
Plus de démarrage à froid : utiliser les transformers pour construire des decks dans Marvel Snap
Note: Cet article a été traduit avec Claude Code le 31 janvier 2026. La version originale est disponible ici.
Bienvenue dans le monde passionnant de Marvel Snap, où stratégie et compétence se rencontrent pour créer le jeu de cartes numérique ultime. Construire le deck parfait est crucial pour réussir, mais avec tant de cartes parmi lesquelles choisir, il peut être difficile de savoir par où commencer, surtout en ce qui concerne les nouvelles cartes. C’est un problème courant dans le monde des systèmes de recommandation, connu sous le nom de problème du “démarrage à froid”.
Cet article explorera comment utiliser un ensemble de données lié aux decks Marvel Snap que j’ai récemment construit. De la compréhension des règles du jeu à la découverte de nouvelles combinaisons de cartes et à la création d’embeddings, cet article vous guidera à travers le processus de construction d’un système de recommandation capable de gérer de nouveaux éléments et d’aider à découvrir de nouvelles approches pour jouer à Marvel Snap.
Alors, construisons le deck ultime tout en abordant le problème du “démarrage à froid”.
Construire un deck pour la victoire : une introduction à Marvel Snap
Il y a quelques semaines, j’ai commencé à construire un ensemble de données lié à une récente addition à mes passe-temps, Marvel Snap, un jeu de cartes numérique construit par Second Dinner.

L’objectif de la construction d’un deck dans Marvel Snap est de confronter des joueurs dans des matchs 1v1 et de gagner en ayant la puissance la plus élevée cumulée par les cartes du côté du terrain du joueur.
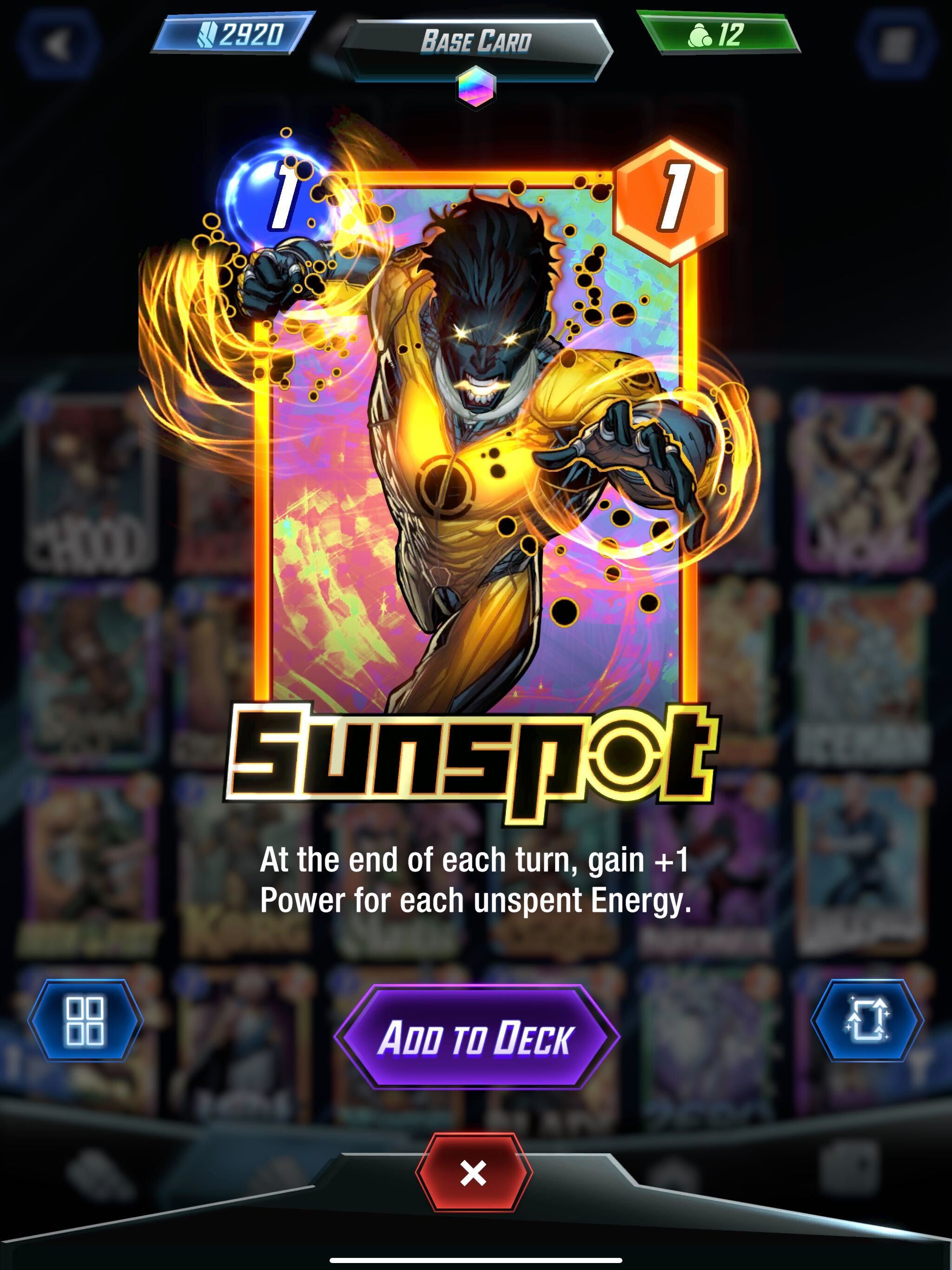
Le nombre dans le cercle bleu définit l’énergie, et cette carte possède une puissance (dans le cercle orange); cette carte peut également avoir une capacité unique qui peut être permanente ou apparaître pendant la phase de révélation. Les cartes dans Marvel Snap possèdent des capacités uniques qui peuvent être permanentes ou activées pendant la phase de révélation; ces capacités peuvent donner un avantage au joueur en augmentant la puissance des cartes ou en ajoutant de nouvelles règles au match.
C’est un jeu divertissant, facile à jouer et difficile à maîtriser, c’était une présentation très brève des règles, mais si vous voulez mieux comprendre le jeu, il y a une bonne vidéo des créateurs.
Maintenant, concernant l’ensemble de données, il existe plusieurs sites où les gens partagent leurs meilleurs decks dans le jeu; le plus populaire est Marvel Snap Zone. J’ai construit un scraper que j’ai exécuté périodiquement pour collecter des decks et des cartes sur le site web, et vous pouvez trouver ces données sur Kaggle ICI.
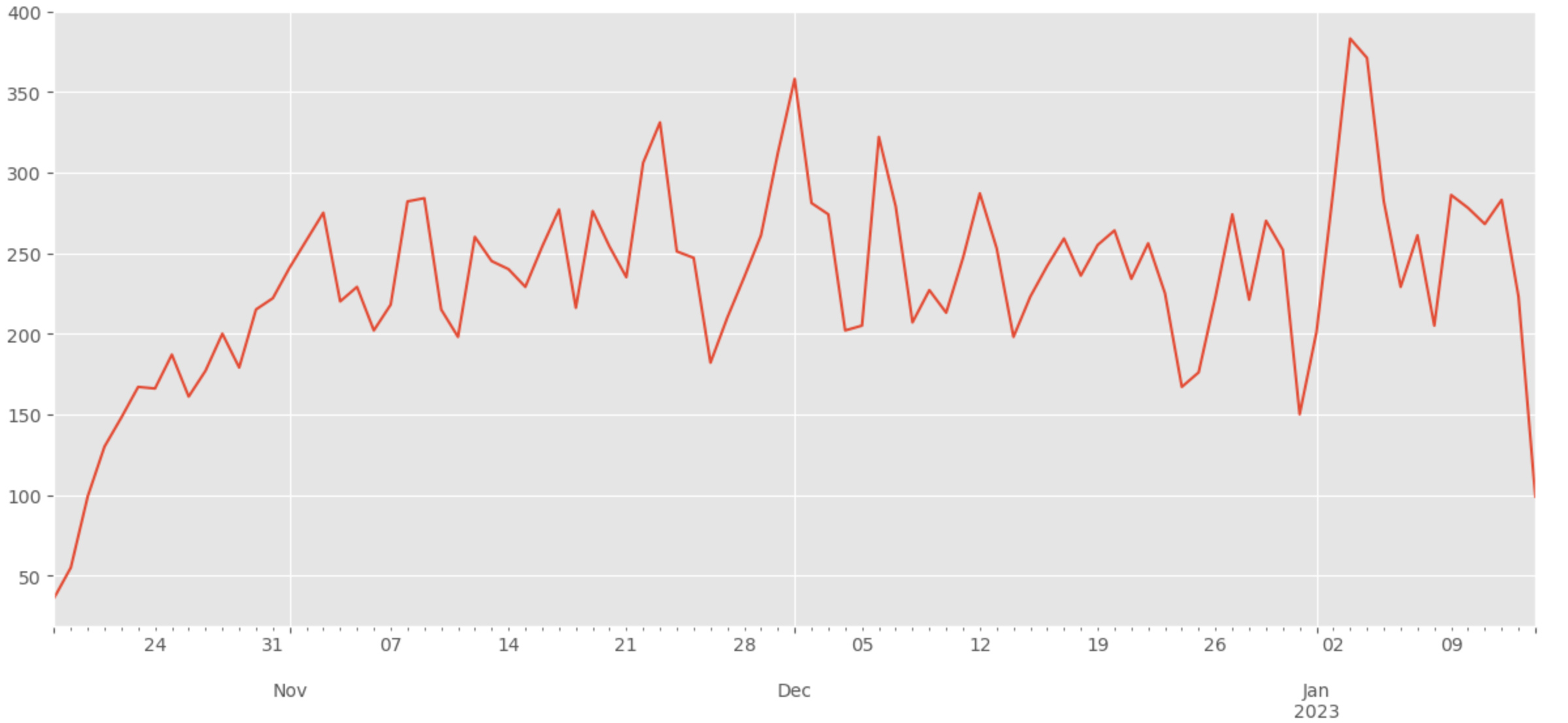
Après un peu d’ETL et de filtrage basé sur l’analyse des decks (assez de cartes, bonnes cartes et date de dernière mise à jour), il y a environ 20723 decks pour 245 cartes dans la version actuelle. Voici une représentation simple de l’évolution des decks depuis la sortie officielle du jeu.
Cet ensemble de données est bon mais loin d’être parfait :
- L’art associé à la carte n’est pas tout à fait propre
- Aucune information sur le taux de victoire des decks et l’utilisation de la carte lors d’un match
Avec tout cela à l’esprit, parlons des systèmes de recommandation.
Créer une stratégie gagnante : implémenter un système de recommandation pour Marvel Snap
Pour cette section, j’équilibre mon rôle de data scientist et de joueur de Marvel Snap et j’utiliserai cette double perspective pour concevoir un cas d’usage liant les deux.
L’un des défis de Marvel Snap est de déterminer par où commencer pour construire un deck. En tant que joueur, je suis très intéressé par une fonctionnalité qui peut me guider dans la construction d’un deck et démarrer un deck à partir d’une carte spécifique.
Voici un exemple de ce à quoi la fonctionnalité pourrait ressembler.
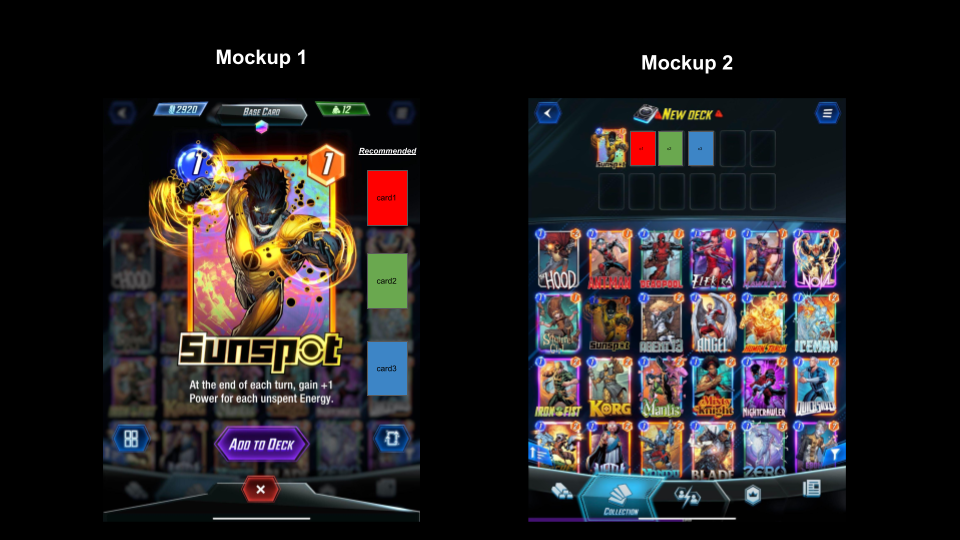
À partir de l’ensemble de données que j’ai construit, il est très simple de le faire en construisant un comptage d’associations par carte avec d’autres (exemple ICI). Voici une illustration du flux de construction de ces associations.

Pour illustrer cela, j’ai sélectionné les cartes suivantes avec des attributs très distincts.

Sunspot est une carte à 1-coût avec une capacité unique pour augmenter sa puissance avec les énergies restantes, Ka-zar soutient les cartes à un coût, et Heimdall est une carte forte avec la capacité de déplacer des cartes. Si nous revenons à l’association, il est simple de classer la carte par l’occurrence avec laquelle elles sont associées ensemble. Voici quelques résultats pour les trois cartes sélectionnées.



Les associations font beaucoup de sens, selon mon expérience, mais voici quelques analyses :
- Sunspot est lié à des cartes solides, et il y a une connexion avec d’autres cartes ayant des capacités liées au niveau d’énergie (comme she-hulk)
- Ka-zar est lié à squirrel girl et Ultron qui produisent des cartes pouvant être améliorées par sa capacité OU d’autres cartes qui améliorent la puissance des cartes à 1 coût.
- Heimdall est lié à des cartes qui peuvent se déplacer sur le terrain ou qui sont améliorées par un mouvement.
Nous avons un vecteur qui stocke l’association globale normalisée avec les autres cartes pour chaque carte (c’est un vecteur avec plus de 240 composants). Ce vecteur est un embedding, et comme il est normalisé, il est facile de calculer une distance entre les cartes basée sur l’embedding. Pour faciliter le calcul, nous allons utiliser la distance euclidienne, mais il y avait d’autres options possibles.
Voici une visualisation des distances.
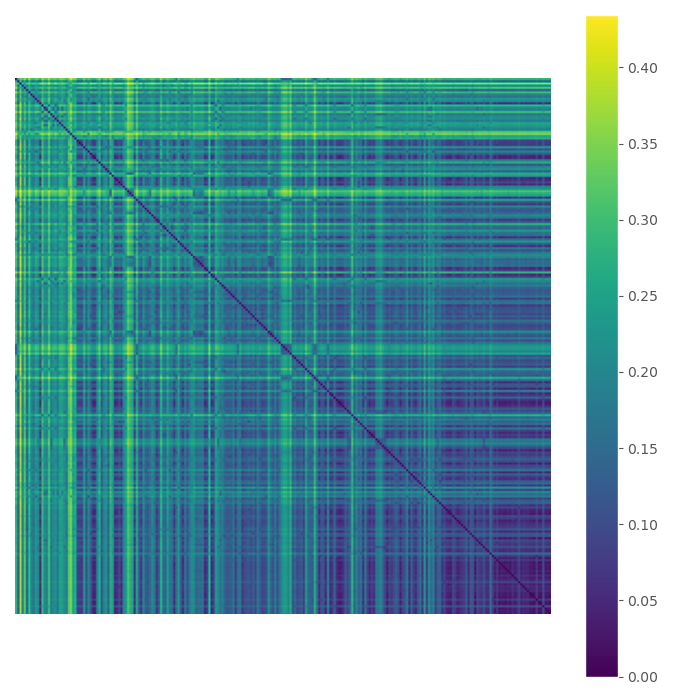
Avec ces distances, il est facile de construire d’autres types de recommandations qui auront une connaissance plus approfondie des associations de cartes. (la plus petite distance signifie qu’elles sont plus proches)



Il y a toujours des recommandations similaires, mais de nouvelles tendances émergent (comme hulk + sunspot).
Dans un jeu comme celui-ci, de nouvelles cartes peuvent apparaître avec de nouvelles versions ou lorsque certains joueurs atteignent un certain niveau d’expérience; récemment, Zabu est apparu sur mon radar.

Sur la base des systèmes de recommandation précédents, voici les recommandations pour Zabu.
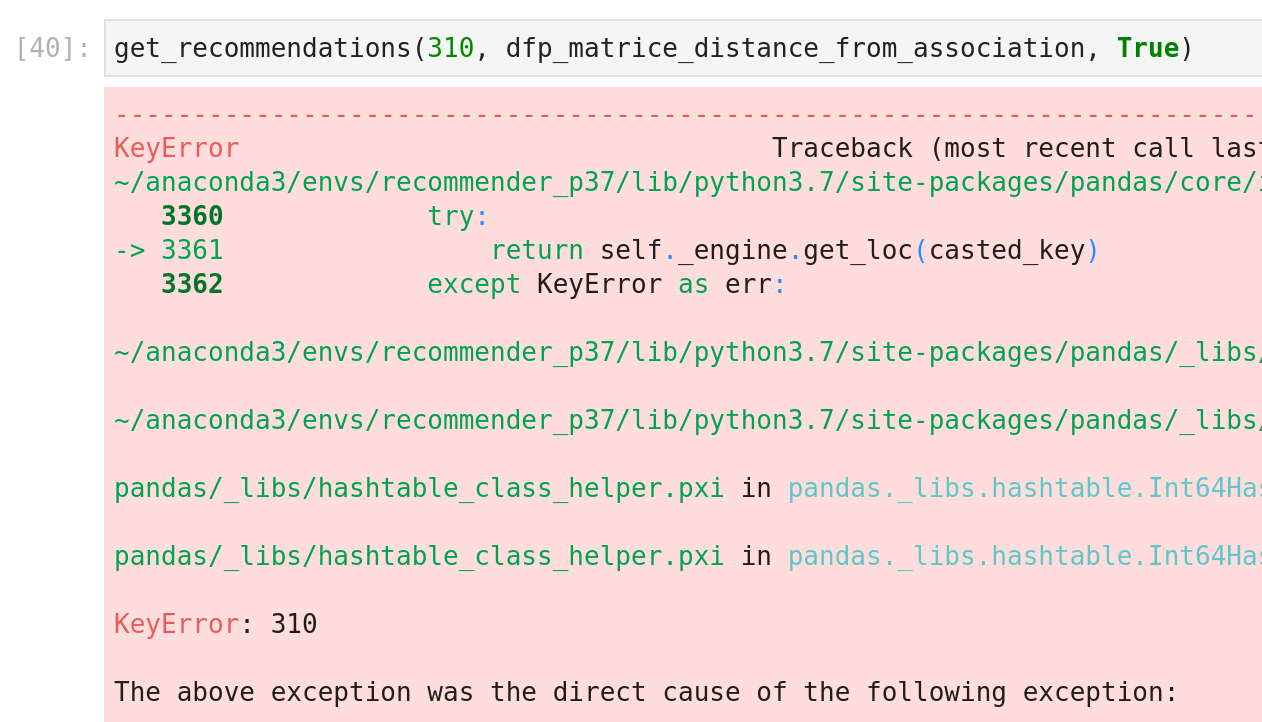
Comme prévu, la fonctionnalité ne fonctionne plus.
J’ai supprimé tous les decks associés à Zabu pour le simuler comme une nouvelle carte et illustrer ce piège des systèmes de recommandation.
Découvrir de nouvelles approches : gérer le démarrage à froid et construire des embeddings dans Marvel Snap
Cet exemple illustre parfaitement un phénomène dans le système de recommandation appelé démarrage à froid pour un élément. Le démarrage à froid peut être de deux types :
- Utilisateur : un nouvel utilisateur s’inscrit sur une plateforme e-commerce et commence à parcourir les produits mais n’a pas encore consulté, acheté ou évalué d’articles.
- Élément : un nouveau produit vient d’être ajouté à la plateforme mais n’a pas encore été consulté, acheté ou évalué par des utilisateurs.
Dans ce scénario, le système de recommandation manque de données suffisantes sur l’interaction de l’utilisateur avec le produit ou les caractéristiques du produit pour faire des recommandations précises.
Dans notre cas, c’est un démarrage à froid lié à un élément car il n’y a pas d’interactions, donc construire des recommandations est impossible (avec les mêmes méthodes précédentes), mais ne vous inquiétez pas, il existe des solutions pour réchauffer la situation.
C’est une approche possible qui donnera une idée générale d’un flux possible pour aborder le problème du démarrage à froid lié aux éléments, mais gardez à l’esprit qu’il existe des approches plus simples ou plus complexes pour aborder ce problème.
L’idée du flux est représentée dans ce schéma
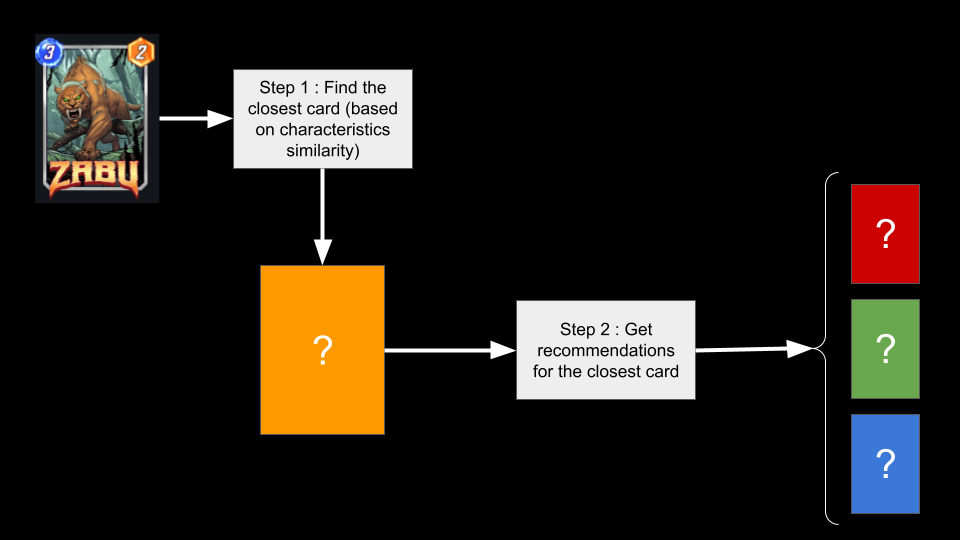
Ce flux peut être assigné à un système de recommandation hybride car il mélange le filtrage basé sur le contenu (étape 1) et les techniques de recommandation classiques (étape 2). La deuxième étape est assez simple, mais comment trouver les cartes les plus proches de la carte Zabu ? Nous connaissons les caractéristiques de la carte, comme son coût, sa puissance ou sa capacité, et c’est suffisant pour prototyper quelque chose.

L’idée est de construire des embeddings; je voulais aller dans la voie du texte, construire une description de la carte qui intégrera le coût, la puissance et la capacité et, après cela, utiliser un transformer pour créer des embeddings à partir de la description.
La fonction pour construire la description est simple.
dfp_cards["description"] = dfp_cards.apply(lambda row: f"This card is called {row['cname']} with a cost of {row['cost']} and a power of {row['power']}. His ability is {row['ability']}".lower(), axis=1)Maintenant, la partie délicate est les transformers, commençons par un mème.
Les transformers ont été la technique phare en apprentissage automatique au cours des cinq dernières années; c’est l’approche derrière des applications comme dalle ou chatgpt, par exemple. Ils sont également utilisés dans d’autres domaines que l’IA générative, comme les systèmes de recommandation (cf recsys 2022 récapitulatif), la vision par ordinateur, etc.
Comment cela fonctionne-t-il sous le capot ? Souvenez-vous que les transformers sont un type d’architecture de réseau de neurones que Google a introduit en 2017 dans l’article “Attention is all you need.” La partie critique de cette architecture est son mécanisme d’auto-attention, qui permet au modèle (dans un contexte NLP) de peser l’importance de différents mots dans une phrase lors de la prédiction. De plus, cela permet au modèle de gérer des séquences d’entrée de longueurs variables et des dépendances à longue portée dans les données.
Actuellement, il existe de nombreuses architectures différentes utilisant l’idée des Transformers avec quelques ajustements; j’ai lié quelques articles sur le sujet :
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- GPT: Improving Language Understanding by Generative Pre-Training
- GPT-2: Language Models are Unsupervised Multitask Learners
- GPT-3: Language Models are Few-Shot Learners
- Roberta: A Robustly Optimized BERT Pretraining Approach
- ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Dans l’article original de Google, l’architecture ressemble à cela.

Il est composé d’un encodeur et d’un décodeur; dans notre cas, nous nous concentrerons uniquement sur la partie d’encodage, mais si vous êtes curieux de comprendre comment cela fonctionne, il y a un excellent cours sur Hugging Face avec un chapitre dédié ICI.
Pour exploiter la partie encodeur d’un transformer, j’ai utilisé un package appelé sentence-bert qui exploite PyTorch et Transformers (de Hugging Face encore, l’un des créateurs du package est un ancien de Hugging Face) pour rendre les pièces d’un transformer facilement accessibles, et c’est très simple à faire.

(J’ai utilisé le modèle basé sur Microsoft mp-net dans ce cas)
Avec cette technique, il est simple d’encoder la description et d’obtenir un embedding (avec ce modèle, c’est un vecteur avec 768 composants). Si nous appliquions cette technique à toutes les cartes, voici quelques résultats pour les cartes initiales sélectionnées (Sunspot, ka-zar et Heimdall) basés sur la distance euclidienne entre les embeddings de leurs descriptions.



Comme nous pouvons le voir, il y a quelques connexions intéressantes, similaires à ce qui était dans l’association des decks (comme Heimdall-Quake, par exemple), mais de nouvelles tendances émergent également.
Revenons à Zabu, sa carte la plus proche de l’analyse des distances euclidiennes semble être ka-zar, donc voici les cartes recommandées basées sur mon flux.


Pour être honnête, je pense que cela n’a pas beaucoup de sens, j’ai reconstruit une matrice d’association avec toutes les cartes, et voici la recommandation attendue (basée sur l’association)

Cela a plus de sens certainement (pour de nombreuses cartes à 4-coûts, Zabu est bénéfique pour faciliter leur utilisation).
Peut-on dire que c’est un échec ? Pas vraiment, car je pense que l’approche est toujours bonne (dans le flux) mais nécessite quelques ajustements pour être meilleure :)
Récapitulatif et prochaines étapes
Cet article a été l’occasion de :
- Donner plus de détails sur mon récent ensemble de données sur Kaggle (gardez à l’esprit que j’essaierai également de le mettre à jour régulièrement)
- Explorer l’encodage d’un élément basé sur sa description; je pense que c’est toujours une approche solide pour commencer qui nécessite quelques ajustements (avec des métriques à optimiser)
Il existe de nombreuses autres approches pour construire des embeddings pour un élément ou pour aborder le démarrage à froid en général (selon le type d’éléments et les recommandations à fournir), donc ce ne sera pas la dernière expérience sur le sujet pour moi. Pour être honnête, je pense que pour concevoir ce genre de recommandations, pour le nombre de cartes disponibles, je pense que commencer avec des règles codées en dur pour chaque carte peut être faisable et avoir plus de sens.
En bonus, j’ai également décidé de jouer avec les Spaces de Hugging Face, pour déployer et opérer une version “en direct” des systèmes de recommandation. J’ai donc simplement intégré les différents systèmes de recommandation dans cette application, et vous pouvez également l’utiliser ici (pas de plan pour faire une mise à jour des données/app, mais qui sait).
J’ai eu du mal à utiliser l’intégration git, mais Hugging Face offre également une excellente façon glisser-déposer pour déployer des spaces.
Ce projet m’a donné la motivation de :
- Creuser davantage dans l’utilisation de techniques d’apprentissage profond comme les transformers en général (je viens de trouver ce grand notebook lié aux systèmes de recommandation de Janu Verna de Microsoft)
- Travailler sur un projet autour de la visualisation d’embeddings/réduction de dimensionnalité : j’ai joué avec ces données et TSNE, mais je veux prendre plus de temps dessus.
- Commencer des cas d’usage NLP.
Au-delà de cet article, j’aime discuter de données, d’IA et de conception de systèmes - comment les projets sont construits, où ils réussissent et où ils échouent. Si vous voulez échanger des idées, remettre en question des hypothèses ou parler de vos propres projets, n’hésitez pas à me contacter. Je suis toujours ouvert à une bonne conversation.
Références
- ensemble de données — Kaggle
- Marvel Snap — marvelsnap.com
- Second Dinner — seconddinner.com
- Marvel Snap Zone — marvelsnapzone.com
- ICI — Kaggle
- distance euclidienne — Wikipedia
- Attention is all you need — arXiv
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding — arXiv
- GPT: Improving Language Understanding by Generative Pre-Training — openai.com
- GPT-3: Language Models are Few-Shot Learners — openai.com
- Roberta: A Robustly Optimized BERT Pretraining Approach — arXiv
- ALBERT: A Lite BERT for Self-supervised Learning of Language Representations — arXiv
- ICI — Hugging Face
- sentence-bert — documentation
- Transformers — Hugging Face
- le modèle basé sur Microsoft mp-net — Hugging Face
- Spaces — Hugging Face
- dans cette application — Hugging Face
- grand notebook — GitHub