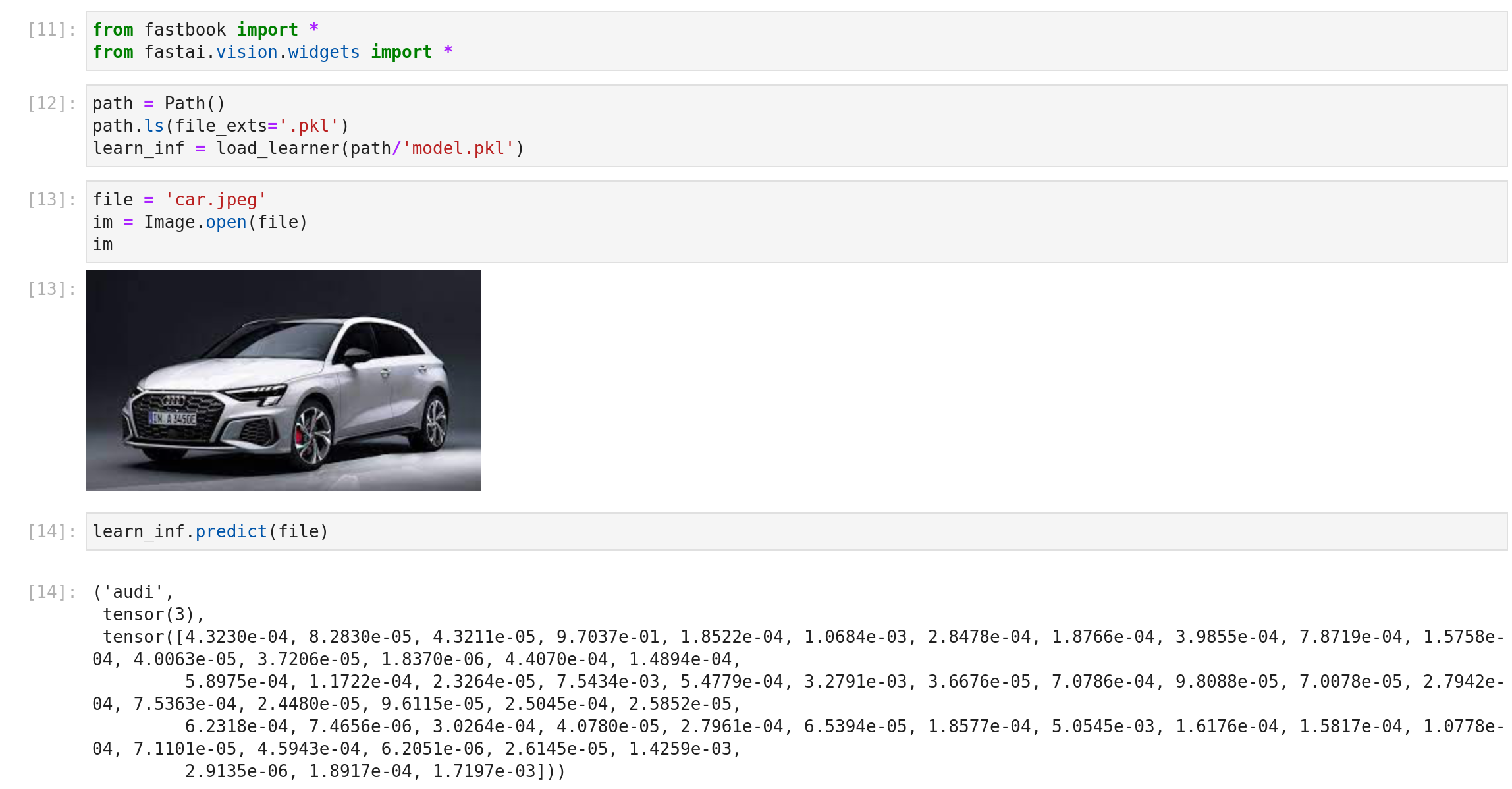
Tellement satisfaisant, profitez !!!
Conclusion
Cette expérience a été convaincante ; j’ai un premier modèle qui peut convenir à mon besoin pour ma preuve de concept ; bien sûr, ce n’est pas parfait, mais c’est toujours une bonne base de référence que je peux itérer. Si j’avais plus de temps et de motivation, il y a quelques choses que j’aurais essayées (ou essayerai) :
- Travailler sur le dataloader et tester l’impact de l’augmentation des données et du redimensionnement sur l’efficacité du modèle ; construire un modèle est une chose, mais le traitement des données est, je pense, également important
- Ce jeu de données est super déséquilibré, essayer de gérer cela
- Utiliser d’autres métriques pour l’évaluation, la précision est une bonne chose, mais il y a bien plus de métriques qui pourraient être pertinentes que celle-ci (mais toujours un bon départ)
- Prendre plus de temps pour enquêter sur d’autres architectures
- Déployer le modèle comme application web pour le rendre disponible pour tout le monde (je ferai peut-être cela à un moment donné #streamlit)
Pour fastai, l’expérience était excellente. Je viens juste de gratter le package. Il y a des fonctions excitantes autour du texte, des données tabulaires et de la recommandation (avec collab) que j’utiliserai plus tard dans l’année. Je conseille aux gens de l’essayer pour découvrir des systèmes de deep learning comme un classifieur d’images.
Références
- Site web fastai — fast.ai
- Page about fastai — fast.ai
- Cours fastai — fast.ai
- Framework fastai — GitHub — GitHub
- Deep Learning for Coders — Livre O’Reilly — oreilly.com
- fastai fastbook — GitHub — GitHub
- PyTorch Lightning — pytorchlightning.ai
- Chapitre 02 du livre fastai — production — GitHub
- Notebook crop_raw_images — GitHub
- Documentation cnn_learner — documentation
- Documentation fine_tune — documentation
- Brandon Rohrer — Collection de cours e2eml — e2eml.school
- Chapitre convolutions fastai — GitHub
- Exploration des architectures CNN avec fast.ai (Towards Data Science) — Medium / Towards Data Science
- Chapitre resnet fastai — GitHub
- Documentation lr_find — documentation
- Notebook use_car_classifier — GitHub