
Hello, the season of the Open starts again this year (once again !?) so I am writing this article to:
- Introduce a new dataset on kaggle
- Have an overview of the last open
What are the Open ?
The Open is a process of selection for the “world cup” call the Games of crossfit that will happened next year in the US. This selection is 5 weeks long, composed of 5 events called WoD where every participant in the open has to completed to obtain a score and be in the leaderboard for the selection for the Games (where the best in the leaderboard are chosen). Everybody that is part of a gym called affiliate can participate to this competition there is multiple divisions and if you don’t feel capable to do the original WoD (like me) you can do a “scaled” version where the original will be a little bit modified but the spirit of the exercice will be the same.
You can find more details on the exercices of the last open at this link.
I started to collect the data on the Open in 2018 in a previous article, I decided now to share part of the data that I collected on the events. The data can be found at this link on kaggle website and you will find data about the open of 2019.
The dataset is described and I will try to add more and more data on the opens and the games in the future (I am planning to do some ML work with these data in the future).
So now let’s start the analysis.
Overview of the Open
In the following figure there is a repartition of the athletes in the different divisions of the selection.
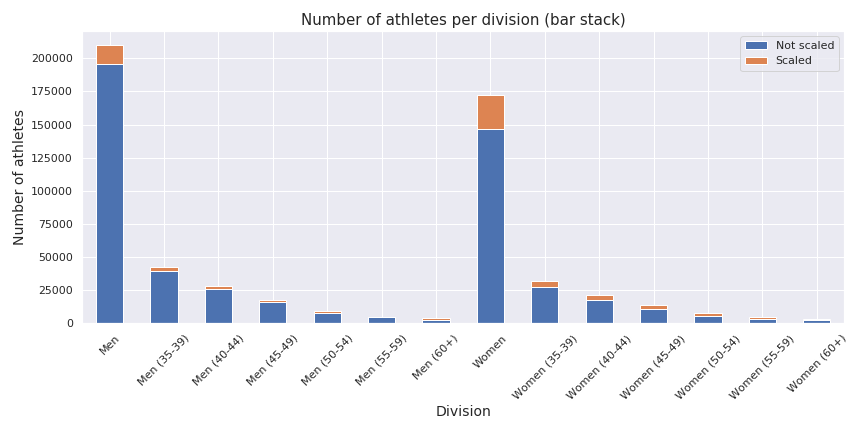
As we can see the some most popular divisions are the Men and Women divisions and most of the athletes are not scaling the exercice. There is around 355418 athletes that were in the competition.
For the next step of the analysis I am going to focus on the Men and Women divisions, not scaled (so around 341875 athletes).
Let’s have now have a look on the popularity of the competition in these divisions.
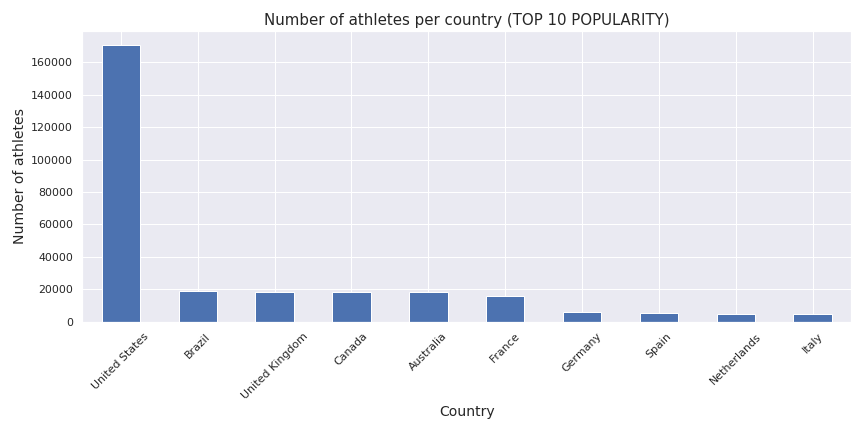
As the crossfit is coming from the US, as expected the more important bastion of athletes is in the US followed by the Brazil and the UK. The other buckets of countries are way smaller than the US.
What is the parity in this buckets ?

It looks like that there is still more men but the parity is not too far.
I computed some simple analysis on the athletes based on the overall score during the open and I classified in different categories:
- Are they top 100 athletes ? Yes or No
- Are they top 1000 athletes ? Yes or No
So let’s see if some countries can be defined at “Champion nest”.
Evaluation of the country based on their top athletes
Let’s have a look first on the country where the crossfit is the most popular.
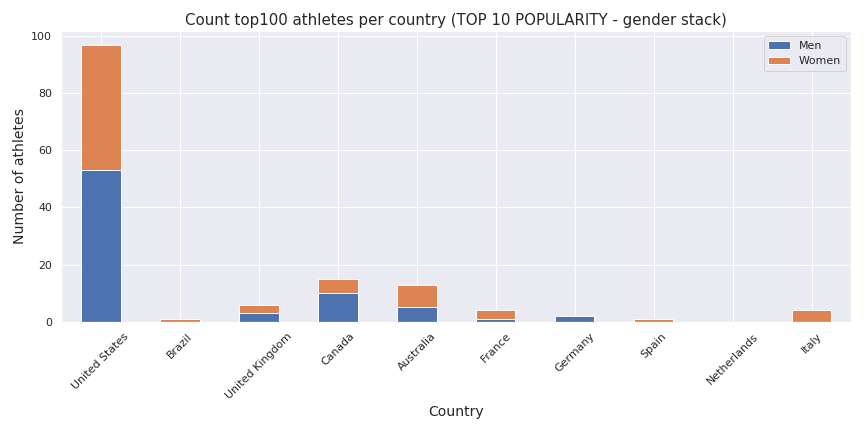
As we can see popularity is not synonym of champion. If we except the US the order is not respected on the number of top athletes.
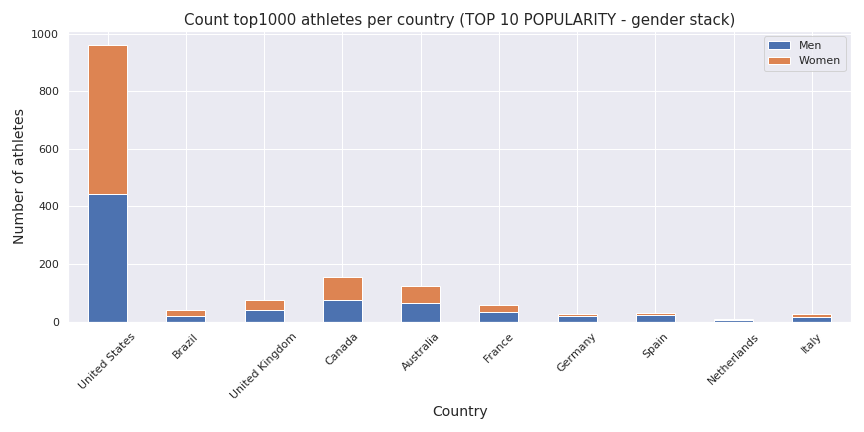
Still the same logic but each country as some champions in the top 1000.
Let’s have a look now on top country based on the number of top athletes.
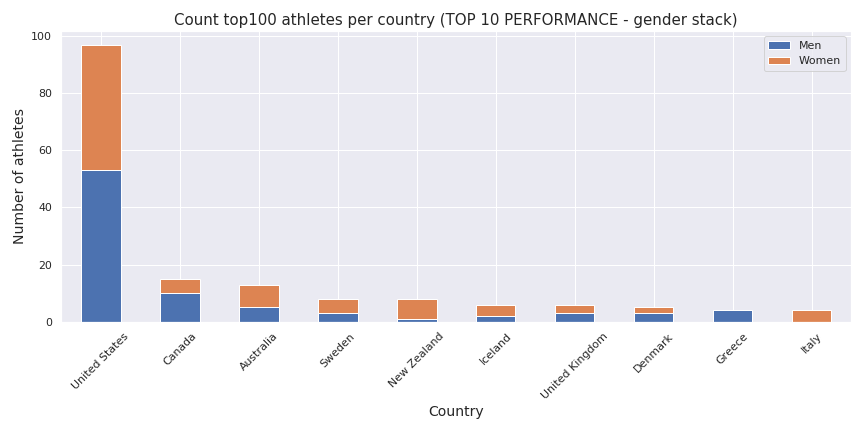
As we can see there is some newcomers in the list of the countries, and some small country like New Zealand and Iceland (in terms of crossfiters and population) are making champions (the former woman who won the game this year is from New Zealand).
Now let’s try to find the answer to the following question:
What makes a top athlete ?
I try to add some data related to the country from the world bank data but I found no real connection between the country and the fact to have some top athletes in their pool (I attached some of this data in the Kaggle dataset).
As in the data about the athletes some of them gave their weight and height (but it is a free field so there is a lot of crap inside). If I just dropping the athlete that didn’t fill the field I am loosing around 45% of the athletes. I just made a quick pairplot with the height, weight and the BMI versus if the athlete are on the top (I dropped some bad values).
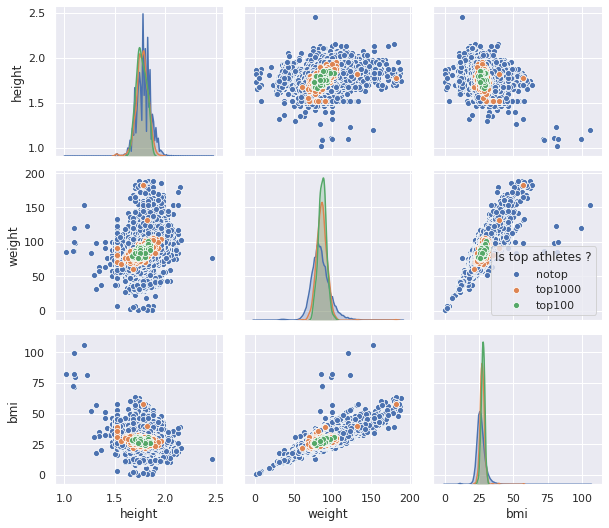
There is no real optimal body it seems to be in the top athletes the people looks very fit but they don’t have crazy body (like hercules or captain america), they are people with normal size but very fit.
But now a new question is popping on my mind is Are they managing their effort during the Open ?
So far the WoD are not know in advance so maybe that this guy try to keep energy during tha ll Open to be more performant on some specific WoD. There is a pairplot based on the score of the athletes at each WoD.

The results are the same for women than men but as we can see for the Men there is definetly clusters based on the fact that most of the athletes are not completing all the WoD. Let’s have a zoom on the athletes that really have completed all the WoD.
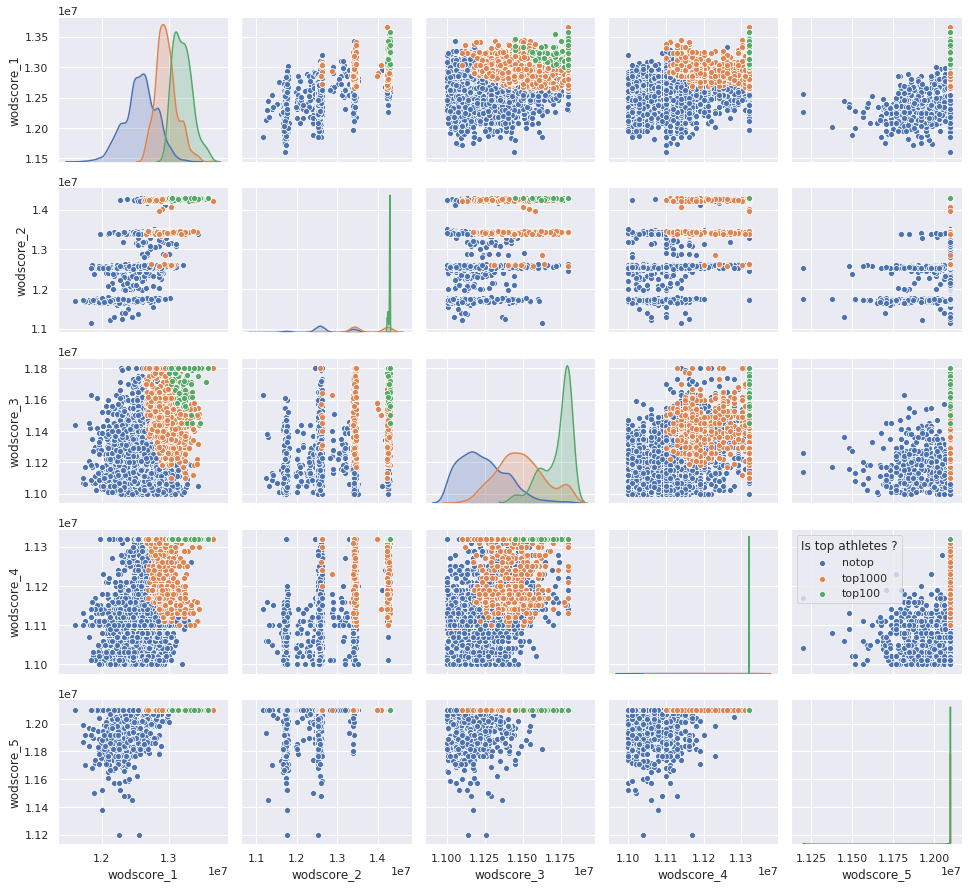
It seems that there is no “laisser aller” for the top 100 athletes they are going “ALL IN” and they are always on the top score for each WoD. The top 1000 looks a little bit more disperse than the top 100 so we can say that the 100 are definetly MACHINES.
Conclusion
As we can see from this analysis:
- the crossfit looks like to be a sport that is popular to the men and the women, and that could be explained by the fact that it’s always been advertised equally fro both genders
- The top athlete don’t have physic out of the normal in term of weight and height
- It doesn’t seems that there is no strategy to win the Open just go ALL IN
As I said previously I am planning to add more data in the dataset and make some other analysis but honestly this analysis is an appetizer (like 2 hours max) don’t hesitate to contact me if you have any remarks/ideas/results for the dataset.







{kind=link}