
Concevez et versionnez votre workflow ML avec DVC (compétition Kaggle)
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Depuis quelques mois, je voulais tester DVC, un toolkit de versioning pour les projets ML construit par iterative. Je l’ai essayé un peu chez Ubisoft pour voir comment cet outil pourrait s’intégrer dans notre workflow actuel pour notre plateforme ML, mais j’avais le sentiment de n’avoir fait qu’effleurer la surface de cette bibliothèque. Donc, il y a quelques semaines, Kaggle a ouvert une compétition autour de la conception de compétition Kaggle où chaque mois (pendant cinq mois), la meilleure compétition sélectionnée par les organisateurs gagnait un prix pour son originalité et son organisation, alors pourquoi ne pas utiliser cela comme prétexte pour tester DVC dans ce contexte.
Conception de la compétition Kaggle
Pour ma soumission à cette compétition, j’ai décidé de construire une compétition communautaire autour des images et, plus précisément, de prédire l’attrait d’une image uniquement en fonction de ses attributs visuels. Cette idée ne vient pas de nulle part mais d’une précédente compétition organisée par Petfinder.my sur Kaggle ; l’objectif de la compétition était de prédire l’attrait de l’image d’un animal de compagnie en fonction de l’image et d’informations supplémentaires (curées manuellement).
Cette compétition était intéressante à regarder (jetez un œil à la section discussion), et j’ai eu du plaisir à y participer (découvert quelques astuces pour l’analyse d’images). Mais de cette configuration, je pense que cette compétition a une plus grande utilité que de simplement prédire l’attrait d’une image mais était aussi là pour être utilisée pour construire des systèmes pour conseiller le photographe de l’animal (avec les informations supplémentaires qui étaient binaires) pour améliorer sa photo. Je voulais rester simple et me concentrer sur la prédiction d’attrait pour ma compétition, mais j’avais besoin de trouver un jeu de données approprié pour le faire.
Sur mon backlog de jeux de données pour mes projets (professionnels ou personnels), j’avais un jeu de données d’Unsplash autour des images.

Il y a une version lite en open-source et une version complète où vous devez demander l’accès ; je vais me concentrer uniquement sur la lite. Il y a un lien vers des images (lien téléchargeable) sur ce jeu de données et beaucoup d’informations sur les recherches, descriptions d’images, couleurs et interactions. Pour construire ma compétition, j’ai décidé de garder ma sélection sur les images et les interactions (vues, téléchargements).
Et pour conclure la conception de la compétition, la métrique d’évaluation sera le RMSE, qui est très courant pour ce genre de problème (et dans la compétition Pawpularity).
Commençons à construire le jeu de données pour la compétition.
Construire les jeux de données pour la compétition
La structure de la compétition est simple, et la documentation est claire. L’objectif des jeux de données est d’avoir des jeux de données d’entraînement et de test avec des fichiers supplémentaires comme des images dans le cas de cette compétition.
Construire les jeux de données est simple, mais il y a plusieurs étapes définies dans le diagramme suivant.
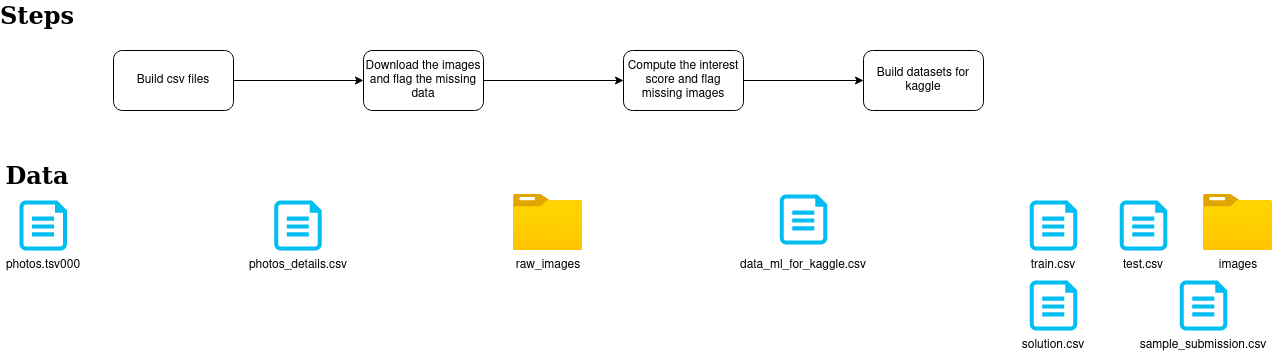
Le flux est très simple avec :
- une première étape consiste à sélectionner le tsv avec les informations précieuses liées à l’image et aux interactions vers un fichier CSV
- une deuxième étape consiste à télécharger les images d’Unsplash et à les stocker dans un dossier (avec leur identifiant d’origine)
- une troisième étape (qui était la plus lourde) pour calculer le score d’intérêt (équivalent à l’attrait de la compétition Pawpularity), détecter les images manquantes et construire un nouvel identifiant
- la dernière étape consiste à construire les fichiers et à reformater le jeu de données selon les exigences de Kaggle (pour le dossier d’images, il y a un fichier zip pour les images d’entraînement et les images de test, cela aide pour le téléchargement sur Kaggle)
Les différentes étapes sont une compilation de notebooks ; je ne les partagerai pas car cela peut impacter la compétition (et pas parce qu’ils sont un désordre). Pendant le développement de ce flux, j’ai décidé de tester DVC pour utiliser ce flux comme cobaye pour les fonctionnalités de versioning de données de l’outil. DVC est simple à installer avec la commande suivante.
pip install dvc #original install
pip install "dvc[s3]" #install with aws dependencies (be careful on it, I had to do some manual install of s3fs)J’ai ajouté le dernier composant car je voulais utiliser un bucket s3 comme stockage distant, mais le versioning local aurait pu fonctionner parfaitement. Après avoir suivi le tutoriel sur le site web de DVC sur la gestion des données, la commande la plus critique était la suivante.
dvc init # to init your DVC project
dvc add file/folder # to add a new file folder to your DVC project
dvc push # to push chnages to your dvc projectAu premier regard de ces commandes, DVC ressemble beaucoup à Git en nommant l’étape avec les actions init et add, et DVC n’a pas volé le titre de Git pour les projets ML. Cependant, je serai plus critique sur l’aspect git. Je l’appellerai un **module complémentaire Git pour les projets ML, **et les deux dernières commandes m’aideront à faire valoir mon point. Les deux dernières commandes sont équivalentes à initier la présence de ces nouvelles données dans le projet. Après leur exécution, il y a aussi un ajout de fichiers au projet.
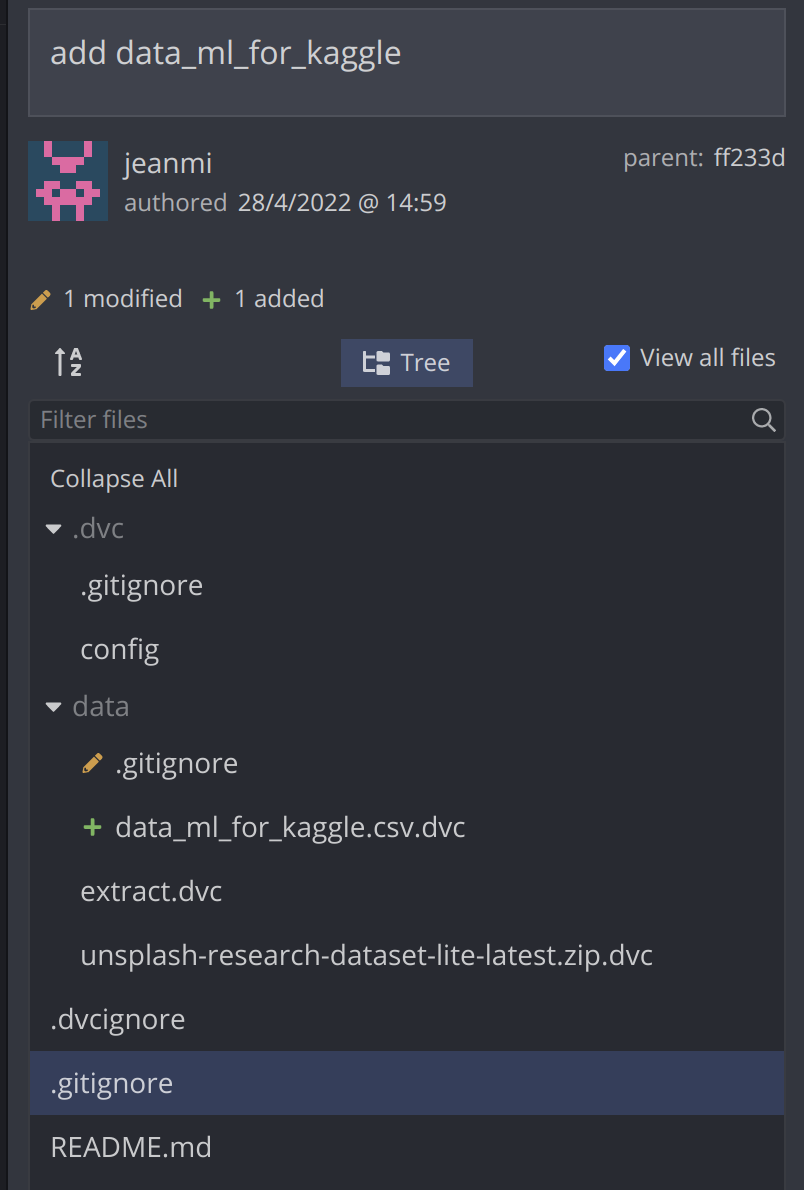
Lors de l’ajout d’un nouveau fichier dans le projet avec la commande dvc add data/data_ml_for_kaggle.csv, il y a une mise à jour d’un gitignore lié au dossier de données et un fichier .dvc ajouté au dépôt Git qui contient des détails sur le nouveau fichier dans le stockage distant.
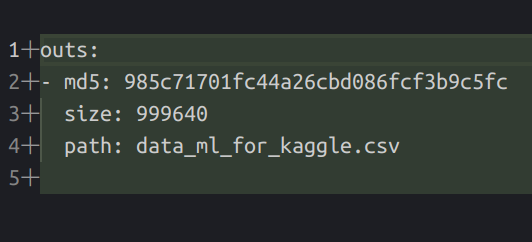
Cette approche offre la possibilité de se concentrer uniquement sur les informations essentielles des données (son emplacement sur le stockage distant) et le code sur le dépôt Git. De plus, avec cette méthode, vous pouvez versionner n’importe quel fichier de données, modèles aux images.
Les données n’étaient qu’un aspect de la conception. Pour valider le flux de soumission dans la compétition, il existe un outil pour soumettre des soumissions sur Kaggle avant le lancement, donc j’ai décidé de construire un pipeline pour construire des soumissions aléatoires et évaluer la performance de la métrique RMSE utilisée pour l’évaluation de la compétition.
Construire les soumissions pour tester la compétition
Le flux pour cette évaluation est de :
- Construire la soumission
- Calculer le RMSE sur le classement public et privé (défini dans le fichier solution.csv)
Pour déclencher le flux, j’ai décidé d’exploiter la fonctionnalité de pipeline de données de DVC (basée sur ce tutoriel) qui offre la possibilité de construire un DAG avec deux étapes. Pour déclencher cette fonctionnalité, j’ai utilisé les commandes suivantes.
dvc stage add --force -n build_submissions \
-p build_submissions.seed\
-d build_submissions.py \
python build_submissions.py # add a new step in the DAG
dvc repro # execute the DAGLa première commande a construit un fichier de configuration pour le DAG et l’a exécuté par la deuxième commande. La configuration ressemble à ceci.
stages:
build_submissions:
cmd: python build_submissions.py
deps:
- build_submissions.py
params:
- build_submissions.seed
outs:
- ./data/random_submission.csv
compute_rmse_random:
cmd: python compute_rmse.py ./data/random_submission.csv ../dvc_build_kaggle_competition/data/kaggle/
./data/metrics_random.json
deps:
- ./data/random_submission.csv
- compute_rmse.py
metrics:
- ./data/metrics_random.json:
cache: falseAvec DVC facilement, le DAG peut être affiché avec une ligne de commande avec dvc dag (rappel de vim pour quitter cette vue**:q **)
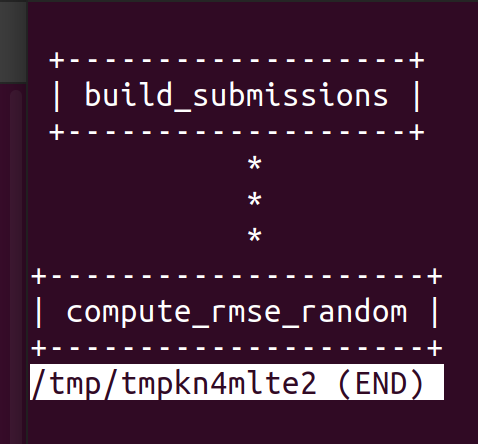
Une chose également utile lorsque vous utilisez un pipeline de données de DVC est de construire un fichier params.yaml qui configurera l’exécution du travail (dans mon cas, contenant uniquement le numéro de seed que je veux appliquer pour faciliter la reproductibilité de mon pipeline de soumissions aléatoires)
Tout le code que j’ai construit pour ce pipeline est dans ce dépôt sur Github.
Une autre fonctionnalité qui peut être utile dans ce contexte d’évaluation est la possibilité de construire des métriques. Dans la dernière étape, calculer RMSE, vous pouvez voir une notion de métrique dans le fichier de configuration (un JSON avec les valeurs RMSE sur les données des classements publics et privés). Cette notion de métrique est pratique car DVC joue le rôle de l’orchestrateur de tâches. Il peut également enregistrer des informations sur l’exécution (dans ce cas, le RMSE), le versionner avec Git et enregistrer un historique de son évolution. J’ai rapidement testé mon rmse localement, et le RMSE calculé sur l’outil kaggle est assez similaire (comme prévu).
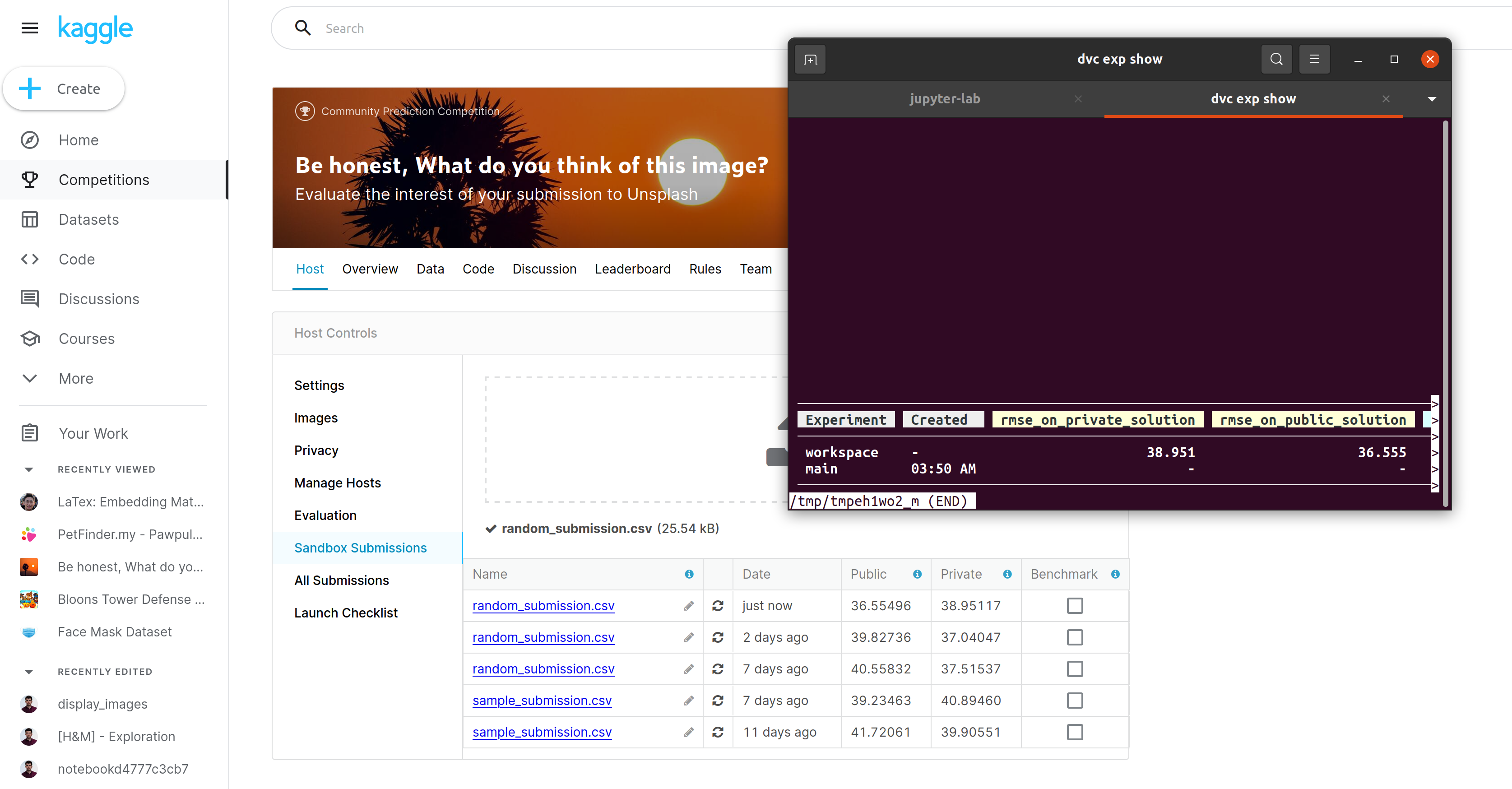
Je voulais également essayer un outil publié il y a quelques semaines/mois appelé iterative studio (à l’origine, c’était DVC studio). L’outil connecte votre projet DVC et votre dépôt git à une interface pour parcourir les changements et comparer les différentes exécutions commitées. L’outil est facile à configurer dans l’ensemble (vous devez donner quelques accès), et définitivement, c’est une interface conviviale, mais je n’ai pas réussi à afficher mes métriques 😶🌫️; vous pouvez trouver la vue de mon projet ici.
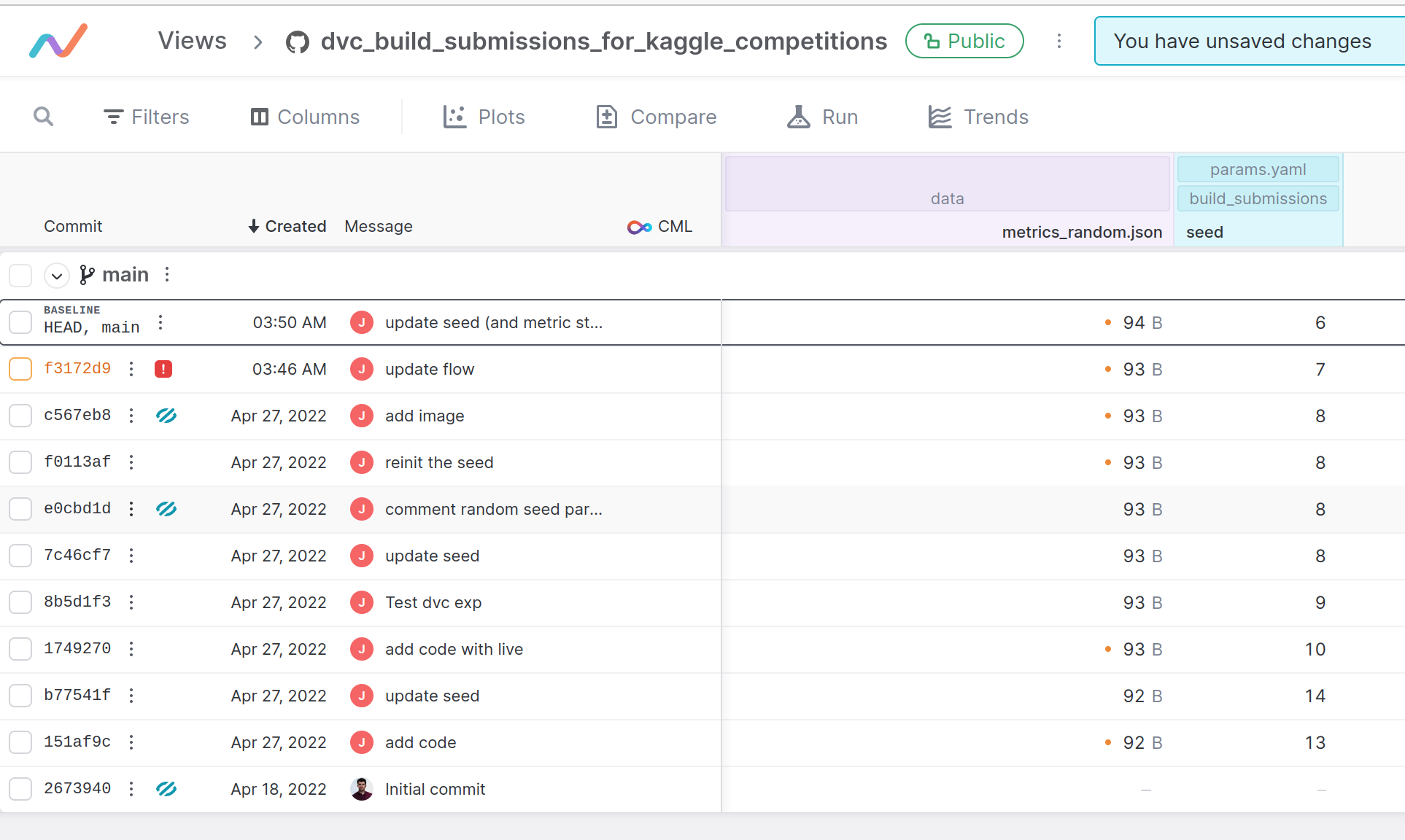
L’outil offre une très belle façon de vérifier l’évolution des paramètres dans le fichier de configuration, par exemple (dans mon cas, le seed pour la soumission aléatoire) avec un lien vers les différents commits sur le dépôt.
Enfin, et pour conclure sur DVC et son facteur métrique, DVC a une fonctionnalité de journalisation autour des métriques très similaire à mlflow ou weight and bias appelée dvc live. La bibliothèque semble plus orientée vers l’entraînement du modèle avec epoch (cela ressemble à cela sur la démo), j’ai essayé de l’utiliser sur mon projet, mais cela n’a pas trop de sens. Les fonctionnalités qu’elle contient semblent cool :
- connexion avec iterative studio
- construire un rapport HTML à la fin d’un pipeline
Et maintenant nous en avons fini avec la conception de la compétition.
Conclusion
Si vous êtes curieux de voir la compétition construite à partir de cette expérience (et peut-être d’y participer), il y a le lien.
Dans l’ensemble, mon expérience avec DVC était excellente, l’outil est pour les data scientists, et l’intégration avec Git est vitale, donc cela facilite le déploiement en production et la traçabilité. De plus, j’ai été positivement surpris par la possibilité de construire et d’exécuter des DAG avec DVC en inspirant le développement du pipeline ML.
Un composant critique qui n’était pas évident dans cet article est autour de l’écosystème Iterative ; il y a bien plus que DVC et iterative studio dans leur boîte à outils :
- CML, un CI/CD pour les projets ML, l’un de mes collègues nous a fait une démo récemment, et cela semble super prometteur pour l’opération d’un pipeline ML.
- MLEM, outil pour déployer un modèle ML (et registre de modèles), j’ai eu mon accès à la beta très récemment, mais je pense que c’est prometteur (restez à l’écoute)
- TPI, plug-in Terraform pour gérer les ressources informatiques sans être un expert du cloud (passionnant pour moi)
L’écosystème semble s’attaquer à de nombreux aspects du problème MLops et va plus loin que de nombreuses solutions actuellement sur le marché.
Mais j’ai encore quelques questions qui me viennent à l’esprit et auxquelles peut-être certains employés de DVC (s’ils voient cet article) seront intéressés de discuter :
- De mon point de vue, dans un contexte d’un pipeline Spark entier, DVC ne semble pas être le bon outil pour versionner les données (écrire des fichiers localement pour les ajouter au projet ne me semble pas efficace) ; quelle serait l’approche appropriée dans ce cas ?
- Automatisation, actuellement l’exécution du pipeline semble très manuelle avec les commandes DVC et git, mais dans un contexte d’un pipeline qui exécute des prédictions régulièrement (déclenché par un planificateur externe qui mettra à jour un ensemble de scoring avec de nouveaux utilisateurs et de nouvelles fonctionnalités). Comment DVC peut-il aider à versionner l’ensemble de scoring à chaque exécution ?
J’espère que vous avez apprécié la lecture et que cela déclenchera quelques tests de votre côté.
Références
- DVC — dvc.org
- iterative — iterative.ai
- Prix créateur de compétition communautaire Kaggle — Kaggle
- Compétition Petfinder Pawpularity Score — Kaggle
- Petfinder.my — petfinder.my
- Section discussion de la compétition Petfinder — Kaggle
- Jeu de données Unsplash sur GitHub — GitHub
- Version lite du jeu de données Unsplash — unsplash.com
- RMSE — Wikipedia — Wikipedia
- Guide de configuration des compétitions communautaires Kaggle — Kaggle
- Tutoriel DVC sur la gestion des données — dvc.org
- Tutoriel DVC sur les pipelines — dvc.org
- DAG — Wikipedia — Wikipedia
- Dépôt GitHub pour les soumissions DVC Kaggle — GitHub
- Vue du projet Iterative Studio — studio.iterative.ai
- Documentation DVCLive — dvc.org
- Compétition Kaggle — Be Honest What Do You Think of This Image — Kaggle
- CML — CI/CD pour ML — cml.dev
- MLEM — Outil de déploiement de modèles ML — mlem.ai
- Terraform Provider Iterative (TPI) — GitHub
- Terraform — terraform.io